
La meg si det sånn: Hvis jeg fikk en dollar hver gang noen sendte meg en PDF full av «viktige data» og forventet at jeg på magisk vis skulle gjøre den om til et regneark, hadde jeg sannsynligvis hatt nok til å kjøpe en livslang forsyning med kaffe (og kanskje noen ekstra Chrome-utvidelser). PDF-er er overalt — salgskontrakter, produktkataloger, forskningsartikler, fakturaer, alt mulig. Men når det faktisk kommer til å bruke dataene inni disse filene? Vel, det er der moroa (les: hodepinen) begynner.
Jeg har vært der selv — kopiert, limt inn, omformatert og noen ganger bare gitt opp når formateringen går helt i vranglås, eller bilder og lenker forsvinner som dugg for solen. Men her er den gode nyheten: verdenen av PDF-uttrekk har endret seg dramatisk, særlig med fremveksten av AI-drevne verktøy. Hvis du er lei av å bruke timer på å taste inn tall på nytt eller miste vettet over ødelagte tabeller, er du på rett sted. La oss dykke ned i PDF-uttrekk, hvorfor det betyr noe, og hvordan verktøy som Thunderbit gjør det (endelig) smertefritt.
Hva er PDF-uttrekk? Grunnleggende om datauttrekk fra PDF
La oss starte enkelt: PDF-uttrekk betyr bare en fancy måte å si «få strukturert data ut av PDF-filer — automatisk». En PDF-uttrekker er et verktøy (programvare, utvidelse eller tjeneste) som henter ut det du bryr deg om — tekst, tabeller, bilder, lenker, alt mulig — og legger det inn i et format du faktisk kan bruke, som Excel, Google Sheets eller en database.
Men her er haken: PDF-er er ikke som nettsider eller Excel-filer. De ligner mer på digitale utskrifter, laget for å se like ut overalt, ikke for å plukkes lett fra hverandre av en datamaskin. Noen PDF-er har valgbare tekstfelt, andre er bare skannede bilder (som krever OCR — optisk tegngjenkjenning), og formateringen kan være helt kaotisk. Så å trekke ut data fra en PDF handler ikke bare om å kopiere tekst — det handler om å dekode et puslespill av layout, fonter og noen ganger til og med skjulte metadata.
Hva kan du hente ut fra en PDF?
- Ren tekst (avsnitt, overskrifter osv.)
- Tabeller (tenk: regnskap, produktspesifikasjoner, spørreundersøkelser)
- Bilder og grafikk (diagrammer, logoer, skannede signaturer)
- Hyperlenker og referanser (innebygde URL-er, sitater)
- Skjemadata (felter fra utfyllbare skjemaer)
- Metadata (forfatter, tittel, opprettelsesdato, tagger)
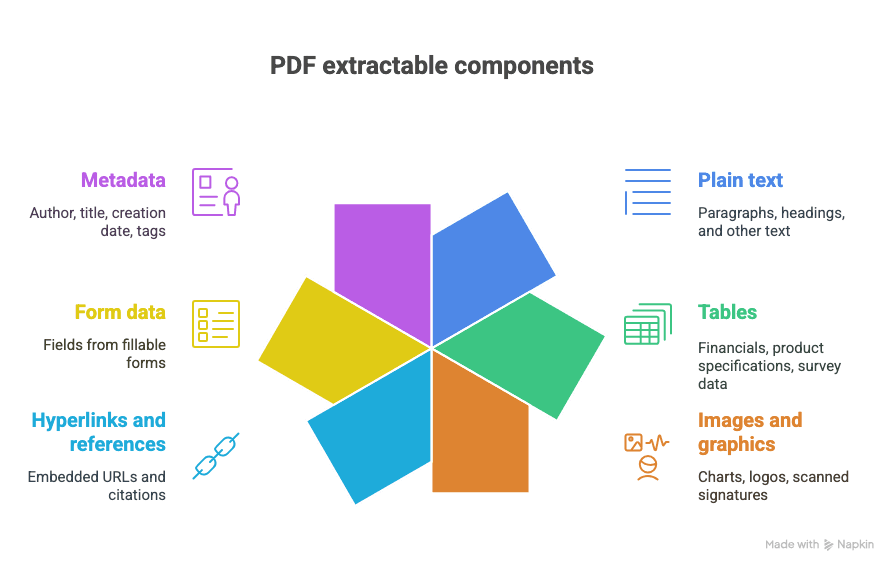
Og ja, noen ganger er alt dette blandet sammen i ett eneste herlig, kaotisk dokument.
Hvorfor PDF-uttrekk er viktig: Bruksområder i praksis og forretningsfordeler
Så hvorfor bry seg med å trekke ut data fra PDF-er? Fordi alle bruker dem, og dataene inni er ofte kritiske for virksomheten. Det er her PDF-uttrekk virkelig skinner:
| Bruksområde | Manuelt arbeid | Med PDF-uttrekker | Tids- og feilbesparelse |
|---|---|---|---|
| Uttrekk av salgsemner | Timer med å kopiere kontakter fra tilbud eller arrangements-PDF-er, risiko for å miste leads | Henter alle leads direkte inn i et regneark | 80–90 % raskere, færre feil |
| Produktdata for e-handel | Dager med å legge inn produktspesifikasjoner fra leverandør-PDF-er, formateringsmareritt | Masseuttrekk til CSV eller Sheets | 95 %+ spart tid, konsistente data |
| Analyse av forskningsdata | Uker med å transkribere tabeller fra akademiske artikler, høy risiko for tastefeil | Henter tabeller, referanser og til og med skannet tekst | 80 % spart tid, høyere nøyaktighet |
La oss sette noen tall på det:
- 2,5 billioner PDF-er opprettes hvert år.
- 90 % av organisasjoner bruker PDF som primært format for deling av informasjon.
- Manuell digital administrasjon (som dataregistrering fra PDF) sluker 40 % av arbeidstiden.
- Automatiserte verktøy kan redusere feilraten fra 5–10 % ned til 1 %.
Hvis du jobber med salg, e-handel eller forskning, er automatisering av datauttrekk fra PDF ikke bare «kjekt å ha» — det er et konkurransefortrinn.
Tradisjonelle metoder for PDF-uttrekk: utfordringer og begrensninger
La oss være ærlige: de gamle måtene å få data ut av PDF-er på er … ikke så bra. Her er det de fleste av oss har prøvd (og hvorfor det er så frustrerende):

1. Manuell kopier og lim inn
- Smertepunkter: Formateringen blir ødelagt, tabeller blir til kaos, bilder og lenker forsvinner, og du sitter igjen med migrene.
- Arbeidskostnad: Høy. Har du 5000 PDF-er, så er det 80+ timer av livet du aldri får igjen, selv om det bare tar 1 minutt per fil.
- Feilrate: 5–10 %. Skrivefeil, hoppede rader, utilsiktede slettinger — vært der, gjort det.
2. Konverter til Word/Excel, og rydd opp etterpå
- Smertepunkter: Fungerer noen ganger for enkle dokumenter, men komplekse layouter eller tabeller blir ofte totalt omstokket. Du må fortsatt rydde opp i rotet.
- Bilder/lenker: Som regel tapt i overføringen.
- Målrettet uttrekk: Glem det — du får hele dokumentet, ikke bare det du trenger.
3. Egendefinerte skript (Python osv.)
- Smertepunkter: Du må kunne kode (eller ha en på hurtigvalg). Hvert nytt PDF-format betyr at skriptet må justeres. Skannede PDF-er? Lykke til.
- Vedlikehold: Høyt. Hver gang en leverandør endrer fakturamal, ryker skriptet ditt.
- Skalerbarhet: Ikke for den lettskremte (eller den ikke-tekniske).
4. Nettbaserte konverterere
- Smertepunkter: Enkelt for engangsjobber, men du må laste opp sensitive dokumenter til en tredjepartsserver (hei, compliance-problemer). Begrenset kontroll over hva som faktisk blir hentet ut.
- Formatering: Uforutsigbart. Du kan ende opp med å bruke mer tid på opprydding enn du sparer.
Kort fortalt: Tradisjonelle metoder er trege, feilutsatte og skalerer dårlig. Derfor «lever» så mange team bare med det — men til en enorm produktivitetskostnad.
Moderne løsninger for PDF-uttrekk: fra kode til no-code-verktøy
Heldigvis sitter vi ikke fast i steinalderen lenger. Landskapet har eksplodert med smartere, raskere og mer brukervennlige alternativer for PDF-uttrekk.
1. Kodebiblioteker (for utviklere)
- Eksempler: PyPDF2, PDFMiner, Tabula-py.
- Styrker: Superfleksibelt, kan automatiseres for store batcher, gratis (åpen kildekode).
- Svakheter: Høy oppsettstid, krever programmeringsferdigheter, skjør løsning (kan ryke ved nye formater), begrenset OCR-/bilde-støtte.
2. Nettbaserte PDF-konverterere
- Eksempler: Smallpdf, PDF2Go, Zamzar.
- Styrker: Ingen oppsett, enkelt for ikke-tekniske brukere, raskt for små jobber.
- Svakheter: Begrenset tilpasning, personvernproblemer, formateringsfeil, begrensninger på filstørrelse/antall sider.
3. AI-drevne PDF-uttrekkere
- Eksempler: Thunderbit, Nanonets, Docparser.
- Styrker: Ingen koding nødvendig, håndterer tekst/tabeller/bilder/lenker, AI foreslår hva som bør hentes ut, støtter batchjobber, integreres med Sheets/Notion/Airtable.
- Svakheter: Noen har grenser for kreditter/sider, kan kreve internettforbindelse, litt læringskurve for komplekse dokumenter.
Sammenligning av verktøy for PDF-uttrekk: hvilken tilnærming passer for deg?
| Verktøy/metode | Oppsett | Best for | Henter ut | Kan tilpasses? | Pris |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Middels (UI/koding) | Tabeller i PDF-er | Tabeller | Delvis | Gratis |
| PDFMiner | Krever koding | Teksttunge PDF-er | Tekst | Ja (kode) | Gratis |
| PyPDF2 | Krever koding | Enkel tekst/metadata | Tekst, metadata | Ja (kode) | Gratis |
| Smallpdf/nettkonv. | Ingen (nettbasert) | Raske konverteringer | Hele dokumentet (Word/Excel) | Nei | Freemium |
| Thunderbit | 2-klikk installasjon | Forretningsbrukere, team | Tekst, tabeller, bilder, lenker | Ja (AI-ledetekster) | Freemium (16,5 USD/mnd for Pro) |
Møt Thunderbit: AI PDF-uttrekkeren som Chrome-utvidelse
Hvordan hente ut data fra PDF med AI Get Started Free
Nå skal vi snakke om verktøyet som har gjort livet mitt (og livet til mange forretningsbrukere) så mye enklere: Thunderbit.
Hva gjør Thunderbit annerledes?
- 2-klikk-uttrekk: Åpne en PDF i Chrome, klikk på Thunderbit-utvidelsen, og la AI gjøre resten.
- AI-drevne forslag til felt: Thunderbits «AI Suggest Fields» leser PDF-en din og anbefaler kolonnene du sannsynligvis vil ha (som «Navn», «E-post», «Pris» osv.).
- Håndterer bilder, lenker og tabeller: Ikke bare ren tekst — Thunderbit kan hente ut bilder, hyperlenker og til og med kjøre OCR på skannede dokumenter.
- Egendefinerte ledetekster: Trenger du bare telefonnumre eller produktspesifikasjoner? Legg inn en tilpasset instruksjon, så fokuserer Thunderbit bare på det.
- Eksporter overalt: Send dataene dine rett til Excel, Google Sheets, Airtable eller Notion. Slutt på CSV-krøll.
- Batch- og underside-uttrekk: Har du en liste med PDF-er eller lenker? Thunderbit kan behandle dem alle i én operasjon.
- Pålitelighet i bedriftsklasse: Bygget for nøyaktighet, personvern og reelle arbeidsflyter.
Kort sagt er det som å ha en digital praktikant som faktisk liker å registrere data (og aldri blir sliten).
Slik henter du data fra en PDF med Thunderbit: steg-for-steg-guide
Last ned Thunderbit Chrome-utvidelsen Get Started Free
Klar for å se hvor enkelt det kan være? Slik bruker jeg Thunderbit til å gjøre PDF-er om til strukturert, brukbar data:
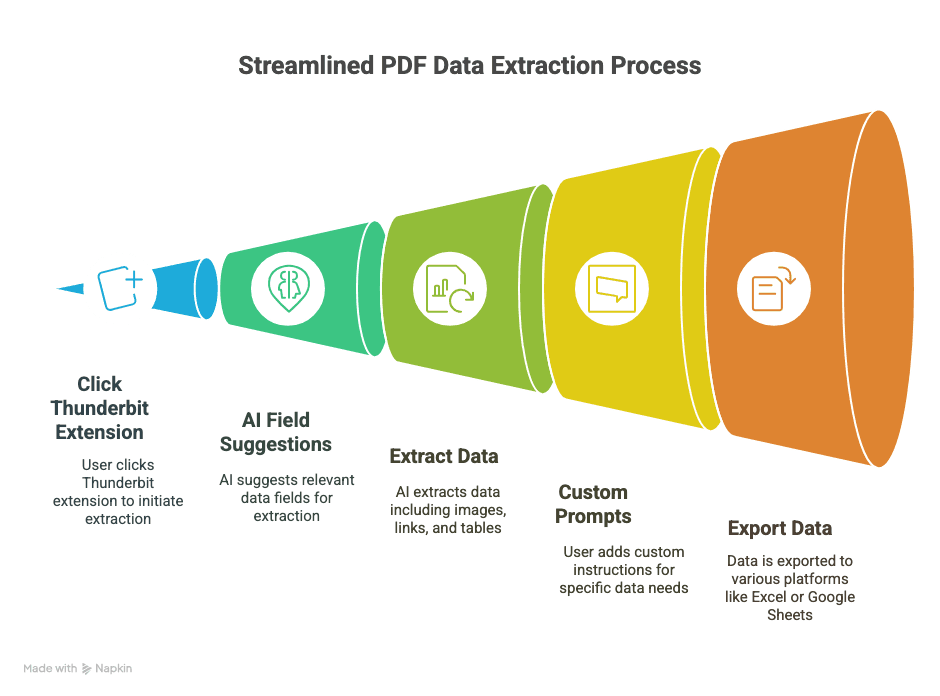
1. Installer Thunderbit
- Hent Thunderbit Chrome-utvidelsen.
- Registrer deg (Google-konto eller e-post — tar sekunder).
2. Åpne PDF-en din i Chrome
- Enten åpner du en PDF fra en nettlenke, eller så drar du en lokal PDF inn i en Chrome-fane.
3. Start Thunderbit på PDF-en
- Klikk på Thunderbit-ikonet i verktøylinjen i nettleseren.
- Velg «AI Web Scraper» — Thunderbit oppdager PDF-en og gjør seg klar til å jobbe.
4. La AI foreslå felt
- Klikk «AI Suggest Columns».
- Thunderbits AI skanner PDF-en og anbefaler kolonner (som «Dato», «Beløp», «Kontaktnavn» osv.).
- Forhåndsvis de uttrukne dataene i en tabell direkte i utvidelsen.
5. Tilpass om nødvendig
- Gi kolonnene nye navn, slett ekstra felt eller legg til dine egne (for eksempel «Garantitid» eller «Produkt-URL»).
- For vriene data kan du markere tekst i PDF-en for å lære opp AI-en på det du vil ha.
6. Velg eksportformat
- Velg mellom CSV, Google Sheets, Airtable eller Notion.
- Gi Thunderbit tilgang til å koble til (engangsoppsett).
7. Trekk ut og eksporter
- Trykk «Scrape» eller «Export».
- Thunderbit behandler PDF-en og sender dataene dit du vil ha dem — som regel i løpet av sekunder.
Prøv Thunderbit PDF-uttrekker nå
Det var det. Ingen koding, ingen kopier-og-lim inn, ingen drama.
Tips for nøyaktig datauttrekk fra PDF med Thunderbit
- Se gjennom AI-forslåtte felt: AI-en er smart, men et raskt blikk sikrer at du får akkurat det du trenger.
- Håndter komplekse tabeller: For tabeller med flere sider eller merkelige formater, bruk forhåndsvisningen til å oppdage problemer og justere kolonner ved behov.
- Trekk ut bilder/lenker: Sørg for å inkludere disse feltene hvis PDF-en har dem — Thunderbit kan hente dem også.
- Skannede PDF-er: Thunderbits innebygde OCR er solid, men jo renere skanningen er, desto bedre blir resultatet.
- Egendefinerte ledetekster: Vil du bare ha e-postadresser eller telefonnumre? Legg inn en ledetekst som «Hent ut alle e-postadresser», så fokuserer Thunderbit på dem.
Avansert PDF-uttrekk: hente ut bilder, lenker og egendefinerte data
Thunderbit handler ikke bare om ren tekst. Slik kan du få enda mer ut av PDF-ene dine:
- Bilder: Hent ut logoer, diagrammer eller annen innebygd grafikk. Thunderbit kan til og med kjøre OCR på tekst inni bilder.
- Hyperlenker: Trekk ut alle URL-er eller referanser — flott for forskningsartikler eller CV-er.
- Egendefinerte datatyper: Bruk AI-ledetekster til å hente ut akkurat det du trenger (for eksempel: «Finn alle produkt-SKU-er og prisene deres»).
- Sammendrag og kategorisering: Legg til en kolonne og be Thunderbit oppsummere et avsnitt eller kategorisere data i sanntid.
Tolkning av data fra PDF for spesifikke forretningsbehov
- Salg: Trekk bare ut kontaktinformasjon fra en bunke tilbud.
- E-handel: Hent produktspesifikasjoner, priser og bilder fra leverandørkataloger.
- Forskning: Få tak i tabeller, referanser og til og med generere sammendrag fra akademiske artikler.
Og når du først har dataene, kan du strukturere dem for enkel analyse i Excel, Google Sheets eller Notion — Thunderbit gjør grovarbeidet, du får bare bruke resultatene.
Eksport og bruk av PDF-dataene dine: fra uttrekk til handling
Å få dataene ut er bare begynnelsen. Slik får du dem til å jobbe for deg:
- Eksportalternativer: CSV, Excel, Google Sheets, Airtable, Notion — velg det du liker best.
- Formateringstips: Bruk Thunderbits innstillinger for kolonnetyper (tall, dato, tekst) for rene data som er klare for analyse.
- Arbeidsflytintegrasjon: Koble de eksporterte dataene til CRM-er, lagerstyringssystemer eller analysedashbord.
- Samarbeid: Del Google Sheets eller Airtable-baser med teamet ditt — alle jobber ut fra de samme, oppdaterte dataene.
Det beste? Slutt på å sende regneark frem og tilbake på e-post eller lure på om du har hoppet over en rad.
Vanlige fallgruver ved PDF-uttrekk og hvordan du unngår dem
Selv med de beste verktøyene kan det dukke opp noen feller. Her er det jeg har lært (noen ganger på den harde måten):
- OCR-feil: Uskarpe skanninger eller rare fonter kan lure selv den beste OCR-en. Prøv å bruke så rene PDF-er som mulig, og dobbeltsjekk kritiske felt.
- Komplekse layouter: Tabeller med flere kolonner eller innrykk kan trenge litt manuell veiledning — bruk Thunderbits manuelle valg eller ledetekster.
- Datatyper: Tall med kommaer eller datoer i uvanlige formater? Sett kolonnetypen før eksport, eller rydd opp i Excel/Sheets.
- Filstørrelse-/sidesgrenser: Store PDF-er? Del dem i mindre biter, eller bruk Thunderbits skybaserte modus for batchjobber.
- AI-«hallusinasjon»: Sjelden, men noen ganger kan AI gjette et kolonnenavn eller fylle inn manglende data. Kontroller alltid resultatet, spesielt når det gjelder viktige tall.
- Manuell kontroll: For data som er kritiske for virksomheten, gjør en rask validering — automatiserte verktøy er nøyaktige, men et menneskelig blikk skader aldri.
Og hvis du møter en vegg, er Thunderbits support og community der for å hjelpe.
Konklusjon og viktige poenger: få PDF-uttrekk til å fungere for virksomheten din
La oss runde av. Å trekke ut data fra PDF-er var før et mareritt — tregt, feilutsatt og bare kjedelig. Men med moderne verktøy som Thunderbit er det nå raskt, nøyaktig og — våger jeg å si det — nesten gøy.
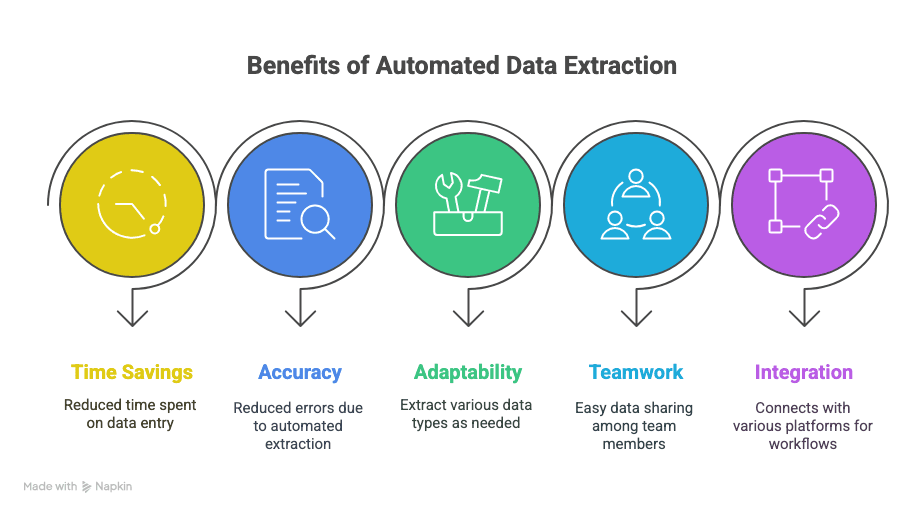
Dette får du:
- Tid tilbake: Timer (eller til og med uker) spart på manuell dataregistrering.
- Færre feil: Automatisert uttrekk betyr færre skrivefeil og færre hoppede rader.
- Fleksibilitet: Hent ut akkurat det du trenger — tekst, tabeller, bilder, lenker, alt mulig.
- Samarbeid: Del data umiddelbart med teamet ditt, uansett hvor de er.
- Smartere arbeidsflyter: Integrer med Sheets, Notion, Airtable og mer.
Klar til å prøve? Last ned Thunderbit Chrome-utvidelsen, kjør den på din neste PDF, og se hvor mye enklere livet kan bli. Fremtidige deg (og håndleddene dine) kommer til å takke deg.
For flere tips og guider, sjekk ut Thunderbit-bloggen eller gå dypere inn i Hvordan hente ut data fra PDF med AI.
La oss gjøre PDF-hodepinen om til produktivitetsgevinster — ett klikk om gangen.
Shuai Guan, medgründer og administrerende direktør, Thunderbit
Prøv Thunderbit AI PDF-uttrekker Get Started Free




