Tumblr Scraper
Dipercaya para profesional di perusahaan terkemuka














Buka data Tumblr dengan Thunderbit
Ekstrak data Tumblr seperti isi postingan dan jumlah like dengan mudah.
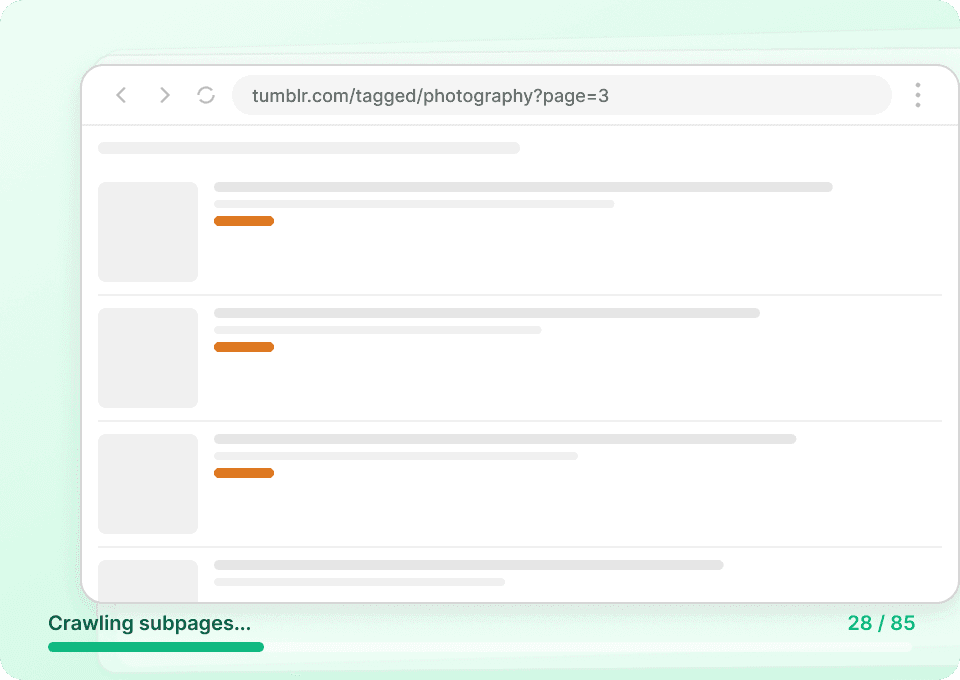
Dapatkan cerita Tumblr secara utuh
Halaman listing Tumblr biasanya hanya menampilkan cuplikan. Untuk mendapatkan gambaran lengkap, Anda perlu isi postingan secara penuh, detail penulis, dan semua data terkait. Thunderbit otomatis membuka setiap subpage yang terhubung, mengekstrak detailnya, lalu menambahkannya sebagai kolom baru, sehingga Anda bisa dengan mudah mengambil post_id, post_date, dan lainnya tanpa klik manual.
Otomatiskan pengumpulan data Tumblr Anda
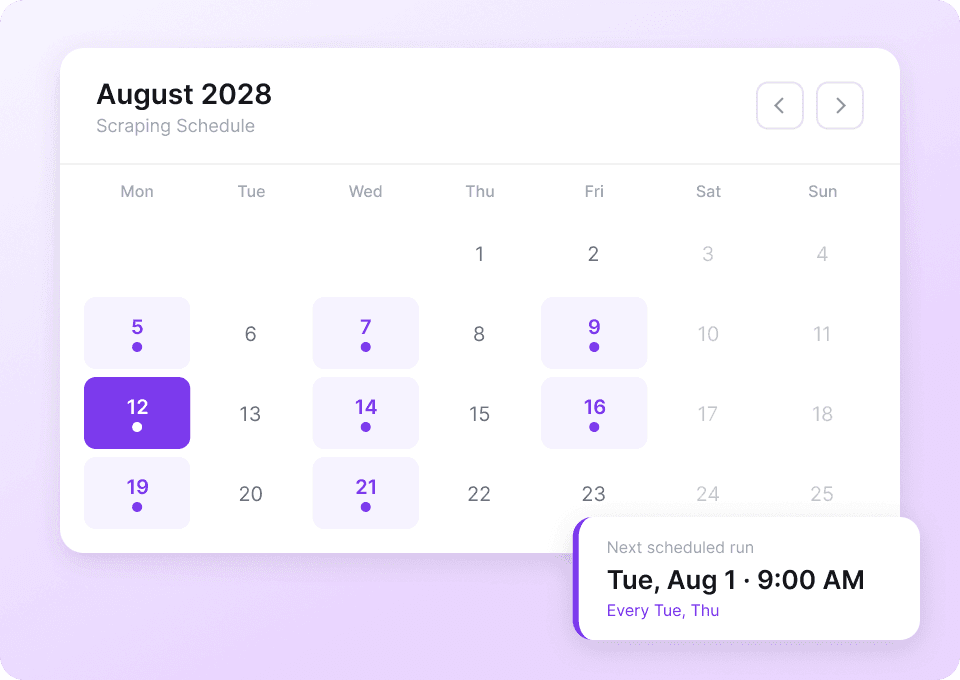
Data Tumblr terus berubah. Men-scrape blog yang sama berulang kali secara manual tentu melelahkan. Dengan scheduled scraping dari Thunderbit, Anda bisa menyiapkan tugas berulang yang berjalan otomatis. Dapatkan data terbaru seperti like_count dan post_content langsung ke Google Sheets tanpa perlu repot.
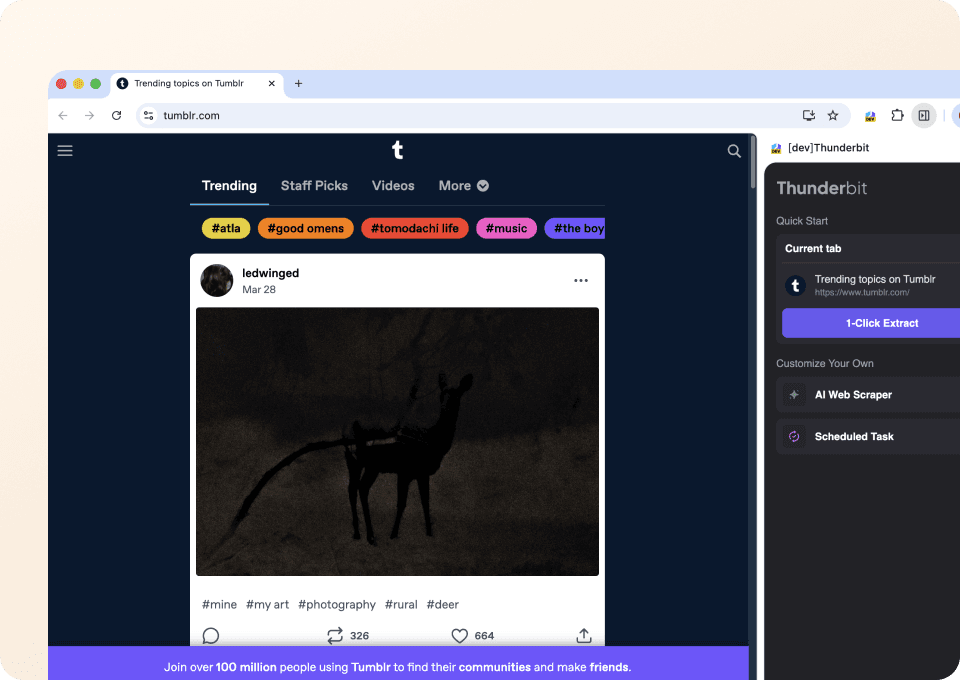
Scrape postingan Tumblr dalam dua klik
Lupakan kode rumit atau CSS selector. Thunderbit memungkinkan Anda mengekstrak data Tumblr hanya dalam dua klik. Cukup arahkan ke data yang Anda butuhkan, dan semantic AI Thunderbit akan mendeteksi field yang relevan (seperti post_type dan post_author), lalu mengekstraknya. Tidak perlu coding untuk mendapatkan data yang Anda cari dari Tumblr.
Mengapa Thunderbit berbeda dari tumblr scrapers tradisional?
Ekstrak data Tumblr dengan mudah, bahkan saat layout berubah atau berganti secara tiba-tiba.
Scraper tradisional
Cara lama dalam bekerjaThunderbit AI
Pendekatan yang lebih cerdasJangan hanya percaya kata kami
Lihat apa kata pengguna tentang Thunderbit.






