

Thunderbits PubMed Scraper gjør PubMed-sider om til ryddige, strukturerte datasett ved hjelp av AI. Du kan hente ut trendende medisinsk forskning, evidens fra kliniske studier, sammendrag, forfattere, tilknytninger, publiseringsdatoer, PMID-er og artikkellenker – og deretter eksportere til Excel, Google Sheets, Airtable eller Notion. Du åpner bare PubMed i Chrome, lar AI foreslå de beste kolonnene, og skraper.
🧬 Hva er PubMed Scraper
PubMed Scraper er en AI Web Scraper laget for . Med (en AI web scraper-utvidelse for Chrome) kan du gå til hvilken som helst resultatside i PubMed, klikke AI Suggest Columns, og deretter Scrape for å hente ut strukturert data – helt uten koding.
🔎 Hva kan du skrape fra PubMed
PubMed er fullt av verdifull biomedisinsk metadata, men innholdet er ikke alltid klart for analyse. Thunderbits AI Web Scraper (https://thunderbit.com/) hjelper deg å samle inn og strukturere PubMed-lister, og du kan berike dem med detaljer på artikkelnivå via Subpage Scraping (åpne hver artikkelside og legg til felt som sammendrag, tilknytninger, DOI og mer).
Nedenfor er to vanlige arbeidsflyter du kan kjøre på få minutter.
📈 Skrap PubMed Trending for overvåking av trendende medisinsk forskning
Bruk denne arbeidsflyten for å følge med på hva som trender i medisinsk forskning på PubMeds trend-side. Den er nyttig for å holde seg oppdatert, lage interne oppsummeringer, følge konkurrenters publiseringer eller mate en pipeline for litteraturovervåking.
Eksempel på destinasjonsside:
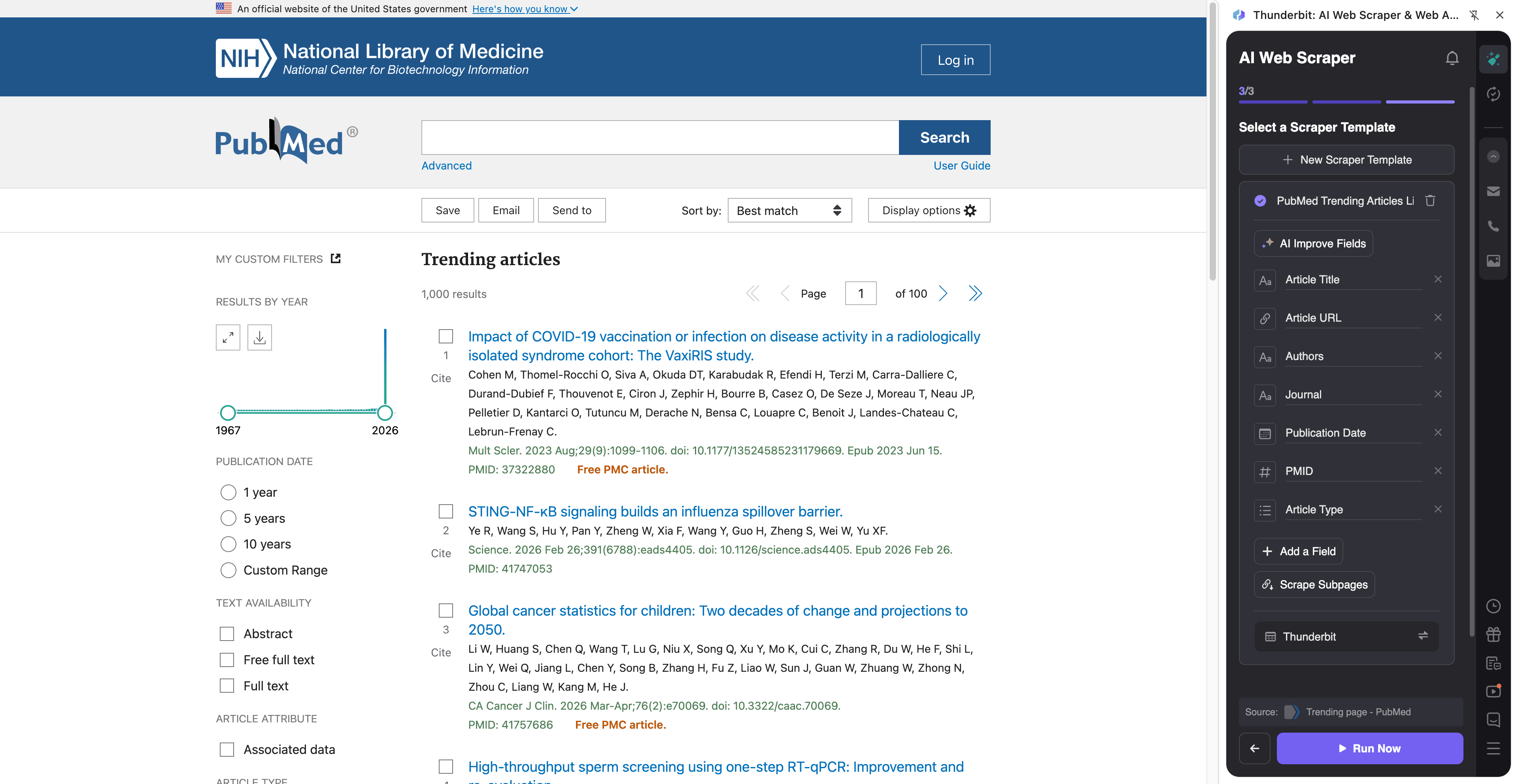
