
Se hai mai provato a estrarre dati da un sito che carica i contenuti mentre scorri, nasconde i prezzi dietro un login o sembra cambiare layout ogni due settimane, sai bene quanto possa essere frustrante. Gli scraper statici, ormai, non bastano più. Anzi, oltre il si affida oggi al web scraping per i dati alternativi, e automatizza il monitoraggio dei prezzi dei concorrenti. Ma il punto è questo: gran parte di quei dati vive su siti dinamici, caricati da JavaScript e nascosti dietro le interazioni dell’utente. È qui che entrano in gioco l’automazione del browser headless e strumenti come Puppeteer.
Avendo passato anni a sviluppare strumenti di automazione e AI (e sì, a fare scraping di una buona dose di siti per team sales e operations), ho visto in prima persona come Puppeteer possa sbloccare dati che gli scraper tradizionali si lasciano sfuggire. Ma ho visto anche quanto il codice possa diventare un ostacolo per chi lavora in azienda. In questa guida ti mostrerò esattamente cos’è uno scraper Puppeteer, come usarlo per il web scraping e quando potrebbe convenirti qualcosa di ancora più semplice, come , il nostro web scraper no-code basato su AI.
Cos’è Puppeteer Scraper? Una panoramica rapida
 Partiamo dalle basi. è una libreria open-source per Node.js di Google che ti permette di controllare un browser Chrome o Chromium headless usando JavaScript. In parole semplici: è come avere un robot che può aprire pagine web, cliccare pulsanti, compilare moduli, scorrere e, soprattutto, estrarre dati, tutto senza mostrare nulla sullo schermo.
Partiamo dalle basi. è una libreria open-source per Node.js di Google che ti permette di controllare un browser Chrome o Chromium headless usando JavaScript. In parole semplici: è come avere un robot che può aprire pagine web, cliccare pulsanti, compilare moduli, scorrere e, soprattutto, estrarre dati, tutto senza mostrare nulla sullo schermo.
Perché Puppeteer è speciale?
- Può renderizzare contenuti dinamici: in pratica aspetta che JavaScript finisca di caricare, proprio come farebbe un utente reale.
- Può simulare le azioni dell’utente: clic, digitazione, scroll e persino la gestione dei popup.
- È perfetto per fare scraping di siti in cui i dati compaiono solo dopo un’interazione, come inserzioni e-commerce, feed social o dashboard.
Come si confronta con altri strumenti?
- Selenium: il veterano dell’automazione del browser. Funziona con molti browser e linguaggi, ma è più pesante e un po’ più datato. Ottimo per il test cross-browser, ma Puppeteer è più agile per progetti Chrome/Node.js.
- Thunderbit: qui mi entusiasmo. Thunderbit è un web scraper no-code, basato su AI, che vive nel browser. Invece di scrivere script, ti basta cliccare “AI Suggest Fields” e lasciare che l’AI capisca cosa estrarre. È perfetto per chi in azienda vuole risultati senza codice (ne parleremo tra poco).
In breve: Puppeteer = controllo massimo (se sai programmare). Thunderbit = comodità massima (se non vuoi programmare).
Perché il web scraping con Puppeteer è importante per chi lavora in azienda
Diciamolo chiaramente: il web scraping non è più solo roba da hacker o data scientist. Team sales, operations, marketing e persino real estate usano i dati del web per avere un vantaggio. E con così tante informazioni critiche bloccate dietro siti dinamici, Puppeteer è spesso la chiave per sbloccarle.
