
Qual linguagem de programação você deve usar para web scraping? Depende do seu projeto — e eu já vi desenvolvedores desistirem irritados depois de escolher a errada.
O mercado de software de web scraping alcançou . A linguagem certa pode significar resultados mais rápidos e menos manutenção. A errada vira raspadores quebrados e fins de semana perdidos.
Trabalho com ferramentas de automação há anos. Aqui estão sete linguagens que já usei para scraping — com trechos de código, trade-offs honestos e uma análise de quando vale mais a pena largar a programação de lado e usar no lugar.
Como Escolhemos a Melhor Linguagem para Web Scraping
Quando o assunto é web scraping, nem todas as linguagens de programação são iguais. Já vi projetos decolarem — e também afundarem — por causa de alguns fatores-chave:
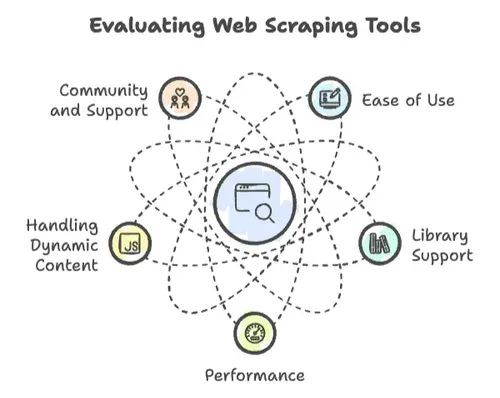
- Facilidade de uso: Com que rapidez você consegue começar? A sintaxe é amigável ou você precisa de um PhD em ciência da computação só para imprimir “Hello, World”?
- Suporte a bibliotecas: Existem bibliotecas robustas para requisições HTTP, parsing de HTML e tratamento de conteúdo dinâmico? Ou você vai reinventar a roda?
- Desempenho: Ela consegue lidar com a extração de milhões de páginas ou trava depois de algumas centenas?
- Tratamento de conteúdo dinâmico: Os sites modernos amam JavaScript. Sua linguagem dá conta do recado?
- Comunidade e suporte: Quando você bater numa parede — e vai bater — existe uma comunidade para ajudar?
Com base nesses critérios — e em muitas noites testando — aqui estão as sete linguagens que vou cobrir:
- Python: a escolha padrão para iniciantes e profissionais.
- JavaScript e Node.js: o rei do conteúdo dinâmico.
- Ruby: sintaxe limpa, scripts rápidos.
- PHP: simplicidade no lado do servidor.
- C++: para quando você precisa de velocidade bruta.
- Java: pronta para empresas e escalável.
- Go (Golang): rápida e concorrente.
E, se você estiver pensando: “Shuai, eu não quero programar nada”, fique por aqui para ver o Thunderbit no final.
Web Scraping com Python: a Potência Amigável para Iniciantes
Vamos começar com a favorita do público: Python. Se você perguntar para uma sala cheia de pessoas de dados: “Qual é a melhor linguagem de programação para web scraping?”, vai ouvir Python ecoar de volta como um mantra num show da Taylor Swift.
Por que Python?
- Sintaxe amigável para iniciantes: Dá para ler código Python em voz alta e ele quase soa como inglês.
- Suporte imbatível a bibliotecas: De para analisar HTML, a para crawling em larga escala, para HTTP e para automação de navegador — Python tem tudo.
- Comunidade enorme: Mais de só sobre web scraping.
Exemplo de código em Python: extraindo o título de uma página
1import requests
2from bs4 import BeautifulSoup
3response = requests.get("<https://example.com>")
4soup = BeautifulSoup(response.text, 'html.parser')
5title = soup.title.string
6print(f"Título da página: \{title\}")Pontos fortes:
- Desenvolvimento e prototipagem rápidos.
- Toneladas de tutoriais e perguntas e respostas.
- Ótima para análise de dados — extraia com Python, analise com pandas, visualize com matplotlib.
- As bibliotecas continuam evoluindo: o lançamento 2.14 do Scrapy (janeiro de 2026) trouxe
async/awaitnativo por todo o framework, então a história de async não é mais só coisa de Selenium/Playwright.
