
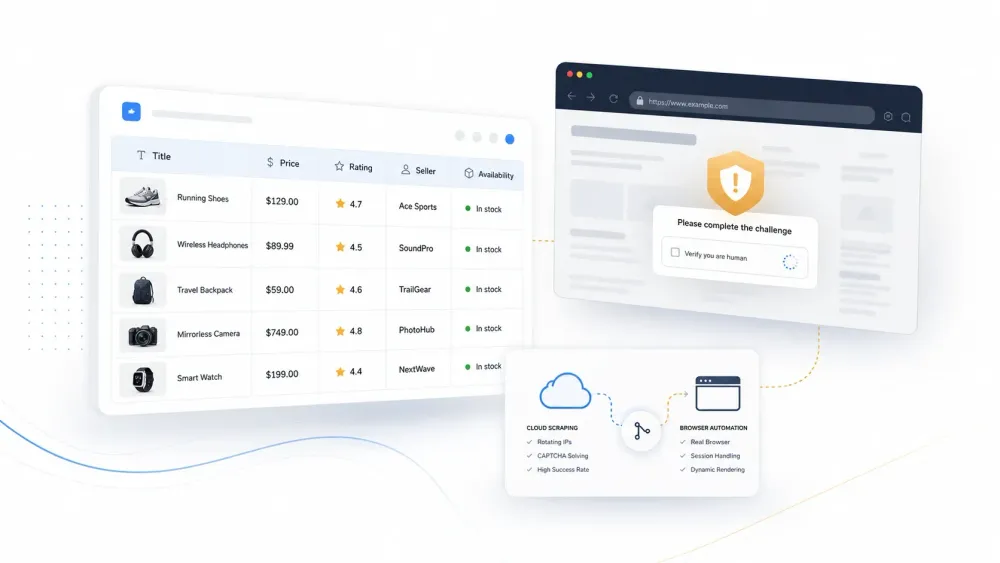
Na demo do produto, todo AI web scraper parece coisa de outro mundo. O problema é o que vem depois: você aponta a ferramenta para um site real protegido pela Cloudflare, ela recebe uma página de desafio de volta e, mesmo assim, garante com a maior tranquilidade que encontrou 47 anúncios de produtos.
Passei os últimos meses avaliando ferramentas de scraping para a nossa equipe na Thunderbit. Essa distância entre o que a demo mostra e o que aguenta em produção é, quase sempre, a maior dor de cabeça que vejo nas comunidades. Um usuário do Reddit resumiu numa frase: "O que segura em produção e o que só roda numa demo antes de morrer duas semanas depois?" Com 31 produtos listados no Capterra só na categoria de web scraping, fora dezenas de extensões para Chrome, provedores de API e marketplaces de actors, o paradoxo da escolha é real. Por isso, testei 12 deles.
Este artigo avalia 12 ferramentas de AI web scraper com critérios de produção: enfrentamento de anti-bot, escalabilidade, qualidade da saída estruturada, eficiência de custo, suporte a sites dinâmicos e flexibilidade para quem programa. Nada de lista de funcionalidades. Nada de captura de tela de marketing. Só o que realmente funciona quando a demo acaba.
Veja como é um AI Web Scraper pronto para produção
Por que a maioria dos AI Web Scrapers desanda depois da demo
O roteiro é sempre o mesmo. O site de marketing da ferramenta exibe a extração de colunas limpinhas numa página simples de listagem de produtos. Você instala, testa num e-commerce com proteção e recebe um destes resultados:
- Uma resposta
200 OKcom uma página de desafio da Cloudflare no lugar dos dados reais - Resultados limpos nas primeiras 5 páginas e, depois, falhas silenciosas ou linhas inventadas
- Extração perfeita hoje, seletores quebrados na semana seguinte por causa de uma atualizaçãozinha de layout
Isso não é exceção. É a regra.
Como disse um profissional no Reddit: "O scraper devolve um 200 com uma página de desafio da Cloudflare, seu agente tenta raciocinar em cima disso, inventa respostas e você nem sabe por quê."
O problema, no fundo, é de arquitetura. A maioria das demos mostra a camada de parsing em páginas públicas e limpas, mas o trabalho de verdade trava na camada de coleta. Os sites de produção adicionam proteção contra bots, renderização dinâmica, páginas internas aninhadas, scroll infinito, estado de login, variação de localidade e mudanças de layout.
Uma ferramenta pode parecer fantástica num tour de produto e ainda assim desmoronar no primeiro fluxo de trabalho sério de um cliente.
É por isso que este artigo avalia cada ferramenta sob a ótica da prontidão para produção, e não por uma lista de funcionalidades. Os seis critérios que usei foram:
| Critério | Por que importa |
|---|---|
| Enfrentamento de anti-bot/CAPTCHA | Sites protegidos travam antes mesmo de a qualidade da extração entrar em jogo |
| Escalabilidade além da demo | Jobs em lote e execuções paralelas escancaram os limites operacionais |
| Qualidade da saída estruturada | O usuário precisa de JSON/CSV limpo, não de HTML bruto para limpar na mão |
| Eficiência de tokens/custo | A extração com IA pode sair mais cara do que o próprio scraping |
| Suporte a sites dinâmicos/pesados em JS | As páginas de hoje exigem DOMs renderizados, não HTML estático |
| Flexibilidade sem código x API | Times de vendas e engenheiros de dados têm necessidades diferentes |
Se quiser uma visão geral rápida de como o web scraping mudou nos últimos dois anos, esta palestra da Browserless é um bom ponto de partida antes de comparar as ferramentas uma a uma.
