Há três semanas, sentei-me para pesquisar vendedores de "retratos personalizados de pets" no Etsy. Depois de 47 separadores abertos, duas horas de copiar e colar e uma folha de cálculo bem confusa, ainda não tinha uma visão clara sobre preços, avaliações ou quem estava a correr anúncios em vez de aparecer organicamente no ranking. Foi essa experiência que deu início a todo este projeto.
Hoje, o Etsy tem , 5,6 milhões de vendedores ativos e 86,5 milhões de compradores ativos. É um marketplace enorme e ruidoso — e, se é vendedor, profissional de marketing ou investigador de ecommerce e quer perceber o que funciona no seu nicho, precisa de dados estruturados, não de um mar de separadores abertos. O problema? As defesas anti-bot do Etsy ficaram muito mais sofisticadas em 2026. Entre estruturas dinâmicas da página, TLS fingerprinting, CAPTCHAs e análise comportamental, já lá vai o tempo em que bastava escrever um script Python rápido e dar o assunto por fechado.
Passei as últimas semanas a testar seis scrapers de Etsy lado a lado — desde ferramentas de IA sem código até APIs para programadores — e vou mostrar exatamente o que funcionou, o que não funcionou e qual a ferramenta certa para cada tipo de utilizador. Também vou explicar que dados realmente consegue extrair (e quais não consegue), a discussão entre API do Etsy e scraping, casos de uso reais e como validar os resultados para não tomar decisões com dados errados.
Por que fazer scraping do Etsy é mais difícil do que parece
Se já tentou fazer scraping no Etsy e deu de caras com uma parede, saiba que não está sozinho. O Etsy não é um catálogo estático — é um marketplace dinâmico e personalizado. Os resultados de pesquisa, anúncios, selos, informações de envio e até os nomes das classes CSS da página podem mudar entre sessões, dispositivos e países.
Aqui está o resumo do que torna o Etsy complicado:
- Estrutura de página dinâmica: o front-end do Etsy muda com frequência. Seletores que funcionavam ontem podem devolver vazio hoje. É como se o Etsy trocasse as fechaduras das portas de poucas em poucas horas — a página continua a parecer familiar para o comprador, mas os pontos de captura de dados de que um scraper depende podem mudar sem aviso.
- Sistemas de gestão de bots: fornecedores de scrapers como o observam publicamente que o Etsy usa "proteção agressiva contra bots" e que as sessões podem ser bloqueadas. Algumas páginas de Actor referem padrões de URL para evitar DataDome e imitação de fingerprint TLS do Chrome. De forma mais ampla, o mostrou que o tráfego automatizado representou 53% de todo o tráfego da web em 2025, e a que os bots representaram 42,1% de todo o tráfego da web — os sites de ecommerce são um alvo prioritário.
- CAPTCHAs e limitação de taxa: scraping em grande volume pode acionar CAPTCHAs ou bloqueios diretos. O até observa que, se aparecer um CAPTCHA, os utilizadores podem pausar a tarefa e resolvê-lo manualmente.
- Resultados patrocinados e personalização: os resultados de pesquisa do Etsy misturam listagens orgânicas e pagas, e o . Se não acompanhar quais os resultados que são anúncios, a sua análise competitiva pode ficar totalmente distorcida.
Nada disto significa que fazer scraping no Etsy seja impossível. Significa que a ferramenta escolhida importa muito mais do que antes.

Que dados realmente consegue extrair do Etsy?
Esta é a secção que eu queria que todos os artigos concorrentes incluíssem — mas quase nenhum inclui. Antes de escolher uma ferramenta, precisa de saber o que, de facto, é possível.
Dados que consegue obter dos resultados de pesquisa do Etsy
As páginas de resultados de pesquisa oferecem abrangência. Aqui está o que normalmente dá para extrair da grelha:
- Título do produto
- Preço (atual, promocional, original, quando visível)
- Moeda
- URL da imagem principal
- URL da listagem / ID da listagem
- Nome da loja (quando visível — os anúncios às vezes mostram "Ad by Etsy Seller")
- Avaliação
- Número de avaliações
- Selo de envio grátis
- Selos de bestseller / Etsy's Pick / Star Seller
- Etiqueta de patrocinado/anúncio
- Número da página e posição
- Metadados de consulta, filtro, ordenação e país/sessão
Por exemplo, o expõe campos como listingId, name, url, imageUrl, shop, shopId, price, originalPrice, currency, onSale, freeShipping, rating, availability, position, query, page e scrapedAt — uma validação útil do que é, na prática, possível extrair com fiabilidade.
Dados que exigem visitar cada página de produto (scraping de subpáginas)
Os cartões de pesquisa são propositadamente compactos. Se estiver a fazer uma pesquisa séria de produtos, precisa dos campos que ficam a um clique de distância:
- Descrição completa
- Galeria completa de imagens e URLs de vídeo
- Variações e opções de personalização
- Detalhes do item (materiais, atributos, dimensões)
- Tempo de processamento
- Informações de envio e estimativas de entrega
- Detalhes e políticas do perfil do vendedor/loja
- Excertos de avaliações ou avaliações completas
- Itens relacionados
A própria confirma que os vendedores inserem título, categoria, atributos, preço, variações, personalização, descrição, perfil de envio, detalhes de processamento/envio e dimensões/peso do item — por isso esses campos existem, mas tem de visitar a página para os obter.
É aqui que o scraping de subpáginas se torna realmente útil. Com o , por exemplo, pode fazer scraping de uma página de resultados do Etsy para obter títulos, preços e avaliações e, depois, clicar em "Scrape Subpages" para que a IA visite cada anúncio individual e enriqueça a tabela com tags, materiais, detalhes de envio e informações do vendedor — sem qualquer configuração adicional. O Field AI Prompt do Thunderbit também permite adicionar instruções personalizadas por coluna (por exemplo, "categorize este produto em Joias / Decoração para Casa / Roupas").
