Resumo executivo
Extraímos o arquivo robots.txt de cada domínio da lista Tranco top 10.000 dos sites com maior tráfego do mundo. Depois, analisámos cada um com um parser compatível com a RFC 9309, classificámos o arquivo segundo a política de bots de IA adotada pelo site, quando existia, e contamos quantos dos sites mais visitados do mundo tentam realmente bloquear ChatGPT, Claude, Perplexity, Gemini, Common Crawl, Bytespider, Apple Intelligence e os restantes crawlers que treinam e servem grandes modelos de linguagem em 2026.
Os números principais, numa amostra de 7.248 sites cujos robots.txt conseguimos ler sem problemas:
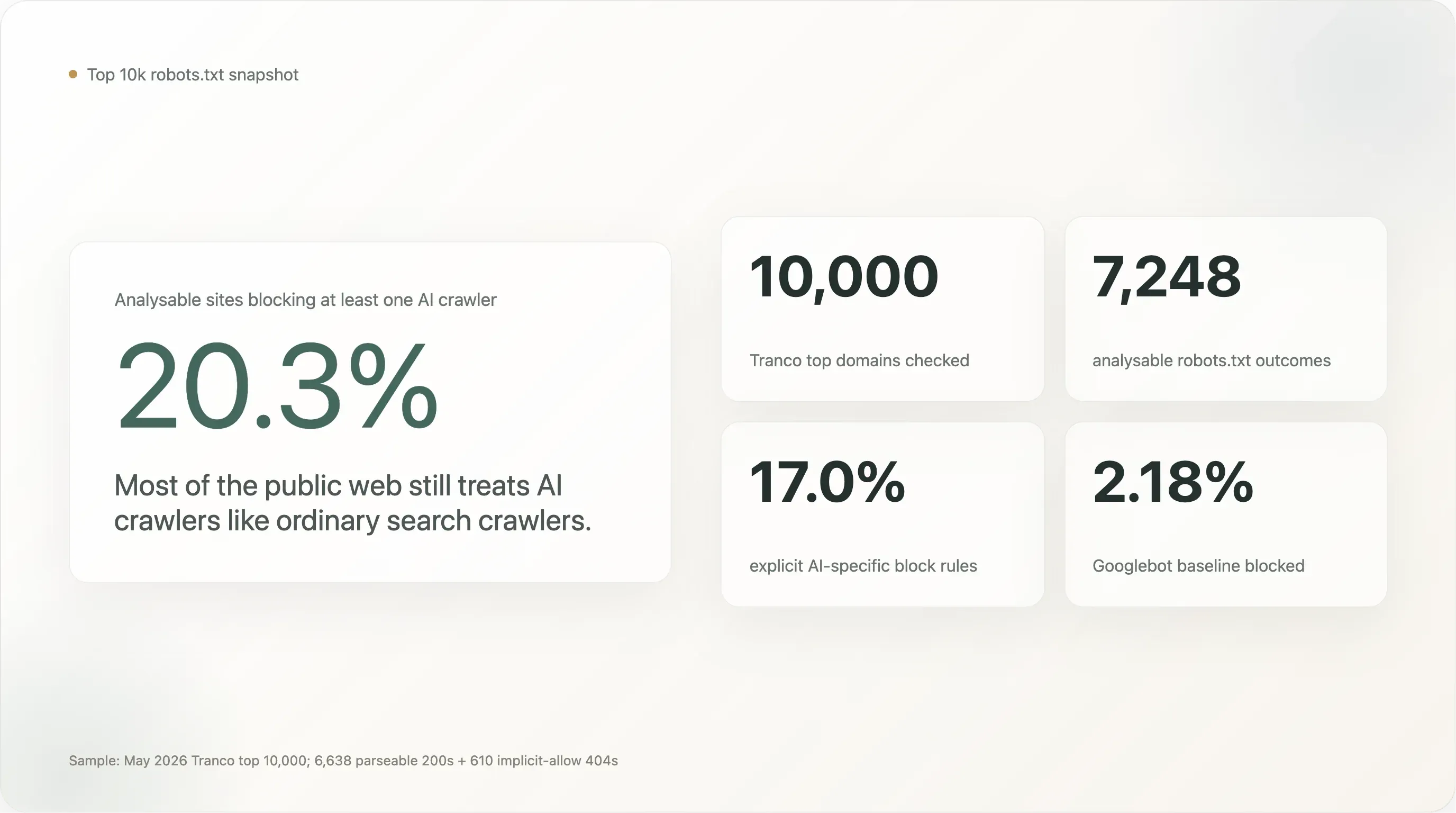
20,3% dos 10.000 sites mais visitados do mundo bloqueiam pelo menos um bot de IA. 17,0% têm uma regra explícita e específica para IA, escrita de propósito. Os outros 80% recebem os bots de IA tão bem como o Googlebot.
Seis conclusões que mudam o rumo da história:
- Veículos de notícias bloqueiam em 47% — a taxa mais alta entre todos os setores. A Alemanha lidera entre as notícias com 88%, a França com 80% e a Rússia com 0%. O principal fator é o regime jurídico, não a tecnologia nem a economia do setor.
CCBot(Common Crawl) é o bot mais bloqueado, com 16,3% — à frente deGPTBot(15,8%) eBytespider(14,9%). Os publishers visam o corpus de treino, não a marca do modelo. A regra seletiva mais usada é “bloquearCCBot, permitirGooglebot” (14,1% dos sites).- A França lidera todos os países, com 50,6% de bloqueio de IA em sites
.fr; o bloco da UE está 16 pontos acima da média global. 275 arquivosrobots.txtcitam explicitamente a Diretiva UE 2019/790. O Artigo 4 é o único regime jurídico que está a mexer nos números de forma visível. - 17,8% escreveram as suas próprias regras de IA; 4,5% usam o modelo padronizado da Cloudflare; 75,7% não dizem nada. Os sites grandes fazem as suas próprias regras; a cauda longa usa o alternador. The Atlantic e o próprio
cloudflare.comestão na lista gerida pela Cloudflare. - 108 sites permitem explicitamente
GPTBot— WordPress.org, Kaspersky, Norton, Avast, Sophos, The Verge, The Atlantic, NBA.com, The Sun, Branch.io. Segurança e ferramentas para dev estão fortemente sobrerrepresentadas. - A política de IA não fica mais agressiva no topo da curva. Top 100, 101–1000, 1001–5000, 5001–10000 ficam todos entre 19% e 23%. A taxa principal é uma característica da web pública em 2026, não um sinal do tamanho de cada site individual.
A questão já não é se a web está “a resistir”. É quais os setores, quais os países, quais os regimes jurídicos e quais os fornecedores de IA que são alvo de políticas ativas — e quais não são.
I. Contexto: como o robots.txt se tornou um artefacto de política de IA
Três forças mudaram o significado de robots.txt desde que a OpenAI lançou o GPTBot em agosto de 2023.
Os fornecedores de IA multiplicaram-se. O Google-Extended da Google, o ClaudeBot da Anthropic, o Bytespider da ByteDance, o Applebot-Extended da Apple, o Amazonbot da Amazon e o Meta-ExternalAgent da Meta surgiram a seguir. O CCBot, já existente da Common Crawl, tornou-se o alvo de bloqueio com maior impacto, porque o seu acervo alimenta a maioria dos modelos de pesos abertos. Também surgiram bots não ligados a fornecedores: AI2Bot, cohere-ai, PerplexityBot, YouBot, DuckAssistBot, Diffbot, Omgili. Em 2026, uma lista abrangente de bloqueio ronda cerca de 25 nomes.
O Artigo 4 da Diretiva de Direitos de Autor da UE 2019/790 criou uma exceção legal para mineração de texto e dados que não se aplica se o titular dos direitos tiver “reservado expressamente” os seus direitos de forma “legível por máquina”. Ao longo de 2024–2025, publishers e advogados da UE consolidaram o robots.txt como a forma canónica de expressar essa reserva. O nosso conjunto de dados mostra 275 sites a citar explicitamente a Diretiva 2019/790 e 87 a mencionar “TDM” — concentrados em sites europeus de notícias, onde aparecem como um preâmbulo jurídico de 4 a 8 linhas.
A Cloudflare transformou o alternador em produto. Em 2024–2025, a Cloudflare lançou um painel de “AI Audit”, um alternador “Block AI Bots” e um modelo gerido de robots.txt com a taxonomia Content-Signal: search=yes,ai-train=no e texto-base sobre a UE 2019/790. Em maio de 2026, o modelo já corria em 4,5% dos top 10 mil analisáveis. O roadmap da Cloudflare fala publicamente em deixar esse alternador ativado por defeito para contas novas — o que aumentaria a taxa global de bloqueio em 5 a 8 pontos sem que um único publisher tomasse uma decisão individual.
Em 2026, robots.txt já não é o ficheiro de configuração sem glamour que era em 2022. É um mecanismo de reserva de direitos de autor com respaldo de tratado na UE, um artefacto de política moldado por fornecedor na cauda longa e a linha da frente de uma negociação lenta entre quem opera sites e quem treina modelos.
II. Metodologia
Tentámos tornar isto o mais aborrecido e reproduzível possível. O pipeline completo (scripts Python, CSVs analisados, ficheiro bruto de robots.txt, gráficos) está publicado junto com este relatório.
Amostra
Partimos da lista Tranco de maio de 2026, descarregada como top-1m.csv.zip, e recortámos as 10.000 primeiras linhas. O Tranco agrega quatro rankings de origem (Cisco Umbrella, Majestic, Farsight e Cloudflare Radar), filtra estabilidade numa janela de 30 dias e remove ruído evidente de crawlers/CDNs. A lista resultante é o que mais se aproxima de um “top 10 mil global do tráfego web” canónico disponível em aberto, e é a amostra padrão para pesquisa académica sobre web (usada em mais de 600 artigos revistos por pares desde o seu lançamento pela KU Leuven em 2018).
A lista mistura (a) sites principais acedidos por pessoas, (b) domínios de infraestrutura / API / DNS / CDN que não servem conteúdo em /, e (c) domínios usados internamente por grandes plataformas (por exemplo, gvt1.com, apple-dns.net, googleusercontent.com). Em vez de os pré-filtrarmos, mantivemo-los todos e marcámo-los com a categoria infrastructure na camada de análise. Eles desaparecem naturalmente quando restringimos a “sites que devolveram um robots.txt analisável”.
Recolha
Para cada um dos 10.000 domínios, fizemos um GET /robots.txt assíncrono via HTTPS, com fallback para HTTP, redirecionamentos seguidos por até quatro saltos, timeout total de 12 segundos, limite de corpo de 500 KB e uma string de User-Agent de navegador real, com Accept-Language: en-US. A concorrência ficou em 80 pedidos simultâneos. O trabalho correu a partir de um único IP residencial em San Francisco.
O resultado da recolha:
| Estado | Quantidade | Interpretação |
|---|---|---|
200 OK | 6.638 | Corpo de robots.txt devolvido e analisável. |
404 Not Found | 610 | Não existe robots.txt. A RFC 9309 define isto como um “permitir tudo” implícito. |
403 Forbidden | 563 | A origem rejeita ativamente pedidos para robots.txt. Excluído da análise. |
429 Too Many Requests | 7 | Quase nenhum throttling ao nível da CDN neste patamar de ranking. |
fetch_failed (erro TLS / DNS / TCP) | 2.065 | Principalmente domínios apex de CDN (akamai.net, cloudfront.net, fastly.net, gtld-servers.net, apple-dns.net) que não executam servidor web em /. Não estão “bloqueados” — simplesmente não têm robots.txt para servir. |
| Outros 4xx/5xx | 117 | Mistos — erros de servidor, geofencing, respostas malformadas. |
Isto dá-nos 7.248 sites na amostra analisável (6.638 200 + 610 404). Os 2.065 fetch_failed são domínios reais, mas são pontos apex de CDN/DNS, não sites que as pessoas visitam; tratá-los como se tivessem uma “política de IA” não faz sentido. Ficam no conjunto de dados como uma estatística separada de acessibilidade.
