Døde lenker. Foreldreløse sider. En «testside» fra 2019 som Google på et eller annet vis har klart å indeksere. Hvis du drifter et nettsted, kjenner du den følelsen altfor godt.
En god crawler plukker opp alt dette – og tegner opp hele nettstedet ditt, så du faktisk kan rydde skikkelig. Men det er lett å blande «web crawler» med «web scraper». Det er to forskjellige ting.
Jeg har testet 10 gratis crawlere på ekte nettsteder. Noen er helt rå til SEO-revisjoner. Andre er mer laget for datauthenting. Her er hva som faktisk funket – og hva som ikke gjorde det.
Hva er en nettstedcrawler? Grunnleggende forståelse
La oss ta det helt basic først: en nettstedcrawler er ikke det samme som en web scraper. Folk bruker ofte ordene om hverandre, men de gjør ulike jobber. Se for deg en crawler som nettstedets karttegner – den går gjennom hver krok, følger lenker og bygger et kart over alle sidene dine. Hovedjobben er oppdagelse: finne URL-er, forstå strukturen og registrere innhold. Det er sånn søkemotorer som Google jobber med botene sine, og sånn SEO-verktøy sjekker «helsa» til nettstedet ditt ().
En web scraper er mer som en data-gruvearbeider. Den bryr seg ikke om hele kartet – den vil hente ut «gullet»: produktpriser, firmanavn, anmeldelser, e-poster, you name it. Scrapere trekker ut konkrete felter fra sidene som crawleren finner ().
En enkel analogi:
- Crawler: Personen som går gjennom alle gangene i en dagligvarebutikk og lager en oversikt over alt som finnes.
- Scraper: Personen som går rett til kaffehylla og noterer prisen på alle økologiske varianter.
Hvorfor betyr dette noe? Fordi hvis du bare vil finne alle sidene på nettstedet ditt (for eksempel til en SEO-audit), trenger du en crawler. Hvis du vil hente ut alle produktprisene fra konkurrentens nettbutikk, trenger du en scraper – eller helst et verktøy som kan gjøre begge deler.
Hvorfor bruke en nettbasert web crawler? Viktige fordeler for bedriften
Hvorfor gidde å bruke en web crawler i det hele tatt? Fordi nettet ikke akkurat blir mindre. Faktisk bruker over for å optimalisere nettstedene sine, og enkelte SEO-verktøy crawler .
Dette kan crawlere hjelpe deg med:
- SEO-audits: Finn døde lenker, manglende titler, duplikatinnhold, foreldreløse sider og mer ().
- Lenkesjekk og QA: Oppdag 404-feil og redirect-looper før brukerne dine gjør det ().
- Generering av sitemap: Lag XML-sitemaps automatisk for søkemotorer og planlegging ().
- Innholdsoversikt: Bygg en komplett liste over sider, hierarki og metadata.
- Etterlevelse og tilgjengelighet: Sjekk alle sider for WCAG, SEO og juridisk etterlevelse ().
- Ytelse og sikkerhet: Marker trege sider, for store bilder eller sikkerhetsproblemer ().
- Data til AI og analyse: Bruk crawl-data i analyse- eller AI-verktøy ().
Her er en kjapp tabell som kobler bruksområder til roller:
| Bruksområde | Passer best for | Gevinst / resultat |
|---|---|---|
| SEO og nettsted-audit | Markedsføring, SEO, småbedriftseiere | Finn tekniske feil, forbedre struktur, løft rangeringer |
| Innholdsoversikt og QA | Innholdsansvarlige, webansvarlige | Revider eller migrer innhold, oppdag ødelagte lenker/bilder |
| Leadgenerering (scraping) | Salg, forretningsutvikling | Automatiser prospektering, fyll CRM med ferske leads |
| Konkurrentanalyse | E-handel, produktledere | Overvåk priser, nye produkter, lagerendringer |
| Sitemap og strukturkloning | Utviklere, DevOps, konsulenter | Kopier struktur for redesign eller backup |
| Innholdsaggregering | Forskere, media, analytikere | Samle data fra flere nettsteder for analyse eller trendovervåking |
| Markedsundersøkelser | Analytikere, AI-treningsteam | Samle store datasett til analyse eller trening av AI-modeller |
()
Slik valgte vi de beste gratis verktøyene for nettstedcrawling
Jeg har brukt mange sene kvelder (og mer kaffe enn jeg liker å innrømme) på å teste crawlere, lese dokumentasjon og kjøre prøvecrawl. Dette var kriteriene mine:
- Teknisk kapasitet: Takler den moderne nettsteder (JavaScript, innlogging, dynamisk innhold)?
