
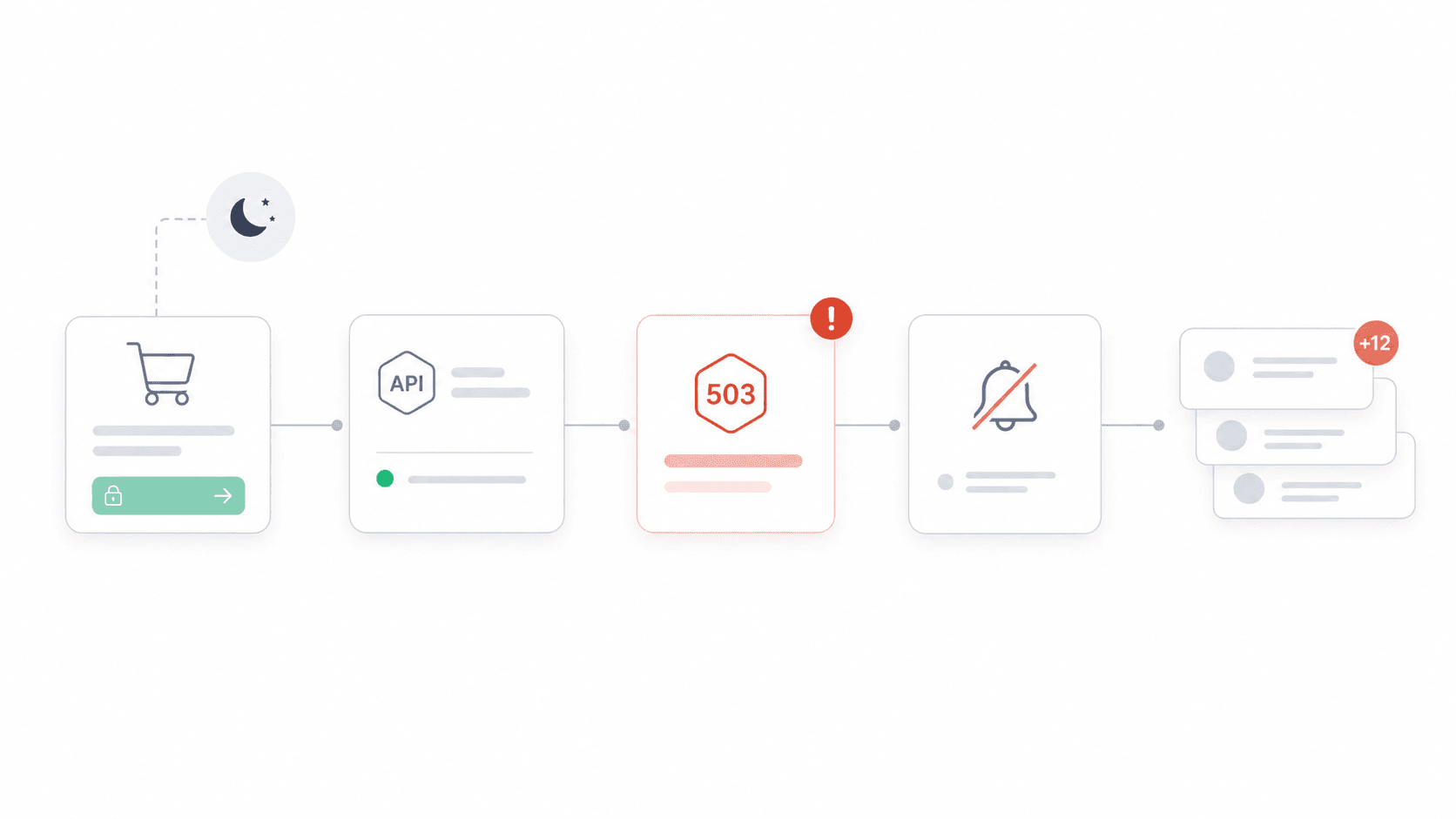
No mês passado, a integração Stripe de um amigo começou a devolver 503s em silêncio às 23h de uma sexta-feira. Ninguém percebeu até a manhã de sábado — quando a caixa de entrada do suporte já tinha mais de 200 e-mails furiosos de clientes cujos pagamentos haviam falhado.
Essa história não é rara. Uma estima o downtime médio em US$ 5.600 por minuto, enquanto . O valor real depende do tráfego, da taxa de conversão, do valor do pedido, da exposição ao SLA e do custo de recuperação — mas a conclusão geral é clara: APIs sem monitoramento são um risco de negócio, não apenas um incômodo de engenharia. E, com e , o monitoramento deixou de ser opcional. O que eu quis fazer com este guia foi algo que não vi em outro lugar: organizar as ferramentas por caso de uso, avaliar a qualidade dos alertas (não só a existência deles), mostrar preços reais de 2026 e medir quão rápido você realmente consegue começar a usar. Não é só mais uma lista de logotipos.
Mais uma coisa: se o seu trabalho com APIs envolve coletar dados da web, alimentar LLMs, construir sistemas RAG, monitorar páginas de concorrentes ou extrair dados de preços/produtos de sites, a conversa sobre “ferramentas de API” não deve parar em monitoramento de uptime. Você também precisa de uma forma confiável de transformar páginas confusas da web em dados estruturados. É aí que entra neste guia: ela não é um monitor de uptime, mas é uma das maneiras mais rápidas de transformar sites em Markdown limpo ou JSON baseado em schema por meio de uma API.
O que é monitoramento de API (e por que sua equipe deveria se importar)?