Parsing
Todo o corpo 200 foi analisado com protego, uma implementação em Python da RFC 9309 usada em produção pelo Scrapy. Para cada par (site, bot), calculámos três coisas:
can_fetch_root— se o bot pode aceder a/, com a semântica padrão de grupos da especificação, precedência da regra de correspondência mais longa e a substituição deUser-agent: *por um bloqueio específico do bot quando ambos existem.has_specific_rule— se o ficheiro contém uma linhaUser-agent:que nomeia exatamente esse bot (sem diferenciar maiúsculas de minúsculas).disallow_count— quantas diretivasDisallow:existem no bloco correspondente, usadas para distinguir bans totais do site de restrições por caminho.
Esta combinação importa porque uma taxa geral de “bloqueio” esconde dois fenómenos bem diferentes: marcas que intencionalmente escreveram User-agent: GPTBot \n Disallow: / porque decidiram reagir, e marcas cujo bloqueio genérico User-agent: * \n Disallow: / (configurado anos atrás para staging ou manutenção) também acaba por proibir qualquer bot de IA que não existia quando o modelo foi criado. Ao longo deste relatório, o número de “qualquer bloqueio de IA” inclui os dois casos; o número de “bloqueio explícito de IA” é o subconjunto intencional.
Bots em escopo
Rastreámos 25 bots, agrupados em três categorias:
- Crawlers de treino de IA (16):
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Meta-ExternalAgent,Bytespider,Applebot-Extended,Diffbot,Amazonbot,ImagesiftBot,FacebookBot,cohere-ai,AI2Bot,Omgili,Omgilibot. - Bots de inferência / recuperação em tempo real de IA (7):
PerplexityBot,Perplexity-User,ChatGPT-User,OAI-SearchBot,ClaudeBot(que serve tanto treino como inferência),YouBot,DuckAssistBot. - Base de pesquisa (6):
Googlebot,Bingbot,DuckDuckBot,Slurp(Yahoo),Baiduspider,YandexBot.
Alguns bots ficam na fronteira entre treino e inferência. ClaudeBot é o exemplo mais importante — a Anthropic descontinuou o UA antigo anthropic-ai em 2024 e agora usa ClaudeBot tanto para treino como para recuperação em tempo real; assim, uma regra Disallow: ClaudeBot já não corresponde de forma limpa a “bloquear treino, mas manter visibilidade”. Mantivemos a atribuição como está e apontamos a consequência mais adiante.
Classificação setorial
Classificámos cada domínio numa de 16 categorias (news, social, streaming, ecommerce, search, finance, infrastructure, saas, academia, dev, gov, adult, gambling, travel, telecom, unknown) usando uma abordagem em camadas:
- Dicionário de domínios conhecidos — um mapa curado manualmente com cerca de 500 domínios de alto tráfego por setor.
- Padrões de TLD / sufixo —
.gov→gov,.edue.ac.*→academia, sufixos de CDN reconhecidos →infrastructure. - Palavras-chave no nome do domínio — news, post, shop, bank, porn, casino etc. como sinais de recurso.
- Leitura da homepage — para sites que as três primeiras camadas não conseguiam classificar e que devolviam
200emrobots.txt, descarregámos o HTML da página inicial, extraímos<title>,<meta name="description">,<meta property="og:type">e corremos uma pontuação por palavras-chave contra pistas de categorias em estilo de modelo de linguagem.
Isto produziu 3.407 sites (34%) com etiquetas setoriais confiáveis e 6.593 deixados como unknown. A categoria unknown é dominada por portais regionais não ingleses, sites corporativos em .com que não encaixam numa única categoria e meios tradicionais de mercados de menor escala para os quais não tínhamos entradas no dicionário. Quando este relatório cita uma percentagem por setor, o denominador é a amostra classificada desse setor, e não os 10.000 sites completos.
III. Resultados
Conclusão 1 — Um em cada cinco sites de maior tráfego bloqueia pelo menos um bot de IA
Entre os 7.248 sites analisáveis, 1.472 (20,31%) bloqueiam pelo menos um bot de IA. 1.230 (16,97%) têm uma regra deliberada e específica para IA. A base de Googlebot é 2,18% (158 sites — a maioria deles bloqueando tudo como padrão de manutenção ou, em três casos, sendo motores de busca a bloquear concorrentes).
A taxa principal de 20% é 9× a base de Googlebot. Isso é um sinal real — sites de alto tráfego têm muito mais probabilidade de bloquear um crawler de IA do que um crawler de pesquisa —, mas também é um número bem menor do que a narrativa de “o bloqueio de IA já está a chegar à adoção universal” que circula na imprensa desde 2024. Mesmo nos 10.000 sites mais visitados da web, a maioria de cinco em cada seis não diz nada sobre IA.
A diferença entre “qualquer bloqueio de IA” (20,3%) e “bloqueio explícito de IA” (17,0%) é pequena em termos absolutos, mas conceitualmente importante. A diferença de 3,3 pontos é a parcela de sites que bloqueia bots de IA apenas porque a regra já existente User-agent: * \n Disallow: / apanha tudo o que passa, incluindo bots que não existiam quando foi escrita. O número deliberado de 17,0% é a leitura mais limpa de “quantos dos maiores sites do mundo tomaram uma decisão específica sobre IA”.
Em comparação com a literatura anterior:
| Fonte | Data | Amostra | Taxa de bloqueio |
|---|---|---|---|
| Originality.ai | Mar 2025 | 1.000 notícias mais populares (em inglês) | 35,7% bloqueiam GPTBot |
| Palewire | Ago 2024 | 1.500 veículos de notícias | 36,0% de qualquer crawler de IA |
| Reuters Institute | Primavera de 2025 | 50 marcas líderes de notícias, 10 países | 78% de qualquer crawler de IA |
| WIRED / NYT | Final de 2023 | Top 50 notícias dos EUA | 26% bloqueiam GPTBot |
| Este relatório (Thunderbit) | Mai 2026 | Tranco top 10.000 (todos os setores) | 20,3% / 17,0% explícito |
O nosso 17,0% explícito é menor do que todos os estudos focados só em notícias porque dois terços da amostra não são notícias. Restrito aos 650 sites de notícias, chegamos a 47% — dentro da mesma faixa dos estudos anteriores quando se tem em conta a composição da amostra. O quadro estrutural é consistente: o grupo das notícias bloqueia IA a uma taxa 3 a 4 vezes superior ao resto da web.
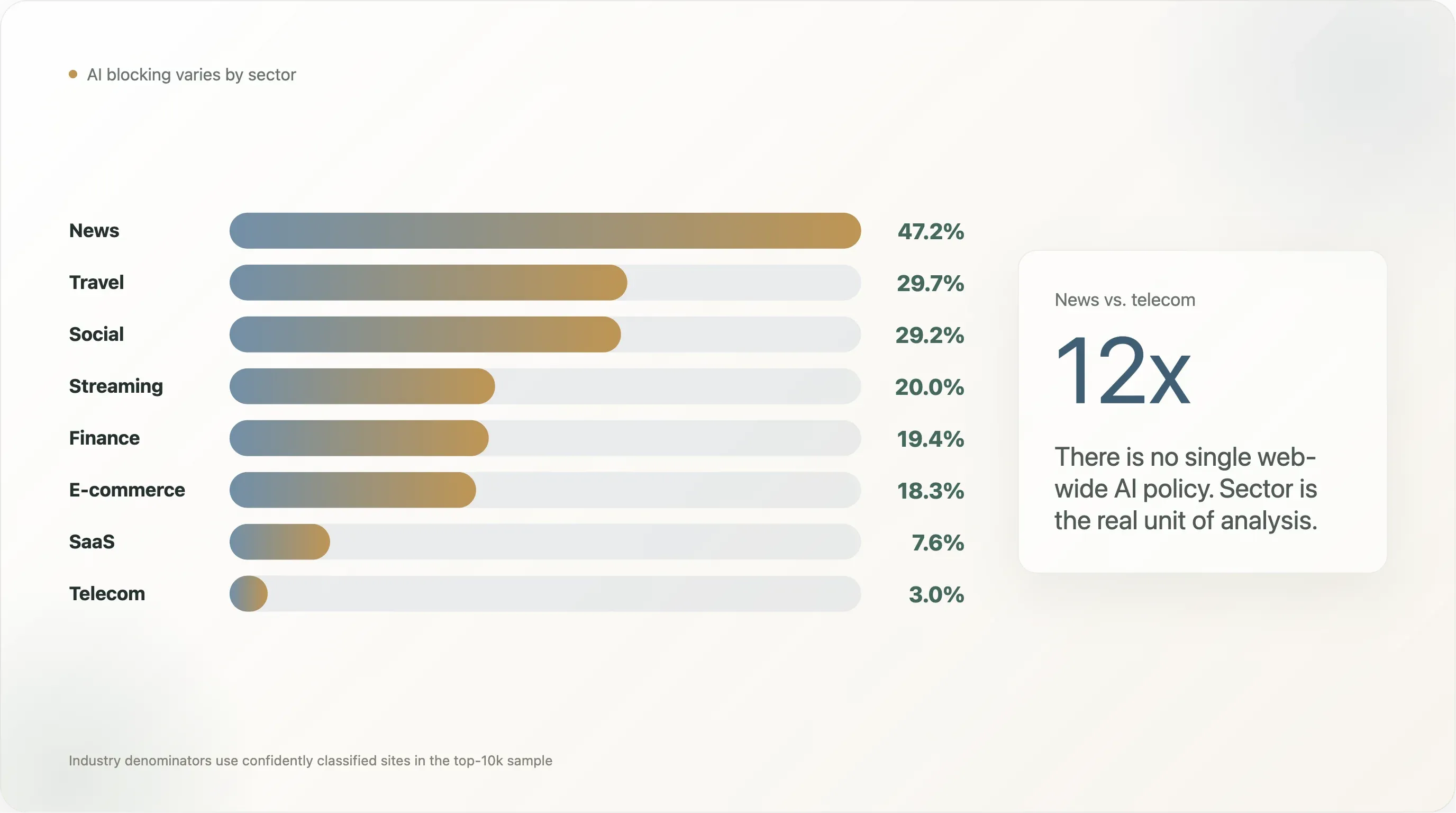
Conclusão 2 — Análises setoriais: uma variação de 12× entre notícias e telecom
A descoberta mais citada em dois anos de cobertura sobre “web scraping com IA” tem sido o número de 80% das redações bloqueiam GPTBot vindo de Originality.ai e Palewire. O nosso recorte gera um valor menor, mas ainda assim distinto: 47,2% dos sites de notícias no top 10.000 bloqueiam pelo menos um bot de IA, com 45,2% a escrever uma regra explícita de IA.
Mas “notícias vs. tudo o resto” é um corte demasiado grosseiro. A distribuição completa (setores com n ≥ 10 na amostra) conta uma história muito mais rica:
| Setor | n | Qualquer bloqueio de IA | Explícito | Googlebot bloqueado | Regras próprias | Cloudflare Managed | Silencioso |
|---|---|---|---|---|---|---|---|
| Notícias | 650 | 47,2% | 45,2% | 1,5% | 46,9% | 1,5% | 48,5% |
| Viagens | 64 | 29,7% | 29,7% | 0,0% | 35,9% | 3,1% | 54,7% |
| Social | 65 | 29,2% | 23,1% | 4,6% | 23,1% | 6,2% | 66,2% |
| Streaming | 440 | 20,0% | 17,7% | 0,7% | 16,8% | 3,6% | 75,5% |
| Finanças | 129 | 19,4% | 12,4% | 0,8% | 14,7% | 2,3% | 75,2% |
| E-commerce | 224 | 18,3% | 17,4% | 0,4% | 24,1% | 1,3% | 66,1% |
| Adulto | 254 | 17,3% | 14,6% | 0,4% | 10,2% | 7,9% | 79,5% |
| Busca | 12 | 16,7% | 0,0% | 0,0% | 0,0% | 0,0% | 100,0% |
| Academia | 268 | 14,6% | 13,8% | 0,4% | 13,4% | 3,4% | 77,2% |
| Jogos de azar | 100 | 14,0% | 13,0% | 0,0% | 18,0% | 4,0% | 77,0% |
| Ferramentas para dev | 129 | 10,1% | 7,8% | 0,0% | 8,5% | 5,4% | 77,5% |
| SaaS | 369 | 7,6% | 6,2% | 0,3% | 9,5% | 0,8% | 87,5% |
| Governo | 172 | 5,2% | 3,5% | 0,0% | 4,1% | 0,6% | 83,1% |
| Infrastructure | 47 | 4,3% | 0,0% | 0,0% | 4,3% | 2,1% | 72,3% |
| Telecom | 33 | 3,0% | 3,0% | 0,0% | 12,1% | 0,0% | 78,8% |
A variação de 12× entre notícias e telecom é o que torna “a política de IA da web” uma unidade errada de análise. Não existe um único número; existem números setoriais que divergem por uma ordem de grandeza. Abaixo, detalhamos as quatro descobertas mais marcantes.