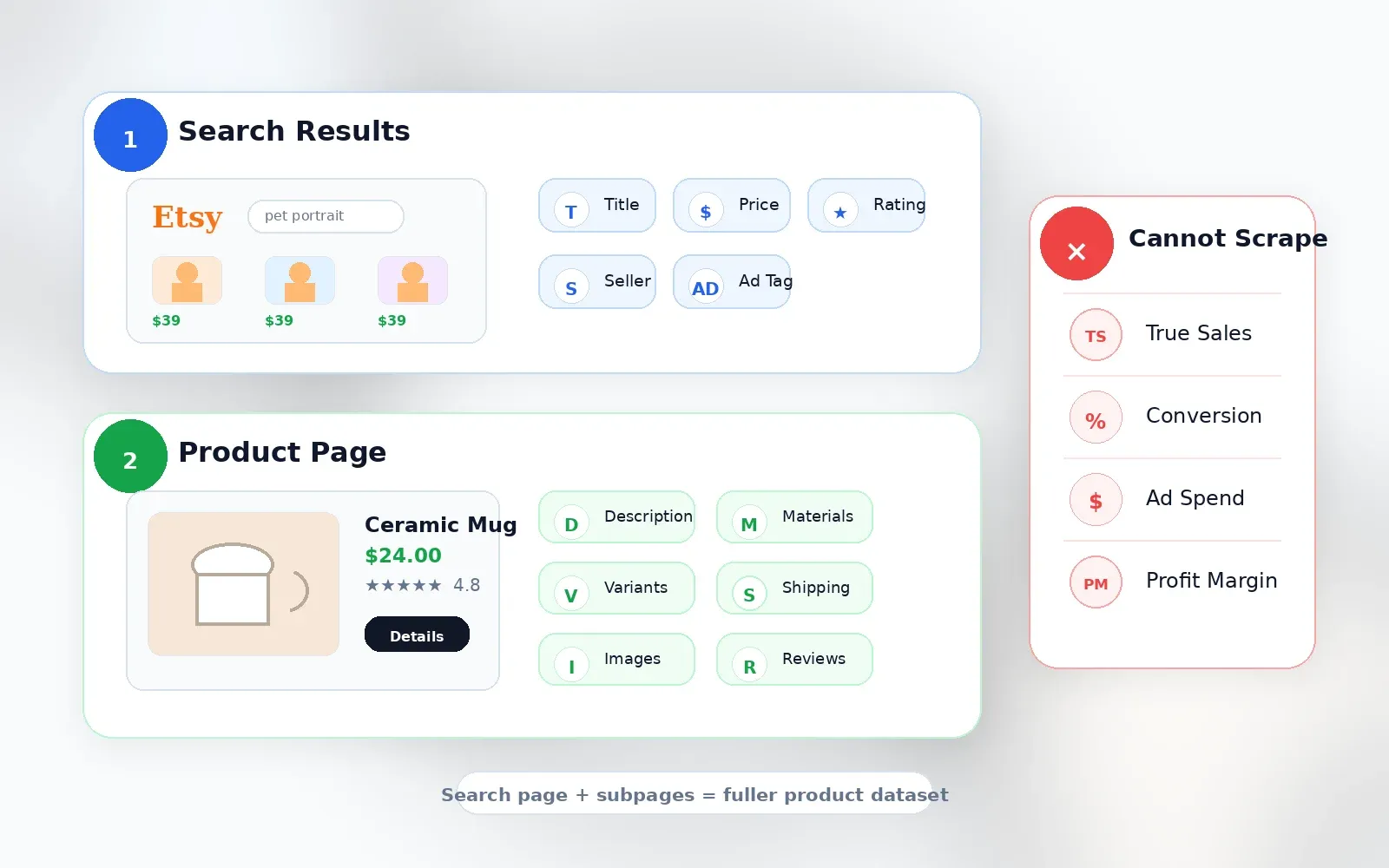
O que o scraping não consegue dizer
Quero ser claro nisto, porque é aqui que muitas ferramentas perdem credibilidade:
| Ponto de dados | Disponível via scraping? | Observações |
|---|---|---|
| Vendas reais por anúncio | Não | O Etsy não mostra publicamente as vendas exatas de cada anúncio. As vendas ao nível da loja podem ser visíveis, mas as vendas por anúncio não são. |
| Taxas de conversão | Não | Apenas nas análises do vendedor, não publicamente. |
| Volume real de pesquisa por palavra-chave | Não | O Etsy Marketplace Insights mostra dados de 30 dias dentro das ferramentas do vendedor, mas isso não é um campo público para scraping. |
| Gastos com anúncios / dados de lance | Não | Não são expostos como dados públicos da listagem. |
| Margem de lucro | Não | Preço e envio são visíveis; custo de produção, taxas e devoluções não são. |
Qualquer ferramenta que afirme mostrar vendas exatas de anúncios concorrentes no Etsy está a estimar, não a fazer scraping de um facto público. Ferramentas como , e descrevem abertamente o uso de algoritmos de estimativa, e não de acesso direto aos dados.
API do Etsy vs. scraping: de que é que realmente precisa?
