

Hvilket programmeringsspråk bør du bruke til webskraping? Det kommer helt an på prosjektet ditt — og jeg har sett utviklere kaste inn håndkleet i ren 빡침 etter å ha valgt feil.
Markedet for webskrapingsprogramvare nådde 1,01 milliarder dollar i 2024 og forventes å mer enn dobles innen 2032. Velger du riktig språk, får du raskere leveranser og mye mindre vedlikehold. Velger du feil, ender du med scrapers som ryker, og helger som bare… forsvinner.
Jeg har bygget automatiseringsverktøy i mange år. Her er sju språk jeg selv har brukt til skraping — med kodeeksempler, ærlige avveininger, og når du faktisk bør droppe koding helt og bruke Thunderbit i stedet.
Slik valgte vi beste språk for webskraping
Når det gjelder webskraping, er ikke alle språk like godt skrudd sammen for jobben. Jeg har sett prosjekter både fly (대박) og gå rett i bakken, ofte på grunn av noen få helt avgjørende ting:
- Brukervennlighet: Hvor fort er du i gang? Er syntaksen lett å lese, eller må du nesten ta en doktorgrad bare for å skrive «Hello, World»?
- Bibliotekstøtte: Finnes det solide biblioteker for HTTP-forespørsler, HTML-parsing og håndtering av dynamisk innhold? Eller må du bygge alt fra scratch (직접 다)?
- Ytelse: Tåler det å skrape millioner av sider, eller stopper det etter noen hundre?
- Håndtering av dynamisk innhold: Moderne nettsteder elsker JavaScript. Klarer språket å henge med, eller blir det 버벅?
- Fellesskap og støtte: Når du møter veggen (og det gjør du), finnes det et miljø som kan hjelpe?
Basert på disse kriteriene — og en god del nattestesting (야근각) — er dette de sju språkene jeg går gjennom:
- Python: Førstevalget for både nybegynnere og erfarne.
- JavaScript & Node.js: Kongen av dynamisk innhold.
- Ruby: Ren syntaks, raske skript.
- PHP: Enkelt på serversiden.
- C++: Når du trenger rå ytelse.
- Java: Klar for enterprise og skalerbart.
- Go (Golang): Raskt og laget for samtidighet.
Og hvis du tenker: «Shuai, jeg vil ikke kode i det hele tatt», så vent til Thunderbit-delen mot slutten.
Python for webskraping: Kraftpakken som er lett å komme i gang med
Vi starter med publikumsfavoritten: Python. Spør du et rom fullt av datafolk «hva er beste programmeringsspråk for webskraping?», får du ofte Python tilbake som et refreng (거의 국룰).
Hvorfor Python?
- Nybegynnervennlig syntaks: Python-kode kan nesten leses høyt som vanlig språk.
- Enorm bibliotekstøtte: Fra BeautifulSoup for HTML-parsing, til Scrapy for storskala crawling, Requests for HTTP, og Selenium for nettleserautomatisering — Python har alt.
- Stort community: Over 33 000+ Stack Overflow-spørsmål om webskraping alene.
Eksempel i Python: Skrape sidetittel
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"Page title: {title}")
Styrker:
- Rask utvikling og prototyping.
- Massevis av guider og Q&A.
- Supert for dataanalyse — skrap med Python, analyser med pandas, visualiser med matplotlib.
Begrensninger:
- Tregere enn kompilerte språk ved virkelig store jobber.
- Veldig dynamiske nettsteder kan bli litt tungvint (selv om Selenium og Playwright hjelper).
- Ikke ideelt hvis du skal skrape millioner av sider i «lynfart» (초고속).
Konklusjon:
Er du ny i skraping, eller vil du bare få ting gjort raskt, er Python det beste språket for webskraping — punktum. Mer om hvorfor Python dominerer webskraping.
JavaScript & Node.js: Skrap dynamiske nettsteder uten stress
Hvis Python er en sveitsisk lommekniv, er JavaScript (og Node.js) en kraftdrill — spesielt når du skal skrape moderne nettsteder som er tunge på JavaScript (요즘 웹 국룰).
Hvorfor JavaScript/Node.js?
- Naturlig for dynamisk innhold: Det kjører i nettleseren, så det «ser» det brukeren ser — selv når siden er bygget med React, Angular eller Vue.
- Asynkront som standard: Node.js kan håndtere hundrevis av forespørsler samtidig.
- Kjent for webutviklere: Har du bygget nettsider, kan du allerede litt JavaScript.
Viktige biblioteker:
- Puppeteer: Automatisering av headless Chrome.
- Playwright: Automatisering på tvers av flere nettlesere.
- Cheerio: jQuery-lignende HTML-parsing for Node.
Eksempel i Node.js: Skrape sidetittel med Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`Page title: ${title}`);
await browser.close();
})();
Styrker:
- Håndterer JavaScript-renderet innhold «native».
- Perfekt for infinite scroll, pop-ups og interaktive sider.
- Effektivt for stor skala og parallell skraping.
Begrensninger:
- Asynkron programmering kan være krevende for nybegynnere.
- Headless-nettlesere bruker mye minne hvis du kjører mange samtidig.
- Færre verktøy for dataanalyse enn Python.
Når er JavaScript/Node.js beste språk for webskraping?
Når målsiden er dynamisk, eller du vil automatisere handlinger i nettleseren. Mer om Node.js for skraping av dynamisk innhold.
Ruby: Ren syntaks for raske skrapeskript
Ruby er ikke bare for Rails og elegant kodepoesi. Det er også et fint valg for webskraping — særlig hvis du liker at koden er lett å lese og føles litt “깔끔”.
Hvorfor Ruby?
- Lesbar og uttrykksfull syntaks: Du kan skrive en Ruby-scraper som nesten er like lett å lese som handlelista.
- Bra for prototyping: Rask å skrive, enkel å justere.
- Viktige biblioteker: Nokogiri for parsing, Mechanize for å automatisere navigasjon.
Eksempel i Ruby: Skrape sidetittel
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "Page title: #{title}"
Styrker:
- Veldig lesbart og konsist.
- Flott for små prosjekter, engangsskript, eller hvis du allerede bruker Ruby.
Begrensninger:
- Tregere enn Python eller Node.js ved store jobber.
- Færre skrapebiblioteker og mindre skrapefokusert community.
- Ikke ideelt for JavaScript-tunge sider (selv om Watir eller Selenium kan brukes).
Passer best:
Hvis du er Rubyist eller vil lage et raskt skript, er Ruby en fornøyelse. For massiv, dynamisk skraping: velg noe annet.
PHP: Enkel datauthenting på serversiden
PHP kan føles som et ekko fra webens barndom, men det lever fortsatt sterkt — spesielt hvis du vil skrape data direkte på serveren uten mye styr (그냥 서버에서 바로).
Hvorfor PHP?
- Kjører nesten overalt: De fleste webservere har allerede PHP.
- Enkelt å koble til webapper: Skrap og vis data på nettstedet ditt i samme løsning.
- Viktige biblioteker: cURL for HTTP, Guzzle for forespørsler, Symfony Panther for headless nettleserautomatisering.
Eksempel i PHP: Skrape sidetittel
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "Page title: $title\n";
?>
Styrker:
- Lett å rulle ut på webservere.
- Bra når skraping er del av en webflyt.
- Raskt for enkle, serverbaserte skrapeoppgaver.
Begrensninger:
- Begrenset bibliotekstøtte for avansert skraping.
- Ikke laget for høy samtidighet eller skraping i stor skala.
- JavaScript-tunge sider er krevende (selv om Panther hjelper).
Passer best:
Hvis stacken din allerede er PHP, eller du vil skrape og vise data på nettstedet ditt, er PHP et praktisk valg. Mer om PHP vs Python for skraping.
C++: Høyytelses webskraping for store prosjekter
C++ er muskelbilen blant programmeringsspråk. Trenger du maks fart og full kontroll — og tåler litt manuelt arbeid (손 많이 감) — kan C++ levere skikkelig.
Hvorfor C++?
- Ekstremt raskt: Slår de fleste språk på CPU-tunge oppgaver.
- Detaljkontroll: Du styrer minne, tråder og ytelsesoptimalisering.
- Viktige biblioteker: libcurl for HTTP, htmlcxx for parsing.
Eksempel i C++: Skrape sidetittel
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "Page title: " << title << std::endl;
} else {
std::cout << "Title tag not found" << std::endl;
}
return 0;
}
Styrker:
- Uslåelig hastighet for enorme skrapejobber.
- Bra når skraping skal inn i høyytelsessystemer.
Begrensninger:
- Bratt læringskurve (ta med kaffe, 진짜).
- Manuell minnehåndtering.
- Få høynivåbiblioteker; dårlig egnet for dynamisk innhold.
Passer best:
Når du må skrape millioner av sider, eller ytelse er helt kritisk. Ellers kan du fort bruke mer tid på feilsøking enn på skraping.
Java: Webskraping som tåler enterprise-krav
Java er arbeidshesten i enterprise-verdenen. Hvis du bygger noe som skal kjøre lenge, håndtere mye data og være stabilt i produksjon, er Java et trygt valg (안정감).
Hvorfor Java?
- Robust og skalerbart: Perfekt for store, langvarige skrapeprosjekter.
- Sterk typing og feilhåndtering: Færre overraskelser i produksjon.
- Viktige biblioteker: Jsoup for parsing, Selenium WebDriver for nettleserautomatisering, Apache HttpClient for HTTP.
Eksempel i Java: Skrape sidetittel
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("Page title: " + title);
}
}
Styrker:
- Høy ytelse og god støtte for samtidighet.
- Svært godt egnet for store, vedlikeholdbare kodebaser.
- Grei støtte for dynamisk innhold (via Selenium eller HtmlUnit).
Begrensninger:
- Omstendelig syntaks; mer oppsett enn skriptspråk.
- Overkill for små engangsjobber.
Passer best:
Skraping i enterprise-skala, eller når du trenger bunnsolid drift og skalerbarhet.
Go (Golang): Rask og parallell webskraping
Go er relativt nytt, men har allerede fått skikkelig fotfeste — spesielt når du vil ha høy hastighet og parallell skraping uten for mye drama (깔끔하게).
Hvorfor Go?
- Kompilert hastighet: Nesten på nivå med C++.
- Innebygd samtidighet: Goroutines gjør parallell skraping enkelt.
- Viktige biblioteker: Colly for skraping, Goquery for parsing.
Eksempel i Go: Skrape sidetittel
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Page title:", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("Error:", err)
}
}
Styrker:
- Svært raskt og ressursvennlig for skraping i stor skala.
- Enkelt å distribuere (én binærfil).
- Veldig bra for parallell crawling.
Begrensninger:
- Mindre community enn Python eller Node.js.
- Færre høynivåbiblioteker.
- JavaScript-tunge sider krever ekstra oppsett (Chromedp eller Selenium).
Passer best:
Når du må skrape i stor skala, eller Python ikke er raskt nok. Go vs Python for skraping: ytelsessammenligning.
Sammenligning av de beste programmeringsspråkene for webskraping
La oss samle trådene. Her er en side-ved-side-sammenligning som hjelper deg å velge beste språk for webskraping i 2026:
| Språk/verktøy | Brukervennlighet | Ytelse | Bibliotekstøtte | Håndtering av dynamisk innhold | Best egnet til |
|---|---|---|---|---|---|
| Python | Svært høy | Moderat | Utmerket | God (Selenium/Playwright) | Allround, nybegynnere, dataanalyse |
| JavaScript/Node.js | Middels | Høy | Sterk | Utmerket (native) | Dynamiske sider, asynkron skraping, webutviklere |
| Ruby | Høy | Moderat | Grei | Begrenset (Watir) | Raske skript, prototyping |
| PHP | Middels | Moderat | Ok | Begrenset (Panther) | Serverside, integrasjon i webapper |
| C++ | Lav | Svært høy | Begrenset | Svært begrenset | Ytelseskritisk, ekstrem skala |
| Java | Middels | Høy | God | God (Selenium/HtmlUnit) | Enterprise, langvarige tjenester |
| Go (Golang) | Middels | Svært høy | Voksende | Moderat (Chromedp) | Høy hastighet, parallell skraping |
Når du bør droppe koding: Thunderbit som no-code-løsning for webskraping
Prøv Thunderbit AI Web Scraper No-code, AI-drevet webskraping for forretningsbrukere, markedsførere og salgsteam. Get Started Free
La oss være ærlige: Noen ganger vil du bare ha dataene — uten koding, debugging eller «hvorfor fungerer ikke denne selector-en» (이거 왜 안 돼?).
