
Det er noe helt tidløst med å fyre opp terminalen, taste inn én kommando og se rå webdata renne inn – litt som å ha knekt Matrix-koden. For utviklere og tekniske power users er den lille tryllestaven: et nøkternt kommandolinjeverktøy som i praksis kjører «overalt», fra skyservere til smarte kjøleskap. Og selv i 2026, med alle de glossy no-code- og AI-verktøyene der ute, er webskraping med curl fortsatt et go-to valg for deg som vil ha fart, kontroll og muligheten til å skripte absolutt alt.
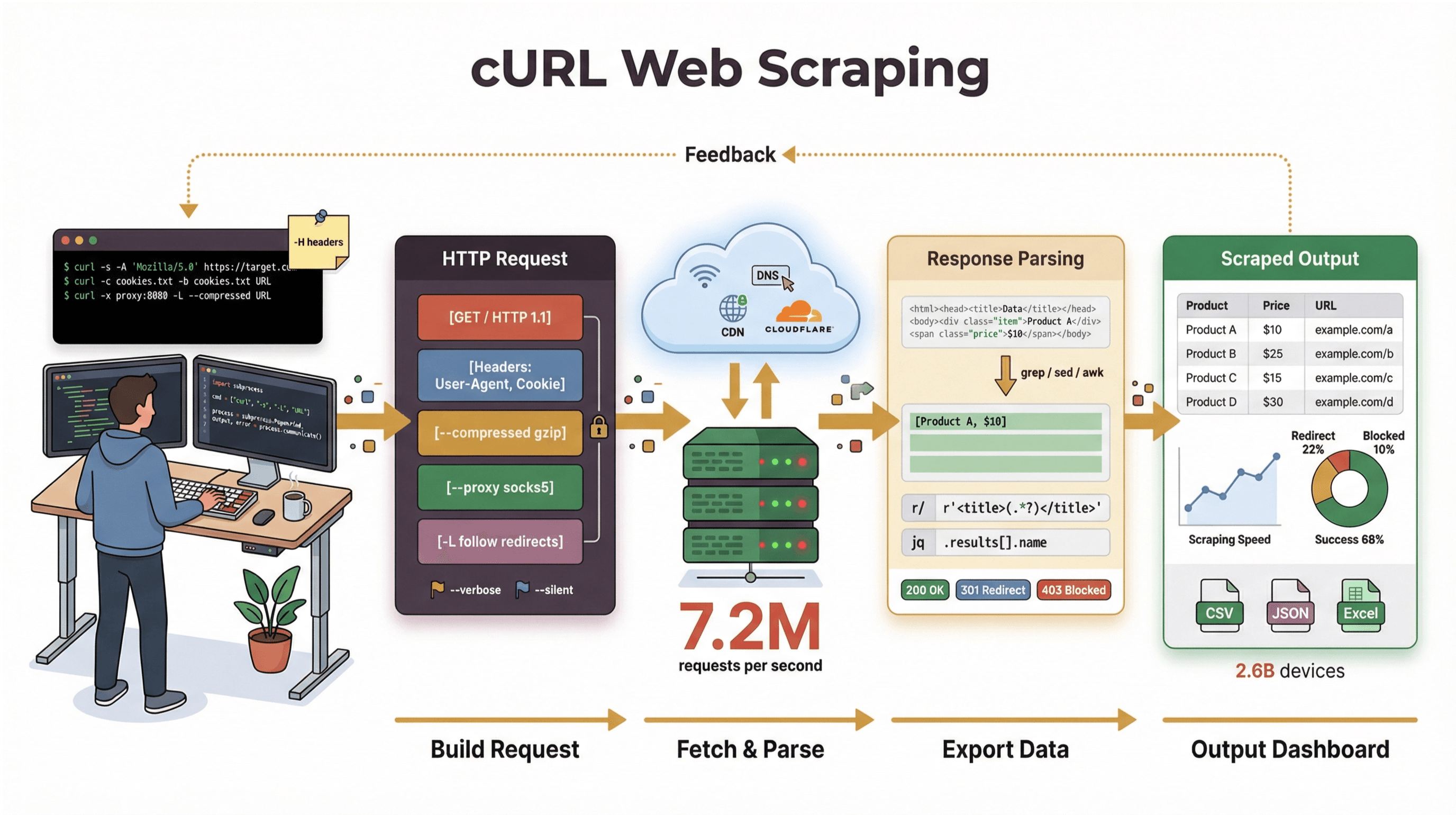 Jeg har brukt mange år på å bygge automatisering og hjelpe team med å temme webdata, og jeg ender fortsatt opp med å bruke cURL når jeg må hente en side, feilsøke et API eller skissere en scraping-flyt. I denne guiden får du en curl webskraping tutorial som tar deg gjennom både grunnmuren og profftriksene – med ekte kommandoeksempler, praktiske tips og en ærlig vurdering av hvor cURL er best (og hvor det begynner å knirke). Og hvis du heller er en forretningsbruker som helst vil slippe kommandolinjen, viser jeg hvordan , vår AI-drevne web scraper, kan ta deg fra «jeg trenger disse dataene» til «her er regnearket» på to klikk – helt uten kode.
Jeg har brukt mange år på å bygge automatisering og hjelpe team med å temme webdata, og jeg ender fortsatt opp med å bruke cURL når jeg må hente en side, feilsøke et API eller skissere en scraping-flyt. I denne guiden får du en curl webskraping tutorial som tar deg gjennom både grunnmuren og profftriksene – med ekte kommandoeksempler, praktiske tips og en ærlig vurdering av hvor cURL er best (og hvor det begynner å knirke). Og hvis du heller er en forretningsbruker som helst vil slippe kommandolinjen, viser jeg hvordan , vår AI-drevne web scraper, kan ta deg fra «jeg trenger disse dataene» til «her er regnearket» på to klikk – helt uten kode.
La oss se hvorfor cURL fortsatt er relevant for webskraping i 2025, hvordan du bruker det effektivt, og når det er på tide å velge noe enda kraftigere.
Hva er cURL? Grunnmuren i web-scraping-with-curl
Helt i bunn er et kommandolinjeverktøy (og et bibliotek) for å overføre data via URL-er. Det har eksistert i snart 30 år (jepp, faktisk), og det er overalt – innebygd i operativsystemer, brukt i skript, og i det stille ansvarlig for dataflyt i mer enn . Har du noen gang kjørt en kjapp kommando for å hente en nettside, teste et API eller laste ned en fil, er sjansen stor for at det var cURL som gjorde jobben.
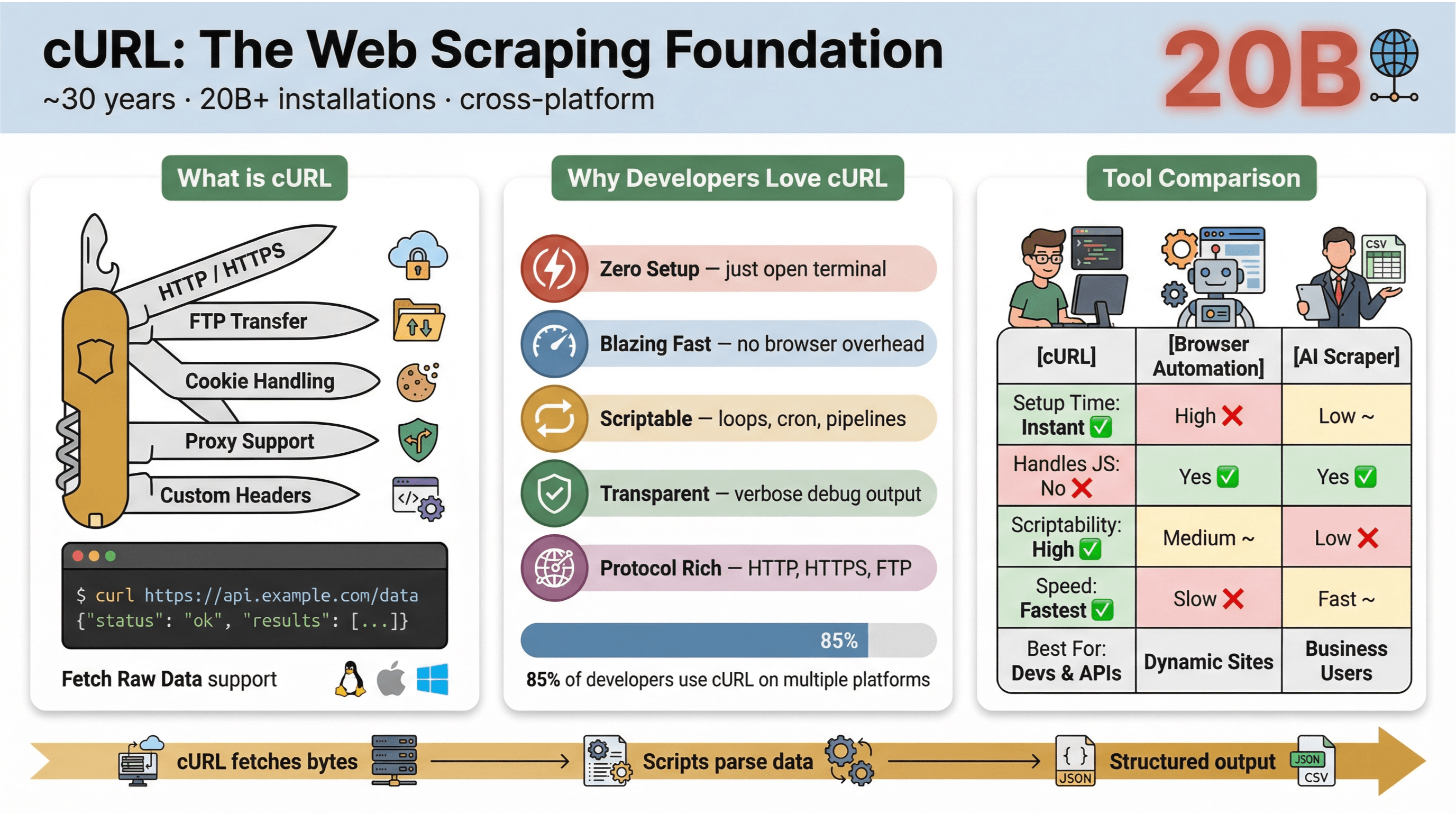 Derfor er cURL så populært til webskraping:
Derfor er cURL så populært til webskraping:
- Lett og plattformuavhengig: Funker på Linux, macOS, Windows – og til og med på innebygde enheter.
- Støtte for protokoller: Takler HTTP, HTTPS, FTP og mer.
- Kan skriptes: Perfekt for automatisering, cron-jobber og «limkode».
- Ingen brukerinteraksjon: Bygget for ikke-interaktiv bruk – ideelt for batchjobber og pipelines.
Men la oss være krystallklare: cURLs hovedjobb er å hente rådata – HTML, JSON, bilder, hva som helst. Det verken parser, renderer eller strukturerer dataene for deg. Tenk på cURL som «første etappe» i webskraping: det skaffer deg bytes, men du trenger andre verktøy (som Python-skript, grep/sed/awk eller en AI web scraper) for å gjøre det om til strukturert informasjon.
Vil du ha offisiell dokumentasjon, kan du sjekke .
Hvorfor bruke cURL til webskraping? (curl web scraping tutorial)
Hvorfor går utviklere og tekniske brukere stadig tilbake til cURL for webskraping, selv med alle de nye verktøyene? Dette er det som gjør cURL ekstra nyttig:
- Minimalt oppsett: Ingen installasjon, ingen avhengigheter – åpne terminalen og kjør.
- Hastighet: Hent data med én gang, uten å vente på at en nettleser skal laste.
- Skriptvennlig: Enkelt å loope over URL-er, automatisere forespørsler og kjede kommandoer.
- Støtte for funksjoner: Håndter cookies, proxyer, redirects, egendefinerte headere og mer.
- Full innsikt: Se nøyaktig hva som skjer med verbose/debug-utskrift.
I svarte over 85 % at de bruker cURL-kommandolinjeverktøyet, og nesten alle sa at de bruker det på flere plattformer. Det er fortsatt den sveitsiske lommekniven for HTTP-forespørsler, raske datauttak og feilsøking.
Her er en rask sammenligning av cURL mot andre metoder:
| Funksjon | cURL | Nettleserautomatisering (f.eks. Selenium) | AI Web Scraper (f.eks. Thunderbit) |
|---|---|---|---|
| Oppsettstid | Umiddelbart | Høy | Lav |
| Skriptbarhet | Høy | Middels | Lav (ingen kode nødvendig) |
| Håndterer JavaScript | Nei | Ja | Ja (Thunderbit: via nettleser) |
| Cookie/økt-støtte | Manuelt | Automatisk | Automatisk |
| Strukturering av data | Manuelt (parse senere) | Manuelt (parse senere) | AI-/malbasert |
| Best for | Utviklere, raske uttak | Komplekse, dynamiske sider | Forretningsbrukere, strukturert eksport |
Kort fortalt: cURL er knallbra for raske, skriptbare datahentinger – spesielt for statiske sider, API-er eller når du vil automatisere enkle flyter. Men i det øyeblikket du må parse kompleks HTML, håndtere JavaScript eller eksportere strukturert data, trenger du noe mer spesialisert.
Kom i gang: Enkle kommandoeksempler for cURL webskraping
La oss gjøre det hands-on. Slik bruker du cURL til grunnleggende webskraping – steg for steg.
Hente rå HTML med cURL
Det enkleste du kan gjøre: hent HTML-en til en nettside.
1curl https://books.toscrape.com/Kommandoen henter forsiden til , en offentlig demoside for webskraping. Du får rå HTML rett i terminalen – se etter tagger som <title> eller tekstbiter som «In stock.»
Lagre output til fil
Vil du lagre HTML-en for parsing senere? Bruk -o:
1curl -o page.html https://books.toscrape.com/Da får du en page.html-fil med hele HTML-innholdet. Perfekt for videre analyse eller parsing med andre verktøy.
Sende POST-forespørsler med cURL
Må du sende inn et skjema eller prate med et API? Bruk -d for POST. Her er et eksempel med , en side laget for HTTP-testing:
1curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"Du får et JSON-svar som speiler dataene du sendte inn – supert for testing og prototyping.
Se headere og feilsøke
Noen ganger vil du se respons-headere eller debugge forespørselen:
-
Kun headere (HEAD-request):
1curl -I https://books.toscrape.com/ -
Headere + body:
1curl -i https://httpbin.org/get -
Verbose/debug-output:
1curl -v https://books.toscrape.com/
Disse flaggene gjør det mye enklere å skjønne hva som skjer «under panseret» – helt essensielt når du feilsøker.
Her er en kjapp referansetabell:
| Oppgave | Kommandoeksempel | Notater |
|---|---|---|
| Hent HTML | curl URL | Skriver HTML til terminalen |
| Lagre til fil | curl -o file.html URL | Skriver output til fil |
| Inspiser headere | curl -I URL eller curl -i URL | -I for kun HEAD, -i inkluderer headere med body |
| POST skjemadata | curl -d "a=1&b=2" URL | Sender form-enkodede data |
| Debug request/response | curl -v URL | Viser detaljert request/response-info |
Flere eksempler finner du i .
Neste nivå: Avansert webskraping med cURL (web-scraping-with-curl)
Når du har kontroll på basics, åpner cURL for en hel del mer avanserte grep for mer krevende scraping.
Håndtere cookies og økter
Mange nettsteder krever cookies for å holde på innlogging eller spore brukere. Med cURL kan du lagre og gjenbruke cookies mellom forespørsler:
1# Lagre cookies etter innlogging
2curl -c cookies.txt https://example.com/login
3# Bruk cookies i senere forespørsler
4curl -b cookies.txt https://example.com/accountSlik kan du etterligne en nettleserøkt og nå sider bak innlogging (så lenge det ikke er en JavaScript-utfordring).
Etterligne User-Agent og bruke egendefinerte headere
Noen nettsteder serverer ulikt innhold basert på User-Agent eller headere. Som standard identifiserer cURL seg som «curl/VERSION», noe som kan trigge blokkering eller gi deg «feil» innhold. For å ligne en nettleser:
1curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/Du kan også sette egne headere, som språkpreferanser:
1curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/Dette øker sjansen for at du får samme innhold som en ekte nettleser.
Bruke proxyer til webskraping
Trenger du å rute trafikken via en proxy (for geo-testing eller for å redusere risikoen for IP-blokkering)? Bruk -x:
1curl -x http://proxy.example.org:4321 https://remote.example.org/Bruk proxyer ansvarlig og i tråd med nettstedets vilkår.
Automatisere skraping av flere sider
Vil du hente flere sider – for eksempel paginerte produktlister? Bruk en enkel shell-løkke:
1for p in $(seq 2 5); do
2 curl -s -o "books-page-${p}.html" \
3 "https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
4 sleep 1
5doneDette henter side 2 til 5 i Books to Scrape-katalogen og lagrer hver side i en egen fil. (Side 1 er forsiden.)
Begrensninger ved web-scraping-with-curl: Dette må du vite
Selv om cURL er rått, er det ikke en «one size fits all». Her er hvor det typisk stopper opp:
- Ingen JavaScript-kjøring: cURL kan ikke håndtere sider som krever JavaScript for å rendre innhold eller løse anti-bot-utfordringer ().
- Parsing må gjøres manuelt: Du får rå HTML eller JSON, men må selv trekke ut feltene – ofte med ekstra skript eller verktøy.
- Begrenset økthåndtering: Komplekse innlogginger, tokens eller flertrinnsskjemaer blir fort rotete.
- Ingen innebygd strukturering: cURL gjør ikke nettsider om til rader, tabeller eller regneark.
- Sårbart for bot-detektering: Mange nettsteder bruker avansert bot-beskyttelse (JavaScript, fingerprinting, CAPTCHA) som cURL ikke kan omgå ().
En rask sammenligning:
| Begrensning | Kun cURL | Moderne scraping-verktøy (f.eks. Thunderbit) |
|---|---|---|
| JavaScript-støtte | Nei | Ja |
| Strukturering av data | Manuelt | Automatisk (AI/mal) |
| Økthåndtering | Manuelt | Automatisk |
| Omgå anti-bot | Begrenset | Avansert (nettleserbasert/AI) |
| Brukervennlighet | Teknisk | Ikke-teknisk |
For statiske sider og API-er er cURL glimrende. For mer dynamiske eller beskyttede sider bør du oppgradere verktøykassen.
Thunderbit vs. cURL: Beste tilnærming for ikke-tekniske brukere
La oss snakke om , vår AI-drevne web scraper Chrome Extension. Hvis du jobber med salg, markedsføring eller drift og bare vil få data fra en nettside inn i Excel, Google Sheets eller Notion – uten å røre kommandolinjen – er Thunderbit laget for deg.
Slik står Thunderbit mot cURL:
| Funksjon | cURL | Thunderbit |
|---|---|---|
| Brukergrensesnitt | Kommandolinje | Pek-og-klikk (Chrome Extension) |
| AI-forslag til felter | Nei | Ja (AI leser siden og foreslår kolonner) |
| Paginering/undersider | Manuell skripting | Automatisk (AI oppdager og skraper) |
| Eksport av data | Manuelt (parse + lagre) | Direkte til Excel, Google Sheets, Notion, Airtable |
| JavaScript/beskyttede sider | Nei | Ja (nettleserbasert skraping) |
| No-code | Nei (krever skripting) | Ja (alle kan bruke) |
| Gratisnivå | Alltid gratis | Gratis opptil 6 sider (10 med prøve-boost) |
Med Thunderbit åpner du utvidelsen, klikker «AI Suggest Fields», og lar AI-en finne ut hvilke data som skal hentes. Du kan skrape tabeller, lister, produktdetaljer – og til og med besøke undersider automatisk. Deretter eksporterer du rett til verktøyene du bruker i hverdagen – uten parsing og uten frustrasjon.
Thunderbit brukes av over , og er spesielt populært i salg, netthandel og eiendom der strukturert data trengs raskt.
Vil du teste? .
Kombiner cURL og Thunderbit: Fleksible strategier for webskraping
Er du teknisk bruker, trenger du ikke velge bare ett verktøy. Mange team bruker faktisk cURL og Thunderbit sammen for maksimal fleksibilitet:
- Prototyp med cURL: Test endepunkter raskt, inspiser headere og forstå hvordan et nettsted svarer.
- Skaler med Thunderbit: Når du trenger strukturert data, skraping av mange sider eller en repeterbar arbeidsflyt, bytt til Thunderbit for pek-og-klikk og direkte eksport.
Et eksempel på arbeidsflyt for markedsanalyse:
- Bruk cURL til å hente noen sider og se på HTML-strukturen.
- Finn feltene du vil ha (f.eks. produktnavn, priser, anmeldelser).
- Åpne Thunderbit, klikk «AI Suggest Fields», og la AI sette opp skraperen.
- Skrap alle sider (inkludert undersider eller paginerte lister) og eksporter til Google Sheets.
- Analyser, del og bruk dataene – uten manuell parsing.
En rask beslutningstabell:
| Scenario | Bruk cURL | Bruk Thunderbit | Bruk begge |
|---|---|---|---|
| Rask henting fra API eller statisk side | ✅ | ||
| Trenger strukturert data i regneark | ✅ | ||
| Feilsøking av headere/cookies | ✅ | ||
| Skrape dynamiske/JS-tunge sider | ✅ | ||
| Bygge repeterbar no-code arbeidsflyt | ✅ | ||
| Prototyping, deretter skalering | ✅ | ✅ | Hybrid arbeidsflyt |
Vanlige utfordringer og fallgruver ved webskraping med cURL
Før du går helt bananas med cURL, er det smart å vite hva som typisk skaper trøbbel i praksis:
- Anti-bot-systemer: Mange nettsteder bruker avansert beskyttelse (JavaScript-utfordringer, CAPTCHA, fingerprinting) som cURL ikke kommer forbi ().
- Datakvalitet: Endringer i HTML, manglende felter eller ujevne layouts kan knekke skriptene dine.
- Vedlikehold: Hver gang et nettsted endrer seg, må du oppdatere parsing-logikken.
- Juridisk og compliance-risiko: Sjekk alltid vilkår, robots.txt og relevante lover før du skraper. At data er offentlig betyr ikke automatisk at den kan brukes fritt (, ).
- Skaleringsgrenser: cURL er supert for små jobber, men ved stor skala må du håndtere proxyer, rate limits og robust feilhåndtering.
Tips for feilsøking og ansvarlig skraping:
- Start alltid med sider der du har tillatelse eller demosider (som ).
- Respekter rate limits – ikke overbelast endepunkter.
- Unngå å skrape persondata uten lovlig grunnlag.
- Treffer du JavaScript- eller CAPTCHA-vegger, vurder et nettleserbasert verktøy som Thunderbit.
Trinnvis oppsummering: Slik skraper du nettsider med cURL
Her er en sjekkliste du kan bruke som hurtigreferanse for web-scraping-with-curl:
- Finn mål-URL(ene): Start med en statisk side eller et API-endepunkt.