Esta é uma pergunta que vejo constantemente em fóruns: "Como a API do Etsy não fornece dados de palavras-chave, acho que eles estão a fazer scraping." A confusão é real, por isso aqui vai uma explicação clara.
| Dimensão | API oficial do Etsy | Web scraping |
|---|---|---|
| Melhor caso de uso | Gerir a sua própria loja, anúncios, stock, encomendas e pagamentos | Pesquisa competitiva, monitorização de pesquisa, inteligência de preços, enriquecimento de subpáginas |
| Anúncios | Endpoints ativos de pesquisa e detalhes de listagens | Qualquer página pública de pesquisa/listagem/loja/avaliação |
| Vendas/encomendas da sua própria loja | Sim, com autorização/escopos | Não é necessário; use API/Shop Manager |
| Vendas exatas de concorrentes | Não | Não (apenas estimativas) |
| Volume de pesquisa por palavra-chave | Não exposto como endpoint público da Open API | Não diretamente; o Marketplace Insights fica na interface do vendedor |
| Limites de taxa | QPS/QPD específicos por app; tratamento de 429 | Depende da ferramenta/plataforma |
| Postura dos termos de utilização | Caminho oficial quando usado dentro dos termos | Os termos do Etsy restringem scraping sem autorização |
| Saída | Respostas JSON da API | CSV/Sheets/JSON/HTML, dependendo da ferramenta |
Em resumo: se precisa de gerir a sua própria loja, use a API. Se precisa de perceber a concorrência, monitorizar preços ou pesquisar um nicho, o scraping é o caminho mais prático. Ferramentas como eRank e Alura provavelmente combinam acesso à API com scraping e estimativas — agora já sabe porquê.
Sem código vs. com código: como escolher o melhor scraper de Etsy
A maioria das pessoas que procura os "melhores scrapers de Etsy" não são programadores a montar infraestrutura. São vendedores, profissionais de marketing, assistentes virtuais ou investigadores de ecommerce que querem uma tabela útil. Mesmo assim, muitos artigos concorrentes focam-se em ferramentas de API ou bibliotecas Python. Isso é um desencontro.
Aqui está o meu framework de decisão:
| Se é... | Escolha... | Porquê |
|---|---|---|
| Vendedor ou profissional de marketing sem perfil técnico | Thunderbit | Sugestões de campos por IA, extensão do Chrome, scraping de subpáginas, exportação direta, scraping agendado |
| Sem perfil técnico, mas gosta de fluxos visuais | Octoparse | Construtor visual para desktop, modelos, deteção automática, modo cloud |
| Freelancer ou pequena agência a criar trabalhos recorrentes no Etsy | Apify | Actors na cloud, agendador, API, opções de pagamento por resultado |
| Programador a criar um pipeline interno | ScrapingBee ou ZenRows | Transporte por API, renderização JS, tratamento de proxy/CAPTCHA; controla parser e armazenamento |
| Equipa de dados empresarial | Bright Data | API/dataset de scraper gerido, opções de entrega, postura de uptime/conformidade |
"Sem código", para este público, significa: sem configuração de proxy, sem seletores CSS, sem comandos de terminal, sem gestão de navegador headless, sem lógica personalizada de retry e sem configuração de base de dados. Exporta diretamente para uma folha de cálculo ou app de trabalho, e o enriquecimento de subpáginas não exige criar loops de clique.
Como avaliei estes 6 scrapers de Etsy
Executei cada ferramenta com o mesmo conjunto de tarefas: uma pesquisa no Etsy ("personalized pet portrait"), uma pesquisa concorrida de produto ("gold huggie earrings"), uma URL de loja com muitas listagens, dez páginas de detalhes de listagem para enriquecimento de subpáginas, uma tarefa agendada semanal de monitorização de preços e uma exportação para Google Sheets ou CSV.
Aqui está o que avaliei:
| Critério | Porque é que isto importa |
|---|---|
| Facilidade de uso (sem código vs. com código) | Os vendedores do Etsy não deveriam ter de se tornar engenheiros de scraping |
| Tratamento de anti-bot/CAPTCHA | Uma ferramenta que funciona para 10 linhas, mas falha na página 2, não serve |
| Campos de dados extraíveis | Os campos dos resultados de pesquisa não chegam para uma pesquisa séria de produto |
| Opções de exportação (CSV, JSON, Sheets, Airtable) | O fluxo real normalmente termina no Sheets, Airtable, Notion, CSV, JSON ou ferramentas de BI |