Ecco alcuni casi d’uso concreti:
| Caso d’uso | Chi ne beneficia | Impatto / ROI |
|---|---|---|
| Generazione di lead | Sales, Business Development | Automatizza la creazione di liste prospect; risparmia oltre 8 ore a settimana per commerciale (case study) |
| Monitoraggio prezzi | E-commerce, Product Ops | Tracciamento in tempo reale dei concorrenti; un’azienda ha risparmiato 3,8 milioni di dollari l’anno (source) |
| Ricerche di mercato | Marketing, Strategy, Finance | Il 67% dei consulenti finanziari usa dati estratti dal web; in alcuni casi il ROI arriva fino al 890% (source) |
| Aggregazione immobiliare | Agenti, analisti | Estrai dati da oltre 50 pagine immobiliari in pochi minuti, non in ore (source) |
| Monitoraggio della compliance | Operations, Legal | Automatizza il controllo; una compagnia assicurativa ha evitato 50 milioni di dollari di sanzioni (source) |
E non dimentichiamolo: dedica un quarto della settimana ad attività ripetitive come la raccolta dati. Automatizzare questo processo con il web scraping non è solo un vantaggio in più: è un vero vantaggio competitivo.
Per iniziare: configurare il tuo scraper Puppeteer
Pronto a rimboccarti le maniche? Ecco come far partire Puppeteer in meno di 10 minuti (ammesso che tu abbia un minimo di confidenza con JavaScript):
1. Installa Node.js
Puppeteer gira su Node.js. Scarica l’ultima versione LTS da .
2. Crea una nuova cartella di progetto
Apri il terminale ed esegui:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Installa Puppeteer
1npm install puppeteerQuesto scaricherà anche una versione compatibile di Chromium (circa 100 MB).
4. Crea il tuo primo script
Crea un file chiamato scrape.js:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Titolo della pagina:', title);
8 await browser.close();
9})();Eseguilo con:
1node scrape.jsSe vedi “Titolo della pagina: Example Domain”, complimenti: hai appena automatizzato Chrome!
Costruire il tuo primo script di web scraping con Puppeteer
Passiamo alla pratica. Supponiamo che tu voglia estrarre delle citazioni da (un sito demo per gli scraper).
Passo 1: vai alla pagina
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Passo 2: estrai i dati
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Passo 3: gestisci la paginazione
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Estrai le citazioni come sopra
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Passo 4: salva in JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));Ed ecco fatto: uno scraper Puppeteer di base che naviga, estrae, gestisce la paginazione e salva i dati.
Tecniche avanzate per Puppeteer scraper: gestire contenuti dinamici
La maggior parte dei siti reali non è semplice come un elenco statico. Ecco come affrontare le situazioni più ostiche:
1. Attendere elementi dinamici
1await page.waitForSelector('.product-list-item');Questo garantisce che il contenuto desiderato sia caricato prima di provare a estrarlo.
2. Simulare le azioni dell’utente
- Cliccare un pulsante:
await page.click('#load-more'); - Digitare in un campo:
await page.type('#search', 'laptop'); - Scorrere per infinite scroll:
1// Nota: page.waitForTimeout è stato rimosso in Puppeteer v22. Usa invece una semplice promise. 2const sleep = (ms) => new Promise(r => setTimeout(r, ms)); 3let previousHeight = await page.evaluate('document.body.scrollHeight'); 4while (true) { 5 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 6 await sleep(1500); 7 const newHeight = await page.evaluate('document.body.scrollHeight'); 8 if (newHeight === previousHeight) break; 9 previousHeight = newHeight; 10}
1**3. Gestire i login**
2```javascript
3await page.goto('https://exampleshop.com/login');
4await page.type('#login-username', 'myusername');
5await page.type('#login-password', 'mypassword');
6await page.click('#login-button');
7await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Gestire dati caricati via AJAX A volte i dati non sono nel DOM ma arrivano da una chiamata API. Puoi intercettare le risposte di rete con:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Elabora i dati
5 }
6});Esempio reale: estrarre dati prodotto da un sito e-commerce
Mettiamo tutto insieme. Immagina di voler estrarre nomi prodotto, prezzi e immagini da un sito e-commerce (demo) dopo aver effettuato l’accesso.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Passo 1: accedi
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Passo 2: vai alla pagina della categoria
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Passo 3: estrai i prodotti
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Passo 4: salva in JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Questo script effettua il login, naviga, estrae e salva tutto in automatico. Per esigenze più avanzate, puoi aggiungere cicli per la paginazione o persino aprire la scheda di ogni prodotto per raccogliere più dettagli.
Thunderbit: rendere lo scraper Puppeteer più semplice con l’AI
Se sei arrivato fin qui e stai pensando: “Bello, ma non voglio scrivere codice ogni volta che mi serve un nuovo dataset”, non sei il solo. È esattamente per questo che abbiamo creato .
Cosa rende Thunderbit diverso?
- Nessun codice richiesto: installa semplicemente la , apri la pagina che vuoi estrarre e clicca “AI Suggest Fields”.
- Rilevamento dei campi basato su AI: Thunderbit legge la pagina e suggerisce le colonne migliori da estrarre, come “Nome prodotto”, “Prezzo”, “Immagine” e così via.
- Gestione dei contenuti dinamici: scroll infinito, popup e sottopagine? L’AI di Thunderbit può gestirli, cliccando attraverso la paginazione o visitando persino la pagina dettagli di ogni prodotto per arricchire i dati.
- Export immediato: invia i dati direttamente a Excel, Google Sheets, Notion o Airtable con un solo clic. Nessun costo extra per l’export.
- Template per i siti più popolari: devi estrarre dati da Amazon, Zillow o LinkedIn? Thunderbit ha template pronti all’uso, senza configurazione.
- Scraping da cloud o da browser: per i lavori più grandi, Thunderbit può estrarre fino a 50 pagine in contemporanea nel cloud.
Ho visto utenti passare da “vorrei poter ottenere questi dati” a “ecco il mio foglio di calcolo” in meno di cinque minuti. E la cosa migliore? Niente più preoccupazioni per script che si rompono quando il sito cambia: l’AI di Thunderbit si adatta al volo.
Puppeteer vs Thunderbit: scegliere lo strumento giusto per il web scraping
Quindi, quale dovresti usare? Ecco come lo valuterei per i team:
| Fattore | Puppeteer (codice) | Thunderbit (no-code, AI) |
|---|---|---|
| Facilità d’uso | Richiede JavaScript e conoscenza del DOM | Punto e clic, l’AI suggerisce i campi |
| Velocità di setup | Da ore a giorni per attività complesse | Minuti: installa e via |
| Controllo/Flessibilità | Massimo: puoi scrivere logiche personalizzate e integrarlo con altro codice | Alto per i casi standard; meno adatto a workflow molto personalizzati |
| Contenuti dinamici | Script manuali per attese, clic e scroll | L’AI integrata gestisce automaticamente contenuti dinamici, paginazione e sottopagine |
| Manutenzione | Gli script sono tuoi: vanno aggiornati quando i siti cambiano | L’AI si adatta ai cambi di layout; meno manutenzione per l’utente |
| Export dei dati | Devi scrivere tu la logica di esportazione | Export con un clic verso Excel, Sheets, Notion, Airtable, CSV, JSON |
| Ideale per | Sviluppatori, scraping molto personalizzato o su larga scala | Utenti business, progetti rapidi, team non tecnici |
| Costo | Gratis (a parte il tuo tempo e l’infrastruttura) | Piano gratuito disponibile; piani a pagamento basati su crediti (vedi Thunderbit Pricing) |
In sintesi:
- Usa Puppeteer se ti serve controllo totale, hai risorse di sviluppo o vuoi integrare lo scraping in un’app più ampia.
- Usa Thunderbit se vuoi risultati rapidi, non vuoi programmare o devi dare potere a colleghi non tecnici.
Onestamente, ho visto team usare entrambi: Thunderbit per i risultati rapidi e la prototipazione, Puppeteer per integrazioni profonde o casi limite.
Checklist passo passo: come far partire con successo un progetto di web scraping con Puppeteer
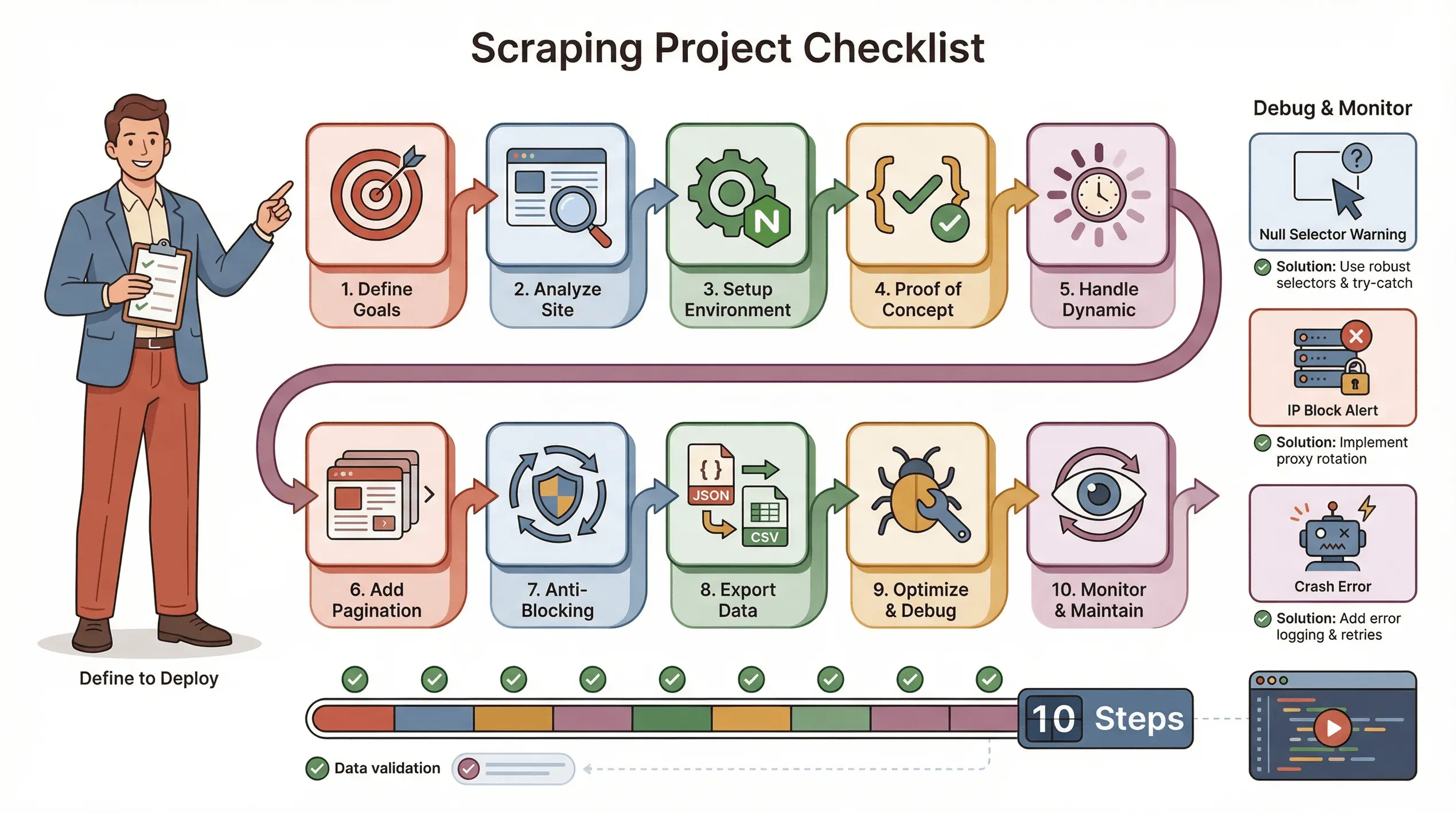 Ecco la mia checklist di riferimento per un progetto di scraping con Puppeteer senza intoppi:
Ecco la mia checklist di riferimento per un progetto di scraping con Puppeteer senza intoppi:
- Definisci gli obiettivi: di quali dati hai bisogno? Dove si trovano?
