
Se ti sei mai cimentato nell’estrazione di dati da un sito che carica i contenuti mentre scorri, nasconde i prezzi dietro un login o cambia aspetto ogni settimana, sai già che la faccenda può diventare un vero rompicapo. Gli estrattori statici ormai non bastano più. Pensa che oltre il si affida all’estrazione dati dal web per ottenere informazioni alternative, e automatizza il monitoraggio dei prezzi dei concorrenti. Il punto è che la maggior parte di questi dati si trova su siti dinamici, caricati via JavaScript e nascosti dietro interazioni utente. Qui entrano in gioco l’automazione con browser headless e strumenti come Puppeteer.
Dopo anni passati a lavorare su soluzioni di automazione e intelligenza artificiale (e sì, anche a estrarre dati per team di vendita e operations), ho visto quanto Puppeteer possa sbloccare dati che gli estrattori tradizionali non riescono nemmeno a sfiorare. Ma so anche che la programmazione può essere un ostacolo per chi lavora in ambito business. In questa guida ti spiego cos’è un estrattore Puppeteer, come usarlo per l’estrazione dati dal web e quando conviene puntare su una soluzione ancora più semplice, come , il nostro Estrattore Web AI senza codice.
Cos’è Puppeteer Scraper? Una panoramica veloce
 Partiamo dalle basi. è una libreria open-source per Node.js sviluppata da Google che ti permette di controllare un browser Chrome o Chromium in modalità headless tramite JavaScript. In parole povere: è come avere un robottino che apre pagine web, clicca pulsanti, compila moduli, scorre la pagina e – soprattutto – estrae dati, tutto senza mostrare nulla sullo schermo.
Partiamo dalle basi. è una libreria open-source per Node.js sviluppata da Google che ti permette di controllare un browser Chrome o Chromium in modalità headless tramite JavaScript. In parole povere: è come avere un robottino che apre pagine web, clicca pulsanti, compila moduli, scorre la pagina e – soprattutto – estrae dati, tutto senza mostrare nulla sullo schermo.
Cosa rende Puppeteer speciale?
- Sa gestire contenuti dinamici: aspetta che il JavaScript carichi i dati, proprio come farebbe una persona.
- Può simulare azioni dell’utente: click, digitazione, scroll e gestione di pop-up.
- È perfetto per estrarre dati da siti dove le informazioni compaiono solo dopo un’interazione, come e-commerce, feed social o dashboard.
Come si confronta con altri strumenti?
- Selenium: Il classico dell’automazione browser. Compatibile con diversi browser e linguaggi, ma più pesante e un po’ datato. Ottimo per test cross-browser, ma Puppeteer è più snello per progetti su Chrome/Node.js.
- Thunderbit: Qui si fa interessante. Thunderbit è un Estrattore Web AI senza codice che funziona direttamente dal browser. Invece di scrivere script, basta cliccare su “AI Suggerisci Campi” e lasciare che l’AI capisca cosa estrarre. Perfetto per chi vuole risultati senza programmare (ne parliamo tra poco).
In breve: Puppeteer = massimo controllo (se sai programmare). Thunderbit = massima semplicità (se non vuoi scrivere codice).
Perché l’estrazione dati con Puppeteer è fondamentale per le aziende
Parliamoci chiaro: l’estrazione dati dal web non è più roba da hacker o data scientist. Team di vendita, operations, marketing e persino agenzie immobiliari usano i dati online per ottenere un vantaggio competitivo. E con così tante informazioni strategiche bloccate su siti dinamici, Puppeteer spesso è la chiave per accedervi.
Ecco qualche esempio concreto:
| Caso d’uso | Chi ne beneficia | Impatto / ROI |
|---|---|---|
| Generazione lead | Vendite, Business Dev | Automatizza la creazione di liste di potenziali clienti; risparmia oltre 8 ore/settimana per ogni commerciale (case study) |
| Monitoraggio prezzi | E-commerce, Product Ops | Tracciamento in tempo reale dei concorrenti; un’azienda ha risparmiato $3,8M/anno (fonte) |
| Ricerche di mercato | Marketing, Strategia, Finanza | Il 67% dei consulenti usa dati estratti dal web; ROI fino all’890% in alcuni casi (fonte) |
| Aggregazione immobiliare | Agenti, Analisti | Estrai dati da oltre 50 annunci immobiliari in pochi minuti (fonte) |
| Monitoraggio compliance | Operations, Legale | Automatizza i controlli; un’assicurazione ha evitato $50M di sanzioni (fonte) |
E non dimenticare che passa un quarto della settimana su attività ripetitive come la raccolta dati. Automatizzare questi processi con l’estrazione web non è solo utile: è un vero vantaggio competitivo.
