

Dados da web são a base para vendas, marketing e operações. Se você ainda copia e cola manualmente, está ficando para trás.
Mas aqui está o problema das ferramentas de extração “gratuitas”: a maioria não é realmente gratuita. Ou são testes com limites apertados, ou deixam as funções de que você realmente precisa atrás de um paywall.
Avaliei 12 ferramentas para descobrir quais permitem trabalho de verdade no plano gratuito. Testei listagens do Google Maps, páginas dinâmicas com login e PDFs. Algumas entregaram. Outras só me fizeram perder a tarde.
Aqui vai uma análise honesta — começando pelas que eu realmente recomendaria.
Por que os Raspadores Gratuitos Importam Mais do que Nunca
Vamos ser sinceros: em 2026, web scraping não é mais coisa só de hackers ou cientistas de dados. Virou ferramenta essencial para empresas modernas, e os números comprovam isso. O mercado de software de web scraping movimentou US$ 1,01 bilhão em 2024 e deve mais que dobrar até 2032. Por quê? Porque todo mundo, de equipes comerciais a corretores de imóveis, está usando dados da web para sair na frente.
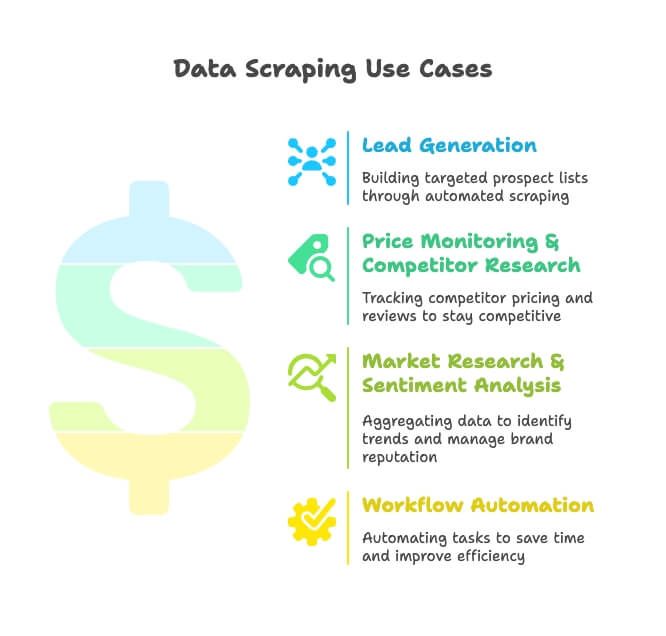
- Geração de leads: equipes de vendas extraem diretórios, Google Maps e redes sociais para montar listas segmentadas de prospects — sem caça manual.
- Monitoramento de preços e análise da concorrência: equipes de e-commerce e varejo acompanham SKUs, preços e avaliações da concorrência para se manterem competitivas (e sim, 82% das empresas de e-commerce fazem scraping exatamente por esse motivo).
- Pesquisa de mercado e análise de sentimento: profissionais de marketing reúnem avaliações, notícias e conversas em redes sociais para identificar tendências e cuidar da reputação da marca.
- Automação de fluxos de trabalho: equipes de operações automatizam tudo, de conferência de estoque a relatórios agendados, economizando horas toda semana.
E aqui vai um dado interessante: empresas que usam raspadores com IA economizam 30% a 40% do tempo em comparação com métodos manuais. Isso não é só “um pouco” de tempo — é a diferença entre sair às 18h ou às 21h.
Como Selecionamos as Melhores Ferramentas Gratuitas de Extração de Dados
Já vi muitas listas de “melhores web scrapers” que só repetem texto de marketing. Aqui não. Para esta seleção, considerei:
- Usabilidade real do plano gratuito: o plano grátis permite fazer trabalho de verdade ou é só uma amostra?
- Facilidade de uso: alguém sem conhecimento técnico consegue resultados em minutos ou é preciso um doutorado em Regex?