- Brukervennlighet: Er den forståelig for ikke-tekniske brukere, eller krever den kommandolinje-magi?
- Begrensninger i gratisplanen: Er den faktisk gratis, eller bare en liten smakebit?
- Tilgjengelighet: Er det et skyverktøy, en desktop-app eller et kodebibliotek?
- Unike funksjoner: Gjør den noe ekstra – som AI-uthenting, visuelle sitemaps eller hendelsesdrevet crawling?
Jeg testet hvert verktøy, sjekket tilbakemeldinger fra brukere og sammenlignet funksjoner side om side. Hvis et verktøy fikk meg til å vurdere å kaste laptopen ut av vinduet, kom det ikke med på lista.
Rask sammenligning: 10 beste gratis nettstedcrawlere
| Verktøy og type | Kjernefunksjoner | Beste bruksområde | Tekniske krav | Detaljer om gratisplan |
|---|---|---|---|---|
| BrightData (Sky/API) | Enterprise-crawling, proxyer, JS-rendering, CAPTCHA-løsning | Datainnsamling i stor skala | Litt teknisk kompetanse er nyttig | Gratis prøve: 3 scrapere, 100 poster hver (ca. 300 poster totalt) |
| Crawlbase (Sky/API) | API-crawling, anti-bot, proxyer, JS-rendering | Utviklere som trenger backend-infrastruktur for crawling | API-integrasjon | Gratis: ca. 5 000 API-kall i 7 dager, deretter 1 000/mnd |
| ScraperAPI (Sky/API) | Proxy-rotasjon, JS-rendering, asynkron crawling, ferdige endepunkter | Utviklere, prisovervåking, SEO-data | Minimal oppsett | Gratis: 5 000 API-kall i 7 dager, deretter 1 000/mnd |
| Diffbot Crawlbot (Sky) | AI-crawl + uthenting, knowledge graph, JS-rendering | Strukturert data i stor skala, AI/ML | API-integrasjon | Gratis: 10 000 kreditter/mnd (ca. 10k sider) |
| Screaming Frog (Desktop) | SEO-audit, lenke/meta-analyse, sitemap, tilpasset uthenting | SEO-audits, nettstedansvarlige | Desktop-app, GUI | Gratis: 500 URL-er per crawl, kun kjernefunksjoner |
| SiteOne Crawler (Desktop) | SEO, ytelse, tilgjengelighet, sikkerhet, offline eksport, Markdown | Utviklere, QA, migrering, dokumentasjon | Desktop/CLI, GUI | Gratis og open source, 1 000 URL-er i GUI-rapport (kan justeres) |
| Crawljax (Java, OpenSrc) | Hendelsesdrevet crawling for JS-tunge sider, statisk eksport | Utviklere, QA for dynamiske webapper | Java, CLI/konfig | Gratis og open source, ingen grenser |
| Apache Nutch (Java, OpenSrc) | Distribuert, plugin-basert, Hadoop-integrasjon, tilpasset søk | Egen søkemotor, crawling i stor skala | Java, kommandolinje | Gratis og open source, kun infrastrukturkostnad |
| YaCy (Java, OpenSrc) | Peer-to-peer crawling og søk, personvern, indeksering av web/intranett | Privat søk, desentralisering | Java, nettleser-UI | Gratis og open source, ingen grenser |
| PowerMapper (Desktop/SaaS) | Visuelle sitemaps, tilgjengelighet, QA, nettleserkompatibilitet | Byråer, QA, visuell kartlegging | GUI, enkelt | Gratis prøve: 30 dager, 100 sider (desktop) eller 10 sider (online) per skann |
BrightData: Skybasert nettstedcrawler i enterprise-klassen

BrightData er «tungvekteren» innen web crawling. Det er en skyplattform med et massivt proxy-nettverk, JavaScript-rendering, CAPTCHA-løsning og en IDE for skreddersydde crawl-jobber. Hvis du driver datainnsamling i stor skala – for eksempel overvåker priser på hundrevis av nettbutikker – er infrastrukturen vanskelig å matche ().
Styrker:
- Takler krevende nettsteder med anti-bot
- Skalerer bra for enterprise-behov
- Ferdige maler for vanlige nettsteder
Begrensninger:
- Ingen permanent gratisnivå (kun prøve: 3 scrapere, 100 poster hver)
- Kan bli «overkill» for enkle audits
- Litt bratt læringskurve for ikke-tekniske brukere
Hvis du må crawle nettet i stor skala, er BrightData som å leie en Formel 1-bil. Bare ikke regn med at det er gratis etter prøveturen ().
Crawlbase: API-drevet gratis web crawler for utviklere

Crawlbase (tidligere ProxyCrawl) er laget for programmatisk crawling. Du kaller API-et deres med en URL, og får HTML tilbake – mens proxyer, geotargeting og CAPTCHAs håndteres i bakgrunnen ().
Styrker:
- Høy treffrate (99 %+)
- Takler JavaScript-tunge nettsteder
- Veldig bra for integrasjon i egne apper og arbeidsflyter
Begrensninger:
- Krever API/SDK-integrasjon
- Gratisplan: ca. 5 000 API-kall i 7 dager, deretter 1 000/mnd
Hvis du er utvikler og vil crawle (og kanskje scrape) i stor skala uten å drifte proxyer selv, er Crawlbase et trygt og solid valg ().
ScraperAPI: Gjør dynamisk web crawling enklere

ScraperAPI er «bare hent siden for meg»-API-et. Du sender inn en URL, og tjenesten fikser proxyer, headless nettlesere og anti-bot – og returnerer HTML (eller strukturert data for enkelte nettsteder). Den er spesielt nyttig for dynamiske sider og har en ganske romslig gratisordning ().
Styrker:
- Veldig enkelt for utviklere (ett API-kall)
- Håndterer CAPTCHAs, IP-blokkering og JavaScript
- Gratis: 5 000 API-kall i 7 dager, deretter 1 000/mnd
Begrensninger:
- Ingen visuelle crawl-rapporter
- Du må selv kode logikken for å følge lenker
Hvis du vil koble web crawling inn i kodebasen din på minutter, er ScraperAPI et veldig naturlig valg.
Diffbot Crawlbot: Automatisk oppdagelse av nettstedstruktur

Diffbot Crawlbot er der det begynner å bli «smart». Den crawler ikke bare – den bruker AI til å klassifisere sider og hente ut strukturert data (artikler, produkter, arrangementer osv.) som JSON. Litt som å ha en robot-intern som faktisk skjønner hva den leser ().
Styrker:
- AI-basert uthenting, ikke bare crawling
- Takler JavaScript og dynamisk innhold
- Gratis: 10 000 kreditter/mnd (ca. 10k sider)
Begrensninger:
- Mest for utviklere (API-integrasjon)
- Ikke et visuelt SEO-verktøy – mer for dataprosjekter
Hvis du trenger strukturert data i stor skala, særlig til AI eller analyse, er Diffbot skikkelig kraftig.
Screaming Frog: Gratis desktop-crawler for SEO

Screaming Frog er klassikeren for SEO-audits på desktop. Gratisversjonen crawler opptil 500 URL-er per skann og gir deg «alt»: døde lenker, metatagger, duplikatinnhold, sitemaps og mer ().
Styrker:
- Rask, grundig og veldig anerkjent i SEO-miljøet
- Ingen koding – lim inn URL og kjør
- Gratis opptil 500 URL-er per crawl
Begrensninger:
- Kun desktop (ingen skyversjon)
- Avanserte funksjoner (JS-rendering, planlegging) krever betalt lisens
Hvis du tar SEO seriøst, er Screaming Frog et must – bare ikke forvent gratis crawling av et nettsted med 10 000 sider.
SiteOne Crawler: Eksport av statisk nettsted og dokumentasjon

SiteOne Crawler er litt som en sveitsisk lommekniv for tekniske revisjoner. Den er open source, funker på flere plattformer og kan både crawle, auditere og eksportere nettstedet ditt til Markdown for dokumentasjon eller offline-bruk ().
Styrker:
- Dekker SEO, ytelse, tilgjengelighet og sikkerhet
- Eksporterer nettsteder for arkivering eller migrering
- Gratis og open source, uten bruksbegrensninger
Begrensninger:
- Mer teknisk enn enkelte rene GUI-verktøy
- GUI-rapporten er som standard begrenset til 1 000 URL-er (kan endres)
Hvis du er utvikler, jobber med QA eller er konsulent og vil ha dyp innsikt (og liker open source), er SiteOne en liten skjult perle.
