Sejamos sinceros: a Amazon é, basicamente, o centro comercial, o supermercado e a loja de eletrónica de toda a internet. Se trabalha com vendas, e-commerce ou operações, já sabe que o que acontece na Amazon não fica só na Amazon — influencia os seus preços, o stock e até o próximo grande lançamento de produto. Mas aqui está o problema: todos aqueles detalhes apetecíveis sobre produtos, preços, avaliações e comentários estão presos numa interface feita para compradores, não para equipas sedentas de dados. Então, como é que se põe a mão nesses dados sem passar o fim de semana inteiro a copiar e colar como se ainda estivéssemos em 1999?
É aqui que entra o web scraping. Neste guia, vou mostrar duas formas de extrair dados de produtos da Amazon: a abordagem clássica de “arregaçar as mangas e programar em Python” e a via moderna de “deixar a IA fazer o trabalho pesado” com um raspador web sem código como o . Vou passar por código Python real (com todas as armadilhas e soluções alternativas) e, depois, mostrar como o Thunderbit consegue extrair os mesmos dados em apenas alguns cliques — sem necessidade de programar. Seja você programador, analista de negócio ou simplesmente alguém farto de introduzir dados manualmente, este guia é para si.
Por que extrair dados de produtos da Amazon? (amazon scraper python, web scraping with python)
A Amazon não é apenas o maior retalhista online do mundo — é também o maior mercado ao ar livre do mundo para inteligência competitiva. Com e , a Amazon é uma mina de ouro para quem quer:

- Monitorizar preços (e ajustar os seus em tempo real)
- Analisar concorrentes (acompanhar novos lançamentos, avaliações e comentários)
- Gerar leads (encontrar vendedores, fornecedores ou até potenciais parceiros)
- Prever a procura (observando níveis de stock e rankings de vendas)
- Identificar tendências de mercado (analisando avaliações e resultados de pesquisa)
E isto não é só teoria — empresas reais estão a ver ROI real. Por exemplo, um retalhista de eletrónica usou dados de preços raspados da Amazon para , enquanto outra marca conseguiu depois de automatizar o acompanhamento de preços da concorrência.
Aqui fica uma tabela rápida com casos de uso e o tipo de ROI que pode esperar:
| Caso de uso | Quem usa | ROI / benefício típico |
|---|---|---|
| Monitorização de preços | E-commerce, operações | Aumento de 15%+ na margem de lucro, alta de 4% nas vendas, 30% menos tempo de analistas |
| Análise da concorrência | Vendas, produto, operações | Ajustes de preço mais rápidos, maior competitividade |
| Pesquisa de mercado (avaliações) | Produto, marketing | Iteração de produto mais rápida, textos de anúncio melhores, insights de SEO |
| Geração de leads | Vendas | Mais de 3.000 leads/mês, mais de 8 horas poupadas por representante por semana |
| Stock e previsão de procura | Operações, supply chain | Redução de 20% em excesso de stock, menos rupturas |
| Identificação de tendências | Marketing, executivos | Detecção antecipada de produtos e categorias em alta |
E aqui está o ponto essencial: já relatam valor mensurável com analytics de dados. Se não estiver a extrair dados da Amazon, está a deixar insights — e dinheiro — em cima da mesa.
Visão geral: Amazon Scraper Python vs. ferramentas de raspador web sem código
Há duas formas principais de tirar dados da Amazon do navegador e levá-los para as suas folhas de cálculo ou dashboards:
-
Amazon Scraper Python (web scraping com Python):
Escreva o seu próprio script com bibliotecas Python como Requests e BeautifulSoup. Isto dá-lhe controlo total, mas vai precisar de saber programar, lidar com mecanismos anti-bot e manter o script atualizado sempre que a Amazon alterar o site.
-
Ferramentas de raspador web sem código (como o Thunderbit):
Use uma ferramenta que permite apontar, clicar e extrair dados — sem necessidade de programação. Ferramentas modernas como o até usam IA para descobrir que dados capturar, lidar com subpáginas e paginação e exportar diretamente para Excel ou Google Sheets.