| Transparência de preços (plano grátis + custo por 1 mil registos) | O custo por linha utilizável importa mais do que o preço mensal anunciado |
| Enriquecimento de subpáginas | Tags, descrições, envio, materiais, variações e avaliações ficam um clique mais fundo |
1. Thunderbit
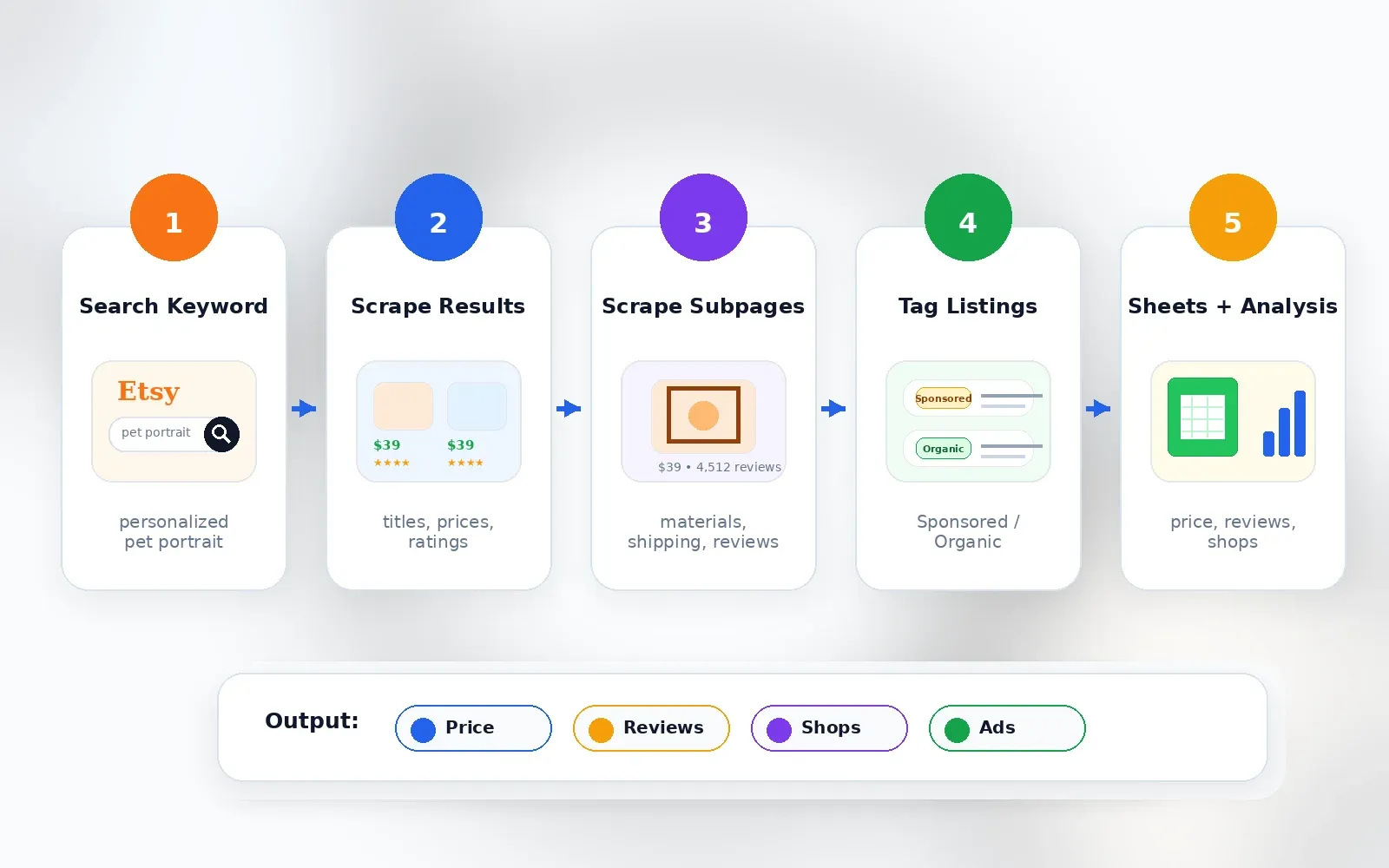
O é a ferramenta que criámos na Thunderbit especificamente para utilizadores sem perfil técnico que precisam de dados estruturados da web com rapidez. É uma com IA — abre uma página do Etsy, clica em "AI Suggest Fields" e a IA lê a estrutura da página e sugere colunas como título, preço, avaliações, vendedor, URL, imagem, selo e envio. Depois, clica em "Scrape" e obtém uma tabela. É só isso.
O que torna o Thunderbit especialmente útil para pesquisas no Etsy é o recurso de scraping de subpáginas. Depois de fazer scraping de uma página de resultados, pode clicar em "Scrape Subpages" e a IA do Thunderbit visita cada anúncio individual para enriquecer a sua tabela com descrições completas, detalhes de envio, materiais, tags e informações do vendedor — sem precisar de configuração adicional. Usei este fluxo para passar de uma pesquisa a uma folha de cálculo completa de análise competitiva em menos de dez minutos.
Principais funcionalidades
- AI Suggest Fields: a IA lê a página do Etsy e recomenda colunas. Sem seletores, sem adivinhação.
- Scraping em 2 cliques: ótimo para pesquisas pontuais de produto.
- Scraping de subpáginas: enriqueça os resultados de pesquisa com detalhes completos de cada anúncio num só clique.
- Scraping agendado: configure a monitorização semanal de preços da concorrência descrevendo o intervalo em linguagem natural.
- Field AI Prompt: adicione instruções personalizadas por coluna (por exemplo, "categorize em Joias / Decoração para Casa / Roupas" ou "assinale se este anúncio parece personalizado").
- Exportações: Excel, Google Sheets, Airtable, Notion, CSV, JSON — .
- Modo cloud e modo no navegador: modo cloud para trabalhos públicos mais rápidos; modo no navegador para páginas em que a sua sessão/renderização atual importa (mais preciso para campos dinâmicos, como favoritos).
- API aberta: o aceita URL + JSON Schema e suporta lotes de até 100 URLs por pedido.
Como o Thunderbit faz scraping do Etsy em 2 cliques
- Navegue até uma página de resultados de pesquisa do Etsy (por exemplo, pesquise "personalized pet portrait").
- Clique em AI Suggest Fields — a IA sugere colunas como título, preço, avaliações, vendedor, URL, imagem e selos.
- Clique em Scrape — os dados aparecem numa tabela.
- Opcionalmente, clique em Scrape Subpages na coluna da URL da listagem para enriquecer as linhas com descrição completa, detalhes de envio, materiais ou avaliações.
- Exporte para Google Sheets, Airtable, Notion, Excel, CSV ou JSON.
Também pode consultar o nosso para tutoriais em vídeo.
Preço
O Thunderbit usa um modelo baseado em créditos. Existe um plano gratuito/teste, e o plano Starter custa cerca de US$ 15/mês por 500 créditos (ou US$ 108/ano por 5.000 créditos anuais). O scraping de subpáginas pode consumir mais créditos, já que cada linha/página enriquecida conta separadamente. Consulte para informações atualizadas.
Prós e contras
| Prós | Contras |
|---|---|
| Sem código, sem configuração de seletores | Baseado em créditos; trabalhos muito grandes exigem plano pago |
| A deteção de campos por IA reduz manutenção quando a página muda | A extensão do Chrome exige instalação no navegador |
| O enriquecimento de subpáginas já vem integrado | Não é posicionado como fornecedor de datasets em escala empresarial |
| Scraping agendado e autoexportação apoiam fluxos de monitorização | A precisão ainda precisa de validação pontual (isto vale para todas as ferramentas) |
| Funciona além do Etsy — útil para pesquisa geral de ecommerce | Alguns campos continuam indisponíveis porque o Etsy não os expõe |
Ideal para: vendedores do Etsy a fazer pesquisa de produto, profissionais de marketing a montar relatórios da concorrência, equipas de operações a monitorizar preços.