Steg:
- Last ned og registrer en konto.
- Gå til destinasjonssiden, for eksempel: .
- Klikk AI Suggest Columns for å la AI anbefale de beste kolonnenavnene og datatypene.
- Klikk Scrape for å hente ut dataene, og eksporter deretter til Excel, Google Sheets, Airtable eller Notion.
Kolonnenavn
| Kolonne | Beskrivelse |
|---|---|
| 🧾 Artikkeltittel | Tittelen på den trendende PubMed-artikkelen. |
| 🔗 Artikkel-URL | Direkte lenke til PubMed-oppføringen. |
| 🆔 PMID | PubMed-identifikator for oppføringen (nyttig som stabil nøkkel). |
| 🏛️ Tidsskrift | Navnet på tidsskriftet der artikkelen er publisert. |
| 📅 Publiseringsdato | Publiseringsdatoen som vises i listen. |
| ✍️ Forfattere | Forfatterlinjen som vises på resultatkortet. |
| 🧪 Artikkeltype | Publikasjonstype når tilgjengelig (f.eks. Review, Clinical Trial). |
| 🏷️ Nøkkelord / temaer | Synlige emnetagger eller nøkkelord i listen (hvis tilgjengelig). |
| 📝 Utdrag / sammendrag | Kort utdragstekst som vises i listen (hvis tilgjengelig). |
| 🧷 DOI | DOI når tilgjengelig (ofte best å hente via subpage scraping). |
| 🧑🔬 Tilknytninger | Forfattertilknytninger (hentes vanligvis via subpage scraping). |
| 📄 Sammendrag (abstract) | Abstract-tekst (hentes vanligvis via subpage scraping). |
🧫 Skrap PubMed for uthenting av evidens fra kliniske studier
Bruk denne arbeidsflyten for å hente ut evidens knyttet til kliniske studier fra PubMed-søkeresultater, og berik deretter hver rad ved å besøke artikkelsiden for å hente sammendrag, «trial»-signaler og metadata du trenger til gjennomgang.
