
Nettsiden vokser i et tempo som ærlig talt er vanskelig å ta inn over seg. Hver eneste dag legges det ut milliarder av nye sider, produkter, anmeldelser og datasett — og de driver alt fra markedsanalyse og AI-trening til ditt neste Amazon-kjøp. Som en som har jobbet i flere år med SaaS og automatisering, har jeg sett med egne øyne hvordan riktig data kan være forskjellen på en god og en dårlig forretningsbeslutning. Men her er utfordringen: det blir vanskeligere, ikke enklere, å samle inn, oppdatere og forstå all denne webdataen. Tradisjonelle webskrapere klarer rett og slett ikke å holde tritt, og bedrifter leter etter en smartere og raskere måte å gjøre internett om til konkrete innsikter. Her kommer cloud crawler inn — et verktøy som stille og rolig er i ferd med å endre hvordan organisasjoner finner og utnytter webdata i stor skala.
Så, hva er egentlig en cloud crawler? Hvordan skiller den seg fra webskraperne du kanskje allerede kjenner? Og hvorfor satser team innen alt fra salg til drift på denne teknologien for å ligge foran i en datadrevet verden? La oss rydde opp i begrepene, gå rett på sak og se hvordan cloud crawlere — spesielt Thunderbits løsning — endrer spillereglene for moderne virksomheter.
Hva er en cloud crawler? Neste steg i datainnsamling
La oss gjøre det enkelt: en cloud crawler er ikke bare en webskraper som tilfeldigvis kjører i skyen. Den er mer som en motor for dataoppdagelse — et smart, skybasert system som automatisk finner, henter ut og analyserer enorme datasett fra hele internett. Mens en tradisjonell webskraper henter informasjon fra noen få sider (ofte én om gangen, og som regel fra én enhet), jobber en cloud crawler på et helt annet nivå. Den kjører i kraftige datasentre i skyen, crawler tusenvis (eller til og med millioner) av sider samtidig, og kan håndtere alt fra tekst og bilder til PDF-er — uansett hvor kompleks eller omfattende nettsiden er.
Tenk på det slik: hvis en webskraper er som én enkelt bibliotekar som kopierer utdrag fra en bok, er en cloud crawler som et helt team av superdatamaskiner som skanner hver eneste bok i biblioteket samtidig, og merker, organiserer og analyserer innholdet underveis. Resultatet? Bedrifter får rikere, ferskere og mer handlingsrettet data — uten flaskehalser fra lokal maskinvare eller manuelt arbeid (, ).
Cloud crawler vs. tradisjonell webskraper: Hva er den reelle forskjellen?
Hvis du noen gang har brukt en webskraper, kjenner du grunnprinsippet: pek den mot en side, definer hva du vil ha, og la den hente dataene. Men etter hvert som nettet blir større og mer komplisert, begynner den gamle metoden å vise sine begrensninger. Slik står cloud crawlere og tradisjonelle webskrapere mot hverandre:
| Funksjon/område | Tradisjonell webskraper | Cloud crawler |
|---|---|---|
| Drift | Kjører på din lokale enhet eller server | Kjører i skyen (eksterne datasentre) |
| Skala | Begrenset av kraften i maskinen din | Massivt parallell — tusenvis av sider samtidig |
| Hastighet | Tregere, særlig ved store oppdrag | Høyhastighets batchbehandling |
| Vedlikehold | Trenger hyppige oppdateringer, bryter når nettsteder endrer seg | Skybasert, oppdateres automatisk, mindre skjør |
| Datatyper | Vanligvis tekst, noen ganger bilder | Tekst, bilder, PDF-er, komplekse layouts |
| Tilgang | Bundet til enheten og nettverket ditt | Tilgjengelig hvor som helst, på hvilken som helst enhet |
| Planlegging | Manuell eller enkel automatisering | Avansert planlegging, gjentakende jobber |
| Best for | Små prosjekter, enkle nettsteder | Store, hyppige eller komplekse databehov |
Cloud crawlere er bygget for det moderne nettet — der data finnes overalt, og fart og skala er helt avgjørende (, ).