Onde a IA realmente ajuda num pipeline de scraping — e onde não ajuda
Um mito que insiste em sobreviver nesse mercado é que "AI web scraper" significa que a IA faz tudo do início ao fim. O consenso da comunidade é surpreendentemente claro: scraper primeiro, LLM depois. Como resumiu um usuário, sem rodeios: "Você usa IA para ler uma captura de tela de uma página web. Não usa IA para programar o scraper em si."
O pipeline de scraping tem três camadas distintas, e o valor da IA muda bastante de uma para a outra:
Rastreamento e coleta: a camada de infraestrutura
É aqui que as requisições acontecem: proxies, navegadores headless, gestão de sessão, resolução de CAPTCHA, novas tentativas. A IA quase não agrega nada nessa parte. Você continua precisando de pools de proxy, fingerprinting de navegador e infraestrutura de desbloqueio. É nesta camada que a maioria das ferramentas tropeça primeiro em produção.
Parsing e extração: onde a IA brilha
Com o conteúdo limpo da página em mãos, a IA é excelente para transformar HTML não estruturado em campos organizados. Extração baseada em esquema, detecção adaptativa de campos e tratamento de variações de layout sem seletores XPath frágeis: esse é o ponto forte da IA no scraping.
Pós-processamento: rotulagem, tradução, categorização
Depois da extração, a IA agrega valor categorizando produtos, traduzindo texto, padronizando números de telefone ou resumindo descrições. Combinação ótima — mas só se os dados extraídos já estiverem corretos.
Veja como as 12 ferramentas se encaixam nessas camadas:
| Ferramenta | Rastreamento/Coleta | Parsing/Extração | Pós-processamento | Resumindo |
|---|---|---|---|---|
| Thunderbit | Forte | Forte | Forte | AI scraper completo sem código |
| Octoparse | Forte | Médio | Baixo | Scraper visual baseado em regras com infraestrutura na nuvem |
| Browse AI | Médio | Médio | Médio | Plataforma de robôs na nuvem focada em monitoramento |
| Firecrawl | Médio | Forte | Baixo-Médio | API de extração para quem programa |
| Apify | Forte | Médio-Forte | Médio | Marketplace de actors e orquestração |
| Gumloop | Médio | Médio | Forte | Automação de fluxos com nós de scraping |
| Bright Data | Muito forte | Médio | Baixo-Médio | Stack de infraestrutura enterprise |
| Bardeen | Médio | Médio | Forte | Automação de navegador para fluxos de GTM |
| Diffbot | Baixo-Médio | Muito forte | Médio | Extração pré-treinada com grafo de conhecimento |
| ScrapingBee | Forte | Baixo-Médio | Baixo | API de coleta e desbloqueio |
| Instant Data Scraper | Baixo | Médio (páginas simples) | Baixo | Scraper rápido heurístico no navegador |
| ParseHub | Médio | Médio | Baixo | Scraper visual de desktop para interações complexas |
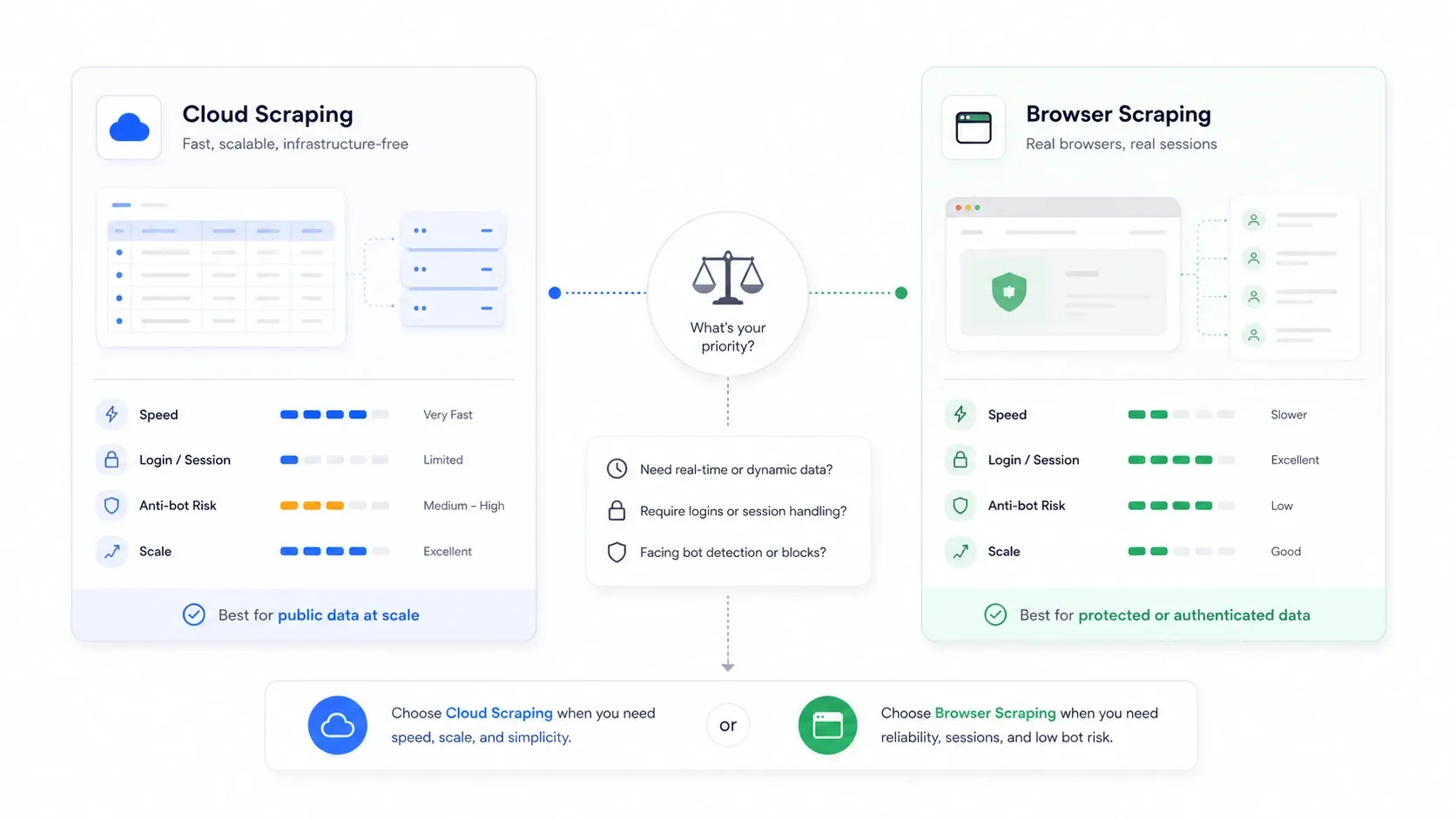
Scraping na nuvem x scraping no navegador: a escolha que ninguém explica
Essa é a decisão de arquitetura que a maioria dos artigos de comparação ignora por completo — e que, muitas vezes, pesa mais do que a ferramenta escolhida.
