

A demanda por dados rotulados de alta qualidade em machine learning nunca foi tão alta. Sempre que converso com equipes que estão criando novos modelos de IA — seja para previsão de vendas, recomendações de produtos ou análise de sentimento de clientes —, os mesmos pontos de dor aparecem: rotular dados manualmente é lento, caro e, sinceramente, um pouco desgastante para a alma. Já vi projetos ficarem parados por semanas, ou até meses, só à espera de exemplos rotulados suficientes para treinar um modelo decente. E quando os rótulos não são consistentes? Bem, vamos dizer apenas que as previsões do seu modelo podem acabar tão confiáveis quanto as minhas tentativas de estacionar de ré.
Mas aqui vem a boa notícia: o rotulamento automático de dados com machine learning está a mudar esse cenário. Ao deixar a IA assumir o trabalho pesado, as empresas não estão apenas a acelerar o processo de rotulagem, como também a melhorar a precisão e a consistência — duas coisas que podem definir o sucesso ou o fracasso do seu projeto de ML. Neste guia, vou mostrar como funciona a rotulagem automática de dados, por que ela é tão importante para criar modelos robustos e como você pode usar ferramentas como Thunderbit para montar o seu próprio fluxo de rotulagem automatizado — sem precisar programar.
O que é rotulagem automática de dados com machine learning?
Vamos simplificar. Rotulagem automática de dados com machine learning significa usar algoritmos e ferramentas de IA para atribuir rótulos (como “spam” ou “não spam”, “gato” ou “cachorro”, “positivo” ou “negativo”) aos seus dados brutos — sem que uma pessoa precise clicar item por item. Pense nisso como a diferença entre marcar manualmente milhares de fotos de férias versus usar reconhecimento facial para organizá-las automaticamente por pessoa, local ou até humor.
A rotulagem manual tradicional é exatamente o que parece: pessoas a rever os dados um item de cada vez e a atribuir o rótulo correto. É precisa, às vezes, mas lenta, cara e difícil de escalar. Já a rotulagem automatizada usa modelos de machine learning — treinados com um conjunto menor de dados rotulados manualmente — para prever rótulos para o restante do conjunto de dados. O resultado? Rotulagem mais rápida, mais consistente e mais escalável (GeeksforGeeks).
Para utilizadores de negócio, isso significa construir modelos melhores, mais depressa e com menos trabalho manual pesado. E, no mundo orientado por dados de hoje, isso é uma vantagem competitiva séria.
Automatize a rotulagem de dados com o Thunderbit Use o raspador web com IA do Thunderbit para automatizar o seu fluxo de rotulagem de dados — sem precisar programar. Get Started Free
Por que a rotulagem automática de dados é essencial para modelos de machine learning de alta qualidade
O ponto é este: a qualidade dos seus dados rotulados impacta diretamente o desempenho dos seus modelos de machine learning. Como diz o ditado, “dado ruim entra, dado ruim sai”. Se os seus rótulos forem inconsistentes ou incorretos, o seu modelo vai aprender os padrões errados — e as suas previsões vão sofrer (DataCamp).
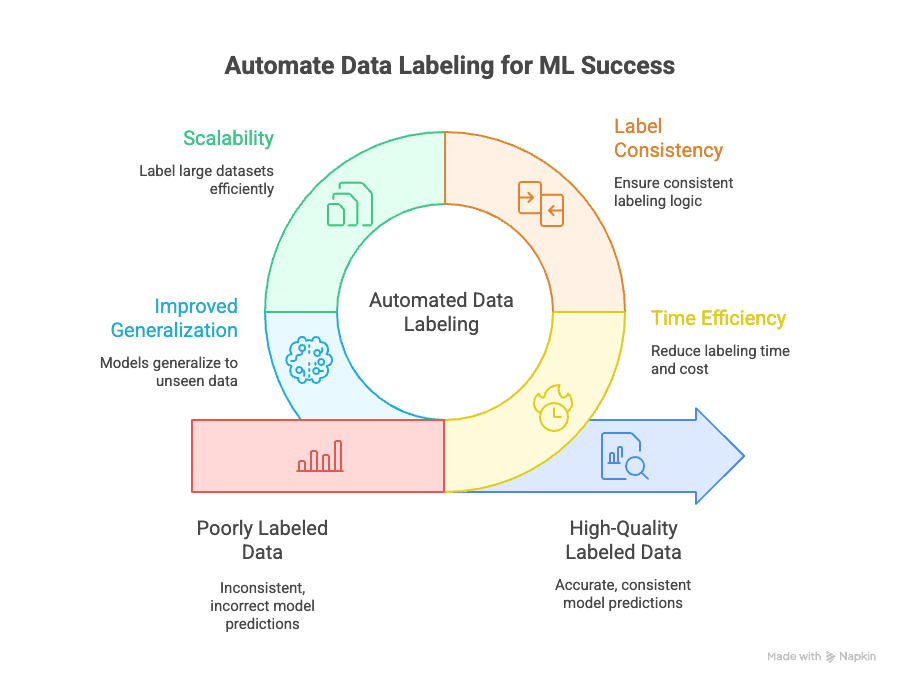
A rotulagem automática de dados resolve vários desafios importantes:
- Eficiência de tempo: a rotulagem manual pode consumir 70% do tempo e do custo total de um projeto de ML. A automação reduz isso para uma fração, permitindo iterar e lançar modelos mais rapidamente.