Limitações:
- Mais lenta que linguagens compiladas em tarefas massivas.
- Lidar com sites superdinâmicos pode ficar complicado — embora Selenium e Playwright ajudem.
- Não é ideal para extrair milhões de páginas em velocidade máxima.
Resumo:
Se você está começando em scraping, ou só quer resolver as coisas rápido, Python é a melhor linguagem para web scraping — sem discussão. .
JavaScript e Node.js: Extraindo Sites Dinâmicos com Facilidade
Se Python é o canivete suíço, JavaScript (e Node.js) é a furadeira de impacto — especialmente para extrair sites modernos, cheios de JavaScript.
Por que JavaScript/Node.js?
- Nativo para conteúdo dinâmico: Ele roda no navegador, então consegue ver o que os usuários veem — mesmo que a página tenha sido construída com React, Angular ou Vue.
- Assíncrono por padrão: Node.js consegue lidar com centenas de requisições ao mesmo tempo.
- Familiar para quem faz desenvolvimento web: Se você já criou um site, já conhece um pouco de JavaScript.
Bibliotecas principais:
- : suporte a múltiplos navegadores (Chromium, Firefox, WebKit), com espera automática e proxies por contexto. Se você vai começar um novo scraper em Node em 2026, esta é a escolha padrão.
- : Chrome sem interface via Chrome DevTools Protocol. Continua excelente para tarefas só em Chrome e com dependências mais leves.
- : parsing de HTML no estilo jQuery para Node, quando você não precisa de um navegador de verdade.
Exemplo de código em Node.js: extraindo o título de uma página com Puppeteer
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
6 const title = await page.title();
7 console.log(`Título da página: $\{title\}`);
8 await browser.close();
9})();Pontos fortes:
- Lida nativamente com conteúdo renderizado em JavaScript.
- Ótimo para infinite scroll, pop-ups e sites interativos.
- Eficiente para scraping em larga escala e com concorrência.
Limitações:
- Programação assíncrona pode ser difícil para iniciantes.
- Navegadores sem interface consomem muita memória se você rodar muitos ao mesmo tempo.
- Menos ferramentas de análise de dados em comparação com Python.
Quando JavaScript/Node.js é a melhor linguagem de programação para web scraping?
Quando o site de destino é dinâmico ou você quer automatizar ações no navegador. .
Ruby: Sintaxe Limpa para Scripts Rápidos de Web Scraping
Ruby não serve só para apps Rails e poesia de código elegante. É uma ótima escolha para web scraping — especialmente se você gosta que o código leia quase como um haicai.
Por que Ruby?
- Sintaxe legível e expressiva: Dá para escrever um scraper em Ruby quase tão fácil de ler quanto sua lista de compras.
- Ótima para prototipagem: Rápida de escrever, fácil de ajustar.
- Bibliotecas principais: para parsing e para automatizar navegação.
Exemplo de código em Ruby: extraindo o título de uma página
1require 'open-uri'
2require 'nokogiri'
3html = URI.open("<https://example.com>")
4doc = Nokogiri::HTML(html)
5title = doc.at('title').text
6puts "Título da página: #\{title\}"Pontos fortes:
- Super legível e concisa.
- Ótima para projetos pequenos, scripts pontuais ou se você já usa Ruby.
Limitações:
- Mais lenta que Python ou Node.js em trabalhos grandes.
- Menos bibliotecas de scraping e menos suporte da comunidade nessa área.
- Não é ideal para sites pesados em JavaScript — embora você possa usar Watir ou Selenium.
Melhor encaixe:
Se você é Rubyist ou quer montar um script rápido, Ruby é uma delícia. Para scraping massivo e dinâmico, procure outra opção.
PHP: Simplicidade no Lado do Servidor para Extração de Dados na Web
PHP pode parecer uma relíquia da web antiga, mas ainda está firme — especialmente se você quer extrair dados diretamente no seu servidor.
Por que PHP?