Scraping na nuvem quer dizer que servidores remotos fazem o trabalho de coleta por você. Scraping no navegador quer dizer que a extração acontece na sua própria sessão de navegador, usando seus cookies, seu IP e seu estado autenticado.
| Cenário | Modo ideal | Por quê |
|---|---|---|
| Sites públicos de e-commerce e listagens em volume | Nuvem | Mais paralelismo e sem o gargalo da máquina local |
| Sites que exigem login ou autenticação | Navegador | Reaproveita seus cookies reais de sessão |
| Sites que penalizam IPs de datacenter | Navegador | Passa por tráfego normal de usuário |
| Jobs grandes e recorrentes de monitoramento | Nuvem | Agendamento e continuidade mais simples |
| Jobs únicos, frágeis e sensíveis a anti-bot | Navegador | Mais fácil inspecionar o que o site renderizou de fato |
E isso também conta do ponto de vista do bolso. O relatório State of Web Scraping 2026 da Apify mostrou que 65,8% dos profissionais aumentaram o uso de proxies na comparação ano a ano, e mais de 62% relataram alta nas despesas de infraestrutura. Anti-bot não é só um problema técnico. É um problema de orçamento.
A maioria das ferramentas oferece só um modo. Olha como fica o panorama:
| Ferramenta | Nuvem | Navegador | Ambos |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (local) | ✅ |
| Browse AI | ✅ | Apenas configuração | — |
| Firecrawl | ✅ | API para interativo | — |
| Apify | ✅ | ✅ (via actors) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Limitado (páginas públicas) | ✅ | Parcial |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (pago) | ✅ (desktop) | ✅ |
As 12 AI Web Scrapers em resumo
Aqui está a comparação principal entre as 12 ferramentas:
| Ferramenta | Melhor para | Plano gratuito | Nuvem/Navegador | Acesso à API | Scraping agendado | Enfrentamento de anti-bot |
|---|---|---|---|---|---|---|
| Thunderbit | Times não técnicos | ✅ (6 páginas) | Ambos | ✅ | ✅ | Forte |
| Octoparse | Scraping com muitos templates | ✅ (limitado) | Ambos | ✅ | ✅ | Moderado-Forte |
| Browse AI | Monitorar mudanças | ✅ (limitado) | Principalmente nuvem | ✅ | ✅ | Moderado |
| Firecrawl | Pipelines de extração para devs | ✅ (1.000 créditos/mês) | Nuvem mais API de navegador | ✅ | Não | Moderado |
| Apify | Times de devs com marketplace | ✅ (US$ 5 em uso grátis) | Ambos | ✅ | ✅ | Forte com complementos |
| Gumloop | Automação de fluxos | ✅ (5.000 créditos/mês) | Ambos | ✅ | ✅ | Médio |
| Bright Data | Acesso a dados enterprise | Teste / créditos | Ambos | ✅ | Externo | Muito forte |
| Bardeen | Automação de navegador para vendas e operações | ✅ (100 créditos) | Primeiro navegador | Limitado | ✅ | Médio-Baixo |
| Diffbot | APIs de extração estruturada | ✅ (10.000 créditos) | Nuvem | ✅ | Não | Baixo na coleta / alto na extração |
| ScrapingBee | Coleta e desbloqueio para devs | ✅ (1.000 créditos) | Nuvem | ✅ | Não | Forte |