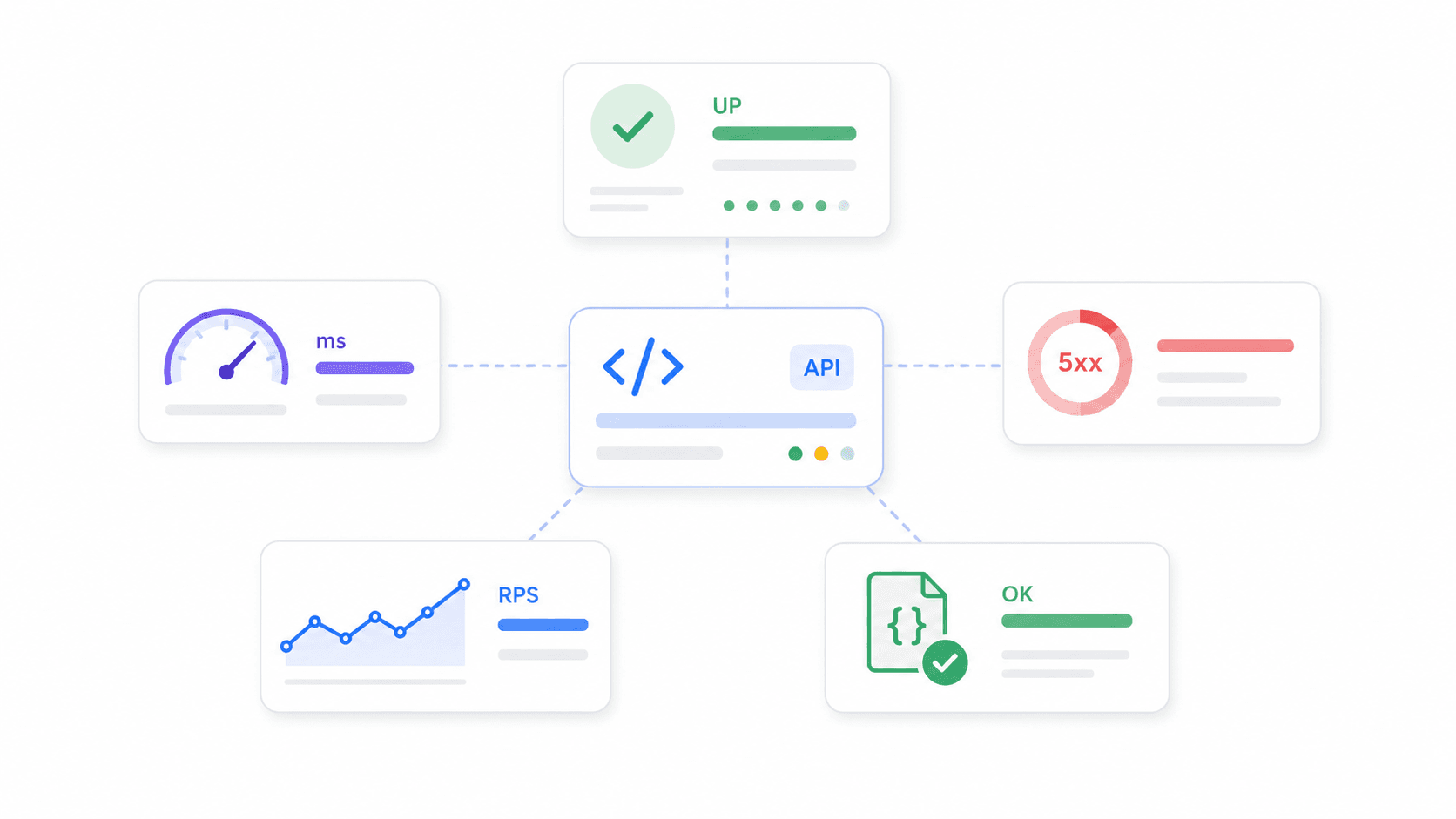
Monitoramento de API significa verificar continuamente se seus endpoints de API estão disponíveis, rápidos e retornando os dados corretos. Não é só “o servidor está no ar?” — um bom monitor valida códigos de status HTTP, payloads de resposta, latência, certificados SSL, fluxos em várias etapas (como login → busca → checkout) e até a correção do schema.
Isso é diferente de monitoramento geral de site (que verifica se uma página carrega) e de APM (Application Performance Monitoring), que aprofunda em traces no nível de código, consultas ao banco de dados e detalhes internos de runtime. O monitoramento de API fica na fronteira: ele testa o que usuários, parceiros e integrações realmente experimentam quando chamam seus endpoints.
Também existe uma categoria relacionada que vale destacar: APIs de dados da web. Elas não monitoram se a sua própria API está saudável; ajudam seu produto ou fluxo de trabalho a coletar dados externos da web de forma confiável. Por exemplo, pode condensar uma página da web em Markdown limpo, extrair campos estruturados em JSON e executar tarefas em lote em várias URLs. Se o seu projeto de “API” depende de dados atualizados de fornecedores, páginas de produto, listagens públicas, páginas de documentação ou fontes de pesquisa, esse tipo de API de extração de dados pode ser tão importante operacionalmente quanto as verificações de uptime.
Por que pessoas que não são engenheiras deveriam se importar? Porque e . Quando um gateway de pagamento, serviço de autenticação ou API de frete falha, não é um problema abstrato de infraestrutura — é perda de receita, quebra de contratos com parceiros, aumento no volume de suporte e erosão de confiança. PMs, equipes de vendas, operações e sucesso do cliente também têm interesse nisso.
Métricas principais para acompanhar:
- Percentual de uptime: parcela do tempo em que um endpoint fica disponível
- Tempo de resposta / latência: quanto tempo o endpoint leva para responder (média, p95, p99)
- Taxa de erro: parcela de requisições que retornam 5xx, timeouts ou falhas de validação
- Throughput: requisições por segundo/minuto
- Corretude: se a API retorna os dados esperados, e não apenas um 200 OK
Como avaliamos as melhores ferramentas de monitoramento de API para 2026
A maioria dos artigos sobre “melhores ferramentas de monitoramento de API” só empilha nomes de fornecedores e recursos. Eu quis ser mais criterioso na seleção — em parte porque passei muito tempo lendo fóruns de desenvolvedores e, em parte, porque a equipe da Thunderbit me ajudou a dos sites dos fornecedores para montar uma comparação real (mais sobre esse fluxo depois).