- Roda em todo lugar: A maioria dos servidores web já tem PHP.
- Fácil de integrar com apps web: Extraia e exiba no seu site em uma única etapa.
- Bibliotecas principais: para HTTP, para requisições, para automação de navegador sem interface.
Exemplo de código em PHP: extraindo o título de uma página
1<?php
2$ch = curl_init("<https://example.com>");
3curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
4$html = curl_exec($ch);
5curl_close($ch);
6$dom = new DOMDocument();
7@$dom->loadHTML($html);
8$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
9echo "Título da página: $title\n";
10?>Pontos fortes:
- Fácil de implantar em servidores web.
- Bom para scraping como parte de um fluxo web.
- Rápido para tarefas simples de scraping no lado do servidor.
Limitações:
- Suporte limitado a bibliotecas para scraping avançado.
- Não foi feito para alta concorrência nem para scraping em escala.
- Lidar com sites pesados em JavaScript é complicado — embora Panther ajude.
Melhor encaixe:
Se sua stack já é PHP ou você quer extrair e exibir dados no seu site, PHP é uma escolha prática. .
C++: Web Scraping de Alta Performance para Projetos em Grande Escala
C++ é o carro esportivo das linguagens de programação. Se você precisa de velocidade bruta e controle, e não tem medo de um pouco de trabalho manual, C++ pode te levar longe.
Por que C++?
- Velocidade impressionante: Supera a maioria das linguagens em tarefas limitadas por CPU.
- Controle refinado: Gerencie memória, threads e ajustes de desempenho.
- Bibliotecas principais: para HTTP, para parsing.
Exemplo de código em C++: extraindo o título de uma página
1#include <curl/curl.h>
2#include <iostream>
3#include <string>
4size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
5 std::string* html = static_cast<std::string*>(userp);
6 size_t totalSize = size * nmemb;
7 html->append(static_cast<char*>(contents), totalSize);
8 return totalSize;
9}
10int main() {
11 CURL* curl = curl_easy_init();
12 std::string html;
13 if(curl) {
14 curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
15 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
16 curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
17 CURLcode res = curl_easy_perform(curl);
18 curl_easy_cleanup(curl);
19 }
20 std::size_t startPos = html.find("<title>");
21 std::size_t endPos = html.find("</title>");
22 if(startPos != std::string::npos && endPos != std::string::npos) {
23 startPos += 7;
24 std::string title = html.substr(startPos, endPos - startPos);
25 std::cout << "Título da página: " << title << std::endl;
26 } else {
27 std::cout << "Tag title não encontrada" << std::endl;
28 }
29 return 0;
30}Pontos fortes:
- Velocidade incomparável para trabalhos massivos de scraping.
- Ótimo para integrar scraping em sistemas de alto desempenho.
Limitações:
- Curva de aprendizado íngreme — leve café.
- Gerenciamento manual de memória.
- Poucas bibliotecas de alto nível; não é ideal para conteúdo dinâmico.
Melhor encaixe:
Quando você precisa extrair milhões de páginas ou o desempenho é absolutamente crítico. Caso contrário, talvez você passe mais tempo depurando do que extraindo.
Java: Soluções de Web Scraping Prontas para Empresas
Java é o cavalo de batalha do mundo corporativo. Se você está construindo algo que precisa rodar para sempre, lidar com toneladas de dados e sobreviver a um apocalipse zumbi, Java é seu amigo.
Por que Java?
- Robusto e escalável: Ótimo para projetos grandes e de longa duração.
- Tipagem forte e tratamento de erros: Menos surpresas em produção.
- Bibliotecas principais: para parsing, para automação de navegador, para HTTP.
Exemplo de código em Java: extraindo o título de uma página
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3public class ScrapeTitle {
4 public static void main(String[] args) throws Exception {
5 Document doc = Jsoup.connect("<https://example.com>").get();
6 String title = doc.title();
7 System.out.println("Título da página: " + title);
8 }
9}Pontos fortes:
- Alto desempenho e concorrência.
- Excelente para bases de código grandes e fáceis de manter.