- Hent siden:
curl URL - Lagre output til fil:
curl -o file.html URL - Se headere/debug:
curl -I URL,curl -v URL - Send POST-data:
curl -d "a=1&b=2" URL - Håndter cookies/økter:
curl -c cookies.txt ...,curl -b cookies.txt ... - Sett headere/User-Agent:
curl -A "..." -H "..." URL - Følg redirects:
curl -L URL - Bruk proxy (ved behov):
curl -x proxy:port URL - Automatiser flere sider: Bruk shell-løkker eller skript.
- Parse og strukturer data: Bruk ekstra verktøy/skript ved behov.
- Bytt til Thunderbit for strukturert no-code skraping eller dynamiske sider.
Konklusjon og hovedpoeng: Velg riktig verktøy for webskraping
webskraping med curl er fortsatt en verdifull ferdighet for tekniske brukere i 2026 – spesielt for raske datauttak, prototyping og automatisering. cURLs hastighet, skriptbarhet og utbredelse gjør det til en klassiker i enhver utviklers verktøykasse. Men etter hvert som nettet blir mer dynamisk og bedre beskyttet, og forretningsbrukere forventer strukturert data uten kode, flytter verktøy som grensene for hva som er mulig.
Viktigste takeaways:
- Bruk cURL for statiske sider, API-er og rask prototyping – særlig når du vil ha full kontroll.
- Bytt til Thunderbit (eller lignende AI web scrapers) når du trenger strukturert data, må håndtere dynamiske/JavaScript-tunge sider, eller vil ha en no-code arbeidsflyt som passer for business.
- Kombiner begge for maksimal fleksibilitet: prototyp med cURL, skaler og strukturer med Thunderbit.
- Skrap alltid ansvarlig – respekter vilkår, rate limits og juridiske rammer.
Nysgjerrig på hvor enkelt webskraping kan være? og opplev AI-drevet datauthenting selv. Vil du dykke dypere, finner du flere guider, tips og innsikt i . Du liker kanskje også:
Lykke til med skrapingen – og måtte dataene dine alltid være rene, strukturerte og bare en kommando (eller et klikk) unna.
Vanlige spørsmål (FAQ)
1. Kan cURL håndtere nettsider som rendres med JavaScript?
Nei, cURL kan ikke kjøre JavaScript. Det henter rå HTML slik serveren leverer den. Hvis en side krever JavaScript for å vise innhold eller løse anti-bot-utfordringer, vil cURL ikke få tak i dataene. Da bør du bruke nettleserbaserte verktøy som .
2. Hvordan lagrer jeg cURL-output direkte til en fil?
Bruk -o: curl -o filename.html URL. Da skrives respons-body til en fil i stedet for å vises i terminalen.
3. Hva er forskjellen på cURL og Thunderbit for webskraping?
cURL er et kommandolinjeverktøy for å hente rå webdata – ideelt for tekniske brukere og automatisering. Thunderbit er en AI-drevet Chrome Extension for forretningsbrukere som vil hente strukturert data fra hvilken som helst nettside, håndtere dynamiske sider og eksportere direkte til verktøy som Excel eller Google Sheets – uten kode.
4. Er det lovlig å skrape nettsider med cURL?
Å skrape offentlig tilgjengelige data er ofte lovlig i USA etter nyere rettsavgjørelser, men du bør alltid sjekke nettstedets vilkår, robots.txt og relevante lover. Unngå å skrape persondata eller beskyttet innhold uten tillatelse, og respekter rate limits og etiske retningslinjer (, ).
5. Når bør jeg bytte fra cURL til et mer avansert verktøy som Thunderbit?
Hvis du må skrape dynamiske/JavaScript-tunge sider, vil ha strukturert data i et regneark, eller foretrekker en no-code arbeidsflyt, er Thunderbit et bedre valg. Bruk cURL til raske, tekniske oppgaver; bruk Thunderbit til forretningsvennlig og repeterbar datauthenting.
For flere tips og guider om webskraping, besøk eller sjekk .