- Tipos de sites compatíveis: páginas estáticas, dinâmicas, paginadas, com login, PDFs, redes sociais — a ferramenta lida com cenários reais?
- Opções de exportação de dados: dá para mandar os dados para Excel, Google Sheets, Notion ou Airtable sem complicação?
- Recursos extras: extração com IA, agendamento, modelos, pós-processamento, integrações.
- Perfil de usuário ideal: a ferramenta é para usuários de negócios, analistas ou desenvolvedores?
Também analisei a documentação de cada ferramenta, testei o onboarding e comparei os limites dos planos gratuitos — porque “gratuito” nem sempre é tão gratuito quanto parece.
Visão Geral: 12 Raspadores de Dados Gratuitos Comparados
Aqui está um panorama lado a lado para ajudar você a encontrar a ferramenta certa para sua necessidade.
| Ferramenta | Plataforma | Limitações do Plano Gratuito | Ideal para | Formatos de Exportação | Recursos Exclusivos |
|---|---|---|---|---|---|
| Thunderbit | Extensão Chrome | 6 páginas/mês | Não programadores, negócios | Excel, CSV | Prompts de IA, extração de PDF/imagem, rastreamento de subpáginas |
| Browse AI | Nuvem | 50 créditos/mês | Usuários no-code | CSV, Sheets | Robôs de clique, agendamento |
| Octoparse | Desktop | 10 tarefas, 50 mil linhas/mês | No-code, usuários semi-técnicos | CSV, Excel, JSON | Fluxo visual, suporte a sites dinâmicos |
| ParseHub | Desktop | 5 projetos, 200 páginas/execução | No-code, usuários semi-técnicos | CSV, Excel, JSON | Visual, suporte a sites dinâmicos |
| Webscraper.io | Extensão Chrome | Uso local ilimitado | No-code, tarefas simples | CSV, XLSX | Baseado em sitemap, modelos da comunidade |
| Apify | Nuvem | US$ 5 em créditos/mês | Equipes, usuários semi-técnicos, devs | CSV, JSON, Sheets | Marketplace de actors, agendamento, API |
| Scrapy | Biblioteca Python | Ilimitado (open source) | Desenvolvedores | CSV, JSON, DB | Controle total via código, escalável |
| Puppeteer | Biblioteca Node.js | Ilimitado (open source) | Desenvolvedores | Personalizado (código) | Navegador headless, suporte a JS dinâmico |
| Selenium | Multilíngue | Ilimitado (open source) | Desenvolvedores | Personalizado (código) | Automação de navegador, suporte a vários browsers |
| Zyte | Nuvem | 1 spider, 1h/trabalho, retenção de 7 dias | Devs, equipes de operações | CSV, JSON | Scrapy hospedado, gerenciamento de proxy |
| SerpAPI | API | 100 buscas/mês | Devs, analistas | JSON | APIs de buscadores, anti-bloqueio |
| Diffbot | API | 10 mil créditos/mês | Devs, projetos de IA | JSON | Extração com IA, grafo de conhecimento |
Thunderbit: a Melhor Escolha para Extração de Dados com IA e Facilidade de Uso
Extraia dados de qualquer site usando IA Get Started Free
Vamos falar sobre por que o Thunderbit está no topo da minha lista. E não estou dizendo isso só porque faço parte da equipe — de verdade, acredito que o Thunderbit é o mais perto que você vai chegar de ter um estagiário de IA que realmente escuta e não pede pausa para o café.
O Thunderbit não é aquela experiência típica de “aprenda a ferramenta e depois extraia os dados”. Ele funciona mais como dar instruções para um assistente inteligente: você descreve o que quer (“pegue todos os nomes de produtos, preços e links desta página”) e a IA do Thunderbit faz o resto. Sem XPath, sem seletores CSS, sem dor de cabeça com Regex. E, se você quiser extrair subpáginas (como páginas de detalhes de produto ou links de contato de empresas), o Thunderbit pode clicar automaticamente e enriquecer sua tabela — de novo, com um clique.
