
Tempoet i digitale nyheter i dag er rett og slett svimlende. Hvert minutt publiseres, oppdateres eller diskret redigeres tusenvis av overskrifter — på alt fra store nyhetskanaler og nisjeblogger til sosiale medier.
For å sette det i perspektiv samler inn over 4 millioner nyhetsartikler hver eneste dag, mens overvåker nyheter på 100+ språk og oppdaterer den globale feeden sin hvert 15. minutt.
For alle som jobber med medier, forskning eller business intelligence, føles det å prøve å holde tritt med denne strømmen manuelt som å øse vann ut av en synkende båt med kaffekopp.
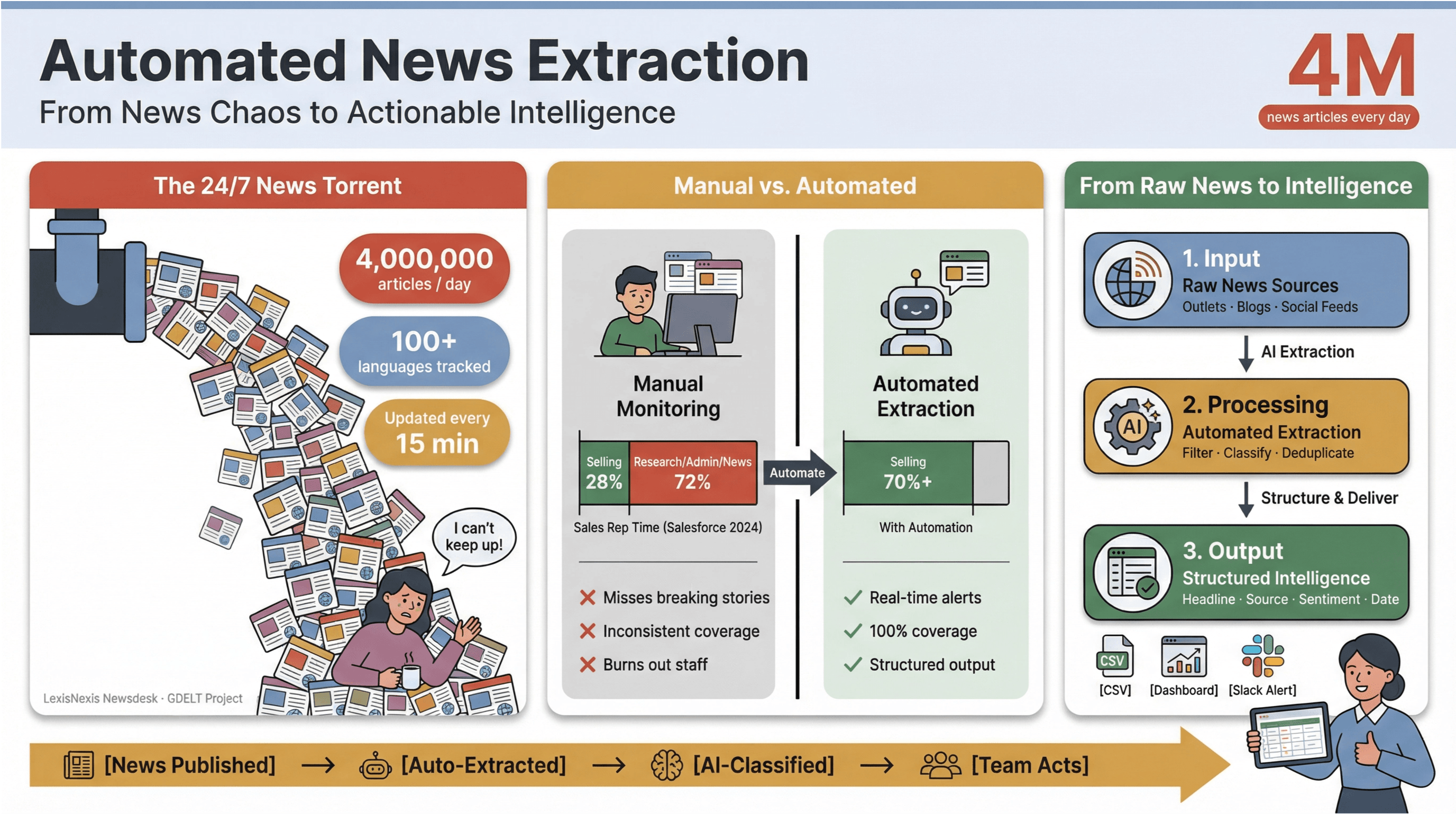
Jeg har sett med egne øyne hvordan manuell nyhetsovervåking sluker tid og tapper ressurser. Salgsteam bruker mindre enn en tredel av uken sin på faktisk salg — — mens resten forsvinner i research, administrasjon og, ja, endeløs hopping mellom nyhetsfaner.
Derfor har automatisert nyhetsekstraksjon blitt et hemmelig våpen for moderne team: Det er den eneste måten å gjøre kaoset i nyhetsdøgnet om til strukturert, handlingsrettet innsikt — uten å brenne ut medarbeiderne eller gå glipp av historiene som betyr mest.
La oss se nærmere på hva automatisert nyhetsekstraksjon egentlig betyr, hvorfor det er helt avgjørende for alle som bryr seg om sanntidsnyheter, og hvordan du bygger en robust og regelverkstilpasset arbeidsflyt ved hjelp av de beste verktøyene (inkludert hvordan gjør hele prosessen oppsiktsvekkende enkel — selv for ikke-tekniske folk som moren min).
Automatisert nyhetsekstraksjon: Hvorfor det er avgjørende for moderne redaksjoner
Automatisert nyhetsekstraksjon er akkurat det det høres ut som: bruk av programvare for å samle inn nyhetsinnhold automatisk og gjøre det om til strukturerte, søkbare data — tenk rader og kolonner i stedet for rotete nettsider eller PDF-er. I praksis betyr det at du kan overvåke hundrevis (eller tusenvis) av kilder, hente ut nøkkelfelter som overskrift, tidsstempel, forfatter og brødtekst, og sende disse dataene videre til dashbord, varsler eller videre analyse — uten å røre Ctrl+C/Ctrl+V.
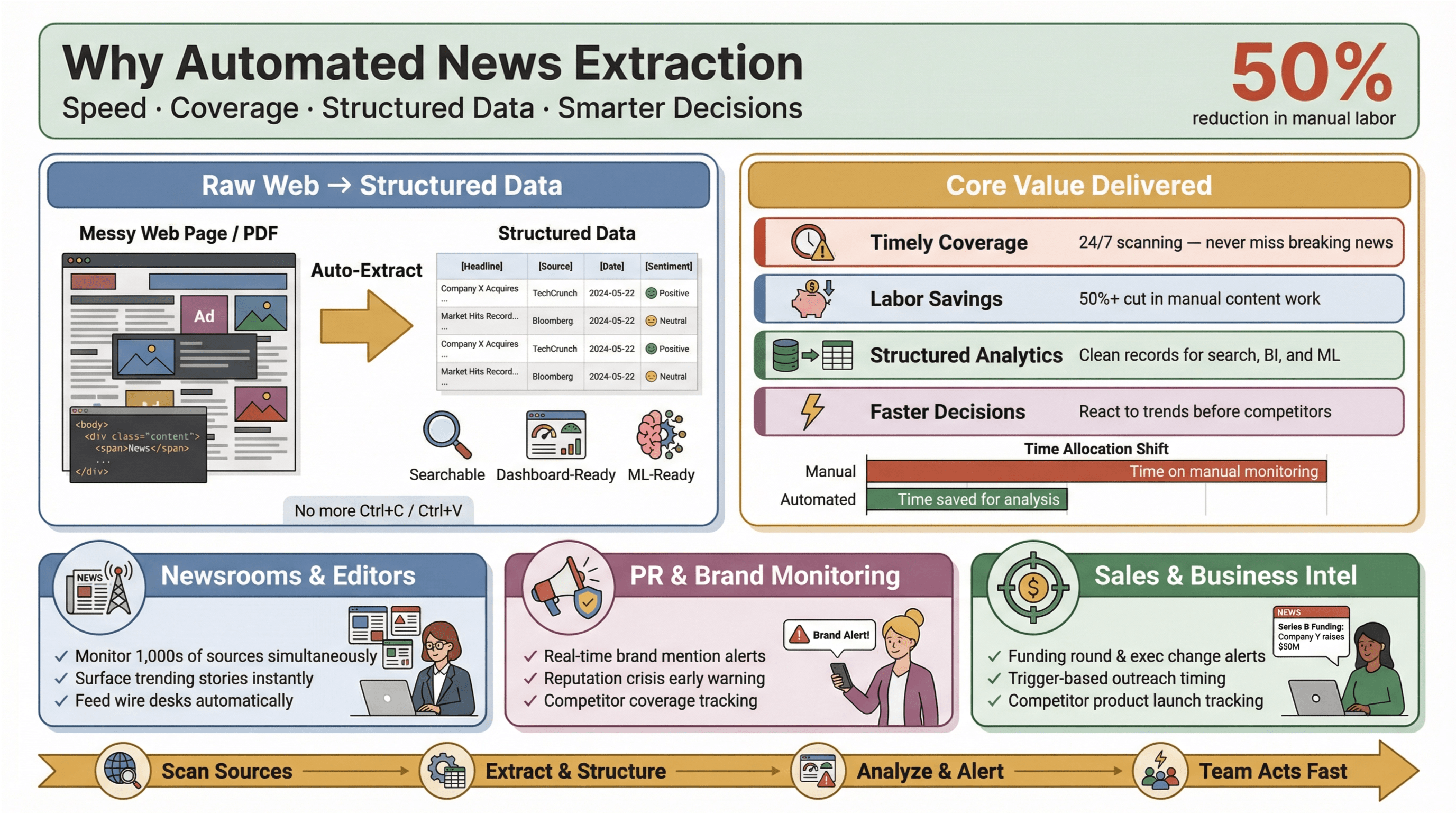 Hvorfor er dette viktig? Fordi fart er alt i dagens nyhetslandskap. Enten du er redaktør i en redaksjon, PR-ansvarlig som følger med på merkenavn, eller forretningsanalytiker som sporer konkurrentbevegelser, kan det å være først til å vite bety forskjellen mellom å gripe en mulighet og å måtte løpe etter. Automatiserte ekstraksjonsverktøy lar selv små team slå godt over sin vektklasse — ved å samle inn sanntidsnyheter fra hele nettet, redusere manuelt arbeid og løfte fram historiene som betyr mest.
Hvorfor er dette viktig? Fordi fart er alt i dagens nyhetslandskap. Enten du er redaktør i en redaksjon, PR-ansvarlig som følger med på merkenavn, eller forretningsanalytiker som sporer konkurrentbevegelser, kan det å være først til å vite bety forskjellen mellom å gripe en mulighet og å måtte løpe etter. Automatiserte ekstraksjonsverktøy lar selv små team slå godt over sin vektklasse — ved å samle inn sanntidsnyheter fra hele nettet, redusere manuelt arbeid og løfte fram historiene som betyr mest.
Og effekten er reell: Studier viser at automatisering kan redusere manuelt arbeid knyttet til innholdsoppdateringer med minst 50 %, og dermed frigjøre tid til faktisk analyse og beslutningstaking.
Kjerneverdien av automatisert nyhetsekstraksjon i nyhetsbransjen
La oss være praktiske. Hva leverer egentlig automatisert nyhetsekstraksjon til redaksjoner og forretningsteam?
- Tidsriktig og bred dekning: Slutt på å gå glipp av nyhetsbomber fordi noen glemte å sjekke en feed. Automatiserte verktøy skanner kilder døgnet rundt, så du ikke går glipp av noe.
- Arbeids- og kostnadsbesparelser: Små og mellomstore team kan overvåke like mange kilder som de store — uten å ansette en hær av interns.
- Strukturerte data for analyse: I stedet for å grave deg gjennom ustrukturerte artikler får du rene, strukturerte poster klare for søk, dashbord og maskinlæring.
- Raskere og smartere beslutninger: Sanntids nyhetsdata gjør at du kan reagere på markedsendringer, PR-kriser eller nye trender før konkurrentene dine.
Ta PR og kommunikasjon: Plattformene og posisjonerer sanntids medieovervåking som helt nødvendig for å beskytte omdømmet og handle raskt på skadelig omtale. I salg blir sanntids nyhetsvarsler til «kontekstkort» for prospektering — tenk finansieringsrunder, lederbytter eller produktlanseringer som utløser kontakt akkurat når timingen er riktig.
Velg riktige nyhetsscraping-verktøy for ulike scenarioer
Ikke alle verktøy for nyhetsscraping er like. Det riktige valget avhenger av målene dine, hvor teknisk komfortabel du er, og hvilke typer nyheter du bryr deg om. Her er en ramme som hjelper deg å velge det som passer best:
Vurdere brukervennlighet og tilgjengelighet
For de fleste forretningsbrukere og journalister er brukervennlighet ikke til forhandling. Du vil ha et verktøy som fungerer rett ut av boksen, uten koding eller komplisert oppsett. No-code- og low-code-plattformer som , og lar deg bygge scrapers visuelt — bare pek, klikk og hent ut.
Thunderbit skiller seg spesielt ut med sin to-trinnsprosess: Beskriv hva du vil ha, la AI foreslå feltene, og trykk «Scrape». Selv brukere uten teknisk bakgrunn kan sette opp en pipeline for nyhetsdata på minutter, ikke timer.
Vurdering av sikkerhet og personvern
Med gode data følger stort ansvar. Verktøy for nyhetsscraping får ofte tilgang til sensitivt innhold, så sikkerhet og etterlevelse bør stå høyt på agendaen. Se etter:
- Datakryptering (under overføring og lagring)
- Tydelige personvernregler (Thunderbit opplyser for eksempel at det ikke selger brukerdata og bare får tilgang til innhold du selv velger å hente ut)
- Detaljerte tillatelser (særlig for nettleserutvidelser — sjekk alltid hvilke data verktøyet kan få tilgang til)
- Etterlevelse av lokale lover (GDPR, CCPA og for EU-brukere )
For ekstra trygghet bør du velge anerkjente leverandører, kontrollere utvidelsestillatelser og begrense tilgangen til bare det som er nødvendig.
Tilpasse verktøy til nyhetstyper og bransjebehov
Noen verktøy er spesielt gode på bestemte nyhetsdomener:
- Finans: API-er som og tilbyr klynging, sentiment og hendelsesdeteksjon for finansnyheter.
- Teknologi og startups: Egendefinert scraping med Thunderbit eller Octoparse lar deg målrette nisjeblogger, pressemeldinger eller arrangementslister.
- Politikk og policy: Lisensierte databaser som og gir tilgang til premiumkilder og arkiver.
Hvis du trenger å overvåke en blanding av store, smale og internasjonale kilder — også de uten API-er — er fleksible AI-drevne scrapers som Thunderbit det beste valget.
Thunderbits unike fordeler for ekstraksjon av sanntids nyhetsdata
La oss nå snakke om det som gjør til et fremragende valg for automatisert nyhetsekstraksjon — spesielt hvis du vil ha sanntids nyhetsdata uten tekniske hodepiner.
Thunderbit er en AI-drevet Chrome-utvidelse for webscraping utviklet for forretningsbrukere, journalister og analytikere som trenger oppdatert, strukturert nyhetsinnhold fra hvilken som helst nettside. Her er hvorfor den har blitt min favoritt:
- AI-forslag til felt: Thunderbit leser nyhetssiden og foreslår automatisk de beste kolonnene å hente ut — overskrift, tidsstempel, forfatter, sammendrag og mer. Du slipper å styre med selektorer eller maler.
- Undersidescraping: Trenger du hele artikkelen, ikke bare overskriften? Thunderbit kan besøke hver nyhetslenke, hente ut brødtekst, entiteter og tagger, og slå alt sammen til én strukturert tabell.
- Masseeksport og umiddelbare oppdateringer: Eksporter nyhetsdata direkte til Excel, Google Sheets, Airtable eller Notion med ett klikk. Slutt på endeløse kopier-og-lim og CSV-krøll.
- Planlagt scraping: Sett opp gjentakende jobber (hver time, daglig eller med egendefinerte intervaller) for å holde nyhetsløpet ferskt — ideelt for ferske nyheter, markedsovervåking eller løpende research.
- Tilpasningsevne: Thunderbits AI tilpasser seg layoutendringer og lange haler av nyhetssider, så du bruker mindre tid på å fikse ødelagte scrapers og mer tid på å analysere data.
Med over og en vurdering på 4,8 stjerner er den betrodd av team over hele verden til alt fra PR-overvåking til konkurranseinnsikt.
AI-drevet feltdeteksjon og undersidescraping
En av Thunderbits sterkeste funksjoner er den AI-drevne feltdeteksjonen. Bare klikk på «AI Suggest Fields», så skanner verktøyet nyhetssiden — og identifiserer nøkkelfelter som tittel, dato, forfatter og sammendrag. Du kan justere eller legge til egendefinerte felt (for eksempel «merk denne artikkelen som 'inntjening' hvis den nevner kvartalsresultater»), og Thunderbits AI tar seg av resten.
Undersidescraping er en gamechanger for nyheter: Skrap en forside eller en seksjonsliste for overskrifter, og la deretter Thunderbit besøke hver artikkel-URL for å hente ut hele saken, entiteter og til og med bilder. Det betyr at du får komplette, berikede nyhetsposter — klare for søk, dashbord eller videre AI-analyse.
Masseeksport og umiddelbare oppdateringer
Thunderbit gjør eksport av nyhetsdata smertefri. Med ett klikk kan du sende den strukturerte nyhetsstrømmen til Google Sheets, Airtable eller Notion, eller laste den ned som CSV/Excel. For team som lever i regneark eller BI-verktøy, er dette en enorm tidsbesparelse.
Og fordi Thunderbit støtter planlagt scraping, kan du sette den til å kjøre hver time, hver dag eller etter din egen tidsplan — slik at nyhetsdataene alltid er oppdaterte. Slutt på å vente på at Google Alerts skal indeksere saker flere dager for sent.
Løs operative utfordringer i sanntidsløsninger for nyhetsdata
Selv med de beste verktøyene kommer sanntidsekstraksjon av nyheter med sine egne utfordringer. Slik takler du de vanligste:
Håndtere forsinkelse og ferskhet i data
- Planlegg scraping etter nyhetshastighet: For brennhete nyheter bør scrapers kjøres hvert 15.–30. minutt (i tråd med ). For roligere stoff kan daglig eller hver time være nok.
- Overvåk tidsforskjellen mellom publisering og henting: Følg med på forskjellen mellom når en artikkel publiseres og når systemet ditt henter den. Hvis forsinkelsen øker, sjekk for blokkeringer eller treghet.
- Skrap på nytt for «stille redigeringer»: Nyhetsartikler oppdateres ofte etter publisering. Legg inn en ny scraping 24 timer senere for å fange opp rettelser eller skjulte endringer ().
Håndtere API-begrensninger og variasjon mellom kilder
- Respekter API-kvoter: Hvis du bruker nyhets-API-er, vær oppmerksom på rate limits — fordel forespørsler over tid og cache resultater når det er mulig ().
- Fjern duplikater og bruk kanoniske URL-er: Nyhetssaker finnes ofte på flere URL-er eller blir oppdatert. Fang opp kanoniske URL-er og bruk hasher (for eksempel tittel + dato) for å unngå duplikater ().
- Håndter dynamisk innhold: For nettsteder med uendelig scroll eller lazy loading bør du bruke verktøy som støtter dynamisk rendering og følge med på layoutendringer ().
Smart analyse av nyhetsdata: Rollen til AI og maskinlæring
Å hente ut nyheter er bare første steg. Den virkelige verdien ligger i å analysere og handle på dataene — og det er her AI og maskinlæring virkelig skinner.
- Entitetsuttrekk: Bruk NLP til å trekke ut personer, organisasjoner og steder som nevnes i hver artikkel ().
- Emneklassifisering: Merk artikler automatisk etter tema, sentiment eller hast — for smartere dashbord og varsler ().
- Hendelsesklynging: Gruppér dupliserte eller beslektede saker på tvers av medier, slik at du ser helheten — ikke bare en flom av nesten identiske overskrifter.
- Personalisering og målretting: Bruk sanntids nyhetsdata til å segmentere målgrupper, forbedre annonsering eller anbefale innhold — og dermed øke engasjement og ROI.
PR-team bruker for eksempel sanntids analyse av nyheter til å oppdage nye kriser før de går viralt, mens salgsteam beriker prospektlister med «utløserhendelser» som finansieringsrunder eller ansettelser av ledere.
Sjekkliste for beste praksis ved automatisert nyhetsekstraksjon
Her er en rask sjekkliste som hjelper deg å holde nyhetsekstraksjonspipelinen stabil:
| Beste praksis | Hvorfor det er viktig | Hvordan implementere |
|---|---|---|
| Planlegg hyppig scraping | Minimer datalogg, fang opp brennhete nyheter | Tilpass oppdateringsfrekvensen til nyhetshastigheten (f.eks. hvert 15. minutt for raske saker) |
| Bruk AI-drevet ekstraksjon | Tilpass deg layoutendringer, reduser oppsettstid | Verktøy som Thunderbit, Diffbot, Zyte API |
| Fjern duplikater og bruk kanoniske URL-er | Unngå dupliserte varsler, sørg for rene data | Fang opp kanoniske URL-er, bruk hasher for deduplisering |
| Overvåk ekstraksjonskvalitet | Oppdag manglende felt, avvik eller feil | Følg med på andel fullførte poster, forsinkelse og feilrater |
| Respekter juridiske og regulatoriske grenser | Unngå juridisk risiko, bygg tillit | Foretrekk offisielle API-er/feed, gjennomgå vilkår, minimer persondata |
| Eksporter til strukturerte formater | Gjør videre analyse mulig | CSV, Excel, Sheets, Notion, Airtable |
| Planlegg ny skraping ved endringer | Fang opp endringer etter publisering | Gå tilbake til artikler etter 24 t/1 uke (GDELT-modellen) |
| Sikre pipelinen din | Beskytt sensitive data | Kryptering, tilgangskontroller, pålitelige verktøy |
Bygg en robust automatisert arbeidsflyt for nyhetsekstraksjon
Klar til å bygge din egen «black box» for nyhetsdata? Her er en trinnvis arbeidsflyt:
- Identifiser kildene dine: Lag en liste over nyhetssider, blogger eller API-er du vil overvåke.
- Sett opp ekstraksjonen: Bruk Thunderbit eller verktøyet du foretrekker til å definere felter (AI Suggest Fields gjør dette til en lek).
- Planlegg scraping: Sett frekvensen etter nyhetshastigheten — hver time for ferske nyheter, daglig for roligere stoff.
- Berik undersider: For hver overskrift, skrap hele artikkelen for brødtekst, entiteter og tagger.
- Fjern duplikater og normaliser: Fang opp kanoniske URL-er, hasher poster og standardiser feltene.
- Eksporter og integrer: Send strukturerte data til Excel, Google Sheets, Airtable eller Notion for analyse.
- Overvåk og tilpass: Følg med på ekstraksjonskvalitet, se etter layoutendringer og juster ved behov.
- Hold deg innenfor regelverket: Gå gjennom vilkår, respekter robots.txt og minimer persondata.
For en visuell arbeidsflyt kan du tenke slik:
Kilder → Ekstraksjon (AI-felter) → Beriking av undersider → Deduplisering → Eksport → Analyse/varsler → Overvåking
Konklusjon og viktige læringspunkter
Automatisert nyhetsekstraksjon er ikke lenger bare «kjekt å ha» — det er et must for alle som må ligge i forkant i en verden der nyheter bryter ut (og endrer seg) fra minutt til minutt. Ved å følge beste praksis og bruke de riktige verktøyene kan du gjøre den digitale nyhetsflommen om til en jevn strøm av handlingsrettet, strukturert innsikt.
Viktige læringspunkter:
- Omfanget og hastigheten i nettbaserte nyheter krever automatisering — manuell overvåking klarer rett og slett ikke å holde tritt.
- Automatiserte verktøy for nyhetsekstraksjon sparer tid, reduserer kostnader og gjør små team i stand til å matche dekningen til langt større organisasjoner.
- Å velge riktig verktøy handler om å balansere brukervennlighet, sikkerhet og tilpasningsevne — Thunderbit skiller seg ut med AI-drevet enkelhet og eksportmuligheter i sanntid.
- Bygg arbeidsflyten rundt ferskhet, deduplisering, etterlevelse og kvalitetskontroll for å sikre pålitelige og handlingsrettede nyhetsdata.
- AI og maskinlæring åpner for enda større verdi — med smartere målretting, personalisering og beslutningstaking.
Hvis du fortsatt kopierer og limer inn overskrifter, eller venter på at Google Alerts skal ta igjen forspranget, er det på tide å ta det et steg videre. og se hvor enkelt automatisert nyhetsekstraksjon kan være. For flere tips, arbeidsflyter og dypdykk, sjekk ut .
Vanlige spørsmål
1. Hva er automatisert nyhetsekstraksjon, og hvordan fungerer det?
Automatisert nyhetsekstraksjon er prosessen der programvare brukes til å samle inn nyhetsartikler og gjøre dem om til strukturerte data (for eksempel tabeller eller JSON) for analyse, søk eller varsler. Verktøy som Thunderbit bruker AI til å identifisere nøkkelfelter (overskrift, tidsstempel, forfatter, brødtekst) og hente dem ut automatisk fra nettsider eller API-er.
2. Hvorfor er sanntids nyhetsdata så viktig for bedrifter?
Sanntids nyhetsdata gjør at bedrifter kan reagere raskt på markedsendringer, PR-kriser eller konkurrentbevegelser. Enten du jobber med salg, PR eller forskning, betyr oppdaterte nyheter at du kan ta smartere og raskere beslutninger og ligge foran konkurrentene.
3. Hvordan gjør Thunderbit nyhetsscraping enklere for ikke-tekniske brukere?
Thunderbit tilbyr en enkel totrinnsprosess: Beskriv hvilke data du vil ha, og la AI foreslå feltene. Med funksjoner som undersidescraping og umiddelbar eksport til Excel eller Google Sheets kan selv brukere uten teknisk bakgrunn bygge robuste pipelines for nyhetsdata på minutter.
4. Hva er de juridiske og regulatoriske hensynene ved nyhetsscraping?
Gå alltid gjennom bruksvilkårene for målsidene dine, foretrekk offisielle API-er eller feeds når de er tilgjengelige, og respekter robots.txt-direktivene. Unngå å skrape innhold som krever innlogging eller ligger bak betalingsmur uten tillatelse, og minimer innsamlingen av persondata for å holde deg innenfor personvernreglene.
5. Hvordan kan jeg sikre at arbeidsflyten min for nyhetsekstraksjon forblir pålitelig over tid?
Planlegg regelmessig scraping, følg med på ekstraksjonskvaliteten, og bruk verktøy som tilpasser seg layoutendringer (som Thunderbits AI-drevne ekstraksjon). Fjern duplikater, spor forsinkelsen mellom publisering og ekstraksjon, og sett opp varsler for feil eller manglende felt for å holde pipelinen sunn og oppdatert.
Les mer