Foi isso que ponderamos:
| Critério | Por que importa | |---|---| | Facilidade de configuração / tempo até o primeiro alerta | Equipes pequenas precisam de cobertura hoje, não depois de um projeto de plataforma | | Inteligência de alertas e redução de ruído | Se os alertas são barulhentos, a equipe ignora e perde incidentes reais | | Generosidade do plano gratuito | Projetos paralelos e startups no início geralmente começam grátis | | Transparência de preços | Contas de observabilidade podem explodir com hosts, seats, logs, execuções sintéticas e ingestão de dados | | Amplitude de integrações | Os alertas precisam chegar onde a equipe já trabalha (Slack, PagerDuty etc.) | | Escalabilidade e profundidade de dados | Equipes maduras precisam de traces, logs, APM, RBAC, SSO e retenção | | Qualidade da comunidade e do suporte | Equipes open-source precisam de cadência de releases; equipes enterprise precisam de SLAs | | Capacidade de extração de dados da web | Apps de IA, fluxos de RAG e ferramentas de pesquisa de mercado muitas vezes precisam de dados externos limpos, não apenas uptime de endpoint |
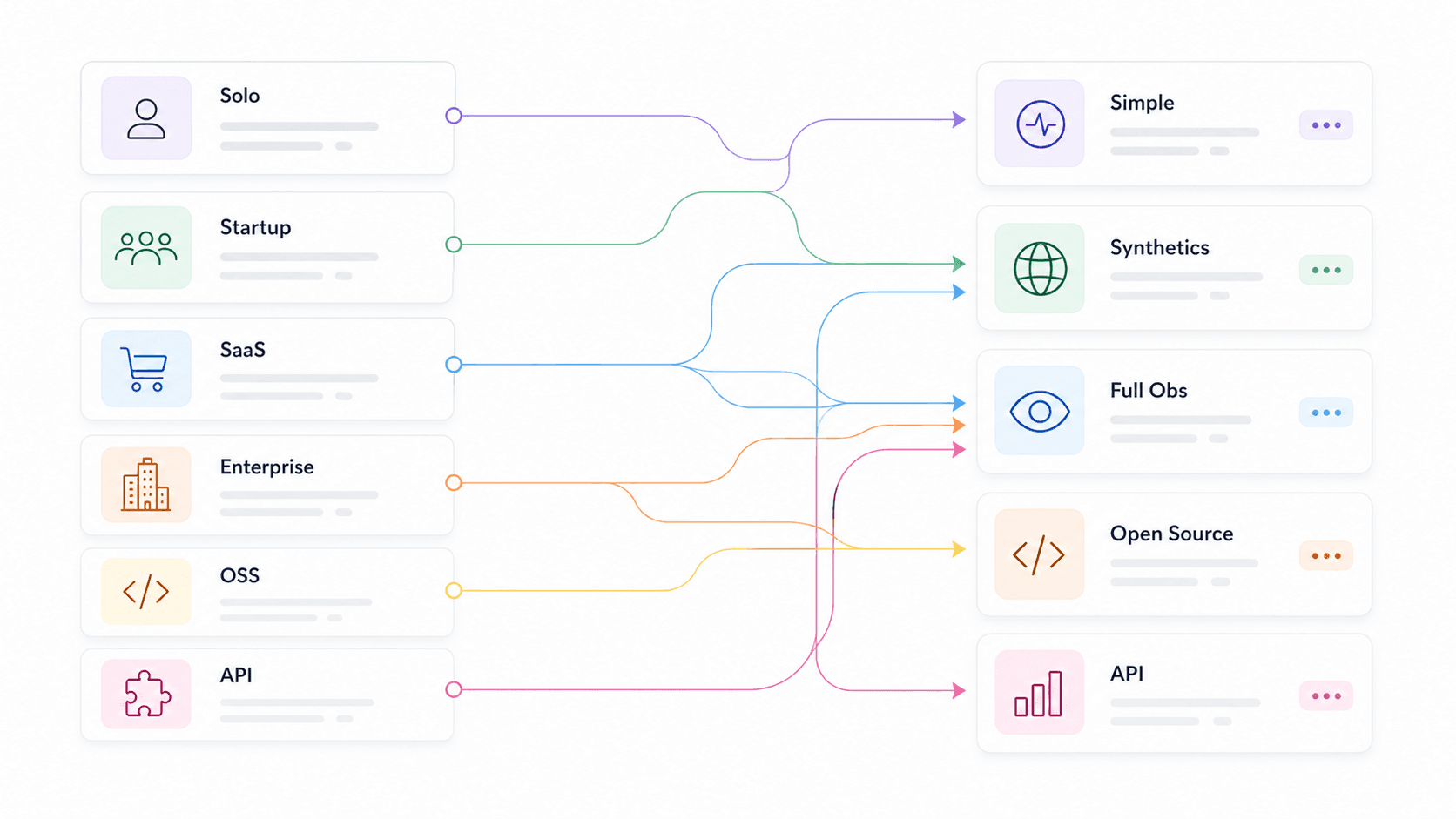
Também separamos recomendações por caso de uso — dev solo, startup, e-commerce/SaaS, enterprise, purista open-source, equipe de produto de API e equipe de dados da web/IA — para que você possa ir direto ao seu contexto em vez de ler 14 resumos de ferramentas tentando adivinhar qual serve para você. A apontou que e como critérios de escolha, o que confirma que esses pontos não são apenas “bons de ter”.
Melhores ferramentas de monitoramento de API por caso de uso: tabela de seleção rápida
Este é o atalho. Encontre sua linha e depois vá para as seções das ferramentas abaixo para ver a análise completa.
| Caso de uso | Ferramentas recomendadas | Diferencial principal | |---|---|---| | Equipes de dados da web / apps de IA | Thunderbit Open API, Moesif, Apitally | Transforme sites em Markdown limpo ou JSON estruturado para fluxos de LLM, RAG, preços e pesquisa | | Dev solo / projeto paralelo | UptimeRobot, Uptime Kuma, Gatus | Grátis ou auto-hospedado, configuração mínima, rápido para começar | | Startup (equipe de 5–15 pessoas) | Checkly, Better Stack, Postman | Alertas inteligentes, setup rápido, preço acessível, páginas de status | | E-commerce / SaaS | Datadog, New Relic, Moesif, Checkly | Métricas de negócio, APM/tracing, profundidade de SDK, sintéticos em múltiplas etapas | | Enterprise / multi-cloud | Datadog, New Relic, Splunk, Grafana Cloud | Distributed tracing, compliance, ambiente híbrido, RBAC/SSO | | Puristas de open-source | Prometheus + Grafana, Uptime Kuma, Gatus, Uptrace | Controle total, nativo de OTel, sem lock-in de fornecedor | | Equipes de produto de API | Moesif, Apitally, New Relic | Uso por cliente, tendências de endpoint, alertas de anomalia |
O maior padrão: as ferramentas mais rápidas de configurar tendem a ser mais leves em analytics, enquanto as plataformas mais profundas exigem mais configuração e disciplina de custos. Isso não é um defeito — é uma troca que você precisa conhecer. A Thunderbit fica em uma faixa um pouco diferente: ela é mais rápida quando a tarefa é transformar páginas da web em dados prontos para API, e não avisar engenheiros sobre downtime.
Thunderbit Open API: melhor para transformar sites em dados estruturados via API
A é a API que eu colocaria em primeiro lugar para equipes cujo fluxo de trabalho de “monitoramento” ou pesquisa depende de dados externos da web. Ela não é uma ferramenta tradicional de monitoramento de uptime como Checkly ou UptimeRobot. Em vez disso, a Thunderbit transforma qualquer página da web em dados limpos e estruturados que seus apps, agentes, dashboards e pipelines de LLM realmente conseguem usar.
A API tem três fluxos principais. Condensar converte uma página em Markdown limpo, pronto para LLM. Extrair recebe um schema e devolve campos JSON estruturados como nome do produto, preço, disponibilidade, porte da empresa, estágio de captação ou avaliação média. Lote permite processar até 100 URLs de forma assíncrona com webhooks, o que é útil quando você monitora páginas de preços, catálogos de concorrentes, documentação de fornecedores, fontes de notícias ou grandes listas de pesquisa.
Ela merece espaço neste guia de ferramentas de API porque as equipes subestimam o quanto de infraestrutura é necessário para “só extrair essa página”. Sites pesados em JavaScript exigem renderização. Algumas páginas precisam de roteamento geográfico. O HTML precisa ser limpo de barras de navegação, anúncios, modais e boilerplate antes de ficar útil para um LLM. Seletores quebram quando o layout muda. Rotação de proxy, tratamento anti-bot, retries, filas e polling de resultados podem transformar um pequeno fluxo de dados em um projeto de manutenção. A Thunderbit absorve boa parte desse trabalho por trás de uma única API.