Notícias: 47% a bloquear, 47% com regras próprias. O setor de notícias é o que escreveu o manual. O Cloudflare Managed aparece em apenas 1,5% no setor de notícias — estes publishers não terceirizam a regra. O texto é excecionalmente rico: o NYT abre com um preâmbulo jurídico de 14 linhas citando “Art. 4 da Diretiva da UE”; a BBC com “Please use our site like a human, not a robot... TL;DR: Browse, read, watch, enjoy — like a human.”; The Sun com “The Sun does not permit the unlicensed use of our content for large language models.” Isto é robots.txt como declaração de política, não como configuração.
Viagens em 30% — a surpresa. Booking, Expedia, TripAdvisor, Kayak e as grandes companhias aéreas bloqueiam a dois terços da taxa das notícias. O padrão seletivo é consistente: o bloqueador médio de viagens desautoriza 5 a 7 UAs de treino, mas deixa intocados os UAs de inferência (PerplexityBot, ChatGPT-User, OAI-SearchBot). Dados agregados de preços e avaliações são o moat; citações de volta para o site são o upside. Este é o padrão mais limpo de “treino fora, inferência dentro” em qualquer setor individual.
Adulto em 17% — outra surpresa. Amostras menores anteriores mostravam 0%. Os dados da amostra completa mostram que 1 em cada 6 sites adultos desautoriza pelo menos um bot de IA, com a maior taxa de Cloudflare Managed de qualquer setor (7,9%). Mais de metade dos bloqueios de IA em sites adultos vem do alternador da Cloudflare, não de decisão do publisher. O treino para geração de imagens é a ameaça implícita — modelos do tipo Stable Diffusion aprendem estilo visual mais depressa do que modelos de texto aprendem estilo de escrita.
SaaS em 7,6% é contraintuitivo. Fornecedores de software são o segmento mais barulhento no discurso sobre políticas de IA, mas o robots.txt deles está amplamente aberto. A leitura correta: as equipas de marketing de SaaS identificaram corretamente a pesquisa com IA como canal de distribuição. Os fornecedores que realmente pensaram nisto estão a entrar, não a sair — a lista de Allow: / explícito para GPTBot (Conclusão 12) é dominada por segurança e SaaS de ferramentas para dev.
Governo 5,2%, telecom 3,0%, infrastructure 4,3%, dev 10,1%. Mandatos de registos públicos tornam Disallow: / juridicamente delicado em domínios .gov. Sites de marketing de telecom querem ser descobertos. Domínios apex de CDN não têm nada a proteger. Ferramentas para dev fazem opt-in explícito (o conteúdo ganha valor quando LLMs o citam).
A conclusão: não existe um único número “a web bloqueia / não bloqueia IA” que não perca mais do que comunica. Reportar dados por setor é a única forma honesta de falar sobre o tema.
Conclusão 3 — Por fornecedor de IA: quem está a ser mais bloqueado?
Outro recorte natural dos dados é por empresa de IA, e não por bot. Vários fornecedores operam múltiplos bots (a OpenAI opera três: GPTBot, ChatGPT-User, OAI-SearchBot; a Anthropic opera dois: ClaudeBot, anthropic-ai; a Meta opera dois: Meta-ExternalAgent, FacebookBot). Agregar ao nível do fornecedor é a forma mais próxima que temos de responder “o que pensa a web pública de cada empresa de IA?”.
| Fornecedor de IA | Bots agregados | Sites bloqueando ≥ 1 bot | % da amostra analisável |
|---|---|---|---|
| Common Crawl | CCBot | 1.178 | 16,25% |
| OpenAI | GPTBot, ChatGPT-User, OAI-SearchBot | 1.172 | 16,17% |
| Anthropic | ClaudeBot, anthropic-ai | 1.111 | 15,33% |
| ByteDance | Bytespider | 1.082 | 14,93% |
| Meta | Meta-ExternalAgent, FacebookBot | 989 | 13,65% |
Google-Extended | 970 | 13,38% | |
| Amazon | Amazonbot | 877 | 12,10% |
| Apple | Applebot-Extended | 859 | 11,85% |
| Webz.io (Omgili) | Omgili, Omgilibot | 731 | 10,09% |
| Cohere | cohere-ai | 717 | 9,89% |
| Perplexity | PerplexityBot, Perplexity-User | 715 | 9,86% |
| Diffbot | Diffbot | 684 | 9,44% |
| You.com | YouBot | 563 | 7,77% |
| AI2 (Allen AI) | AI2Bot | 487 | 6,72% |
| DuckDuckGo | DuckAssistBot | 482 | 6,65% |
Common Crawl é a única entidade mais visada, embora seja um arquivo web sem fins lucrativos, não um operador de LLM. A razão é o efeito de alavanca: CCBot alimenta quase todos os modelos de pesos abertos e uma parte substancial dos fechados. Bloquear CCBot primeiro é a regra de maior cobertura que um publisher pode escrever.
OpenAI, Anthropic e ByteDance ficam agrupadas entre 14% e 16%. A liderança da OpenAI é em parte um artefacto de contagem (três bots da OpenAI contra um da ByteDance). Os 14,9% de Bytespider são o efeito “comportamento de Bytespider” — há documentação de que ignora robots.txt desde 2024, e os publishers bloqueiam-no como sinal público, não porque estejam preocupados com o TikTok.
Meta, Google, Amazon e Apple, entre 12% e 14%, formam a segunda faixa — regras escritas de forma defensiva, não como manifestação de posição. Fornecedores menores (Webz.io, Cohere, Perplexity, Diffbot, You.com, AI2, DuckDuckGo), entre 6% e 10%, são puxados sobretudo pelo piso genérico de 3,8%; regras explícitas para eles ficam na faixa de 1% a 4%.
xAI (Grok), Mistral e a maioria dos laboratórios europeus/asiáticos de modelos estão ausentes da tabela — não publicaram UAs documentados de crawler de treino. O ecossistema atual de robots.txt é um diálogo entre fornecedores dos EUA/China que lançaram UAs e publishers dos EUA/UE que escreveram as regras; quem não lançou UA não entra na negociação.
Conclusão 4 — CCBot é o novo ponto de mira, não GPTBot
A ordem dos bots no top-10k é esta:
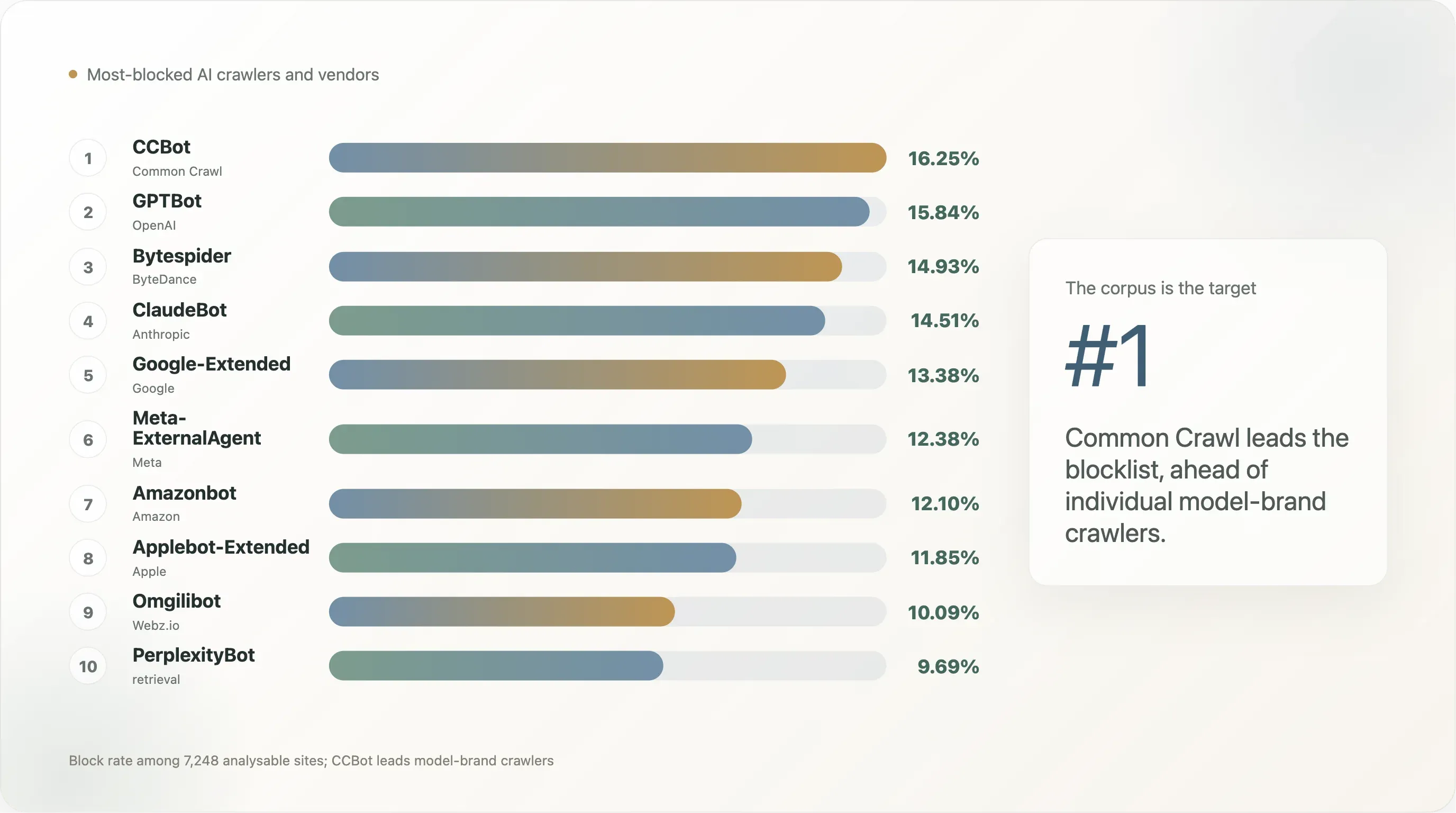
| Posição | Bot | Taxa de bloqueio | Taxa de regra explícita |
|---|---|---|---|
| 1 | CCBot (Common Crawl) | 16,25% | 12,90% |
| 2 | GPTBot (OpenAI) | 15,84% | 12,72% |
| 3 | Bytespider (ByteDance) | 14,93% | 11,35% |
| 4 | ClaudeBot (Anthropic) | 14,51% | 11,13% |
| 5 | Google-Extended | 13,38% | 10,18% |
| 6 | Meta-ExternalAgent | 12,38% | 8,95% |
| 7 | Amazonbot | 12,10% | 8,66% |
| 8 | Applebot-Extended | 11,85% | 8,72% |
| 9 | Omgilibot | 10,09% | 5,31% |
| 10 | anthropic-ai (obsoleto) | 9,99% | 6,55% |
| 11 | cohere-ai | 9,89% | 6,42% |
| 12 | PerplexityBot | 9,69% | 6,40% |
| 13 | Diffbot | 9,44% | 5,95% |
| 14 | ChatGPT-User (inferência) | 8,90% | 5,73% |
| 15 | YouBot (inferência) | 7,77% | 4,29% |
| 16 | OAI-SearchBot (inferência) | 6,83% | 3,66% |
| base | Googlebot | 2,18% | — |
| base | Bingbot | 2,27% | — |
A mensagem desta tabela é que o bot que a web pública bloqueia primeiro não é a marca do modelo — é o corpus. O ficheiro de 250 mil milhões de páginas da Common Crawl foi a maior entrada de treino para GPT-3, GPT-4, Llama 1 / 2 / 3, Falcon, Mistral, BLOOM e a maioria dos modelos de pesos abertos lançados desde 2020. Um site que quer sair de “estar no próximo modelo de fronteira” otimiza bloqueando primeiro o CCBot — uma vez fora da Common Crawl, fica efetivamente fora do pipeline de treino open source, de graça. GPTBot e ClaudeBot vêm em segundo e terceiro lugares porque são a face visível de dois produtos comerciais específicos; o UA ao nível do corpus é o alvo estrutural.
