Wikipedia Search Result Scraper
Vil du hente data i bulk? Prøv Thunderbit gratis.








Collect Wikipedia Search Results Fast
How to Extract Wikipedia Results Using Thunderbit



Learn how to extract structured data from Wikipedia search results
Collect Topic Data from Wikipedia Search Pages

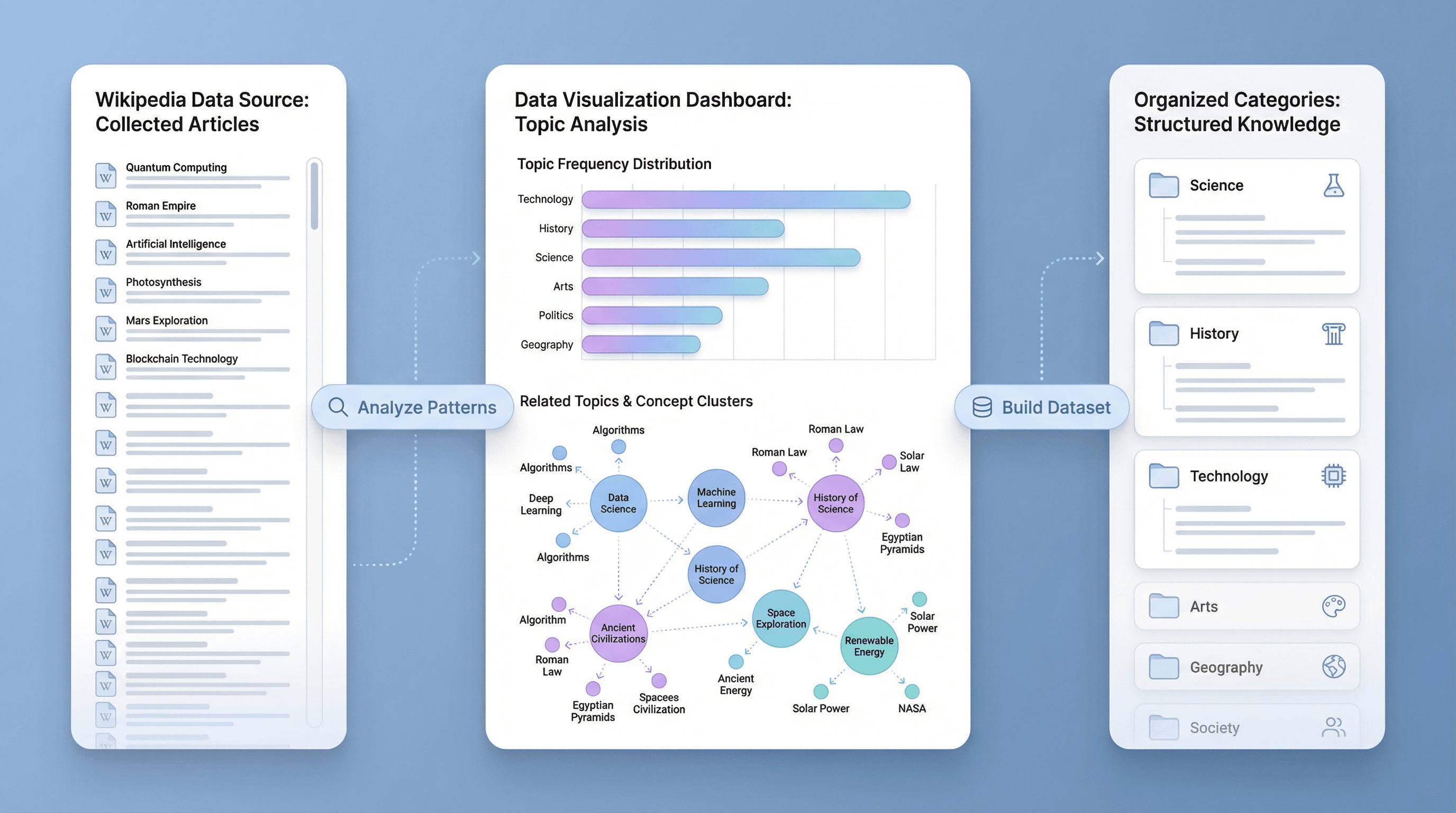
Analyze and Organize Large Sets of Wikipedia Results
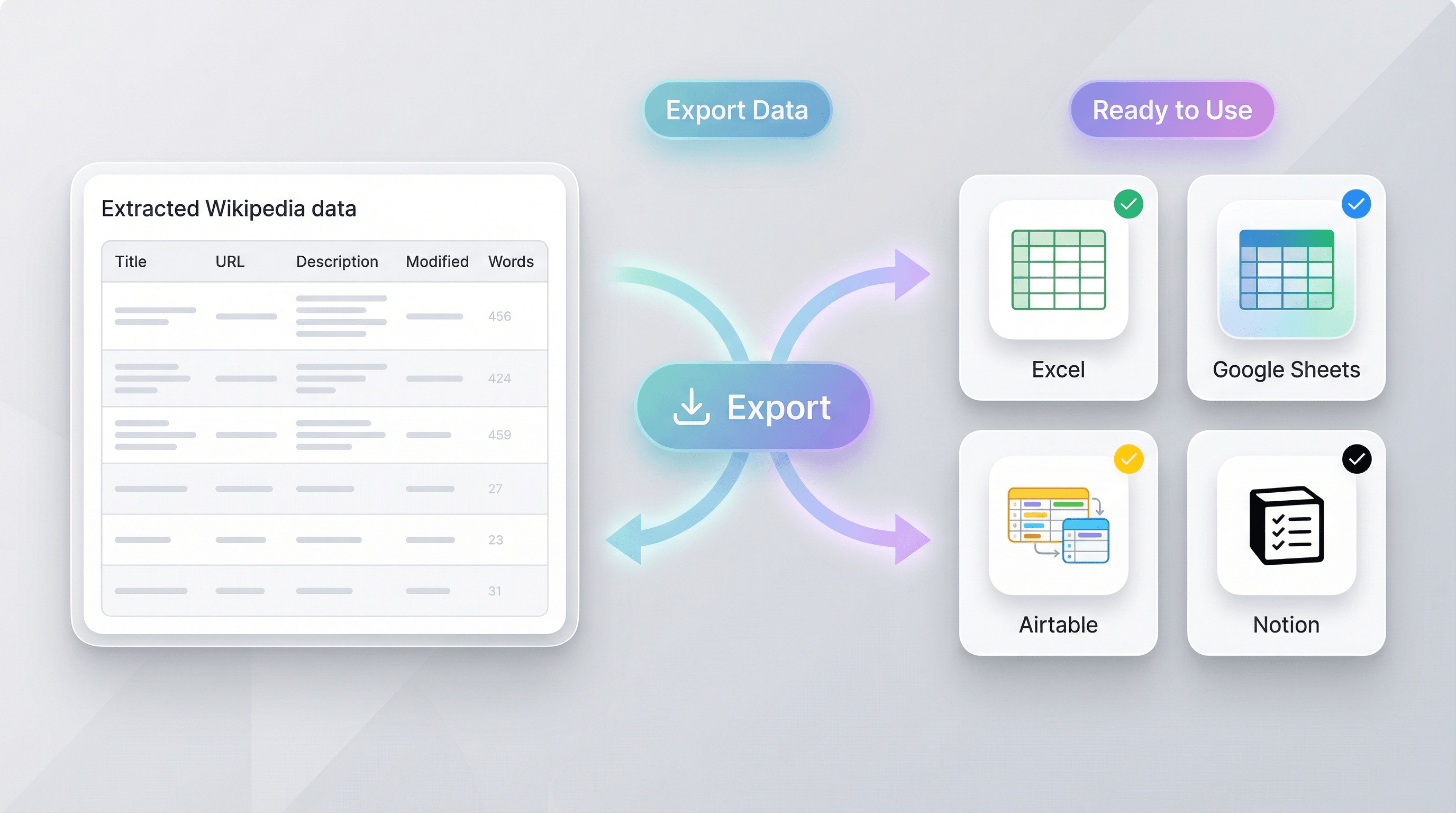
Export Wikipedia Data to Spreadsheets and Databases
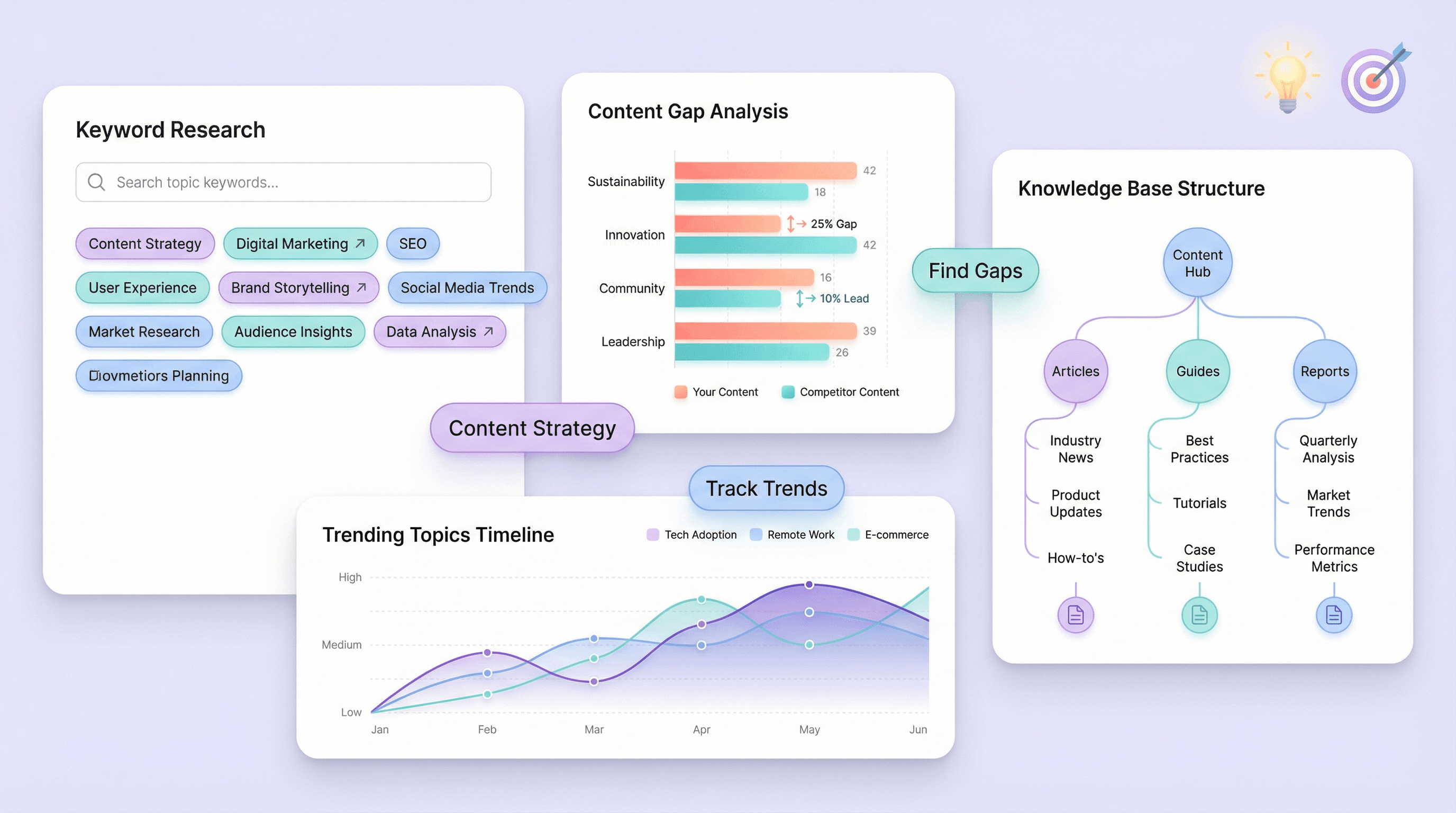
Support Content Strategy and SEO Research
Oppdag flere gratis verktøy
Sitemap-uttrekker
Analyser en XML-sitemap-URL og list opp hver sidelenke i en ryddig tabell. Gjennomgå nettstedstrukturen raskt og finn manglende eller uventede URL-er for SEO og QA.
Bildeuttrekker fra et nettsted
Trekk ut alle bilder fra enhver nettside umiddelbart og last dem ned på kort tid. Helt gratis, raskt og superenkelt å eksportere.
Listekravler
Trekk ut punktlister og nummererte lister fra hvilken som helst nettside-URL. Gå gjennom grupperte lister i ren tekst for å fange nøkkelpunkter raskt.
URL-uttrekker og batchnedlaster
Trekk ut alle nettstedlenker fra enhver side og last dem ned som CSV. Samle URL-er raskt til research, analyse eller datainnsamling.
G2 Software Product Scraper
Extract structured insights from any G2 software page, including ratings, reviews, and product details, to streamline competitor analysis and market research.
Google Scholar-scraper
Trekk ut akademiske resultater fra en Google Scholar-side og eksporter titler på artikler, sitater, forfattere og publikasjonsdetaljer i CSV for raskere forskning.
Text Extractor
Extracts text from images and lets you download the results. Quickly convert scanned documents or pictures into editable text for easy use.
Amazon Produktskraper
Hent produktinformasjon fra Amazon ved å lime inn produkt-URL-er. Få titler, priser, vurderinger og mer i en strukturert tabell som enkelt kan eksporteres og gjennomgås.
AI Sales Email Generator
Create personalized sales emails in seconds with the free AI Sales Email Generator. Perfect for sales teams and entrepreneurs. Try it now and boost your outreach with Thunderbit’s suite of AI tools.
AI-emnefeltgenerator for e-post
Generer overbevisende emnefelt til e-post ut fra en kort beskrivelse. Øk åpningsraten med AI-drevne forslag. Raskt, enkelt og uten registrering.
Telefonnummeruttrekker
Skann raskt nettsider, filer eller tekst for å finne telefonnumre. Få en ryddig, eksportklar liste på sekunder – ideelt for å bygge kontaktlister eller verifisere data.
E-postuttrekker og verifisering
Finn og trekk ut e-postadresser med E-postuttrekker fra nettsider, PDF-er eller tekst. Raskt, nøyaktig og klart til eksport når som helst.
Bilde til Excel-konverter
Konverter bilder av tabeller, kvitteringer eller lister til strukturerte JSON-arrayer for enkel eksport til Excel. Spar tid på manuell dataregistrering og sikre nøyaktighet.
Testverktøy for emnelinjer i e-post
Vurder en emnelinje etter lengde, tydelighet, hastverk, personalisering og spamrisiko. Få konkrete tips for å øke åpningsraten.