I dati sul web stanno esplodendo a velocità pazzesca, e con loro cresce anche la pressione di non restare indietro. Mi è capitato di vedere team sales e operations passare più tempo a “domare” fogli di calcolo e a fare copia-incolla dai siti che a prendere decisioni vere. Secondo Salesforce, i commerciali oggi dedicano , e Asana riporta che . Sono ore e ore bruciate nella raccolta manuale dei dati—tempo che potresti investire per chiudere deal o far partire campagne.
La buona notizia? Oggi il web scraping è davvero alla portata di tutti: non devi per forza essere uno sviluppatore per sfruttarlo. Ruby è da anni uno dei linguaggi più amati per automatizzare l’estrazione dati dal web, ma se lo affianchi a un moderno estrattore web ai come , ti porti a casa il meglio di due mondi: la flessibilità per chi fa web scraping con ruby e la semplicità da web scraper no code per chi vuole solo arrivare al risultato. Che tu sia marketer, responsabile ecommerce o semplicemente stufo del copia-incolla infinito, questa guida ti fa vedere come dominare il web scraping con Ruby e l’AI—anche senza scrivere codice.
Che cos’è il web scraping con Ruby? La porta d’accesso ai dati automatizzati
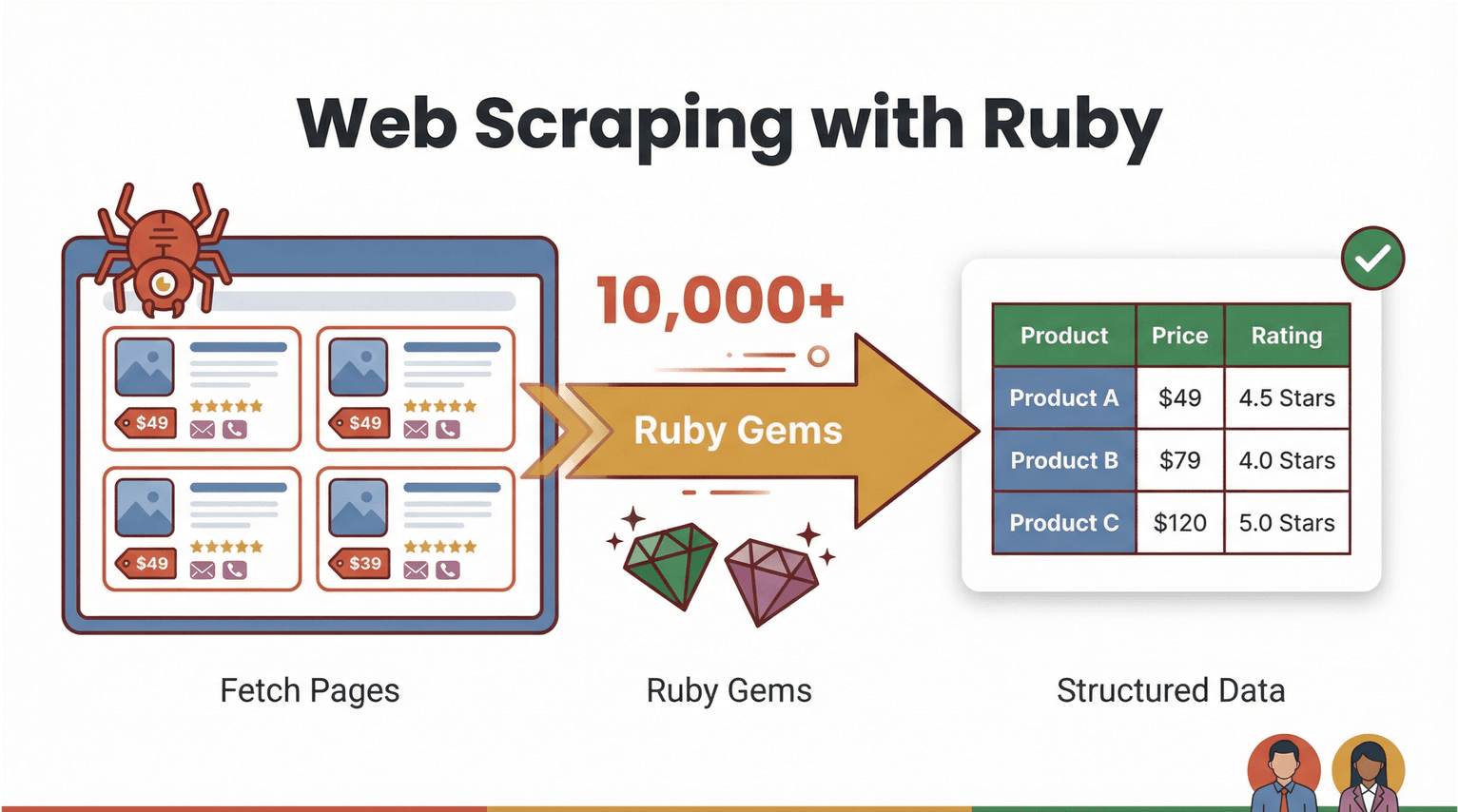
Partiamo dalle basi, senza giri di parole. Il web scraping è il processo con cui un software visita pagine web ed estrae informazioni specifiche—tipo prezzi, contatti o recensioni—per trasformarle in un formato strutturato (CSV, Excel, ecc.). Con Ruby, fare web scraping è potente ma anche abbastanza “umano”: il linguaggio è famoso per la sintassi leggibile e per un ecosistema enorme di “gem” (librerie) che rendono l’automazione molto più scorrevole ().
Ma com’è, in pratica, fare web scraping con ruby? Immagina di voler estrarre nomi e prezzi dei prodotti da un ecommerce. Con Ruby puoi scrivere uno script che:
- Scarica la pagina web (con una libreria come )
- Analizza l’HTML per pescare i dati che ti servono (con )
- Esporta tutto in un foglio di calcolo o in un database