Eksempel på destinasjonsside:
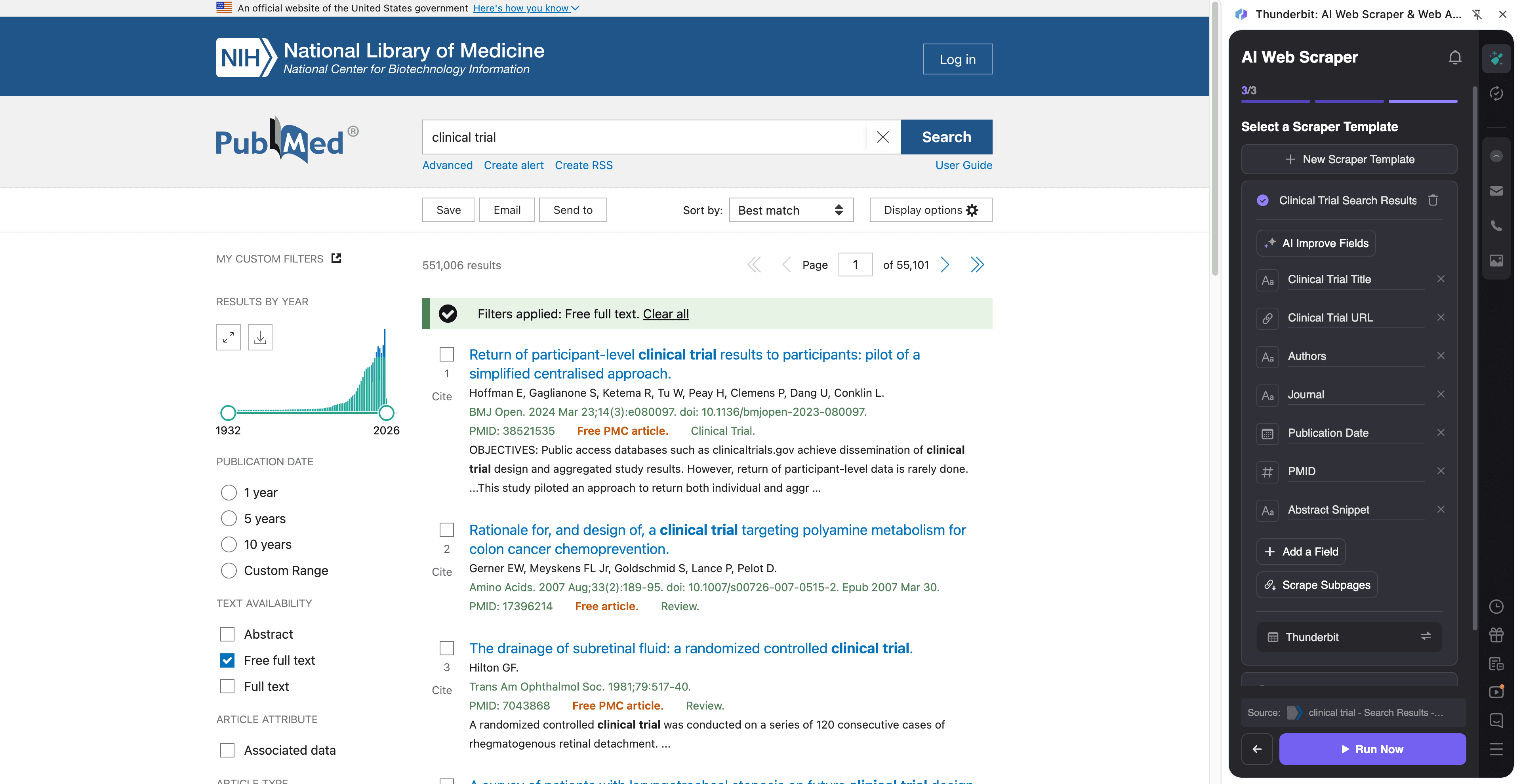
Steg:
- Last ned og registrer en konto.
- Gå til destinasjonssiden, for eksempel: .
- Klikk AI Suggest Columns for å generere anbefalte felt (du kan gi dem nye navn eller legge til egne).
- Klikk Scrape for å samle inn resultatene, og bruk deretter Scrape Subpages for å berike hver rad med abstract, tilknytninger, DOI og mer.