- Analizza il sito: è dinamico? Richiede login? Ci sono misure anti-bot?
- Configura l’ambiente: Node.js, Puppeteer e tutte le librerie di supporto.
- Scrivi una proof of concept: parti da una sola pagina e individua i selettori giusti.
- Gestisci i contenuti dinamici: usa
waitForSelector, simula clic e scroll quando serve. - Aggiungi paginazione o cicli: estrai tutte le pagine, non solo una.
- Implementa tecniche anti-blocco: randomizza i ritardi, imposta un vero User-Agent, usa proxy se necessario.
- Esporta e valida i dati: salva in JSON/CSV e controlla che tutto sia completo.
- Ottimizza e gestisci gli errori: aggiungi try/catch, registra l’avanzamento e gestisci i dati mancanti con grazia.
- Monitora e mantieni: i siti cambiano, quindi preparati ad aggiornare lo script.
Consigli per il troubleshooting:
- Se i selettori restituiscono
null, ricontrolla l’HTML e usa le attese. - Se vieni bloccato, rallenta, ruota gli IP o usa plugin stealth.
- Se lo script va in crash, controlla eventuali memory leak o eccezioni non gestite.
Conclusione e punti chiave
Il web scraping è ormai una competenza indispensabile per i team data-driven. Puppeteer ti offre la potenza per estrarre dati anche dai siti più dinamici e ricchi di JavaScript, ma richiede un minimo di competenze di programmazione e manutenzione continua. Per chi in azienda vuole saltare il codice e arrivare subito ai dati, Thunderbit offre un’alternativa no-code basata su AI, veloce, flessibile e sorprendentemente robusta.
Ecco cosa ti consiglierei:
- Se sei tecnico e hai bisogno di una personalizzazione profonda, parti da Puppeteer.
- Se vuoi velocità, semplicità e meno manutenzione, prova (la è un ottimo punto di partenza).
- Per la maggior parte dei team, una combinazione di entrambi coprirà il 99% delle esigenze di dati dal web.
Vuoi vedere altre guide come questa? Dai un’occhiata al per tutorial, confronti e le ultime novità sul web scraping basato su AI.
FAQ
1. Cos’è uno scraper Puppeteer e perché si usa per il web scraping?
Puppeteer è una libreria Node.js che ti permette di controllare un browser Chrome headless con JavaScript. Si usa per il web scraping perché può caricare contenuti dinamici, simulare le azioni dell’utente ed estrarre dati da siti che gli scraper tradizionali non riescono a gestire.
2. Come si confronta Puppeteer con Selenium e Thunderbit?
Selenium funziona con più browser e linguaggi, ma è più pesante. Puppeteer è più snello per Chrome/Node.js ed è più veloce in molte attività di scraping. Thunderbit, invece, è uno strumento no-code basato su AI che consente anche a chi non è tecnico di estrarre dati in pochi clic.
3. Quali sono i principali vantaggi business del web scraping con Puppeteer?
Automatizzare la raccolta dati fa risparmiare tempo, riduce gli errori e permette insight in tempo reale per sales, marketing, operations e altro ancora. I casi d’uso vanno dalla generazione di lead al monitoraggio prezzi e alle ricerche di mercato.
4. Quali sono le sfide principali nello scraping con Puppeteer?
Le sfide principali sono gestire i contenuti dinamici, evitare i blocchi anti-bot e mantenere gli script quando i siti cambiano. Dovrai scrivere codice per gestire le attese, simulare le interazioni e trattare gli errori.
5. Quando dovrei usare Thunderbit invece di Puppeteer?
Usa Thunderbit se vuoi evitare di programmare, se ti servono risultati rapidi o se vuoi aiutare i colleghi non tecnici. È ideale per attività di scraping standard, progetti rapidi o quando vuoi esportare dati in Excel o Google Sheets con il minimo sforzo.
Pronto a provare un modo più intelligente di fare scraping? oppure approfondisci con altre guide nel . Buon scraping!
Scopri di più