Come iniziare: configura il tuo Puppeteer Scraper
Pronto a metterti all’opera? Ecco come avviare Puppeteer in meno di 10 minuti (se hai un po’ di confidenza con JavaScript):
1. Installa Node.js
Puppeteer gira su Node.js. Scarica la versione LTS più recente da .
2. Crea una nuova cartella di progetto
Apri il terminale e digita:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Installa Puppeteer
1npm install puppeteerQuesto comando scarica anche una versione compatibile di Chromium (circa 100MB).
4. Crea il tuo primo script
Crea un file chiamato scrape.js:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Page title:', title);
8 await browser.close();
9})();Eseguilo con:
1node scrape.jsSe vedi “Page title: Example Domain”, complimenti: hai appena automatizzato Chrome!
Costruisci il tuo primo script di web scraping con Puppeteer
Passiamo alla pratica. Supponiamo tu voglia estrarre citazioni da (un sito demo per testare scraper).
Step 1: Vai alla pagina
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Step 2: Estrai i dati
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Step 3: Gestisci la paginazione
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Estrai le citazioni come sopra
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Step 4: Salva in JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));Ecco fatto: un estrattore Puppeteer base che naviga, estrae, gestisce la paginazione e salva i dati.
Tecniche avanzate con Puppeteer Scraper: come gestire contenuti dinamici
La maggior parte dei siti reali non è semplice come una lista statica. Ecco come affrontare le sfide più comuni:
1. Attendere elementi dinamici
1await page.waitForSelector('.product-list-item');Così ti assicuri che i contenuti siano caricati prima di estrarli.
2. Simulare azioni utente
- Cliccare un pulsante:
await page.click('#load-more'); - Scrivere in un campo:
await page.type('#search', 'laptop'); - Scroll per infinite scroll:
1let previousHeight = await page.evaluate('document.body.scrollHeight'); 2while (true) { 3 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 4 await page.waitForTimeout(1500); 5 const newHeight = await page.evaluate('document.body.scrollHeight'); 6 if (newHeight === previousHeight) break; 7 previousHeight = newHeight; 8}
3. Gestire i login
1await page.goto('https://exampleshop.com/login');
2await page.type('#login-username', 'myusername');
3await page.type('#login-password', 'mypassword');
4await page.click('#login-button');
5await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Gestire dati caricati via AJAX A volte i dati non sono nel DOM ma arrivano tramite chiamate API. Puoi intercettare le risposte di rete così:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Elabora i dati
5 }
6});Esempio pratico: estrarre dati prodotto da un sito e-commerce
Mettiamo insieme tutto. Immagina di voler estrarre nomi, prezzi e immagini dei prodotti da un sito e-commerce (demo) dopo aver fatto il login.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Step 1: Login
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Step 2: Vai alla pagina di categoria
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Step 3: Estrai i prodotti
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Step 4: Salva in JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Questo script effettua il login, naviga, estrae e salva i dati in automatico. Se ti servono funzioni più avanzate puoi aggiungere cicli per la paginazione o entrare nei dettagli di ogni prodotto.
Thunderbit: rendi Puppeteer Scraper ancora più semplice con l’AI
Se sei arrivato fin qui e pensi: “Ok, ma non voglio scrivere codice ogni volta che mi serve un nuovo dataset”, non sei il solo. È proprio per questo che abbiamo creato .
Cosa rende Thunderbit diverso?
- Zero codice: Installa la , apri la pagina che ti interessa e clicca su “AI Suggerisci Campi”.
- Rilevamento campi con AI: Thunderbit analizza la pagina e suggerisce le colonne migliori da estrarre, come “Nome prodotto”, “Prezzo”, “Immagine”, ecc.
- Gestione contenuti dinamici: Scroll infinito, pop-up e sottopagine? L’AI di Thunderbit li gestisce, cliccando su paginazione o visitando ogni dettaglio prodotto per arricchire i dati.
- Esportazione immediata: Invia i dati direttamente su Excel, Google Sheets, Notion o Airtable con un click. Nessun costo extra per l’export.
- Template per siti famosi: Devi estrarre dati da Amazon, Zillow o LinkedIn? Thunderbit offre template già pronti, senza configurazione.
- Estrazione cloud o da browser: Per grandi volumi, Thunderbit può estrarre dati da fino a 50 pagine contemporaneamente nel cloud.
Ho visto utenti passare da “Mi servirebbero questi dati” a “Ecco il mio file Excel” in meno di cinque minuti. E la cosa migliore? Niente più ansia per script che si rompono quando il sito cambia: l’AI di Thunderbit si adatta in tempo reale.
Puppeteer vs. Thunderbit: quale strumento di web scraping scegliere?