Veja como se comparam:
| Critério | Raspador Python | Sem código (Thunderbit) |
|---|---|---|
| Tempo de configuração | Elevado (instalar, programar, depurar) | Baixo (instalar a extensão) |
| Habilidade necessária | É preciso saber programar | Nenhuma (apontar e clicar) |
| Flexibilidade | Ilimitada | Alta para casos de uso comuns |
| Manutenção | Você corrige o código | A ferramenta atualiza-se sozinha |
| Tratamento anti-bot | Você gere proxies e headers | Integrado, tratado por si |
| Escalabilidade | Manual (threads, proxies) | Raspagem na nuvem, paralelizada |
| Exportação de dados | Personalizada (CSV, Excel, base de dados) | Um clique para Excel e Sheets |
| Custo | Grátis (o seu tempo + proxies) | Freemium, paga para escalar |
Nas próximas secções, vou guiá-lo por ambas as abordagens — primeiro, como criar um raspador da Amazon em Python (com código real), e depois como fazer a mesma coisa com o raspador web com IA do Thunderbit.
Começando com Amazon Scraper Python: pré-requisitos e configuração
Antes de mergulharmos no código, vamos preparar o ambiente.
Vai precisar de:
- Python 3.x (faça o download em )
- Um editor de código (gosto do VS Code, mas qualquer um serve)
- As seguintes bibliotecas:
requests(para pedidos HTTP)beautifulsoup4(para análise de HTML)lxml(analisador de HTML rápido)pandas(para tabelas/exportação de dados)re(expressões regulares, integrado)
Instale as bibliotecas:
1pip install requests beautifulsoup4 lxml pandasConfiguração do projeto:
- Crie uma nova pasta para o projeto.
- Abra o editor, crie um novo ficheiro Python (por exemplo,
amazon_scraper.py). - Está pronto para começar!
Passo a passo: web scraping com Python para dados de produtos da Amazon
Vamos ver como extrair uma única página de produto da Amazon. (Não se preocupe, já lá vamos à extração de vários produtos e páginas.)
1. Enviando pedidos e obtendo o HTML
Primeiro, vamos buscar o HTML de uma página de produto. (Substitua a URL por qualquer produto da Amazon.)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)Atenção: este pedido básico provavelmente será bloqueado pela Amazon. Pode ver um erro 503 ou um CAPTCHA em vez da página do produto. Porquê? Porque a Amazon sabe que não é um navegador real.
Lidando com as medidas anti-bot da Amazon
A Amazon não gosta de bots. Para evitar bloqueios, vai precisar de:
- Definir um header User-Agent (fingir que é Chrome ou Firefox)
- Alternar User-Agents (não usar sempre o mesmo)
- Controlar a frequência dos pedidos (adicionar atrasos aleatórios)
- Usar proxies (para raspagem em grande escala)
Veja como definir os headers:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)Quer ir mais longe? Use uma lista de User-Agents e vá alternando entre eles a cada pedido. Para projetos maiores, vale a pena usar um serviço de proxy (há vários no mercado), mas, para raspagem em pequena escala, headers e atrasos costumam ser suficientes.
Extraindo campos principais do produto
Depois de ter o HTML, é altura de o analisar com BeautifulSoup.
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")Agora, vamos extrair o que interessa:
Título do produto
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else NonePreço
O preço na Amazon pode aparecer em vários sítios. Experimente estes:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.textAvaliação e número de comentários
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # por exemplo, "1,554 ratings"URL da imagem principal
Às vezes, a Amazon esconde imagens em alta resolução em JSON dentro do HTML. Veja uma abordagem rápida com regex:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else NoneOu então obtenha a tag da imagem principal:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else NoneDetalhes do produto
Especificações como marca, peso e dimensões geralmente ficam numa tabela:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = valueOu, se a Amazon usar o formato “detailBullets”:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()Imprima os resultados:
1print("Title:", product_title)
2print("Price:", price)
3print("Rating:", rating, "based on", reviews_count, "reviews")
4print("Main image URL:", main_image_url)
5print("Details:", details)Extraindo vários produtos e lidando com paginação
Um produto é bom, mas provavelmente quer uma lista inteira. Veja como extrair resultados de pesquisa e várias páginas.