| Instant Data Scraper | Scrapes únicos e gratuitos | ✅ (totalmente grátis) | Apenas navegador | Não | Não | Baixo |
| ParseHub | Fluxos visuais complexos | ✅ (5 projetos) | Desktop mais nuvem | ✅ | ✅ (pago) | Médio |
Entenda como a extração com IA se encaixa num pipeline real de scraping
1. Thunderbit
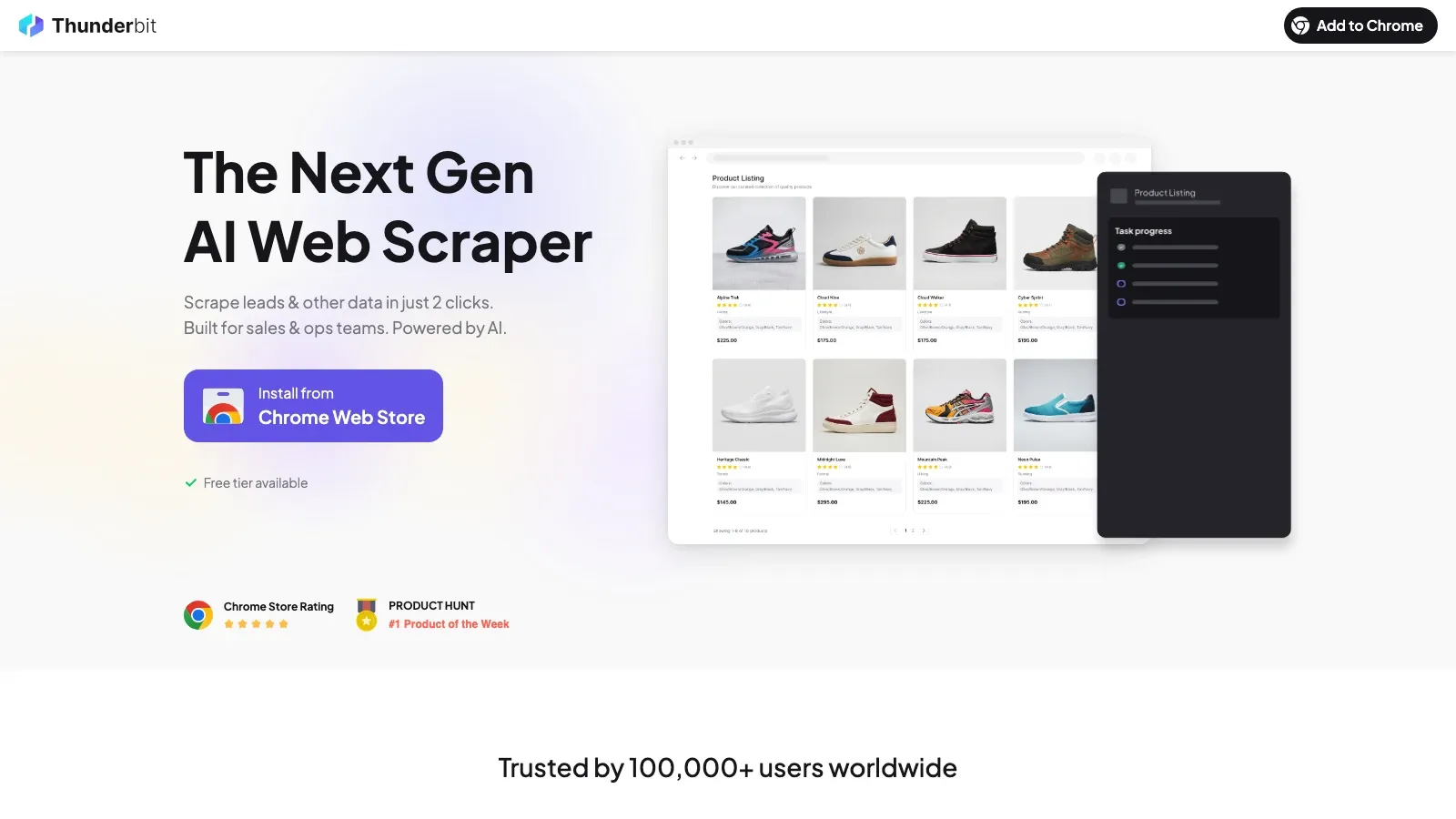
A Thunderbit é o AI web scraper que criamos pensando exatamente nos times não técnicos que precisam de dados com qualidade de produção sem escrever código nem cuidar de infraestrutura. O fluxo principal cabe em dois cliques mesmo: AI Suggest Fields lê a página e propõe as colunas, depois Scrape executa a extração em modo nuvem ou navegador.
O que a separa de outros scrapers sem código é a arquitetura. A Thunderbit isola as questões de coleta — como infraestrutura na nuvem, rotação de proxy, enfrentamento de anti-bot e renderização de JavaScript — da extração com IA, que lê o HTML e monta as colunas estruturadas. Isso bate com o padrão que os especialistas recomendam, "scraper primeiro, LLM depois", mas empacotado num fluxo de extensão do Chrome que representante de vendas e gestor de operações conseguem usar de verdade.
Principais pontos fortes
- Scraping na nuvem e no navegador na mesma interface. Alterne entre os modos conforme o site seja público ou exija sua sessão autenticada. O modo nuvem processa até 50 páginas em paralelo.
- A IA relê a estrutura da página a cada execução. Sem manutenção de XPath. Quando um site muda o layout, a Thunderbit se ajusta sozinha na execução seguinte.
- Scraping de subpáginas. A IA visita as páginas de detalhe ligadas e enriquece a tabela principal sem configuração manual.
- Field AI Prompts. Rotulagem, tradução e categorização personalizadas durante a própria extração, em vez de uma etapa separada de pós-processamento.
- Exportações grátis para Google Sheets, Excel, Airtable e Notion.
- Modelos de scraper instantâneos para sites populares como Amazon, Zillow e LinkedIn.
- Agendamento em linguagem natural. Diga "extrair toda segunda-feira às 9h" e ele converte isso num agendamento recorrente.
- API aberta com endpoints Distill e Extract, processamento em lote de até 100 URLs e concorrência publicada de 2 no plano grátis a 50 no Pro 1.
Onde dá pra melhorar
- O plano gratuito é limitado de propósito.
- A experiência sem código gira em torno da extensão do Chrome. Quem programa e quer fluxos só via API precisa usar a Open API à parte.
- Não é a ferramenta certa se a sua necessidade principal for só infraestrutura bruta de proxy, sem extração.
Preços
Plano gratuito disponível. Os planos sem código começam em US$ 9/mês na cobrança anual ou US$ 15/mês na cobrança mensal para o Starter. O preço da API é separado: uso único grátis de 600 unidades, depois US$ 16/mês na cobrança anual para o Starter API e US$ 40/mês na cobrança anual para o Pro 1 API. Veja preços da Thunderbit e preços da API.
Melhor para: times de vendas, e-commerce e operações que precisam de dados web estruturados sem depender da engenharia.
2. Octoparse
A Octoparse é um construtor visual de fluxos para web scraping com uma biblioteca grande de modelos prontos. Já está no mercado há tempo suficiente para ter uma infraestrutura de nuvem madura e lida bem com paginação em sites estruturados e previsíveis.
Principais pontos fortes
- Biblioteca extensa de templates de scraping para sites populares
- Extração na nuvem com execuções agendadas
- Rotação de IP e resolução de CAPTCHA como complementos pagos
- Acesso à API nos planos superiores
Onde dá pra melhorar
- Os recursos de IA são mais leves do que os de ferramentas nativas de LLM. A sugestão de campos ainda depende mais de templates do que de leitura adaptativa.
- Layouts complexos ou fora do comum exigem bastante ajuste manual no editor visual.
- A curva de aprendizado sobe quando você precisa de lógica condicional ou de driblar bloqueios.
Preços
Há um plano gratuito para sempre. A central oficial de ajuda hoje indica preços de Standard a partir de US$ 75/mês na cobrança anual e Professional a partir de US$ 208/mês na cobrança anual, enquanto algumas páginas localizadas e caminhos de upgrade mostram equivalentes mensais mais altos. O ponto importante é que o preço da Octoparse agora mistura planos de assinatura com complementos pagos, como proxies residenciais e resolução de CAPTCHA.
Melhor para: analistas e times de operações que extraem sites estruturados e amigos de templates em escala moderada.
3. Browse AI
A Browse AI é uma plataforma sem código baseada na nuvem, feita principalmente para monitorar mudanças em sites ao longo do tempo, como preços da concorrência, disponibilidade de estoque e atualizações de conteúdo. O scraping faz parte do produto, mas o verdadeiro diferencial é o sistema recorrente de monitoramento e alertas.
Principais pontos fortes
- Detecção de mudanças e alertas integrados
- Gravador de robôs sem código com configuração ponto a ponto
- Robôs prontos para sites populares
- Suporte a proxies premium nos planos superiores
Onde dá pra melhorar
- O modelo de preços por créditos encarece rápido quando você monitora páginas de detalhe em escala
- É menos atraente para extração única em grande volume do que ferramentas API-first
- Enfrentamento de anti-bot moderado; alguns sites ainda exigem proxies premium ou contornos
Preços
Conta gratuita disponível. Os planos pagos começam em torno de US$ 19/mês na cobrança anual para o Starter, com níveis mais altos de créditos e monitoramento acima disso.
Melhor para: times que precisam monitorar continuamente preços da concorrência, mudanças de conteúdo ou níveis de estoque, em vez de fazer extrações em massa de uma vez só.
4. Firecrawl
A Firecrawl é uma API pensada primeiro para quem programa, que converte páginas web em Markdown limpo ou JSON estruturado. Ela mora principalmente na camada de extração e é excelente para times que estão montando pipelines de RAG ou alimentando LLMs com conteúdo web.
Principais pontos fortes
- Ótima qualidade de saída em Markdown para fluxos de LLM posteriores
- API limpa com ações de scrape, crawl, map, search, extract e browser
- Suporte a processamento em lote
- Concorrência de 2 no plano gratuito a 100 no Growth
Onde dá pra melhorar
- Não tem interface sem código e exige conhecimento de desenvolvimento
- Há suporte integrado a proxy e anti-bot, mas a Firecrawl não se posiciona como provedor dedicado de desbloqueio
- Não tem agendador nativo para jobs recorrentes
- Não é custo-eficiente para quem não programa e só quer uma planilha de dados
Preços
O plano gratuito inclui 1.000 créditos por mês. Os planos pagos começam em US$ 16/mês na cobrança anual para o Hobby e sobem com mais créditos, concorrência e uso de navegador. As sessões de navegador são cobradas à parte em créditos.
Melhor para: quem programa e constrói pipelines de LLM, sistemas de RAG ou fluxos de extração personalizados que precisam de Markdown ou JSON limpos a partir de páginas web.
5. Apify
A Apify é uma plataforma com um marketplace de actors prontos para scraping e ferramentas para criar os seus próprios. Pense nela como uma camada de orquestração em que você escolhe ou monta scrapers especializados para sites específicos e depois os agenda e gerencia por uma API unificada.
Principais pontos fortes
- Marketplace gigante de actors com scrapers criados pela comunidade para centenas de sites
- API e SDK robustos para quem programa
- Gestão de proxies e agendamento integrados
- Integra com muitas ferramentas downstream
Onde dá pra melhorar
- O "sem código" só vale em parte; quando você sai do marketplace e precisa de lógica personalizada, a história muda
- A confiabilidade dos actors depende da manutenção feita pela comunidade
- O preço pode subir porque os custos de compute, actors e proxies vão se acumulando
Preços
O plano gratuito inclui US$ 5 em créditos mensais da plataforma. Os planos pagos começam em US$ 39/mês para o Starter, com níveis voltados a escala acima disso.
Melhor para: times de desenvolvimento que querem fluxos de scraping reutilizáveis e agendáveis com um grande ecossistema de soluções prontas.
6. Gumloop
A Gumloop é uma plataforma de automação de fluxos sem código que traz um nó de web scraping. O valor de verdade não está só no scraping. Está em ligar a extração a LLMs, Google Sheets, CRMs e outras ferramentas dentro de uma única interface visual.
