

Nettet flommer over av verdifulle data — enten du jobber med salg, e-handel eller markedsanalyse, er web scraping det hemmelige våpenet for leadgenerering, prisovervåking og konkurranseanalyse. Men her er baksiden: Etter hvert som flere bedrifter tar i bruk scraping, slår nettstedene hardere tilbake enn noen gang. Endringen er tydelig: en analyse fra ppc.land i 2024 fant at mer enn en tredjedel av de 1 000 største nettstedene allerede blokkerer bare OpenAIs crawler — og det bredere verktøysettet med IP-blokkeringer, CAPTCHAs og nettleserfingeravtrykk er nå normalen, ikke unntaket.
Hvis du noen gang har sett Python-scriptet ditt kjøre problemfritt i 20 minutter — og så plutselig treffe en vegg av 403-feil — vet du hvor frustrerende det er.
Jeg har jobbet i årevis med SaaS og automatisering, og jeg har sett med egne øyne hvordan scraping-prosjekter kan gå fra «wow, dette er enkelt» til «hvorfor blir jeg blokkert overalt?» på et øyeblikk. Så la oss være praktiske: Jeg skal vise deg hvordan du gjør web scraping uten å bli blokkert i Python, dele de beste teknikkene og kodebitene, og vise når det er på tide å vurdere AI-drevne alternativer som Thunderbit. Enten du er en Python-proff eller bare så vidt får det til (ordspill ment), går du herfra med et verktøysett for pålitelig datauthenting uten blokkeringer.
Hva er web scraping uten å bli blokkert i Python?
Kjernen i web scraping uten å bli blokkert er å hente data fra nettsteder på en måte som ikke utløser anti-bot-forsvaret deres. I Python-verdenen handler dette om mer enn bare å skrive en requests.get()-løkke — det handler om å gli inn i mengden, etterligne ekte brukere og ligge ett steg foran deteksjonssystemene.
Hvorfor Python? Python er det mest populære språket for web scraping — takket være enkel syntaks, et enormt økosystem (tenk: requests, BeautifulSoup, Scrapy, Selenium) og fleksibilitet for alt fra raske skript til distribuerte crawlere. Men popularitet har en pris: mange anti-bot-systemer er nå finjustert for å oppdage scraping-mønstre fra Python.
Så hvis du vil scrape pålitelig, må du gå lenger enn det grunnleggende. Det betyr å forstå hvordan nettsteder oppdager roboter, og hvordan du kan lure dem — uten å krysse noen etiske eller juridiske grenser.
Hvorfor det er viktig å unngå blokkeringer i Python-webscraping-prosjekter
Å bli blokkert er ikke bare et teknisk lite irritasjonsmoment — det kan velte hele forretningsprosesser. La oss bryte det ned:
| Bruksområde | Konsekvens av å bli blokkert |
|---|---|
| Leadgenerering | Ufullstendige eller utdaterte prospektlister, tapte salg |
| Prisovervåking | Går glipp av konkurrenters prisendringer, dårlige prisbeslutninger |
| Innholdsaggregasjon | Hull i nyheter, anmeldelser eller forskningsdata |
| Markedsinnsikt | Blinde flekker i overvåking av konkurrenter eller bransje |
| Eiendomsannonser | Unøyaktige eller utdaterte eiendomsdata, tapte muligheter |
Når en scraper blir blokkert, mister du ikke bare data — du sløser med ressurser, risikerer samsvarsproblemer og kan i verste fall ta dårlige forretningsbeslutninger basert på ufullstendig informasjon. I en verden der 79 % av virksomheter bruker web scraping til leadgenerering, er pålitelighet alt.
Hvordan nettsteder oppdager og blokkerer Python-webscrapere
Nettsteder har blitt utrolig flinke til å avsløre roboter. Her er de vanligste anti-scraping-forsvarene du vil støte på (Medium, Bright Data):
- Svartelisting av IP-adresser: For mange forespørsler fra én IP? Blokkert.
- Sjekk av User-Agent og headere: Forespørsler med manglende eller generiske headere (som Pythons standard
python-requests/2.25.1) skiller seg ut. - Rate limiting: For mange forespørsler på kort tid utløser struping eller utestengelse.
- CAPTCHAs: «Bevis at du er menneske»-oppgaver som roboter ikke kan løse (lett).
- Atferdsanalyse: Nettsteder ser etter robotaktige mønstre — som å klikke på samme knapp med samme intervall.
- Honeypots: Skjulte lenker eller felt som bare roboter vil samhandle med.
- Nettleserfingeravtrykk: Innsamling av detaljer om nettleseren og enheten din for å oppdage automatiseringsverktøy.
- Cookie- og sessionsporing: Roboter som ikke håndterer cookies eller økter riktig, blir flagget.
Tenk på det som sikkerhetskontroll på flyplassen: Hvis du ser ut, oppfører deg og beveger deg som alle andre, glir du rett gjennom. Dukker du opp i trenchcoat og solbriller, kan du regne med ekstra spørsmål.
Viktige Python-teknikker for web scraping uten å bli blokkert
La oss komme til det som virkelig gjelder: hvordan du faktisk unngår blokkeringer når du scraper med Python. Her er kjerne-strategiene alle scrapere bør kjenne til:

Roterende proxyer og IP-adresser
Hvorfor det er viktig: Hvis alle forespørslene dine kommer fra samme IP, er du et enkelt mål for IP-blokkering. Roterende proxyer lar deg fordele forespørslene på mange IP-er, noe som gjør deg mye vanskeligere å blokkere.
Slik gjør du det i Python:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...flere proxyer
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# behandle responsen
Du kan bruke betalte proxy-tjenester (som residential eller roterende proxyer) for bedre pålitelighet (ScrapingBee).
Sette User-Agent og tilpassede headere
Hvorfor det er viktig: Standard headere fra Python roper «bot». Etterlign ekte nettlesere ved å sette user-agent og andre headere.
Eksempelkode:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
Roter user-agents for ekstra skjuling (ZenRows).
Randomisering av forespørselstidspunkt og mønstre
Hvorfor det er viktig: Roboter er raske og forutsigbare; mennesker er trege og tilfeldige. Legg inn pauser og varier navigasjonen.
Python-tips:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # Vent 2–7 sekunder
Du kan også randomisere klikkstier og rullingsmønstre hvis du bruker Selenium.
Håndtere cookies og økter
Hvorfor det er viktig: Mange nettsteder krever cookies eller økt-token for å få tilgang til innhold. Roboter som ignorerer dette, blir blokkert.
Slik håndterer du det i Python:
import requests
session = requests.Session()
response = session.get(url)
# session håndterer cookies automatisk
For mer komplekse flyter kan du bruke Selenium til å hente og gjenbruke cookies.
Simulere menneskelig atferd med headless-nettlesere
Hvorfor det er viktig: Noen nettsteder bruker JavaScript, musebevegelser eller rulling som signaler på ekte brukere. Headless-nettlesere som Selenium eller Playwright kan etterligne disse handlingene.
Eksempel med Selenium:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
Dette hjelper deg å omgå atferdsanalyse og dynamisk innhold (ScrapingBee).
Avanserte strategier: omgå CAPTCHAs og honeypots i Python
CAPTCHAs er laget for å stoppe roboter effektivt. Selv om noen Python-biblioteker kan løse enkle CAPTCHAs, er det fleste seriøse scrapere som bruker tredjepartstjenester (som 2Captcha eller Anti-Captcha) for å løse dem mot betaling (Medium).
Eksempel på integrasjon:
# Pseudokode for bruk av 2Captcha API
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# Vent på løsning, og send deretter inn sammen med forespørselen din
Honeypots er skjulte felt eller lenker som bare roboter vil samhandle med. Unngå å klikke på eller sende inn noe som ikke er synlig i en ekte nettleser (ZenRows).
Slik designer du robuste request-headere med Python-biblioteker
I tillegg til user-agent kan du rotere og randomisere andre headere (som Referer, Accept, Origin osv.) for å gli enda bedre inn.
Med Scrapy:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# Flere headere
}
}
Med Selenium: Bruk nettleserprofiler eller utvidelser for å sette headere, eller injiser dem via JavaScript.
Hold header-listen oppdatert — kopier ekte nettleserforespørsler med DevTools i nettleseren for inspirasjon.
Når tradisjonell Python-scraping ikke er nok: fremveksten av anti-bot-teknologi
Her er realiteten: Jo mer populært scraping blir, desto mer utvikles anti-bot-løsningene. Store nettsteder blokkerer nå ikke bare åpenbare roboter, men også avanserte headless-nettlesere og roterende proxyer. AI-drevet deteksjon, dynamiske terskler for forespørsler og nettleserfingeravtrykk gjør det vanskeligere enn noen gang for selv avanserte Python-skript å forbli uoppdaget (Medium).
Noen ganger, uansett hvor smart koden din er, treffer du en vegg. Da er det på tide å vurdere en annen tilnærming.
Thunderbit: et AI Web Scraper-alternativ til Python-scraping
Når Python når grensen sin, trer Thunderbit inn som en kodefri, AI-drevet webscraper bygget for forretningsbrukere — ikke bare utviklere. I stedet for å slite med proxyer, headere og CAPTCHAs, leser Thunderbits AI-agent nettstedet, foreslår de beste feltene å hente ut og håndterer alt fra navigasjon på undersider til dataeksport.
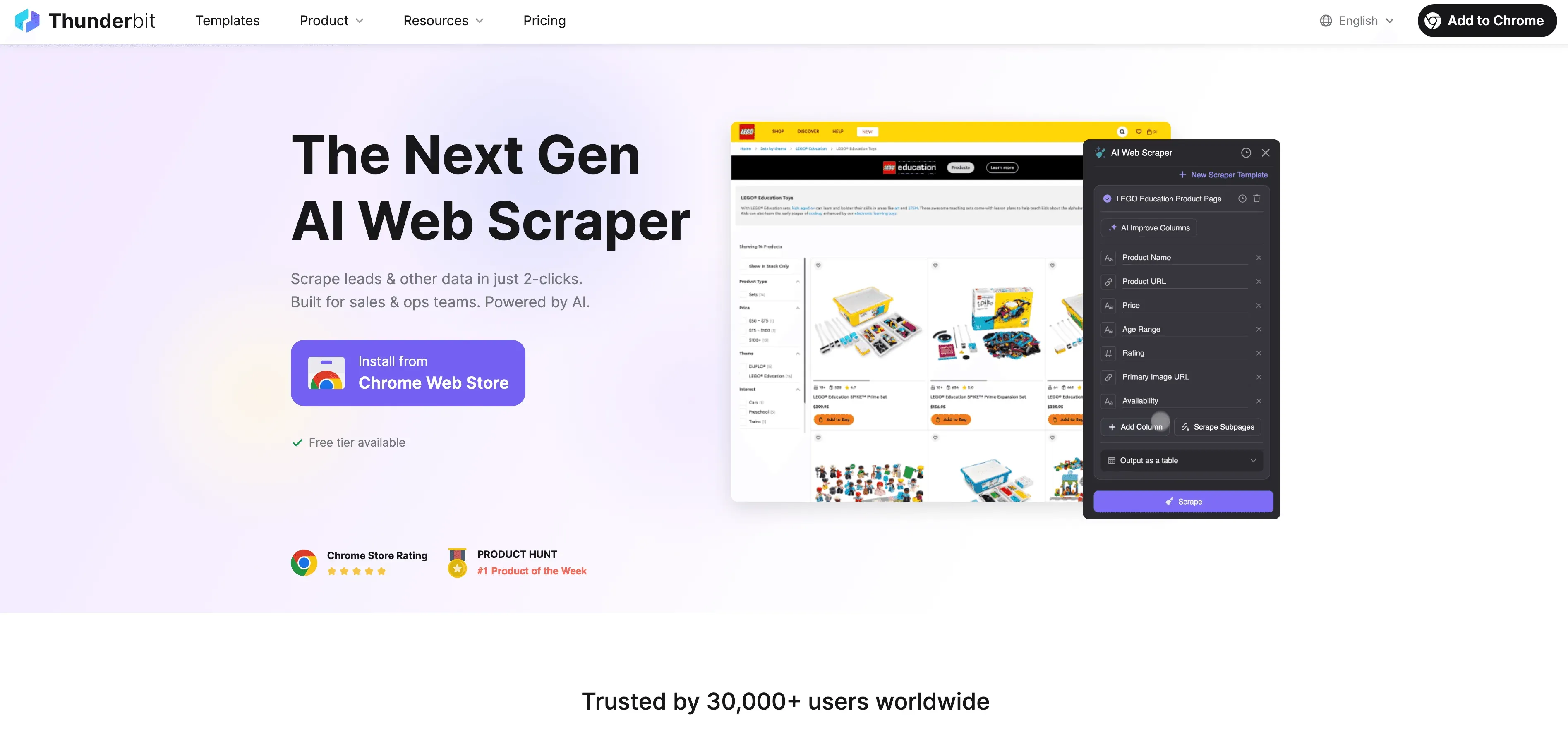
Hva gjør Thunderbit annerledes?
- AI-forslag til felt: Klikk på «AI Suggest Fields», så skanner Thunderbit siden, anbefaler kolonner og genererer til og med henteinstruksjoner.
- Scraping av undersider: Thunderbit kan besøke hver underside (som produktdetaljer eller LinkedIn-profiler) og berike tabellen din automatisk.
- Cloud- eller nettleserscraping: Velg det raskeste alternativet — skyen for offentlige nettsteder, nettleser for sider bak innlogging.
- Planlagt scraping: Sett det opp én gang og glem det — Thunderbit kan scrape etter en tidsplan, slik at dataene alltid er ferske.
- Umiddelbare maler: For populære nettsteder (Amazon, Zillow, Shopify osv.) tilbyr Thunderbit maler med ett klikk — ingen oppsett nødvendig.
- Gratis dataeksport: Eksporter til Excel, Google Sheets, Airtable eller Notion — ingen ekstra kostnader.
Thunderbit er betrodd av over 100 000 brukere over hele verden, og du trenger ikke skrive én eneste linje kode.
Hent data fra hvilket som helst nettsted med AI Get Started Free
Slik hjelper Thunderbit brukere med å unngå blokkeringer og automatisere datauthenting
Thunderbits AI etterligner ikke bare menneskelig atferd — den tilpasser seg hvert nettsted i sanntid og reduserer risikoen for å bli blokkert. Slik fungerer det:
- AI tilpasser seg layoutendringer: Mindre omarbeiding når et nettsted oppdaterer designet — du slipper å gå tilbake og justere selektorer hver uke.
- Håndtering av undersider og paginering: Thunderbit følger lenker og paginerte lister for deg, slik en person som klikker seg gjennom ville gjort.
- Sky-scraping i batcher: Kjør jobber fra Thunderbits sky i stedet for fra laptopen din, med batchstørrelser satt per plan (se prissiden for gjeldende grenser).
- Mindre kode å vedlikeholde: Du er ikke den som jakter på ødelagte selektorer ved midnatt når et nettsted endrer seg; AI-en leser siden på nytt.
For en dypere gjennomgang, se Slik scraper du hvilket som helst nettsted med AI.
Sammenligning av Python-scraping vs. Thunderbit: hva bør du velge?
La oss sette dem side om side:
| Egenskap | Python-scraping | Thunderbit |
|---|---|---|
| Oppsettstid | Middels–høy (skript, proxyer osv.) | Lav (2 klikk, AI gjør resten) |
| Teknisk ferdighetsnivå | Koding kreves | Ingen koding nødvendig |
| Pålitelighet | Varierer (lett å ødelegge) | Høy (AI tilpasser seg endringer) |
| Risiko for blokkering | Middels–høy | Lav (AI etterligner brukere og tilpasser seg) |
| Skalerbarhet | Trenger egen kode og skyoppsett | Innebygd sky- og batchescraping |
| Vedlikehold | Hyppig (endringer på nettsteder, blokkeringer) | Minimalt (AI justerer seg automatisk) |
| Eksportalternativer | Manuelt (CSV, DB) | Direkte til Sheets, Notion, Airtable, CSV |
| Kostnad | Gratis (men tidkrevende) | Gratis nivå, betalte planer for større volum |
Når du bør bruke Python:
- Du trenger full kontroll, egendefinert logikk eller integrasjon med andre Python-flyter.
- Du scraper nettsteder med minimale anti-bot-forsvar.
Når du bør bruke Thunderbit:
- Du vil ha fart, pålitelighet og null oppsett.
- Du scraper komplekse eller ofte endrede nettsteder.
- Du vil slippe proxyer, CAPTCHAs eller kode.
Prøv Thunderbit AI Web Scraper gratis
Steg-for-steg-guide: Slik setter du opp web scraping uten å bli blokkert i Python
La oss gå gjennom et praktisk eksempel: scraping av produktdata fra et eksempelnettsted, samtidig som vi bruker beste praksis for å unngå blokkeringer.
1. Installer nødvendige biblioteker
pip install requests beautifulsoup4 fake-useragent
2. Forbered skriptet ditt
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Erstatt med dine URL-er
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Hent ut data her
print(soup.title.text)
else:
print(f"Blokkert eller feil på {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # Tilfeldig forsinkelse
3. Legg til proxyrotasjon (valgfritt)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# Flere proxyer
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...resten av koden
4. Håndter cookies og økter
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...resten av koden
5. Feilsøkingstips
- Hvis du ser mange 403/429-feil, senk farten på forespørslene eller prøv nye proxyer.
- Hvis du møter CAPTCHAs, vurder å bruke Selenium eller en tjeneste for CAPTCHA-løsning.
- Sjekk alltid nettstedets
robots.txtog vilkårene for bruk.
Konklusjon og viktige læringspunkter
Web scraping i Python er kraftfullt — men å bli blokkert er en konstant risiko ettersom anti-bot-teknologien utvikler seg. Den beste måten å unngå blokkeringer på? Kombiner tekniske beste praksiser (roterende proxyer, smarte headere, tilfeldige forsinkelser, øktbehandling og headless-nettlesere) med respekt for nettstedets regler og etikk.
Men noen ganger er ikke engang de beste Python-triksene nok. Da kommer AI-verktøy som Thunderbit inn — kodefritt, laget for å håndtere layoutendringer og paginering som setter rigide skript ut av spill, og rettet mot forretningsbrukere som helst slipper å sitte og passe på en Selenium-jobb hele kvelden.
Vil du se hvor enkelt scraping kan være? Last ned Thunderbits Chrome-utvidelse og prøv det selv — eller sjekk ut bloggen vår for flere scraping-tips og veiledninger.
Vanlige spørsmål
1. Hvorfor blokkerer nettsteder Python-webscrapere?
Nettsteder blokkerer scrapere for å beskytte dataene sine, hindre overbelastning av servere og stoppe automatiserte roboter fra å misbruke tjenestene deres. Python-skript er lette å oppdage hvis de bruker standard headere, ikke håndterer cookies eller sender for mange forespørsler for raskt.
2. Hva er de mest effektive måtene å unngå å bli blokkert når man scraper med Python?
Bruk roterende proxyer, sett realistiske user-agents og headere, randomiser tidspunktet for forespørsler, håndter cookies/økter og simuler menneskelig atferd med verktøy som Selenium eller Playwright.
3. Hvordan hjelper Thunderbit med å unngå blokkeringer sammenlignet med Python-skript?
Thunderbit bruker AI til å tilpasse seg sideoppsett, etterligne menneskelig nettlesing og håndtere undersider og paginering automatisk. Det reduserer risikoen for blokkeringer ved å gli inn og oppdatere tilnærmingen i sanntid — uten koding eller proxyer.
4. Når bør jeg bruke Python-scraping vs. et AI-verktøy som Thunderbit?
Bruk Python når du trenger egendefinert logikk, integrasjon med annen Python-kode, eller scraper enkle nettsteder. Bruk Thunderbit for rask, pålitelig og skalerbar scraping — spesielt når nettstedene er komplekse, endrer seg ofte eller blokkerer skript aggressivt.
5. Er web scraping lovlig?
Web scraping er lovlig for offentlig tilgjengelige data, men du må respektere hvert nettsteds vilkår, personvernerklæringer og relevante lover. Scrape aldri sensitive eller private data, og bruk alltid scraping på en etisk og ansvarlig måte.
Klar for å scrape smartere, ikke hardere? Prøv Thunderbit, og legg blokkeringene bak deg.
Les mer:
- Google News-scraping med Python: en steg-for-steg-guide
- Bygg et verktøy for prisovervåking av Best Buy med Python
- 14 måter å gjøre web scraping uten å bli blokkert
- 10 beste tips for hvordan du ikke blir blokkert ved web scraping
Prøv AI Web Scraper Get Started Free