Quale scegliere? Ecco come lo spiego ai team:
| Fattore | Puppeteer (con codice) | Thunderbit (No-Code, AI) |
|---|---|---|
| Facilità d’uso | Richiede conoscenze di JavaScript e DOM | Punta e clicca, l’AI suggerisce i campi |
| Velocità di setup | Da ore a giorni per attività complesse | Minuti: basta installare e partire |
| Controllo/Flessibilità | Massima: puoi programmare qualsiasi logica personalizzata | Alta per casi standard; meno adatto a flussi di lavoro molto personalizzati |
| Contenuti dinamici | Script manuali per attese, click, scroll | L’AI gestisce automaticamente contenuti dinamici, paginazione e sottopagine |
| Manutenzione | Gli script sono tuoi: da aggiornare quando il sito cambia | L’AI si adatta ai cambiamenti di layout; meno manutenzione per l’utente |
| Esportazione dati | Devi scrivere tu la logica di export | Esportazione con un click su Excel, Sheets, Notion, Airtable, CSV, JSON |
| Ideale per | Sviluppatori, scraping personalizzato o su larga scala | Utenti business, progetti rapidi, team non tecnici |
| Costo | Gratis (a parte il tuo tempo e l’infrastruttura) | Piano gratuito disponibile; piani a pagamento a crediti (vedi Prezzi Thunderbit) |
In breve:
- Scegli Puppeteer se vuoi il massimo controllo, hai risorse di sviluppo o devi integrare lo scraping in un’app più grande.
- Scegli Thunderbit se vuoi risultati rapidi, non vuoi programmare o vuoi dare autonomia anche ai colleghi non tecnici.
A dirla tutta, molti team usano entrambi: Thunderbit per prototipi e risultati veloci, Puppeteer per integrazioni profonde o casi particolari.
Checklist pratica: come gestire un progetto di web scraping con Puppeteer
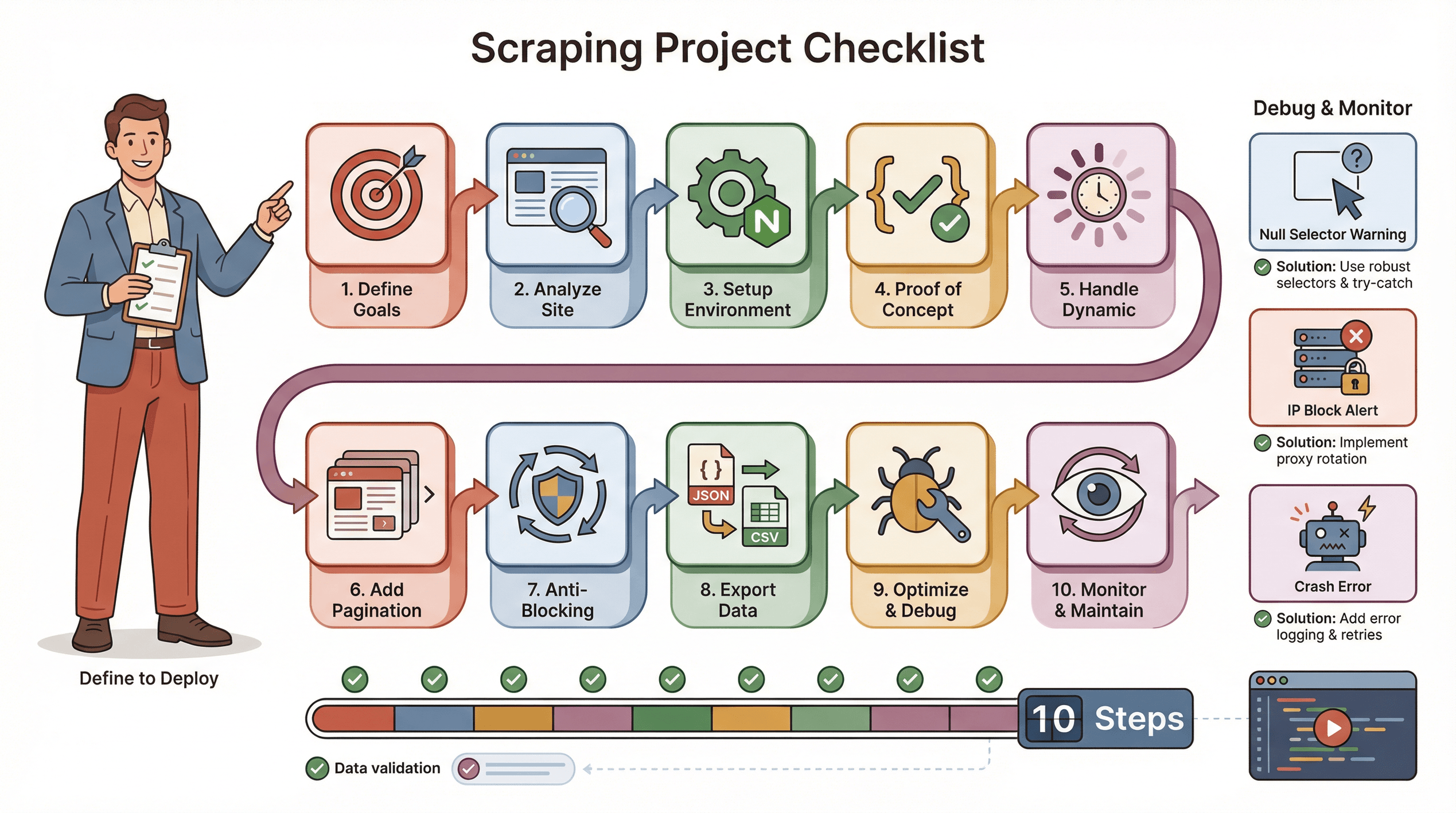 Ecco la mia checklist per un progetto di scraping con Puppeteer senza intoppi:
Ecco la mia checklist per un progetto di scraping con Puppeteer senza intoppi:
- Definisci gli obiettivi: quali dati ti servono? Dove si trovano?
