ויקיפדיה סקרייפר














חילוץ נתוני ויקיפדיה בשני קליקים
מצביעים ומחלצים נתוני ויקיפדיה מיד
העתקה ידנית של נתונים מוויקיפדיה היא פעולה מייגעת ונוטה לטעויות. Thunderbit מאפשר לחלץ נתוני תבנית מידע, טקסט של ערכים, קטגוריות ועוד — בלי שום קוד. פשוט מצביעים על הנתון שרוצים, ובקליק שני Thunderbit מזהה את השדות ושולף אותם לטבלה מסודרת. בלי הגדרות מסובכות ובלי CSS selectors.

Thunderbit מסתגל לשינויים במבנה של ויקיפדיה
המבנה של ויקיפדיה משתנה כל הזמן, וסקרייפרים מסורתיים נשברים בכל שינוי כזה. Thunderbit משתמש ב-AI סמנטי כדי להבין את המשמעות של העמוד, ולא רק ב-selectors קבועים. המשמעות היא שהוא מסתגל אוטומטית לשינויים במבנה, כך שאפשר להמשיך לחלץ טקסט מערכים, מקורות ונתונים מובנים בלי לתקן את הסקרייפר כל הזמן.

ייצוא נתוני ויקיפדיה לכלים שלכם
תפסיקו לבזבז זמן על העתקה והדבקה של טבלאות וקישורים חיצוניים מוויקיפדיה לגיליונות שלכם. Thunderbit מאפשר לייצא את הנתונים שחילצתם ל-Excel, ל-Google Sheets, ל-Notion או ל-Airtable בלחיצה אחת. זו הדרך המהירה ביותר להעביר נתונים מובנים מוויקיפדיה לכלים שכבר עובדים איתם.