Melhor para: criadores de apps de IA, equipes de RAG, operações de e-commerce, sales ops, growth, pesquisadores de mercado e desenvolvedores que precisam de dados de sites via API sem construir e cuidar de uma pilha de scraping.
Preço: , incluindo até 600 páginas em Condensar ou 30 páginas em Extrair, com 2 requisições simultâneas. O plano Starter aparece por US$ 16/mês no anual para 60.000 unidades de API/ano e 30 requisições simultâneas. O Pro aparece por US$ 40/mês no anual para 600.000 unidades de API/ano e 50 requisições simultâneas.
Velocidade de configuração: ~5–15 minutos para obter uma chave de API e executar a primeira requisição de Condensar ou Extrair com cURL, SDKs ou o .
Pontos fracos: a Thunderbit não substitui Datadog, New Relic, Better Stack ou Checkly para verificações de uptime, escalonamento de incidentes, traces, logs ou roteamento de plantão. Pense nela como a API que você usa para coletar e estruturar dados da web — incluindo preços de fornecedores, documentação, páginas de concorrentes, listagens de produtos ou datasets públicos — não como o sistema que aciona o engenheiro de plantão.
Datadog: melhor para visibilidade de stack completo
O Datadog é a ferramenta que eu mais vejo em stacks de SaaS enterprise e mid-market, e com razão. Ele não é apenas monitoramento de API — é uma plataforma completa de observabilidade que conecta testes sintéticos de API a distributed traces, logs, métricas de infraestrutura e monitoramento de usuário real em uma única visão.
Especificamente para monitoramento de API, o Datadog suporta HTTP, SSL, DNS, WebSocket, TCP, UDP, ICMP, gRPC e . Seus aprendem padrões esperados e alertam sobre desvios em vez de limiares estáticos — o que é um avanço significativo em relação a “alertar quando a latência > 500 ms”. Ele também oferece que antecipam quando uma métrica vai ultrapassar um limite, além de monitores compostos que combinam várias condições.
Melhor para: equipes de e-commerce, SaaS e enterprise que precisam de uma visão única de APIs, infraestrutura, logs e traces.
Preço: os detalhes do plano gratuito variam por produto. ; testes sintéticos de API custam US$ 5 por 10.000 execuções. Mais de 800 integrações.
Velocidade de configuração: ~15–30 minutos para instalar o agente e criar um teste sintético básico.
Pontos fracos: pode ficar caro em escala — “surpresa na fatura” é um tema recorrente no Hacker News e no Reddit. A quantidade enorme de SKUs (hosts, logs, métricas personalizadas, sintéticos, usuários) significa que você precisa de alguém olhando a conta, não só os dashboards. A curva de aprendizado da plataforma completa é real.
Checkly: melhor para verificações sintéticas pensadas para desenvolvedores
O Checkly é a ferramenta que eu daria a uma equipe de engenharia de startup que quer checks de API próximos do código. A ideia central é “monitoramento como código”: defina verificações de API e browser programaticamente, execute-as a partir de locais globais, integre com pipelines de CI/CD e gerencie tudo via Git.
O ponto de qualidade dos alertas é forte aqui. A do Checkly é explicitamente apresentada como a “primeira linha de defesa” contra falsos positivos — você pode configurar retries fixos, lineares ou exponenciais, retries no mesmo local ou em locais diferentes e duração máxima de retry antes que um alerta seja disparado. Ele também diferencia estados degradado, falho e recuperado, o que ajuda a reduzir páginas barulhentas.
Melhor para: startups e equipes de dev que querem checks de API programáveis, , integração com CI/CD e configuração rápida.
Preço: dados públicos recentes mostram um plano gratuito com 10 monitores de uptime, 1.000 checks de browser e 10.000 checks de API. Starter em torno de US$ 24/mês no anual — antes de comprar.
Velocidade de configuração: ~10–20 minutos para um primeiro check de API e canal de alerta.
Pontos fracos: focado em verificações sintéticas. Não substitui APM profundo, analytics de logs ou distributed tracing. Se você precisa correlacionar uma falha de API com um gargalo de banco de dados, vai precisar de outra ferramenta junto.
UptimeRobot: melhor para acompanhamento simples e acessível de uptime
O UptimeRobot é o Honda Civic do monitoramento de API. Faz uma coisa bem feita: você cria um monitor HTTP, keyword, ping, porta, SSL ou heartbeat, escolhe o intervalo e recebe alerta quando falha. É isso.
Melhor para: devs solo, equipes pequenas, agências ou qualquer pessoa que precise de uptime e latência básicos sem complexidade.
Preço: . Plano Solo pago em torno de US$ 7/mês no anual. Não exige cartão de crédito no plano gratuito. Velocidade de configuração: ~2–5 minutos — a mais rápida desta lista.
Pontos fracos: inteligência de alertas limitada. Alertas básicos por limiar, sem detecção de anomalias, sem distributed tracing, sem analytics profundos. Se você precisa saber por que um endpoint está lento (e não só que ele está lento), o UptimeRobot não resolve.
Uptime Kuma: melhor ferramenta gratuita e auto-hospedada de monitoramento de API
O Uptime Kuma é o queridinho da comunidade de self-hosting, e os números do GitHub confirmam isso: , com a versão 2.3.2 em maio de 2026. É licenciado sob MIT, suporta HTTP(s), keyword, consulta JSON, WebSocket, TCP, ping, DNS, push, Docker, várias páginas de status e mais de 90 serviços de notificação.
Melhor para: devs solo e equipes que querem controle total, privacidade e custo SaaS recorrente zero — desde que tenham um servidor.
Preço: grátis. O custo real é a sua VM/container, backups, atualizações e garantir que o próprio monitor continue no ar. Velocidade de configuração: ~5–15 minutos com Docker para um check básico; 15–30 minutos com ajustes de notificação e página de status.
Pontos fracos: a manutenção é sua. E aqui está o problema crítico: se você hospedar o Uptime Kuma na mesma infraestrutura que ele monitora, uma indisponibilidade de nuvem ou DNS derruba tanto seu app quanto o monitor. Hospede externamente ou combine com um check SaaS.
Better Stack: melhor para resposta rápida a incidentes
O Better Stack (ainda frequentemente chamado de Better Uptime por usuários) combina monitoramento de uptime com gestão de incidentes, escalonamento de plantão, políticas de escalonamento e páginas de status em uma só plataforma. O ponto mais forte não é analytics, e sim o fluxo de trabalho de incidentes em torno do monitoramento.
As definem quem recebe alerta, em que ordem, com quais atrasos, até a confirmação. O roteamento baseado em metadados envia incidentes por severidade ou responsabilidade. Ele se integra com Slack, Teams, webhooks e Zapier.
Melhor para: startups e equipes de médio porte que querem monitoramento + resposta a incidentes + páginas de status sem juntar três ferramentas separadas.
