

Å optimalisere spørringer mot Apollo-lister er ikke bare en teknisk øvelse — det er en overlevelsesferdighet for alle som er avhengige av sanntidsnyheter, automatisert nyhetsinnhenting eller salgs- og driftsprosesser med høyt tempo. Jeg har selv sett hvordan en treg listespørring kan gjøre et elegant dashboard til en flaskehals, mens salgsteam sitter og ser på lastesymboler og driftsteam må finne nødløsninger i regneark. I en verden der 60 % av selgernes tid allerede går tapt til oppgaver som ikke selger, teller hvert millisekund.
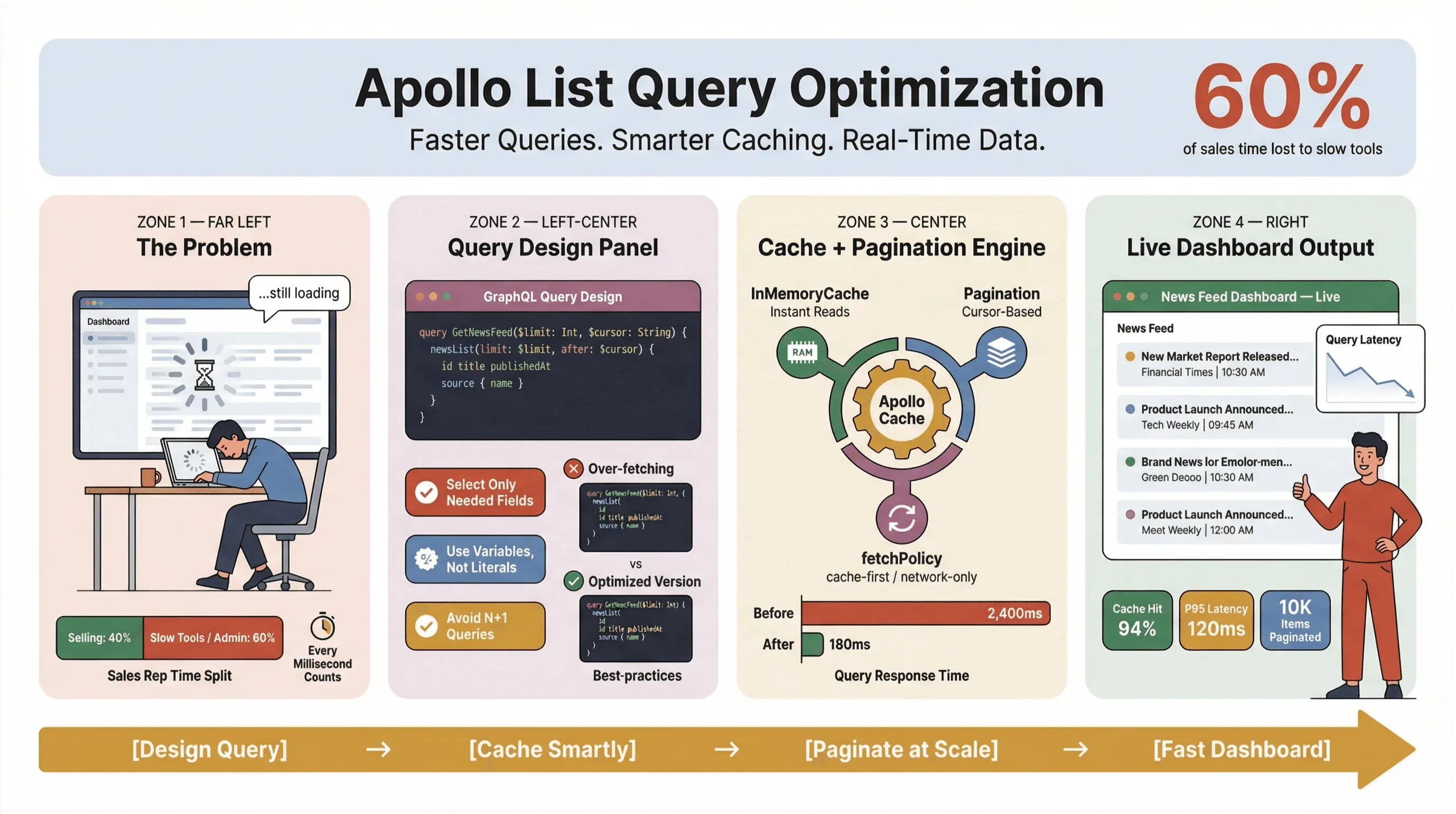
Så hvordan holder du Apollo Client-listeforespørsler raske, stabile og konsistente i stor skala — spesielt når du skraper nyheter, følger leads eller driver kritiske dashboards? I denne guiden går jeg gjennom metodene som faktisk fungerer i produksjon: spørringsdesign, caching, paginering og integrasjon med no-code-verktøy som Thunderbit for å automatisere det tunge arbeidet med nyhetsinnhenting.
--- Enten du er utvikler, produktleder eller bare personen alle peker på når dashboardet er tregt, er dette verktøykassa di for Apollo GraphQL-listeytelse.
Prøv Thunderbit for automatisert nyhetsinnhenting
Hvorfor optimalisere Apollo-listeforespørsler? (apollo client list performance, optimize apollo list queries)
La oss være ærlige: ingen vil vente på at nyhetsoverskrifter eller salgsleads skal laste inn. I forretningsmiljøer — særlig der man er avhengig av automatisert nyhetsinnhenting eller sanntidsdata — betyr trege Apollo-listeforespørsler mer enn bare irritasjon. De koster penger, forsinker beslutninger og sender folk tilbake til manuelt arbeid. Gjentatt forskning fra Slack Workforce Lab har konsekvent vist at kontoransatte bruker omtrent en tredel — og i nyere rapporter nærmere 40 % — av dagen sin på lavverdige, repetitive oppgaver, ofte fordi verktøyene deres splitter arbeidet opp på trege flater.
Dette skjer når listespørringer ikke er optimalisert:
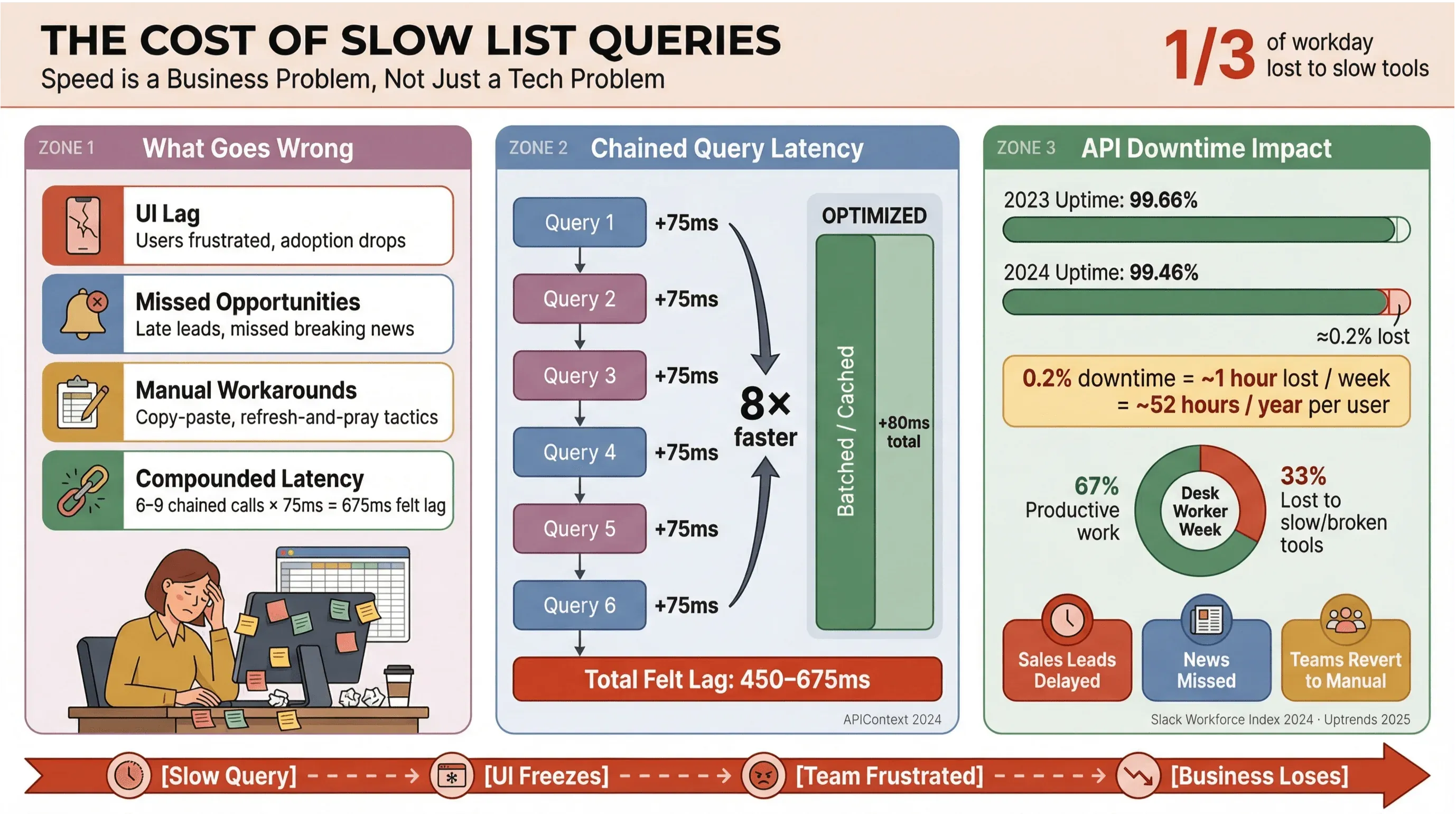
- Treg brukeropplevelse: Brukerne opplever forsinkelser, noe som skaper frustrasjon og lavere bruk.
- Tapte muligheter: I salg eller nyhetsovervåking kan bare noen sekunders forsinkelse bety at du går glipp av en het lead eller en viktig nyhet.
- Manuelle snarveier: Team går tilbake til kopi-og-lim, regneark eller «refresh og håp på det beste».
- Akkumulert forsinkelse: Hvert trege API-kall bygger seg opp — hvis arbeidsflyten din utløser 6–9 avhengige forespørsler, kan en moderat 75 ms forsinkelse per kall bli til en opplevd treghet på 450–675 ms (APIContext).
Og det handler ikke bare om fart. API-nedetid øker, og gjennomsnittlig oppetid falt fra 99,66 % til 99,46 % på bare ett år — noe som tilsvarer nesten en time tapt produktivitet i uken for apper med mye lister. Når virksomheten din er avhengig av sanntidsnyheter, er det en risiko du ikke har råd til.
Velg riktig datastruktur og riktige felter (apollo graphql list best practices)
En av de vanligste feilene jeg ser (og ja, jeg har gjort den selv) er å behandle hver listespørring som en detaljspørring. I GraphQL kan du hente akkurat det du trenger — så bruk den muligheten. Å hente for mye data er fienden til ytelse, særlig i verktøy for nyhetsskraping og sanntidsdashboards.
Tilpass feltene for automatisert nyhetsinnhenting
La oss si at du bygger en nyhetsfeed. Trenger du virkelig hele brødteksten, alle tagger, kommentarer og forfatterbio i listespørringen? Sannsynligvis ikke. Slik ser forskjellen ut:
Effektiv listespørring:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Lite effektiv listespørring (ikke gjør dette):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
Den første spørringen er slank og rask — perfekt for sortering, filtrering og visning av rader. Den andre? Den er i praksis en detaljspørring forkledd som en liste, og den drar med seg tunge payloads som bremser alt (GraphQL-specifikasjonen, Apollo best practices).
Profftips: Bruk en todelt modell — hent bare lette felter i listen, og last tunge detaljer (som fulltekst eller NLP-berikelse) først når brukeren åpner et element eller holder musepekeren over det.
Bruk Apollo Client-cache for raskere spørringer (apollo client list performance)
Apollo Client-cachen er den viktigste spaken du har for ytelse på listespørringer. Når den er satt opp riktig, kan den hjelpe deg med å:
- Svare umiddelbart på gjentatte spørringer (ingen nye nettverksrunder)
- Redusere belastning på serveren og API-kostnader
- Gi sømløs navigasjon fram/tilbake og raske filterendringer
Men caching er ikke magi — det krever litt oppsett og disiplin.
Sett effektive cache-policyer
Apollo støtter flere fetch policies:
| Policy | Hva den gjør | Beste bruk for nyhetslister |
|---|---|---|
| cache-first | Leser fra cache, henter fra nettverket hvis noe mangler | Når man går tilbake til lister, bytter filtre, navigerer fram/tilbake |
| network-only | Henter alltid fra nettverket | Manuell oppdatering, «siste overskrifter» |
| cache-and-network | Returnerer cache først, oppdaterer deretter med nettverksdata | Rask første visning + oppdatering i bakgrunnen (fint for nyhetsfeeder) |
| no-cache | Henter alltid, lagrer aldri i cache | Engangsspørringer med sensitivt innhold (sjeldent for lister) |
For sanntidsnyheter liker jeg cache-and-network — brukeren får resultater med en gang, og data oppdateres i bakgrunnen. Vær bare obs på eventuell «flicker» i grensesnittet hvis rekkefølgen på data endrer seg ved oppdatering (GitHub-issue).
Tips til cache-oppsett:
- Bruk stabile ID-er (
ideller_id) for normalisering (Apollo cache docs). - Juster cachestørrelse og garbage collection for store lister (memory management).
- Unngå å lagre enorme, ikke-normaliserte data under
ROOT_QUERY— det kan bremse appen (community report).
Implementer paginering og begrens antall elementer (apollo graphql list best practices)
Hvis du laster inn hundrevis eller tusenvis av nyhetsartikler eller leads på én gang, inviterer du til problemer. Paginering er ikke bare en UX-funksjon — det er en ytelsesnødvendighet.
Apollo støtter både offset-basert og cursor-basert paginering. Slik står de mot hverandre:
| Pagineringstype | Fordeler | Ulemper | Best egnet for |
|---|---|---|---|
| Offset-basert | Enkel, lett å implementere | Kan hoppe over/duplisere elementer hvis data endrer seg | Uforanderlige eller små lister |
| Cursor-basert | Stabil, håndterer datendringer godt | Litt mer kompleks | Nyhetsfeeder, store lister |
For de fleste sanntidsnyheter eller lead-lister er cursor-basert paginering det beste valget. Den holder dataene konsistente selv når nye elementer kommer inn eller gamle blir slettet (GraphQL Foundation).
Apollo-tips for paginering:
- Konfigurer
keyArgsfor å styre cache-nøkler for paginerte felter (docs). - Implementer en
merge-funksjon for å kombinere sider i cachen. - Bruk
fetchMorefor å laste flere sider uten å overskrive tidligere resultater.
Praktiske pagineringsmønstre for verktøy for nyhetsskraping
Et typisk UI for nyhetsskraping vil:
- Vise de 20–50 nyeste overskriftene (bare lette felter)
- Laste mer ved scroll eller ved klikk på «neste side»
- Hente detaljer kun når de trengs
Dette holder UI-et raskt, API-et fornøyd og brukerne produktive.
Integrer Thunderbit for automatisert nyhetsinnhenting
Nå til elefanten i rommet: hvor kommer all denne strukturerte nyhetsdataen egentlig fra? Det er her Thunderbit kommer inn.
Få Thunderbit Chrome-utvidelsen Get Started Free
Thunderbit er en no-code AI web scraper Chrome Extension som kan hente ut nyhetsoverskrifter, URL-er, kilder, forfattere, publiseringsdatoer, sammendrag og bilder fra nesten hvilken som helst nettside — uten at du trenger å kode. Jeg har sett team bruke Thunderbit til å automatisere hele prosessen med nyhetsinnhenting, og gjøre ustrukturert nettsideinnhold om til ryddige, strukturerte data som kan sendes rett inn i en database eller GraphQL API.
Kombiner Thunderbit med Apollo for sanntidsnyheter
Her er en arbeidsflyt jeg liker godt for salgs- og driftsteam som trenger oppdaterte nyheter:
- Innsamlingslag: Bruk Thunderbits News Scraper-mal til å hente strukturert nyhetsdata fra målområdene på en fast plan.
- Lagringslag: Lagre de skrapede dataene i en database optimalisert for rask uthenting.
- GraphQL-lag: Eksponer et
newsFeed-listefelt og etnewsArticle(id)-detaljfelt via API-et ditt. - Klientlag: Bruk Apollo Client til å hente listen (lette felter, paginert), og hent detaljer kun når det trengs.
Denne «skrap → lagre → spør»-kjeden gjør at Apollo-spørringene alltid jobber mot ferske, strukturerte data — uten manuell kopi-og-lim eller skjøre scripts.
Bonus: Thunderbit kan også berike listene dine med ekstra felter (som sentiment eller kategori) ved hjelp av AI-drevne feltforslag, slik at nyhetsfeeden blir enda smartere.
Steg-for-steg-guide: optimalisering av Apollo-listeforespørsler
Klar til å sette dette ut i livet? Her er min faste sjekkliste for optimalisering av Apollo-lister:
-
Slank ned spørringene dine
- Be bare om feltene som trengs for å vise listen (tittel, URL, tidsstempel osv.).
- Flytt tunge felter (fulltekst, bilder, berikelse) til detaljspørringer.
-
Implementer paginering
- Bruk cursor-basert paginering for store eller dynamiske lister.
- Konfigurer
keyArgsogmerge-funksjoner for korrekt cache-håndtering.
-
Bruk Apollo-cachen smart
- Normaliser entiteter med stabile ID-er.
- Velg riktig fetch-policy (
cache-and-networker veldig bra for nyheter). - Juster cachestørrelse og garbage collection etter datamengden.
-
Integrer automatisert innhenting
- Bruk Thunderbit til å automatisere nyhetsskraping og holde dataene ferske.
- Eksporter strukturerte data direkte til databasen eller et regneark.
-
Overvåk og feilsøk
- Bruk Apollo Client Devtools for å inspisere spørringer, cache og ytelse.
- Se etter store cache-skrivinger, for mange overvåkede spørringer og hakking i UI-et.
- Følg med på p95/p99-latens og feilrater (New Relic, Uptrends).
Overvåking og feilsøking av spørringsytelse
Apollo sine Devtools er gull verdt her. Du kan:
- Inspektere aktive spørringer og cache-tilstand
- Oppdage dupliserte spørringer eller for mange watchers
- Finne store cache-blokker eller problemer med normalisering
Hvis du ser treg UI eller forsinkede oppdateringer, se etter:
- For store listespørringer (slank dem ned)
- Dårlig cache-normalisering (fiks ID-ene dine)
- Problemer med paginerings-merge (gå gjennom
keyArgsogmerge)
Og ikke glem å måle hale-latens — ikke bare gjennomsnitt. Det er der den reelle frustrasjonen for brukeren ofte skjuler seg.
Sammenligning av tradisjonell og AI-drevet nyhetsskraping
La oss være ærlige: før i tiden betydde skraping av nyhetsdata at du måtte skrive egne scripts, håndtere headless-browsere og håpe at nettsidens layout ikke endret seg over natten. Nå, med AI-drevne verktøy som Thunderbit, kan du automatisere hele prosessen — uten kode, uten drama.
| Tilnærming | Styrker | Begrensninger for forretningsbrukere |
|---|---|---|
| Script-basert scraping | Fullt tilpassbar, billig i stor skala | Mye vedlikehold, krever utviklertid |
| Administrerte scraping-plattformer | Rask å komme i gang, håndterer anti-bot | Krever fortsatt oppsett, kostnader øker med bruk |
| AI-drevet innhenting (Thunderbit) | Takler rotete layouts, ingen kode nødvendig | Resultatet bør kvalitetssikres, integreres med skjemaet ditt |
| Visuelle no-code-scrapere | Tilgjengelig for ikke-utviklere | Kan knekke ved UI-endringer, begrenset skala |
| Proxy/unlocker-infrastruktur | Omgår sperrer, støtter høy throughput | Trenger fortsatt utvinningslogikk, risiko knyttet til etterlevelse |
Juridisk merknad: Skraping av offentlige data er som regel lovlig, men respekter alltid bruksvilkår og rate limits (Reuters).
Viktige læringspunkter for beste praksis med Apollo GraphQL-lister
La oss oppsummere det viktigste:
- Optimaliser for fart og tydelighet: Slank ned listespørringer, bruk paginering og cache aggressivt.
- Struktur er avgjørende: Hent bare det du trenger — legg tunge felter i detaljspørringer.
- Cache er din venn: Bruk Apollo-normalisering og fetch-policyer for å levere data umiddelbart.
- Automatiser innhenting: Verktøy som Thunderbit gjør nyhetsskraping og beriking av lister tilgjengelig for alle.
- Overvåk og forbedre: Bruk Devtools og observasjonsdashboards for å fange flaskehalser tidlig.
For salg, drift og nyhetsteam betyr disse beste praksisene mindre venting, mer handling — og langt færre Slack-meldinger à la «hvorfor er dette så tregt?».
Konklusjon: neste steg for å optimalisere Apollo-listeforespørslene dine
Hvis du fortsatt kjører tunge, upaginerte eller cache-uvillige listespørringer, er det på tide å rydde opp og oppgradere. Start i det små: kutt ned feltene, legg til paginering og finjuster cachen. Deretter kan du ta det videre ved å integrere automatiserte innhentingsverktøy som Thunderbit for å holde dataene ferske og handlingsorienterte.
Vil du gå dypere? Sjekk ut Apollo-dokumentasjonen, Thunderbit-bloggen, eller bli med i Apollo Community for praktiske tips og feilsøking. Og hvis du er klar til å automatisere nyhetsinnhentingen, prøv Thunderbits News Scraper-mal — det er en skikkelig gamechanger for alle som trenger sanntidsdata uten hodebry.
Bruk Thunderbit News Scraper-mal
Hvis du ikke gjør noe annet etter å ha lest dette: slank ned feltutvalget i listespørringene dine, legg til cursor-basert paginering og velg en fornuftig fetch-policy. Bare disse tre endringene tar ofte en listespørring fra «merkbart» treg til «knapt merkbar» — og frigjør deg til å fokusere på dataene, ikke lastestatusen.
Vanlige spørsmål
1. Hvorfor blir Apollo-listeforespørsler trege i sanntidsdashboards for nyheter eller salg?
Listespørringer kan bli trege hvis de henter for mye data, mangler paginering eller ikke er riktig cachestyrt. I arbeidsflyter med høy frekvens, som nyhetsovervåking, bygger selv små forsinkelser seg opp og gir treg UI og tapt produktivitet.
2. Hva er den beste måten å strukturere Apollo-listeforespørsler for automatisert nyhetsinnhenting?
Be bare om feltene som trengs for å vise listen (for eksempel tittel, URL og tidsstempel). Flytt tunge felter, som full artikkeltekst eller bilder, til detaljspørringer, og bruk paginering for å holde payloadene små og raske.
3. Hvordan forbedrer Apollo Client-cachen listeytelsen?
Apollo-cachen lagrer tidligere hentede data, slik at gjentatte spørringer kan besvares umiddelbart. Riktig normalisering og fetch-policyer, som cache-and-network, kan gjøre listevisninger mye raskere og redusere belastningen på serveren.
4. Hvordan kan Thunderbit hjelpe med nyhetsskraping og Apollo-integrasjon?
Thunderbit er en no-code AI web scraper som henter ut strukturert nyhetsdata fra nesten hvilken som helst nettside. Du kan bruke den til å automatisere nyhetsinnhenting og sende dataene videre til databasen eller GraphQL API-et ditt for bruk i Apollo Client.
5. Hvilke verktøy kan jeg bruke for å overvåke og feilsøke ytelsen til Apollo-listeforespørsler?
Apollo Client Devtools lar deg inspisere spørringer, cache-tilstand og ytelse i sanntid. Kombiner dette med observasjonsdashboards (som New Relic eller Uptrends) for å følge med på latens og feilrater, og forbedre spørringsdesignet ditt for best mulig resultat.
Vil du ha flere tips om web scraping, automatisering og sanntidsdataflyt? Sjekk ut Thunderbit-bloggen for dypdykk, guider og det nyeste innen AI-drevet produktivitet.
Prøv Thunderbit AI Web Scraper Get Started Free
Les mer
- Slik optimaliserer du Apollo-lister for mer effektiv lead-håndtering
- Apollo Data Enrichment: funksjoner, fordeler og AI-boost
- Slik mestrer du Apollo-prospektering: en steg-for-steg-guide
- Slik bruker du paginering i webscraping for effektiv innhenting
- Slik bruker du paginering i webscraping for effektiv innhenting