Os bots de IA mais abaixo na tabela também são informativos. Omgilibot com 10% é invulgarmente alto para um bot que a maioria dos leitores nem conhece — é operado pela Webz.io, uma corretora de dados de conteúdo que vende arquivos web para operadores de LLM, e uma fatia relevante de veículos de notícias passou a nomeá-lo explicitamente nos ficheiros. AI2Bot com 6,7% (e uma regra correspondente Ai2Bot-Dolma em sites Squarespace) sugere que a comunidade académica de LLM também está a entrar na mira de publishers que não distinguem necessariamente “crawler de pesquisa sem fins lucrativos” de “crawler comercial.”
O grupo de inferência — ChatGPT-User, OAI-SearchBot, YouBot, Perplexity-User — fica 4 a 8 pontos percentuais abaixo do grupo de treino. Essa diferença responde a uma pergunta de política que se arrasta há algum tempo: sim, sites de alto tráfego distinguem entre um bot a recolher dados para treino futuro do modelo e um bot a fazer recuperação em tempo real para responder à pergunta de um utilizador agora. Nem sempre fazem essa distinção (as regras genéricas não o fazem), mas uma parte relevante escreve regras que visam especificamente o lado do treino.
Conclusão 5 — 14% bloqueiam CCBot e mantêm Googlebot bem-vindo — o padrão “bloqueie o corpus, mantenha a pesquisa”
A regra seletiva com maior adoção no top-10k:
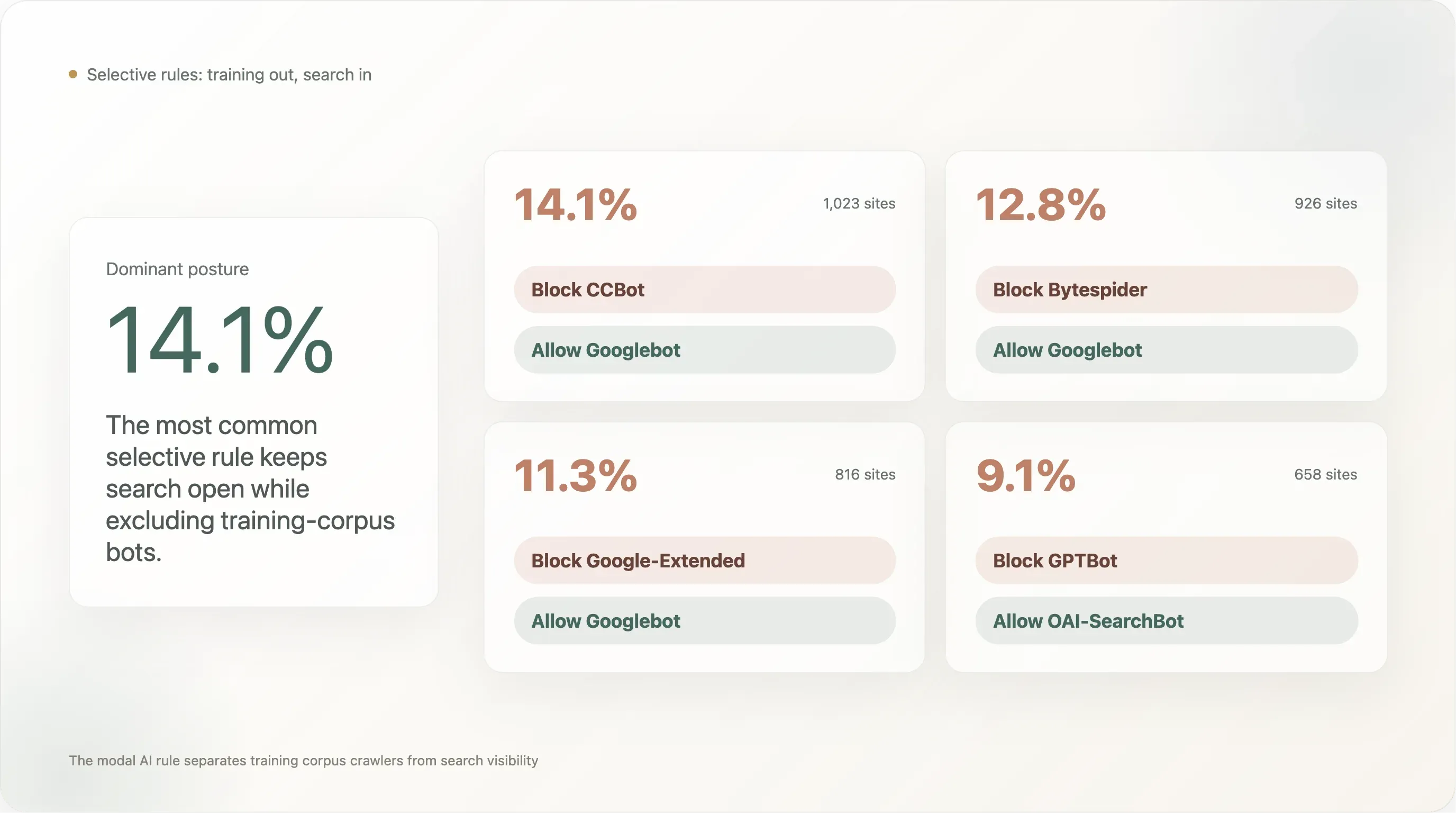
| Padrão de regra | Sites | % da amostra analisável |
|---|---|---|
Bloquear CCBot, permitir Googlebot | 1.023 | 14,11% |
Bloquear Bytespider, permitir Googlebot | 926 | 12,78% |
Bloquear Google-Extended, permitir Googlebot | 816 | 11,26% |
Bloquear GPTBot, permitir OAI-SearchBot | 658 | 9,08% |
Bloquear GPTBot, permitir ChatGPT-User | 525 | 7,24% |
Bloquear CCBot, permitir PerplexityBot | 519 | 7,16% |
Bloquear anthropic-ai, permitir ClaudeBot | 59 | 0,81% |
O padrão mais adotado (14,1%) é “bloquear Common Crawl, manter visibilidade na pesquisa da Google.” O segundo colocado (12,8%) é “bloquear Bytespider, manter visibilidade na pesquisa da Google” — ou seja, bloquear o rastreador da ByteDance com má reputação, sem mexer na base legítima de pesquisa. O terceiro (11,3%) é “bloquear o UA de treino de IA da Google, mantendo o UA de pesquisa da Google”, que é exatamente o corte para o qual a Google desenhou o Google-Extended: o publisher sai do treino do Bard / Gemini sem perder ranking de pesquisa.
Estes três números, em conjunto, descrevem a postura de política dominante na web top-10k: desautorizar os bots do corpus de treino e deixar intocados os bots de pesquisa e inferência. O padrão minoritário de “desautorizar treino, mas permitir o UA específico de recuperação em tempo real deste LLM” — GPTBot ✗ / ChatGPT-User ✓ em 7,2% — existe, mas é menor do que os cortes ao nível do corpus.
A linha anthropic-ai / ClaudeBot em 0,81% reflete a descontinuação do UA da Anthropic em 2024: ClaudeBot agora serve tanto treino como inferência, eliminando a expressão limpa “bloquear treino, permitir citação” que o antigo anthropic-ai permitia para Claude. Esta é a decisão de design de UA menos discutida de 2024–2025 — removeu uma classe inteira de expressão de política do robots.txt.
Conclusão 6 — Notícias em detalhe: por país e idioma
Quando dividimos a categoria de notícias por TLD de código de país — lembrando que isto significa .de para notícias alemãs, .fr para notícias francesas etc., e não o idioma servido —, a variação dentro do próprio setor de notícias é maior do que a variação entre notícias e o restante:
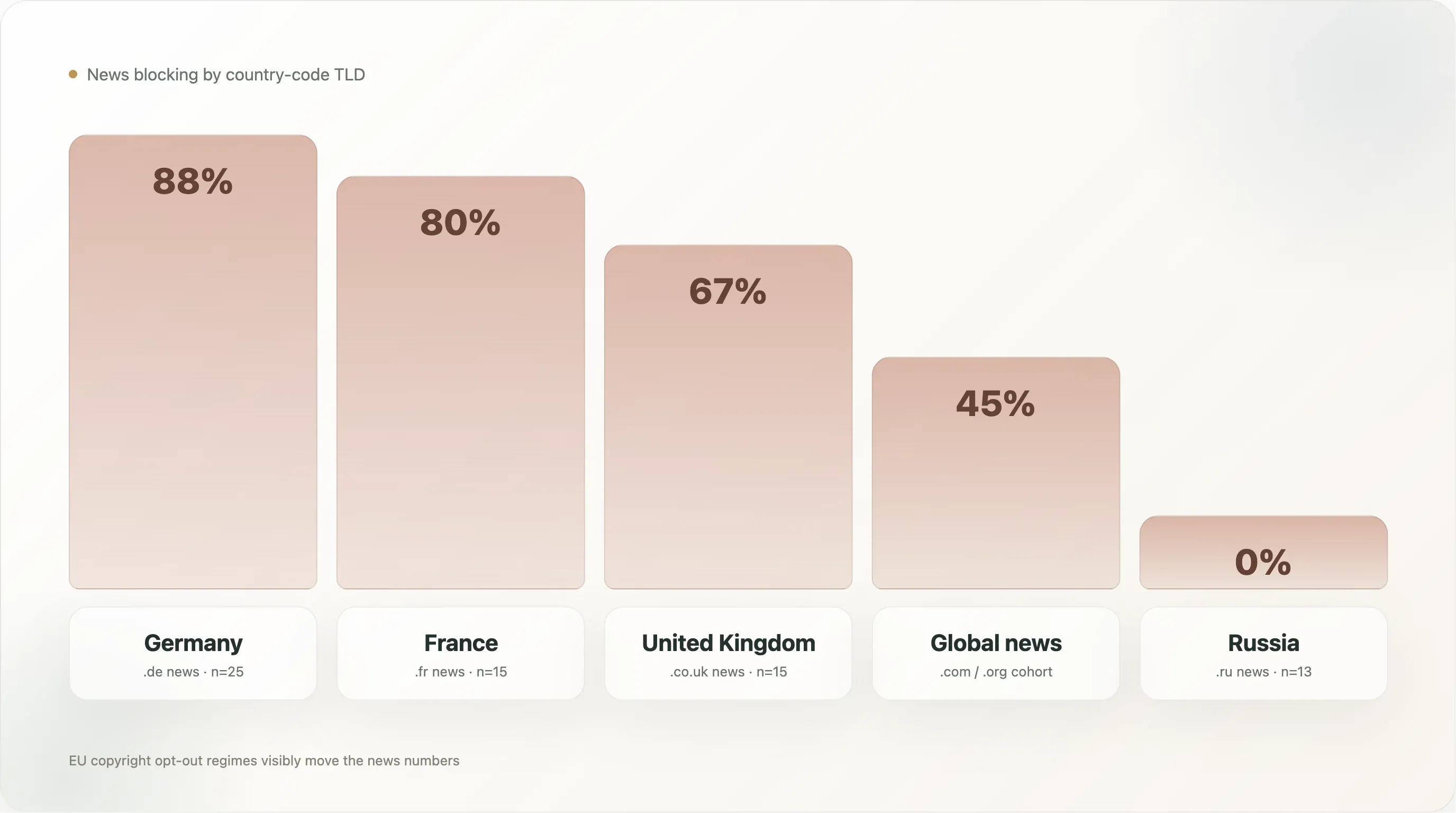
| País (apenas notícias) | n | Qualquer bloqueio de IA | Explícito |
|---|---|---|---|
🇩🇪 Alemanha (.de) | 25 | 88,0% | 88,0% |
🇫🇷 França (.fr) | 15 | 80,0% | 80,0% |
🇬🇧 Reino Unido (.co.uk) | 15 | 66,7% | 53,3% |
🇪🇸 Espanha (.es) | 5 | 60,0% | 60,0% |
🇮🇹 Itália (.it) | 13 | 53,8% | 53,8% |
Notícias globais (.com/.org/etc) | 500 | 45,0% | 42,8% |
🇵🇱 Polónia (.pl) | 7 | 42,9% | 42,9% |
🇯🇵 Japão (.jp) | 12 | 25,0% | 25,0% |
🇷🇺 Rússia (.ru) | 13 | 0,0% | 0,0% |
🇬🇷 Grécia (.gr) | 6 | 0,0% | 0,0% |
As notícias alemãs são o subsegmento que mais bloqueia em todo o conjunto, com 88%, e 88% desse total é explícito — praticamente não existe veículo de notícias alemão no top 10 mil que deixe crawlers de treino de IA aceder ao seu acervo. O grupo é liderado por Spiegel, Bild, Welt, Zeit, FAZ, Süddeutsche, Heise, Golem, Stern, Focus — toda a grande imprensa alemã, além de publishers de tecnologia que escreveram as suas próprias regras. A infraestrutura política por trás disto é densa: a VG Media, organização coletiva de direitos dos publishers alemães, tem sido o grupo de autores mais agressivo em litígios de copyright de IA na UE, e o Artigo 4 da Diretiva da UE é implementado no direito alemão como §44b UrhG, com linguagem explícita de opt-out legível por máquina. Quando os fornecedores de IA chegaram, os publishers alemães eram o grupo nacional mais preparado para traduzir essa postura jurídica em regras de robots.txt.