Obter links de produtos de uma página de pesquisa
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)Lidar com paginação
As URLs de pesquisa da Amazon usam &page=2, &page=3 etc.
1for page in range(1, 6): # extrai as primeiras 5 páginas
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... extraia os links de produtos como acima ...Percorrer páginas de produto e exportar para CSV
Junte os dados dos produtos numa lista de dicionários e use pandas:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # lista de dicionários
3df.to_csv("amazon_products.csv", index=False)Ou para Excel:
1df.to_excel("amazon_products.xlsx", index=False)Boas práticas para projetos de Amazon Scraper Python
Sejamos realistas: a Amazon altera o site constantemente e vive a dificultar a vida aos raspadores. Veja como manter o projeto a funcionar:
- Alterne headers e User-Agents (use uma biblioteca como
fake-useragent) - Use proxies para raspagem em grande escala
- Controle a frequência dos pedidos (com
time.sleep()aleatório entre eles) - Trate erros com elegância (tente novamente em caso de 503, recue se for bloqueado)
- Escreva lógica de análise flexível (procure vários seletores por campo)
- Monitore mudanças no HTML (se o script começar a devolver
Nonepara tudo, verifique a página) - Respeite o robots.txt (a Amazon proíbe raspagem em várias secções — raspe com responsabilidade)
- Limpe os dados à medida que recolhe (remova símbolos de moeda, vírgulas e espaços em branco)
- Mantenha contacto com a comunidade (fóruns, Stack Overflow, r/webscraping no Reddit)
Checklist para manter o seu raspador:
- [ ] Alterne User-Agents e headers
- [ ] Use proxies se estiver a extrair dados em escala
- [ ] Adicione atrasos aleatórios
- [ ] Modularize o código para facilitar atualizações
- [ ] Monitore bloqueios ou CAPTCHAs
- [ ] Exporte os dados regularmente
- [ ] Documente os seus seletores e a sua lógica
Para um mergulho mais profundo, confira o meu .
A alternativa sem código: extraindo dados da Amazon com o Thunderbit AI Web Scraper
Certo, então já viu o caminho com Python. Mas e se não quiser programar — ou simplesmente quiser obter os dados em dois cliques e seguir com o seu dia? É aí que entra o .
O Thunderbit é uma extensão Chrome de raspador web com IA que permite extrair dados de produtos da Amazon (e dados de praticamente qualquer site) sem escrever código. Eis porque gosto tanto dele:
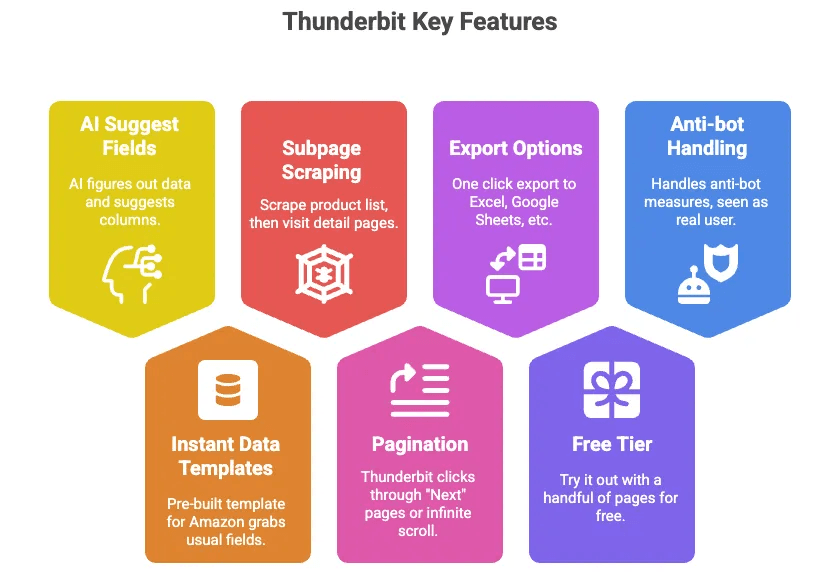
- Sugestão de campos por IA: basta clicar num botão, e a IA do Thunderbit descobre que dados existem na página e sugere colunas (como Título, Preço, Avaliação etc.).