Preço: . Team em torno de US$ 29/mês no anual. Velocidade de configuração: ~5–10 minutos via assistente de interface.
Pontos fracos: menor profundidade em analytics de payload de API, distributed tracing ou análise de KPI de negócio em comparação com Datadog, New Relic ou Moesif.
Prometheus + Grafana: melhor stack open-source para monitoramento de API
Esta é a combinação open-source padrão do setor. O coleta e armazena métricas de séries temporais. O (73.705 estrelas no GitHub, 3.010 contribuidores) fornece dashboards e alertas. O cuida de roteamento, agrupamento, deduplicação, silenciamento e inibição. Para checagens de endpoint de API, as equipes adicionam o para probing de HTTP, HTTPS, DNS, TCP, ICMP e gRPC.
Melhor para: puristas de open-source, equipes de Kubernetes/SRE e organizações já padronizadas em métricas do Prometheus.
Preço: grátis se auto-hospedado. O tem plano gratuito (100 mil execuções de teste de API/mês) e planos pagos baseados no uso.
Velocidade de configuração: 1–4 horas para uma configuração básica com Blackbox + Prometheus + Grafana + Alertmanager. Dias para HA em produção e ajuste fino de alertas.
Pontos fracos: PromQL, YAML, relabeling, design de dashboards, retenção, armazenamento, HA e ajuste de alertas exigem trabalho operacional de verdade. A troca recorrente é “menos interface, mais YAML”. É a stack para equipes que já pensam em métricas e querem um plano de controle único — não para quem quer o monitoramento rodando antes do almoço.
New Relic: melhor para performance de aplicações SaaS
O New Relic combina APM, monitoramento de infraestrutura, logs, distributed tracing, monitoramento sintético, alertas, dashboards e análise de incidentes com apoio de IA. Seu plano gratuito — — é realmente generoso para equipes pequenas.
A inteligência de alertas é onde o New Relic brilha na discussão sobre fadiga de alertas. Os recursos de incluem correlação de eventos, detecção de anomalias, alertas preditivos, análise de causa raiz e supressão de flapping. O New Relic publicou um exemplo em que — um número concreto de redução de ruído.
Melhor para: equipes de SaaS e plataformas de e-commerce que querem monitoramento de API fortemente integrado a traces, erros, throughput e impacto no usuário.
Preço: grátis: 100 GB/mês, 1 usuário full. Pago usa precificação por usuário e por volume de dados.
Velocidade de configuração: ~15–30 minutos para instalar o agente e seguir a configuração guiada.
Pontos fracos: o preço pode ficar complexo em escala. A configuração de alertas tem curva de aprendizado — a plataforma é poderosa, mas não é imediatamente óbvia.
Moesif: melhor para analytics de API e métricas de negócio
O Moesif não é um monitor tradicional de uptime. É analytics de API e inteligência de produto: entender o uso da API por cliente, endpoint, coorte, empresa, geografia, SDK, plano e comportamento. Se a sua pergunta é “qual cliente foi afetado?” e não “o endpoint está no ar?”, o Moesif foi feito para isso.
Ele suporta para métricas de API como picos/quedas de tráfego, latência e mudanças de comportamento. Os alertas dinâmicos precisam de alguns dias de comportamento da API para construir um modelo, mas, depois de treinados, detectam mudanças que regras estáticas não percebem.
Melhor para: equipes de produto de API, empresas SaaS e plataformas de e-commerce que precisam conectar performance de API com receita, engajamento e retenção.
Preço: ; os planos pagos escalam com o volume de eventos da API. Os valores self-service não ficaram totalmente acessíveis no meu levantamento — verifique a página atual.
Velocidade de configuração: ~20–45 minutos (a integração via SDK/proxy/gateway é mais profunda do que um ping externo).
Pontos fracos: mais focado em analytics do que em monitoramento tradicional de uptime. Provavelmente você vai querer combinar o Moesif com Checkly, UptimeRobot ou sintéticos do Datadog para checagens externas de disponibilidade.
Splunk: melhor para análise de logs enterprise e compliance
O Splunk é a ferramenta para quando agregação de logs, busca, correlação, auditabilidade pronta para compliance e suporte híbrido/multi-cloud são inegociáveis. O cobre infraestrutura, APM, sintéticos, monitoramento de usuário real, logs e resposta a incidentes. O pode agrupar eventos relevantes em episódios e reduzir ruído entre silos de monitoramento.
A própria é preocupante: , e .
Melhor para: equipes enterprise e multi-cloud com requisitos rígidos de compliance, segurança, auditoria e busca em logs.
Preço: baseado em uso e normalmente via proposta. Não há um plano gratuito simples para produção.
Velocidade de configuração: a entrada na nuvem pode ser mais rápida, mas uma implementação enterprise muitas vezes leva de dias a semanas.
Pontos fracos: caro em escala. Configuração complexa. Exagerado para dev solo e startups pequenas.
Postman: melhor para equipes que já testam APIs
O Postman é principalmente uma plataforma de desenvolvimento e teste de APIs, mas o permite que as equipes agendem collections do Postman e as executem a partir de locais na nuvem. O argumento mais forte é o reuso: se sua equipe de QA ou desenvolvimento já tem collections com assertions, transformá-las em monitores é um próximo passo natural.
Melhor para: equipes de dev e QA que já usam collections do Postman e querem verificações agendadas sem comprar uma ferramenta sintética separada.
Preço: existe plano gratuito. ; pacote adicional de 50.000 chamadas por US$ 20/mês. Verifique a — a estrutura de planos do Postman muda.
Velocidade de configuração: ~10 minutos se as collections já existirem.
Pontos fracos: as capacidades de monitoramento são mais leves do que ferramentas dedicadas como Checkly, Datadog ou New Relic. As opções de alerta são básicas.
Outras ferramentas de monitoramento de API que valem uma olhada
: dashboard de saúde leve, auto-hospedado e orientado por configuração. , com suporte a HTTP, ICMP, TCP, DNS, métricas amigáveis ao Prometheus e badges de uptime. Ótimo para devs solo que querem algo mais simples que o Prometheus, mas preferem YAML/config-as-code à interface do Uptime Kuma.
: ferramenta mais nova focada em analytics de tráfego de API e acompanhamento de qualidade para startups. Afirma com alertas personalizados em 14 métricas. Boa para analytics leve de API sem adotar uma plataforma completa de observabilidade.
: monitoramento full stack com logs, sintéticos e visibilidade de infraestrutura. . Uma alternativa ao Datadog de menor custo para equipes mid-market.
: backend de APM, tracing, métricas e logs nativo de OpenTelemetry. . Não é um verificador puro de uptime, mas é ideal para equipes padronizadas em OTel que querem um backend de tracing amigável ao open-source.
Construir ou comprar: vale a pena fazer seu próprio monitoramento de API?