E qui arriva la parte più interessante: non sempre devi scrivere codice. Gli strumenti no-code e gli estrattore web ai come oggi fanno il “lavoro sporco”—leggono le pagine, riconoscono i campi e ti tirano fuori tabelle pulite esportabili con un paio di clic. Ruby resta una colla perfetta per automatizzare flussi su misura, ma gli estrattori web ai stanno aprendo le porte anche a chi lavora in business.
Perché il web scraping con Ruby è importante per i team business

Diciamocelo: nessuno sogna di passare la giornata a copiare e incollare dati. La domanda di estrazione automatizzata dal web sta crescendo a razzo, e non è un caso. Ecco come il web scraping con Ruby (e gli strumenti AI) sta cambiando le operazioni aziendali:
- Lead generation: estrai al volo contatti da directory o LinkedIn per riempire la pipeline.
- Monitoraggio prezzi dei competitor: segui le variazioni di prezzo su centinaia di SKU ecommerce—senza controlli manuali.
- Creazione cataloghi prodotto: aggrega dettagli e immagini per il tuo store o marketplace.
- Ricerche di mercato: raccogli recensioni, valutazioni o articoli per analisi di trend.
Il ritorno è lampante: chi automatizza la raccolta dati dal web risparmia ore ogni settimana, riduce gli errori e lavora con dati più freschi e affidabili. Nel manifatturiero, per esempio, , anche se il volume di dati è raddoppiato in soli due anni. Tradotto: un’enorme occasione per automatizzare.
Ecco un riepilogo rapido di come Ruby e gli strumenti AI creano valore:
| Caso d’uso | Problema del lavoro manuale | Vantaggio dell’automazione | Risultato tipico |
|---|---|---|---|
| Lead generation | Copiare email una per una | Estrarre migliaia in pochi minuti | 10x lead, meno lavoro ripetitivo |
| Monitoraggio prezzi | Controlli quotidiani sui siti | Estrazioni programmate e automatiche | Intelligence prezzi in tempo reale |
| Creazione cataloghi | Inserimento dati manuale | Estrazione massiva e formattazione | Lancio più rapido, meno errori |
| Ricerche di mercato | Leggere recensioni a mano | Raccolta e analisi su larga scala | Insight più profondi e aggiornati |
E non è solo una questione di velocità: automatizzare significa anche meno errori e dati più coerenti—fondamentale quando .
