Substack-scraper

Brukt av fagfolk i ledende selskaper














Lås opp Substack-data med Thunderbit
Send Substack-data direkte til appene dine
Slutt å kopiere og lime inn publikasjonss detaljer fra Substack manuelt, som forfatternavn, artikeltittel og antall abonnenter. Med Thunderbit sender du bare de uttrukne dataene direkte til Google Sheets, Notion eller Airtable med ett klikk. Analyser publiseringstrender og innholdsprestasjoner uten det tidkrevende manuelle arbeidet.
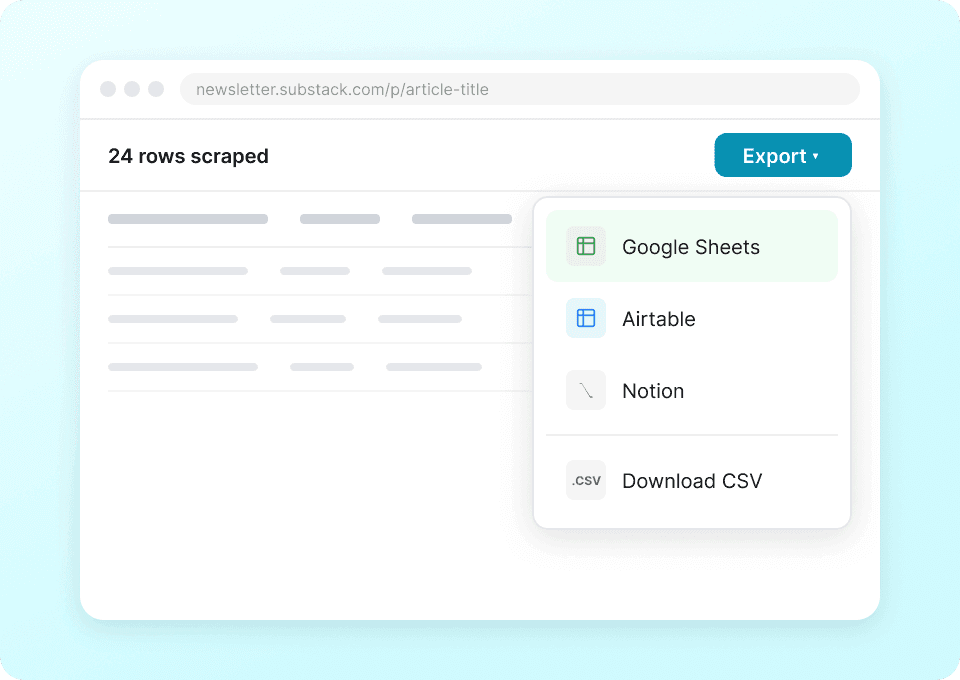
Én skraper for Substack og mer
Ikke bli låst til å bruke en अलग skraper for hvert nettsted. Thunderbit fungerer på Substack rett ut av boksen, og inkluderer over 50 ferdige maler for andre populære plattformer. Trekk ut publikasjonbeskrivelser, artikkelinnhold og mer, og bruk deretter det samme verktøyet til å samle data fra andre steder.
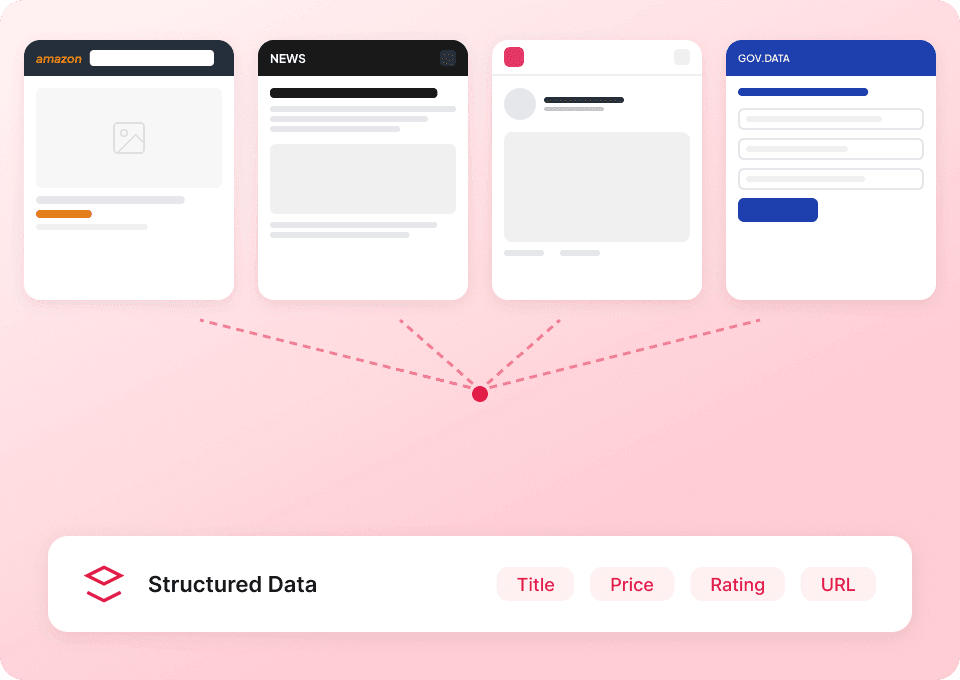
Få hele Substack-historien
Lister på Substack viser bare sammendrag. Thunderbit besøker automatisk hver artikkels underside for å trekke ut hele innholdet, slik at du får et komplett datasett. Få hele artikeltittelen, forfatternavnet, publikasjonens navn og artikkelinnholdet i én operasjon.
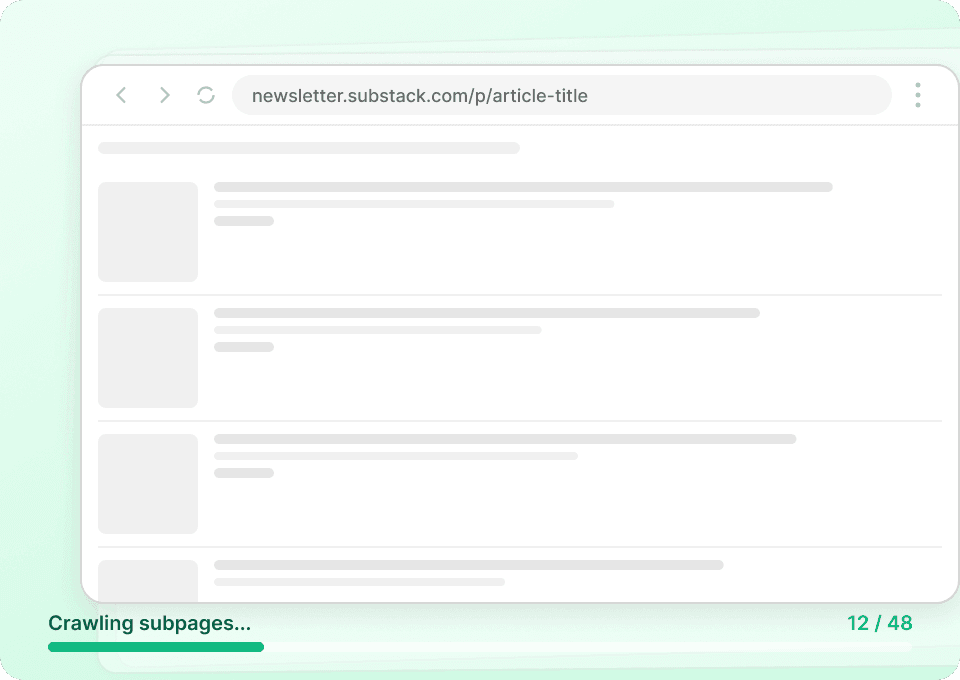
Sliter du med å skrape Substack effektivt?
Se hvorfor Thunderbit slår tradisjonelle skrapere for Substack-data.
Tradisjonelle skrapere
Den gamle måten å gjøre ting påThunderbit
Den smartere tilnærmingenIkke bare ta vårt ord for det
Se hva brukerne våre sier om Thunderbit.






Ofte stilte spørsmål
Relatert bruksområder
Utforsk flere bruksområder for Thunderbits web scraper.

Trustpilot-skraper
Gjør Trustpilot-sider om til et ryddig regneark med anmeldelser, vurderinger og navn på anmelderne. Vi leser hver side for deg, så du slipper kode og kopiering og liming.
Les mer ->
UNIQLO Scraper
Hent produktdata fra UNIQLO, som navn, priser og tilgjengelige størrelser, med bare 2 klikk takket være Thunderbit sin Chrome-utvidelse.
Les mer ->
PubMed Scraper
Thunderbits PubMed Scraper hjelper deg å hente ut strukturert data fra PubMed-søkeresultater og artikkelsider ved hjelp av AI. Samle inn trendende medisinsk forskning, dokumentasjon fra kliniske studier, sammendrag, forfattere, tilknytninger, publiseringsdatoer og lenker – og eksporter til Excel, Google Sheets, Airtable eller Notion.
Les mer ->
Wikipedia-skraper
Få infoboksdata, referanser og artikkeltekst fra Wikipedia inn i et ryddig regneark — uten kode, AI-en ordner struktureringen for deg.
Les mer ->Amazon pris-scraper
Hent Amazon-priser, vurderinger og ASIN-er inn i Google Sheets med punkt-og-klikk-scraping — helt uten komplisert oppsett.
Les mer ->
Sports Direct Scraper
Hent produktnavn, priser og rabattprosent fra Sports Direct med Thunderbits AI — ingen komplisert oppsett eller koding nødvendig.
Les mer ->Klar til å gi datauthentingen et løft?
Bli med over 100 000 fagfolk som allerede bruker Thunderbit for å automatisere web scraping-arbeidsflytene sine.
Gratis prøveperiode gir ubegrensede kreditter for 8 nettsider.