Slik gjør cloud crawlere datainnsamling mye mer effektiv
Her blir det virkelig interessant. Cloud crawlere bruker kraften i skybasert databehandling til å behandle tusenvis av nettsider parallelt. Det betyr at du kan skrape et helt e-handelskatalog, overvåke konkurrentpriser på tvers av mange nettsteder, eller samle eiendomsannonser fra alle de store portalene — på en brøkdel av tiden en tradisjonell skraper ville brukt.
Hvorfor er dette viktig? Fordi i bransjer som e-handel, finans og eiendom er fersk data helt avgjørende. Priser, lagerstatus og markedstrender kan endre seg fra minutt til minutt. Å vente i timevis eller dager på at en lokal skraper skal bli ferdig, er rett og slett ikke et alternativ. Cloud crawlere er ikke begrenset av RAM-en på laptopen din eller kontorets Wi‑Fi — de skalerer opp etter behov, slik at du kan ta deg an store oppdrag uten å svette (, ).
Bransjer som særlig drar nytte av denne effektiviteten inkluderer:
- E-handel: Priskontroll, innsamling av produktkataloger, analyse av anmeldelser
- Eiendom: Samle annonser, følge markedstrender, sammenligne objekter
- Finans: Analyse av nyheter og stemning, overvåking av aksjer/krypto, regulatorisk oppfølging
- Salg og markedsføring: Lead-generering, konkurrentanalyse, trendidentifisering
Og ærlig talt — det er bare toppen av isfjellet. Hvis du trenger webdata i stor skala, er en cloud crawler din nye bestevenn.
Thunderbits cloud crawler-løsning: Rask, fleksibel og kraftig
La meg ta på meg Thunderbit-hatten et øyeblikk (ok, jeg tar den egentlig aldri av). sin skybaserte scraping-modus er vårt svar på den moderne datautfordringen — en cloud crawler laget for bedriftsbrukere som vil ha resultater, ikke hodepine.
Dette er det som gjør Thunderbits cloud crawler spesielt sterk:
- Høyhastighets batch-skraping: Skrap opptil 50 sider om gangen, med cloud-servere i USA, EU og Asia for global dekning. Slutt å vente på at laptopen skal jobbe seg gjennom en lang liste.