“Será que eu só escrevo um script para fazer ping nos meus endpoints ou uso uma ferramenta dedicada?”
Essa pergunta aparece o tempo todo em fóruns de desenvolvedores. Já li threads suficientes no Reddit para ver o padrão com clareza: as equipes começam com curl + cron, funciona bem por um tempo e depois migram quando precisam de dashboards, dados históricos, checagens em múltiplas regiões, roteamento confiável de alertas ou visibilidade entre equipes.
Uma matriz de decisão honesta:
| Fator | Script customizado | Ferramenta especializada | |---|---|---| | Tempo de configuração | 1–4 horas (básico); dias (robusto) | 5–30 minutos | | Manutenção | Você assume para sempre | O fornecedor cuida das atualizações | | Qualidade dos alertas | Básica (up/down) | Inteligente (tendências de latência, anomalias, retries) | | Custo | Grátis (seu tempo) | US$ 0–US$ 500+/mês | | Dashboard | Construir do zero | Pronto, personalizável | | Melhor quando… | ≤3 endpoints, equipe muito técnica, projeto hobby | 5+ endpoints, equipe de ops/produto, receita em jogo |
O principal insight dos fóruns: quem constrói o próprio sistema muitas vezes se arrepende quando passa a precisar de dashboards, dados históricos ou visibilidade entre times. E existe o problema meta — “você precisa monitorar o seu monitoramento”. Um monitor auto-hospedado, banco de dados, backup, caminho de rede e provedor de alertas também precisam ser confiáveis.
Construa se você tem 2 endpoints e gosta de fuçar. Compre se você tem um produto para lançar.
A mesma lógica vale para extração de dados da web. Você pode escrever um scraper, rodar navegadores headless, rotacionar proxies, manter seletores, limpar HTML e montar uma fila. Mas, se o trabalho é alimentar de forma confiável um produto de API, um agente de IA ou um fluxo de pesquisa com dados da web, usar a costuma ser mais rápido do que criar sua própria infraestrutura de scraping.
Fadiga de alertas: por que a qualidade do alerta supera a quantidade
Este talvez seja o critério mais subestimado na escolha de uma ferramenta de monitoramento de API. Fadiga de alertas acontece quando as equipes recebem tantos alertas barulhentos, duplicados ou sem ação prática que passam a ignorá-los — e acabam perdendo incidentes reais.
Os números são impressionantes. O mostrou que a organização mediana gerava e . A ação prática mediana dos incidentes era de apenas — ou seja, menos de um em cada cinco incidentes derivados de alertas era realmente acionável. A mostrou que e .
A melhor ferramenta de monitoramento é aquela cujos alertas você realmente confia. Aqui vai uma comparação de como as ferramentas lidam com inteligência de alertas:
| Ferramenta | Tipo de alerta | Método de redução de ruído | Canais de alerta | |---|---|---|---| | Datadog | Anomalia por ML, previsão, composto | Faixas históricas de anomalia, baselines dinâmicos, Watchdog AI | Slack, PagerDuty, Opsgenie, Teams, mais de 20 | | Checkly | Limiar + degradação | Retry antes do disparo, retries no mesmo/diferente local | Slack, PagerDuty, Opsgenie, Teams, incident.io | | New Relic | Agrupamento de issues por IA, anomalia, preditivo | Correlação de eventos, supressão de flapping, contexto de causa raiz | Slack, PagerDuty, Teams, webhooks | | Moesif | Anomalia comportamental | Modelos dinâmicos após vários dias de comportamento | Slack, PagerDuty, e-mail, SMS | | Better Stack | Uptime/incidente/plantão | Políticas de escalonamento, roteamento por responsabilidade, atrasos | Slack, Teams, webhooks, Zapier | | Prometheus + Alertmanager | Alertas por regras PromQL | Agrupamento, deduplicação, silenciamento, inibição | E-mail, PagerDuty, Opsgenie, webhooks | | Splunk | Eventos, episódios, saúde do serviço | ITSI Event Analytics, agrupamento por episódios, ticketing | Splunk On-Call, ServiceNow, webhooks | | Thunderbit Open API | Não é uma plataforma de alertas | Use com seu próprio scheduler, ferramenta de workflow ou stack de monitoramento | Webhooks para tarefas em lote; alertas tratados externamente |
Conselho prático: comece com menos alertas, mas com mais confiança. Use retry antes do disparo, confirmação em múltiplas regiões, alertas por burn rate de SLO, deduplicação e roteamento por responsabilidade. Alerta sobre impacto no usuário e fluxos críticos de negócio (falha no checkout, falha de autenticação, 5xx no pagamento), não sobre cada sintoma interno.
Planos gratuitos e preços de 2026: o que você realmente paga
As páginas de preço mudam. Planos gratuitos também. Custos ocultos (hosts, seats, logs, execuções sintéticas, ingestão de dados) podem surpreender. Esta é a seção que eu gostaria que existisse em todo artigo de “melhores ferramentas”. O panorama de 2026:
| Ferramenta | Plano gratuito | A partir de | Cartão de crédito é necessário? | Melhor caso de uso gratuito | |---|---|---|---|---| | Thunderbit Open API | 600 unidades de API de uso único | ~US$ 16/mês no anual | Não | Extração de dados da web para LLMs, RAG, preços e pesquisa | | Uptime Kuma | Ilimitado (auto-hospedado) | — | Não | Monitoramento completo, seu próprio servidor | | UptimeRobot | 50 monitores, intervalos de 5 min | ~US$ 7/mês | Não | Verificações básicas de uptime | | Better Stack | 10 monitores, 1 página de status | ~US$ 29/mês | Não | Uptime de startup + página de status | | Checkly | 10 uptime, 10 mil checks de API | ~US$ 24/mês | Sim | Checks sintéticos de API | | Postman | Conta gratuita + cota de monitoramento | ~US$ 14/usuário/mês | Não | Reutilização de collections existentes | | Prometheus + Grafana | Ilimitado (auto-hospedado) | — | Não | Métricas + visualização | | Grafana Cloud | 100 mil execuções de teste de API/mês | US$ 29/mês da plataforma + uso | Verificar | Avaliação de sintéticos gerenciados | | New Relic | 100 GB/mês, 1 usuário full | Por usuário + dados | Alguns planos | APM + observabilidade básica | | Datadog | Trial/varia por produto | US$ 15/host/mês (Infra Pro) | Muitas vezes, sim | Avaliação de stack completo | | Moesif | Grátis/trial disponível | Baseado em volume | Verificar | Avaliação de analytics de API | | Splunk | Trials disponíveis | Sob proposta | Fluxo comercial | Prova de conceito enterprise | | Gatus | Ilimitado (auto-hospedado) | — | Não | Dashboard de status orientado por YAML | | Apitally | Grátis/trial disponível | Verificar | Verificar | Analytics leve de API | | Sematext | Trial/grátis varia | ~US$ 2/monitor HTTP | Verificar | Sintéticos/logs de menor custo | | Uptrace | Grátis auto-hospedado | Planos cloud variam | Verificar | Avaliação de APM com OTel |
Nota sobre custos ocultos: ferramentas auto-hospedadas (Uptime Kuma, Prometheus, Gatus) são “grátis” em termos de licença, mas uma pequena VM, backups, tempo de manutenção e failover externo podem facilmente se tornar o custo real. Para APIs de dados da web, o custo oculto costuma ser diferente: manter navegadores headless, seletores quebrados, pools de proxy, gambiarras anti-bot e limpeza de HTML.