As notícias francesas, com 80%, ficam logo atrás. O ambiente jurídico francês é semelhante (a Diretiva 2019/790 foi transposta para a lei francesa), e o comportamento do grupo também — lemonde.fr, lefigaro.fr, liberation.fr, lequipe.fr, 20minutes.fr, ouest-france.fr bloqueiam, com o ficheiro do Le Monde ainda a citar o droit du producteur de base de données francês (Artigo L 342-1 do Code de la propriété intellectuelle) como base jurídica doméstica paralela. A França tem ainda uma decisão de 2024 do tribunal comercial de Paris que afirma que opt-outs baseados em robots.txt constituem aviso suficiente ao abrigo do Artigo 4; isso oferece respaldo direto de jurisprudência que nenhuma outra jurisdição igualou até agora.
O Reino Unido, com 67%, é mais baixo, e o motivo é que vários grandes publishers britânicos (thesun.co.uk, dailymail.co.uk, mirror.co.uk) usam bloqueios gerais via User-agent: * em vez de regras específicas para IA, o que baixa o número explícito para 53%. O efeito agregado é o mesmo — estes sites não permitem crawling de IA —, mas a política é expressa como “sem robôs, exceto esta lista específica de buscadores permitidos” e não como desautorização de bots de IA nomeados. A base legal também é mais fraca: após o Brexit, o Reino Unido herdou a lógica do Artigo 4, mas a jurisprudência doméstica correspondente é mais escassa.
As notícias russas, com 0%, são a linha mais surpreendente. Treze sites de notícias em domínio russo na amostra (dzen.ru, rbc.ru, ria.ru, kommersant.ru, tass.ru, lenta.ru, gazeta.ru, interfax.ru, kp.ru, tass.com, etc.) — nenhum deles bloqueia qualquer crawler de IA. A explicação provável: o treino de LLM em russo é dominado pelos próprios modelos ao estilo GPT da Yandex (que usam crawlers internos da Yandex, não a Common Crawl), o ambiente de copyright russo não adotou um equivalente ao Artigo 4, e os grandes publishers russos veem os LLMs ocidentais como irrelevantes (os controlos de exportação dos EUA já limitam os serviços da OpenAI e da Anthropic na Rússia) e a Yandex como parte interessada doméstica, não como adversária. A postura de política é simplesmente diferente.
As notícias japonesas, com 25%, mostram outro padrão. O Japão tem exceções explícitas de mineração de texto e dados na lei de copyright doméstica (Artigo 30-4 da Lei de Copyright japonesa, alterado em 2018) que são mais permissivas do que o Artigo 4 da Diretiva da UE — permitem TDM para fins “não de fruição”, incluindo treino de IA, sem exigir consentimento do titular dos direitos. Os publishers japoneses têm menos base jurídica para opt-out, e as taxas em robots.txt são mais baixas. Os 25% que bloqueiam são, na sua maioria, os publishers mais grandes e cosmopolitas (asahi.com, nikkei.com), posicionados de forma mais internacional do que doméstica.
Os dados de notícias por país são a evidência mais clara do relatório de que o regime jurídico, não a tecnologia nem a economia do setor, é o principal motor do bloqueio de IA. Os grupos de notícias da UE ficam entre 54% e 88%; os grupos fora da UE (Rússia, Japão, o grupo global .com) variam de 0% a 45%. O pico de 88% está no país com a implementação mais madura do Artigo 4; o piso de 0% está no país praticamente sem lei de política de IA.
Conclusão 7 — UE vs. resto: uma diferença de 16 pontos
Ampliando a lente por país para o nível regional, a divisão UE vs. resto é nítida:
| Região | n | Qualquer bloqueio de IA | Explícito |
|---|---|---|---|
ccTLDs da UE (.fr, .de, .es, .it, .nl, .pl, .se, .dk, .fi, .be, .at, .cz, .hu, .ro, .gr, .pt, .ie, .sk, .bg) | 617 | 35,2% | 33,9% |
ccTLDs nacionais fora da UE (.uk, .jp, .kr, .cn, .ru, .br, .in, .au, .mx, .ca, .tr, .ar, .cl, .co, .pe) | 897 | 17,2% | 13,6% |
Global (.com, .net, .org, etc.) | 5.734 | 19,2% | 15,7% |
Os sites em ccTLD da UE bloqueiam IA a uma taxa duas vezes superior ao grupo nacional fora da UE e quase o dobro da média global de .com. A diferença é consistente entre os estados-membros da UE (nenhum país isolado puxa a média sozinho) e consistente entre setores (.de notícias em 88%, .de SaaS em cerca de 12%, .de e-commerce em cerca de 25% — todos acima dos correspondentes globais).
Encontrámos 275 arquivos robots.txt no top-10k que citam explicitamente a Diretiva 2019/790 nos comentários — cerca de 3,8% da amostra analisável. O grupo é dominado por publishers da UE, mas vai além deles: várias marcas de notícias dos EUA (principalmente o NYT, que cita diretamente “Art. 4 da Diretiva da UE”), alguns sites do Reino Unido e alguns destinos maiores de e-commerce europeus reproduzem a linguagem jurídica. 87 arquivos mencionam “TDM” ou “text and data mining” pelo nome. 460 arquivos contêm algum tipo de linguagem de reserva de direitos de autor (“expressly opts out”, “all rights reserved”, “no commercial use”, “no machine learning”), mesmo quando não citam uma lei específica.
Dois observações mais granulares deste recorte:
O efeito UE não se limita às notícias. Mantendo notícias constantes, os sites não jornalísticos da UE ainda bloqueiam IA a taxas mais altas do que os não jornalísticos fora da UE (cerca de 28% contra 14%). Uma parcela pequena, mas real, de SaaS, e-commerce e academia da UE internalizou o quadro do Artigo 4 para os seus próprios setores.
A linguagem com sabor de UE está a tornar-se template de facto mesmo fora da UE. O modelo gerido de robots.txt da Cloudflare — adotado globalmente — cita explicitamente “ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790” no seu texto-base. Um site dos EUA que ativa o “Block AI Bots” da Cloudflare está, sem necessariamente o saber, a afirmar uma reserva legal de direitos baseada em estatuto da UE. Este é um dos artefactos mais interessantes de deriva de política que encontrámos: um conceito jurídico europeu está a ser globalizado através da interface de produto de um fornecedor de infraestrutura dos EUA.
Conclusão 8 — Modelos e origem dos templates
A distribuição de origem dos templates nos 6.638 sites que devolveram um robots.txt analisável:
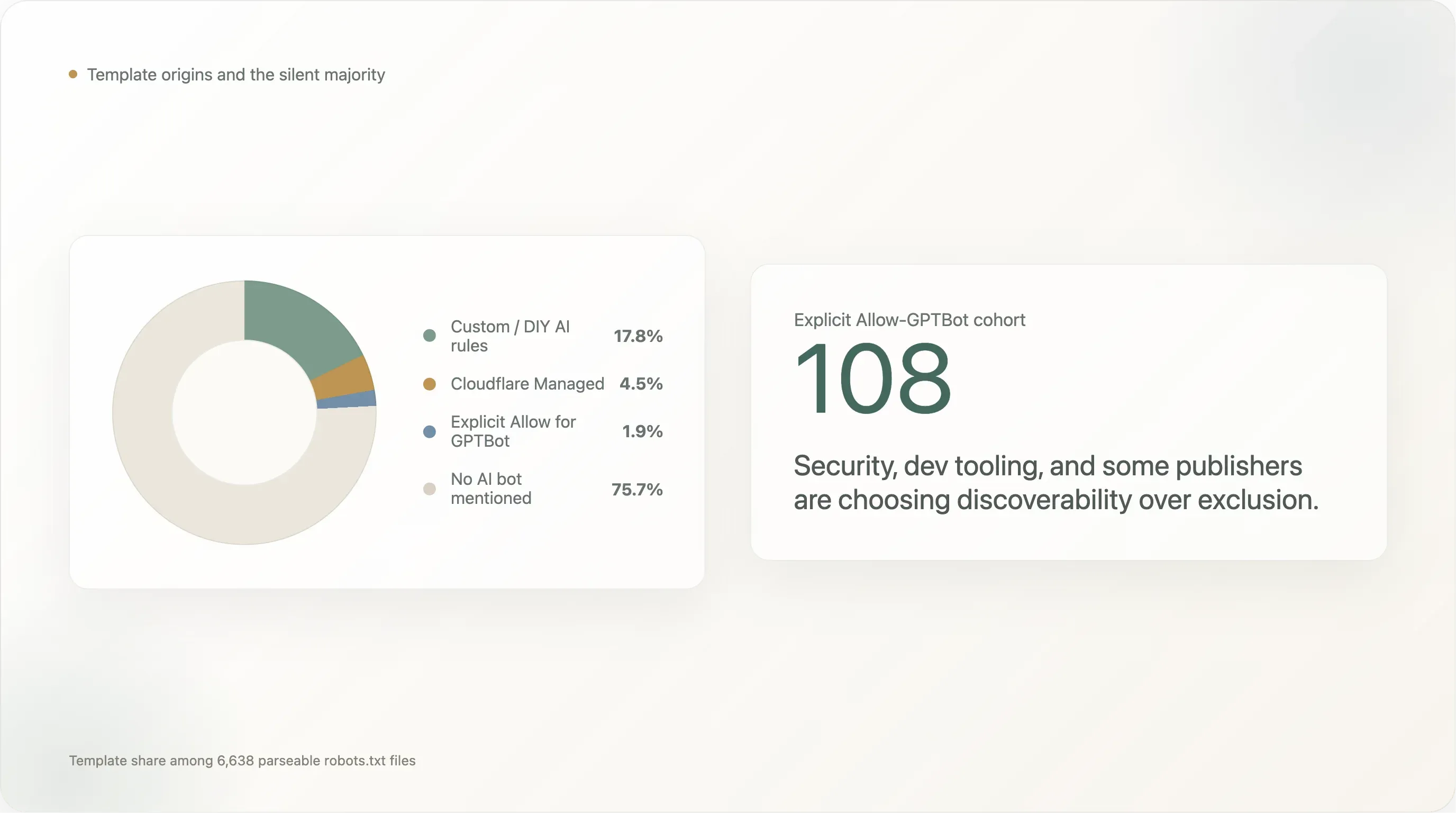
| Template | Sites | Participação |
|---|---|---|
| Nenhum bot de IA mencionado (padrão tipo Shopify, Yoast, ou escrito à mão sem considerar IA) | 5.024 | 75,7% |
| Regras próprias / DIY de IA | 1.183 | 17,8% |
Cloudflare Managed (Content-Signal: search=yes,ai-train=no) | 302 | 4,5% |
Allow: / explícito para GPTBot | 124 | 1,9% |
| Padrão Squarespace (28 UAs de IA no bloco com restrição por caminho) | 5 | 0,1% |
As regras próprias dominam, com 17,8%. O grupo de bloqueadores escritos internamente é liderado por todas as plataformas de redes sociais (facebook.com, twitter.com, linkedin.com, whatsapp.com, tiktok.com, snapchat.com, pinterest.com, x.com, chatgpt.com em si), os maiores destinos de e-commerce (amazon.com, amazonvideo.com), as principais marcas de notícias (nytimes.com, cnn.com, bbc.com, theguardian.com, forbes.com, reuters.com, bbc.co.uk, t-online.de, weather.com), meios / streaming importantes (netflix.com, vimeo.com, soundcloud.com, imdb.com) e uma cauda longa de sites de serviços profissionais (canva.com, medium.com).