Mas o que realmente diferencia o Thunderbit é o que acontece depois da extração. Precisa resumir, traduzir, categorizar ou limpar os dados? O pós-processamento com IA integrado resolve. Você não recebe só dados brutos — recebe informações estruturadas e prontas para usar, já preparadas para seu CRM, planilha ou próximo projeto.
Plano gratuito: o teste gratuito do Thunderbit permite extrair até 6 páginas (ou 10 com o bônus de teste), incluindo PDFs, imagens e até modelos para redes sociais. Você pode exportar para Excel ou CSV sem pagar, e testar recursos como extração de e-mail, telefone e imagem. Para tarefas maiores, os planos pagos liberam mais páginas, exportação direta para Google Sheets/Notion/Airtable, scraping agendado e modelos instantâneos para sites populares como Amazon, Google Maps e Instagram.
Se quiser ver o Thunderbit em ação, confira a Extensão Thunderbit para Chrome ou visite nosso canal no YouTube para vídeos rápidos de início.
Experimente o Thunderbit Grátis
Recursos que Fazem o Thunderbit se Destacar
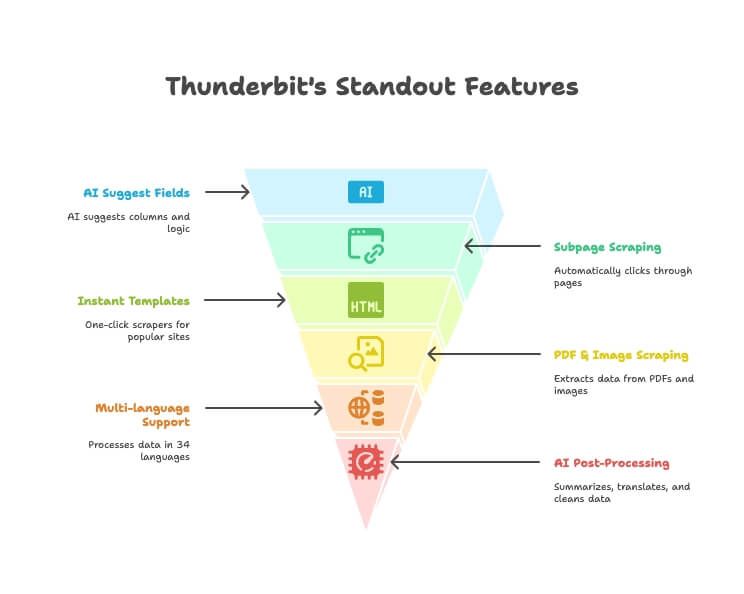
- Sugestão de campos por IA: basta descrever os dados que você quer, e a IA do Thunderbit sugere as colunas e a lógica de extração corretas.
- Extração de subpáginas: clica automaticamente em páginas de detalhe ou links e enriquece sua tabela principal — sem configuração manual.
- Modelos instantâneos: scrapers em um clique para Amazon, Google Maps, Instagram e muito mais.
- Extração de PDF e imagem: extraia tabelas e dados de PDFs e imagens com IA — sem ferramentas extras.
- Suporte multilíngue: extraia e processe dados em 34 idiomas.
- Exportação direta: envie seus dados diretamente para Excel, Google Sheets, Notion ou Airtable (nos planos pagos).
- Pós-processamento com IA: resuma, traduza, categorize e limpe os dados enquanto faz a extração.
- Extração gratuita de e-mail/telefone/imagem: capture contatos ou imagens de qualquer site com um clique.
O Thunderbit faz a ponte entre “apenas extrair dados” e “obter dados realmente utilizáveis”. É o mais próximo que já vi de um verdadeiro assistente de dados com IA para usuários de negócios.
O Resto do Top 12: Ferramentas Gratuitas de Extração de Dados Avaliadas
Vamos destrinchar o restante do grupo, organizado por tipo de usuário.