- Bom suporte para conteúdo dinâmico (via Selenium ou HtmlUnit).
Limitações:
- Sintaxe verbosa; exige mais configuração do que linguagens de script.
- Exagero para scripts pequenos e pontuais.
Melhor encaixe:
Scraping em escala corporativa, ou quando você precisa de confiabilidade e escalabilidade de verdade.
Go (Golang): Web Scraping Rápido e Concorrente
Go é o novato da turma, mas já está chamando atenção — especialmente para scraping rápido e concorrente.
Por que Go?
- Velocidade de linguagem compilada: Quase tão rápido quanto C++.
- Concorrência nativa: Goroutines tornam o scraping em paralelo muito fácil.
- Bibliotecas principais: para scraping, para parsing.
Exemplo de código em Go: extraindo o título de uma página
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly"
5)
6func main() {
7 c := colly.NewCollector()
8 c.OnHTML("title", func(e *colly.HTMLElement) {
9 fmt.Println("Título da página:", e.Text)
10 })
11 err := c.Visit("<https://example.com>")
12 if err != nil {
13 fmt.Println("Erro:", err)
14 }
15}Pontos fortes:
- Muito rápido e eficiente para scraping em larga escala.
- Fácil de implantar (binário único).
- Ótimo para crawling concorrente.
Limitações:
- Comunidade menor que a de Python ou Node.js.
- Menos bibliotecas de scraping de alto nível.
- Lidar com sites pesados em JavaScript exige configuração extra (Chromedp ou Selenium).
Melhor encaixe:
Quando você precisa de scraping em escala, ou quando Python simplesmente não é rápido o suficiente. .
Comparando as Melhores Linguagens de Programação para Web Scraping
Vamos juntar tudo. Aqui vai uma comparação lado a lado para ajudar você a escolher a melhor linguagem para web scraping em 2026:
| Linguagem/Ferramenta | Facilidade de uso | Desempenho | Suporte a bibliotecas | Tratamento de conteúdo dinâmico | Melhor caso de uso |
|---|---|---|---|---|---|
| Python | Muito alta | Moderado | Excelente | Bom (Selenium/Playwright) | Uso geral, iniciantes, análise de dados |
| JavaScript/Node.js | Média | Alta | Forte | Excelente (nativo) | Sites dinâmicos, scraping assíncrono, devs web |
| Ruby | Alta | Moderado | Decente | Limitado (Watir) | Scripts rápidos, prototipagem |
| PHP | Média | Moderado | Razoável | Limitado (Panther) | Lado do servidor, integração com app web |
| C++ | Baixa | Muito alta | Limitado | Muito limitado | Desempenho crítico, escala massiva |
| Java | Média | Alta | Bom | Bom (Selenium/HtmlUnit) | Empresas, serviços de longa duração |
| Go (Golang) | Média | Muito alta | Em crescimento | Moderado (Chromedp) | Scraping rápido e concorrente |
Quando Pular a Programação: Thunderbit como Solução Sem Código para Web Scraping
Certo, vamos ser honestos: às vezes você só quer os dados — sem programação, sem depuração, sem a dor de cabeça do tipo “por que esse seletor não funciona?”. É aí que entra o .
Como cofundador da Thunderbit, eu queria criar uma ferramenta que tornasse o web scraping tão fácil quanto pedir comida. Veja o que diferencia o Thunderbit:
- Configuração em 2 cliques: Basta clicar em “AI Suggest Fields” e “Scrape”. Sem mexer em requisições HTTP, proxies ou truques anti-bot.
- Modelos inteligentes: Um modelo de scraper pode se adaptar a vários layouts de página. Não precisa reescrever seu scraper toda vez que um site muda.
- Scraping no navegador e na nuvem: Escolha entre extrair no seu navegador (ótimo para sites com login) ou na nuvem (super-rápido para dados públicos).
- Lida com conteúdo dinâmico: A IA do Thunderbit controla um navegador real — então consegue lidar com infinite scroll, pop-ups, logins e muito mais.