O Cloudflare Managed fica em 4,5% — bem acima da penetração do mesmo template no topo da curva e abaixo da sua penetração na cauda longa fora da janela deste relatório. O template é mais adotado no segmento de rank 1001 a 10000 (4–5%) e praticamente desaparece no topo da curva (Top 100: 1 site usa; Top 101–1000: 5 sites). As grandes propriedades globais escrevem as suas próprias regras; a cauda longa usa o alternador.
Alguns sites específicos do Cloudflare Managed merecem destaque. cloudflare.com usa o próprio template — consistente, já que a Cloudflare está a “dogfooding” o seu produto no próprio domínio. theatlantic.com usa o template — a única grande marca de notícias dos EUA que encontrámos sem uma regra customizada. spankbang.com usa o template — o site adulto mais bem posicionado a adotar um bloqueio de IA injetado pela Cloudflare. linktr.ee usa o template, bloqueando o treino de IA em toda a economia de criadores hospedada no Linktree por uma única decisão do fornecedor. launchpad.net, nexusmods.com, vinted.fr, cookielaw.org, rustdesk.com e uma longa lista de propriedades de mídia menores completam o grupo visível do Cloudflare Managed.
O padrão de adoção da Cloudflare é a evidência mais concreta que vimos de que uma grande parte da “política de IA da web” está a ser decidida por fornecedores de infraestrutura. A participação absoluta é pequena (4,5%), mas estruturalmente importante: o template é o padrão que a Cloudflare envia, e a trajetória para ativação por defeito nos próximos 12 meses é de alta. Se a Cloudflare mudar o alternador para ativado por defeito em contas novas, a taxa global de bloqueio sobe materialmente sem que qualquer publisher individual tome uma decisão.
O padrão Squarespace default (5 sites no top-10k, mas um grupo muito maior fora da nossa amostra) é diferente: a Squarespace publica um robots.txt que nomeia 28 bots de IA num único bloco, mas esses bots herdam as restrições de caminho de User-agent: * em vez de receberem um banimento global do site. Os crawlers de IA podem aceder a /, à homepage, às páginas de produto, ao blog. Só não podem aceder a /config ou /account. Já apontámos antes isto como fonte de leituras falsas de “bloqueio de IA” em varreduras de terceiros em sites Squarespace; a mesma ressalva aplica-se aqui.
Conclusão 9 — A política de IA é uniforme ao longo da distribuição de rank
A intuição convencional para este tipo de estudo é que os sites mais visitados teriam a política de IA mais agressiva — teriam mais a perder com desvio de treino, mais capacidade jurídica, mais escrutínio público. Os dados não sustentam essa intuição.
| Faixa de rank | n | Qualquer bloqueio de IA | Explícito | Cloudflare Managed |
|---|---|---|---|---|
| Top 100 | 67 | 22,4% | 17,9% | 1 site |
| Top 101–1.000 | 598 | 22,9% | 19,2% | 5 sites |
| Top 1.001–5.000 | 2.810 | 19,0% | 15,3% | 99 sites |
| Top 5.001–10.000 | 3.773 | 20,8% | 17,8% | 197 sites |
As quatro faixas ficam entre 19% e 23%. O Top 100 não é mais agressivo do que a cauda longa do rank 5001 ao 10000. A taxa principal parece ser uma característica da web pública em 2026, não um sinal do tamanho ou da proeminência de cada site individual.
Dois fatores contribuem. Primeiro, o topo da curva é dominado por domínios de infraestrutura / SaaS / pesquisa / portais (Microsoft, Apple, Google etc.) que, por si só, bloqueiam IA em menor grau. Segundo, a cauda longa inclui uma parcela elevada de publishers regionais de notícias e sites sob jurisdição da UE que — como mostraram as Conclusões 6 e 7 — bloqueiam IA com mais agressividade do que a média global. Os dois efeitos anulam-se aproximadamente, e o resultado é uma manchete uniforme.
A coluna Cloudflare Managed, porém, muda ao longo da curva. O Top 1000 tem 6 sites geridos pela Cloudflare (1,0%); o Top 1001–10000 tem 296 (5,7%). Os grandes sites escrevem as suas próprias regras; a cauda longa usa o alternador do fornecedor. Este é o único sinal verdadeiramente dependente do rank no conjunto de dados, e sugere que à medida que se desce a curva de tráfego do topo da web em direção à cauda longa, a parcela da política de IA definida pelo fornecedor, e não pelo publisher, aumenta de forma constante. Esperamos que este gradiente continue para além do top 10k, rumo ao top 100k e mais além.
Conclusão 10 — Cinco anatomias: como robots.txt fica quando é mesmo uma política
Os números descrevem a forma do conjunto de dados; o carácter real da “política de IA na web pública” aparece melhor quando lemos ficheiros específicos. Aqui estão cinco que valem a pena, escolhidos para cobrir o espaço das políticas.
Anatomia 1 — The New York Times (nytimes.com)
As primeiras 14 linhas de nytimes.com/robots.txt:
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.Isto é robots.txt como peça jurídica. O ficheiro foi estruturado para ser admissível como prova no litígio NYT v. OpenAI, do qual o jornal faz parte. As referências ao “Art. 4 da Diretiva da UE” — feitas por um publisher dos EUA — ilustram a observação da Conclusão 7 de que quadros legais da UE estão a transbordar para o discurso global. A proibição explícita de “criar ou fornecer conjuntos de dados arquivados ou em cache” visa diretamente a Common Crawl. O ficheiro tem mais de 60 linhas, com blocos nomeados de User-agent para GPTBot, OAI-SearchBot, ChatGPT-User, anthropic-ai, ClaudeBot, CCBot, Google-Extended, Applebot-Extended, Bytespider, Diffbot, Meta-ExternalAgent, Amazonbot, Omgili, Omgilibot e meia dúzia de outros — cada bot nomeado recebe o seu próprio Disallow: /.
Anatomia 2 — Der Spiegel (spiegel.de) — permissão de IA por secção
O Der Spiegel tem o robots.txt operacionalmente mais sofisticado que encontrámos em todo o conjunto. O bloco relevante:
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /O comentário significa “ativação de teste dos crawlers de pesquisa da OpenAI para secções selecionadas.” O Spiegel liberou sete categorias específicas de conteúdo — notícias internacionais, parcerias, saúde, família, viagens, psicologia e lifestyle — para os UAs de inferência da OpenAI, bloqueando todo o resto. As secções políticas, as notícias nacionais alemãs e as reportagens investigativas são explicitamente excluídas. Common Crawl, Bytespider, Cohere, Webzio-Extended e os outros UAs de treino recebem um Disallow: / integral mais abaixo no ficheiro.
Isto é robots.txt como política editorial por secção. A teoria implícita é que conteúdo de lifestyle tem menor risco de desvio de treino e maior retorno de citação na inferência, então o Spiegel permite que a IA exponha essas secções; política e jornalismo investigativo são o moat, então a IA é excluída. Não vimos este padrão em mais lado nenhum. Sugere um nível de coordenação interna entre redação, jurídico e infraestrutura que a maioria das redações ainda não atingiu. Esperamos que este tipo de política granular por secção se espalhe em 2026–2027 — o ficheiro do Spiegel é, na prática, um indicador antecedente.
Anatomia 3 — BBC (bbc.com) — a forma de declaração de política
O robots.txt da BBC abre com:
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.A BBC versiona o seu robots.txt (# version: ec59bd... é um hash de commit git), proíbe os oito usos específicos de IA que os advogados da BBC acompanham e termina com um resumo numa única linha, na voz textual sobre a qual a marca da BBC foi construída. A frase “expressly opts out of any statutory exceptions in any jurisdiction” é uma reserva global deliberada — está a dizer não confiamos em nenhum regime jurídico único para nos dar a proteção de que precisamos, por isso estamos a afirmar opt-out em todos ao mesmo tempo. Este é o robots.txt mais redigido do conjunto e lê-se mais como um press release do que como um ficheiro de configuração.
Anatomia 4 — WordPress.org — o opt-in explícito
Compare tudo isto com wordpress.org:
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /O WordPress.org faz opt-in explícito para nove crawlers de treino de IA, incluindo os três (Bytespider, CCBot, anthropic-ai) que são mais bloqueados noutros locais. A teoria implícita é que a documentação e o ecossistema de plugins do WordPress são um bem público cujo valor aumenta quando assistentes de IA conseguem responder a perguntas sobre ele. Sempre que alguém pergunta ao Claude “como configuro links permanentes no WordPress?” e o Claude foi treinado em wordpress.org/documentation/, a missão do WordPress já foi cumprida. A Fundação parece ter decidido que estar dentro do corpus de treino de todos os modelos é estrategicamente positivo — e usou a gramática expressiva do ficheiro para o dizer.
Anatomia 5 — The Verge (theverge.com) — o híbrido patrocinado
Mais um padrão que vale a pena mostrar. O Verge estrutura as suas regras de IA como Disallow: / \ Allow: /sp/:
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp/O caminho /sp/ é a secção de conteúdo patrocinado / de parceiros do The Verge. O conteúdo editorial é bloqueado do treino de IA; o conteúdo patrocinado é permitido. A lógica económica é clara: os patrocinadores pagam para que o conteúdo deles seja descoberto, inclusive por IA; a marca editorial principal é o moat. O GPTBot fica totalmente aberto (presumivelmente por uma relação direta com a OpenAI), o Applebot fica totalmente aberto como base de pesquisa, e o restante recebe o tratamento híbrido. Esta é a única estrutura de “acesso escalonado de IA” deste tipo que encontrámos.
Estes cinco ficheiros descrevem a faixa atual de políticas de IA no robots.txt. A maioria dos ficheiros do top 10k não se parece com nenhum deles — ou estão silenciosos, ou usam um template de fornecedor. Os que se parecem com um destes foram escritos por pessoas que decidiram que o ficheiro merece leitura cuidada.
Uma nota sobre o tamanho dos ficheiros: o corpo mediano de robots.txt na nossa amostra tem 858 bytes — demasiado pequeno para codificar uma política de IA significativa. É na cauda direita que as regras vivem: 1.005 sites (15,3%) têm um ficheiro com mais de 5 KB, 273 têm mais de 20 KB, e o máximo foi 248 KB. 460 ficheiros contêm linguagem de reserva de direitos de autor; 275 citam a UE 2019/790 pelo nome. Em 2026, um robots.txt está a tornar-se cada vez mais um documento versionado, revisto por advogados, e não uma simples linha de configuração.