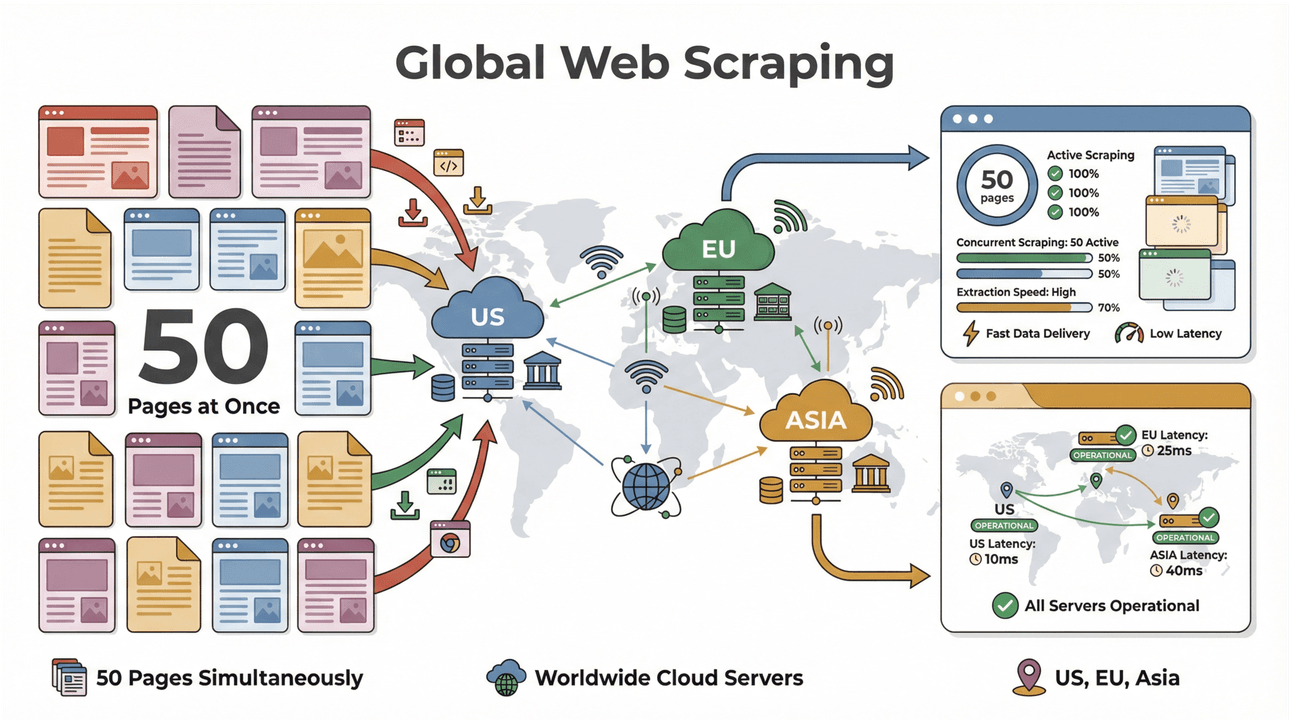
- Støtte for komplekse sider: Thunderbits AI kan håndtere alt fra dynamiske e-handelsnettsteder til vriene PDF-er og til og med utvinning av bilder. Hvis det finnes på nettet, kan Thunderbit sannsynligvis skrape det ().
- Crawling av undersider: Trenger du å berike dataene dine med detaljer fra undersider, som produktspecs eller forfatterbiografier? Thunderbits AI kan besøke hver underside og slå resultatene sammen med hoveddatasettet ditt ().
- Smart strukturering av data: Bruk “AI Suggest Fields” for å la Thunderbit lese siden og foreslå de beste kolonnene — ingen koding eller malbygging nødvendig.
- Eksporter dit du vil: Send dataene rett til Excel, Google Sheets, Airtable eller Notion. Eller last dem ned som CSV/JSON — det som passer arbeidsflyten din best ().
- Ingen vedlikehold nødvendig: Thunderbits AI tilpasser seg nettsideendringer, så du slipper å fikse ødelagte skrapere hele tiden ().
Og ja, du kan teste alt dette med en — så du trenger ikke bare å stole på meg.
Implementering av cloud crawler: Sky vs. lokal — hva passer best for deg?
En av de største fordelene med cloud crawlere er fleksibiliteten i hvordan de settes opp. Med en tradisjonell, lokal crawler er du bundet til en bestemt enhet, et bestemt nettverk og ofte mye oppsett og frustrasjon. Hvis PC-en går i dvale eller internett faller ut, stopper skrapingen. Skaleringen betyr ofte at du må kjøpe mer maskinvare eller kjøre flere skript.
Cloud crawlere snur dette på hodet:
- Ingen spesialmaskinvare nødvendig: Alt det tunge arbeidet skjer i skyen. Du kan starte store scraping-jobber fra en Chromebook, en Mac eller til og med telefonen din.
- Tilgang fra hvor som helst: På reise? Jobber du eksternt? Ikke noe problem — cloud crawleren din er alltid tilgjengelig.
- Enkel skalering: Trenger du å skrape 10 000 sider i stedet for 100? Bare øk jobbstørrelsen — uten involvering fra IT.
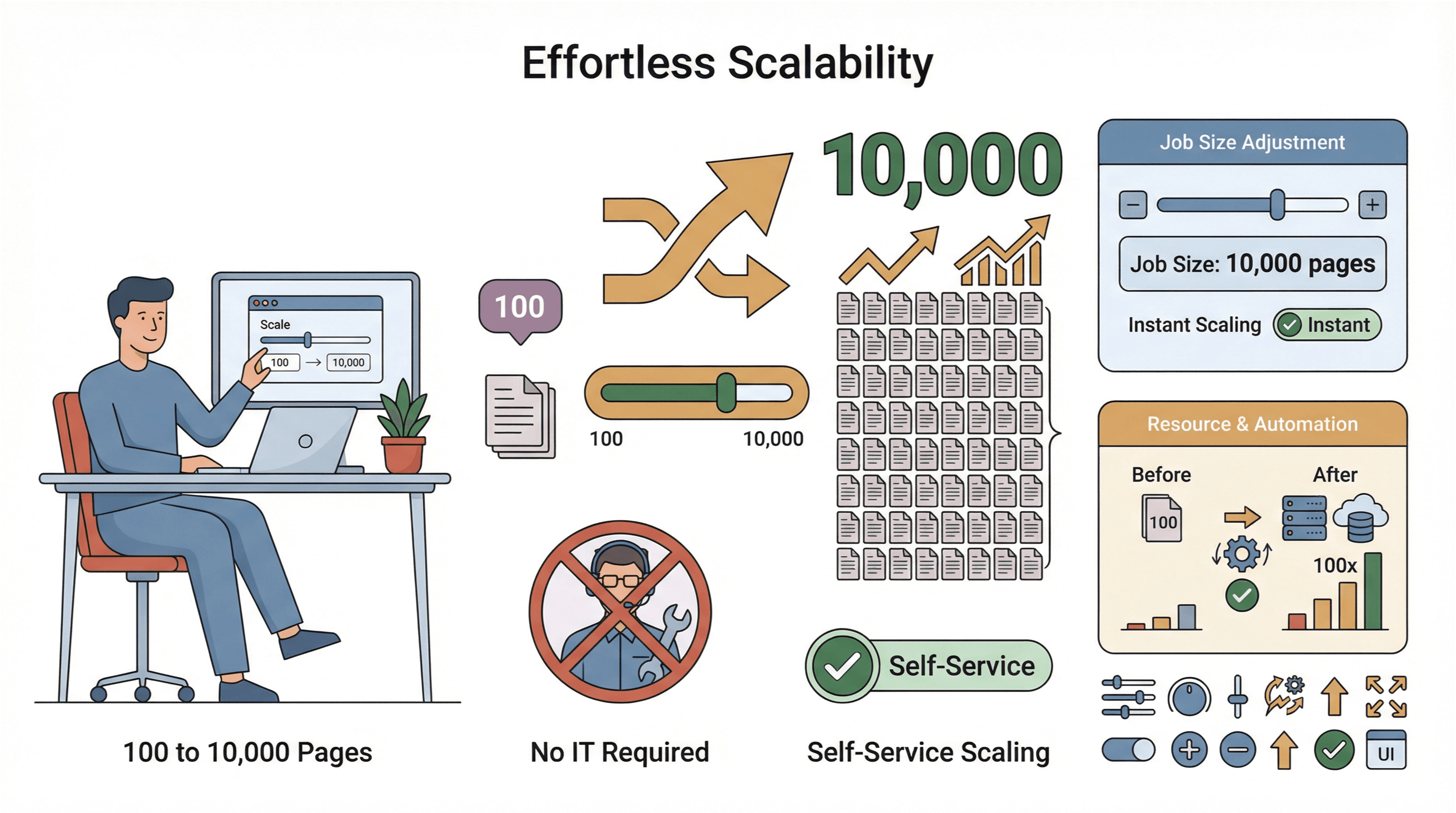
- Global datainnsamling: Med cloud-servere i flere regioner kan du få tilgang til geo-begrenset innhold og håndtere etterlevelse enklere ().
Selvfølgelig er sikkerhet og etterlevelse alltid viktige hensyn. De beste cloud crawlerne, inkludert Thunderbit, bruker krypterte forbindelser, respekterer nettsiders vilkår og tilbyr funksjoner som hjelper deg å håndtere sensitive data på en ansvarlig måte.
Effekten i praksis: Slik endrer cloud crawlere datadrevne strategier
La oss bli konkrete. Hvorfor går bedrifter over til cloud crawlere? Fordi de ser reell og målbar effekt:
- Sanntids markedsanalyse: Retailere bruker cloud crawlere til å følge konkurrentpriser og lagerstatus i sanntid, noe som muliggjør dynamisk prising og raskere respons på markedsendringer ().
- Forutsigelse av forbrukertrender: Merkevarer samler anmeldelser, innlegg i sosiale medier og forumdiskusjoner for å oppdage nye trender og justere kampanjer fortløpende.
- Salg og lead-generering: Salgsteam bygger oppdaterte lead-lister fra kataloger, arrangementsider og til og med PDF-er — og mater CRM-systemene med ferske, kvalifiserte kontakter ().
- Drift og compliance: Finansselskaper bruker cloud crawlere til å overvåke regulatoriske oppdateringer, nyheter og innsendinger på tvers av flere jurisdiksjoner — for å redusere risiko og holde seg foran endringene.
Den røde tråden? Cloud crawlere gjør at team kan jobbe raskere, ta smartere beslutninger og slå konkurrenter som fortsatt sitter fast i treg lane.
Viktige funksjoner å se etter i en cloud crawler
Ikke alle cloud crawlere er like gode. Hvis du vurderer alternativer, er dette funksjonene som betyr mest — og der Thunderbit virkelig utmerker seg:
- Skalerbarhet: Klarer den tusenvis av sider samtidig? Blir den tregere når jobbene blir større?
- Brukervennlighet: Er grensesnittet enkelt for ikke-tekniske brukere? Kan du sette opp en scraping-jobb med noen få klikk?
- Støtte for flere datatyper: Tekst, bilder, PDF-er, undersider — kan den håndtere alt?
- Integrasjoner: Eksporterer den til verktøyene du allerede bruker (Excel, Sheets, Notion, Airtable)?
- Planlegging: Kan du sette opp gjentakende jobber for alltid ferske data?
- AI-assistanse: Tilbyr den smarte feltforslag, databerikelse og automatisk tilpasning når nettsteder endrer seg?
- Sikkerhet og etterlevelse: Er dataene og innloggingsdetaljene dine beskyttet? Hjelper den deg å følge personvernregler?
Thunderbit krysser av på alle disse punktene, og er derfor et sterkt valg for team som vil ha kraft uten plunder.
Kom i gang: Slik bruker du en cloud crawler i bedriften din
Klar til å sette i gang? Slik kommer en typisk bedriftsbruker i gang med en cloud crawler som Thunderbit:
- Installer : Rask oppstart, ingen IT-hjelp nødvendig.
- Velg målet ditt: Åpne nettsiden, listen eller dokumentet du vil skrape.
- Klikk “AI Suggest Fields”: La Thunderbits AI skanne siden og foreslå de beste kolonnene å hente ut.
- Tilpass ved behov: Legg til, fjern eller gi feltene nye navn slik at de passer det du trenger.
- Velg cloud scraping-modus: For store jobber eller komplekse sider, bytt til sky-modus for maksimal hastighet.
- Start skrapingen: Thunderbit behandler opptil 50 sider om gangen i skyen.
- Gå gjennom og eksporter: Forhåndsvis resultatene, og eksporter deretter til Excel, Google Sheets, Notion eller Airtable.
- Planlegg gjentakende jobber: Ved løpende behov kan du sette opp planlagte skrapinger — dataene oppdateres automatisk ().
Tips: Begynn med en liten jobb for å bli kjent med flyten, og skaler opp når du føler deg trygg. Og ikke vær redd for å bruke Thunderbits support eller dokumentasjon — de er der for å hjelpe.
Fremtiden for datainnsamling: Hva blir det neste for cloud crawlere?
Revolusjonen rundt cloud crawlere har så vidt begynt. Dette følger jeg ekstra nøye med på de neste årene:
- Smartere AI-uttrekk: Cloud crawlere blir stadig bedre til å forstå kontekst, relasjoner og til og med sentiment — noe som gjør dataene de samler inn mer verdifulle ().
- Støtte for nye datatyper: Forvent bedre håndtering av video, lyd og interaktivt innhold — ikke bare statisk tekst og bilder.
- Dypere automatisering: Fra automatisk planlegging til varsler i sanntid — cloud crawlere blir enda mer hands-off for bedriftsbrukere.
- Sterkere compliance: Etter hvert som personvernlovene utvikler seg, vil cloud crawlere få flere innebygde verktøy som hjelper team å holde seg innenfor regelverket.
- Integrasjon med BI- og AI-verktøy: Direkte datapipelines fra cloud crawlere til analyseverktøy, dashboards og maskinlæringsplattformer.
Kort sagt er cloud crawlere på god vei til å bli ryggraden i digital forretningsstrategi — og drive alt fra produktlanseringer til AI-drevet prognosearbeid ().
Konklusjon: Hvorfor cloud crawlere er uunnværlige for moderne bedrifter
Kort oppsummert: nettet eksploderer med data, og de gamle metodene for å samle dem inn henger rett og slett ikke med. Cloud crawlere er neste utviklingstrinn — med fart, skala og intelligens som tradisjonelle skrapere ikke kan matche. Verktøy som gjør det mulig for alle team, tekniske eller ikke, å utnytte hele potensialet i webdata — og dermed ta smartere beslutninger, reagere raskere og få et reelt konkurransefortrinn.
Hvis du er klar til å legge manuell skraping og trege dataprosesser bak deg, er det nå du bør utforske hva en cloud crawler kan gjøre for virksomheten din. Prøv Thunderbits cloud scraping-modus, og se hvor enkelt — og kraftfullt — moderne datainnsamling kan være. Og hvis du vil gå dypere, kan du sjekke ut for flere guider, tips og eksempler fra virkeligheten.
Vanlige spørsmål
1. Hva er en cloud crawler, enkelt forklart?
En cloud crawler er et skybasert verktøy som automatisk finner, henter ut og analyserer store mengder data fra nettet. I motsetning til tradisjonelle skrapere som kjører på din lokale enhet, opererer cloud crawlere i kraftige datasentre, noe som gir enorm skala og høy hastighet.
2. Hvordan skiller en cloud crawler seg fra en vanlig webskraper?
Cloud crawlere kjører i skyen, håndterer tusenvis av sider samtidig, støtter komplekse datatyper som bilder og PDF-er, og krever verken vedlikehold eller lokal maskinvare. Tradisjonelle skrapere er begrenset av kraften i enheten din og passer best for mindre og enklere jobber.
3. Hva er de største fordelene med å bruke en cloud crawler?
Cloud crawlere gir høyhastighets datainnsamling i stor skala, støtte for komplekse nettsteder, enkel tilgang fra hvor som helst og avanserte funksjoner som planlegging og AI-drevet uttrekk. De er ideelle for bedrifter som trenger ferske, handlingsrettede data raskt.
4. Hvordan fungerer Thunderbits cloud crawler for bedriftsbrukere?
Thunderbits cloud crawler lar deg sette opp en scraping-jobb på bare noen få klikk — helt uten koding. Du kan hente data fra nettsteder, PDF-er og bilder, berike dem med AI og eksportere direkte til Excel, Google Sheets, Notion eller Airtable. Den er laget for ikke-tekniske brukere som vil ha resultater, ikke kompleksitet.
5. Er cloud crawling trygt og i tråd med personvernregler?
Ja, ledende cloud crawlere som Thunderbit bruker krypterte forbindelser og beste praksis for datasikkerhet. Sørg alltid for å hente kun offentlig tilgjengelige data og respekter nettsiders vilkår og gjeldende personvernregler.
Klar til å se hva en cloud crawler kan gjøre? og begynn å utforske verdenen av storskala, skybasert datainnsamling i dag.
Lær mer