2. Apify Etsy Scraper
O é uma plataforma de automação na cloud com um marketplace de "Actors" — scrapers prontos a correr sem ter de gerir a sua própria infraestrutura. Para Etsy, há vários Actors disponíveis, incluindo o e o .
O Actor da Automation Lab suporta pesquisa por palavra-chave, filtro por categoria, paginação (até 5.000 produtos por execução) e saída estruturada com campos como ID da listagem, título, URL, URL da imagem, loja, preço, preço original, moeda, estado de promoção, envio grátis, avaliação, disponibilidade, posição, consulta, página e timestamp do scraping. É um conjunto sólido para dados ao nível dos resultados de pesquisa.
Principais funcionalidades
- Hospedado na cloud (sem necessidade de recursos locais)
- Scraping por palavra-chave, categoria e URL de loja
- Tratamento de paginação
- Exportação em JSON, CSV e Excel
- Integração com proxy (proxies residenciais disponíveis por custo extra)
- Agendador para tarefas recorrentes
- Acesso via API para integração em pipelines
Preço
O cobra por execução mais preço por produto: cerca de US$ 0,80–US$ 3,45 por 1 mil produtos, dependendo do seu plano Apify. Os planos da plataforma começam em cerca de US$ 9/mês (Starter), mais o uso dos Actors. O plano gratuito inclui US$ 5/mês de utilização da plataforma.
Prós e contras
| Prós | Contras |
|---|---|
| Actors de Etsy prontos a usar | A qualidade do Actor varia consoante o mantenedor |
| Execução na cloud, agendador, API e webhooks | Actors da comunidade podem ficar desatualizados quando o Etsy muda o layout |
| Preço transparente por resultado em alguns Actors | Os custos de proxy aumentam em escala |
| Exportações JSON/CSV/Excel via dataset do Apify | O enriquecimento de subpáginas pode exigir configuração |
| Bom para pipelines recorrentes de dados | Low-code, não é tão simples como uma extensão de navegador para vendedores |
Ideal para: freelancers, pequenas agências e utilizadores semitécnicos que querem um pipeline de dados do Etsy pronto a usar.
3. Bright Data
A é a opção empresarial. Se é uma grande empresa de ecommerce ou uma equipa de dados a fazer scraping de milhares de anúncios do Etsy por dia, esta ferramenta foi feita para si. A Bright Data oferece uma e um com mais de 18 milhões de registos e 59 campos.
A infraestrutura deles é enorme — mais de 100 milhões de IPs residenciais, tratamento anti-bot completo (proxies residenciais, resolução de CAPTCHA, fingerprinting de browser), saída JSON estruturada e uma abordagem orientada para a conformidade. Também têm uma opção no-code de Data Collector para utilizadores que não querem lidar com código.
Principais funcionalidades
- Coletor de dados Etsy pronto a usar (opção de painel sem código)
- Tratamento anti-bot completo
- Saída JSON estruturada com mais de 59 campos
- Entrega gerida, webhook e integrações com armazenamento na cloud
- SLAs empresariais, ferramentas de conformidade, garantias de uptime
- Dataset de Etsy pronto para análise em massa
Preço
A API Etsy Scraper da Bright Data começa em cerca de no modelo pay-as-you-go. O dataset de Etsy tem um mínimo de US$ 50. Não há plano gratuito, mas a página da Scraper API anuncia 1 mil pedidos de teste. O plano Scale custa US$ 499/mês. É um preço premium — não é para quem está a raspar 50 anúncios numa tarde de sábado.
Prós e contras
| Prós | Contras |
|---|---|
| Plataforma mais fiável e estável | Demasiado para pesquisas pontuais de vendedores |
| Bypass anti-bot líder de mercado | Preço premium (barreira para pequenas empresas) |
| Opção de Data Collector sem código | Número enorme de funcionalidades para tarefas simples |
| Ferramentas rígidas de conformidade | Sem plano gratuito |
| Escala massiva | A personalização de subpáginas pode exigir trabalho com API/configuração |
Ideal para: grandes empresas de ecommerce, equipas de dados e corporações que precisam de uptime garantido, conformidade legal e escala.
4. Octoparse
A é uma aplicação de desktop com uma interface visual point-and-click para construir fluxos de scraping. Se gosta de ver exatamente o que o seu scraper está a fazer — a clicar, deslocar-se, paginar — esta é a ferramenta certa.
A Octoparse tem um que consegue extrair nome do produto, vendedor, avaliação, número de avaliações, preço, URL e URL da imagem por palavra-chave. O mostra como raspar informações de produtos do Etsy, incluindo deteção automática dos dados da página e criação de fluxos com paginação e scroll.
Principais funcionalidades
- Construtor visual de fluxos de trabalho (arrastar e largar)
- Rotação de IP integrada
- Tratamento de CAPTCHA através de integrações de terceiros (o template do Etsy menciona opção de resolução manual)
- Suporte a scroll infinito e paginação
- Opção de execução na cloud
- Exportações: CSV, Excel, JSON, ligações a base de dados, Google Sheets (em planos pagos)
Preço
Plano gratuito com extração local e limites de linhas. O plano Standard custa cerca de no plano anual. Os níveis pagos acrescentam funcionalidades cloud, mais opções de exportação e limites de linhas mais altos.