Conclusão 11 — 108 sites recebem explicitamente bem o GPTBot
Um grupo pequeno, mas visível, escreve a regra User-agent: GPTBot \n Allow: / — o inverso do mais discutido “Disallow GPTBot”. O total na nossa amostra é de 108 sites com Allow explícito para GPTBot no caminho raiz. Os primeiros 25 por rank Tranco:
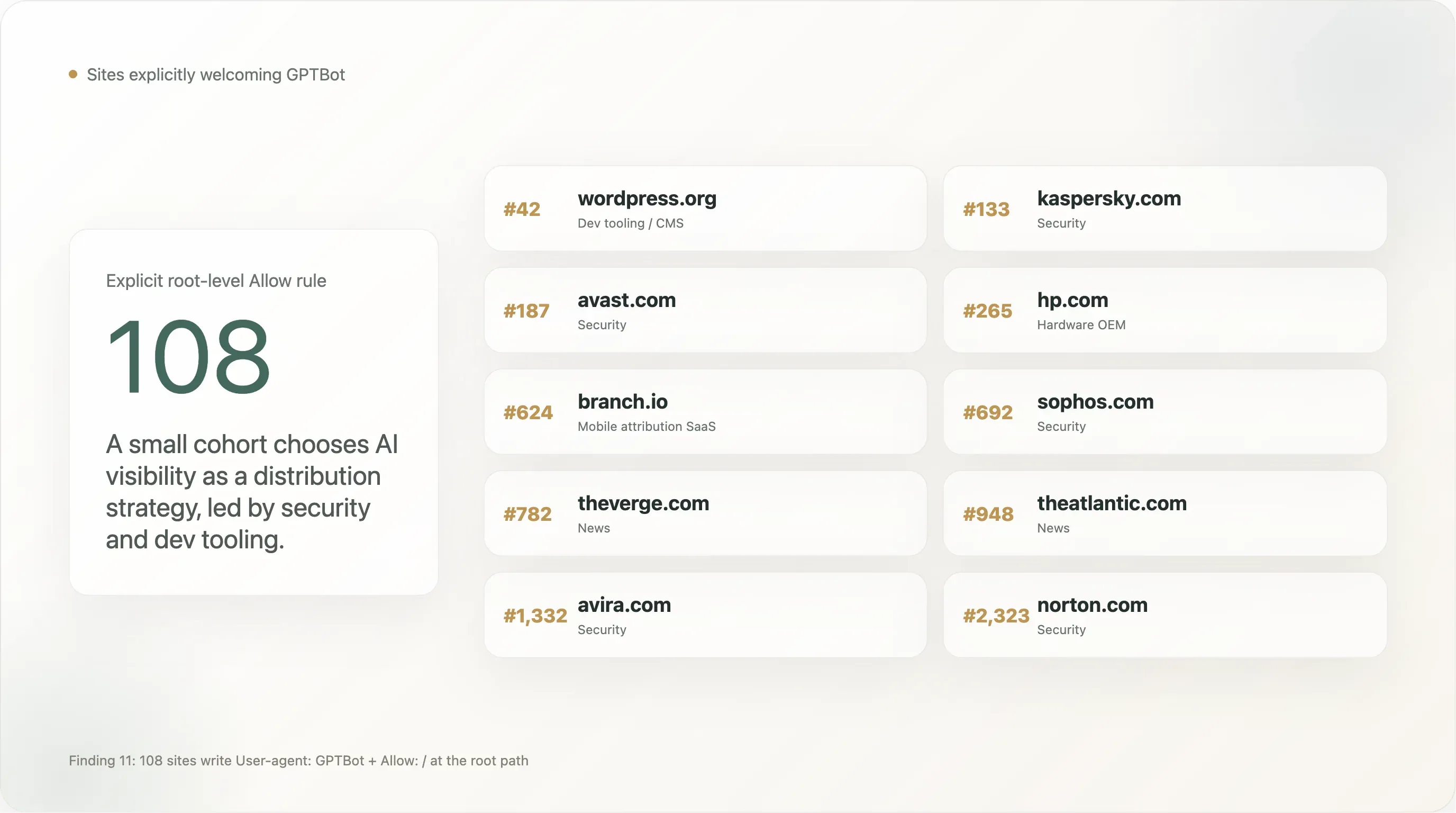
| Rank | Domínio | Setor |
|---|---|---|
| 42 | wordpress.org | Ferramentas para dev / CMS |
| 133 | kaspersky.com | Segurança |
| 187 | avast.com | Segurança |
| 265 | hp.com | Fabricante de hardware |
| 624 | branch.io | SaaS de atribuição mobile |
| 692 | sophos.com | Segurança |
| 782 | theverge.com | Notícias |
| 905 | rambler.ru | Portal russo |
| 945 | kleinanzeigen.de | Marketplace alemão |
| 948 | theatlantic.com | Notícias |
| 1.092 | lge.com | LG Electronics |
| 1.300 | justdial.com | Pesquisa local na Índia |
| 1.332 | avira.com | Segurança |
| 1.412 | youm7.com | Notícias egípcias |
| 1.530 | goodreturns.in | Finanças na Índia |
| 1.621 | publi24.ro | Classificados romenos |
| 1.807 | geocomply.com | SaaS de compliance |
| 1.908 | nba.com | Desporto |
| 1.956 | oneindia.com | Notícias na Índia |
| 1.974 | mindbox.ru | SaaS russo |
| 2.009 | thesun.co.uk | Notícias |
| 2.126 | vox.com | Notícias |
| 2.140 | mgid.com | Publicidade nativa |
| 2.314 | ninjarmm.com | SaaS de gestão de TI |
| 2.323 | norton.com | Segurança |
Alguns padrões:
As empresas de segurança estão visivelmente sobrerrepresentadas. Kaspersky, Avast, Sophos, Avira, Norton e NinjaRMM permitem GPTBot explicitamente. Este é um movimento de distribuição deliberado: quando um utilizador pergunta ao ChatGPT “qual o melhor antivírus para o meu PC com Windows?”, ter a marca dentro do corpus de treino do modelo afeta diretamente a recomendação. Segurança é uma das poucas categorias B2C em que a pesquisa com IA já está a substituir o SEO como canal principal de aquisição, e estas marcas saíram na frente. Esperamos que o resto do setor de segurança siga no prazo de 12 meses.
Algumas grandes marcas de notícias estão nesta lista, não na lista de bloqueio. The Verge, The Atlantic, Vox, The Sun, NBA.com. Isso não é contradição — estes publishers parecem ter decidido que ser citável dentro da pesquisa do ChatGPT vale mais do que ser protegido do treino, e escreveram a regra Allow explícita para se defender contra futuros excessos de bloqueio por parte da CDN ou do CMS. Compare com a postura de NYT / Reuters / BBC / Forbes / Guardian de Disallow explícito. As duas posturas são defensáveis; a indústria das notícias não é monolítica.
A presença de The Sun é notável porque o mesmo site usa, noutra parte do ficheiro, um bloqueio geral via User-agent: *. A política do The Sun é melhor lida como “o treino de IA é proibido, a pesquisa com IA é permitida, e nós adicionámos explicitamente GPTBot à exceção do deny-all para garantir que o ChatGPT possa responder citando The Sun.” Esta é a regra GPTBot-Allow mais sofisticada do ponto de vista jurídico — um opt-out com opt-in para um fornecedor específico.
A presença de WordPress.org é a entrada individual mais importante da lista. Uma parte não trivial do ecossistema global de CMS open source aponta para o WordPress.org em documentação ou hospeda plugins de lá. Ao permitir explicitamente GPTBot em wordpress.org/robots.txt, a WordPress Foundation disse, na prática, que o ecossistema de documentação do WordPress está aberto para treino — o que tem efeitos em cascata sobre quão bem Claude, Gemini e ChatGPT respondem a perguntas do tipo “como é que eu...?” sobre WordPress.
Os outros 83 sites da lista completa de Allow-GPTBot formam uma cauda longa de notícias regionais, fornecedores menores de segurança, plataformas de classificados em mercados não ingleses e SaaS B2B. Não vemos, tanto quanto conseguimos apurar, uma coordenação setorial ampla do tipo “Allow-GPTBot”; a regra está a ser adotada site a site, por operadores que decidiram que estar no corpus é a posição estratégica.
Conclusão 12 — llms.txt mal passa de rumor nesta escala
llms.txt, o formato alternativo proposto para descoberta de conteúdo amigável a LLMs (promovido por Mintlify, Anthropic, Vercel e alguns fornecedores de ferramentas para dev desde o fim de 2024), quase não aparece na nossa amostra.
Dos 6.638 sites que devolveram um robots.txt analisável, 83 (1,15%) mencionam llms.txt — geralmente como uma linha Sitemap: https://example.com/llms.txt. Isso é duas ordens de magnitude abaixo da mesma métrica observada em amostras de comércio com forte presença de ferramentas para dev, onde defaults de Vercel e Mintlify inflacionam a adoção.
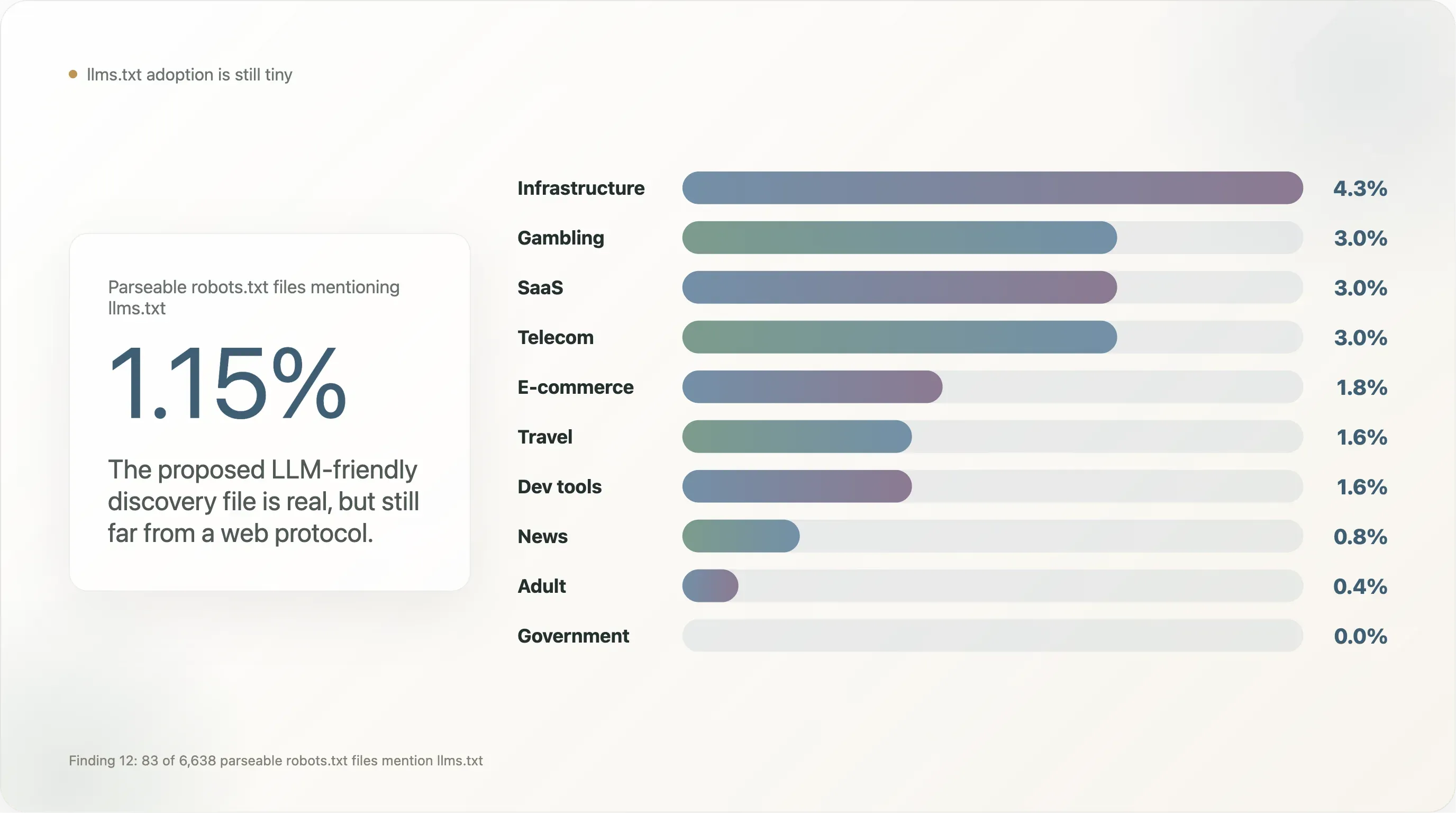
A distribuição por categoria:
| Setor | n | % que menciona llms.txt |
|---|---|---|
| Infrastructure | 47 | 4,3% |
| Jogos de azar | 100 | 3,0% |
| SaaS | 369 | 3,0% |
| Telecom | 33 | 3,0% |
| E-commerce | 224 | 1,8% |
| Viagens | 64 | 1,6% |
| Ferramentas para dev | 129 | 1,6% |
| Notícias | 650 | 0,8% |
| Adulto | 254 | 0,4% |
| Governo | 172 | 0,0% |
| Academia | 268 | 0,0% |
| Busca | 12 | 0,0% |
llms.txt está concentrado em SaaS próximo de ferramentas para dev, em jogos de azar (que adotam novos recursos de robots.txt mais depressa do que outros setores regulados porque têm equipas de compliance habituadas a adicionar metadados extra) e em e-commerce B2B. Está notavelmente ausente de notícias e governo — os dois segmentos mais envolvidos com política de IA e cuja adoção seria necessária para que o padrão saísse de “experimento do fornecedor” para “protocolo da web”. Até lá, llms.txt é real, mas pequeno; uma auditoria de acompanhamento no fim de 2026 será um bom reteste.