- Modelos de dados instantâneos: para a Amazon, há um modelo pronto que captura todos os campos habituais — sem necessidade de configuração.
- Raspagem de subpáginas: extraia uma lista de produtos e depois deixe o Thunderbit visitar a página de detalhes de cada produto para extrair mais informações automaticamente.
- Paginação: o Thunderbit pode clicar nas páginas “Próxima” ou fazer scroll infinito por si.
- Exportação para Excel, Google Sheets, Airtable, Notion: um clique e os seus dados ficam prontos a usar.
- Plano gratuito: teste com algumas páginas sem pagar.
- Lida com as medidas anti-bot por si: como corre no seu navegador (ou na nuvem), a Amazon vê-o como um utilizador real.
Passo a passo: usar o Thunderbit para extrair dados de produtos da Amazon
É assim tão fácil:
-
Instale o Thunderbit:
Descarregue a e faça login.
-
Abra a Amazon:
Vá até à página da Amazon que quer extrair dados (resultados de pesquisa, página de produto, o que quiser).
-
Clique em “Sugestão de campos por IA” ou use um modelo:
O Thunderbit vai sugerir colunas para extrair (ou pode escolher o modelo de Produto da Amazon).
-
Revise as colunas:
Ajuste as colunas se quiser (adicionar/remover campos, renomear etc.).
-
Clique em “Raspar”:
O Thunderbit recolhe os dados da página e mostra tudo numa tabela.
-
Lide com subpáginas e paginação:
Se extraiu uma lista, clique em “Raspar subpáginas” para visitar a página de detalhes de cada produto e obter mais informações. O Thunderbit também pode clicar automaticamente nas páginas “Próxima”.
-
Exporte os seus dados:
Clique em “Exportar para Excel” ou “Exportar para Google Sheets”. Pronto.
-
(Opcional) Agende a raspagem:
Precisa destes dados todos os dias? Use o agendador do Thunderbit para automatizar.
É isso. Sem código, sem depuração, sem proxies, sem dor de cabeça. Para um passo a passo visual, confira o ou a .
Amazon Scraper Python vs. raspador web sem código: comparação lado a lado
Vamos juntar tudo:
| Critério | Raspador Python | Thunderbit (sem código) |
|---|---|---|
| Tempo de configuração | Elevado (instalar, programar, depurar) | Baixo (instalar a extensão) |
| Habilidade necessária | É preciso saber programar | Nenhuma (apontar e clicar) |
| Flexibilidade | Ilimitada | Alta para casos de uso comuns |
| Manutenção | Você corrige o código | A ferramenta atualiza-se sozinha |
| Tratamento anti-bot | Você gere proxies e headers | Integrado, tratado por si |
| Escalabilidade | Manual (threads, proxies) | Raspagem na nuvem, paralelizada |
| Exportação de dados | Personalizada (CSV, Excel, base de dados) | Um clique para Excel e Sheets |
| Custo | Grátis (o seu tempo + proxies) | Freemium, paga para escalar |
| Melhor para | Programadores, necessidades personalizadas | Utilizadores de negócio, resultados rápidos |
Se é um programador que adora mexer em tudo e precisa de algo superpersonalizado, Python é o seu aliado. Se quer rapidez, simplicidade e zero código, o Thunderbit é o caminho.
