

Imagine a situação: você está diante de um site com milhares de produtos e seu chefe (ou aquele seu lado curioso por dados) quer todos os preços, nomes e avaliações organizados numa planilha — para ontem. Você até poderia passar horas copiando e colando, mas... por que não deixar o Python fazer esse trabalho chato? É aí que entra o raspador web, e pode acreditar: essa técnica não é só para hackers ou engenheiros do Vale do Silício. Hoje, a raspagem de dados virou uma habilidade indispensável para quem trabalha com vendas, imóveis, pesquisa de mercado e muito mais. O mercado global de softwares de raspagem web já ultrapassa US$ 1 bilhão e deve dobrar até 2032. Ou seja: dados não faltam e as oportunidades estão por toda parte.
Como cofundador da Thunderbit, passei anos ajudando empresas a automatizar a coleta de dados. Antes de existirem raspadores com IA como o Thunderbit, que extraem dados da web em poucos cliques, comecei minha trajetória com o trio clássico do Python: beautifulsoup python, requests e muita tentativa e erro. Neste guia, vou te mostrar o que é o beautifulsoup, como instalar e usar, e por que ele ainda é uma das ferramentas preferidas de quem trabalha com dados. Depois, vou apresentar como soluções com IA, como o Thunderbit, estão revolucionando a raspagem web (e poupando muita dor de cabeça). Seja você iniciante em Python, profissional de negócios ou só curioso sobre raspagem, vem comigo!
O que é BeautifulSoup? Descubra o poder da raspagem web em Python
Vamos ao básico. BeautifulSoup (ou BS4) é uma biblioteca Python para extrair dados de arquivos HTML e XML. Pense nela como um detetive de HTML: você entrega um código todo bagunçado e ela organiza tudo numa estrutura fácil de navegar. Assim, buscar o nome de um produto, preço ou avaliação vira tarefa simples — basta pedir pelo nome da tag ou classe.
O beautifulsoup python não faz o download das páginas sozinho (para isso usamos bibliotecas como requests), mas, com o HTML em mãos, filtrar e extrair exatamente o que você precisa fica fácil. Não à toa, em uma pesquisa recente, mais de 43% dos desenvolvedores escolheram o beautifulsoup como ferramenta preferida para raspagem web — mais do que qualquer outra biblioteca.
Você vai encontrar scripts com beautifulsoup python em pesquisas acadêmicas, análises de e-commerce, geração de leads e muito mais. Já vi equipes de marketing montando listas de influenciadores, recrutadores extraindo vagas de emprego e até jornalistas automatizando investigações. É uma ferramenta flexível, tolerante a erros e, para quem já tem alguma noção de Python, bem acessível.
Por que usar BeautifulSoup? Vantagens e aplicações reais para negócios
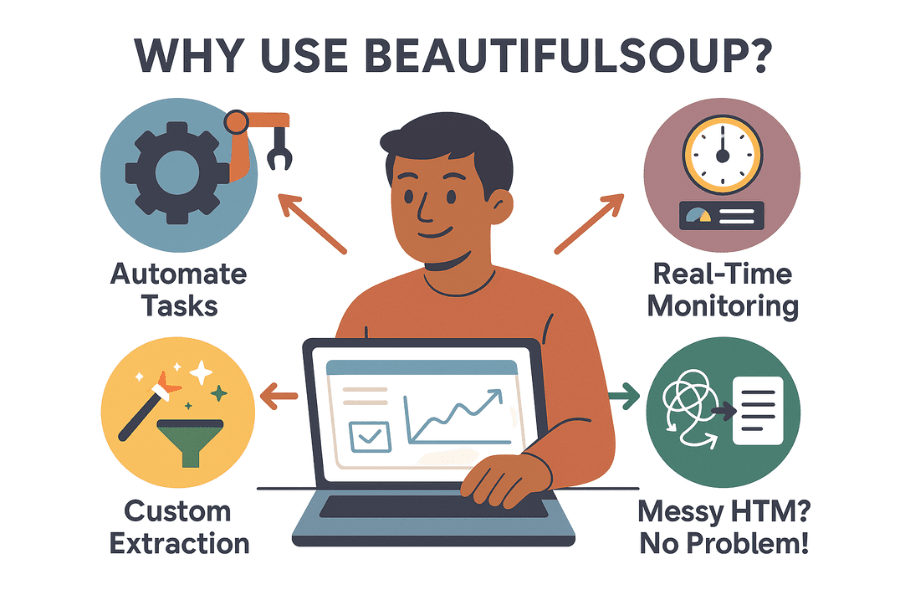
Mas afinal, por que tanta gente que trabalha com dados recorre ao beautifulsoup? Veja alguns motivos que fazem dele um clássico da raspagem web:
- Automatiza tarefas repetitivas: Por que perder tempo copiando e colando se um script pode fazer isso por você? O beautifulsoup python coleta milhares de dados em minutos, liberando sua equipe para tarefas mais estratégicas.