O problema estrutural que llms.txt enfrenta é que não foi padronizado por nenhum processo da IETF e os principais fornecedores de IA não se comprometeram a respeitá-lo. Uma regra robots.txt tem 30 anos de infraestrutura de crawlers à sua volta; uma regra llms.txt não tem nada. Até que pelo menos um grande fornecedor (OpenAI, Anthropic, Google, Cloudflare) declare suporte formal, o ficheiro é essencialmente um artefacto de marketing do ecossistema Mintlify / Vercel. Não esperamos que isso mude em 2026.
Conclusão 13 — Acessibilidade: robots.txt ainda é legível para dois terços da web principal
Uma observação lateral que não devia ter virado conclusão: 66% dos 10.000 sites mais visitados devolveram um robots.txt analisável para um único IP de pesquisa, e apenas 7 de 10.000 (0,07%) devolveram 429 Too Many Requests. Isso é uma boa notícia para robots.txt como protocolo público.
Para comparação, o mesmo pipeline executado dois meses antes sobre uma amostra de 1.008 domínios de e-commerce de média dimensão recebeu 429 de 52% dos domínios resolvidos — Shopify e CDNs da Cloudflare a limitar agressivamente a taxa de qualquer User-Agent que não fosse de um grande buscador. A web de alto tráfego é muito mais amigável: sites grandes têm maior probabilidade de ter ou (a) camadas de gestão de bots menos agressivas, ou (b) allowlists explícitas para crawlers de pesquisa conhecidos, ou ambos.
A taxa de fetch_failed de 21% no top-10k é dominada por domínios apex de CDN (akamai.net, cloudfront.net, fastly.net, apple-dns.net, gtld-servers.net) que não executam servidor web em /. Não estão a bloquear-nos; simplesmente não têm nada para servir. Excluindo estes casos, a taxa real de “tentámos ler, mas não deu” fica num dígito baixo.
Isto significa que iterações futuras deste relatório — capturas trimestrais, comparações ano a ano — podem ser executadas de forma barata e reproduzível numa única máquina. A janela de auditoria continua aberta no topo da curva. O caso assimétrico é a cauda longa e o segmento de comércio, onde o throttling ao nível da CDN já privatizou efetivamente o robots.txt. Esperamos que esta divergência aumente: os sites do topo continuarão legíveis porque são indexados por motores de busca que exigem legibilidade; o comércio da cauda longa ficará menos legível à medida que as camadas de combate a bots da Cloudflare forem lançadas de forma mais agressiva. A auditabilidade pública de robots.txt está a bifurcar-se na mesma linha que separa “a web visível” da “web protegida operacionalmente.”
IV. O que tudo isto significa
Quatro afirmações, por ordem da força com que os dados as sustentam.
1. A internet tem uma política de IA por setor, não uma política global. A variação de 12× entre notícias e telecom domina qualquer número agregado. Reportar “X% da web bloqueia IA” sem um recorte setorial sobrestima SaaS/governo/dev e subestima notícias/viagens/social. Setor por setor é o único enquadramento honesto.
2. O Artigo 4 da Diretiva de Copyright da UE é o único regime jurídico que está a mover os números de forma visível. Sites em ccTLD da UE bloqueiam em 35% contra a base global de 19%. O litígio nos EUA (NYT v. OpenAI, relatório do Copyright Office de janeiro de 2025) mudou o grupo de notícias dos EUA, mas não a web americana mais ampla. O enquadramento da UE também está a transbordar globalmente através do template da Cloudflare, que cita a Diretiva 2019/790 no texto-base independentemente da jurisdição do cliente.
3. Duas “políticas de IA” paralelas estão a ser expressas e não concordam entre si. A política deliberada, escrita à mão (17,8%, maioritariamente notícias/social/viagens/e-commerce) e a política herdada e gerida pela Cloudflare (4,5%) sobrepõem-se no conteúdo, mas divergem na legitimidade. Num mundo em que operadores de IA procuram cobertura jurídica para ignorar robots.txt, a defesa “nós escrevemos e revimos isto” é estruturalmente mais forte do que “eu só ativei o alternador”. O incentivo no litígio é empurrar a política da segunda categoria para a primeira.
4. O alvo que publishers estão a bloquear é o corpus, não o modelo. CCBot em 16,3% — mais alto do que qualquer bot de marca de modelo — é a afirmação mais limpa disso. Desautorizar a OpenAI não tira um publisher do conjunto de treino; desautorizar CCBot tira. 14,1% da web top-10k bloqueia CCBot e mantém Googlebot bem-vindo. O padrão “bloquear treino, manter pesquisa” é a regra modal de IA em 2026.
Para sites que estejam a pensar na sua própria postura: a postura mediana é o silêncio — 80% do top 10k não dizem nada sobre IA. Os 17% que escrevem regras tendem para o Disallow, mas um grupo pequeno e crescente (a lista de 1,5% de Allow explícito para GPTBot, liderada por fornecedores de segurança) está a escolher publicamente o inverso. Não existe consenso setorial e não vai haver um nos próximos doze meses.
Para operadores de IA: continuar a argumentar que robots.txt é um protocolo legado com semântica ambígua está cada vez mais difícil de sustentar quando 17% dos maiores sites do mundo escreveram regras explícitas e deliberadas nomeando bots manualmente, e 3,8% dos ficheiros citam uma lei específica da UE por número de secção. Se respeitar estas regras é ou não uma decisão de negócio; que elas existem, isso já é um facto empírico.
V. Perspetiva: o que esperamos até ao fim de 2026
Três trajetórias visíveis no conjunto de dados:
O Cloudflare Managed vai mais do que duplicar a sua participação, possivelmente chegando a 10%+ do top-10k analisável. O roadmap da Cloudflare fala publicamente em ativar o Block AI Bots por defeito para contas novas. Se o alternador vier ativado por defeito, a taxa global de bloqueio sobe de 5 a 8 pontos percentuais sem que um publisher individual tome qualquer decisão. Saberemos que isto está a acontecer quando a participação de Cloudflare Managed na faixa 5001–10000 subir acima dos atuais 5,7%.
Políticas de IA por secção (estilo Spiegel) vão espalhar-se entre as principais marcas de notícias. A lógica económica — deixar a IA citar conteúdo de baixo risco e proteger o conteúdo moat — é convincente o suficiente para esperar que pelo menos mais 10 redações âncora lancem regras por secção até ao fim de 2026. Fique atento primeiro à imprensa alemã e francesa de média dimensão; o enquadramento jurídico recompensa a experimentação nesses mercados.
O grupo de Allow explícito para GPTBot vai crescer, liderado por SaaS B2B e ferramentas para dev. Quando a pesquisa com IA se tornar um canal de aquisição mensurável para fornecedores de software (como já acontece para segurança), o CMO marginal vai escrever User-agent: GPTBot \n Allow: / para se proteger contra bloqueios acidentais em excesso. Esperamos que a lista de 108 sites duplique aproximadamente até ao fim do ano.
O que não esperamos: mudança material na participação da maioria silenciosa. Os 80% da web que não dizem nada sobre IA incluem setores (governo, telecom, infraestrutura, SaaS B2B) sem motivo económico para escrever uma regra e sem pressão jurídica para isso. Uma política universal de IA não está a chegar.
VI. Limitações
- Viés de uma única captura. As coletas ocorreram numa janela de 36 horas no início de maio de 2026. O arquivo muda diariamente no Top 100; espere uma deriva de 1 a 2 pontos percentuais por trimestre nos números principais.
- Lacunas na classificação setorial. 6.593 de 10.000 sites ficaram
unknowndepois do classificador em quatro camadas. As percentagens por setor são robustas onde n é grande (notícias: 650, streaming: 440, saas: 369, academia: 268, adulto: 254, ecommerce: 224, gov: 172, finanças: 129, dev: 129) e mais ruidosas abaixo de n=30. O recorte por país nas notícias também é limitado — DE/FR/UK têm n≥15, enquanto Coreia/Suécia/Chéquia repousam em n=20–25. robots.txté voluntário. UmDisallowé um pedido, não uma barreira.Bytespider,PerplexityBote outros já foram documentados a ignorar regras. Medimos declarações de política, não a sua aplicação.- Auditoria de IP único, baseada nos EUA. Não conseguimos ler 21% dos domínios resolvidos. A maioria são apex de CDN sem servidor web; uma pequena parte é de sites cuja CDN nos bloqueou antes de chegarmos à origem. Isto tende a enviesar a amostra ligeiramente para infraestrutura mais antiga e contra sites geofenced por país de origem.
- Semântica da lista Tranco. O Tranco filtra estabilidade; não é um ranking verdadeiro de comportamento do utilizador. Os números agregados são robustos à escolha da lista; as posições específicas no ranking, não.
- Sem dados de tráfego. Medimos a política de
robots.txt, não o throughput real de bots de IA. Política e tráfego nem sempre coincidem.
VII. Reproduza isto
Tudo o que foi usado para produzir este relatório está na pasta de entrega.
- tranco_top10k.csv — lista de entrada
- out/sites.csv — domínio × rank × setor × idioma × estado de robots.txt (10.000 linhas)
- out/fetch_meta.csv — resultado da recolha por domínio (estado, esquema, bytes, erro)
- out/bot_status.csv — grelha domínio × bot (250.000 linhas: bloqueado, tem_regra, estado_da_coleta)
- out/site_meta.csv — um registo analítico por site (template, booleanos-resumo)
- out/analysis.json — todas as métricas citadas no relatório
- 01_fetch_robots.py, 02_classify.py, 03_parse_and_analyze.py — pipeline Python completo
Correções de metodologia, problemas no conjunto de dados e análises de acompanhamento são bem-vindos em support@thunderbit.com. Este relatório é publicado de forma independente de qualquer posição comercial da Thunderbit; construímos um Raspador Web IA e temos interesse estrutural em que o robots.txt continue a ser um contrato relevante e legível por máquina na web pública. Os dados deste relatório valem por si só. — Equipa de investigação da Thunderbit, maio de 2026.