Kolonnenavn
| Kolonne | Beskrivelse |
|---|---|
| 🧾 Tittel | Artikkeltittel fra søkeresultatene. |
| 🔗 PubMed-URL | Lenke til PubMed-artikkelsiden for beriking via subpage. |
| 🆔 PMID | PubMed-identifikator for deduplisering og referanser. |
| 🧑⚕️ Forfattere | Forfattere som vises i resultatutdraget. |
| 🏛️ Tidsskrift | Tidsskriftnavn og siteringsinfo som vises i resultatene. |
| 📅 Dato | Publiseringsdato (eller ePub-dato) som vises i listen. |
| 🧪 Publikasjonstype | Signaler som Clinical Trial, Randomized Controlled Trial, Meta-Analysis (ofte tydeligere på artikkelsiden). |
| 🧾 Sammendrag (abstract) | Full abstract-tekst (best via subpage scraping). |
| 🧬 MeSH-termer | Medical Subject Headings når tilgjengelig (ofte på artikkelsiden). |
| 🧷 DOI | DOI for lenking til forlagssider og referanseverktøy. |
| 🏥 Tilknytninger | Forfattertilknytninger for institusjonsanalyse (subpage scraping). |
| 🌍 Land / institusjon | Tolket fra tilknytninger med Field AI Prompts (valgfritt). |
| 🔍 Nøkkelord for kliniske studier | AI-merkede flagg som «randomized», «double-blind», «placebo» (valgfritt via Field AI Prompt). |
| 📎 Lenker til fulltekst | Utgående lenker til forlag eller gratis fulltekst når de finnes. |
🎯 Hvorfor bruke PubMed-verktøyet
Å skrape PubMed handler om fart, konsistens og å gjøre forskningsdata praktisk anvendbare i arbeidsflyten din. I stedet for å kopiere siteringer én og én, kan du bygge et strukturert datasett du kan filtrere, tagge og dele.
Vanlige grunner til at team skraper PubMed:
- Medical affairs- og farmateam: Følg nye publikasjoner innen et terapiområde, overvåk konkurrenters studier og bygg evidenstabeller til interne vurderinger.
- Biotek og klinisk drift: Samle publikasjoner knyttet til studier, kartlegg institusjoner og utprøvere, og hold en levende bibliografi.
- Helsemarkedsføring og innholdsteam: Finn trendende temaer, tidsskrifter med høy impact og nye nøkkelord til innholdsplanlegging.
- Akademiske forskere og bibliotekarer: Bygg datasett til litteraturgjennomganger, dedupliser med PMID og eksporter til regneark for screening.
- Datateam: Lag strukturerte input til videre analyse, dashboards eller interne kunnskapsbaser.
Thunderbit er spesielt nyttig når du trenger mer enn bare listesiden. Med Subpage Scraping kan du hente ut abstracts, tilknytninger, DOI, MeSH-termer og fulltekstlenker i stor skala.
🧩 Slik bruker du PubMed Chrome-utvidelsen
- Installer Thunderbit Chrome Extension: Hent den fra og opprett konto.
- Gå til en PubMed-side: Åpne , en trend-side som , eller et søk som .
- Aktiver AI-drevet skraping: Klikk AI Suggest Columns for å generere felt, juster datatyper (tekst/dato/url), og legg til valgfrie Field AI Prompts (for merking, formatering eller uthenting av «trial»-signaler).
- Skrap og eksporter: Klikk Scrape. Hvis du trenger abstracts/tilknytninger/MeSH, kjør Scrape Subpages for å berike hver rad, og eksporter deretter til Excel, Google Sheets, Airtable eller Notion.
Nyttig lesning hvis du vil bygge en repeterbar arbeidsflyt:
💳 Priser for PubMed
Thunderbit bruker et enkelt kredittsystem:
- 1 kreditt = 1 utdata-rad i resultattabellen din (for eksempel én PubMed-oppføring).
