

Hvis du noen gang har prøvd å bygge en målrettet salgsliste, kartlegge nye markeder eller sammenligne konkurrenter, vet du hvor mye gull Google Maps faktisk inneholder. Men her er det som gjør det ekstra interessant: med over 1,5 milliarder «near me»-søk hver måned og 76 % av lokale søkere som besøker en bedrift innen 24 timer (thinkwithgoogle.com), har behovet for oppdatert, stedbasert bedriftsdata aldri vært større.
Enten du jobber med salg, markedsføring eller drift, kan strukturert uthenting av data fra Google Maps være forskjellen mellom en kald oppringning og en varm lead med høy konvertering.
Jeg har jobbet i SaaS og automatisering i mange år, og jeg har sett på nært hold hvordan team bruker Python – og nå også AI-drevne verktøy som Thunderbit – til å gjøre Google Maps til en strategisk ressurs.
I denne guiden viser jeg nøyaktig hvordan du henter ut Google Maps-data med Python i 2026 – steg for steg, med kode, råd om etterlevelse og en sammenligning med no-code-løsninger. Enten du er Python-proff eller bare vil ha den raskeste veien til brukbare data, er du på rett sted.
Hva betyr det å hente ut Google Maps med Python?
La oss starte med det grunnleggende: å hente ut data fra Google Maps med Python betyr å trekke ut bedriftsinformasjon programmessig – som navn, adresser, vurderinger, anmeldelser, telefonnumre og koordinater – fra Google Maps, slik at du kan analysere, filtrere og eksportere det til forretningsbruk.

Det finnes to hovedmåter å gjøre dette på:
- Google Maps Places API: Den offisielle, lisensierte metoden. Du bruker en API-nøkkel til å sende spørringer til Googles servere og får tilbake strukturert JSON-data. Dette er stabilt, forutsigbart og (for det meste) i tråd med reglene, men det kommer med kvoter og kostnader.
- Webscraping av HTML: Du automatiserer en nettleser (med verktøy som Playwright eller Selenium) for å laste Google Maps, utføre søk og parse den gjengitte siden. Dette er mer fleksibelt, men også mer skjørt – Google endrer ofte nettsidestrukturen, og scraping av HTML kan bryte med Googles vilkår.
Typiske datafelt du kan hente ut:
- Bedriftsnavn
- Kategori/type
- Full adresse (pluss by, delstat/fylke, postnummer, land)
- Breddegrad og lengdegrad
- Telefonnummer
- Nettadresse
- Vurdering og antall anmeldelser
- Prisnivå
- Bedriftsstatus (åpen/stengt)
- Åpningstider
- Place ID (Googles unike identifikator)
- Google Maps-URL
Hvorfor er dette viktig? Fordi disse feltene driver alt fra leadgenerering og territorieplanlegging til konkurransesammenligning og markedsanalyse. Poenget er å hente ut riktig data til forretningsmålene dine – ikke bare scrape i blinde.
Hvorfor salgs- og markedsføringsteam henter data fra Google Maps med Python
La oss være konkrete. Hvorfor er så mange salg- og markedsføringsteam så opptatt av Google Maps-data i 2026?
- Leadgenerering: Bygg svært målrettede lister over lokale virksomheter, komplett med kontaktinfo og vurderinger, til utgående kampanjer.
- Territorieplanlegging: Kartlegg salgsområder, leveringssoner eller tjenesteområder basert på faktisk tetthet av bedrifter og typer.
- Konkurrentovervåking: Følg med på konkurrenters lokasjoner, vurderinger og anmeldelser over tid for å oppdage trender og muligheter.
- Markedsanalyse: Analyser bedriftskategorier, åpningstider og anmeldelsessentiment for å informere go-to-market-strategier.
- Stedsvalg: For eiendom og detaljhandel kan du vurdere potensielle lokasjoner ut fra fasiliteter i nærheten, fottrafikk og konkurranse.