Principais pontos fortes
- Construtor visual de fluxos por arrastar e soltar
- Integra scraping com LLMs e ferramentas de negócio downstream num único fluxo
- O plano gratuito hoje é anunciado com 5.000 créditos/mês
- Agendamento por tempo para fluxos recorrentes
- Os modos básicos de scraping e o Web Agent interativo cobrem fluxos simples e mais elaborados
Onde dá pra melhorar
- O motor de scraping é menos robusto do que o de ferramentas dedicadas de AI web scraper
- Menor profundidade de anti-bot e proxy na comparação com provedores especializados
- Limites de concorrência e acionamento são mais apertados nos planos gratuitos
- Não é ideal quando o caso de uso principal é scraping de altíssimo volume
Preços
Plano gratuito disponível. A Gumloop unificou a antiga estrutura Solo e Team num plano Pro no fim de 2025, e a comunicação pública desde então gira em torno de créditos gratuitos mais generosos e níveis pagos consolidados, em vez de preços centrados em scraping.
Melhor para: times que querem o scraping como uma etapa de um fluxo de automação maior: extrair, analisar e mandar para ferramentas de negócio.
Se quiser ver como um fluxo de extração nativo de IA funciona na prática antes de ler o resto da lista, este tutorial da Thunderbit é a demonstração de produto mais relevante para times não técnicos.
7. Bright Data
A Bright Data é a stack de infraestrutura de nível enterprise desta lista. Se o seu problema é "não consigo furar a proteção contra bots deste site, faça o que fizer", a Bright Data provavelmente é a resposta — mas vem com a complexidade e o preço de uma solução enterprise.
Principais pontos fortes
- Rede de proxies líder do setor com IPs residenciais, de datacenter e móveis
- Web Unlocker para anti-bot e bypass de CAPTCHA
- Scraping Browser com desbloqueio embutido
- Conjuntos de dados pré-coletados disponíveis para compra
- Controle programático completo via API e SDK
Onde dá pra melhorar
- Não foi desenhada para quem não é técnico
- O preço reflete o posicionamento enterprise
- A extração com IA não é o principal motivo para comprar a plataforma
Preços
A Browser API começa em US$ 8/GB no modelo pay as you go, com tarifas menores por GB em compromissos mensais maiores. Outros produtos da Bright Data, como Unlocker, Scraper APIs, datasets e pools de proxies, usam unidades de preço diferentes.
Melhor para: times de dados enterprise que precisam extrair sites fortemente protegidos em escala e têm pessoal técnico para cuidar da infraestrutura.
8. Bardeen
A Bardeen é uma ferramenta de automação de navegador focada em cliques, preenchimento de formulários e scraping, com extração de dados turbinada por IA por cima. Faz mais sentido entendê-la como uma ferramenta de workflow de GTM que também faz scraping — e não o contrário.
Principais pontos fortes
- Automação intuitiva no estilo playbook, com scraping como uma das etapas
- Scrapers oficiais mantidos pela própria equipe da Bardeen para sites populares
- Integrações fortes com CRM, Google Sheets, Slack e outras ferramentas de negócio
- Boa opção para scraping de leads, enriquecimento e exportação para o CRM
Onde dá pra melhorar
- A arquitetura centrada no navegador limita o scraping em alto volume e sem supervisão
- O scraping na nuvem só funciona em páginas públicas, não em páginas com acesso restrito
- O enfrentamento de anti-bot é basicamente o que a sua sessão de navegador já oferece
- A extração com IA pode patinar com layouts complexos ou fora do padrão
Preços
O plano gratuito inclui 100 créditos mensais. A documentação pública de suporte menciona o antigo preço Pro de US$ 15/mês para usuários existentes, enquanto a embalagem comercial atual da Bardeen está mais voltada a enterprise e workflows do que ao preço clássico de scraper de baixo custo.
Melhor para: times de vendas e operações que precisam de scraping como parte de um fluxo maior de automação no navegador.
9. Diffbot
A Diffbot usa visão computacional e NLP para ler páginas web como um humano, gerando dados estruturados para artigos, produtos, discussões e organizações. É uma das APIs de extração de mais alta qualidade que existem — se as suas páginas se encaixarem nos modelos pré-treinados.
Principais pontos fortes
- Modelos de extração pré-treinados para artigos, produtos, discussões e mais
- Knowledge Graph com bilhões de entidades para enriquecimento de dados
- Alta qualidade de saída estruturada nos tipos de página suportados
- API clara para quem programa, com limites de taxa publicados
Onde dá pra melhorar
- Não tem interface sem código
- Não tem crawling integrado, gestão de proxy nem enfrentamento de anti-bot
- É cara para times pequenos
- Menos flexível em tipos de página fora do padrão do que extratores baseados em prompts e esquemas
Preços
O plano gratuito inclui 10.000 créditos. O Startup custa US$ 299/mês por 250.000 créditos, e o Plus custa US$ 899/mês por 1.000.000 de créditos.
Melhor para: times de desenvolvimento que precisam de extração estruturada de alta precisão em tipos de página padrão e topam cuidar da coleta à parte.
10. ScrapingBee
A ScrapingBee é uma API de web scraping focada na camada de coleta e desbloqueio. Você manda uma URL, ela cuida dos proxies, da renderização em navegador headless e das defesas anti-bot, e devolve HTML ou, opcionalmente, os dados já extraídos.
Principais pontos fortes
- Rotação de proxy e enfrentamento de anti-bot integrados
- Suporte a renderização JavaScript
- API REST simples
- Endpoint para scraping da Busca do Google
- Concorrência publicada por plano
Onde dá pra melhorar
- Os recursos de extração com IA são limitados
- Não tem interface sem código
- Não tem agendamento nem monitoramento integrados
- Uma resposta
200com uma página bloqueada ainda pode contar como requisição bem-sucedida
Preços
O plano gratuito inclui 1.000 créditos de API. Os planos pagos começam em US$ 49/mês e sobem com mais concorrência e volume de requisições.