- Consistência dos rótulos: máquinas não se cansam nem se distraem. A rotulagem automatizada garante que cada ponto de dados seja rotulado com a mesma lógica, reduzindo erro humano e viés (GeeksforGeeks).
- Escalabilidade: precisa de rotular 10.000, 100.000 ou até um milhão de pontos de dados? A automação torna isso possível — sem contratar um exército de anotadores (Keylabs).
- Melhor generalização: rótulos consistentes e de alta qualidade ajudam os seus modelos a generalizar melhor para dados novos e nunca vistos, que é o objetivo final em machine learning (Kili Technology).
E o impacto no negócio é real: a Keylabs relata que fluxos híbridos, que combinam rotulagem assistida por IA com revisão humana, podem aumentar a precisão da rotulagem em até 80% em comparação com pipelines puramente manuais, o que se traduz diretamente em iterações de modelo mais rápidas e previsões mais confiáveis nas fases seguintes.
Comparando rotulagem manual e rotulagem automática de dados
Vamos colocar lado a lado:
| Fator | Rotulagem manual | Rotulagem automatizada com ML |
|---|---|---|
| Velocidade | Lenta (semanas/meses para grandes conjuntos de dados) | Rápida (minutos/horas para grandes conjuntos de dados) |
| Precisão | Alta, mas sujeita a erro/inconsistência humana | Alta, com lógica consistente e menos erros |
| Escalabilidade | Limitada pelos recursos humanos | Escala facilmente para milhões de pontos de dados |
| Custo | Cara (exige muito trabalho manual) | Menores custos no longo prazo (Keylabs) |
| Melhor para | Conjuntos de dados pequenos, complexos ou ambíguos | Conjuntos de dados grandes, repetitivos ou bem definidos |
A rotulagem manual ainda tem o seu espaço — especialmente para casos-limite ou dados ambíguos —, mas, para a maioria das aplicações de negócio, a automação é o caminho certo.
Os passos básicos da rotulagem automática de dados com machine learning
Então, como é que a rotulagem automática de dados funciona na prática? Aqui está o fluxo completo que eu recomendo (e que eu próprio uso):
- Coleta e pré-processamento de dados
- Extração e preparação de características
- Rotulagem automatizada usando machine learning
- Garantia de qualidade e revisão humana
Vamos detalhar cada etapa.
Etapa 1: coleta e pré-processamento de dados
Antes de rotular qualquer coisa, você precisa reunir e limpar os seus dados. Isso pode significar extrair listagens de produtos de sites, exportar avaliações de clientes ou recolher imagens de bases de dados internas. O ponto-chave aqui é a qualidade: dados ruins geram rótulos ruins, que geram modelos ruins (Snorkel AI).
Boas práticas:
- Remover duplicados e registos irrelevantes
- Padronizar formatos (datas, moedas etc.)
- Tratar dados em falta ou incompletos
Etapa 2: extração e preparação de características
Em seguida, você identifica as características que importam para a tarefa de rotulagem. Por exemplo, se estiver a rotular listagens de produtos, talvez queira extrair atributos como preço, marca, categoria e descrição. Em vendas ou marketing, isso pode significar extrair nomes de empresas, informações de contacto ou sentimento de e-mails.
Exemplo de negócio: usando Thunderbit, você pode extrair dados estruturados de páginas da web — como especificações de produtos, avaliações ou detalhes de contacto — sem escrever uma única linha de código.
Etapa 3: rotulagem automatizada usando machine learning
É aqui que a mágica acontece. Você usa modelos de machine learning (treinados com um conjunto menor de dados rotulados manualmente) para prever rótulos para o restante dos dados. As técnicas mais comuns incluem:
- Modelos supervisionados: treine um classificador com exemplos rotulados e depois use-o para rotular novos dados.
