News Scraper














Data berita, ditangkap lebih cepat
Tarik data berita yang rapi dari artikel, daftar, dan sumber tanpa kerja manual yang melelahkan.
Dapatkan detail artikel lengkap
Halaman daftar berita hanya memberi Anda teaser. Thunderbit membuka halaman lengkap tiap artikel dan mengambil semua yang penting — judul, ringkasan, penulis, tanggal publikasi, sumber berita, dan bagian. Beralih dari daftar tautan mentah menjadi dataset yang lengkap dan terstruktur tanpa kerja manual yang membosankan.
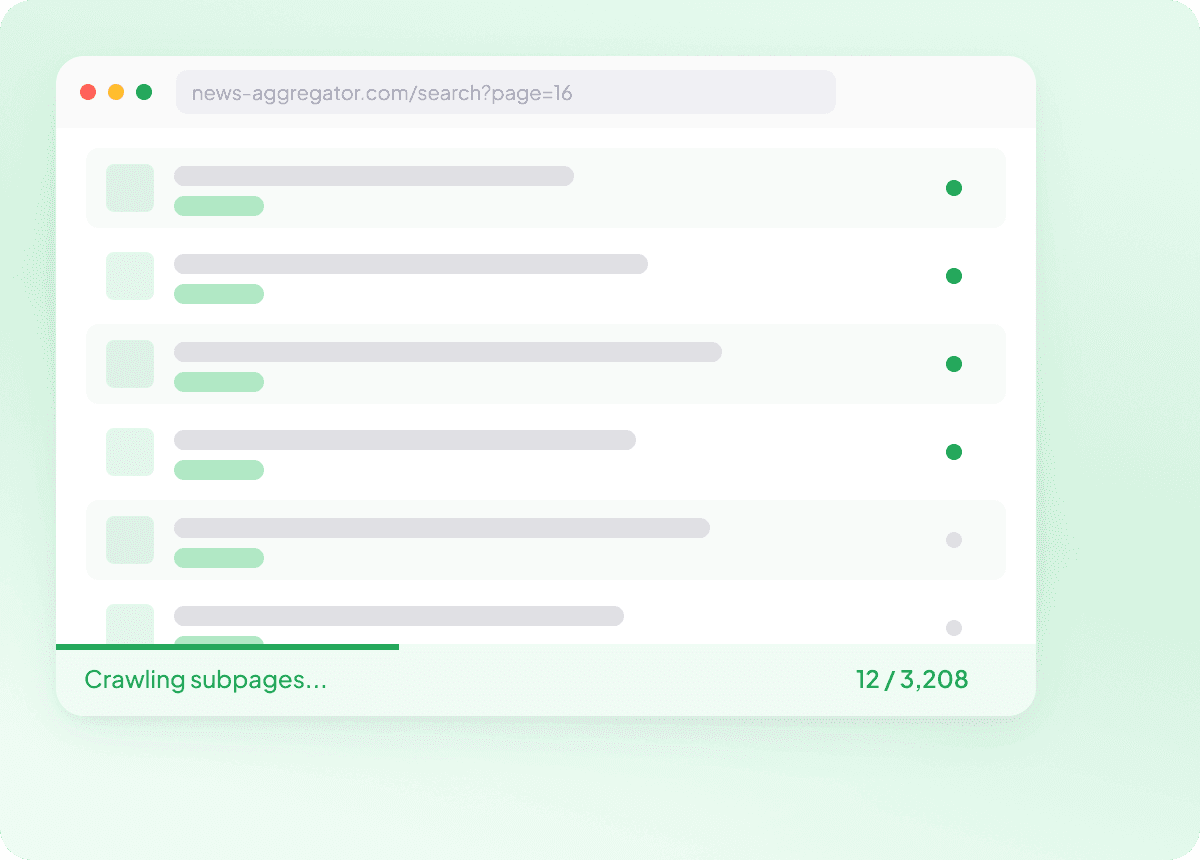
Scrape massal daftar URL News
Scraping satu artikel demi satu bukan alur kerja — itu pekerjaan yang merepotkan. Tempel daftar URL artikel dan Thunderbit akan melakukan scrape massal ratusan halaman dalam satu kali jalan, menangkap semua field yang Anda butuhkan dari setiap cerita. Mengumpulkan dataset berita besar belum pernah semudah ini.

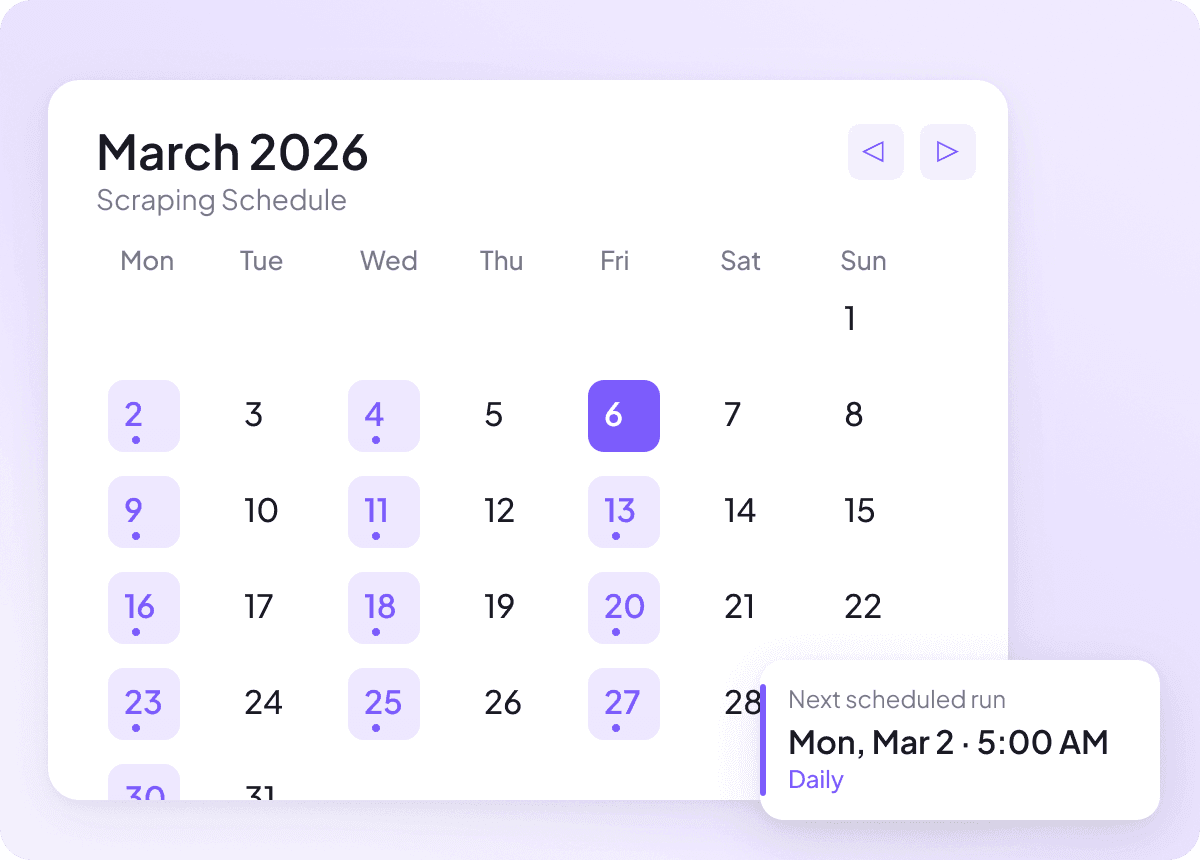
Jaga data News tetap segar
Dunia berita bergerak cepat, dan data kemarin cepat kehilangan nilainya. Jadwalkan scraping Anda dan Thunderbit akan berjalan otomatis — menjaga spreadsheet Anda tetap terisi headline, ringkasan, penulis, tanggal publikasi, sumber, dan bagian terbaru sesuai frekuensi yang Anda tentukan. Update berkala, tanpa usaha manual.
Mengapa Thunderbit berbeda dari news scraper tradisional?
Cara yang lebih cepat untuk mengumpulkan data berita yang berantakan tanpa sering rusak.
Scraper tradisional
Cara lama melakukan pekerjaanThunderbit AI
Pendekatan yang lebih cerdasJangan hanya percaya kata kami
Lihat apa kata pengguna kami tentang Thunderbit.







Pertanyaan yang sering diajukan
Terkait use case
Jelajahi lebih banyak use case web scraper Thunderbit.
Video Scraper
Video Scraper dari Thunderbit membantu Anda mengekstrak data video dan kreator dengan AI hanya dalam beberapa klik. Ambil daftar video, metrik performa, serta detail profil, lalu ekspor ke Excel, Google Sheets, Airtable, atau Notion untuk pelacakan dan riset influencer.
Pelajari lebih lanjut ->
HKTVmall Scraper
Ekstrak nama produk, harga, rating, dan lainnya dari listing HKTVmall hanya dengan 2 klik — tanpa perlu coding. Ekspor langsung ke Excel, Google Sheets, atau Notion, lalu ubah data HKTVmall menjadi insight yang bisa langsung ditindaklanjuti.
Pelajari lebih lanjut ->
Spokeo Scraper Tanpa Kode
Ambil detail lengkap profil Spokeo — nama, usia, alamat, nomor telepon, dan kerabat — hanya dalam 2 klik, lalu ekspor ke Excel, Google Sheets, atau Notion. Tanpa coding, tanpa copy-paste.
Pelajari lebih lanjut ->
Priceline scraper
Ekstrak nama hotel, harga, rating, dan fasilitas dari Priceline dalam 2 klik dengan AI Thunderbit — lalu ekspor data yang rapi dan terstruktur ke Excel, Google Sheets, atau Notion secara instan.
Pelajari lebih lanjut ->
Trivago scraper
Ekstrak nama hotel, harga, rating, dan ulasan dari Trivago dalam 2 klik — lalu ekspor langsung ke Excel, Google Sheets, atau Notion. Tanpa coding, tanpa perlu setting apa pun.
Pelajari lebih lanjut ->Substack scraper
Ekstrak jumlah subscriber Substack, judul artikel, dan deskripsi publikasi hanya dengan 2 klik — lalu ekspor ke Excel, Google Sheets, atau Notion. Tanpa perlu coding; AI Thunderbit akan menangani struktur datanya untuk Anda.
Pelajari lebih lanjut ->Siap meningkatkan ekstraksi datamu?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Uji coba gratis menyediakan kredit tak terbatas untuk 8 halaman web.