- Monitoramento em tempo real: Programe scripts para acompanhar preços de concorrentes, estoques ou manchetes de notícias. Se o rival baixar o preço, você descobre antes do café.
- Extração personalizada: Precisa dos 10 produtos mais vendidos, com avaliações e notas? O beautifulsoup te dá controle total sobre o que coletar e como tratar os dados.
- Lida com HTML bagunçado: Mesmo que o código do site pareça um caos, o beautifulsoup geralmente consegue interpretar e organizar tudo.
Veja alguns exemplos práticos de uso:
| Caso de Uso | Descrição | Resultado Esperado |
|---|---|---|
| Geração de Leads | Raspagem de diretórios de empresas ou LinkedIn para e-mails e telefones | Criar listas segmentadas para prospecção |
| Monitoramento de Preços | Acompanhar preços de concorrentes em lojas online | Ajustar seus preços em tempo real |
| Pesquisa de Mercado | Coletar avaliações, notas ou detalhes de produtos em e-commerces | Identificar tendências e orientar o desenvolvimento de produtos |
| Dados Imobiliários | Agregar anúncios de imóveis de sites como Zillow ou Realtor.com | Analisar tendências de preços ou oportunidades de investimento |
| Agregação de Conteúdo | Reunir notícias, posts de blogs ou menções em redes sociais | Alimentar newsletters ou análises de sentimento |
E o resultado? Uma varejista do Reino Unido usou raspagem web para monitorar concorrentes e aumentou as vendas em 4%. A ASOS dobrou as vendas internacionais ajustando campanhas com base em preços locais extraídos. Ou seja: dados raspados geram decisões de negócio reais.
Mão na massa: Instalando o BeautifulSoup no Python
Pronto para começar? Veja como instalar o beautifulsoup python:
Passo 1: Instale o BeautifulSoup (do jeito certo)
Certifique-se de instalar a versão mais recente — BeautifulSoup 4 (ou bs4). Não confunda com o pacote antigo!
pip install beautifulsoup4
Se estiver no macOS ou Linux, talvez precise usar pip3 ou adicionar sudo:
sudo pip3 install beautifulsoup4
Dica: Se rodar pip install beautifulsoup (sem o “4”), vai instalar uma versão antiga e incompatível. Já passei por isso!
Passo 2: Instale um parser (opcional, mas recomendado)
O beautifulsoup pode usar o parser HTML nativo do Python, mas para mais velocidade e confiabilidade, vale instalar lxml e html5lib:
pip install lxml html5lib
Passo 3: Instale o Requests (para baixar páginas)
O beautifulsoup interpreta o HTML, mas você precisa baixá-lo antes. A biblioteca requests é a mais usada:
pip install requests
Passo 4: Verifique seu ambiente Python
Garanta que está usando Python 3. Se estiver numa IDE (PyCharm, VS Code), confira o interpretador. Se aparecer erro de importação, talvez esteja instalando pacotes no ambiente errado. No Windows, py -m pip install beautifulsoup4 pode ajudar a instalar na versão correta.
Passo 5: Teste sua instalação
Faça um teste rápido:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Se aparecer a tag <title>, está tudo certo.
BeautifulSoup na prática: conceitos e sintaxe essenciais
Vamos entender os principais objetos e conceitos do beautifulsoup:
- Objeto BeautifulSoup: É a raiz da árvore HTML analisada. Criado com
BeautifulSoup(html, parser). - Tag: Representa uma tag HTML ou XML (como
<div>,<p>,<span>). Permite acessar atributos, filhos e texto. - NavigableString: Representa o texto dentro de uma tag.
Entendendo a árvore de análise
Pense no HTML como uma árvore genealógica: a tag <html> é o ancestral, <head> e <body> são filhos, e assim por diante. O beautifulsoup permite navegar por essa árvore de forma intuitiva com Python.
Exemplo:
html = """
<html>
<head><title>Minha Página de Teste</title></head>
<body>
<p class="story">Era uma vez <b>três irmãs</b>...</p>
</body>
</html>
"""
soup = BeautifulSoup(html, "html.parser")
# Acessar a tag title
print(soup.title) # <title>Minha Página de Teste</title>
print(soup.title.string) # Minha Página de Teste
# Acessar a primeira tag <p> e seu atributo de classe
p_tag = soup.find('p', class_='story')
print(p_tag['class']) # ['story']
# Obter todo o texto dentro da tag <p>
print(p_tag.get_text()) # Era uma vez três irmãs...