Effekt i praksis: Ifølge HubSpot 2025 State of Sales planlegger 92 % av salgsorganisasjoner å øke investeringene i AI/data, og team som bruker målrettede, lokale data ser konverteringsrater opptil 8× høyere enn de som baserer seg på generiske kalde lister (martal.ca). En studie av leadgenerering for franchise viste 15 dollar i ny omsetning for hver dollar brukt på leadlister basert på Google Maps.
Koble forretningsmål til Google Maps-felt:
| Forretningsmål | Google Maps-felt du trenger |
|---|---|
| Lokal leadliste | navn, adresse, telefon, nettsted, kategori |
| Territorieplanlegging | navn, bredde-/lengdegrad, bedriftsstatus, åpningstider |
| Sammenligning av konkurrenter | navn, vurdering, antall brukervurderinger, prisnivå, anmeldelser |
| Stedsvalg | kategori, bredde-/lengdegrad, anmeldelsestetthet, åpningsdato |
| Sentiment-/menyinnsikt | anmeldelser, redaksjonssammendrag, bilder, typer |
| E-post-/telefonutsendelser | nasjonalt telefonnummer, nettsted-URI (deretter berik etter behov) |
Slik setter du opp en Python Google Maps-scraper: verktøy og krav
Før du begynner å scrape, må du sette opp Python-miljøet ditt og samle riktig verktøy. Dette trenger du i 2026:
1. Installer Python og nødvendige biblioteker
Anbefalt Python-versjon: 3.10 eller nyere.
Installer nøkkelbibliotekene:
pip install \
requests==2.33.1 httpx==0.28.1 \
beautifulsoup4==4.14.3 lxml==6.0.3 \
pandas==2.3.3 \
selenium==4.43.0 playwright==1.58.0 \
googlemaps==4.10.0 google-maps-places==0.8.0 \
schedule==1.2.2 APScheduler==3.11.2 \
python-dotenv==1.2.2 tenacity==9.1.4
playwright install chromium
Hva dette gjør:
requests,httpx: HTTP-forespørsler (API-kall)beautifulsoup4,lxml: HTML-parsing (for webscraping)pandas: Datavask, analyse og eksportselenium,playwright: Nettleserautomatisering (for HTML-scraping)googlemaps,google-maps-places: Google Maps API-klienterschedule,APScheduler: Planlegging av oppgaverpython-dotenv: Last API-nøkler sikkert fra.env-filertenacity: Retry-logikk for feilbehandling
2. Skaff en Google Maps API-nøkkel (for API-basert scraping)
- Gå til Google Cloud Console.
- Opprett eller velg et prosjekt.
- Aktiver fakturering (påkrevd, også for bruk i gratisnivået).
- Aktiver «Places API (New)» under APIs & Services > Library.
- Gå til Credentials > Create Credentials > API Key.
- Begrens nøkkelen til bestemte API-er og IP-adresser av sikkerhetshensyn.
- Lagre API-nøkkelen i en
.env-fil (aldri sjekk den inn i kode):
GOOGLE_MAPS_API_KEY=your_actual_api_key_here
Merk: Per mars 2025 tilbyr ikke Google lenger en universell gratis kreditt på 200 dollar per måned. I stedet får du gratis månedsterskler per API-nivå (se offisielle priser).
Slik henter du ut data fra Google Maps med Python: steg-for-steg-guide
La oss bryte ned de to hovedtilnærmingene – API-basert og HTML-scraping – slik at du kan velge det som passer behovene dine.
Tilnærming 1: Bruke Google Maps Places API (anbefalt)
Steg 1: Installer og importer nødvendige biblioteker
import os
import httpx
import pandas as pd
from dotenv import load_dotenv
Steg 2: Last API-nøkkelen sikkert
load_dotenv()
API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]
Steg 3: Bygg søkespørringen din
Du bruker Text Search-endepunktet for å finne virksomheter som matcher kriteriene dine.