Estimativa para equipes pequenas: para 10 endpoints de API e 3 pessoas na equipe, o caminho SaaS mais barato costuma ser UptimeRobot grátis ou pago básico, Better Stack grátis/Team, ou Checkly se o volume de execuções couber. Datadog e New Relic podem ser acessíveis para avaliação, mas a fatura real depende de hosts, usuários, logs, traces e volume de execuções sintéticas. Se o seu projeto precisa de dados de site como API, as unidades gratuitas da Thunderbit são suficientes para testar o fluxo antes de assinar um plano pago.
Scorecard de complexidade de configuração: quão rápido até o primeiro alerta?
Nenhum artigo concorrente que encontrei avalia o tempo até gerar valor — quanto tempo vai do cadastro até receber o primeiro alerta realmente útil. Para equipes menores, isso importa mais do que a profundidade de recursos.
| Ferramenta | Tempo até o primeiro alerta | Nível técnico necessário | Abordagem de configuração | |---|---|---|---| | Thunderbit Open API | ~5–15 minutos | Baixo–médio | Chave de API, cURL/SDK/CLI | | UptimeRobot | ~2–5 minutos | Baixo | GUI, adicionar com um clique | | Better Stack | ~5–10 minutos | Baixo | Assistente visual | | Checkly | ~10–20 minutos | Baixo–médio | Código ou GUI | | Postman | ~10 minutos (com collections) | Baixo–médio | Agendador de collections | | Uptime Kuma | ~5–30 minutos | Médio | Docker + GUI | | Gatus | ~15–45 minutos | Médio | YAML + Docker | | Datadog | ~15–30 minutos | Médio | Instalação do agente + GUI | | New Relic | ~15–30 minutos | Médio | Agente + configuração guiada | | Moesif | ~20–45 minutos | Médio | Integração via SDK/proxy | | Grafana Cloud Synthetics | ~15–45 minutos | Médio | GUI, Terraform opcional | | Prometheus + Grafana | 1–4 horas | Médio–alto | YAML, PromQL | | Uptrace | 30–90 minutos | Médio–alto | Integração com SDK OTel | | Splunk | Horas a semanas | Alto | Onboarding enterprise |
Se o monitoramento precisa entrar no ar até o fim do dia, comece na metade superior dessa tabela. Se o objetivo é observabilidade durável da plataforma, trate a metade inferior como um projeto separado. E, se seu primeiro marco for “colocar dados limpos dessas 100 páginas da web em um app”, comece com a Thunderbit antes de construir uma infraestrutura própria de scraping.
Comparativo completo das melhores ferramentas de monitoramento de API
Uma tabela para olhar antes de decidir:
| Ferramenta | Melhor caso de uso | Plano gratuito | Inteligência de alertas | Tempo de configuração | Hospedagem | Recurso de destaque | |---|---|---|---|---|---|---| | Thunderbit Open API | Extração de dados da web/pipelines de dados de API | 600 unidades de API | Não é ferramenta de alertas | 5–15 min | Cloud | Condensa páginas em Markdown ou extrai JSON baseado em schema | | Datadog | Enterprise/SaaS full stack | Trial/varia | Anomalia, previsão, IA | 15–30 min | Cloud | Correlaciona sintéticos com logs/traces/infra | | Checkly | Sintéticos pensados para dev | Generoso por checks | Retries, degradação | 10–20 min | Cloud | Monitoramento como código + Playwright | | UptimeRobot | Uptime simples | 50 monitores | Limiar básico | 2–5 min | Cloud | Monitor básico mais rápido e barato | | Uptime Kuma | Auto-hospedado grátis | Ilimitado | Status/limiar básico | 5–30 min | Auto-hospedado | UI limpa, sem taxa SaaS | | Better Stack | Resposta a incidentes/páginas de status | 10 monitores | Escalonamentos, roteamento | 5–10 min | Cloud | Monitoramento + plantão + página de status | | Prometheus + Grafana | Stack open-source de métricas | Ilimitado (auto-hospedado) | Agrupamento do Alertmanager | 1–4 h | Auto-hospedado/cloud | Profundidade do ecossistema PromQL | | New Relic | APM SaaS + checks de API | 100 GB/mês, 1 usuário | Agrupamento por IA, supressão de flapping | 15–30 min | Cloud | APM forte + sintéticos juntos | | Moesif | Analytics de API/métricas de negócio | Grátis/trial | Anomalias comportamentais | 20–45 min | Cloud | Analytics do comportamento da API por cliente | | Splunk | Logs/compliance enterprise | Trial | Episódios ITSI, AIOps | Dias+ | Cloud/gerenciado pelo cliente | Busca e governança de logs enterprise | | Postman | Equipes que já testam APIs | Conta gratuita | Alertas básicos de monitoramento | 10 min | Cloud | Reutiliza collections de teste de API |
Como a Thunderbit pode acelerar sua avaliação de ferramentas de API
Transparência total: a não é uma ferramenta de monitoramento de API — é um web scraper com IA e uma para transformar páginas da web em Markdown limpo ou JSON estruturado. Isso a torna útil em outra parte do processo de decisão sobre ferramentas de monitoramento: coletar preços de fornecedores, limites de planos, recursos, detalhes de documentação e listas de integrações antes de escolher uma plataforma.
Em vez de abrir manualmente mais de 10 páginas de preços de fornecedores, copiar nomes de planos, limites de monitores, intervalos de verificação, integrações e exigências de cartão de crédito para uma planilha, usamos a para extrair dados estruturados das páginas de preços e recursos de cada ferramenta. A IA da Thunderbit lê cada página e sugere campos — nome do plano, detalhes do plano gratuito, preço pago, integrações suportadas — e depois estrutura a saída em uma planilha exportável.
Para fluxos de trabalho de desenvolvedores, a oferece a mesma ideia de forma programática. Use Condensar quando quiser Markdown limpo para LLMs ou RAG. Use Extrair quando precisar de campos específicos em JSON. Use Lote quando precisar processar uma lista de páginas de preços, URLs de documentação, páginas de produto ou páginas de concorrentes e receber os resultados de forma assíncrona.
O fluxo de trabalho:
- Abra a página de preços de um fornecedor (Datadog, Checkly, UptimeRobot etc.)