Para Usuários No-Code e de Negócios
Thunderbit
Já coberto acima. A forma mais fácil de começar para quem não programa, com recursos de IA e modelos instantâneos.
Webscraper.io
- Plataforma: Extensão Chrome
- Ideal para: Sites simples e estáticos; usuários sem código que não se importam em testar e ajustar.
- Recursos principais: scraping baseado em sitemap, suporta paginação, exportação CSV/XLSX.
- Plano gratuito: uso local ilimitado, mas sem execução em nuvem nem agendamento. Operação manual apenas.
- Limitações: não trata logins, PDFs ou conteúdo dinâmico complexo de forma nativa. Suporte só da comunidade.
ParseHub
- Plataforma: App desktop (Windows, Mac, Linux)
- Ideal para: usuários sem código e semi-técnicos dispostos a investir tempo no aprendizado.
- Recursos principais: construtor visual de fluxos, suporta sites dinâmicos, AJAX, logins e paginação.
- Plano gratuito: 5 projetos públicos, 200 páginas por execução, apenas execuções manuais.
- Limitações: os projetos ficam públicos no plano gratuito (atenção com dados sensíveis), sem agendamento e com extração mais lenta.
Octoparse
- Plataforma: App desktop (Windows/Mac), nuvem (paga)
- Ideal para: usuários sem código e analistas que querem potência e flexibilidade.
- Recursos principais: interface visual de clique, suporte a conteúdo dinâmico, modelos para sites populares.
- Plano gratuito: 10 tarefas, até 50 mil linhas/mês, apenas desktop (sem nuvem/agendamento).
- Limitações: sem API, rotação de IP ou agendamento no plano gratuito. A curva de aprendizado pode ser alta em sites complexos.
Browse AI
- Plataforma: Nuvem
- Ideal para: usuários no-code que querem automatizar scraping e monitoramento simples.
- Recursos principais: gravador de robôs com clique, agendamento, integrações (Sheets, Zapier).
- Plano gratuito: 50 créditos/mês, 1 site, até 5 robôs.
- Limitações: volume limitado, e sites mais complexos exigem algum aprendizado inicial.
Para Desenvolvedores e Usuários Técnicos
Scrapy
- Plataforma: Biblioteca Python (open source)
- Ideal para: desenvolvedores que querem controle total e escalabilidade.
- Recursos principais: altamente personalizável, suporta grandes rastreamentos, middleware e pipelines.
- Plano gratuito: ilimitado (open source).
- Limitações: sem interface gráfica, exige programação em Python. Não serve para quem não programa.
Puppeteer
- Plataforma: Biblioteca Node.js (open source)
- Ideal para: desenvolvedores que extraem dados de sites dinâmicos e pesados em JavaScript.
- Recursos principais: automação de navegador headless, controle total sobre navegação e extração.
- Plano gratuito: ilimitado (open source).
- Limitações: requer código em JavaScript, sem interface gráfica.
Selenium
- Plataforma: Multilíngue (Python, Java etc.), open source
- Ideal para: desenvolvedores que automatizam navegadores para scraping ou testes.
- Recursos principais: suporte a vários browsers, automatiza cliques, rolagem e logins.
- Plano gratuito: ilimitado (open source).
- Limitações: mais lento que bibliotecas headless, exige scripts.
Zyte (Scrapy Cloud)
- Plataforma: Nuvem
- Ideal para: desenvolvedores e equipes de operações que implantam spiders do Scrapy em escala.
- Recursos principais: Scrapy hospedado, gerenciamento de proxies, agendamento de trabalhos.
- Plano gratuito: 1 spider simultâneo, 1 hora por trabalho, retenção de dados por 7 dias.
- Limitações: sem agendamento avançado no plano gratuito, exige conhecimento de Scrapy.
Para Equipes e Uso Corporativo
Apify
- Plataforma: Nuvem
- Ideal para: equipes, usuários semi-técnicos e desenvolvedores que querem scrapers prontos ou personalizados.
