Deixa eu te contar como tudo começou na minha vida de raspagem de dados. Volta lá para 2015: eu, num apê apertado em Nova Jersey, já na terceira xícara de café, tentando domar um script Python que vivia dando pau toda vez que o site mudava o layout. As armas do momento? Beautiful Soup e Selenium. Agora, corta para 2025: a discussão sobre “beautiful soup vs selenium” segue firme, mas o cenário mudou completamente graças à inteligência artificial — algo que eu nem sonhava naquela época. Hoje, as ferramentas não só leem HTML, mas entendem o conteúdo, navegam por links como gente, extraem dados estruturados com comandos em linguagem natural e ainda limpam, resumem ou traduzem tudo automaticamente.

Hoje em dia, raspar dados não é mais coisa só de programador. Virou rotina para times de vendas, marketing, e-commerce e operações que precisam de dados fresquinhos e organizados — para ontem. O mercado de softwares de raspagem já passou de e soluções com IA como o estão mudando o jogo. Agora, a pergunta não é mais “Qual raspador Python eu uso?”, mas sim “Como consigo os dados que preciso com o mínimo de esforço, manutenção e dor de cabeça técnica?” Bora mergulhar no duelo beautiful soup vs selenium e ver como a IA está virando o jogo.
Beautiful Soup vs Selenium: O que muda de um para o outro?
Se você já pesquisou “python web scraper”, com certeza esbarrou tanto no quanto no . Mas qual é a real diferença entre eles?
Pensa no Beautiful Soup como aquele bibliotecário que acha qualquer livro rapidinho. É uma biblioteca Python feita para analisar e extrair dados de arquivos HTML ou XML estáticos. Se a informação já está no código da página, o Beautiful Soup encontra, organiza e te entrega rapidinho. Ele é leve, rápido e não precisa “ver” a página como a gente — só lê o HTML puro.
O Selenium, por outro lado, é tipo um estagiário robô que realmente usa o navegador. Ele automatiza tudo: clica em botão, preenche formulário, faz login, rola a página, espera o JavaScript carregar. O Selenium é perfeito quando os dados só aparecem depois de alguma interação ou quando a página é toda montada com JavaScript.
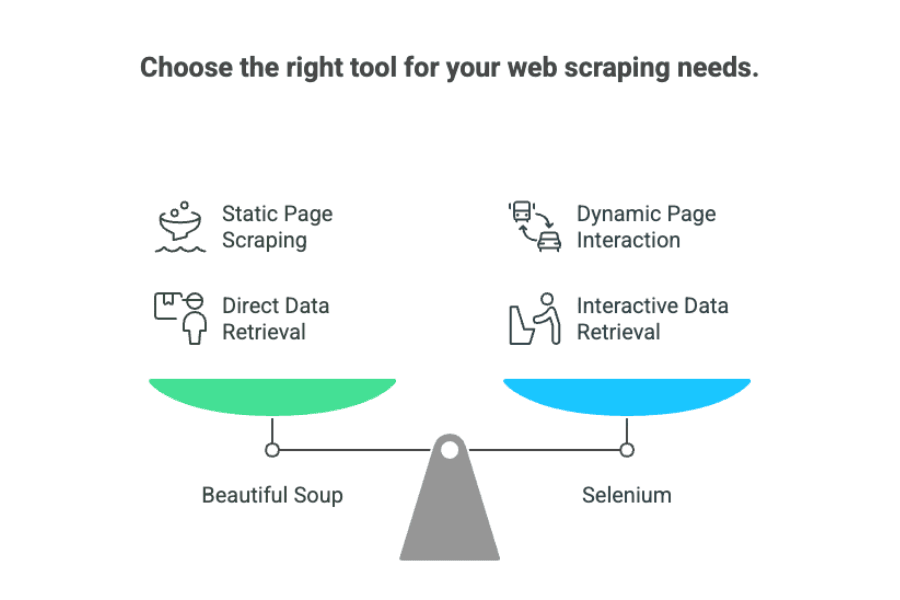
Resumindo o embate beautiful soup vs selenium:
- Beautiful Soup: Melhor para páginas estáticas, onde os dados já estão no HTML.
- Selenium: Ideal para sites dinâmicos que exigem interação ou carregamento de conteúdo.
Para quem é do mundo dos negócios, pensa assim:
- Beautiful Soup é como copiar informações de um catálogo impresso.
- Selenium é como mandar alguém até a loja, folhear o catálogo, apertar uns botões e pegar os preços atualizados.