- Dataeksport er gratis: last ned CSV/JSON eller send til Excel, Google Sheets, Airtable eller Notion.
Du kan starte med:
- Gratisnivå: skrap 6 sider per måned (sidebasert kvote på Free).
- Gratis prøveperiode: skrap 10 sider gratis, ideelt for å teste PubMed Trending og noen resultatsider for kliniske studier.
Hvis du skraper jevnlig (ukentlig overvåking, evidensoppdateringer eller store søk), gir betalte planer deg flere kreditter. Årsplanen er som regel mer kostnadseffektiv fordi den inkluderer rabatt sammenlignet med månedlig betaling.
Du kan se alternativene på .
❓ FAQ
-
Hva er den AI-drevne PubMed Scraper?
Den AI-drevne PubMed Scraper er en arbeidsflyt i Thunderbit som henter ut strukturert data fra PubMed-søkeresultater og artikkelsider. Du kan la AI foreslå kolonner, skrape lister og berike hver rad ved å besøke artikkelens undersider for abstract, tilknytninger, DOI og mer. -
Hva er Thunderbit?
er en AI web scraper-utvidelse for Chrome, laget for forretnings- og forskningsarbeidsflyter der du trenger strukturert data fra nettsteder. Den hjelper deg å hente ut, merke og eksportere data raskt – uten å bygge eller vedlikeholde skrapeskript. -
Kan du skrape PubMed Trending-sider og vanlige søkeresultater?
Ja. Du kan skrape , vanlige nøkkelordsøk og filtrerte resultatsider (som søk med fokus på kliniske studier). Thunderbits AI tilpasser seg ulike oppsett ved å lese siden og foreslå relevante felt. -
Kan Thunderbit hente ut abstracts, tilknytninger og MeSH-termer?
Ja – og her er Subpage Scraping spesielt nyttig. Du kan først skrape resultatlisten, og deretter la Thunderbit åpne hver PubMed-oppføring for å hente abstract-tekst, tilknytninger, MeSH-termer, DOI og annen metadata inn i samme tabell. -
Hvordan fungerer paginering og uendelig scrolling på PubMed?
Thunderbit støtter skraping med paginering, inkludert navigasjon av typen «neste side». Hvis PubMed endrer hvordan resultater lastes inn, er AI-basert uthenting ofte mer robust enn faste selektorer, siden den leser sidestrukturen på nytt ved hver kjøring. -
Hvilke formater kan jeg eksportere PubMed-data til?
Du kan eksportere til CSV eller JSON, eller sende datasettet til Excel, Google Sheets, Airtable eller Notion. Dette er nyttig for screening, evidenstabeller, dashboards og deling med samarbeidspartnere. -
Hvor mange PubMed-oppføringer kan jeg skrape gratis?
På gratisnivået kan du skrape 6 sider per måned, som ofte holder til mindre overvåkingsoppgaver. Med gratis prøveperiode kan du skrape 10 sider gratis for å verifisere kolonneoppsett og strategi for beriking via subpages. -
Kan jeg tilpasse kolonner for spesifikke behov innen evidensuthenting?
Ja. Du kan gi kolonner nye navn, sette datatyper (tekst/dato/url) og legge til Field AI Prompts for å hente ut eller merke informasjon som nøkkelord for studiedesign, populasjon, intervensjon, komparator, endepunkter eller land fra tilknytninger. Dette gjør at du kan gå fra rå skraping til mer strukturert evidensforberedelse. -
Er det greit å skrape PubMed?
PubMed er en offentlig ressurs, og mange team samler bibliografisk metadata til forskning og analyse. Du bør likevel følge gjeldende lover, respektere nettstedets vilkår og bruke ansvarlige skrapemetoder – spesielt ved store og hyppige jobber.
📚 Les mer
- Last ned utvidelsen:
- Utforsk guider på
- Lær grunnprinsippene:
- Bygg liste-arbeidsflyter:
- Eksporter til regneark:
- Hvis du også skraper PDF-er i research ops: