
La oss være ærlige — Amazon er i praksis kjøpesenteret, dagligvarebutikken og elektronikkbutikken for hele internett. Hvis du jobber med salg, e-handel eller drift, vet du allerede at det som skjer på Amazon, ikke blir værende på Amazon — det påvirker prisingen, lageret ditt og til og med den neste store produktlanseringen. Men her er haken: alle de fristende produktdetaljene, prisene, vurderingene og anmeldelsene er låst bak et webgrensesnitt laget for kunder, ikke for datatørste team. Så hvordan får du tak i dataene uten å bruke helgene dine på å kopiere og lime inn som om det var 1999?
Det er her web scraping kommer inn. I denne guiden viser jeg deg to måter å hente ut Amazon-produktdata på: den klassiske «brett opp ermene og kod det i Python»-tilnærmingen, og den moderne «la AI gjøre grovarbeidet»-løsningen med en no code web scraper som . Jeg går gjennom ekte Python-kode (med alle fallgruvene og løsningene), og viser deretter hvordan Thunderbit kan gi deg de samme dataene på bare et par klikk — uten at du trenger å kode. Enten du er utvikler, forretningsanalytiker eller bare lei av manuell datainntasting, har jeg deg dekket.
Hvorfor hente ut Amazon-produktdata? (amazon scraper python, web scraping with python)
Amazon er ikke bare verdens største nettbutikk — det er også verdens største friluftsmarked for konkurranseinnsikt. Med og , er Amazon en gullgruve for alle som vil:

- Overvåke priser (og justere dine egne i sanntid)
- Analysere konkurrenter (følge nye lanseringer, vurderinger og anmeldelser)
- Generere leads (finne selgere, leverandører eller potensielle partnere)
- Prognostisere etterspørsel (ved å følge lagernivåer og salgstall)
- Oppdage markedstrender (ved å granske anmeldelser og søkeresultater)
Og dette er ikke bare teori — reelle virksomheter ser faktisk reell avkastning. For eksempel brukte en elektronikkforhandler innhentede Amazon-prisdata til å , mens et annet varemerke så etter å ha automatisert sporing av konkurrentpriser.
Her er en rask tabell over bruksområder og typen avkastning du kan forvente:
| Bruksområde | Hvem bruker det | Typisk avkastning / gevinst |
|---|---|---|
| Prisovervåking | E-handel, drift | 15 %+ økning i fortjenestemargin, 4 % salgsøkning, 30 % mindre analytikertid |
| Konkurrentanalyse | Salg, produkt, drift | Raskere prisjusteringer, bedre konkurranseevne |
| Markedsundersøkelser (anmeldelser) | Produkt, markedsføring | Raskere produktforbedringer, bedre annonsetekster, SEO-innsikt |
| Lead-generering | Salg | 3 000+ leads/måned, 8+ timer spart per selger per uke |
| Lager- og etterspørselsprognoser | Drift, forsyningskjede | 20 % reduksjon i overlager, færre utsolgte varer |
| Trendoppdagelse | Markedsføring, ledelse | Tidlig oppdagelse av populære produkter og kategorier |
Og her er det virkelig interessante: rapporterer nå målbar verdi fra dataanalyse. Hvis du ikke scraper Amazon, lar du innsikt — og penger — ligge igjen på bordet.
Oversikt: Amazon Scraper Python vs. No Code Web Scraper-verktøy
Det finnes to hovedmåter å få Amazon-data ut av nettleseren og inn i regnearkene eller dashbordene dine:
-
Amazon Scraper Python (web scraping with python):
Skriv ditt eget skript ved hjelp av Python-biblioteker som Requests og BeautifulSoup. Dette gir deg full kontroll, men du må kunne kode, håndtere anti-bot-tiltak og vedlikeholde skriptet når Amazon endrer nettsiden sin.
-
No Code Web Scraper-verktøy (som Thunderbit):
Bruk et verktøy som lar deg peke, klikke og hente ut data — uten programmering. Moderne verktøy som bruker til og med AI til å finne ut hvilke data som skal hentes, håndtere undersider og paginering, og eksportere rett til Excel eller Google Sheets.
Slik står de seg mot hverandre:
| Kriterium | Python-scraper | No code (Thunderbit) |
|---|---|---|
| Oppsetttid | Høy (installere, kode, feilsøke) | Lav (installer utvidelsen) |
| Nødvendig kompetanse | Krever koding | Ingen (pek og klikk) |
| Fleksibilitet | Ubegrenset | Høy for vanlige bruksområder |
| Vedlikehold | Du fikser koden | Verktøyet oppdaterer seg selv |
| Håndtering av anti-bot | Du håndterer proxyer og headere | Innebygd, håndtert for deg |
| Skalerbarhet | Manuell (tråder, proxyer) | Sky-scraping, parallellisert |
| Dataeksport | Tilpasset (CSV, Excel, database) | Ett klikk til Excel, Sheets |
| Kostnad | Gratis (din tid + proxyer) | Freemium, betal for skala |
I de neste delene går jeg gjennom begge tilnærmingene — først hvordan du bygger en Amazon-scraper i Python (med ekte kode), deretter hvordan du gjør det samme med Thunderbits AI-webskraper.
Kom i gang med Amazon Scraper Python: Forutsetninger og oppsett
Før vi dykker ned i koden, la oss få miljøet ditt klart.
Du trenger:
- Python 3.x (last ned fra )
- En kodeeditor (jeg liker VS Code, men alt fungerer)
- Følgende biblioteker:
requests(for HTTP-forespørsler)beautifulsoup4(for HTML-parsing)lxml(rask HTML-parser)pandas(for datatabeller/eksport)re(regulære uttrykk, innebygd)
Installer bibliotekene:
1pip install requests beautifulsoup4 lxml pandasProsjektoppsett:
- Opprett en ny mappe for prosjektet ditt.
- Åpne editoren din, lag en ny Python-fil (for eksempel
amazon_scraper.py). - Du er klar til å begynne!
Steg for steg: Web scraping med Python for Amazon-produktdata
La oss gå gjennom scraping av én Amazon-produktside. (Ikke bekymre deg, vi kommer til scraping av flere produkter og sider om litt.)
1. Sende forespørsler og hente HTML
Først henter vi HTML-en for en produktside. (Bytt ut URL-en med et hvilket som helst Amazon-produkt.)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)Obs: Denne enkle forespørselen blir sannsynligvis blokkert av Amazon. Du kan se en 503-feil eller en CAPTCHA i stedet for produktsiden. Hvorfor? Fordi Amazon vet at du ikke er en ekte nettleser.
Håndtering av Amazons anti-bot-tiltak
Amazon er ikke spesielt glad i boter. For å unngå å bli blokkert, må du:
- Sette en User-Agent-header (late som om du er Chrome eller Firefox)
- Rullere User-Agents (ikke bruk den samme hver gang)
- Trekke ned tempoet på forespørslene (legg inn tilfeldige forsinkelser)
- Bruke proxyer (for scraping i stor skala)
Slik setter du headere:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)Vil du gjøre det mer avansert? Bruk en liste over User-Agents og roter dem for hver forespørsel. For store jobber vil du gjerne bruke en proxy-tjeneste (det finnes mange der ute), men for scraping i liten skala er headere og forsinkelser som regel nok.
Ekstrahere viktige produktfelt
Når du har HTML-en, er det på tide å parse den med BeautifulSoup.
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")La oss nå hente ut det viktigste:
Produkttittel
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else NonePris
Prisen på Amazon kan ligge flere steder. Prøv disse:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.textVurdering og antall anmeldelser
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # f.eks. "1,554 ratings"URL til hovedbilde
Amazon skjuler noen ganger høyoppløselige bilder i JSON inne i HTML-en. Her er en rask regex-tilnærming:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else NoneEller hent det viktigste bildeelementet:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else NoneProduktdetaljer
Spesifikasjoner som merke, vekt og dimensjoner ligger vanligvis i en tabell:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = valueEller, hvis Amazon bruker formatet “detailBullets”:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()Skriv ut resultatene dine:
1print("Tittel:", product_title)
2print("Pris:", price)
3print("Vurdering:", rating, "basert på", reviews_count, "anmeldelser")
4print("URL til hovedbilde:", main_image_url)
5print("Detaljer:", details)Scraping av flere produkter og håndtering av paginering
Ett produkt er fint, men du vil sannsynligvis ha en hel liste. Slik scraper du søkeresultater og flere sider.
Hent produktlenker fra en søkeside
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)Håndter paginering
Amazons søke-URL-er bruker &page=2, &page=3 og så videre.
1for page in range(1, 6): # scrape de første 5 sidene
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... hent produktlenker som ovenfor ...Gå gjennom produktsider og eksporter til CSV
Samle produktdataene dine i en liste av ordbøker, og bruk deretter pandas:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # liste med dicts
3df.to_csv("amazon_products.csv", index=False)Eller til Excel:
1df.to_excel("amazon_products.xlsx", index=False)Beste praksis for Amazon Scraper Python-prosjekter
La oss være ærlige — Amazon endrer stadig nettsiden sin og kjemper mot scrapers. Slik holder du prosjektet ditt i gang:
- Roter headere og User-Agents (bruk et bibliotek som
fake-useragent) - Bruk proxyer for scraping i stor skala
- Trekke ned tempoet på forespørsler (tilfeldige
time.sleep()mellom forespørsler) - Håndter feil på en robust måte (prøv på nytt ved 503, ta det roligere hvis du blir blokkert)
- Skriv fleksibel parsingslogikk (se etter flere selektorer per felt)
- Overvåk HTML-endringer (hvis skriptet plutselig returnerer
Nonefor alt, sjekk siden) - Respekter robots.txt (Amazon forbyr scraping av mange seksjoner — scrape ansvarlig)
- Rens dataene underveis (fjern valutasymboler, kommaer og mellomrom)
- Hold kontakten med miljøet (forum, Stack Overflow, Reddits r/webscraping)
Sjekkliste for vedlikehold av scraperskriptet ditt:
- [ ] Roter User-Agents og headere
- [ ] Bruk proxyer hvis du scraper i stor skala
- [ ] Legg inn tilfeldige forsinkelser
- [ ] Del opp koden i moduler for enklere oppdateringer
- [ ] Overvåk for utestengelser eller CAPTCHA-er
- [ ] Eksporter data jevnlig
- [ ] Dokumenter selektorer og logikk
For en dypere gjennomgang, ta en titt på min .
Det no code-alternativet: Scraping av Amazon med Thunderbit AI Web Scraper
Greit, så du har sett Python-måten. Men hva om du ikke vil kode — eller du bare vil få dataene på to klikk og gå videre med livet ditt? Da kommer inn i bildet.
Thunderbit er en AI web scraper Chrome-utvidelse som lar deg hente ut Amazon-produktdata (og data fra omtrent hvilken som helst nettside) uten koding. Her er hvorfor jeg liker den:
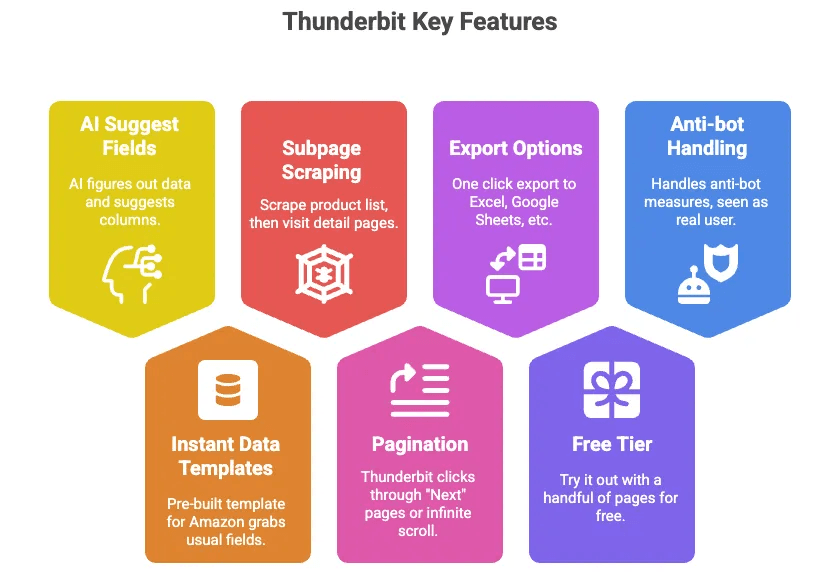
- AI-forslag til felt: Klikk på en knapp, og Thunderbits AI finner ut hvilke data som finnes på siden og foreslår kolonner (som Tittel, Pris, Vurdering osv.).
- Umiddelbare datamaler: For Amazon finnes det en ferdig mal som henter ut alle vanlige felt — ingen oppsett nødvendig.
- Scraping av undersider: Scrape en produktliste, og la deretter Thunderbit besøke hver produkts detaljside og hente mer informasjon automatisk.
- Paginering: Thunderbit kan klikke seg gjennom «Neste»-sider eller uendelig scrolling for deg.
- Eksport til Excel, Google Sheets, Airtable, Notion: Med ett klikk er dataene klare til bruk.
- Gratisnivå: Prøv det på noen få sider gratis.
- Håndterer anti-bot for deg: Siden det kjører i nettleseren din (eller i skyen), ser Amazon det som en ekte bruker.
Steg for steg: Bruke Thunderbit til å scrape Amazon-produktdata
Slik enkelt er det:
-
Installer Thunderbit:
Last ned og logg inn.
-
Åpne Amazon:
Gå til Amazon-siden du vil scrape (søkeresultater, produktside, hva som helst).
-
Klikk «AI Suggest Fields» eller bruk en mal:
Thunderbit foreslår kolonner å hente ut (eller du kan velge Amazon Product-malen).
-
Se over kolonnene:
Juster kolonnene om du vil (legg til/fjern felt, gi nytt navn osv.).
-
Klikk «Scrape»:
Thunderbit henter dataene fra siden og viser dem i en tabell.
-
Håndter undersider og paginering:
Hvis du scrape-et en liste, klikker du «Scrape Subpages» for å besøke hver produkts detaljside og hente mer informasjon. Thunderbit kan også automatisk klikke seg gjennom «Neste»-sider.
-
Eksporter dataene dine:
Klikk «Export to Excel» eller «Export to Google Sheets». Ferdig.
-
(Valgfritt) Planlegg scraping:
Trenger du disse dataene hver dag? Bruk Thunderbits planlegger for å automatisere det.
Det var alt. Ingen kode, ingen feilsøking, ingen proxyer, ingen hodepine. For en visuell gjennomgang, sjekk ut eller siden for .
Amazon Scraper Python vs. No Code Web Scraper: Sammenligning side om side
La oss sette det hele sammen:
| Kriterium | Python-scraper | Thunderbit (no code) |
|---|---|---|
| Oppsetttid | Høy (installere, kode, feilsøke) | Lav (installer utvidelsen) |
| Nødvendig kompetanse | Krever koding | Ingen (pek og klikk) |
| Fleksibilitet | Ubegrenset | Høy for vanlige bruksområder |
| Vedlikehold | Du fikser koden | Verktøyet oppdaterer seg selv |
| Håndtering av anti-bot | Du håndterer proxyer og headere | Innebygd, håndtert for deg |
| Skalerbarhet | Manuell (tråder, proxyer) | Sky-scraping, parallellisert |
| Dataeksport | Tilpasset (CSV, Excel, database) | Ett klikk til Excel, Sheets |
| Kostnad | Gratis (din tid + proxyer) | Freemium, betal for skala |
| Best for | Utviklere, tilpassede behov | Forretningsbrukere, raske resultater |
Hvis du er en utvikler som elsker å eksperimentere og trenger noe svært tilpasset, er Python din venn. Hvis du vil ha fart, enkelhet og null koding, er Thunderbit veien å gå.
Når du bør velge Python, no code eller AI web scraper for Amazon-data
Velg Python hvis:
- Du trenger tilpasset logikk eller vil integrere scraping i backend-systemene dine
- Du scraper i enorm skala (tusenvis av produkter)
- Du vil lære hvordan scraping fungerer under panseret
Velg Thunderbit (no code, AI web scraper) hvis:
- Du vil ha data raskt, uten koding
- Du er en forretningsbruker, analytiker eller markedsfører
- Du trenger å gjøre teamet ditt i stand til å hente data selv
- Du vil unngå bryet med proxyer, anti-bot-tiltak og vedlikehold
Bruk begge hvis:
- Du vil prototypere raskt med Thunderbit og deretter bygge en tilpasset Python-løsning for produksjon
- Du vil bruke Thunderbit til datainnsamling og Python til datarensing/analyse
For de fleste forretningsbrukere vil Thunderbit dekke 90 % av Amazon-scrapingbehovene dine på en brøkdel av tiden. For de andre 10 % — det svært tilpassede, storskala eller dypt integrerte — er Python fortsatt kongen.
Konklusjon og viktigste læringspunkter
Å scrape Amazon-produktdata er en superkraft for alle salg-, e-handels- eller driftsteam. Enten du sporer priser, analyserer konkurrenter eller bare prøver å spare teamet ditt for endeløs kopiering og liming, finnes det en løsning for deg.
- Python-scraping gir deg full kontroll, men kommer med en læringskurve og løpende vedlikehold.
- No code web scrapers som Thunderbit gjør Amazon-datautvinning tilgjengelig for alle — ingen koding, ingen hodepine, bare resultater.
- Den beste tilnærmingen? Bruk verktøyet som passer ferdighetene dine, tidslinjen din og forretningsmålene dine.
Hvis du er nysgjerrig, prøv Thunderbit — det er gratis å komme i gang, og du kommer til å bli overrasket over hvor raskt du kan få tak i dataene du trenger. Og hvis du er utvikler, ikke vær redd for å blande og matche: noen ganger er den raskeste måten å bygge på å la AI gjøre de kjedelige delene for deg.
Vanlige spørsmål
1. Hvorfor skulle en bedrift ønske å scrape Amazon-produktdata?
Scraping av Amazon lar bedrifter overvåke priser, analysere konkurrenter, samle anmeldelser til produktundersøkelser, prognostisere etterspørsel og generere salgsmuligheter. Med over 600 millioner produkter og nesten 2 millioner selgere på Amazon er det en rik kilde til konkurranseinnsikt.
2. Hva er de viktigste forskjellene mellom å bruke Python og no code-verktøy som Thunderbit til å scrape Amazon?
Python-scrapere gir maksimal fleksibilitet, men krever kodeferdigheter, oppsetttid og løpende vedlikehold. Thunderbit, en no code AI web scraper, lar brukere hente Amazon-data umiddelbart via en Chrome-utvidelse — uten koding, med innebygd håndtering av anti-bot og eksport til Excel eller Sheets.
3. Er det lovlig å scrape data fra Amazon?
Amazons bruksvilkår forbyr som regel scraping, og de bruker aktivt anti-bot-tiltak. Likevel scraper mange virksomheter fortsatt offentlig tilgjengelige data, så lenge de opptrer ansvarlig, som å respektere hastighetsgrenser og unngå for mange forespørsler.
4. Hvilken type data kan jeg hente ut fra Amazon med web scraping-verktøy?
Vanlige datafelt inkluderer produkttitler, priser, vurderinger, antall anmeldelser, bilder, produktspesifikasjoner, tilgjengelighet og til og med selgerinformasjon. Thunderbit støtter også scraping av undersider og paginering for å fange data på tvers av flere oppføringer og sider.
5. Når bør jeg velge Python-scraping fremfor et verktøy som Thunderbit, eller omvendt?
Bruk Python hvis du trenger full kontroll, tilpasset logikk eller planlegger å integrere scraping i backend-systemer. Bruk Thunderbit hvis du vil ha raske resultater uten koding, trenger enkel skalering eller er en forretningsbruker som ser etter en løsning med lite vedlikehold.
Vil du gå dypere? Sjekk ut disse ressursene:
God scraping — og måtte regnearkene dine alltid være oppdaterte.