- Exporta para qualquer lugar: Baixe para Excel, Google Sheets, Airtable, Notion ou apenas copie para a área de transferência.
- Sem manutenção: Se um site mudar, basta rodar de novo a sugestão da IA. Chega de sessões de depuração madrugada adentro.
- Agendamento e automação: Configure scrapers para rodar em horários definidos — sem cron jobs, sem configurar servidor.
- Extratores especializados: Precisa de emails, números de telefone ou imagens? O Thunderbit também tem extratores em um clique para isso.
E o melhor? Você não precisa saber uma única linha de código. O Thunderbit foi feito para usuários de negócios, profissionais de marketing, equipes de vendas, profissionais do setor imobiliário — qualquer pessoa que precise de dados rápido.
Quer ver o Thunderbit em ação? ou confira nosso para ver demonstrações.
Conclusão: Escolhendo a Melhor Linguagem para Web Scraping em 2026
O web scraping em 2026 está mais acessível — e mais poderoso — do que nunca. Aqui está o que aprendi depois de anos na linha de frente da automação:
- Python continua sendo a melhor linguagem para web scraping se você quiser começar rápido e ter uma quantidade enorme de recursos ao seu alcance.
- JavaScript/Node.js é imbatível para extrair sites dinâmicos e pesados em JavaScript.
- Ruby e PHP são ótimos para scripts rápidos e integração com a web, especialmente se você já os usa.
- C++ e Go são seus aliados quando velocidade e escala importam.
- Java é a escolha padrão para projetos corporativos e de longo prazo.
- E, se você quiser pular a programação por completo? é sua arma secreta.
Antes de mergulhar, pergunte a si mesmo:
- Quão grande é o meu projeto?
- Preciso lidar com conteúdo dinâmico?
- Qual é o meu nível de conforto técnico?
- Quero construir algo ou só obter os dados?
Teste um dos trechos de código acima ou experimente o Thunderbit no seu próximo projeto. E, se quiser se aprofundar, confira nosso para mais guias, dicas e histórias reais de scraping.
Boa extração — e que seus dados estejam sempre limpos, estruturados e a um clique de distância.
P.S.: Se você algum dia se encontrar preso num buraco de coelho de web scraping às 2 da manhã, lembre-se: sempre existe o Thunderbit. Ou café. Ou os dois.
FAQs
1. Qual é a melhor linguagem de programação para web scraping em 2026?
Python continua sendo a principal escolha graças à sintaxe legível, às bibliotecas poderosas (como BeautifulSoup, Scrapy e Selenium) e à grande comunidade. É ideal para iniciantes e profissionais, especialmente quando você combina scraping com análise de dados.
2. Qual linguagem é melhor para extrair sites pesados em JavaScript?
JavaScript (Node.js) é a melhor opção para sites dinâmicos. Ferramentas como Puppeteer e Playwright oferecem controle total do navegador, permitindo interagir com conteúdo carregado por React, Vue ou Angular.
3. Existe uma opção sem código para web scraping?
Sim — é um raspador web com IA e sem código que cuida de tudo, de conteúdo dinâmico a agendamento. Basta clicar em “AI Suggest Fields” e começar a extrair. É perfeito para equipes de vendas, marketing ou operações que precisam de dados estruturados rapidamente.
4. Ainda preciso escolher uma linguagem se um agente de codificação com IA puder escrever o scraper para mim?
Pergunta justa em 2026. Ferramentas como Claude Code, Cursor e OpenAI Codex vão gerar tranquilamente um spider do Scrapy, um script do Playwright ou um crawler em Go + Colly a partir de um prompt de um parágrafo — então o atrito de “qual linguagem devo aprender primeiro” é realmente menor do que há dois anos. Mas o agente ainda gera código em alguma linguagem, e você — ou quem herdar o projeto — acaba lendo, depurando e implantando isso. Então a escolha ainda importa; só que agora importa mais para manutenção do que para as primeiras 30 linhas. Se você não quiser tocar em código algum, é aí que o se encaixa — ele elimina a questão da linguagem por completo.
Saiba mais: