

OpenRouter-dashbordet mitt viste 47 dollar brukt før lunsj en tirsdag. Jeg hadde kanskje kjørt et dusin kodeoppgaver — ikke noe ekstremt, bare litt refaktorering og noen feilrettinger. Da gikk det opp for meg at OpenClaws standardinnstillinger stille og rolig sendte hver eneste interaksjon, inkludert små bakgrunnspinger, gjennom Claude Opus til over 15 dollar per million tokens.
Hvis du har sett lignende overraskelser — og ut fra forumene er det mange som har det ("I already spend 40 dollars and doesn't even use it much," skrev en bruker) — viser denne guiden deg hele metoden jeg brukte for å gå fra full oversikt til optimalisering og kutte månedskostnadene med rundt 90 %. Ikke bare "bytt til en billigere modell", men en systematisk gjennomgang av hvor tokenene faktisk forsvinner, hvordan du overvåker dem, hvilke budsjettmodeller som faktisk fungerer i agentisk arbeid, og tre ferdigkopierbare oppsett du kan bruke med en gang. Hele prosessen tok én ettermiddag.
Hva er OpenClaw tokenforbruk, og hvorfor er det så høyt som standard?
Tokens er faktureringsenheten for hver AI-interaksjon i OpenClaw. Tenk på dem som små tekstbiter — omtrent 4 engelske tegn per token. Hver melding du sender, hvert svar du får, hver bakgrunnsprosess som trigges: alt faktureres i tokens.
Problemet er at OpenClaws standardoppsett er optimalisert for maksimal kapasitet, ikke lavest mulig kostnad. Rett ut av boksen er primærmodellen satt til anthropic/claude-opus-4-5 — det dyreste alternativet som finnes. Heartbeat-pingene? De går også på Opus. Sub-agenter som opprettes for sideoppgaver? Også Opus. Å bruke Opus til en heartbeat-ping er som å hyre en nevrokirurg for å sette på et plaster. Teknisk sett kompetent, økonomisk helt bak mål.
De fleste skjønner ikke at de betaler premiumpriser for trivielle bakgrunnsoppgaver. Standardkonfigurasjonen antar i praksis at du vil ha den beste modellen til alt, hele tiden — og fakturerer deretter.
Hvorfor det å redusere OpenClaw-tokenforbruket sparer mer enn bare penger
Den åpenbare gevinsten er lavere kostnader. Men det finnes også sekundære fordeler som bygger seg opp over tid.
Billigere modeller er ofte raskere. Gemini 2.5 Flash-Lite kjører på rundt 214 tokens per sekund sammenlignet med Opus på omtrent 51 — altså 4x bedre fart i hver eneste interaksjon. GPT-OSS-120B på Cerebras når 1 917 tokens per sekund, som er omtrent 35x raskere enn Opus. I en agentisk loop med 50+ runder med verktøykall betyr den forskjellen at jobben blir ferdig på minutter i stedet for at du sitter og venter gjennom Opus' smertefulle 13,6 sekunder til første token på hver runde fram og tilbake.
Du får også mer slingringsmonn før du treffer rate limits, færre sesjoner som blir strupet, og bedre rom til å skalere bruken uten at regningen gir deg puls.
Anslåtte besparelser for ulike bruksmønstre:
| Brukerprofil | Estimert månedskostnad (standard) | Etter full optimalisering | Månedlig besparelse |
|---|---|---|---|
| Lett (~10 søk/dag) | ~$100 | ~$12 | ~88% |
| Middels (~50 søk/dag) | ~$500 | ~$90 | ~82% |
| Høy (~200+ søk/dag) | ~$1,750 | ~$220 | ~87% |
Dette er ikke hypotetisk. En utvikler dokumenterte at han gikk fra $600–750/måned ned til $3–4/dag — en reell reduksjon på 90 % — ved å kombinere modellruting med de skjulte lekkasjene som beskrives senere i guiden.
OpenClaw tokenforbruk i praksis: hvor går alle tokenene egentlig?
Dette er delen de fleste optimaliseringsguider hopper over, og det er også den viktigste. Du kan ikke fikse det du ikke ser.
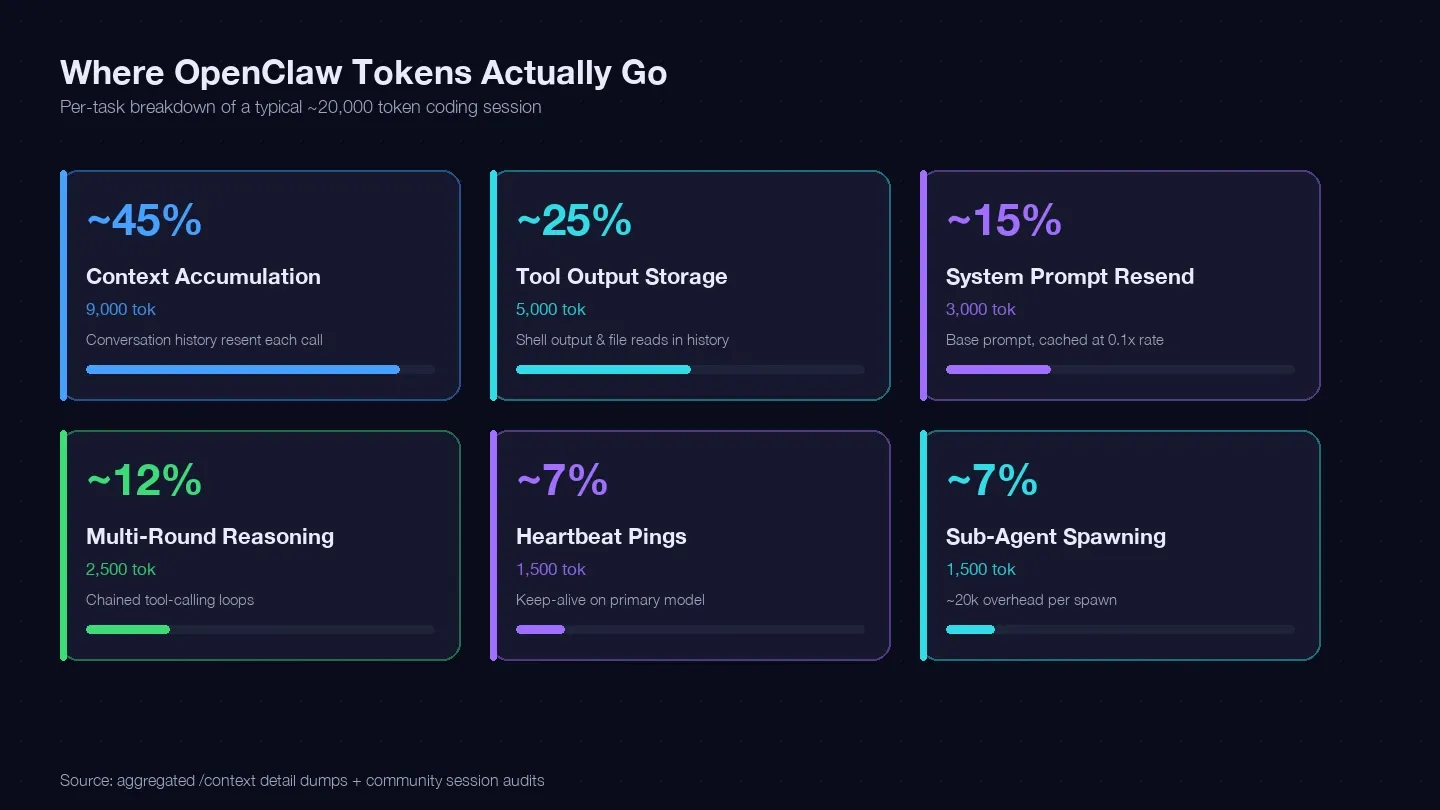
Jeg gikk gjennom flere økter og sammenlignet med LaoZhangs guide til kostnadsoptimalisering og community-dumper av /context for å lage et token-regnskap for en typisk enkelt kodeoppgave. Her er hvor omtrent 20 000 tokens faktisk gikk:
| Tokenkategori | Typisk andel av totalen | Eksempel (1 kodeoppgave) | Kan du styre det? |
|---|---|---|---|
| Akkumulert kontekst (samtalehistorikk sendes på nytt hver gang) | ~40–50% | ~9 000 tokens | Ja — /clear, /compact, kortere sesjoner |
| Lagring av verktøyutdata (shell-output, fil-lesing beholdes i historikken) | ~20–30% | ~5 000 tokens | Ja — mindre lesing, snevrere verktøyscope |
| Ny sending av systemprompt (~15K basis) | ~10–15% | ~3 000 tokens | Delvis — cache-lesing til 0,1x rate |
| Flertrinns resonnering (lenkede verktøykall-løkker) | ~10–15% | ~2 500 tokens | Modellvalg + bedre prompting |
| Heartbeat / keep-alive pinger | ~5–10% | ~1 500 tokens | Ja — konfigurasjonsendring |
| Sub-agent-kall | ~5–10% | ~1 500 tokens | Ja — modellruting |
Den klart største posten — akkumulert kontekst — er at samtalehistorikken din sendes på nytt ved hvert API-kall. Én ekte sesjonsdump viste 185 400 tokens bare i Messages-bøtten, før modellen i det hele tatt hadde svart. Systemprompten og verktøyene la på ytterligere rundt 35 800 tokens i fast overhead.
Hovedpoenget: Hvis du ikke starter nye sesjoner mellom urelaterte oppgaver, betaler du for å sende hele samtalehistorikken din på nytt i hver eneste runde.
Hvordan overvåke OpenClaw-tokenforbruket ditt (du kan ikke kutte det du ikke ser)
Før du endrer noe, må du få oversikt over hvor tokenene faktisk tar veien. Å hoppe rett til "bruk en billigere modell" uten å overvåke er som å prøve å gå ned i vekt uten å gå på vekta.
Sjekk OpenRouter-dashbordet ditt
Hvis du ruter via OpenRouter, er Activity-siden den enkleste oversikten uten oppsett. Der kan du filtrere på modell, leverandør, API-nøkkel og tidsperiode. Usage Accounting-visningen bryter ned prompt, completion, reasoning og cached tokens per forespørsel. Det finnes også en Export-knapp (CSV eller PDF) for mer langsiktig analyse.
Se etter dette: hvilken modell som brukte flest tokens, og om heartbeat- eller sub-agent-forespørsler dukker opp som uventet store enkeltposter.
Gå gjennom dine lokale API-logger
OpenClaw lagrer sesjonsdata i ~/.openclaw/agents.main/sessions/sessions.json, som inkluderer totalTokens per sesjon. Du kan også kjøre openclaw logs --follow --json for sanntidslogging per forespørsel.
En viktig ting å vite: sessions.json totalTokens oppdateres ikke etter komprimering, så dashbordet kan vise gamle tall fra før compaction. Stol mer på /status og /context detail enn på lagrede totalsummer.
Bruk tredjepartssporing (for middels til tunge brukere)
LiteLLM proxy gir deg et OpenAI-kompatibelt endepunkt foran 100+ leverandører og logger automatisk forbruk per virtuell nøkkel, modell, bruker og team. Den store fordelen: harde budsjetter per nøkkel som overlever /clear — en runaway sub-agent kan ikke sprenge grensen du har satt.
Helicone er enda enklere — et ettlinjers bytte av base-URL som gir deg en Sessions-visning der relaterte forespørsler grupperes. En enkel "fiks denne buggen"-prompt som spres ut i 8+ sub-agent-kall vises som én sesjonsrad med den faktiske totalprisen. Gratisnivå: 10 000 forespørsler/måned.
Kjappe sjekker direkte i OpenClaw
Til daglig overvåking holder disse fire kommandoene i sesjonen:
/status— viser kontekstbruk, siste input-/output-tokens og estimert kostnad/usage full— brukssammendrag nederst per svar/context detail— tokenfordeling per fil, skill og verktøy/compact [guidance]— tving komprimering med valgfri fokusstreng
Kjør /context detail før og etter at du endrer konfigurasjon. Slik måler du om optimaliseringen faktisk fungerte.
Kampen om den billigste OpenClaw-modellen: hvilke budsjett-LLM-er takler faktisk agentisk arbeid?
Det er her de fleste guider bommer. De viser deg en prisliste, peker på den billigste raden og er ferdig med det. Benchmarks sier ikke nok om hvordan modellene oppfører seg i ekte agentisk bruk — noe communityet har påpekt høylytt og gjentatte ganger. Som én bruker sa: "benchmarks aren't doing any justice to understand which one works best for agentic AI."
Det viktigste innblikket: Den billigste modellen er ikke alltid den billigste løsningen. En modell som feiler og prøver på nytt fire ganger koster mer enn en mellomklassemodell som lykkes på første forsøk. I produksjon må du regne med en 5–10 % retry-rate — og hvis fem LLM-kall er lenket sammen og steg fire feiler, vil en naiv retry kjøre alle fem stegene på nytt.
Her er min kapabilitetsmatrise, med en "Real Agentic Score" basert på faktiske brukeropplevelser i stedet for syntetiske benchmarks:
| Modell | Input $/1M | Output $/1M | Pålitelighet ved verktøykall | Flerstegsresonnering | Real Agentic Score (1–5) | Best for |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Blandet — av og til løkker | Grunnleggende | ⭐2.5 | Heartbeats, enkle oppslag |
| GPT-OSS-120B | $0.04 | $0.19 | Grei | Grei | ⭐3.0 | Budsjetteksperimentering, fartskritisk bruk |
| DeepSeek V3.2 | $0.26 | $0.38 | Ujevn (6 åpne issues) | God | ⭐3.0 | Resoneringstungt, lite verktøykall |
| Kimi K2.5 | $0.38 | $1.72 | God (via :exacto) | Grei | ⭐3.5 | Enkel til middels koding |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | God | God | ⭐4.0 | Generell koding til daglig bruk |
| Claude Haiku 4.5 | $1.00 | $5.00 | Utmerket | God | ⭐4.5 | Pålitelig mellomklasse-fallback |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Utmerket | Utmerket | ⭐5.0 | Komplekse flertrinnsoppgaver |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Utmerket | Utmerket | ⭐5.0 | Kun for de vanskeligste problemene |
En advarsel om DeepSeek og Gemini Flash for verktøykall
DeepSeek V3.2 ser bra ut på papiret — 72–74 % på SWE-Bench, 11–36x billigere enn Sonnet. I praksis dokumenterer seks separate GitHub-issues på tvers av Cline, Roo Code, Continue og NVIDIA NIM ødelagt verktøykall-oppførsel. Composios head-to-head-dom: "DeepSeek V3.2 built parts of the app but stumbled on execution, speed, and reliability." Zvi Mowshowitz sin korte oppsummering: "okay and cheap, but."
Gemini 2.5 Flash har et lignende gap. En tråd i Google AI Developers Forum med tittelen "Very frustrating experience with Gemini 2.5 function calling performance" starter med: "the function calling behavior of Gemini models has become completely unreliable and unpredictable."
OpenRouter har påpekt en viktig nyanse: "the propensity of a model to call tools and the accuracy of those calls can vary dramatically across hosts of the same weights." Hvis du ruter billige modeller via OpenRouter, se etter :exacto-taggen — en stille bytte av leverandør kan gjøre en pålitelig billig modell om til en dyr retry-løkke over natten.
Når du bør bruke hver modell
- Gemini Flash-Lite: Heartbeats, keep-alive-pinger, enkle spørsmål og svar. Aldri for flertrinns verktøykall.
- MiniMax M2.5/M2.7: Din daglige arbeidshest for generelle kodeoppgaver. SWE-Pro 56.22, Terminal-Bench 2 57.0 % til en brøkdel av prisen på Sonnet.
- Claude Haiku 4.5: Den pålitelige fallbacken når billige modeller sliter med verktøykall. Svært god på verktøykall til rundt 3x lavere pris enn Sonnet.
- Claude Sonnet 4.6: Komplekse agentiske oppgaver med flere steg. Her får du virkelig valuta for pengene.
- Claude Opus: Reserver den for de vanskeligste problemene. Ikke la den være standard for noe som helst.
(Modellpriser endres ofte — sjekk alltid gjeldende priser på OpenRouter eller hos den aktuelle leverandøren før du låser deg til en konfigurasjon.)
De skjulte tokenlekkasjene de fleste guider hopper over
Forumbrukere rapporterer at det å skru av bestemte funksjoner kan redusere kostnadene kraftig, men jeg har ikke funnet noen guide som samler alle de skjulte lekkasjene med faktisk tokenpåvirkning. Her er hele gjennomgangen:
| Skjult lekkasje | Tokenkostnad per hendelse | Slik fikser du det | Konfigurasjonsnøkkel |
|---|---|---|---|
| Standard heartbeat på Opus | ~100 000 tokens/kjøring uten isolasjon | Haiku-overstyring + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Opprettelse av sub-agenter | ~20 000 tokens per opprettelse før noe arbeid er gjort | Ruter sub-agenter til Haiku | subagents.model |
| Lasting av hele kodebasen som kontekst | ~3 000–15 000 tokens per auto-explore | .clawignore for node_modules, dist, lockfiler | .clawrules + .clawignore |
| Automatisk oppsummering av minne | ~500–2 000 tokens/økt | Skru av eller reduser frekvensen | memory: false eller memory.max_context_tokens |
| Akkumulering av samtalehistorikk | ~500+ tokens/runde (kumulativt) | Start nye sesjoner mellom urelaterte oppgaver | /clear-disiplin |
| Verktøyoverhead fra MCP-servere | ~7 000 tokens for 4 servere; 50 000+ for 5+ | Hold MCP-oppsettet minimalt | Fjern ubrukte MCP-er |
| Oppstart av skills/plugins | 200–1 000 tokens per innlastet skill | Skru av ubrukte skills | skills.entries.<name>.enabled: false |
| Agent Teams (planmodus) | ~7x standard sesjonskostnad | Bruk kun for reelt parallelt arbeid | Foretrekk sekvensielt |
Heartbeat-lekkasjen fortjener en egen kommentar. Som standard går heartbeats på primærmodellen (Opus) hvert 30. minutt. Setter du isolatedSession: true, faller dette fra rundt ~100 000 tokens per kjøring ned til 2 000–5 000 tokens — en reduksjon på 95–98 % på akkurat den posten.
Tre raske grep som sparer mest tokens på under to minutter
Alle tre er risikofrie og tar under to minutter:
-
/clearmellom urelaterte oppgaver (5 sekunder). Dette er den klart største tokenbesparelsen. Forumkonsensus sier 50–70 % reduksjon bare ved å tømme sesjonshistorikken før nytt arbeid. Husker du den 185k-token Messages-bøtten fra /context-dumpen?/clearfjerner den. -
/model haiku-4.5for rutinearbeid (10 sekunder). Taktisk modellbytte gir 60–80 % lavere kostnad på vanlige oppgaver. Haiku håndterer de fleste enkle kodeendringer, filoppslag og commit-meldinger helt fint. -
Krymp
.clawrulestil under 200 linjer + legg til.clawignore(90 sekunder). Rules-filen din lastes inn ved hver eneste melding. Ved 200 linjer er det rundt ~1 500–2 000 tokens per runde; ved 1 000 linjer er det 8 000–10 000 tokens som permanent belaster hver forespørsel. Kombinert med en.clawignoresom ekskluderernode_modules/,dist/, lockfiler og generert kode, hevder én utvikler at han fikk 92 % lavere tokenforbruk bare av denne disiplinen.
Trinn for trinn: tre ferdige configer som kutter OpenClaw-tokenforbruket

Nedenfor følger tre komplette, kommenterte openclaw.json-oppsett — fra "bare kom i gang" til "full optimaliseringspakke". Hver av dem inkluderer inline-kommentarer og anslag for månedskostnad.
Før du begynner:
- Vanskelighetsgrad: Nybegynner (Config A) → Middels (Config B) → Avansert (Config C)
- Tidsbruk: ~5 minutter for Config A, ~15 minutter for Config C
- Du trenger: OpenClaw installert, en teksteditor og tilgang til
~/.openclaw/openclaw.json
Config A: Nybegynner — bare spar penger
Fem linjer. Null kompleksitet. Bytter standardmodellen fra Opus til Sonnet, skrur av minneoverhead og isolerer heartbeats til Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // var Opus — umiddelbar 3–5x besparelse
"heartbeat": {
"every": "55m", // samsvarer med 1t cache TTL for flest mulig cache-treff
"model": "anthropic/claude-haiku-4-5", // Haiku for pinger, ikke Opus
"isolatedSession": true // ~100k → 2–5k tokens per kjøring
}
}
},
"memory": { "enabled": false } // sparer ~500–2k tokens/økt
}
Dette bør du se etter å ha brukt dette: Kjør /status før og etter. Kostnaden per forespørsel bør falle merkbart, og heartbeat-oppføringene i OpenRouter Activity-siden skal vise Haiku i stedet for Opus.
| Bruksnivå | Standard (Opus) | Config A (Sonnet + Haiku-heartbeats) | Besparelse |
|---|---|---|---|
| Lett (~10 q/dag) | ~$100 | ~$35 | 65% |
| Middels (~50 q/dag) | ~$500 | ~$250 | 50% |
| Høy (~200 q/dag) | ~$1,750 | ~$900 | 49% |
Config B: Middels — smart trelagsruting
Primær Sonnet for reelt arbeid. Haiku for sub-agenter og komprimering. Gemini Flash-Lite som budsjettfallback når Claude er strupet. Fallback-kjeder håndterer leverandøravbrudd automatisk.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // hvis Sonnet er strupet
"google/gemini-2.5-flash-lite" // ultra-billig siste utvei
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55 min < 1t cache TTL = cache-treff
"model": "google/gemini-2.5-flash-lite", // øre per ping
"isolatedSession": true,
"lightContext": true // minimal kontekst i heartbeat-kall
},
"subagents": {
"maxConcurrent": 4, // ned fra standard 8
"model": "anthropic/claude-haiku-4-5" // sub-agenter trenger ikke Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // oppsummering via Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Forventet resultat: Sub-agent-oppføringene i loggene dine skal nå bruke Haiku-prising. Heartbeats bør koste nær null. Fallback-kjeden betyr at et Claude-avbrudd ikke stopper sesjonen — den faller elegant tilbake til Gemini.
| Bruksnivå | Standard | Config B | Besparelse |
|---|---|---|---|
| Lett | ~$100 | ~$20 | 80% |
| Middels | ~$500 | ~$150 | 70% |
| Høy | ~$1,750 | ~$500 | 71% |
Config C: Power user — full optimaliseringspakke
Per-sub-agent modelltilordning, kontekstkomprimering låst til Haiku, visningsruteriing til Gemini Flash, stram .clawrules + .clawignore, og ubrukte skills skrudd av. Dette er oppsettet som får deg ned i 85–90 % besparelse.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // annen leverandør som backup
"minimax/minimax-m2-7", // billig daglig-fallback
"anthropic/claude-haiku-4-5" // siste utvei
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // ingen heartbeats om natten
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // ned fra standard 20000
"imageModel": "google/gemini-3-flash" // visningsoppgaver via billig modell
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // minimalt minne
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Eksempel på per-sub-agent-overstyring — lim inn i ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Kjører lint/format-sjekker og gjør enkle rettelser
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
Minimumsvennlig .clawignore — dette alene kutter typiske bootstrapper fra 150k tegn ned mot 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Bruksnivå | Standard | Config C | Besparelse |
|---|---|---|---|
| Lett | ~$100 | ~$12 | 88% |
| Middels | ~$500 | ~$90 | 82% |
| Høy | ~$1,750 | ~$220 | 87% |
Disse tallene samsvarer med to uavhengige rapporter fra reelle brukere: Praney Behls dokumenterte $600–750/md → $3–4/dag (90 % kutt), og LaoZhangs caser som viser $943 → $347 (63 %), $1,750 → $1,000 (64 %), $200 → $70 (65 %) ved delvis optimalisering.
Bruke /model-kommandoen for å styre OpenClaw-tokenforbruket i farta
Kommandoen /model bytter aktiv modell for neste runde, samtidig som samtalekonteksten beholdes — ingen reset, ingen tapt historikk. Dette er vanen som bygger besparelser over tid.
Praktisk arbeidsflyt:
- Jobber du med en tøff refaktorering på flere filer? Hold deg på Sonnet.
- Et kjapt "hva gjør denne regexen?"-spørsmål?
/model haiku, spør, og bruk så/model sonnetfor å bytte tilbake. - Commit-melding eller litt dokumentpolering?
/model flash-lite, ferdig.
Du kan sette opp aliaser i openclaw.json under commands.aliases for å mappe korte navn (haiku, sonnet, opus, flash) til fulle leverandørstrenger. Det sparer noen tastetrykk hver gang du bytter.
Regnestykket: 50 forespørsler per dag på Sonnet er omtrent $3 per dag. De samme 50 forespørslene fordelt 70/20/10 mellom Haiku/Sonnet/Opus er rundt $1,10 per dag. Over en måned blir det $90 → $33 — 63 % billigere uten å endre verktøy, bare vaner.
Bonus: Spor modellpriser på tvers av leverandører med Thunderbit
Spor modellpriser på tvers av leverandører med AI Get Started Free
Med så mange modeller og leverandører — OpenRouter, direkte Anthropic API, Google AI Studio, DeepSeek, MiniMax — endrer prisene seg ofte. Anthropic kuttet Opus-utdata-prisen med rundt 67 % over natten. Google reduserte gratisnivå-grensene for Gemini 50–80 % i desember 2025. Å holde et statisk prisark oppdatert manuelt er en tapt kamp.
Thunderbit løser dette uten scraping-kode. Det er en AI-webscraper Chrome-utvidelse laget nettopp for denne typen strukturert datauthenting.
Arbeidsflyten jeg bruker:
- Åpne OpenRouter-modellsiden i Chrome og klikk "AI Suggest Fields" i Thunderbit. Den leser siden og foreslår kolonner — modellnavn, inputpris, outputpris, kontekstvindu, leverandør.
- Trykk Scrape, og eksporter direkte til Google Sheets.
- Sett opp planlagt scraping i vanlig norsk — "hver mandag kl. 09, skrap OpenRouter-modelllisten på nytt" — og den kjører automatisk i skyen.
Derfra oppdaterer prisoversikten din seg selv. Enhver modell som plutselig blir 30 % billigere — eller enhver leverandør som får en Exacto-tag — dukker opp i regnearket ditt mandag morgen uten at du løfter en finger. Vi har skrevet mer om AI datauttrekk for business på bloggen vår.
Sammenligner du priser på tvers av direkte leverandørsider (Anthropic, Google, DeepSeek)? Thunderbits subpage-scraping følger hver modell-lenke inn på detaljsiden og henter prisene per leverandør — nyttig når du vil vite om det er billigere å rute Kimi K2.5 via OpenRouter enn å gå direkte gjennom NVIDIA Build. Se Thunderbit-priser for gratisnivå og planinformasjon.
Viktige lærdommer for å kutte OpenClaw-tokenforbruket
Rammeverket er: Forstå → Overvåk → Ruter → Optimaliser.
Tiltakene med størst effekt, rangert:
- Ikke bruk Opus som standard. Bytt primærmodellen til Sonnet eller MiniMax M2.7. Bare dette gir 3–5x lavere kostnad.
- Isoler heartbeats. Sett
isolatedSession: trueog rute heartbeat til Gemini Flash-Lite. Da går du fra en lekkasje på ~100k tokens til ~2–5k. - Rute sub-agenter til Haiku. Hver opprettelse laster rundt ~20k tokens kontekst før noe arbeid er gjort. Ikke la det skje på Opus.
- Bruk
/clearkonsekvent. Gratis, tar 5 sekunder, og communityet mener dette sparer mer enn noe annet enkeltgrep. - Legg til
.clawignore. Å ekskluderenode_modules, lockfiler og build-artifacts kutter bootstrap-kontekst dramatisk. - Overvåk med
/context detailfør og etter endringer. Hvis du ikke kan måle det, kan du heller ikke forbedre det.
Den billigste modellen avhenger av oppgaven. Gemini Flash-Lite til heartbeats. MiniMax M2.7 til daglig koding. Haiku til pålitelig verktøykall. Sonnet til komplekst flertrinnsarbeid. Opus kun til de virkelig vanskeligste problemene — og ingenting annet.
De fleste lesere kan se 50–70 % besparelse i løpet av én ettermiddag med Config A eller B. Full 85–90 % krever at du setter sammen alt av dette — modellruting, fikser av skjulte lekkasjer, .clawignore, sesjonsdisiplin — men det er fullt mulig, og det varer.
Vanlige spørsmål
1. Hvor mye koster OpenClaw per måned?
Det avhenger helt av oppsettet ditt, bruksvolumet og modellvalgene. Lettere brukere (~10 søk/dag) bruker vanligvis $5–30/måned med optimalisering, eller $100+ med standardinnstillingene. Middels brukere (~50 søk/dag) ligger på $90–400/måned. Tunge brukere kan nå $600–2 000+/måned med standardoppsett — et dokumentert ekstremtilfelle var $5 623 på én måned. Anthropics egne interne målinger antyder en median på $13/utvikler/aktiv dag.
2. Hva er den billigste OpenClaw-modellen som fortsatt fungerer bra til koding?
MiniMax M2.5/M2.7 er den beste generelle daglige arbeidshesten — god på verktøykall, SWE-Pro 56.22, til omtrent $0.28/$1.10 per million tokens. For heartbeats og enkle oppslag er Gemini 2.5 Flash-Lite til $0.10/$0.40 vanskelig å slå. Claude Haiku 4.5 til $1/$5 er den pålitelige mellomklasse-fallbacken når du trenger utmerkede verktøykall uten å betale Sonnet-priser.
3. Kan jeg bruke gratisnivå-modeller med OpenClaw?
Teknisk sett ja. GPT-OSS-120B er gratis via OpenRouters :free-tag og NVIDIA Build. Gemini Flash-Lite har gratisnivå (15 RPM, 1 000 forespørsler/dag). DeepSeek gir 5 millioner gratis tokens ved registrering. Men gratisnivåer har stramme rate limits, lavere hastighet og mindre stabil tilgjengelighet. Billige betalte modeller — øre per million tokens — er langt mer pålitelige i vanlig bruk.
4. Mister jeg konteksten hvis jeg bytter modell midt i en samtale med /model?
Nei. /model bevarer hele sesjonskonteksten din — neste runde går til den nye modellen med full historikk intakt. Dette er bekreftet i OpenClaws dokumentasjon og fungerer på samme måte i Claude Code. Du kan fritt veksle mellom Haiku for raske spørsmål og Sonnet for komplekst arbeid uten å miste noe.
5. Hva er den raskeste måten å redusere OpenClaw-regningen min på i dag?
Skriv /clear mellom urelaterte oppgaver. Det er gratis, tar fem sekunder, og fjerner samtalehistorikken som sendes på nytt ved hvert API-kall. Én ekte sesjon viste 185 000 tokens i akkumulert meldingshistorikk — alt dette ble sendt på nytt og fakturert igjen i hver eneste runde. Å tømme dette før du starter nytt arbeid er vanen med høyest avkastning du kan bygge.
Prøv Thunderbit for AI-webscraping Get Started Free