Prós e contras
| Prós | Contras |
|---|---|
| Interface visual realmente sem código | A aplicação de desktop consome muitos recursos |
| Existe template e tutorial para Etsy | Scraping complexo de subpáginas exige configuração manual do fluxo |
| Lida com paginação/scroll infinito | Em alguns casos, o CAPTCHA pode exigir resolução manual |
| Exporta para CSV, Excel, JSON e bases de dados | Mais lenta do que soluções baseadas em API em grande escala |
| Boa curva de aprendizagem para scraping sem código | Mais fricção de configuração do que ferramentas com sugestão de campos por IA |
Ideal para: investigadores de mercado e analistas de negócio sem perfil técnico que preferem uma interface visual e querem personalizar fluxos de extração sem código.
5. ScrapingBee
A é uma API orientada para programadores. Envia uma URL e ela devolve o HTML renderizado (ou JSON extraído, se configurar regras de extração). Não existe um parser de Etsy pronto a entregar uma folha de cálculo — escreve a sua própria lógica de extração em Python, JavaScript ou qualquer linguagem que preferir.
A diz que os campos extraíveis podem incluir nome do produto, categorias, preço, estado de stock, informações de envio e tamanho usando regras de extração em JSON. Também observa que o scraping do Etsy deve considerar proxies premium, tratamento de taxa de pedidos e riscos relacionados com os termos de utilização.
Principais funcionalidades
- Renderização de JavaScript
- Rotação automática de proxy
- Tratamento de CAPTCHA
- API REST simples
- Suporte a Python/Node.js/qualquer linguagem
- Devolve HTML bruto ou JSON; o utilizador faz parsing e exporta
Preço
1.000 créditos de API grátis para começar. O por 250 mil créditos e 10 pedidos em simultâneo. O Startup custa US$ 99/mês por 1 milhão de créditos. O Business custa US$ 249/mês por 3 milhões de créditos.
Prós e contras
| Prós | Contras |
|---|---|
| Integração por API simples | Exige código (Python/JS) |
| Renderização de JavaScript e opções de proxy | Devolve HTML bruto (sem parsing automático de todos os campos) |
| Funciona com qualquer linguagem | Sem interface visual |
| Bom para pipelines personalizados de dados | O enriquecimento de subpáginas exige script personalizado |
| Mais flexível do que ferramentas visuais | Exportação/armazenamento/agendamento ficam por sua conta |
Ideal para: programadores Python/JS a criar ferramentas internas proprietárias e que precisam de uma "camada de transporte" fiável para obter HTML do Etsy sem bloqueios.
6. ZenRows
A é outra API para programadores, semelhante à ScrapingBee, mas com ainda mais ênfase em bypass anti-bot em escala. Trata automaticamente CAPTCHAs, fingerprinting e proxies residenciais.
A lista campos como desconto, URL, nome do vendedor, descrição, avaliação, nome do produto, preço, disponibilidade, categoria, imagem, avaliações e moeda. A empresa afirma uma taxa de sucesso de 99,93% e funcionalidades como anti-CAPTCHA, proxies premium, stealth mode, smart extraction e renderização de JavaScript.
Principais funcionalidades
- Bypass anti-bot (proxies premium, navegadores headless)
- Rotação automática de headers
- Renderização de JavaScript
- Chamadas simples de API
- Suporte a elevada concorrência
Preço
Teste gratuito de 14 dias com 1.000 resultados básicos e 40 resultados protegidos. O por 250 mil resultados básicos / 10 mil protegidos. Pedidos protegidos (para sites com anti-bot) custam mais por pedido.
Prós e contras
| Prós | Contras |
|---|---|
| Bypass anti-bot forte em escala | Exige código |
| Promessa de elevada taxa de sucesso para ecommerce | Não faz parsing — devolve apenas HTML/JSON |
| Renderização JS, proxies premium, tratamento de CAPTCHA | Sem interface visual |
| Boa documentação e modelo API-first | O enriquecimento de subpáginas é totalmente manual |
| Escala melhor do que ferramentas de desktop | Não é ideal para pesquisas pontuais de vendedores |
Ideal para: equipas de desenvolvimento que constroem pipelines de dados do Etsy em grande escala e precisam de deteção robusta em elevada concorrência.
Comparação dos melhores scrapers de Etsy: tabela lado a lado
| Ferramenta | Sem código? | Tratamento anti-bot | Plano grátis/teste | Formatos de exportação | Scraping de subpáginas | Custo aprox. por 1 mil | Ideal para |
|---|---|---|---|---|---|---|---|
| Thunderbit | ✅ Sim (extensão do Chrome) | Modos cloud + navegador; IA adapta campos | ✅ Plano gratuito/teste | Excel, Sheets, Airtable, Notion, CSV, JSON | ✅ Integrado | ~US$ 9,60–US$ 30/1 mil linhas (depende do plano) | Vendedores e profissionais de marketing sem perfil técnico |
| Apify Etsy Scraper | ⚠️ Low-code | Depende do Actor; tentativas de retry com proxy/sessão | ✅ US$ 5/mês grátis na plataforma | JSON, CSV, Excel, API/webhooks | ⚠️ Requer configuração | ~US$ 0,80–US$ 3,45/1 mil produtos | Pipelines dedicados de dados do Etsy |
| Bright Data | ⚠️ Painel + API | ✅ Full stack (proxies residenciais, CAPTCHA) | ❌ Não (1 mil pedidos de teste) | JSON, NDJSON, CSV, entrega na cloud | ⚠️ Requer configuração | ~US$ 2,50/1 mil registos PAYG | Extração em escala empresarial |
| Octoparse | ✅ Sim (aplicação desktop) | Rotação integrada; opção manual de CAPTCHA | ✅ Plano gratuito (limitado) | CSV, Excel, JSON, DB, Sheets (pago) | ⚠️ Baseado em fluxo | SaaS fixo (a partir de ~US$ 69/mês) | Construtores de fluxos visuais |
| ScrapingBee | ❌ Com código (API) | ✅ Proxy + renderização JS | ✅ 1 mil créditos | JSON, HTML bruto | ❌ Manual | ~US$ 4,90/1 mil (estimativa Freelance) | Programadores com Python/JS |
| ZenRows | ❌ Com código (API) | ✅ Bypass anti-bot, proxies premium | ✅ Teste de 14 dias | JSON, HTML | ❌ Manual | ~US$ 7/1 mil protegidos | Equipas de desenvolvimento que precisam de escala |
Nenhuma ferramenta vence em tudo. O melhor scraper de Etsy depende do seu nível técnico, orçamento e escala necessária. Para vendedores, 500 linhas precisas no Google Sheets com título, preço, avaliações, vendedor, indicador de anúncio e envio valem mais do que 5.000 páginas brutas de HTML baratas.