Quando escolher Python, sem código ou um raspador web com IA para dados da Amazon
Escolha Python se:
- Precisa de lógica personalizada ou quer integrar a raspagem nos seus sistemas de backend
- Vai extrair dados em escala massiva (dezenas de milhares de produtos)
- Quer aprender como a raspagem funciona por baixo do capô
Escolha Thunderbit (sem código, raspador web com IA) se:
- Quer dados rapidamente, sem programar
- É utilizador de negócio, analista ou profissional de marketing
- Precisa de capacitar a sua equipa para procurar os próprios dados
- Quer evitar o trabalho de proxies, medidas anti-bot e manutenção
Use ambos se:
- Quer prototipar rapidamente com o Thunderbit e depois construir uma solução Python personalizada para produção
- Quer usar o Thunderbit para recolha de dados e Python para limpeza/análise
Para a maioria dos utilizadores de negócio, o Thunderbit cobre 90% das necessidades de raspagem da Amazon numa fração do tempo. Para os outros 10% — casos superpersonalizados, em grande escala ou profundamente integrados — Python continua a ser rei.
Conclusão e principais conclusões
Extrair dados de produtos da Amazon é um superpoder para qualquer equipa de vendas, e-commerce ou operações. Seja para monitorizar preços, analisar concorrentes ou simplesmente poupar a sua equipa a copiar e colar sem fim, existe uma solução para si.
- A raspagem com Python dá-lhe controlo total, mas vem com curva de aprendizagem e manutenção contínua.
- Raspadores web sem código como o Thunderbit tornam a extração de dados da Amazon acessível a todos — sem programação, sem dor de cabeça, só resultado.
- A melhor abordagem? Use a ferramenta que se adapta às suas competências, ao seu prazo e aos seus objetivos de negócio.
Se tiver curiosidade, experimente o Thunderbit — é grátis para começar, e vai surpreender-se com a rapidez com que consegue obter os dados de que precisa. E, se é programador, não tenha medo de combinar ferramentas: às vezes, a forma mais rápida de construir algo é deixar a IA tratar das partes chatas por si.
Perguntas frequentes
1. Porque é que uma empresa gostaria de extrair dados de produtos da Amazon?
Extrair dados da Amazon permite que as empresas monitorizem preços, analisem concorrentes, recolham avaliações para pesquisa de produto, prevejam a procura e gerem leads de vendas. Com mais de 600 milhões de produtos e quase 2 milhões de vendedores na Amazon, é uma rica fonte de inteligência competitiva.
2. Quais são as principais diferenças entre usar Python e ferramentas sem código como o Thunderbit para extrair dados da Amazon?
Os raspadores Python oferecem máxima flexibilidade, mas exigem conhecimentos de programação, tempo de configuração e manutenção contínua. O Thunderbit, um raspador web com IA sem código, permite extrair dados da Amazon instantaneamente através de uma extensão Chrome — sem programar, com tratamento anti-bot integrado e opções de exportação para Excel ou Sheets.
3. É legal extrair dados da Amazon?
Os termos de serviço da Amazon geralmente proíbem a raspagem, e a empresa implementa ativamente medidas anti-bot. Ainda assim, muitas empresas continuam a recolher dados públicos, desde que o façam com responsabilidade, respeitando limites de pedidos e evitando excessos.
4. Que tipo de dados posso extrair da Amazon com ferramentas de web scraping?
Os campos mais comuns incluem títulos de produtos, preços, avaliações, número de comentários, imagens, especificações do produto, disponibilidade e até informações do vendedor. O Thunderbit também suporta raspagem de subpáginas e paginação para capturar dados em várias listagens e páginas.
5. Quando devo escolher raspagem com Python em vez de uma ferramenta como o Thunderbit (ou vice-versa)?
Use Python se precisar de controlo total, lógica personalizada ou planear integrar a raspagem em sistemas de backend. Use o Thunderbit se quiser resultados rápidos sem programar, precisar de escalar facilmente ou for um utilizador de negócio à procura de uma solução de baixa manutenção.
Quer aprofundar? Veja estes recursos:
Boa raspagem — e que as suas folhas de cálculo estejam sempre atualizadas.