Melhor para: quem programa e precisa sobretudo de uma coleta confiável de páginas depois das defesas anti-bot, deixando a extração para o próprio código ou para outra ferramenta.
11. Instant Data Scraper
A Instant Data Scraper é uma extensão gratuita do Chrome com mais de 1.000.000 de usuários que detecta automaticamente padrões de dados numa página e deixa você exportar para CSV ou Excel. Não há sugestão de campos por IA no sentido de LLM. Ela usa detecção heurística de padrões.
Principais pontos fortes
- Totalmente gratuita, sem precisar de conta
- Detecção de dados com um clique em muitas páginas de listagem e tabelas
- Dá conta de paginação em alguns sites
- Barreira de entrada baixíssima
- Continua sendo mantida, com atualizações na Chrome Web Store em 2026
Onde dá pra melhorar
- Não tem sugestão de campos nem rotulagem de dados por IA
- Não tem scraping na nuvem, agendamento nem API
- Patina com layouts complexos, conteúdo dinâmico e sites pesados em JS
- Não há enfrentamento de anti-bot além do que o navegador já carrega
- A exportação se limita a CSV e Excel
Preços
Grátis. Para sempre.
Melhor para: quem precisa de um scrape rápido e único de uma página de listagem simples e não quer criar conta nem pagar nada.
12. ParseHub
A ParseHub é um aplicativo de desktop com interface visual de apontar e clicar para criar projetos de scraping. Dá conta de dados aninhados complexos, conteúdo carregado por AJAX, scroll infinito e interações com menus suspensos que extensões mais simples costumam deixar passar.
Principais pontos fortes
- Interface visual de seletores para definir regras de extração
- Lida com dados aninhados, menus suspensos, scroll infinito e conteúdo AJAX
- Plano gratuito com até 5 projetos
- Exporta para JSON, CSV e Excel
- Agendamento na nuvem e rotação de IP nos planos pagos
Onde dá pra melhorar
- Fluxo só para desktop, sem a praticidade da extensão de navegador
- Execução mais lenta do que ferramentas nativas de nuvem
- Os projetos quebram quando o layout do site muda, porque não existe uma camada de releitura por IA
- Capacidades limitadas de IA e um ar mais legado de scraper visual
Preços
Plano gratuito disponível com 5 projetos e 200 páginas por execução. Os planos pagos começam em US$ 189/mês com agendamento, rotação de IP e limites maiores.
Melhor para: quem não é técnico, precisa extrair sites interativos complexos e topa investir tempo na configuração visual do fluxo.
Como começar com um AI Web Scraper em 5 passos
Cada ferramenta desta lista tem um fluxo de onboarding diferente. Vou usar a Thunderbit como exemplo concreto porque é a que melhor responde à intenção de busca "quero só que isto funcione numa página real".
Passo 1: Instale e navegue
Instale a extensão Thunderbit para Chrome e vá até a página que quer extrair: uma listagem de produtos, um diretório ou um portal imobiliário.
Passo 2: Deixe a IA sugerir os campos de dados
Clique em AI Suggest Fields. A IA lê a página atual e propõe nomes de colunas e tipos de dados. Numa página de produtos, ela pode sugerir Nome do Produto, Preço, Avaliação, URL da Imagem e Descrição.
Passo 3: Personalize os campos com prompts de IA
Ajuste as colunas se os padrões não estiverem 100% certos. Adicione Field AI Prompts para transformações personalizadas, como "traduzir a descrição para espanhol", "categorizar como Eletrônicos, Casa ou Moda" ou "extrair apenas o preço numérico".
Passo 4: Escolha o modo nuvem ou navegador e extraia
Selecione o scraping na nuvem para sites públicos ou o scraping no navegador para alvos autenticados ou muito protegidos. Depois clique em Scrape.
Passo 5: Exporte seus dados para onde quiser
Exporte os resultados para Google Sheets, Excel, Airtable ou Notion. As exportações são gratuitas.
E se o layout do site mudar?
Essa é a maior vantagem de produção dos extratores nativos de IA sobre as ferramentas baseadas em regras. Scrapers tradicionais, como o ParseHub e fluxos antigos do Octoparse, dependem de seletores XPath ou caminhos CSS. Quando um site muda a estrutura HTML, esses seletores quebram e você volta à reconfiguração manual.
Extratores com IA, como a Thunderbit, releem a estrutura da página a cada execução. Isso significa zero manutenção de XPath e zero seletores frágeis. A IA se adapta sozinha às mudanças de layout na execução seguinte.
Scraping agendado e acesso à API: os recursos avançados que ninguém analisa
Scrapes pontuais servem bem para pesquisa. Casos de uso em produção, como monitoramento de preços, atualização de listas de leads e acompanhamento de estoque, exigem extração recorrente e acesso programático. Esses recursos separam brinquedo de ferramenta.