Os principais perrengues: Limitações do Beautiful Soup e Selenium
Agora, vamos falar dos sufocos. Depois de muitas horas tentando consertar raspadores quebrados, esses são os maiores desafios dessas ferramentas:
1. Sensibilidade a Mudanças no Site
Ambas são super sensíveis a qualquer alteração no site. Se o dono do site muda o nome de uma classe ou mexe num div, seu raspador pode parar de funcionar do nada. Como , “o custo de manutenção pode ser dez vezes maior que o de desenvolvimento.” É de doer.
2. Velocidade (ou a falta dela)
- Beautiful Soup é rápido para analisar, mas se você precisa raspar milhares de páginas, ainda vai levar um tempinho.
- Selenium é bem mais lento — cada página exige abrir um navegador, esperar scripts carregarem e interagir com a interface. Escalar Selenium significa abrir vários navegadores, gastando muita memória e processamento.
3. Pouca Reutilização de Código
Cada site é um mundo. Ou seja, você precisa criar lógica personalizada para cada novo site e, quando o site muda, começa tudo de novo. Não existe script universal.
4. Complexidade Técnica
Ambas exigem que você entenda de Python, HTML/CSS e (no caso do Selenium) de drivers de navegador. Para quem não é dev, a curva de aprendizado é puxada.
5. Manutenção Sem Fim
Manter raspadores funcionando é um trabalho que nunca acaba. Os sites mudam, as barreiras anti-bot ficam mais fortes e você precisa ficar de olho e atualizar scripts o tempo todo. Para empresas, isso significa depender de devs ou terceirizar a raspagem.
Além dos raspadores Python tradicionais: A revolução das soluções com IA
Agora vem a parte legal. Nos últimos anos, surgiram raspadores web com IA — ferramentas que usam modelos de linguagem avançados (tipo GPT) para “ler” e extrair dados de sites, sem precisar de código.
Conheça o Thunderbit: Raspador Web IA para Empresas
O é uma extensão do Chrome que permite raspar qualquer site em dois cliques. Nada de Python, nada de código, nada de configurar driver. Só apontar, clicar e deixar a IA fazer o trabalho pesado.
Por que raspadores com IA como o Thunderbit são tão relevantes
- Sem código, sem esforço: O Thunderbit vai além do “no code” — é “zero esforço”. Não precisa configurar nada. Instale a , acesse a página e deixe a IA sugerir os campos para extração.
- Lida com conteúdo dinâmico: Por rodar no navegador, o Thunderbit vê tudo que você vê — inclusive dados carregados por JavaScript, depois de cliques ou até atrás de login.
- Rápido e certeiro: A IA do Thunderbit raspa várias páginas em lote, com velocidade e precisão, especialmente para geração de leads, e-commerce e mercado imobiliário.
- Sem manutenção: Pense no Thunderbit como um estagiário de IA que nunca cansa. Se o site muda, a IA se adapta. Chega de reescrever código toda vez que um div muda de lugar.
- Limpeza e enriquecimento de dados: O Thunderbit não só extrai dados brutos — ele pode rotular, formatar, traduzir e até resumir as informações enquanto raspa. É como entregar 10 mil páginas para o ChatGPT e receber uma planilha limpinha.
O resultado? Quem trabalha com negócios finalmente consegue os dados que precisa, sem depender de TI ou aprender Python.
Thunderbit vs Beautiful Soup vs Selenium: Comparativo rápido
Olha só como essas ferramentas se comparam para quem precisa de dados no dia a dia:
| Critério | Beautiful Soup | Selenium | Thunderbit (Raspador Web IA) |
|---|---|---|---|
| Configuração | Instalação simples no Python | Complexa (drivers de navegador) | Extensão Chrome, sem configuração |
| Facilidade de Uso | Fácil para programadores | Mais difícil, exige código | Sem código, amigável para negócios |
| Velocidade | Rápido em páginas estáticas | Lento (sobrecarga do navegador) | Rápido para tarefas pequenas/médias, não para milhões |
| Conteúdo Dinâmico | Não lida com JS | Lida com todo conteúdo dinâmico | Lida com todo conteúdo dinâmico |
| Manutenção | Alta (quebra com mudanças) | Alta (quebra, atualizações de driver) | Baixa (IA se adapta às mudanças) |
| Escalabilidade | Boa para estáticos, precisa de infra | Difícil de escalar, pesado | Melhor para tarefas pequenas/médias, não para grandes volumes |
| Limpeza de Dados | Manual, pós-processamento | Manual, pós-processamento | Integrado: rotula, formata, traduz, resume |
| Integrações | Código personalizado | Código personalizado | 1 clique para Excel, Sheets, Airtable, Notion |
| Habilidade Técnica | Requer Python | Python + conhecimento de navegador | Não precisa de conhecimento técnico |
Recursos avançados: Por que o Thunderbit é um divisor de águas para empresas
Veja o que faz do Thunderbit um salto de qualidade para quem quer dados sem complicação:
1. Extração de Dados com IA
O Thunderbit usa IA para “ler” páginas e sugerir os melhores campos para extração. Só clicar em “Sugerir Campos com IA”, revisar as colunas e começar a raspar. Não precisa escrever seletores nem analisar HTML.