URL = "https://places.googleapis.com/v1/places:searchText"
FIELD_MASK = ",".join([
"places.id", "places.displayName", "places.formattedAddress",
"places.location", "places.rating", "places.userRatingCount",
"places.priceLevel", "places.types",
"places.nationalPhoneNumber", "places.websiteUri",
"nextPageToken",
])
Steg 4: Send API-forespørselen
def text_search(query, lat, lng, radius=3000, min_rating=4.0):
body = {
"textQuery": query,
"minRating": min_rating, # server-side filter
"includedType": "restaurant",
"openNow": False,
"pageSize": 20,
"locationBias": {
"circle": {
"center": {"latitude": lat, "longitude": lng},
"radius": radius,
}
},
}
headers = {
"Content-Type": "application/json",
"X-Goog-Api-Key": API_KEY,
"X-Goog-FieldMask": FIELD_MASK, # Always set this!
}
r = httpx.post(URL, json=body, headers=headers, timeout=30)
r.raise_for_status()
return r.json()
Steg 5: Håndter paginering og samle resultater
def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
results = []
next_page_token = None
while True:
data = text_search(query, lat, lng, radius, min_rating)
places = data.get('places', [])
results.extend(places)
next_page_token = data.get('nextPageToken')
if not next_page_token:
break
return results
Steg 6: Eksporter data med Pandas
df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
df.to_csv("brooklyn_coffee_shops.csv", index=False)
Profftips:
- Sett alltid
X-Goog-FieldMask-headeren for å kontrollere kostnader. Hvis du ber om anmeldelser eller bilder, kan prisen per 1 000 forespørsler hoppe fra 5 til 25 dollar (prisdetaljer). - Bruk server-side-filtre (som
minRating,includedType,locationBias) for å unngå å bruke kreditter på irrelevante resultater. - Cache
place_id-verdier for deduplisering og fremtidige oppdateringer.
Tilnærming 2: Webscraping av Google Maps HTML (for læring eller enkelbruk)
Advarsel: Google Maps er en enkelt-sides applikasjon. Du må bruke nettleserautomatisering (Playwright eller Selenium), og scraping av HTML kan bryte med Googles vilkår. Bruk dette til research, ikke i produksjon.
Steg 1: Installer Playwright og start en nettleser
from playwright.sync_api import sync_playwright
import time, re
def scrape_maps(query, max_results=100):
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
ctx = browser.new_context(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
locale="en-US",
)
page = ctx.new_page()
page.goto("https://www.google.com/maps", timeout=60_000)
page.fill("#searchboxinput", query)
page.click('button[aria-label="Search"]')
page.wait_for_selector('div[role="feed"]')
feed = page.locator('div[role="feed"]')
prev = 0
while True:
feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
time.sleep(2)
count = page.locator('div[role="feed"] > div > div[jsaction]').count()
if count == prev or count >= max_results:
break
prev = count
if page.locator("text=You've reached the end of the list").count():
break
rows = []
cards = page.locator('div[role="feed"] > div > div[jsaction]')
for i in range(cards.count()):
c = cards.nth(i)
name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
rating_el = c.locator('span[role="img"]').first
raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
rating = float(m.group(1)) if m else None
reviews = int(m.group(2).replace(",", "")) if m else None
rows.append({"name": name, "rating": rating, "reviews": reviews})
browser.close()
return rows
Tips:
- Google randomiserer CSS-klasser med noen ukers mellomrom, så denne koden kan trenge jevnlige oppdateringer.
- Bruk menneskelignende forsinkelser og unngå å scrape for raskt for å redusere risikoen for å bli blokkert.
- Forsøk aldri å omgå CAPTCHA-er eller Googles SearchGuard-system – det kan utsette deg for juridisk risiko.
Unngå blind scraping: slik målretter du nøyaktig dataen du trenger
Å scrape alt er en oppskrift på bortkastet tid og oppblåste datasett. Slik målretter du bare dataen som betyr noe:
- Generer målrettede URL-lister: Bruk Googles egne søkefiltre i Maps (kategori, sted, vurdering, åpen nå) for å snevre inn resultatene før scraping.
- Bruk frasematching: Søk etter eksakte bedriftstyper eller nøkkelord (for eksempel «vegan bakery in Austin»).
- Stedfiltre: Angi by, nabolag eller til og med koordinater og radius for presis treffsikkerhet.
- Server-side-filtrering (API): Bruk
minRating,includedTypeoglocationBiasi forespørselsbrødteksten. - Klientsidefiltrering (Python): Etter scraping kan du bruke pandas til å filtrere virksomheter med vurdering over 4.0, mer enn 50 anmeldelser eller bestemte kategorier.
Eksempel: Filtrer bare restauranter på Manhattan med vurdering over 4.0
df = pd.DataFrame(results)
filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
filtered.to_csv("manhattan_top_restaurants.csv", index=False)
Bruk Python-biblioteker til å organisere og eksportere Google Maps-data
Når du har hentet ut dataene, er det på tide å rydde dem, analysere dem og eksportere dem til teamet ditt.
Rydd og strukturer data med Pandas
import pandas as pd
df = pd.read_json("brooklyn_restaurants.json")
df = (
df.dropna(subset=["name", "address"])
.drop_duplicates(subset=["place_id"])
.assign(
name=lambda d: d["name"].str.strip(),
phone=lambda d: d["phone"].astype(str)
.str.replace(r"\D", "", regex=True)
.str.replace(r"^1?(\d{10})$", r"+1\1", regex=True),
rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
user_ratings_total=lambda d: pd.to_numeric(
d["user_ratings_total"], errors="coerce"
).fillna(0).astype("int32"),
)
)
Analyser og oppsummer data
Eksempel: Gjennomsnittsvurdering etter nabolag
by_neighborhood = (
df.groupby("neighborhood", as_index=False)
.agg(avg_rating=("rating", "mean"),
n_places=("place_id", "nunique"),
median_reviews=("user_ratings_total", "median"))
.sort_values("avg_rating", ascending=False)
)
Eksporter til Excel eller CSV
df.to_csv("brooklyn_top.csv", index=False)
df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Topprangert")
Store datasett? Bruk Parquet-format for bedre hastighet og plassutnyttelse:
df.to_parquet("brooklyn_top.parquet", compression="zstd")
Thunderbit: AI-drevet alternativ til Python Google Maps-scraper
Hvis du tenker: «Dette er mye oppsett for en enkel leadliste», er du ikke alene. Det er nettopp derfor vi bygde Thunderbit – en AI-drevet, no-code webscraper som gjør det like enkelt som et par klikk å hente ut Google Maps-data (og mye mer).
Hvorfor Thunderbit?
- Ingen koding eller API-nøkler kreves: Bare åpne Thunderbit Chrome-utvidelsen, gå til Google Maps og klikk «AI Suggest Fields».
- AI-basert feltdeteksjon: Thunderbits AI leser siden og foreslår riktige kolonner – navn, adresse, vurdering, telefon, nettsted og mer.
- Scraping av undersider: Vil du berike tabellen din med data fra hvert bedriftsnettsted? Thunderbit kan besøke hver underside og hente inn ekstra informasjon automatisk.
- Eksporter til Excel, Google Sheets, Airtable eller Notion: Slutt på pandas-knoting – bare klikk «Export», så er dataene klare for teamet ditt.
- Planlagt scraping: Sett opp gjentakende jobber for å overvåke konkurrenter eller oppdatere leadlisten automatisk.
- Null vedlikehold: Thunderbits AI tilpasser seg endringer på nettsiden, så du slipper å fikse ødelagte skript hele tiden.
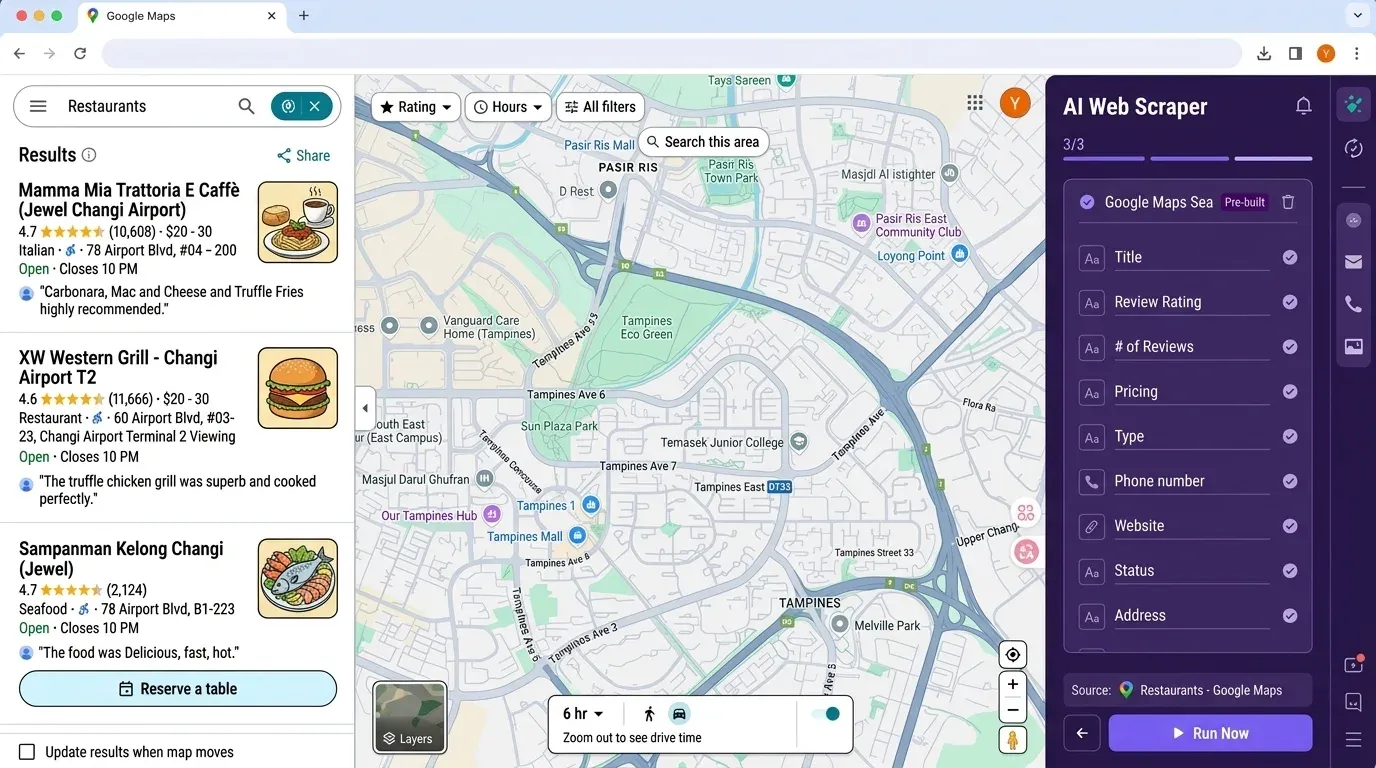
Thunderbit vs. Python-arbeidsflyt:
| Steg | Python-scraper | Thunderbit |
|---|---|---|
| Installer verktøy | 30–60 min (Python, pip, biblioteker) | 2 min (Chrome-utvidelse) |
| Oppsett av API-nøkkel | 10–30 min (Cloud Console) | Ikke nødvendig |
| Valg av felt | Manuell kode, field masks | AI Suggest Fields (1 klikk) |
| Datauttrekk | Skriv/kjør skript, håndter feil | Klikk «Scrape» |
| Eksport | pandas til CSV/Excel | Eksporter til Excel/Sheets/Notion |
| Vedlikehold | Manuelle oppdateringer ved nettsideendringer | AI tilpasser seg automatisk |
Bonus: Thunderbit er betrodd av over 30 000 brukere verden over, og gratisnivået lar deg scrape opptil 6 sider (eller 10 med en prøveboost) uten kostnad.
Hold deg på riktig side av reglene: Googles vilkår og scraping-etikk
Her er det mange Python-guider er farlig utdaterte. Dette må du vite i 2026:
- Google Maps Platform ToS §3.2.3 forbyr strengt scraping, caching eller eksport av data utenfor de offisielle API-ene (cloud.google.com). Det eneste unntaket: bredde-/lengdegrader kan caches i opptil 30 dager; Place ID-er kan lagres uten tidsbegrensning.
- API-brukere er bundet av kontrakt: Hvis du bruker en API-nøkkel, har du godtatt Googles vilkår – selv om du bare henter offentlige data.
- Å omgå tekniske barrierer (CAPTCHA-er, SearchGuard) kan nå være et mulig brudd på DMCA §1201, som kan medføre strafferettslige konsekvenser (ppc.land).
- GDPR og personvernlover: Hvis du samler inn personopplysninger (e-post, telefoner, navn på anmeldere) fra Google Maps, må du ha et lovlig grunnlag og respektere krav om sletting. Det franske CNIL bøtela KASPR med 200 000 euro i 2024 for scraping av LinkedIn-kontakter (edpb.europa.eu).
- Beste praksis:
- Bruk som standard Places API der det er mulig.
- Hastighetsbegrens forespørsler (≤10 QPS for API, 1–2 forespørsler per sekund for HTML-scraping).
- Aldri omgå CAPTCHA-er eller tekniske sperrer.
- Ikke videredistribuer persondata du har hentet ut.
- Respekter forespørsler om reservasjon og sletting.
- Vurder alltid lokale lover – GDPR, CCPA og andre håndheves aktivt.
Kort fortalt: Hvis etterlevelse er en bekymring, hold deg til API-et og minimer mengden data du samler inn. For de fleste bedriftsbrukere reduserer et no-code-verktøy som Thunderbit risikobildet (ingen API-nøkkel, ingen videredistribusjon).
Planlegg og automatiser Google Maps-scrapingen din med Python
Hvis du trenger å holde dataene ferske – for eksempel for ukentlig konkurrentovervåking eller månedlige oppdateringer av leadlister – er automatisering din venn.
Enkel planlegging med schedule
import schedule, time
from my_scraper import run_job
schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
while True:
schedule.run_pending()
time.sleep(30)
Produksjonsklar planlegging med APScheduler
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.triggers.cron import CronTrigger
sched = BackgroundScheduler(timezone="America/New_York")
sched.add_job(
run_job,
CronTrigger(hour=3, minute=15, jitter=600), # 03:15 ± 10 min
kwargs={"query": "restaurants in Brooklyn"},
id="brooklyn_daily",
max_instances=1,
coalesce=True,
misfire_grace_time=3600,
)
sched.start()
Tips for trygg automatisering
- Legg inn tilfeldig jitter i planleggingen for å unngå forutsigbare mønstre.
- For HTML-scraping bør du aldri kjøre mer enn 1–2 forespørsler per sekund.
- Ved API-bruk må du overvåke kvoten og sette opp varsler for fakturering.
- Logg alltid feil og ha en «dead-letter»-fil for mislykkede forespørsler.
Thunderbit-bonus: Med Thunderbit kan du planlegge gjentatte scraping-jobber direkte i UI-en – ingen kode, ingen cron-jobber, ingen serveroppsett.
Viktige poenger: effektiv, målrettet og compliant datainnhenting fra Google Maps
La oss oppsummere det viktigste:
- Google Maps er den viktigste kilden til bedriftslokasjonsdata, og driver alt fra leadgenerering til markedsanalyse.
- Python-scraping gir fleksibilitet og kontroll, men kommer med oppsett, vedlikehold og krav til etterlevelse – særlig når Googles anti-bot-tiltak og håndheving skjerpes.
- API-basert uthenting er den tryggeste og mest skalerbare veien for de fleste team. Bruk alltid field masks og server-side-filtre for å kontrollere kostnader.
- HTML-scraping er skjørt og risikabelt – bruk det bare til engangsresearch, og aldri for å omgå tekniske barrierer.
- Målrett dataen din: Bruk frasematching, stedfiltre og pandas-arbeidsflyter for å hente ut bare det du trenger.
- Thunderbit er den raskeste veien for ikke-utviklere: AI-drevet, ingen oppsett, umiddelbar eksport og innebygd planlegging.
- Etterlevelse er viktig: Respekter Googles vilkår, personvernlover og hastighetsgrenser for å unngå juridisk trøbbel.
For flere guider og tips, sjekk ut Thunderbit-bloggen og vår YouTube-kanal.
Ofte stilte spørsmål
1. Er det lovlig å hente ut Google Maps-data med Python i 2026?
Å hente ut Google Maps-data via det offisielle API-et er tillatt innenfor Googles vilkår, så lenge du respekterer kvoter og ikke videredistribuerer begrensede data. HTML-scraping av Google Maps er uttrykkelig forbudt av Googles ToS og innebærer juridisk risiko, særlig hvis du omgår tekniske barrierer eller samler inn persondata uten samtykke. Sjekk alltid lokale lover (GDPR, CCPA osv.) og følg beste praksis for etterlevelse.
2. Hva er forskjellen mellom å bruke Google Maps API og å webscrape HTML-en?
API-et er stabilt, lisensiert og laget for datauttrekk, men krever en API-nøkkel og er underlagt kvoter og kostnader. HTML-scraping bruker nettleserautomatisering for å hente data fra den gjengitte siden, men er skjørt (siden endrer seg ofte), kan bryte med vilkårene og er juridisk mer risikabelt. For de fleste forretningsbruk er API-et den anbefalte veien.
3. Hvor mye koster det å hente ut data fra Google Maps med Python i 2026?
Google Places API-prising er per 1 000 forespørsler, fra 5 dollar (Essentials) til 25 dollar (Enterprise+Atmosphere), avhengig av hvilke felt du ber om. Det finnes gratis månedsterskler (10 000 for Essentials, 5 000 for Pro, 1 000 for Enterprise), men scraping i stor skala kan fort bli kostbart. Bruk alltid field masks og server-side-filtre for å kontrollere kostnadene.
4. Hvordan er Thunderbit sammenlignet med Python-baserte Google Maps-scrapere?
Thunderbit er en no-code, AI-drevet webscraper som lar deg hente ut Google Maps-data (og mye mer) uten programmering, API-nøkler eller vedlikehold. Det er ideelt for salg- og markedsføringsteam som vil ha raske, pålitelige eksportmuligheter til Excel, Google Sheets, Airtable eller Notion. For tekniske brukere som trenger egendefinert logikk, gir Python mer fleksibilitet, men krever mer oppsett og håndtering av etterlevelse.
5. Hvordan kan jeg automatisere gjentatt uthenting av Google Maps-data?
Med Python kan du bruke planleggingsbiblioteker som schedule eller APScheduler til å kjøre scrapers med faste intervaller (daglig, ukentlig osv.). Legg til tilfeldig jitter for å unngå oppdagelse og overvåk API-kvoten din. Med Thunderbit kan du planlegge gjentatte scraping-jobber direkte i UI-en – ingen kode eller serveroppsett er nødvendig.
Klar til å gjøre Google Maps til din superkraft for salg og markedsføring? Enten du er Python-entusiast eller vil ha den raskeste no-code-løsningen, finnes verktøyene her i 2026. Prøv Thunderbit for umiddelbar, AI-drevet scraping – eller brett opp ermene og gå løs på API-et. Uansett håper vi at leadlistene dine er ferske, eksportene rene og kampanjene fulle av lokale prospekter med høy konvertering. Lykke til med scraping!
Les mer