Soluzioni di web scraping: script Ruby vs strumenti Estrattore Web AI
Quindi: conviene scrivere uno script Ruby o usare un estrattore web ai in modalità web scraper no code? Mettiamo le carte in tavola.
Scripting Ruby: controllo totale, più manutenzione
L’ecosistema Ruby è pieno di gem per praticamente ogni scenario di scraping:
- : lo standard per analizzare HTML e XML.
- : per recuperare pagine web e API.
- : utile quando servono cookie, form e navigazione.
- / : per automatizzare browser reali (perfetto per siti pieni di JavaScript).
Con gli script Ruby hai massima libertà—logica personalizzata, pulizia dati, integrazione con i tuoi sistemi. Però ti prendi anche la manutenzione: se un sito cambia layout, lo script può rompersi. E se non mastichi codice, c’è una curva di apprendimento da mettere in conto.
Estrattori Web AI e strumenti no-code: rapidi, intuitivi e più adattivi
Gli strumenti no-code moderni come ribaltano l’approccio. Invece di scrivere codice, fai così:
- Apri l’estensione Chrome
- Clicca “AI Suggest Fields” per far capire all’AI cosa estrarre
- Premi “Scrape” ed esporta i dati
L’AI di Thunderbit si adatta ai cambiamenti di layout, gestisce le sottopagine (tipo i dettagli prodotto) ed esporta direttamente su Excel, Google Sheets, Airtable o Notion. È l’ideale per chi lavora in azienda e vuole risultati senza sbattimenti.
Confronto rapido:
| Approccio | Pro | Contro | Ideale per |
|---|---|---|---|
| Scripting Ruby | Controllo totale, logica custom, flessibile | Curva più ripida, manutenzione | Sviluppatori, utenti avanzati |
| Estrattore Web AI | No-code, setup veloce, si adatta ai cambiamenti | Meno controllo fine, alcuni limiti | Utenti business, team ops |
La direzione è abbastanza chiara: con siti sempre più complessi (e spesso “difensivi”), gli estrattori web ai stanno diventando la prima scelta per tanti flussi di lavoro.
Per iniziare: configurare l’ambiente Ruby per il web scraping
Se vuoi provare lo scripting Ruby, prepariamo l’ambiente. La cosa bella è che Ruby si installa senza drammi e gira su Windows, macOS e Linux.
Step 1: installa Ruby
- Windows: scarica e segui la procedura. Assicurati di includere MSYS2 per compilare estensioni native (serve per gem come Nokogiri).
- macOS/Linux: usa per gestire le versioni. In Terminale:
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(Controlla la per l’ultima versione stabile.)
Step 2: installa Bundler e le gem essenziali
Bundler ti aiuta a gestire le dipendenze:
1gem install bundlerCrea un Gemfile per il progetto:
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'Poi esegui:
1bundle installCosì l’ambiente resta coerente e pronto per lo scraping.
Step 3: verifica la configurazione
Prova questo in IRB (la shell interattiva di Ruby):
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSIONSe vedi un numero di versione, sei a posto.
Passo dopo passo: creare il tuo primo web scraper in Ruby
Vediamo un esempio concreto: estrarre dati prodotto da , un sito fatto apposta per esercitarsi.
Ecco uno script Ruby semplice per estrarre titoli, prezzi e disponibilità:
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #\{res.code\} for #\{url\}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#\{BASE_URL\}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #\{rows.length\} rows to books.csv"Lo script scarica ogni pagina, analizza l’HTML, estrae i dati e li salva in un CSV. Poi puoi aprire books.csv in Excel o Google Sheets.
Errori comuni:
- Se compaiono errori su gem mancanti, ricontrolla il Gemfile ed esegui
bundle install. - Se un sito carica i dati via JavaScript, ti servirà un tool di automazione browser come Selenium o Watir.
Potenziare lo scraping con Ruby grazie a Thunderbit: Estrattore Web AI in azione
Ora vediamo come può portare lo scraping a un livello superiore—senza scrivere codice.
Thunderbit è un’ che ti permette di estrarre dati strutturati da qualsiasi sito in due clic. Funziona così:
- Apri l’estensione Thunderbit sulla pagina che vuoi estrarre.
- Clicca “AI Suggest Fields”. L’AI analizza la pagina e propone le colonne migliori (ad esempio “Nome prodotto”, “Prezzo”, “Disponibilità”).
- Clicca “Scrape”. Thunderbit raccoglie i dati, gestisce la paginazione e può anche seguire le sottopagine se ti servono più dettagli.
- Esporta i dati direttamente su Excel, Google Sheets, Airtable o Notion.
Quello che rende Thunderbit diverso è la capacità di gestire pagine complesse e dinamiche—senza selettori fragili né codice. E se vuoi unire i flussi, puoi estrarre con Thunderbit e poi elaborare o arricchire i dati con uno script Ruby.
Consiglio pro: la funzione di scraping delle sottopagine di Thunderbit è oro colato per team ecommerce e real estate. Estrai una lista di link prodotto, poi lascia che Thunderbit visiti ogni pagina per recuperare specifiche, immagini o recensioni—arricchendo automaticamente il dataset.
Esempio reale: estrarre dati prodotto e prezzi ecommerce con Ruby e Thunderbit
Mettiamo tutto insieme con un flusso pratico pensato per i team ecommerce.
Scenario: vuoi monitorare prezzi e dettagli prodotto dei competitor su centinaia di SKU.
Step 1: usa Thunderbit per estrarre la lista principale dei prodotti
- Apri la pagina di listing del competitor.
- Avvia Thunderbit e clicca “AI Suggest Fields” (es. Nome prodotto, Prezzo, URL).
- Clicca “Scrape” ed esporta in CSV.
Step 2: arricchisci i dati con lo scraping delle sottopagine
- In Thunderbit, usa “Scrape Subpages” per visitare la pagina dettaglio di ogni prodotto ed estrarre campi aggiuntivi (come descrizione, disponibilità o immagini).
- Esporta la tabella arricchita.
Step 3: elabora o analizza con Ruby
- Usa uno script Ruby per pulire, trasformare o analizzare ulteriormente i dati. Ad esempio potresti:
- Convertire i prezzi in una valuta standard
- Filtrare i prodotti non disponibili
- Generare statistiche riassuntive
Ecco un semplice snippet Ruby per filtrare i prodotti disponibili:
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6endRisultato:
passi da pagine web “grezze” a una tabella pulita e pronta all’uso—perfetta per analisi prezzi, pianificazione inventario o campagne marketing. E lo fai senza scrivere una sola riga di codice di scraping.
No-code? Nessun problema: estrazione dati dal web automatizzata per tutti
Una delle cose che apprezzo di più di Thunderbit è che sblocca anche chi non è tecnico. Non serve conoscere Ruby, HTML o CSS: apri l’estensione, lasci lavorare l’AI ed esporti i dati.
Curva di apprendimento: con gli script Ruby devi imparare le basi della programmazione e capire la struttura delle pagine web. Con Thunderbit, il setup richiede minuti, non giorni.
Integrazioni: Thunderbit esporta direttamente negli strumenti che i team usano già—Excel, Google Sheets, Airtable, Notion. Puoi anche programmare estrazioni ricorrenti per un monitoraggio continuo.
Feedback utenti: ho visto team marketing, sales ops e responsabili ecommerce automatizzare di tutto—dalla creazione di liste lead al tracking prezzi—senza mai coinvolgere l’IT.
Best practice: combinare Ruby e un Estrattore Web AI per un’automazione scalabile
Vuoi un flusso di scraping solido e scalabile? Ecco i consigli più importanti:
- Gestire i cambiamenti dei siti: gli estrattori web ai come Thunderbit si adattano automaticamente; con gli script Ruby, preparati ad aggiornare i selettori quando i siti cambiano.
- Programmare le estrazioni: usa la funzione di pianificazione di Thunderbit per raccolte regolari. Con Ruby, imposta un cron job o un task scheduler.
- Elaborazione a lotti: con dataset grandi, dividi lo scraping in batch per ridurre il rischio di blocchi o sovraccarichi.
- Formattazione dati: pulisci e valida sempre i dati prima dell’analisi—le esportazioni di Thunderbit sono strutturate, ma gli script Ruby custom possono richiedere controlli extra.
- Conformità: estrai solo dati pubblici, rispetta
robots.txte fai attenzione alle norme sulla privacy (soprattutto in UE—). - Strategie di fallback: se un sito diventa troppo complesso o blocca lo scraping, valuta API ufficiali o fonti alternative.
Quando usare cosa?
- Usa gli script Ruby quando ti serve controllo totale, logica personalizzata o integrazione con sistemi interni.
- Usa Thunderbit quando vuoi velocità, facilità e adattabilità—soprattutto per attività business una tantum o ricorrenti.
- Combina entrambi per flussi avanzati: Thunderbit per l’estrazione, Ruby per arricchimento, QA o integrazione.
Conclusione e punti chiave
Il web scraping con ruby è da sempre un superpotere per automatizzare la raccolta dati—ma oggi, con gli estrattori web ai come Thunderbit, questa potenza è accessibile a chiunque. Che tu sia uno sviluppatore in cerca di flessibilità o un utente business che vuole solo risultati, puoi automatizzare l’estrazione dal web, risparmiare ore di lavoro manuale e prendere decisioni migliori e più rapide.
Ecco cosa vorrei ti restasse:
- Ruby è uno strumento eccellente per web scraping e automazione, soprattutto con gem come Nokogiri e HTTParty.
- Gli Estrattori Web AI come Thunderbit rendono l’estrazione dati accessibile anche a chi non programma, grazie a funzioni come “AI Suggest Fields” e lo scraping delle sottopagine.
- Combinare Ruby e Thunderbit ti dà il meglio di entrambi i mondi: estrazione rapida no-code + automazione e analisi personalizzate.
- Automatizzare la raccolta dati dal web è una strategia vincente per sales, marketing ed ecommerce: meno lavoro manuale, più precisione e nuovi insight.
Vuoi partire subito? , prova uno script Ruby semplice e scopri quanto tempo puoi risparmiare. E se vuoi approfondire, visita il per altre guide, consigli ed esempi reali.
FAQ
1. Devo saper programmare per usare Thunderbit per il web scraping?
No. Thunderbit è pensato per utenti non tecnici. Ti basta aprire l’estensione, cliccare “AI Suggest Fields” e lasciare che l’AI faccia il resto. Puoi esportare su Excel, Google Sheets, Airtable o Notion—senza scrivere codice.
2. Quali sono i principali vantaggi di Ruby per il web scraping?
Ruby offre librerie potenti come Nokogiri e HTTParty per creare flussi di scraping flessibili e su misura. È ideale per sviluppatori che vogliono controllo completo, logica personalizzata e integrazioni con altri sistemi.
3. Come funziona la funzione “AI Suggest Fields” di Thunderbit?
L’AI di Thunderbit analizza la pagina, individua i campi più rilevanti (come nomi prodotto, prezzi, email) e propone una tabella strutturata. Prima di estrarre, puoi modificare le colonne secondo necessità.
4. Posso combinare Thunderbit con script Ruby per flussi avanzati?
Certo. Molti team usano Thunderbit per estrarre dati (soprattutto da siti complessi o dinamici) e poi li elaborano o analizzano con script Ruby. Questo approccio ibrido è ottimo per report personalizzati o arricchimento dati.
5. Il web scraping è legale e sicuro per l’uso aziendale?
Il web scraping è legale quando raccogli dati pubblicamente disponibili e rispetti termini di servizio e leggi sulla privacy. Controlla sempre robots.txt ed evita di estrarre dati personali senza consenso—soprattutto per utenti UE soggetti al GDPR.
Vuoi vedere come il web scraping può cambiare il tuo modo di lavorare? Prova il piano gratuito di Thunderbit o sperimenta oggi stesso con uno script Ruby. E se ti blocchi, il e il sono pieni di tutorial e consigli per aiutarti a padroneggiare l’automazione dei dati dal web—senza bisogno di codice.
Approfondisci