Navegação e busca
- Acessores de elementos:
soup.head,soup.body,tag.parent,tag.children - find() / find_all(): Busca por tags pelo nome ou atributos.
- select(): Permite usar seletores CSS para buscas mais avançadas.
Exemplo:
# Encontrar todos os links
for link in soup.find_all('a'):
print(link.get('href'))
# Exemplo com seletor CSS
for item in soup.select('div.product > span.price'):
print(item.get_text())
Mão na massa: criando seu primeiro raspador web com BeautifulSoup
Vamos praticar. Suponha que você queira extrair títulos e preços de produtos em uma página de resultados de busca (usando o Etsy como exemplo):
Passo 1: Baixe a página
import requests
from bs4 import BeautifulSoup
url = "https://www.etsy.com/search?q=clothes"
headers = {"User-Agent": "Mozilla/5.0"} # Alguns sites exigem um user-agent
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, 'html.parser')
Passo 2: Analise e extraia os dados
Suponha que cada produto esteja em um bloco <li class="wt-list-unstyled">, com o título em <h3 class="v2-listing-card__title"> e o preço em <span class="currency-value">.
items = []
for item in soup.find_all('li', class_='wt-list-unstyled'):
title_tag = item.find('h3', class_='v2-listing-card__title')
price_tag = item.find('span', class_='currency-value')
if title_tag and price_tag:
title = title_tag.get_text(strip=True)
price = price_tag.get_text(strip=True)
items.append((title, price))
Passo 3: Salve em CSV ou Excel
Usando o módulo csv do Python:
import csv
with open("etsy_products.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["Título do Produto", "Preço"])
writer.writerows(items)
Ou, com pandas:
import pandas as pd
df = pd.DataFrame(items, columns=["Título do Produto", "Preço"])
df.to_csv("etsy_products.csv", index=False)
Pronto! Agora você tem uma planilha pronta para análise, relatórios ou para mostrar para o time.
Desafios do BeautifulSoup: manutenção, bloqueios e limitações
Agora, papo reto: apesar de adorar o beautifulsoup, ele tem seus desafios — principalmente quando o volume de dados cresce ou o projeto se estende por muito tempo.
1. Fragilidade diante de mudanças no site
Sites mudam layout, nomes de classes e até a ordem dos elementos. Seu script com beautifulsoup só funciona enquanto os seletores estiverem corretos. Se o HTML mudar, o script pode parar de funcionar — e às vezes sem avisar. Se você raspa dezenas (ou centenas) de sites, manter tudo atualizado pode ser um pesadelo.
2. Barreiras anti-raspagem
Muitos sites usam defesas como CAPTCHAs, bloqueio de IP, limites de acesso, conteúdo dinâmico via JavaScript e mais. O beautifulsoup sozinho não resolve isso. Você vai precisar de proxies, navegadores headless ou até serviços para resolver CAPTCHAs. É uma briga constante com os administradores dos sites.
3. Escalabilidade e performance
O beautifulsoup é ótimo para scripts pontuais ou volumes moderados. Mas, se precisar raspar milhões de páginas ou rodar tarefas em paralelo, será necessário programar controle de concorrência, tratamento de erros e infraestrutura. É possível, mas exige tempo e conhecimento.
4. Barreira técnica
Se você não está confortável com Python, HTML e depuração, o beautifulsoup pode assustar. Mesmo para desenvolvedores experientes, a rotina é: inspecionar, codar, rodar, ajustar e repetir.
5. Questões legais e éticas
A raspagem pode esbarrar em questões legais, especialmente se você ignorar o robots.txt ou os termos de uso do site. Com código, a responsabilidade é sua: respeite limites de acesso, regras do site e trate os dados de forma ética.
Além do BeautifulSoup: como ferramentas com IA como o Thunderbit facilitam a raspagem web
Extraia dados de qualquer site usando IA Get Started Free
Agora vem a parte interessante. Com o avanço da IA, ferramentas como o Thunderbit estão tornando a raspagem web acessível para todos — não só para programadores.
O Thunderbit é uma extensão do Chrome com IA que permite raspar qualquer site em dois cliques. Nada de Python, seletores ou manutenção. Basta abrir a página, clicar em “IA Sugerir Campos” e a IA do Thunderbit identifica automaticamente os dados mais relevantes (nomes de produtos, preços, avaliações, e-mails, telefones, etc.). Depois, é só clicar em “Raspar” e pronto.