- Rotulagem baseada em regras: use regras predefinidas (por exemplo, “se o preço > US$ 1000, rotule como ‘premium’”) para casos simples.
- Aprendizagem ativa: o modelo pede entrada humana nos casos incertos, melhorando com o tempo (GeeksforGeeks).
- Transfer learning: use modelos pré-treinados para acelerar a rotulagem em novos domínios (GeeksforGeeks).
O resultado? Rótulos consistentes e de alta qualidade — em escala.
Etapa 4: garantia de qualidade e revisão humana
Até os melhores modelos precisam de uma verificação de sanidade. Revisões humanas periódicas ajudam a identificar casos-limite, dados ambíguos ou desvio do modelo. Passos práticos de QA incluem:
- Amostrar aleatoriamente dados rotulados para revisão manual
- Comparar rótulos automatizados com um conjunto de “gold standard”
- Usar métricas de concordância entre anotadores para medir a consistência (Kili Technology)
Como usar o Thunderbit para rotulagem automática de dados com machine learning
Agora vamos à prática. Thunderbit é um raspador web com IA e uma ferramenta de rotulagem de dados criada para utilizadores de negócio — sem precisar programar. Veja como pode usá-lo para automatizar o seu fluxo de rotulagem:
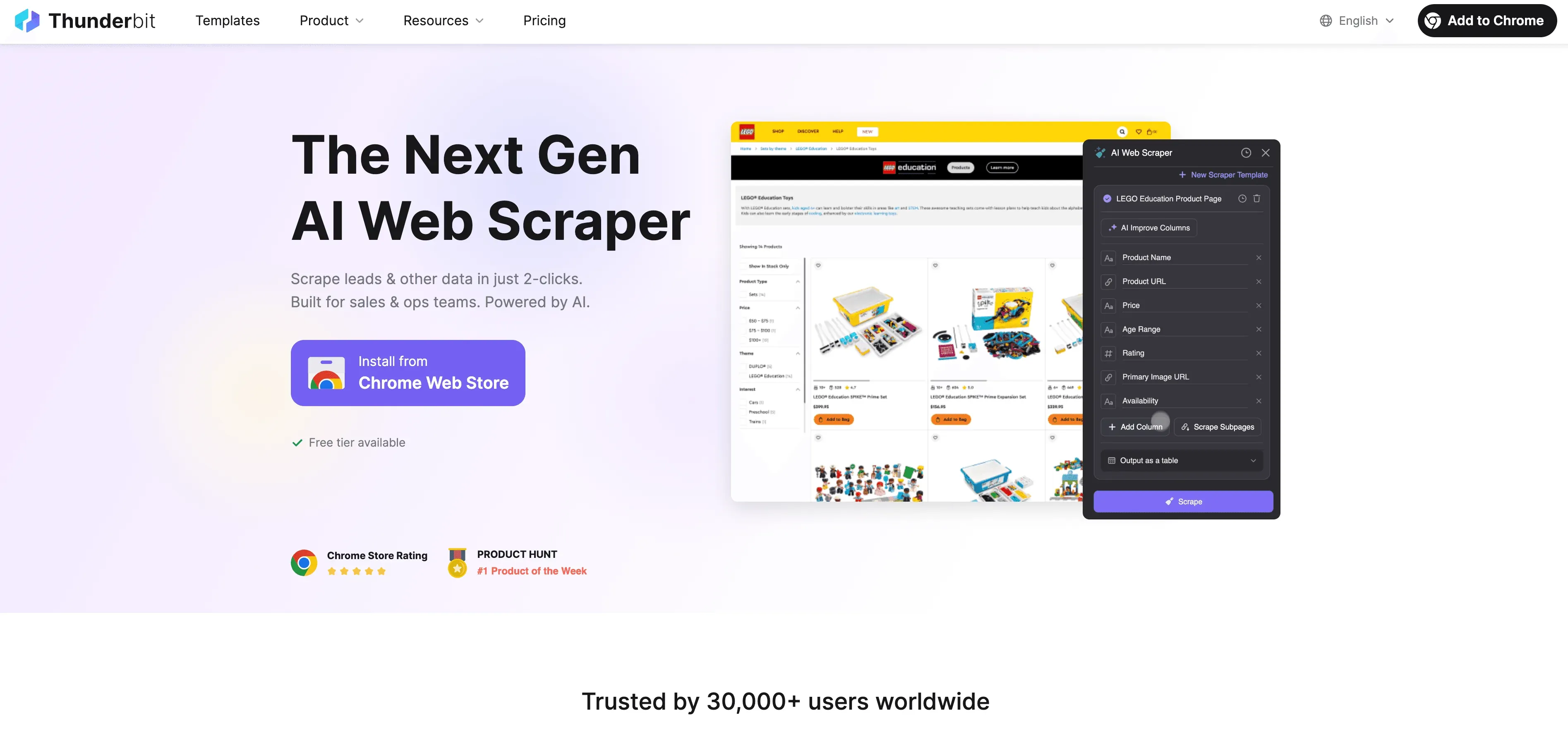
Guia passo a passo
- Extraia dados de sites: use a extensão do Thunderbit para Chrome para recolher dados estruturados de qualquer site. Basta abrir a extensão, selecionar a fonte dos dados e deixar a IA do Thunderbit sugerir os melhores campos para extração.
- Defina instruções de rotulagem: use os prompts em linguagem natural do Thunderbit para dizer à IA como rotular os seus dados. Por exemplo, “Rotule todos os produtos acima de US$ 500 como ‘premium’” ou “Marque avaliações com sentimento positivo”.
- Aplique a rotulagem automatizada: o recurso Field AI Prompt do Thunderbit permite personalizar e refinar como os rótulos são atribuídos — perfeito para tarefas de rotulagem com vários campos ou mais complexas.
- Exporte os dados rotulados: depois de os dados serem rotulados, exporte-os diretamente para Excel, Google Sheets, Airtable ou Notion — prontos para treinamento de modelo ou análise.
A melhor parte? O Thunderbit foi criado para utilizadores sem conhecimento técnico em vendas, marketing, operações e muito mais. Você não precisa escrever uma linha de código nem lidar com templates complexos.
Experimente o Thunderbit para rotulagem automática de dados
Prompts em linguagem natural e recursos Field AI do Thunderbit
Um dos meus recursos favoritos é a capacidade de definir a lógica de rotulagem em português simples. Quer categorizar leads por região, marcar produtos por categoria ou sinalizar e-mails com linguagem urgente? Basta descrever o que quer, e a IA do Thunderbit faz o resto.
Exemplos de prompts:
- “Rotule todos os contactos com e-mail ‘.edu’ como segmento ‘Educação’.”
- “Se a avaliação mencionar ‘envio rápido’, marque como ‘Experiência de envio positiva’.”
- “Agrupe produtos por marca e faixa de preço.”
O Field AI Prompt do Thunderbit permite ir ainda mais fundo — personalizando a lógica de rotulagem para cada coluna, combinando regras ou até traduzindo rótulos para vários idiomas.
Extração de subpáginas e rotulagem multicampos
Estruturas de dados complexas? Sem problema. O recurso de extração de subpáginas do Thunderbit permite extrair e rotular dados de páginas aninhadas (como detalhes de produtos ou biografias de autores) e reunir tudo numa única tabela estruturada. Você pode rotular vários campos de uma só vez — economizando ainda mais tempo.
Caso de uso real: extrair listagens de produtos de um site de ecommerce e, em seguida, seguir o link de cada produto para extrair e rotular especificações, avaliações e informações do vendedor — tudo num único fluxo.
Integrando várias ferramentas de rotulagem de dados para mais precisão e eficiência
Embora o Thunderbit cubra muita coisa, às vezes você precisa de ferramentas especializadas para certos tipos de dados — como anotação de imagens ou rotulagem de vídeos. É aí que entram plataformas como Label Studio ou Supervisely.
Dica de especialista: use o Thunderbit para lidar com a extração de dados da web e a rotulagem inicial e, depois, exporte os seus dados para o Label Studio ou o Supervisely para anotação avançada (como caixas delimitadoras em imagens ou tags de vídeo quadro a quadro). Essa abordagem com várias ferramentas permite aproveitar os pontos fortes de cada plataforma, aumentando tanto a precisão quanto a eficiência (GeeksforGeeks).
Quando usar ferramentas especializadas junto com o Thunderbit
- Anotação de imagens: para tarefas como deteção de objetos ou segmentação, use Supervisely ou Label Studio.
- Rotulagem de vídeos: ferramentas especializadas de vídeo lidam com anotação e rastreamento quadro a quadro.
- Tarefas complexas com múltiplos rótulos: combine a extração estruturada de dados do Thunderbit com ferramentas avançadas de anotação para obter os melhores resultados.
Boa prática: comece com o Thunderbit para rotulagem rápida e escalável de dados estruturados e semiestruturados; depois, recorra a ferramentas especializadas conforme necessário para anotação profunda.