- Analizza il sito: è dinamico? Serve login? Ci sono sistemi anti-bot?
- Prepara l’ambiente: Node.js, Puppeteer e librerie di supporto.
- Scrivi una prova di concetto: parti da una pagina, trova i selettori giusti.
- Gestisci i contenuti dinamici: usa
waitForSelector, simula click/scroll se serve. - Aggiungi paginazione o cicli: estrai dati da tutte le pagine, non solo una.
- Implementa strategie anti-blocco: randomizza i tempi, imposta un User-Agent reale, usa proxy se serve.
- Esporta e valida i dati: salva in JSON/CSV, controlla che siano completi.
- Ottimizza e gestisci gli errori: aggiungi try/catch, logga i progressi, gestisci dati mancanti.
- Monitora e aggiorna: i siti cambiano, sii pronto a modificare lo script.
Consigli per risolvere i problemi:
- Se i selettori restituiscono null, ricontrolla l’HTML e usa le attese.
- Se vieni bloccato, rallenta, cambia IP o usa plugin stealth.
- Se lo script si blocca, verifica eventuali memory leak o eccezioni non gestite.
Conclusioni e takeaway
L’estrazione dati dal web è ormai una skill fondamentale per i team che puntano sui dati. Puppeteer ti permette di ottenere dati anche dai siti più dinamici e complessi, ma richiede capacità di programmazione e manutenzione costante. Se invece vuoi saltare la parte di codice e arrivare subito ai dati, Thunderbit offre un’alternativa AI senza codice, veloce, flessibile e sorprendentemente potente.
Il mio consiglio:
- Se sei tecnico e vuoi la massima personalizzazione, parti da Puppeteer.
- Se cerchi velocità, semplicità e meno manutenzione, prova (l’ è il modo migliore per iniziare).
- Per la maggior parte dei team, una combinazione di entrambi copre il 99% delle esigenze di dati dal web.
Vuoi altre guide come questa? Dai un’occhiata al per tutorial, confronti e novità sull’estrazione dati AI.
Domande frequenti
1. Cos’è Puppeteer scraper e perché viene usato per il web scraping?
Puppeteer è una libreria Node.js che permette di controllare un browser Chrome headless tramite JavaScript. È usato per l’estrazione dati perché può caricare contenuti dinamici, simulare azioni utente ed estrarre dati da siti che gli estrattori tradizionali non riescono a gestire.
2. Come si confronta Puppeteer con Selenium e Thunderbit?
Selenium funziona con diversi browser e linguaggi ma è più pesante. Puppeteer è ottimizzato per Chrome/Node.js ed è più veloce in molti casi. Thunderbit, invece, è uno strumento AI senza codice che permette anche ai non tecnici di estrarre dati in pochi click.
3. Quali sono i principali vantaggi di business dello scraping con Puppeteer?
Automatizzare la raccolta dati fa risparmiare tempo, riduce gli errori e offre insight in tempo reale per vendite, marketing, operations e altro. Gli usi vanno dalla generazione lead al monitoraggio prezzi e alle ricerche di mercato.
4. Quali sono le principali sfide dello scraping con Puppeteer?
Le difficoltà principali sono la gestione di contenuti dinamici, l’evitare blocchi anti-bot e la manutenzione degli script quando i siti cambiano. Serve scrivere codice per gestire attese, simulare interazioni e gestire errori.
5. Quando conviene usare Thunderbit invece di Puppeteer?
Scegli Thunderbit se vuoi evitare la programmazione, hai bisogno di risultati rapidi o vuoi dare autonomia anche ai colleghi non tecnici. È ideale per attività standard, progetti veloci o quando vuoi esportare dati su Excel o Google Sheets senza complicazioni.
Vuoi provare un modo più smart di estrarre dati? o scopri altre guide sul . Buona estrazione!
Scopri di più