Pertanyaan yang sering diajukan
Terkait use case
Jelajahi lebih banyak use case dari web scraper Thunderbit.

Wikipedia scraper
Dapatkan data infobox Wikipedia, referensi, dan teks artikel ke dalam spreadsheet yang rapi — tanpa kode, AI yang menyusun semuanya untuk Anda.
Pelajari lebih lanjut ->
HKTVmall Scraper
Kumpulkan nama produk, harga, bahkan rating pelanggan dari listing HKTVmall hanya dengan beberapa klik saja — tanpa perlu pengaturan rumit.
Pelajari lebih lanjut ->
Trivago scraper
Scrape nama hotel, harga, dan rating dari Trivago hanya dalam beberapa klik — tanpa coding atau setup apa pun.
Pelajari lebih lanjut ->Substack scraper
Dapatkan jumlah pelanggan Substack, judul artikel, dan deskripsi publikasi ke dalam spreadsheet yang rapi — tanpa kode, AI yang menyusun semuanya.
Pelajari lebih lanjut ->PeopleWhiz scraper
Thunderbit PeopleWhiz Scraper memungkinkan Anda mengekstrak data dari hasil pencarian dan profil PeopleWhiz dengan saran kolom berbasis AI. Kumpulkan nama, detail kontak, lokasi, dan lainnya untuk riset, pemasaran, atau perolehan prospek. Ubah data PeopleWhiz menjadi dataset terstruktur dengan cepat dan efisien.
Pelajari lebih lanjut ->
Coupang scraper
Dapatkan nama produk, harga, dan tingkat diskon dari Coupang dalam dua klik — tanpa perlu coding.
Pelajari lebih lanjut ->Siap meningkatkan ekstraksi datamu?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Uji coba gratis menyediakan kredit tak terbatas untuk 8 halaman web.