- Recursos principais: marketplace de actors (bots prontos), agendamento, API, integrações.
- Plano gratuito: US$ 5 em créditos/mês (suficiente para tarefas pequenas), retenção de dados por 7 dias.
- Limitações: alguma curva de aprendizado, uso limitado pelos créditos.
SerpAPI
- Plataforma: API
- Ideal para: desenvolvedores e analistas que precisam de dados de buscadores (Google, Bing, YouTube).
- Recursos principais: APIs de busca, anti-bloqueio, saída JSON estruturada.
- Plano gratuito: 100 buscas/mês.
- Limitações: não serve para sites arbitrários, uso apenas via API.
Diffbot
- Plataforma: API
- Ideal para: desenvolvedores, equipes de IA/ML e empresas que precisam de dados estruturados da web em grande escala.
- Recursos principais: extração com IA, grafo de conhecimento, APIs para artigos/produtos.
- Plano gratuito: 10 mil créditos/mês.
- Limitações: apenas API, exige conhecimento técnico, throughput limitado por taxa.
Limitações do Plano Gratuito: o que “Grátis” Realmente Significa para Cada Raspador de Dados
Vamos ser francos — “gratuito” pode significar desde “ilimitado para hobby” até “só o suficiente para te fisgar”. Veja o que você realmente recebe:
| Ferramenta | Páginas/Linhas por Mês | Formatos de Exportação | Agendamento | Acesso à API | Limites Gratuitos Relevantes |
|---|---|---|---|---|---|
| Thunderbit | 6 páginas | Excel, CSV | Não | Não | Sugestão de campos por IA limitada, sem exportação direta para Sheets/Notion no gratuito |
| Browse AI | 50 créditos | CSV, Sheets | Sim | Sim | 1 site, 5 robôs, retenção de 15 dias |
| Octoparse | 50 mil linhas | CSV, Excel, JSON | Não | Não | Apenas desktop, sem nuvem/agendamento |
| ParseHub | 200 páginas/execução | CSV, Excel, JSON | Não | Não | 5 projetos públicos, velocidade baixa |
| Webscraper.io | Local ilimitado | CSV, XLSX | Não | Não | Execuções manuais, sem nuvem |
| Apify | US$ 5 em créditos (~pequeno) | CSV, JSON, Sheets | Sim | Sim | Retenção de 7 dias, limite por créditos |
| Scrapy | Ilimitado | CSV, JSON, DB | Não | N/A | Exige programação |
| Puppeteer | Ilimitado | Personalizado (código) | Não | N/A | Exige programação |
| Selenium | Ilimitado | Personalizado (código) | Não | N/A | Exige programação |
| Zyte | 1 spider, 1h/trabalho | CSV, JSON | Limitado | Sim | Retenção de 7 dias, 1 trabalho simultâneo |
| SerpAPI | 100 buscas | JSON | Não | Sim | Apenas APIs de busca |
| Diffbot | 10 mil créditos | JSON | Não | Sim | Apenas API, com limite de taxa |
Resumindo: para projetos reais, Thunderbit, Browse AI e Apify oferecem os testes gratuitos mais úteis para usuários de negócios. Para scraping contínuo ou em grande escala, você vai bater nos limites rapidamente e precisar fazer upgrade ou migrar para soluções open source/baseadas em código.
Qual Ferramenta de Extração de Dados é Melhor para Você? (Guia por Perfil)
Aqui vai um resumo rápido para ajudar a escolher a ferramenta certa com base na sua função e no seu nível de conforto com tecnologia:
| Tipo de Usuário | Melhores Ferramentas (Grátis) | Por quê |
|---|---|---|
| Não programador (Vendas/Marketing) | Thunderbit, Browse AI, Webscraper.io | Aprendizado rápido, clique e selecione, ajuda com IA |
| Semi-técnico (Operações/Analista) | Octoparse, ParseHub, Apify, Zyte | Mais potência, lida com sites complexos, permite algum script |
| Desenvolvedor/Engenheiro | Scrapy, Puppeteer, Selenium, Diffbot, SerpAPI | Controle total, ilimitado, foco em API |
| Equipe/Empresa | Apify, Zyte | Colaboração, agendamento, integrações |
Cenários Reais de Web Scraping: Comparação de Adaptabilidade das Ferramentas
Vamos ver como essas ferramentas se saem em cinco cenários comuns de scraping:
| Cenário | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Listagens paginadas | Fácil | Fácil | Médio | Médio | Médio | Fácil | Fácil | Fácil | Fácil | Fácil | N/A | Médio |
| Listagens do Google Maps | Fácil* | Difícil | Médio | Médio | Difícil | Fácil | Difícil | Difícil | Difícil | Difícil | Fácil | N/A |
| Páginas com login | Fácil | Médio | Médio | Médio | Manual | Médio | Fácil | Fácil | Fácil | Fácil | N/A | N/A |
| Extração de dados de PDF | Fácil | Não | Não | Não | Não | Médio | Difícil | Difícil | Difícil | Difícil | Não | Limitado |
| Conteúdo de redes sociais | Fácil* | Parcial | Difícil | Difícil | Difícil | Fácil | Difícil | Difícil | Difícil | Difícil | YouTube | Limitado |
- Thunderbit e Apify oferecem modelos/actors prontos para Google Maps e scraping de redes sociais, tornando esses cenários muito mais fáceis para usuários não técnicos.
Plugin vs. Desktop vs. Nuvem: Qual é a Melhor Experiência de Ferramenta de Web Scraper?
- Extensões Chrome (Thunderbit, Webscraper.io):
- Prós: começam rápido, rodam no navegador, configuração mínima.
- Contras: operação manual, podem ser afetadas por mudanças no site, automação limitada.
- Vantagem do Thunderbit: a IA lida com mudanças de estrutura, navegação entre subpáginas e até extração de PDF/imagem — muito mais robusto que extensões tradicionais.
- Apps Desktop (Octoparse, ParseHub):
- Prós: poderosos, fluxos visuais, lidam com sites dinâmicos e logins.
- Contras: curva de aprendizado mais alta, sem automação em nuvem nos planos gratuitos, dependem do sistema operacional.
- Plataformas em Nuvem (Browse AI, Apify, Zyte):
- Prós: agendamento, colaboração em equipe, escalabilidade, integrações.
- Contras: planos gratuitos geralmente limitados por créditos, exigem alguma configuração, podem pedir conhecimento de API.
- Bibliotecas Open Source (Scrapy, Puppeteer, Selenium):
- Prós: ilimitadas, personalizáveis, ideais para devs.
- Contras: exigem código, não são para usuários de negócios.
Tendências de Web Scraping em 2026: o que Diferencia as Ferramentas Modernas
O web scraping em 2026 gira em torno de IA, automação e integração. Veja o que há de novo:
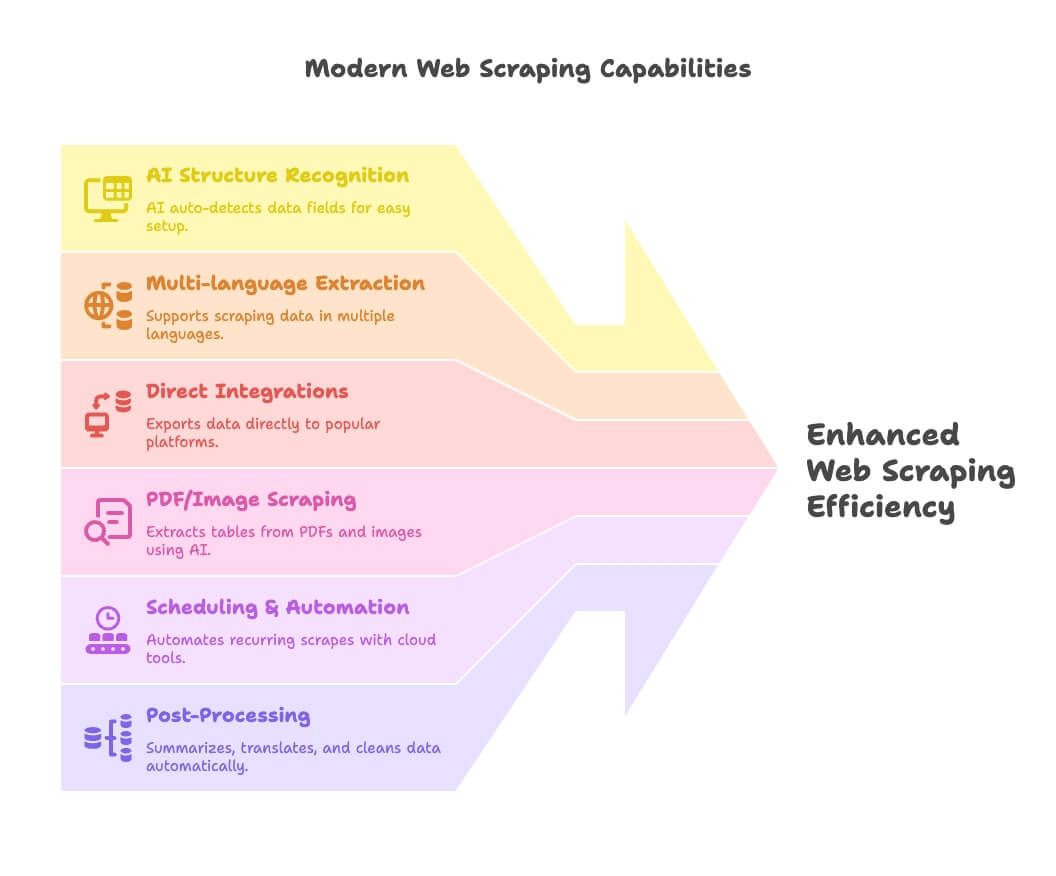
- Reconhecimento de estrutura por IA: ferramentas como o Thunderbit usam IA para detectar campos automaticamente, deixando a configuração muito mais simples para quem não programa.
- Extração multilíngue: o Thunderbit e outras ferramentas suportam extração e processamento em dezenas de idiomas.
- Integrações diretas: exporte dados extraídos direto para Google Sheets, Notion ou Airtable — sem dor de cabeça com CSV.
- Extração de PDF/imagem: o Thunderbit se destaca aqui, permitindo extrair tabelas de PDFs e imagens com IA.
- Agendamento e automação: ferramentas em nuvem (Apify, Browse AI) permitem configurar e esquecer coletas recorrentes.
- Pós-processamento: resuma, traduza, categorize e limpe os dados enquanto faz a extração — adeus planilhas bagunçadas.
Thunderbit, Apify e SerpAPI estão na frente dessas tendências, mas o Thunderbit se destaca por tornar o scraping com IA acessível para todo mundo, não só para desenvolvedores.
Além da Extração: Processamento de Dados e Recursos de Valor Agregado
Não se trata apenas de coletar dados — mas de transformá-los em algo útil. Veja como as principais ferramentas se comparam no pós-processamento:
| Ferramenta | Limpeza | Tradução | Categorização | Resumo | Observações |
|---|---|---|---|---|---|
| Thunderbit | Sim | Sim | Sim | Sim | Pós-processamento com IA integrado |
| Apify | Parcial | Parcial | Parcial | Parcial | Depende do actor usado |
| Browse AI | Não | Não | Não | Não | Apenas dados brutos |
| Octoparse | Parcial | Não | Parcial | Não | Algum processamento de campos |
| ParseHub | Parcial | Não | Parcial | Não | Algum processamento de campos |
| Webscraper.io | Não | Não | Não | Não | Apenas dados brutos |
| Scrapy | Sim* | Sim* | Sim* | Sim* | Se implementado pelo desenvolvedor |
| Puppeteer | Sim* | Sim* | Sim* | Sim* | Se implementado pelo desenvolvedor |
| Selenium | Sim* | Sim* | Sim* | Sim* | Se implementado pelo desenvolvedor |
| Zyte | Parcial | Não | Parcial | Não | Alguns recursos de autoextração |
| SerpAPI | Não | Não | Não | Não | Apenas dados estruturados de busca |
| Diffbot | Sim | Sim | Sim | Sim | Com IA, mas apenas via API |
- O desenvolvedor precisa implementar a lógica de processamento.