2. Raspagem de Subpáginas
Precisa pegar dados de uma lista de produtos e depois visitar cada página para mais detalhes? O Thunderbit faz isso sozinho, enriquecendo sua tabela sem trabalho extra.
3. Limpeza, Rotulagem e Tradução de Dados
A IA do Thunderbit pode:
- Rotular dados: Adicionar categorias ou tags durante a raspagem.
- Formatar dados: Padronizar telefones, datas ou preços.
- Traduzir: Traduzir na hora o conteúdo extraído para o idioma que você quiser.
- Resumir: Gerar resumos ou pontos-chave de textos longos.
É como ter um analista de dados dentro do seu raspador.
4. Integrações sem dor de cabeça
Exporte seus dados direto para Excel, Google Sheets, Airtable ou Notion com um clique. Esqueça o trabalho manual com CSV.
5. Sem código, sem manutenção
O Thunderbit foi feito para quem é de negócios, não para devs. Não precisa saber Python nem se preocupar com manutenção. A IA se adapta às mudanças e seus fluxos continuam rodando.
Quer saber mais sobre o Thunderbit? Veja .
Como escolher a ferramenta certa: Dicas para empresas
Como decidir entre Beautiful Soup, Selenium e Thunderbit? Aqui vai um guia prático, baseado em anos de experiência (e muitos scripts quebrados):
1. Qual o volume de dados?
- Tarefas pequenas ou médias (centenas ou milhares de páginas): Thunderbit é perfeito — configuração rápida, sem código e limpeza de dados integrada.
- Raspagem em larga escala (dezenas de milhares ou milhões de páginas): Beautiful Soup (com frameworks como Scrapy) ou soluções empresariais. O Thunderbit ainda não é feito para volumes gigantes.
2. Você tem equipe de programação?
- Tem devs: Beautiful Soup e Selenium dão controle total.
- Sem devs ou precisa de agilidade: Thunderbit ou outra ferramenta com IA.
3. O site muda com frequência?
- Mudanças frequentes: A IA do Thunderbit se adapta sozinha, poupando tempo de manutenção.
- Mudanças raras: Beautiful Soup ou Selenium funcionam, mas esteja pronto para atualizar scripts.
4. Precisa de limpeza ou enriquecimento de dados?
- Sim: Thunderbit rotula, formata, traduz e resume durante a raspagem.
- Não, só dados brutos: Beautiful Soup ou Selenium.
Checklist de decisão
| Pergunta | Melhor Ferramenta |
|---|---|
| Sem desenvolvedor, precisa de dados agora | Thunderbit |
| Precisa de limpeza/tradução durante a raspagem | Thunderbit |
| Grande escala, pipeline personalizado | Beautiful Soup/Scrapy |
| Mudanças frequentes no site, quer pouca manutenção | Thunderbit |
Conclusão: O futuro das ferramentas Python para raspagem de dados
A raspagem de dados evoluiu muito desde meus primeiros scripts Python cheios de gambiarra. Em 2025, o debate “beautiful soup vs selenium” ainda faz sentido — mas a chegada de ferramentas com IA como o Thunderbit está mudando tudo para quem precisa de dados no dia a dia.
Beautiful Soup segue imbatível para extração rápida de HTML estático — leve, ágil e ótimo para tarefas simples. Selenium ainda é a escolha para automação de navegador e raspagem de sites dinâmicos, mas exige mais configuração e manutenção.
Mas se você quer fugir do código, evitar dor de cabeça com manutenção e receber dados limpos e organizados com o mínimo de esforço, os raspadores web com IA como o Thunderbit são o novo padrão. Não é só “no code” — é “zero esforço”. E para times de vendas, e-commerce e operações que precisam de dados para ontem (sem esperar uma semana por ajustes técnicos), isso faz toda a diferença.
Meu conselho? Reavalie seus processos de raspagem. Se está cansado de script quebrando, manutenção sem fim ou de depender de devs, testa o Thunderbit. O futuro da raspagem de dados está mais inteligente, rápido e acessível do que nunca — e eu, sinceramente, estou animado para ver até onde a gente pode chegar.
Quer ver o Thunderbit funcionando? ou confira mais dicas no . E se quiser aprender a raspar sites específicos (Amazon, Twitter, PDFs e mais), temos guias completos:
Boas raspagens — e que seus dados estejam sempre organizados, atualizados e sem dor de cabeça!