Como extrair dados de PDF usando IA Aprenda a extrair e rotular dados de PDFs usando as ferramentas com IA do Thunderbit. Get Started Free
Boas práticas para rotulagem automática de dados com machine learning
Quer tirar o máximo partido do seu fluxo de rotulagem automatizada? Aqui ficam as minhas principais dicas:
- Defina diretrizes claras para os rótulos: rótulos ambíguos geram dados inconsistentes — seja específico sobre o que cada rótulo significa.
- Comece com um conjunto inicial de alta qualidade: rotule manualmente uma pequena amostra representativa para treinar o seu modelo inicial.
- Itere e melhore: use aprendizagem ativa para refinar o seu modelo ao longo do tempo, concentrando a revisão humana nos casos mais difíceis.
- Valide com frequência: reveja periodicamente uma amostra aleatória dos dados rotulados para detetar erros ou desvio.
- Integre e automatize: use ferramentas como o Thunderbit para ligar coleta de dados, rotulagem e exportação num único fluxo.
Desafios comuns e como superá-los
A rotulagem automática de dados não vem sem obstáculos. Veja como enfrentar os mais comuns:
- Dados ambíguos: use definições claras e detalhadas dos rótulos e forneça exemplos de casos-limite.
- Desvio do modelo: retreine regularmente o seu modelo de rotulagem com novos dados revistos manualmente.
- Casos-limite: estabeleça um processo de revisão humana para pontos de dados incertos ou inéditos.
- Problemas de integração: escolha ferramentas (como o Thunderbit) que ofereçam exportação fácil para as suas plataformas preferidas.
Conclusão e principais aprendizados
A rotulagem automática de dados com machine learning é o ingrediente secreto por trás dos modelos de IA mais eficazes de hoje. Ela poupa tempo, reduz custos e — o mais importante — entrega os rótulos consistentes e de alta qualidade que os seus modelos precisam para ter o melhor desempenho. Ao combinar ferramentas como Thunderbit com plataformas especializadas de anotação, você pode criar um fluxo de rotulagem rápido, preciso e escalável — independentemente do seu nível técnico.
Pronto para ver a diferença na prática? Baixe o Thunderbit, teste a rotulagem automatizada no seu próximo projeto e veja os seus modelos de machine learning ficarem mais inteligentes e mais rápidos. E, se quiser mais dicas e boas práticas, confira o Blog do Thunderbit com conteúdos aprofundados e tutoriais.
Automatize a rotulagem de dados com o Thunderbit
FAQs
1. O que é rotulagem automática de dados com machine learning?
É o processo de usar IA e modelos de ML para atribuir rótulos aos dados automaticamente, em vez de deixar que humanos façam isso manualmente. Essa abordagem acelera a rotulagem, melhora a consistência e escala para grandes conjuntos de dados.
2. Por que a qualidade da rotulagem importa para machine learning?
Os modelos aprendem apenas os padrões codificados nos rótulos, então rótulos inconsistentes ou errados ensinam a coisa errada ao modelo. Textos do setor de fornecedores de rotulagem, como a Keylabs, mostram que fluxos híbridos de IA + humano podem aumentar a precisão da rotulagem em até 80% em relação aos fluxos totalmente manuais — e esse ganho reflete-se diretamente no desempenho do modelo.
3. Como o Thunderbit ajuda na rotulagem automática de dados?
O Thunderbit permite extrair e rotular dados da web usando IA, com prompts em linguagem natural e lógica de campo personalizável — sem precisar programar. É ideal para utilizadores de negócio em vendas, marketing e operações.
4. Posso combinar o Thunderbit com outras ferramentas de rotulagem?
Com certeza. Use o Thunderbit para extração de dados estruturados e rotulagem inicial e, depois, exporte para ferramentas como Label Studio ou Supervisely para anotação avançada de imagens ou vídeos.
5. Quais são as melhores práticas para rotulagem automática de dados?
Defina diretrizes claras para os rótulos, comece com um conjunto inicial de qualidade, itere com aprendizagem ativa, valide regularmente e use ferramentas integradas para simplificar o seu fluxo.
Pronto para automatizar a sua rotulagem de dados e acelerar os seus projetos de machine learning? Experimente o Thunderbit e veja quanto tempo — e frustração — você pode poupar.
Saiba mais:
- Como extrair dados de PDF usando IA
- O que é data scraping e como fazer isso em 2025
- O que é list crawling e como fazer isso usando IA
- Como extrair qualquer site usando IA
Experimente o AI Web Scraper para rotulagem automática de dados Get Started Free