Thunderbit vs. BeautifulSoup: comparação lado a lado
| Recurso | BeautifulSoup (com código) | Thunderbit (IA, sem código) |
|---|---|---|
| Dificuldade de Configuração | Exige programação em Python, conhecimento de HTML e depuração | Sem código — IA detecta campos automaticamente, interface intuitiva |
| Velocidade para Obter Dados | Horas (escrevendo e testando código) | Minutos (2–3 cliques) |
| Adaptação a Mudanças | Quebra se o HTML do site mudar; precisa atualizar manualmente | IA se adapta a muitas mudanças; templates de sites populares são mantidos |
| Paginação/Subpáginas | Precisa programar laços e requisições para cada página | Paginação e subpáginas integradas — basta ativar |
| Bloqueios Anti-bot | Necessário adicionar proxies, resolver CAPTCHAs, simular navegador | Muitos bloqueios tratados internamente; contexto do navegador ajuda a evitar bloqueios |
| Processamento de Dados | Controle total via código, mas precisa programar | IA integrada para resumir, categorizar, traduzir e limpar dados |
| Exportação | Código personalizado para CSV, Excel, banco de dados, etc. | Exportação em um clique para CSV, Excel, Google Sheets, Airtable, Notion |
| Escalabilidade | Ilimitada se você construir a infraestrutura; mas precisa gerenciar erros, tentativas e escalonamento | Alta — extensão/nuvem lida com cargas paralelas, agendamento e grandes volumes (limitado pelo plano/créditos) |
| Custo | Gratuito (open-source), mas consome tempo e manutenção | Freemium (grátis para tarefas pequenas, planos pagos para escala), mas economiza muito tempo e manutenção |
| Flexibilidade | Máxima — o código faz tudo, se você programar | Atende à maioria dos casos comuns; situações muito específicas podem exigir código |
Quer saber mais? Dá uma olhada no blog da Thunderbit e na documentação de recursos.
Passo a passo: raspando dados com Thunderbit vs. BeautifulSoup
Vamos comparar os fluxos de trabalho extraindo dados de produtos em um site de e-commerce.
Com BeautifulSoup
- Inspecione a estrutura HTML do site usando as ferramentas do navegador.
- Escreva código Python para baixar a página (
requests), analisar (BeautifulSoup) e extrair os campos desejados. - Ajuste os seletores (nomes de classes, caminhos das tags) até obter os dados certos.
- Programe a paginação criando laços para seguir os links de “Próxima”.
- Exporte os dados para CSV ou Excel com código extra.
- Se o site mudar, repita os passos 1–5.
Tempo estimado: 1–2 horas para um site novo (mais se houver bloqueios anti-bot).
Com Thunderbit
- Abra o site desejado no Chrome.
- Clique na extensão Thunderbit.
- Clique em “IA Sugerir Campos” — a IA sugere colunas como Nome do Produto, Preço, etc.
- Ajuste as colunas se necessário e clique em “Raspar”.
- Ative a paginação ou subpáginas com um clique, se precisar.
- Visualize os dados em tabela e exporte no formato preferido.
Tempo estimado: 2–5 minutos. Sem código, sem dor de cabeça, sem manutenção.
Bônus: O Thunderbit também extrai e-mails, telefones, imagens e até preenche formulários automaticamente. É como ter um estagiário super-rápido que nunca reclama de tarefas repetitivas.
Experimente o Raspador Web IA Thunderbit gratuitamente
Conclusão & principais aprendizados
O que é raspagem de dados e como fazer em 2025 Get Started Free
A raspagem web deixou de ser um truque de nicho para se tornar uma ferramenta essencial nos negócios, impulsionando desde a geração de leads até pesquisas de mercado. O beautifulsoup continua sendo uma ótima porta de entrada para quem tem familiaridade com Python, oferecendo flexibilidade e controle para projetos personalizados. Mas, à medida que os sites ficam mais complexos — e os usuários de negócios buscam soluções rápidas e fáceis — ferramentas com IA como o Thunderbit estão mudando o jogo.

Se você curte programar e quer criar algo totalmente sob medida, o beautifulsoup ainda é uma excelente escolha. Mas se prefere evitar código, não quer se preocupar com manutenção e busca resultados em minutos, o Thunderbit é o caminho. Por que gastar horas programando se a IA pode resolver em instantes?
Quer experimentar? Baixe a extensão Thunderbit para Chrome ou confira mais tutoriais no Blog da Thunderbit. E se quiser continuar explorando Python, siga testando o beautifulsoup — só não esqueça de alongar os pulsos depois de tanto digitar!
Boas raspagens!
Experimente o Raspador Web IA Thunderbit Get Started Free
Leituras recomendadas:
- Documentação oficial do Beautiful Soup
- O que é raspagem de dados e como fazer em 2025
- Como extrair dados de sites para Excel usando IA
- Canal Thunderbit no YouTube
Se tiver dúvidas, histórias ou quiser compartilhar experiências de raspagem, deixa um comentário ou entra em contato. Provavelmente já quebrei mais raspadores do que muita gente já escreveu.