Como validar a precisão do seu scraper de Etsy (não salte esta etapa)
Quero abordar algo que aparece constantemente nos fóruns de vendedores do Etsy: ceticismo em relação à precisão dos dados. Um utilizador do Reddit relatou que o EverBee mostrava 0 vendas para um autocolante que, na realidade, tinha vendido cerca de 40 unidades em dois meses. Outro disse que os números do EverBee, Alura e eRank estavam "muito incorretos" para a própria loja ligada. Isto não é exclusivo destas ferramentas — qualquer scraper pode devolver dados antigos ou imprecisos se não validar.
Aqui está o método de verificação pontual que eu uso:
- Comece por uma amostra pequena — 20 a 50 linhas.
- Abra manualmente 3–5 anúncios da amostra.
- Confirme título, preço, moeda, número de avaliações, avaliação, envio grátis, nome do vendedor e URL da listagem na página ativa do Etsy.
- Verifique se as linhas patrocinadas/anúncios estão corretamente assinaladas ou separadas.
- Execute a mesma extração novamente após 24 horas e compare as alterações de preço/avaliação.
- Adicione colunas de metadados à exportação: scraped_at, source_url, query, page, position, country, tool, run_id.
A frescura dos dados importa. Ferramentas que fazem scraping em tempo real (como o modo de scraping no navegador do Thunderbit, que acede à página no seu próprio navegador com sessão iniciada) tendem a devolver resultados mais atuais do que tarefas em lote com idade de cache desconhecida. Os próprios exigem que os utilizadores da API não exibam conteúdo de listagens com mais de 6 horas em relação às informações correspondentes do site do Etsy — um bom parâmetro para perceber quão depressa os dados podem ficar desatualizados.
E, para quem está no fundo da sala: qualquer ferramenta que afirme números exatos de vendas por anúncio está a estimar, não a fazer scraping de um facto público. Desconfie de promessas de precisão exagerada.
Casos de uso reais: escolher o melhor scraper de Etsy para o seu trabalho
"O que está a vender no meu nicho?" — pesquisa competitiva de produto
Um vendedor quer ver as principais listagens para "personalized pet portrait" — faixa de preço, número de avaliações, selos de bestseller, envio grátis, nomes das lojas e URLs das listagens.
Melhor opção: Thunderbit (scraping em 2 cliques dos resultados de pesquisa, IA sugere todas as colunas relevantes, exportação para Google Sheets para análise) ou Apify (configure um Actor recorrente para a mesma consulta todas as semanas).
Dica: inclua o indicador de anúncio/patrocinado e a posição. Como os , os dados da primeira página não são puramente orgânicos.
"Monitorizar preços da concorrência todas as semanas" — acompanhamento de preços
O dono de uma loja acompanha 50 anúncios concorrentes para ver alterações de preço ao longo do tempo.
Melhor opção: Scheduled Scraper do Thunderbit (descreva o intervalo em linguagem natural, insira as URLs e está pronto) ou Bright Data (para monitorização em escala empresarial em milhares de SKUs). O Apify também funciona bem para trabalhos recorrentes na cloud com menor custo.
Dica: acompanhe sempre scraped_at, moeda, país e se o anúncio estava em promoção. Um preço sem timestamp e localização é uma prova fraca.
"Criar um catálogo de produtos para a minha loja" — extração em massa de dados
Extraia 500+ anúncios com imagens, títulos, preços, descrições e materiais.
Melhor opção: Thunderbit (o scraping de subpáginas enriquece cada anúncio, e a extração de imagens exporta para Airtable/Notion) ou Octoparse (fluxo visual para extração em massa). O Apify funciona se a saída JSON e a execução na cloud forem mais importantes do que o fluxo visual.
Dica: não reutilize descrições ou imagens protegidas por direitos de autor sem permissão. Use o conteúdo criativo raspado para análise, não para copiar.
"Estou a construir um pipeline de dados do Etsy" — caso de uso para programadores
Um programador precisa de JSON estruturado bruto em escala, com tratamento anti-bot, schema personalizado, logs de retry e um pipeline para data warehouse.
Melhor opção: ScrapingBee ou ZenRows como camadas de acesso/renderização por API. Apify, se o ecossistema de Actors e os datasets geridos forem preferíveis. A do Thunderbit, se extração via JSON Schema e lotes de até 100 URLs se encaixarem no pipeline.
Dica: separe crawling, parsing, validação, armazenamento e relatórios. A ferramenta que obtém o HTML é apenas uma parte do pipeline.
Uma nota sobre listagens patrocinadas
Utilizadores de fóruns queixam-se frequentemente de que uma grande parte dos principais resultados do Etsy são apenas anúncios patrocinados. Um utilizador do Reddit, ao discutir filtros do uBlock, descreveu ver resultados de "Ad by Etsy Seller" repetidamente. Outro vendedor relatou ver o mesmo item tanto como anúncio como resultado orgânico.