Crawljax: Open source Java-crawler for dynamiske sider
Crawljax er en spesialist: den er laget for å crawle moderne, JavaScript-tunge webapper ved å simulere brukerhandlinger (klikk, skjemautfylling osv.). Den er hendelsesdrevet og kan til og med generere en statisk versjon av et dynamisk nettsted ().
Styrker:
- Suveren for SPA-er og AJAX-tunge nettsteder
- Open source og lett å utvide
- Ingen bruksgrenser
Begrensninger:
- Krever Java og en del programmering/konfigurasjon
- Ikke laget for ikke-tekniske brukere
Hvis du må crawle en React- eller Angular-app «som en ekte bruker», er Crawljax et godt valg.
Apache Nutch: Skalerbar, distribuert nettstedcrawler
.
En web scraper er mer som en data-gruvearbeider. Den bryr seg ikke om hele kartet – den vil hente ut «gullet»: produktpriser, firmanavn, anmeldelser, e-poster, you name it. Scrapere trekker ut konkrete felter fra sidene som crawleren finner ().
En enkel analogi:
- Crawler: Personen som går gjennom alle gangene i en dagligvarebutikk og lager en oversikt over alt som finnes.
- Scraper: Personen som går rett til kaffehylla og noterer prisen på alle økologiske varianter.
Hvorfor betyr dette noe? Fordi hvis du bare vil finne alle sidene på nettstedet ditt (for eksempel til en SEO-audit), trenger du en crawler. Hvis du vil hente ut alle produktprisene fra konkurrentens nettbutikk, trenger du en scraper – eller helst et verktøy som kan gjøre begge deler.
Hvorfor bruke en nettbasert web crawler? Viktige fordeler for bedriften
Hvorfor bruke en web crawler i det hele tatt? Fordi nettet ikke akkurat blir mindre. Faktisk bruker over for å optimalisere nettstedene sine, og enkelte SEO-verktøy crawler .
Dette kan crawlere hjelpe deg med:
- SEO-audits: Finn døde lenker, manglende titler, duplikatinnhold, foreldreløse sider og mer ().
- Lenkesjekk og QA: Oppdag 404-feil og redirect-looper før brukerne dine gjør det ().
- Generering av sitemap: Lag XML-sitemaps automatisk for søkemotorer og planlegging ().
- Innholdsoversikt: Bygg en komplett liste over sider, hierarki og metadata.
- Etterlevelse og tilgjengelighet: Sjekk alle sider for WCAG, SEO og juridisk etterlevelse ().
- Ytelse og sikkerhet: Flagge trege sider, for store bilder eller sikkerhetsproblemer ().
- Data til AI og analyse: Bruk crawl-data i analyse- eller AI-verktøy ().
Her er en kjapp tabell som kobler bruksområder til roller:
| Bruksområde | Passer best for | Gevinst / resultat |
|---|---|---|
| SEO og nettsted-audit | Markedsføring, SEO, småbedriftseiere | Finn tekniske feil, forbedre struktur, løft rangeringer |
| Innholdsoversikt og QA | Innholdsansvarlige, webansvarlige | Revider eller migrer innhold, oppdag ødelagte lenker/bilder |
| Leadgenerering (scraping) | Salg, forretningsutvikling | Automatiser prospektering, fyll CRM med ferske leads |
| Konkurrentanalyse | E-handel, produktledere | Overvåk priser, nye produkter, lagerendringer |
| Sitemap og strukturkloning | Utviklere, DevOps, konsulenter | Kopier struktur for redesign eller backup |
| Innholdsaggregering | Forskere, media, analytikere | Samle data fra flere nettsteder for analyse eller trendovervåking |
| Markedsundersøkelser | Analytikere, AI-treningsteam | Samle store datasett til analyse eller trening av AI-modeller |
()
Slik valgte vi de beste gratis verktøyene for nettstedcrawling
Jeg har brukt mange sene kvelder (og mer kaffe enn jeg liker å innrømme) på å teste crawlere, lese dokumentasjon og kjøre prøvecrawl. Dette var kriteriene mine:
- Teknisk kapasitet: Takler den moderne nettsteder (JavaScript, innlogging, dynamisk innhold)?
- Brukervennlighet: Er den forståelig for ikke-tekniske brukere, eller krever den kommandolinje-magi?
- Begrensninger i gratisplanen: Er den faktisk gratis, eller bare en liten smakebit?
- Tilgjengelighet: Er det et skyverktøy, en desktop-app eller et kodebibliotek?
- Unike funksjoner: Gjør den noe ekstra – som AI-uthenting, visuelle sitemaps eller hendelsesdrevet crawling?
Jeg testet hvert verktøy, sjekket tilbakemeldinger fra brukere og sammenlignet funksjoner side om side. Hvis et verktøy fikk meg til å vurdere å kaste laptopen ut av vinduet, kom det ikke med på lista.
Rask sammenligning: 10 beste gratis nettstedcrawlere
| Verktøy og type | Kjernefunksjoner | Beste bruksområde | Tekniske krav | Detaljer om gratisplan |
|---|---|---|---|---|
| BrightData (Sky/API) | Enterprise-crawling, proxyer, JS-rendering, CAPTCHA-løsning | Datainnsamling i stor skala | Litt teknisk kompetanse er nyttig | Gratis prøve: 3 scrapere, 100 poster hver (ca. 300 poster totalt) |
| Crawlbase (Sky/API) | API-crawling, anti-bot, proxyer, JS-rendering | Utviklere som trenger backend-infrastruktur for crawling | API-integrasjon | Gratis: ca. 5 000 API-kall i 7 dager, deretter 1 000/mnd |
| ScraperAPI (Sky/API) | Proxy-rotasjon, JS-rendering, asynkron crawling, ferdige endepunkter | Utviklere, prisovervåking, SEO-data | Minimal oppsett | Gratis: 5 000 API-kall i 7 dager, deretter 1 000/mnd |
| Diffbot Crawlbot (Sky) | AI-crawl + uthenting, knowledge graph, JS-rendering | Strukturert data i stor skala, AI/ML | API-integrasjon | Gratis: 10 000 kreditter/mnd (ca. 10k sider) |
| Screaming Frog (Desktop) | SEO-audit, lenke/meta-analyse, sitemap, tilpasset uthenting | SEO-audits, nettstedansvarlige | Desktop-app, GUI | Gratis: 500 URL-er per crawl, kun kjernefunksjoner |
| SiteOne Crawler (Desktop) | SEO, ytelse, tilgjengelighet, sikkerhet, offline eksport, Markdown | Utviklere, QA, migrering, dokumentasjon | Desktop/CLI, GUI | Gratis og open source, 1 000 URL-er i GUI-rapport (kan justeres) |
| Crawljax (Java, OpenSrc) | Hendelsesdrevet crawling for JS-tunge sider, statisk eksport | Utviklere, QA for dynamiske webapper | Java, CLI/konfig | Gratis og open source, ingen grenser |
| Apache Nutch (Java, OpenSrc) | Distribuert, plugin-basert, Hadoop-integrasjon, tilpasset søk | Egen søkemotor, crawling i stor skala | Java, kommandolinje | Gratis og open source, kun infrastrukturkostnad |
| YaCy (Java, OpenSrc) | Peer-to-peer crawling og søk, personvern, indeksering av web/intranett | Privat søk, desentralisering | Java, nettleser-UI | Gratis og open source, ingen grenser |
| PowerMapper (Desktop/SaaS) | Visuelle sitemaps, tilgjengelighet, QA, nettleserkompatibilitet | Byråer, QA, visuell kartlegging | GUI, enkelt | Gratis prøve: 30 dager, 100 sider (desktop) eller 10 sider (online) per skann |
BrightData: Skybasert nettstedcrawler i enterprise-klassen
BrightData er «tungvekteren» innen web crawling. Det er en skyplattform med et massivt proxy-nettverk, JavaScript-rendering, CAPTCHA-løsning og en IDE for skreddersydde crawl-jobber. Hvis du driver datainnsamling i stor skala – for eksempel prisovervåking på hundrevis av nettbutikker – er infrastrukturen vanskelig å matche ().
Styrker:
- Takler krevende nettsteder med anti-bot
- Skalerer bra for enterprise-behov
- Ferdige maler for vanlige nettsteder
Begrensninger:
- Ingen permanent gratisnivå (kun prøve: 3 scrapere, 100 poster hver)
- Kan bli «overkill» for enkle audits
- Litt bratt læringskurve for ikke-tekniske brukere
Hvis du må crawle nettet i stor skala, er BrightData som å leie en Formel 1-bil. Bare ikke regn med at det er gratis etter prøveturen ().
Crawlbase: API-drevet gratis web crawler for utviklere
Crawlbase (tidligere ProxyCrawl) handler om programmatisk crawling. Du kaller API-et deres med en URL, og får HTML tilbake – mens proxyer, geotargeting og CAPTCHAs håndteres i bakgrunnen ().
Styrker:
- Høy treffrate (99 %+)
- Takler JavaScript-tunge nettsteder
- Veldig bra for integrasjon i egne apper og arbeidsflyter
Begrensninger:
- Krever API/SDK-integrasjon
- Gratisplan: ca. 5 000 API-kall i 7 dager, deretter 1 000/mnd
Hvis du er utvikler og vil crawle (og kanskje scrape) i stor skala uten å drifte proxyer selv, er Crawlbase et solid valg ().
ScraperAPI: Gjør dynamisk web crawling enklere
ScraperAPI er «bare hent siden for meg»-API-et. Du sender inn en URL, og tjenesten fikser proxyer, headless nettlesere og anti-bot – og returnerer HTML (eller strukturert data for enkelte nettsteder). Den er spesielt nyttig for dynamiske sider og har en ganske romslig gratisordning ().
Styrker:
- Veldig enkelt for utviklere (ett API-kall)
- Håndterer CAPTCHAs, IP-blokkering og JavaScript
- Gratis: 5 000 API-kall i 7 dager, deretter 1 000/mnd
Begrensninger:
- Ingen visuelle crawl-rapporter
- Du må selv kode logikken for å følge lenker
Hvis du vil koble web crawling inn i kodebasen din på minutter, er ScraperAPI et opplagt valg.
Diffbot Crawlbot: Automatisk oppdagelse av nettstedstruktur
Diffbot Crawlbot er der det blir «smart». Den crawler ikke bare – den bruker AI til å klassifisere sider og hente ut strukturert data (artikler, produkter, arrangementer osv.) som JSON. Litt som å ha en robot-intern som faktisk skjønner hva den leser ().
Styrker:
- AI-basert uthenting, ikke bare crawling
- Takler JavaScript og dynamisk innhold
- Gratis: 10 000 kreditter/mnd (ca. 10k sider)
Begrensninger:
- Mest for utviklere (API-integrasjon)
- Ikke et visuelt SEO-verktøy – mer for dataprosjekter
Hvis du trenger strukturert data i stor skala, særlig til AI eller analyse, er Diffbot skikkelig kraftig.
Screaming Frog: Gratis desktop-crawler for SEO
Screaming Frog er klassikeren for SEO-audits på desktop. Gratisversjonen crawler opptil 500 URL-er per skann og gir deg «alt»: døde lenker, metatagger, duplikatinnhold, sitemaps og mer ().
Styrker:
- Rask, grundig og veldig anerkjent i SEO-miljøet
- Ingen koding – lim inn URL og kjør
- Gratis opptil 500 URL-er per crawl
Begrensninger:
- Kun desktop (ingen skyversjon)
- Avanserte funksjoner (JS-rendering, planlegging) krever betalt lisens
Hvis du tar SEO seriøst, er Screaming Frog et must – bare ikke forvent gratis crawling av et nettsted med 10 000 sider.
SiteOne Crawler: Eksport av statisk nettsted og dokumentasjon
SiteOne Crawler er litt som en sveitsisk lommekniv for tekniske revisjoner. Den er open source, funker på flere plattformer og kan både crawle, auditere og eksportere nettstedet ditt til Markdown for dokumentasjon eller offline-bruk ().
Styrker:
- Dekker SEO, ytelse, tilgjengelighet og sikkerhet
- Eksporterer nettsteder for arkivering eller migrering
- Gratis og open source, uten bruksbegrensninger
Begrensninger:
- Mer teknisk enn enkelte rene GUI-verktøy
- GUI-rapporten er som standard begrenset til 1 000 URL-er (kan endres)
Hvis du er utvikler, jobber med QA eller er konsulent og vil ha dyp innsikt (og liker open source), er SiteOne en liten skjult perle.
Crawljax: Open source Java-crawler for dynamiske sider
Crawljax er en spesialist: den er laget for å crawle moderne, JavaScript-tunge webapper ved å simulere brukerhandlinger (klikk, skjemautfylling osv.). Den er hendelsesdrevet og kan til og med generere en statisk versjon av et dynamisk nettsted ().
Styrker:
- Suveren for SPA-er og AJAX-tunge nettsteder
- Open source og lett å utvide
- Ingen bruksgrenser
Begrensninger:
- Krever Java og en del programmering/konfigurasjon
- Ikke laget for ikke-tekniske brukere
Hvis du må crawle en React- eller Angular-app «som en ekte bruker», er Crawljax et godt valg.
Apache Nutch: Skalerbar, distribuert nettstedcrawler

Apache Nutch er «bestefaren» blant open source-crawlere. Den er laget for enorme, distribuerte crawl-jobber – typisk hvis du vil bygge din egen søkemotor eller indeksere millioner av sider ().
Styrker:
- Skalerer til milliarder av sider med Hadoop
- Veldig konfigurerbar og utvidbar
- Gratis og open source
Begrensninger:
- Bratt læringskurve (Java, kommandolinje, konfig)
- Lite egnet for små nettsteder eller «casual» bruk
Hvis du vil crawle nettet i stor skala og ikke er redd for kommandolinjen, er Nutch verktøyet.
YaCy: Peer-to-peer web crawler og søkemotor
YaCy er en litt annerledes, desentralisert crawler og søkemotor. Hver instans crawler og indekserer nettsteder, og du kan bli med i et peer-to-peer-nettverk for å dele indekser med andre ().
Styrker:
- Personvernfokusert, ingen sentral server
- Bra for privat søk eller intranett-søk
- Gratis og open source
Begrensninger:
- Resultatene avhenger av hvor godt nettverket dekker
- Krever litt oppsett (Java, nettleser-UI)
Hvis du liker desentralisering eller vil ha din egen søkemotor, er YaCy et spennende alternativ.
PowerMapper: Visuell sitemap-generator for UX og QA

PowerMapper handler om å gjøre nettstedstrukturen synlig. Den crawler nettstedet ditt og lager interaktive sitemaps, samtidig som den sjekker tilgjengelighet, nettleserkompatibilitet og grunnleggende SEO ().
Styrker:
- Visuelle sitemaps er gull for byråer og designere
- Sjekker tilgjengelighet og etterlevelse
- Enkel GUI – ingen tekniske ferdigheter nødvendig
Begrensninger:
- Kun gratis prøve (30 dager, 100 sider desktop / 10 sider online per skann)
- Fullversjonen er betalt
Hvis du må presentere et nettstedkart for kunder eller sjekke compliance, er PowerMapper et praktisk verktøy.
Slik velger du riktig gratis web crawler
Med så mange alternativer – hvordan velger du? Her er min kjappe guide:
- Til SEO-audits: Screaming Frog (små nettsteder), PowerMapper (visuelt), SiteOne (dyptgående audits)
- Til dynamiske webapper: Crawljax
- Til stor skala eller eget søk: Apache Nutch, YaCy
- Til utviklere som trenger API: Crawlbase, ScraperAPI, Diffbot
- Til dokumentasjon eller arkivering: SiteOne Crawler
- Til enterprise-skala med prøveperiode: BrightData, Diffbot
Viktige faktorer å vurdere:
- Skalerbarhet: Hvor stort er nettstedet eller crawl-jobben?
- Brukervennlighet: Er du komfortabel med kode, eller vil du ha «pek og klikk»?
- Eksport: Trenger du CSV, JSON eller integrasjon med andre verktøy?
- Support: Finnes det community eller hjelpedokumentasjon når du står fast?
Når web crawling møter web scraping: Hvorfor Thunderbit er et smartere valg
Realiteten er at de færreste crawler nettsteder bare for å lage pene kart. Målet er som regel å ende opp med strukturert data – enten det er produktlister, kontaktinfo eller en innholdsoversikt. Det er her kommer inn.
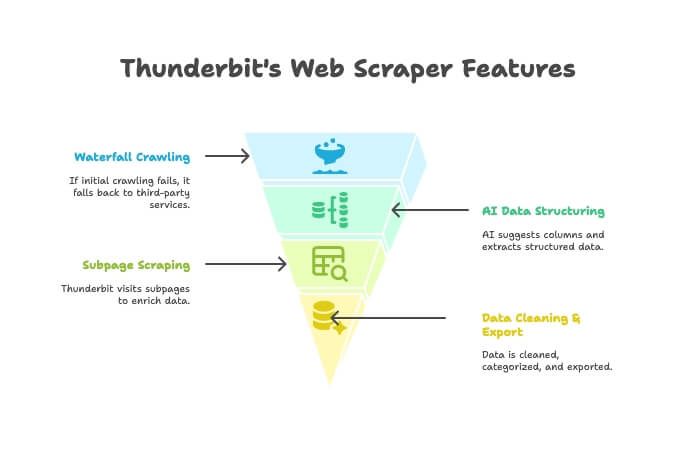
Thunderbit er ikke bare en crawler eller en scraper – det er en AI-drevet Chrome-utvidelse som kombinerer begge. Slik funker det:
- AI Crawler: Thunderbit utforsker nettstedet, akkurat som en crawler.
- Waterfall Crawling: Hvis Thunderbits egen motor ikke får tak i siden (for eksempel på grunn av tøffe anti-bot-tiltak), faller den automatisk tilbake på tredjeparts crawling-tjenester – uten at du må sette opp noe manuelt.
- AI-strukturering av data: Når HTML-en er hentet, foreslår Thunderbits AI riktige kolonner og trekker ut strukturert data (navn, priser, e-poster osv.) uten at du skriver en eneste selector.
- Scraping av undersider: Trenger du detaljer fra hver produktside? Thunderbit kan automatisk besøke hver underside og berike tabellen din.
- Rensing og eksport: Den kan oppsummere, kategorisere, oversette og eksportere til Excel, Google Sheets, Airtable eller Notion med ett klikk.
- No-code og enkelt: Kan du bruke en nettleser, kan du bruke Thunderbit. Ingen koding, ingen proxyer, ingen hodepine.
Når bør du velge Thunderbit fremfor en tradisjonell crawler?
- Når sluttmålet er et ryddig, brukbart regneark – ikke bare en URL-liste.
- Når du vil automatisere hele løpet (crawl, hent ut, rydd, eksporter) i ett verktøy.
- Når du setter pris på tid (og nattesøvn).
Du kan og se selv hvorfor så mange business-brukere bytter.
Konklusjon: Slik får du mest ut av gratis nettstedcrawlere
Nettstedcrawlere har tatt store steg. Enten du er markedsfører, utvikler eller bare vil holde nettstedet ditt i god form, finnes det et gratis (eller i det minste gratis å prøve) verktøy som passer. Fra enterprise-plattformer som BrightData og Diffbot, til open source-favoritter som SiteOne og Crawljax, til visuelle kartleggere som PowerMapper – utvalget er mer variert enn noen gang.
Men hvis du vil ha en smartere og mer helhetlig vei fra «jeg trenger disse dataene» til «her er regnearket mitt», er det verdt å teste Thunderbit. Det er laget for business-brukere som vil ha resultater – ikke bare rapporter.
Klar til å starte? Last ned et verktøy, kjør en skann og se hva du har gått glipp av. Og hvis du vil gå fra crawling til data du faktisk kan bruke på to klikk, .
For flere dypdykk og praktiske guider, besøk .
FAQ
Hva er forskjellen på en nettstedcrawler og en web scraper?
En crawler oppdager og kartlegger alle sidene på et nettsted (tenk: lager en innholdsfortegnelse). En scraper henter ut konkrete datafelter (som priser, e-poster eller anmeldelser) fra disse sidene. Crawlere finner – scrapere henter ut ().
Hvilken gratis web crawler er best for ikke-tekniske brukere?
For små nettsteder og SEO-audits er Screaming Frog ganske lett å bruke. For visuell kartlegging er PowerMapper bra (i prøveperioden). Thunderbit er enklest hvis målet ditt er strukturert data og du vil ha en no-code opplevelse direkte i nettleseren.
Finnes det nettsteder som blokkerer web crawlere?
Ja – noen nettsteder bruker robots.txt eller anti-bot-tiltak (som CAPTCHAs eller IP-blokkering) for å stoppe crawling. Verktøy som ScraperAPI, Crawlbase og Thunderbit (med waterfall crawling) kan ofte komme forbi dette, men crawl alltid ansvarlig og respekter nettstedets regler ().
Har gratis nettstedcrawlere begrensninger på sider eller funksjoner?
Som regel, ja. For eksempel er Screaming Frog gratisversjon begrenset til 500 URL-er per crawl, og PowerMapper-prøven til 100 sider. API-baserte verktøy har ofte månedlige kredittgrenser. Open source-verktøy som SiteOne eller Crawljax har vanligvis ingen harde grenser, men du begrenses av maskinvaren din.
Er det lovlig og personvernmessig greit å bruke en web crawler?
Som hovedregel er det lovlig å crawle offentlige nettsider, men sjekk alltid vilkår og robots.txt. Ikke crawl privat eller passordbeskyttet innhold uten tillatelse, og vær obs på personvernlovgivning hvis du henter ut personopplysninger ().