Suporte a agendamento
| Ferramenta | Agendamento nativo | Observações |
|---|---|---|
| Thunderbit | ✅ | Configuração em linguagem natural |
| Octoparse | ✅ | Execuções agendadas na nuvem |
| Browse AI | ✅ | Recurso central do produto |
| Firecrawl | ❌ | Use cron externo |
| Apify | ✅ | Expressões cron completas |
| Gumloop | ✅ | Gatilhos de workflow por tempo |
| Bright Data | Externo | Em geral orquestrado pelos sistemas do cliente |
| Bardeen | ✅ | Agendamento de playbooks |
| Diffbot | ❌ | API-first, orquestração externa |
| ScrapingBee | ❌ | Apenas API |
| Instant Data Scraper | ❌ | Ferramenta manual de navegador |
| ParseHub | ✅ (pago) | Recurso premium |
Comparação de API para quem programa
| Ferramenta | Sinal de concorrência ou taxa | Modelo de preço |
|---|---|---|
| Thunderbit | 2 → 50 concorrentes | Baseado em créditos |
| Firecrawl | 2 → 100 concorrentes | Baseado em créditos |
| Apify | Depende do plano | Unidades de compute |
| Gumloop | Concorrência de workflow limitada pelo plano | Baseado em créditos |
| Diffbot | 5 chamadas/min → 25 chamadas/seg | Baseado em créditos |
| ScrapingBee | 10 → 200 concorrentes | Créditos de API |
| Bright Data | A Browser API anuncia requisições simultâneas ilimitadas | Baseado em GB |
Se o seu caso de uso for mais técnico e você estiver tentando decidir quanta infraestrutura quer assumir, este guia prático sobre Firecrawl é um complemento útil e mão na massa às comparações de produto acima.
Como escolher o AI Web Scraper certo
Depois de testar as 12 ferramentas, eu decidiria assim:
- Time não técnico que precisa de dados rápido: comece com a Thunderbit. O fluxo de dois cliques, as exportações gratuitas e o alternador navegador-nuvem cobrem a maior parte das necessidades de scraping de negócio sem apoio de engenharia.
- Precisa de monitoramento e alertas contínuos: a Browse AI foi feita pra isso. Não é a melhor extratora única, mas a detecção de mudanças é de primeira linha.
- Quem programa e está montando um pipeline de LLM: Firecrawl para extração em Markdown ou JSON, ou Diffbot para extração estruturada pré-treinada. Combine qualquer uma delas com ScrapingBee ou Bright Data se precisar de enfrentamento sério de anti-bot na camada de coleta.
- Precisa de um marketplace de scrapers prontos: a Apify tem o maior ecossistema de actors. Só esteja preparado para manutenção quando os actors falharem.
- Alvos enterprise com proteção pesada: Bright Data. Nada se compara à infraestrutura de proxy dela, mas ajuste orçamento e equipe técnica de acordo.
- Quer scraping como parte de uma automação maior: Gumloop ou Bardeen, dependendo de você estar automatizando fluxos ou tarefas de GTM baseadas no navegador.
- Só precisa de um scrape grátis e rápido: Instant Data Scraper. Zero configuração, zero custo, zero complexidade — mas também zero agendamento, zero IA e zero nuvem.
- Sites interativos complexos com menus suspensos e AJAX: o ParseHub ainda dá conta disso melhor do que a maioria das extensões, mesmo com um custo de manutenção real.
Teste a Thunderbit numa página real antes de investir numa stack maior
Conclusão
O mercado de AI web scraper em 2026 está abarrotado de ferramentas que impressionam nas demos e decepcionam em produção. A distância entre "funciona numa captura de marketing" e "funciona num e-commerce protegido às 3 da manhã, dentro de um agendamento" é onde a maioria dos compradores perde tempo e dinheiro.
A grande conclusão depois de avaliar as 12 ferramentas é simples: a camada de coleta continua sendo a parte difícil. A IA brilha na extração e no pós-processamento, mas não substitui infraestrutura de proxy, enfrentamento de anti-bot ou gestão de sessão. As melhores ferramentas resolvem as duas camadas, como a Thunderbit e a Bright Data, ou deixam claro qual camada cobrem, como a Firecrawl na extração e a ScrapingBee na coleta.
Se quiser ver como é um AI web scraper pronto para produção sem escrever código, experimente a Thunderbit. O plano gratuito já basta para testar o fluxo completo em páginas reais. Se as suas necessidades forem mais voltadas a desenvolvimento, combine uma API de extração com um serviço dedicado de coleta e poupe-se da frustração de esperar que uma única ferramenta faça tudo.
FAQs
Por que a maioria dos AI web scrapers falha em sites reais depois de ir tão bem nas demos?
As demos costumam mostrar a extração em páginas limpas e sem proteção. Os sites reais somam proteção da Cloudflare, renderização dinâmica em JavaScript, paginação, exigência de login e mudanças frequentes de layout. A maioria das ferramentas vai bem na camada de parsing e extração, mas não tem infraestrutura robusta na camada de coleta.
Qual é a diferença entre scraping na nuvem e scraping no navegador, e quando usar cada um?
O scraping na nuvem usa servidores remotos para coletar as páginas, o que é mais rápido, paralelo e escalável. O scraping no navegador roda na sua própria sessão e é melhor para sites autenticados ou com detecção agressiva de bots. A Thunderbit é uma das poucas ferramentas que oferece os dois modos na mesma interface.
Posso usar um AI web scraper para tarefas recorrentes, como monitoramento de preços?
Sim, mas só se a ferramenta suportar scraping agendado. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen e ParseHub nos planos pagos oferecem agendamento.
Qual AI web scraper é melhor se eu não sei programar?
A Thunderbit oferece o caminho mais rápido até dados úteis para quem não é técnico. O Instant Data Scraper é totalmente gratuito, mas limitado a páginas simples. Browse AI e Octoparse trazem interfaces visuais com mais configuração. O ParseHub é poderoso para sites interativos complexos, mas tem uma curva de aprendizado mais íngreme.
Quanto custa, na prática, o scraping com IA em nível de produção?
A faixa é ampla. O Instant Data Scraper é gratuito. Thunderbit, Firecrawl e Browse AI oferecem pontos de entrada gratuitos com planos pagos de baixo custo. Ferramentas intermediárias como Octoparse, ParseHub e ScrapingBee podem ir de cerca de US$ 49 a US$ 189 por mês. Soluções enterprise como Bright Data e Diffbot começam bem acima disso.