Conselhos práticos de scraping:
- Capture is_sponsored quando estiver visível
- Separe posições pagas das orgânicas
- Vá além da página 1
- Remova duplicados por ID da listagem/URL canónica, não por título (anúncios e linhas orgânicas podem sobrepor-se)
- Faça uma pesquisa limpa deslogada e uma pesquisa logada/com sessão do browser se a sua pergunta de pesquisa depender de personalização
Considerações legais e éticas para fazer scraping no Etsy
Vou ser breve aqui. Os dizem que os utilizadores não podem fazer crawling, scraping ou spider em páginas sem permissão expressa. Os também proíbem o uso de sistemas automatizados para aceder, analisar ou fazer scraping ao site/API/dados do Etsy, a menos que haja autorização expressa.
O precedente jurídico nos EUA é complexo. Casos como o favorecem algumas teses de scraping de dados públicos, mas não eliminam riscos contratuais, de direitos de autor, privacidade ou aplicação de políticas da plataforma. A Bright Data esteve envolvida em sobre estas questões.
O meu conselho: use a API oficial do Etsy quando ela cobrir o seu caso de uso, recolha apenas dados públicos e necessários, evite dados pessoais/privados, respeite limites de taxa e controlos de acesso e não volte a publicar fotos ou descrições protegidas por direitos de autor sem permissão. Isto não é सलाह jurídica — consulte um profissional para situações específicas.
Conclusão: qual é o melhor scraper de Etsy para si?
Depois de testar os seis, a minha opinião sincera é que o "melhor" scraper de Etsy depende inteiramente de quem é e do que precisa:
- Vendedores e profissionais de marketing sem perfil técnico: Thunderbit. Dois cliques, com IA, enriquecimento de subpáginas e exportação direta para Sheets/Airtable/Notion. Comece pelo e veja o quanto resolve.
- Pipelines dedicados de dados do Etsy: Apify. Actors na cloud, agendador, API, preço transparente por resultado.
- Escala empresarial: Bright Data. Infraestrutura gerida, conformidade, SLAs, enorme pool de proxies.
- Preferência por fluxo visual: Octoparse. Construtor desktop point-and-click com modelos.
- Programadores: ScrapingBee ou ZenRows. Transporte por API, renderização JS, anti-bot — o resto constrói você.
A minha dica final: comece com um plano gratuito ou teste, faça uma validação pontual da precisão e só depois amplie a escala quando confirmar a qualidade dos dados. Não subscreva um plano pago antes de confirmar que a ferramenta realmente devolve os campos de que precisa, no formato de que precisa, com a frescura de que precisa.
E que os seus dados do Etsy estejam sempre limpos, estruturados e livres de anúncios patrocinados surpresa.
Perguntas frequentes
Qual é o melhor scraper de Etsy para utilizadores sem perfil técnico?
O Thunderbit é a melhor escolha para vendedores e profissionais de marketing sem perfil técnico. É uma extensão do Chrome em que clica em "AI Suggest Fields" em qualquer página do Etsy, revê as colunas sugeridas, clica em "Scrape" e exporta para Google Sheets, Airtable, Notion ou Excel. O scraping de subpáginas e o scraping agendado já vêm integrados. O Octoparse também é uma boa opção se preferir um construtor visual de fluxos para desktop.
É legal fazer scraping de dados de produtos do Etsy?
Fazer scraping de dados públicos da web tem precedente jurídico favorável em alguns contextos nos EUA (por exemplo, hiQ v. LinkedIn), mas os Termos de Utilização e os Termos da API do Etsy restringem crawling, scraping e acesso automatizado sem autorização. Para uso comercial, é prudente consultar um profissional jurídico, usar a API oficial quando possível e evitar copiar conteúdo protegido por direitos de autor, como fotos ou descrições de produtos.
Que dados consegue extrair do Etsy com um scraper?
Dos resultados de pesquisa: títulos, preços, imagens, URLs das listagens, nomes de vendedores/lojas, avaliações, número de avaliações, selos (bestseller, envio grátis, Star Seller) e etiquetas de patrocinado/anúncio. Das páginas individuais de listagem (via scraping de subpáginas): descrições completas, materiais, atributos, detalhes de envio, variações, políticas do vendedor e avaliações. Números reais de vendas por anúncio, taxas de conversão e volume real de pesquisa por palavra-chave não estão disponíveis diretamente via scraping — qualquer ferramenta que mostre isso está a estimar.
Consigo fazer scraping no Etsy sem ser bloqueado?
Sim, com a ferramenta certa. O Etsy usa controlos anti-bot, incluindo estruturas dinâmicas de página, TLS fingerprinting, CAPTCHAs e limitação de taxa. Ferramentas como Thunderbit (modos cloud e no browser), Bright Data (infraestrutura empresarial de proxies), ScrapingBee (renderização JS e proxies premium) e ZenRows (API anti-bot) tratam destas medidas automaticamente. Para pesquisas em pequena escala, o modo browser do Thunderbit — que usa a sua própria sessão iniciada — tende a ser fiável e a devolver dados atuais.
Quanto custa um scraper de Etsy?
Há planos gratuitos ou testes disponíveis no Thunderbit, Apify, Octoparse, ScrapingBee e ZenRows. A Bright Data oferece pedidos de teste, mas não tem plano gratuito contínuo. Os planos pagos normalmente começam em US$ 49–US$ 69/mês para ferramentas de programador/sem código. APIs específicas de Etsy por resultado variam de cerca de US$ 0,80–US$ 3,45 por 1 mil registos (Apify) até US$ 2,50/1 mil (Bright Data PAYG). O modelo baseado em créditos do Thunderbit começa em cerca de US$ 15/mês. O custo real depende de quantas linhas precisa, se usa enriquecimento de subpáginas e com que frequência faz scraping.
Saiba mais