- Clique em “AI Suggest Fields” — a Thunderbit propõe colunas com base no conteúdo da página
- Clique em “Scrape” — os dados entram em uma tabela estruturada
- Use scraping de subpáginas para acessar páginas de preços, recursos e documentação de cada fornecedor
- Exporte para Google Sheets, Excel, Airtable, Notion ou CSV
Para equipes que trabalham com API primeiro, o fluxo via API é igualmente direto:
- Obtenha uma chave de API gratuita na Thunderbit
- Chame o endpoint Condensar para obter Markdown limpo de qualquer página pública
- Chame o endpoint Extrair com descrições de schema para JSON estruturado
- Use endpoints de Lote e webhooks para listas maiores de URLs
- Envie a saída para seu app, planilha, warehouse, banco vetorial ou fluxo de trabalho de monitoramento
Para uma comparação entre mais de 10 fornecedores, o copy-paste manual pode facilmente levar 2–3 horas quando você inclui subpáginas de preços, documentação e páginas de integrações. A Thunderbit reduziu nossa extração inicial para cerca de 15–30 minutos, com o tempo restante gasto em verificação e decisões de julgamento. Se sua equipe de operações, compras, pesquisa ou produto de IA está avaliando ferramentas sob pressão de tempo, é um atalho prático. Você pode ver mais sobre esse tipo de fluxo no nosso guia de , explorar os ou conferir nosso para tutoriais.
Como escolher a melhor ferramenta de monitoramento de API para sua equipe
A melhor ferramenta de monitoramento de API depende do tamanho da sua equipe, profundidade técnica, orçamento e de como é uma falha para o seu produto.
Um dev solo não precisa de Splunk. Uma empresa regulada não deveria depender de um cron job. Uma equipe de produto de API pode precisar mais de analytics de clientes no estilo Moesif do que de pings de uptime. Uma equipe de e-commerce deve priorizar checagens do caminho crítico para login, busca, adicionar ao carrinho, checkout e autorização de pagamento. Uma equipe de IA ou de dados pode precisar da extração de dados web no estilo Thunderbit antes de precisar de observabilidade completa.
Três princípios que se mantiveram em toda a minha pesquisa:
- Combine a ferramenta com o seu caso de uso. A tabela de seleção rápida existe por um motivo — comece por ela.
- Priorize qualidade de alertas em vez de quantidade. Se sua equipe ignora alertas, você não tem monitoramento. Você tem ruído.
- Não subestime a velocidade de configuração. Um monitor que entra no ar hoje e envia alertas confiáveis é melhor do que um plano de plataforma perfeito que deixa o checkout sem monitoramento por mais um mês.
Se você está comparando várias ferramentas ao mesmo tempo e quer acelerar a pesquisa, experimente a para extrair dados de fornecedores em lote para uma única planilha. Se você está construindo um produto de API, pipeline de RAG, agente de IA ou fluxo de inteligência de mercado que precisa de dados limpos da web, comece com a . Ela não vai escolher a ferramenta de monitoramento para você — mas vai acelerar sua decisão, e ainda pode fornecer ao seu próprio produto uma camada confiável de dados da web.
Perguntas frequentes sobre as melhores ferramentas de monitoramento de API
Qual é a melhor ferramenta gratuita de monitoramento de API em 2026?
Para simplicidade SaaS, o UptimeRobot oferece 50 monitores gratuitos em intervalos de 5 minutos, sem exigir cartão de crédito. Para controle auto-hospedado, o Uptime Kuma é open-source, ilimitado e tem uma interface limpa com mais de 90 serviços de notificação. Para equipes que querem profundidade em métricas e já têm conhecimento técnico, Prometheus + Grafana + Alertmanager é a melhor stack open-source — embora a configuração leve horas, não minutos.
Se o seu objetivo não é monitoramento de uptime, mas extrair dados da web por meio de uma API, a Thunderbit Open API tem um plano gratuito com 600 unidades de API de uso único, suficiente para testar a condensação de páginas em Markdown ou a extração de JSON baseado em schema antes de escalar.
Qual é a diferença entre monitoramento de API e APM?
O monitoramento de API verifica disponibilidade de endpoint, tempo de resposta, erros e correção do lado de fora — ele simula o que um usuário ou integração experimenta. O APM (Application Performance Monitoring) vai mais fundo dentro da aplicação: traces no nível de código, consultas ao banco, erros em runtime, latência de filas e dependências de serviços. Ferramentas como Datadog e New Relic oferecem ambos; UptimeRobot e Uptime Kuma focam em verificações externas de uptime.
A Thunderbit Open API é diferente de ambos: é uma API de extração de dados da web. Ela ajuda você a transformar sites externos em Markdown ou JSON estruturado, o que é útil para apps de LLM, fluxos de pesquisa, inteligência de preços e pipelines de dados.
Com que frequência devo monitorar minhas APIs?
APIs de produção críticas para receita (checkout, autenticação, pagamentos) normalmente devem ser verificadas a cada 1 minuto. APIs internas ou com baixo tráfego podem ser checadas a cada 5 minutos. Mas a frequência sozinha não conta toda a história — use retries, múltiplas regiões e assertions relevantes para que cada verificação seja rápida e confiável. Uma checagem de 1 minuto que dispara falsos alarmes é pior do que uma checagem de 5 minutos em que você confia.
Para fluxos de extração de dados da web, a frequência depende de com que frequência a fonte muda. Páginas de preços podem precisar de extração diária ou semanal. Dados de estoque, viagens ou marketplaces com muita movimentação podem precisar de atualização por hora ou com mais frequência. A API de lote e os webhooks da Thunderbit são úteis quando você precisa processar muitas URLs em uma agenda.
Posso monitorar APIs sem escrever código?
Sim. UptimeRobot, Better Stack e Uptime Kuma podem ser usados inteiramente por GUI. O Checkly suporta configuração por GUI e por código. O Postman usa uma interface baseada em collections. Prometheus/Grafana normalmente exige YAML e PromQL. Datadog e New Relic podem começar com configuração guiada, mas ficam mais poderosos com instrumentação mais profunda.
Se você quiser extrair dados de sites sem escrever código, a extensão do Chrome da Thunderbit é o caminho no-code. Se quiser automatizar esse mesmo fluxo a partir de uma aplicação, a oferece aos desenvolvedores endpoints de Condensar, Extrair e Lote.
Como reduzo a fadiga de alertas do monitoramento de API?
Escolha ferramentas com alertas inteligentes: detecção de anomalias (Datadog, New Relic), retry antes do disparo (Checkly), anomalias comportamentais (Moesif) ou agrupamento/silenciamento (Prometheus Alertmanager). Comece com menos alertas, mas com maior confiança, focados no impacto visível ao usuário. Use alertas por burn rate de SLO em vez de limiares estáticos, deduplicate entre serviços, roteie por responsabilidade e meça a acionabilidade — se menos de 20% dos alertas levam a ações reais, reduza o ruído primeiro.
Saiba mais