O Thunderbit é a única ferramenta que permite a usuários não técnicos ir de dados brutos da web a insights estruturados e acionáveis — tudo em um único fluxo.
Comunidade, Suporte e Recursos de Aprendizado: Como Começar Mais Rápido
Documentação e onboarding importam — muito. Veja como as ferramentas se comparam:
| Ferramenta | Documentação e Tutoriais | Comunidade | Modelos | Curva de Aprendizado |
|---|---|---|---|---|
| Thunderbit | Excelente | Crescente | Sim | Muito baixa |
| Browse AI | Boa | Boa | Sim | Baixa |
| Octoparse | Excelente | Grande | Sim | Média |
| ParseHub | Excelente | Grande | Sim | Média |
| Webscraper.io | Boa | Fórum | Sim | Média |
| Apify | Excelente | Grande | Sim | Média-alta |
| Scrapy | Excelente | Enorme | N/A | Alta |
| Puppeteer | Boa | Grande | N/A | Alta |
| Selenium | Boa | Enorme | N/A | Alta |
| Zyte | Boa | Grande | Sim | Média-alta |
| SerpAPI | Boa | Média | N/A | Alta |
| Diffbot | Boa | Média | N/A | Alta |
Thunderbit e Browse AI são os mais fáceis para iniciantes. Octoparse e ParseHub têm ótimos recursos, mas exigem mais paciência. Apify e as ferramentas para desenvolvedores têm curvas de aprendizado mais íngremes, mas são bem documentadas.
Conclusão: Escolhendo o Raspador de Dados Gratuito Ideal para 2026
Veja as Melhores Ferramentas de Web Scraping em 2026 Get Started Free
Aqui vai a verdade: nem toda ferramenta gratuita de extração de dados é igualmente útil, e sua escolha deve depender da sua função, do seu conforto com tecnologia e da sua necessidade real de scraping.
- Se você é um usuário de negócios ou não programador e quer extrair dados rápido — especialmente de sites complicados, PDFs ou imagens — Thunderbit é o melhor lugar para começar. Sua abordagem guiada por IA, prompts em linguagem natural e recursos de pós-processamento fazem dele o mais próximo de um verdadeiro assistente de dados com IA. Experimente a Extensão Thunderbit para Chrome grátis e veja como é rápido sair de “preciso desses dados” para “aqui está minha planilha”.
- Se você é desenvolvedor ou precisa de scraping ilimitado e personalizável, ferramentas open source como Scrapy, Puppeteer e Selenium são a melhor aposta.
- Para equipes e usuários semi-técnicos, Apify e Zyte oferecem soluções escaláveis e colaborativas, com planos gratuitos generosos para tarefas pequenas.
Seja qual for seu fluxo de trabalho, comece pela ferramenta que combina com suas habilidades e necessidades. E lembre-se: em 2026, você não precisa ser programador para aproveitar o poder dos dados da web — só precisa do assistente certo (e talvez de senso de humor quando os robôs passarem na sua frente).
Quer ir mais fundo? Confira mais guias e comparativos no Blog da Thunderbit, incluindo:
- O que é Data Scraping e Como Fazer Isso em 2026
- Como Extrair Dados de Sites para o Excel usando IA
- As Melhores Ferramentas e Softwares de Web Scraping em 2026
Comece a Extrair Dados com Thunderbit
Experimente o AI Web Scraper Get Started Free