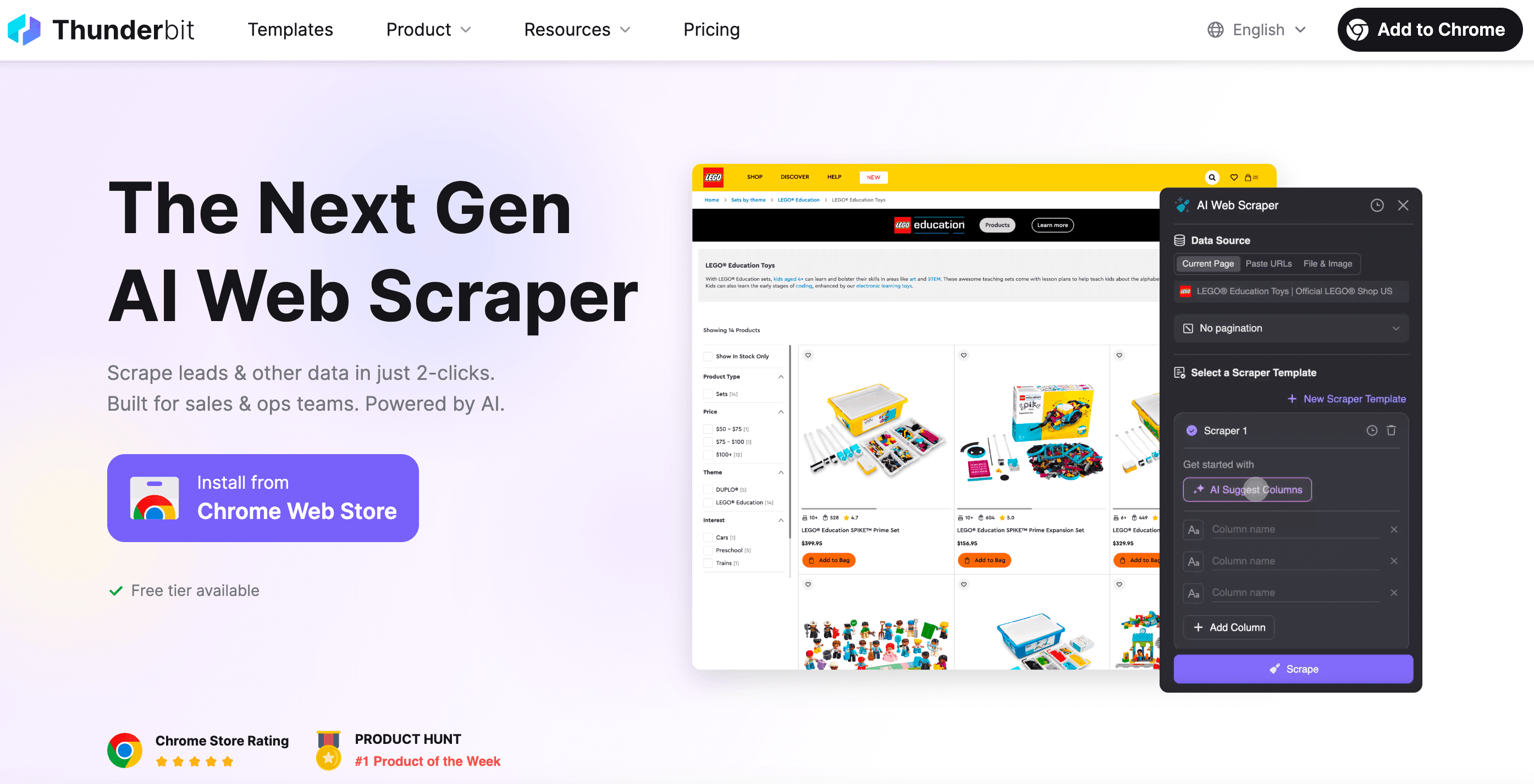
Som medgründer av Thunderbit ønsket jeg å lage et verktøy som gjør webskraping like enkelt som å bestille takeaway. Dette er det som skiller Thunderbit fra mengden:
- Oppsett på 2 klikk: Klikk «AI Suggest Fields» og «Scrape». Ingen styr med HTTP-forespørsler, proxyer eller anti-bot-triks.
- Smarte maler: Én scraper-mal kan tilpasse seg flere sidelayouts. Du slipper å skrive om alt hver gang et nettsted endrer seg.
- Skraping i nettleser og i skyen: Velg mellom skraping i nettleseren (perfekt for innloggede sider) eller i skyen (superraskt for offentlig data).
- Takler dynamisk innhold: Thunderbits AI styrer en ekte nettleser — så den håndterer infinite scroll, pop-ups, innlogginger og mer.
- Eksporter hvor du vil: Last ned til Excel, Google Sheets, Airtable, Notion — eller kopier rett til utklippstavlen.
- Ingen vedlikehold: Hvis et nettsted endrer seg, kjør AI-forslaget på nytt. Slutt på nattlige feilsøkingsøkter.
- Planlegging og automatisering: Kjør scrapers på tidsplan — uten cron jobs og uten serveroppsett.
- Spesialiserte uttrekkere: Trenger du e-poster, telefonnumre eller bilder? Thunderbit har ettklikks-uttak for dette også.
Og det beste? Du trenger ikke kunne én eneste kodelinje. Thunderbit er laget for forretningsbrukere, markedsførere, salgsteam, eiendomsfolk — alle som trenger data raskt.
Vil du se Thunderbit i praksis? Last ned Chrome-utvidelsen eller sjekk YouTube-kanalen vår for demoer.
Prøv Thunderbit AI Web Scraper gratis
Konklusjon: Slik velger du beste språk for webskraping i 2026
Hva er dataskraping – og hvordan gjør du det? Get Started Free
Webskraping i 2026 er mer tilgjengelig — og kraftigere — enn noen gang. Dette er det jeg har lært etter år i automatiseringsgrøfta (현장감 있게):
- Python er fortsatt beste språk for webskraping hvis du vil komme raskt i gang og ha masse ressurser tilgjengelig.
- JavaScript/Node.js er uslåelig for dynamiske, JavaScript-tunge nettsteder.
- Ruby og PHP er fine for raske skript og webintegrasjon, særlig hvis du allerede bruker dem.
- C++ og Go er gode valg når du trenger fart og skala.
- Java er ofte førstevalget for enterprise og langsiktige prosjekter.
- Og vil du droppe koding helt? Da er Thunderbit et skikkelig ess i ermet.
Før du setter i gang, spør deg selv:
- Hvor stort er prosjektet mitt?
- Må jeg håndtere dynamisk innhold?
- Hvor komfortabel er jeg teknisk?
- Vil jeg bygge selv — eller bare få dataene?
Test et av kodeeksemplene over, eller prøv Thunderbit i neste prosjekt. Og vil du dykke dypere, finner du flere guider, tips og historier fra virkeligheten på Thunderbit Blog.
Lykke til med skrapingen — og måtte dataene dine alltid være rene, strukturerte og bare et klikk unna.
P.S. Hvis du noen gang havner i et webskraping-kaninhull kl. 02:00, husk: Det finnes alltid Thunderbit. Eller kaffe. Eller begge deler.
Prøv Thunderbit AI Web Scraper nå Get Started Free
Vanlige spørsmål (FAQ)
1. Hva er beste programmeringsspråk for webskraping i 2026?
Python er fortsatt førstevalget takket være lesbar syntaks, sterke biblioteker (som BeautifulSoup, Scrapy og Selenium) og et stort community. Det passer både nybegynnere og erfarne, spesielt når du kombinerer skraping med dataanalyse.
2. Hvilket språk er best for å skrape JavaScript-tunge nettsteder?
JavaScript (Node.js) er toppvalget for dynamiske sider. Verktøy som Puppeteer og Playwright gir full kontroll over nettleseren, slik at du kan samhandle med innhold som lastes via React, Vue eller Angular.
3. Finnes det et no-code-alternativ for webskraping?
Ja — Thunderbit er en no-code AI Web Scraper som håndterer alt fra dynamisk innhold til planlagt kjøring. Klikk «AI Suggest Fields» og start skrapingen. Perfekt for salg, markedsføring eller driftsteam som trenger strukturert data raskt.
Les mer:




