I 2015 betydde scraping som regel at du måtte mase på en utvikler om et Python-skript – eller ofre en hel helg på å lære XPath. I 2026 holder det å skrive «hent alle produktnavn og priser», så fikser en AI resten.
Den overgangen gikk fort. Over er nå avhengige av web scraping. Markedet passerte og ser ut til å dobles innen 2030.
Den største motoren bak dette? AI-nettrobotene. De tåler at nettsider endrer layout. De skjønner hva som faktisk står på siden – ikke bare HTML-tagger. Og de funker for folk som aldri har skrevet en eneste kodelinje.
Jeg har brukt måneder på å teste 15 ulike. Her er det jeg fant – inkludert hvorfor Thunderbit (ja, selskapet jeg var med å starte) endte øverst.
Hvorfor AI endrer web scraping: En ny æra for Web Scraper-verktøy
La oss si det som det er: tradisjonell web scraping var aldri laget for vanlige folk i business. Det var kode, selektorer og den evige frykten for at alt skulle ryke neste gang en nettside justerte designet sitt. Men AI og LLM-er har snudd hele greia på hodet.
Slik:
- Instruksjoner i naturlig språk: I stedet for å styre med kode, sier du bare til AI-en hva du vil ha. Verktøy som tolker instruksjonene dine i vanlig språk og setter opp uthentingen for deg ().
- Tilpasningsdyktig læring: AI-scrapere kan på nettsider, som betyr mindre vedlikehold.
- Håndtering av dynamisk innhold: Moderne nettsteder elsker JavaScript og uendelig scrolling. AI-drevne verktøy kan samhandle med disse elementene og fange data som «gamle» scrapere ofte går glipp av.
- Strukturert output med AI-tolkning: LLM-baserte scrapere og leverer ryddige, strukturerte datasett.
- Automatisk omgåelse av anti-bot: AI-scrapere kan og bruke proxyer/headless-browsere for å unngå IP-blokkering.
- Integrerte dataflyter: De beste verktøyene henter ikke bare data – de leverer dem dit du trenger dem, med ett klikk til Google Sheets, Airtable, Notion og mer ().
Resultatet? Web scraping har blitt en pek-og-klikk-opplevelse (eller nesten som å chatte), så salg, markedsføring og drift – ikke bare utviklere – kan bruke webdata direkte.
15 AI-nettroboter verdt å følge med på i 2026
La oss gå gjennom de 15 beste AI-nettrobotene, med Thunderbit først. Jeg oppsummerer kjernefunksjoner, hvem de passer for, pris og hva som gjør dem spesielle. Og ja – jeg er ærlig om hvor hver enkelt virkelig leverer (og hvor den kan falle litt gjennom).
1. Thunderbit: AI Web Scraper for alle
Jeg er selvsagt litt inhabil her, men Thunderbit er AI Web Scraper-verktøyet jeg skulle ønske jeg hadde for flere år siden. Derfor er det #1 på lista:
- Uthenting med naturlig språk: Du «chatter» med Thunderbit. Beskriv dataene du vil ha – «scrape alle produktnavn og priser fra denne siden» – og AI-en gjør resten (). Ingen kode, ingen selektorer, ingen hodepine.
- Undersider og flernivå-crawling: Thunderbit kan . For eksempel: hent en produktliste, gå inn på hvert produkt og hent detaljer – i én og samme kjøring.
- Strukturert output umiddelbart: AI-en , foreslår relevante felter, normaliserer formater og kan til og med oppsummere eller kategorisere tekst.
- Støtte for mange kilder: Thunderbit er ikke bare for HTML – den kan også hente fra PDF-er og bilder med innebygd OCR og vision-AI ().
- Integrasjoner for business: Eksporter med ett klikk til Google Sheets, Airtable, Notion eller Excel (). Planlegg scraping og send data rett inn i teamets arbeidsflyt.
- Ferdige maler: For nettsteder som Amazon, LinkedIn, Zillow osv. tilbyr Thunderbit for uthenting med ett klikk.
- Brukervennlig og tilgjengelig: Grensesnittet er pek-og-klikk med en intuitiv assistent. Mange er i gang på få minutter.

Thunderbit brukes av , inkludert team hos Accenture, Grammarly og Puma. Salgsteam bruker det til å , meglere samler boligannonser, og markedsførere følger konkurrenter – uten å skrive en eneste linje kode.
Pris: Det finnes et (scrape opptil 100 steg/måned), og betalte planer starter på $14,99/måned. Selv pro-planene er overkommelige for enkeltpersoner og små team.
Thunderbit er det nærmeste jeg har sett «å gjøre weben om til en database» – og den er laget for alle, ikke bare ingeniører.
2. Crawl4AI
Hvem passer det for: Utviklere og tekniske team som bygger egne pipelines.
Crawl4AI er et open source-rammeverk i Python, optimalisert for fart og storskala crawling, med . Det er skikkelig raskt, støtter headless-browsere for dynamisk innhold og kan strukturere data så det er lett å mate inn i AI-arbeidsflyter.
- Best for: Utviklere som trenger en kraftig og tilpasningsbar crawling-motor.
- Pris: Gratis (MIT-lisens). Du må hoste og kjøre det selv.
3. ScrapeGraphAI
Hvem passer det for: Utviklere og analytikere som bygger AI-agenter eller komplekse datapipelines.
ScrapeGraphAI er et prompt-styrt open source Python-bibliotek som gjør nettsteder om til strukturerte «grafer» ved hjelp av LLM-er. Du kan skrive prompts som «Hent alle produktnavn, priser og vurderinger fra de første 5 sidene», og så bygger den en scraping-workflow for deg ().
- Best for: Tekniske brukere som vil ha fleksibel, prompt-basert scraping.
- Pris: Gratis for open source-biblioteket; cloud-API starter på $20/måned.
4. Firecrawl
Hvem passer det for: Utviklere som bygger AI-agenter eller datapipelines i stor skala.
Firecrawl er en AI-fokusert crawling-plattform og API som gjør hele nettsteder om til «LLM-klare» data (). Den leverer Markdown eller JSON, håndterer dynamisk innhold og integrerer med rammeverk som LangChain og LlamaIndex.
- Best for: Utviklere som vil mate AI-modeller med ferske webdata.
- Pris: Open source-kjernen er gratis; cloud-planer starter på $19/måned.
5. Browse AI
Hvem passer det for: Forretningsbrukere, growth hackers og analytikere.
Browse AI er en no-code-plattform med et . Du «trener» en robot ved å klikke på dataene du vil ha, og AI-en generaliserer mønsteret for fremtidige kjøringer. Den håndterer innlogging, uendelig scrolling og kan overvåke nettsteder for endringer.
- Best for: Ikke-tekniske brukere som vil automatisere datainnsamling og overvåking.
- Pris: Gratis plan (50 kreditter/måned); betalte planer starter på $19/måned.
6. LLM Scraper
Hvem passer det for: Utviklere som vil la AI gjøre parsing-jobben.
LLM Scraper er et open source JavaScript/TypeScript-bibliotek der du kan og la en LLM hente ut dataene fra hvilken som helst nettside. Det bygger på Playwright, støtter flere LLM-leverandører og kan til og med generere gjenbrukbar kode.
- Best for: Utviklere som vil gjøre nettsider om til strukturerte data med LLM-er.
- Pris: Gratis (MIT-lisens).
7. Reader (Jina Reader)
Hvem passer det for: Utviklere som bygger LLM-applikasjoner, chatboter eller oppsummeringsverktøy.
Jina Reader er et API som henter ut , og returnerer LLM-klar Markdown eller JSON. Det drives av en egen AI-modell og kan også lage bildetekster.
- Best for: Å hente lesbart innhold til LLM-er eller Q&A-systemer.
- Pris: Gratis API (ingen nøkkel nødvendig for grunnleggende bruk).
8. Bright Data
Hvem passer det for: Enterprise og profesjonelle brukere som trenger skala, compliance og høy driftssikkerhet.
Bright Data er en tungvekter innen webdata, med et stort proxy-nettverk og . De tilbyr ferdige scrapere, en generell Web Scraper API og «LLM-klare» data-feeds.
- Best for: Organisasjoner som trenger pålitelige webdata i stor skala.
- Pris: Bruksbasert og premium. Gratis prøveperioder finnes.
9. Octoparse
Hvem passer det for: Ikke-tekniske til semi-tekniske brukere.
Octoparse er et etablert no-code-verktøy med en og AI-basert auto-detektering. Det håndterer innlogging, uendelig scrolling og kan eksportere i flere formater.
- Best for: Analytikere, småbedriftseiere eller forskere.
- Pris: Gratisnivå tilgjengelig; betalte planer starter på $119/måned.
10. Apify
Hvem passer det for: Utviklere og tekniske team som trenger skreddersydd scraping/automatisering.
Apify er en cloud-plattform for å kjøre scraping-skript («actors») og tilbyr en . Den skalerer godt, integrerer med AI og støtter proxy-håndtering.
- Best for: Utviklere som vil kjøre egne skript i skyen.
- Pris: Gratisnivå; bruksbaserte planer starter på $49/måned.
11. Zyte (Scrapy Cloud)
Hvem passer det for: Utviklere og selskaper som trenger scraping på enterprise-nivå.
Zyte står bak Scrapy og tilbyr en cloud-plattform med . Den håndterer planlegging, proxyer og prosjekter i stor skala.
- Best for: Dev-team som kjører langsiktige scraping-prosjekter.
- Pris: Gratis prøveperioder til skreddersydde enterprise-avtaler.
12. Webscraper.io
Hvem passer det for: Nybegynnere, journalister og forskere.
er en for uthenting med pek-og-klikk. Den er enkel, gratis lokalt og tilbyr en cloud-tjeneste for større jobber.
- Best for: Raske, engangs scraping-oppgaver.
- Pris: Gratis utvidelse; cloud-planer starter på ca. $50/måned.
13. ParseHub
Hvem passer det for: Ikke-tekniske brukere som trenger mer kraft enn de enkleste verktøyene.
ParseHub er en desktop-app med visuell workflow for å scrape dynamisk innhold, inkludert kart og skjemaer. Den kan kjøre prosjekter i skyen og tilbyr et API.
- Best for: Digitale markedsførere, analytikere og journalister.
- Pris: Gratisnivå (200 sider/kjøring); betalte planer starter på $189/måned.
14. Diffbot
Hvem passer det for: Enterprise og AI-selskaper som trenger strukturerte webdata i stor skala.
Diffbot bruker computer vision og NLP til å fra hvilken som helst nettside, med API-er for artikler, produkter og en stor kunnskapsgraf.
- Best for: Markedsinnsikt, finans og treningsdata til AI.
- Pris: Premium, fra ca. $299/måned.
15. DataMiner
Hvem passer det for: Ikke-tekniske brukere, særlig innen salg, markedsføring og journalistikk.
DataMiner er en for rask uthenting av webdata med pek-og-klikk. Den har et bibliotek med ferdige «oppskrifter» og kan eksportere direkte til Google Sheets.
- Best for: Kjappe oppgaver som å eksportere tabeller eller lister til regneark.
- Pris: Gratisnivå (500 sider/dag); Pro fra ca. $19/måned.
Sammenligning av de beste AI Web Scraper-verktøyene: Hvilket passer dine behov?
Her er en overordnet sammenligning som gjør det enklere å finne riktig match:
| Verktøy | AI/LLM-bruk | Brukervennlighet | Output/Integrasjon | Best for | Pris |
|---|---|---|---|---|---|
| Thunderbit | Naturlig språk; AI foreslår felter | Enklest (no-code chat) | Eksport til Sheets, Airtable, Notion | Ikke-tekniske team | Gratisnivå; Pro ~ $30/mnd |
| Crawl4AI | AI-klar crawling; integrer LLM-er | Vanskelig (Python-kode) | Bibliotek/CLI; integreres via kode | Devs som trenger raske AI-datapipelines | Gratis |
| ScrapeGraphAI | LLM-prompt-pipelines for scraping | Middels (noe koding eller API) | API/SDK; JSON-output | Devs/analytikere som bygger AI-agenter | Gratis OSS; API $20+/mnd |
| Firecrawl | Crawler til LLM-klar Markdown/JSON | Middels (API/SDK) | SDK-er (Py, Node, osv.); LangChain-integrasjon | Devs som kobler live webdata til AI | Gratis + betalt cloud |
| Browse AI | AI-assistert pek og klikk | Enkelt (no-code) | 7000+ app-integrasjoner (Zapier) | Ikke-tekniske som automatiserer overvåking | Gratis 50 kjøringer; $19+/mnd |
| LLM Scraper | Bruker LLM-er til å parse til schema | Vanskelig (TS/JS-kode) | Kodebibliotek; JSON-output | Devs som vil at AI skal gjøre parsing | Gratis (bruk egen LLM-API) |
| Reader (Jina) | AI-modell henter tekst/JSON | Enkelt (enkelt API-kall) | REST API returnerer Markdown/JSON | Devs som legger webinnhold inn i LLM-er | Gratis API |
| Bright Data | AI-forbedrede scraping-API-er; stort proxy-nettverk | Vanskelig (API, teknisk) | API-er/SDK-er; datastrømmer eller datasett | Enterprise-skala | Bruksbasert |
| Octoparse | AI auto-detekterer lister | Moderat (no-code app) | CSV/Excel, API for resultater | Semi-tekniske brukere | Gratis begrenset; $59–$166/mnd |
| Apify | Noen AI-funksjoner (Actors, AI-guider) | Vanskelig (skript) | Omfattende API; integrerer med LangChain | Devs som trenger skreddersydd scraping i skyen | Gratisnivå; pay-as-you-go |
| Zyte (Scrapy) | ML-basert auto-uthenting; Scrapy-rammeverk | Vanskelig (Python-kode) | API, Scrapy Cloud UI; JSON/CSV | Dev-team, langsiktige prosjekter | Tilpasset pris |
| Webscraper.io | Ingen AI (manuelle maler) | Enkelt (utvidelse) | CSV-nedlasting, Cloud API | Nybegynnere, raske engangskjøringer | Gratis utvidelse; Cloud ~ $50/mnd |
| ParseHub | Ingen eksplisitt LLM; visuell bygger | Moderat (no-code app) | JSON/CSV; API for cloud-kjøringer | Ikke-devs som scraper komplekse sider | Gratis 200 sider; $189+/mnd |
| Diffbot | AI vision/NLP for alle sider; kunnskapsgraf | Enkelt (API-kall) | API-er (Article/Prod/...) + Knowledge Graph-spørring | Enterprise, strukturerte webdata | Fra ~ $299/mnd |
| DataMiner | Ingen LLM; community-oppskrifter | Enklest (nettleser-UI) | Excel/CSV; Google Sheets | Ikke-tekniske som vil til regneark | Gratis begrenset; Pro ~ $19/mnd |
Verktøykategorier: Fra utviklerfavoritter til business-vennlige Web Scraper-verktøy
For å gjøre lista litt mer ryddig, kan vi dele verktøyene inn i noen hovedkategorier:
1. Kraftpakker for utviklere og open source
- Eksempler: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Styrker: Høy fleksibilitet, skalerbarhet og mulighet for skreddersøm. Perfekt for egne pipelines eller tett integrasjon med AI-modeller.
- Ulemper: Krever koding og mer oppsett.
- Bruksområder: Bygge egen datapipeline, scrape komplekse nettsteder eller koble mot interne systemer.
2. AI-integrerte scraping-agenter
- Eksempler: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Styrker: Kort vei fra «hent data» til «forstå data». Naturlig språk gjør dem langt mer tilgjengelige.
- Ulemper: Noen er fortsatt i rask utvikling og kan mangle helt finjustert kontroll.
- Bruksområder: Raske svar eller datasett, autonome agenter eller live data inn i LLM-er.
3. No-code/low-code, business-vennlige scrapere
- Eksempler: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- Styrker: Enkle å bruke, lite eller ingen koding, veldig gode for jevnlige forretningsoppgaver.
- Ulemper: Kan slite med ekstremt komplekse sider eller veldig stor skala.
- Bruksområder: Leadgenerering, konkurrentovervåking, research og engangs uthenting.
4. Enterprise-plattformer og datatjenester
- Eksempler: Bright Data, Diffbot, Zyte
- Styrker: Helhetlige løsninger, managed services, compliance og stabil drift i stor skala.
- Ulemper: Høyere kostnad og mer onboarding.
- Bruksområder: Store, kontinuerlige datapipelines, markedsinnsikt og treningsdata til AI.
Slik velger du riktig AI-nettrobot for dine behov innen web scraping
Det kan kjennes litt mye å velge riktig verktøy, så her er en enkel steg-for-steg-guide:
- Avklar mål og databehov: Hvilke nettsteder og hvilke data trenger du? Hvor ofte? Hvor mye? Hva skal du bruke det til?
- Vurder teknisk nivå: Ingen koding? Prøv Thunderbit, Browse AI eller Octoparse. Litt scripting? LLM Scraper eller DataMiner. Sterke dev-ferdigheter? Crawl4AI, Apify eller Zyte.
- Tenk på frekvens og skala: Engangsjobb? Bruk gratisverktøy. Gjentakende? Se etter planlegging. Storskala? Enterprise-verktøy eller open source i stor skala.
- Budsjett og prismodell: Gratisplaner er fine for testing. Abonnement vs. bruksbasert avhenger av behov.
- Test og proof of concept: Prøv noen verktøy på dine faktiske data. De fleste har gratisnivå.
- Vedlikehold og support: Hvem fikser når nettsiden endrer seg? No-code med AI kan ofte rette små endringer automatisk; open source er mer «gjør det selv».
- Koble verktøy til scenario: Salgsteam som scraper leads? Thunderbit eller Browse AI. Forsker som samler tweets? DataMiner eller . AI-modell som trenger nyhetsartikler? Jina Reader eller Zyte. Bygge en sammenligningstjeneste? Apify eller Zyte.
- Planlegg en backup: Noen ganger funker ikke ett verktøy på et bestemt nettsted. Ha en reserve.
Det «riktige» verktøyet er det som gir deg dataene du trenger med minst mulig friksjon – og innenfor budsjettet. Ofte er det en kombinasjon.
Thunderbit vs. tradisjonelle Web Scraper-verktøy: Hva gjør det annerledes?
La oss være konkrete på hvorfor Thunderbit skiller seg ut:
- Grensesnitt i naturlig språk: Ingen kode og ingen «pek-og-klikk-akrobatikk». Bare beskriv hva du vil ha ().
- Null konfigurasjon og malforslag: Thunderbit oppdager automatisk paginering, undersider og foreslår til og med maler for vanlige nettsteder ().
- AI-drevet datarensing og beriking: Oppsummer, kategoriser, oversett og berik data mens du scraper ().
- Mindre vedlikehold: Thunderbits AI tåler mindre endringer på siden, så ting knekker sjeldnere.
- Integrasjon med business-verktøy: Direkte eksport til Google Sheets, Airtable, Notion – uten CSV-styr ().
- Rask vei til verdi: Fra idé til data på minutter, ikke dager.
- Lav læringskurve: Kan du surfe på nett og forklare hva du trenger, kan du bruke Thunderbit.
- Fleksibilitet: Scrape nettsider, PDF-er, bilder og mer – med samme verktøy.
Thunderbit er ikke bare en scraper – det er en dataassistent som glir rett inn i arbeidsflyten din, enten du jobber med salg, markedsføring, netthandel eller eiendom.
Beste praksis for web scraping med AI Web Scraper-verktøy
For å få maks ut av AI-scrapere, er dette mine beste tips:
- Definer databehov tydelig: Vit hvilke felter du vil ha, hvor mange sider og hvilket format.
- Bruk AI-forslag: Utnytt feltdeteksjon og AI-forslag for å fange opp viktige data du ellers kan overse ().
- Start smått og valider: Test på et lite utvalg, sjekk resultatet og juster.
- Håndter dynamisk innhold: Sørg for at verktøyet støtter paginering, uendelig scrolling og interaksjoner.
- Respekter nettstedets regler: Sjekk robots.txt, unngå sensitive data og respekter rate limits.
- Integrer for automatisering: Bruk eksport og webhooks for å sende data rett inn i arbeidsflyten.
- Hold datakvaliteten høy: Gjør fornuftssjekk, bruk etterbehandling og følg med på feil.
- Vær presis i prompts: Klare og konkrete instruksjoner gir bedre resultater.
- Lær av fellesskapet: Bli med i forum og communities for tips og feilsøking.
- Hold deg oppdatert: AI-verktøy utvikler seg raskt – følg med på nye funksjoner.
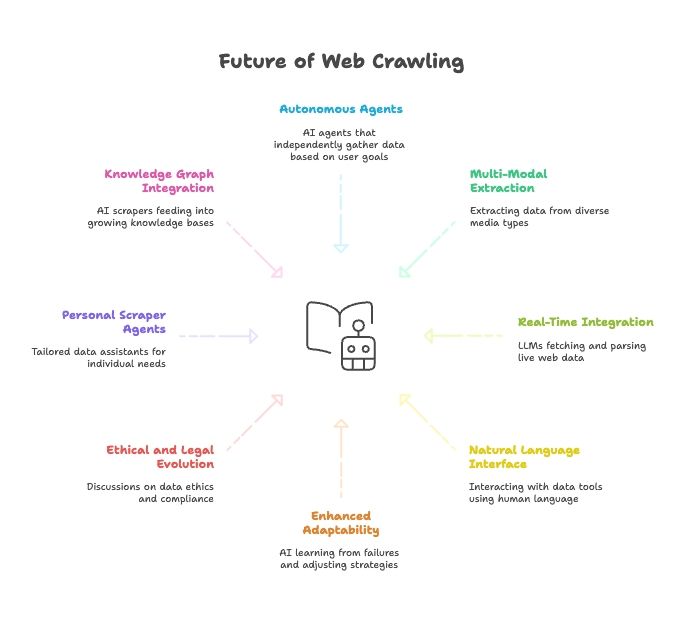
Fremtiden for web scraping: AI, LLM-er og naturlig-språk-agenter
Fremover går sammensmeltingen av AI og web scraping bare raskere:
- Helt autonome scraping-agenter: Snart forteller du bare en agent sluttmålet, og den finner selv ut hvordan dataene skal hentes.
- Multimodal uthenting: Scrapere vil hente fra tekst, bilder, PDF-er – og etter hvert også video.
- Sanntidskobling til AI-modeller: LLM-er får innebygde moduler for å hente og tolke live webdata.
- Alt på naturlig språk: Vi kommer til å snakke med dataverktøy som med mennesker, så flere kan samle inn og transformere data.
- Bedre tilpasningsevne: AI-scrapere lærer av feil og justerer strategi automatisk.
- Etikk og juss i utvikling: Mer fokus på dataetikk, compliance og fair use.
- Personlige scraping-agenter: En personlig dataassistent som samler nyheter, stillingsannonser og mer – tilpasset deg.
- Integrasjon med kunnskapsgrafer: AI-scrapere vil kontinuerlig fylle på kunnskapsbaser og gjøre AI smartere.
Kort sagt: Fremtiden for web scraping henger tett sammen med fremtiden for AI. Verktøyene blir smartere, mer autonome og mer tilgjengelige for hver dag som går.
Konklusjon: Skap forretningsverdi med riktig AI-nettrobot
Web scraping har gått fra å være en nisjeferdighet for tekniske folk til å bli en kjernekapabilitet i business – takket være AI. De 15 verktøyene jeg har dekket her viser det beste som er mulig i 2026, fra utviklerkraft til business-vennlige assistenter.
Hemmeligheten? Riktig verktøy kan øke verdien du får ut av webdata dramatisk. For ikke-tekniske team er Thunderbit den enkleste måten å gjøre weben om til en strukturert, analyse-klar database – uten kode, uten styr, bare resultater.
Enten du samler leads, følger konkurrenter eller mater neste generasjons AI-modell, lønner det seg å kartlegge behovene dine, teste noen alternativer og se hva som passer. Og hvis du vil oppleve fremtiden for web scraping allerede i dag, . Innsikten du trenger er bare en prompt unna.
Nysgjerrig på mer? Ta en titt på for dypdykk, guider og siste nytt innen AI-drevet datauthenting.
Videre lesning:
Vanlige spørsmål (FAQ)
1. Hva er en AI-nettrobot, og hvordan skiller den seg fra tradisjonelle web scrapere?
En AI-nettrobot bruker naturlig språk-prosessering og maskinlæring for å forstå, hente ut og strukturere webdata. I motsetning til tradisjonelle scrapere som ofte krever manuell koding og XPath-selektorer, kan AI-verktøy håndtere dynamisk innhold, tilpasse seg layoutendringer og tolke instruksjoner skrevet på vanlig språk.
2. Hvem bør bruke AI-verktøy for web scraping som Thunderbit?
Thunderbit er laget for både ikke-tekniske og tekniske brukere. Det passer spesielt godt for salg, markedsføring, drift, research og netthandel som vil hente strukturerte data fra nettsider, PDF-er eller bilder – uten å skrive kode.
3. Hvilke funksjoner gjør at Thunderbit skiller seg ut fra andre AI-nettroboter?
Thunderbit tilbyr et grensesnitt i naturlig språk, flernivå-crawling, automatisk strukturering av data, OCR-støtte og sømløs eksport til plattformer som Google Sheets og Airtable. I tillegg får du AI-drevne feltforslag og ferdige maler for populære nettsteder.
4. Finnes det gratis alternativer for AI web scraping i 2026?
Ja. Mange verktøy som Thunderbit, Browse AI og DataMiner har gratisplaner med begrenset bruk. For utviklere finnes open source-alternativer som Crawl4AI og ScrapeGraphAI med full funksjonalitet uten kostnad, men de krever teknisk oppsett.
5. Hvordan velger jeg riktig AI-nettrobot for mine behov?
Start med å definere datamål, teknisk nivå, budsjett og skala. Ønsker du en no-code-løsning som er enkel å bruke, er Thunderbit eller Browse AI gode valg. For storskala eller mer skreddersydde behov passer verktøy som Apify eller Bright Data bedre.