מתקשים לחלץ נתונים מוויקיפדיה בצורה יעילה?
ראו למה Thunderbit עולה על סקרייפרים מסורתיים לחילוץ נתונים מוויקיפדיה.
סקרייפרים מסורתיים
השיטה הישנהThunderbit
הגישה החכמה יותראל תסתמכו רק על המילה שלנו
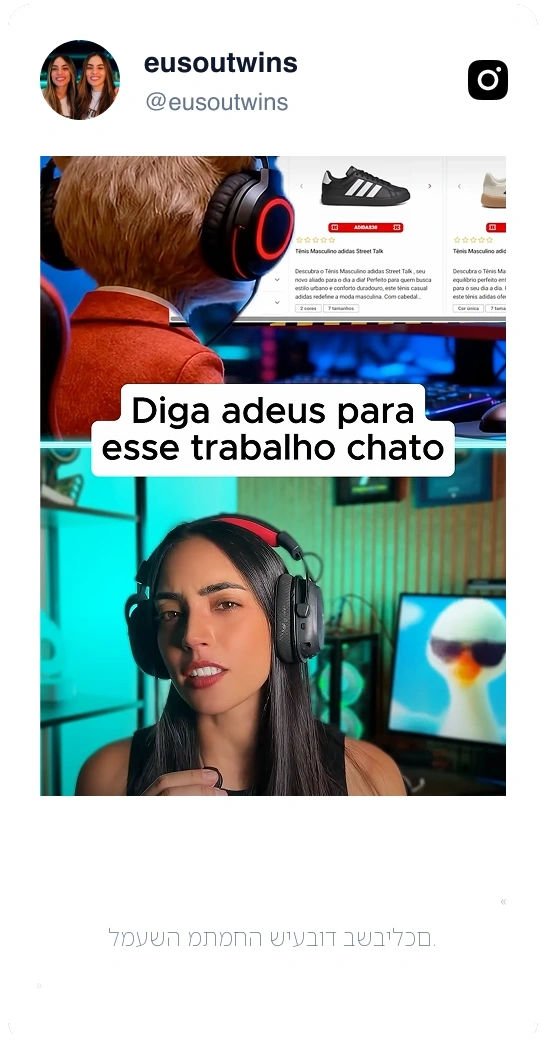
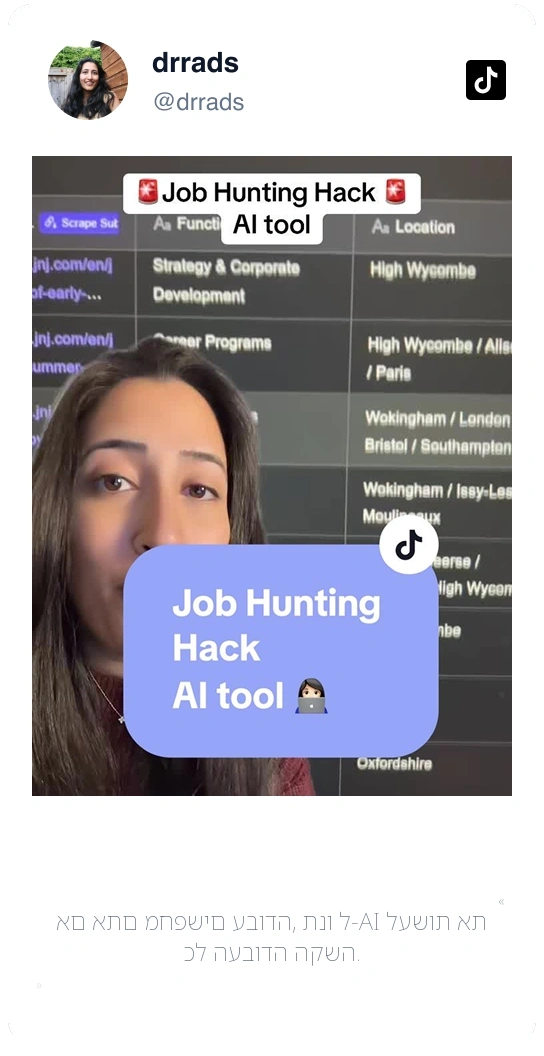
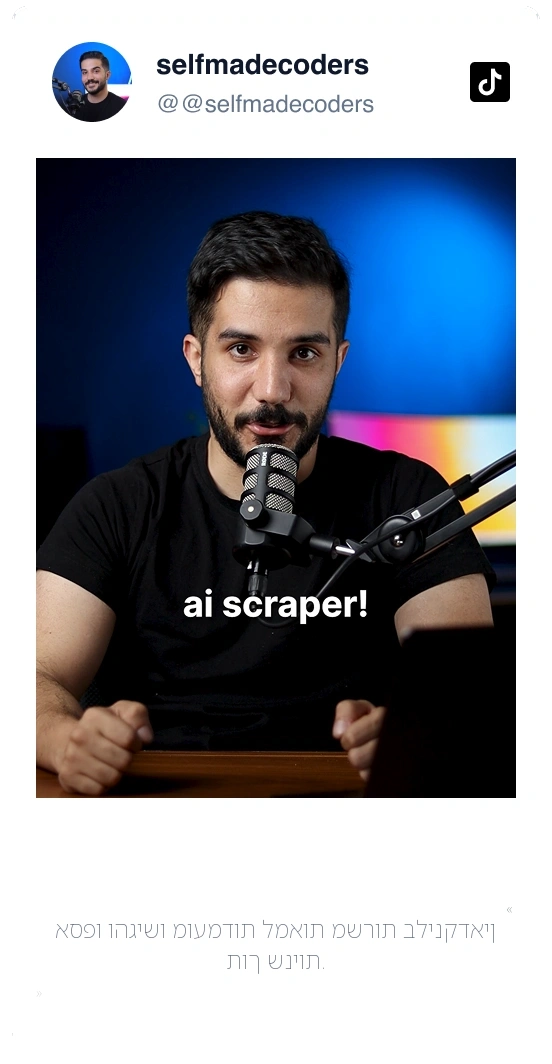
ראו מה המשתמשים שלנו אומרים על Thunderbit.





שאלות נפוצות
קשורים תרחישי שימוש
גלו עוד תרחישי שימוש ב-web scraper של Thunderbit.
PeopleWhiz גריפר
גריפר PeopleWhiz של Thunderbit מאפשר לחלץ נתונים מתוצאות חיפוש ומפרופילים ב-PeopleWhiz בעזרת הצעות שדות מבוססות AI. אספו שמות, פרטי קשר, מיקומים ועוד למחקר, שיווק או יצירת לידים. הפכו נתוני PeopleWhiz למערכי נתונים מובנים במהירות וביעילות.
למידע נוסף ->
סקרייפר Trustpilot
חלצו ביקורות, דירוגים ופרטי הכותבים מ-Trustpilot ב-2 לחיצות בלבד — ואז ייצאו ישירות ל-Google Sheets, Excel או Notion. בלי קוד, בלי העתק-הדבק, רק נתונים מובנים ונקיים מוכנים לניתוח ולשיתוף.
למידע נוסף ->
Steam Scraper
חילוץ שמות משחקים ב-Steam, מחירים וציוני ביקורות משתמשים ב-2 קליקים בלבד — בלי צורך בקוד. ייצוא נתונים נקיים ישירות ל-Excel, Google Sheets או Notion, והתחילו לנתח מיד.
למידע נוסף ->
HKTVmall Scraper
בלחיצות ספורות בלבד אפשר לחלץ שמות מוצרים, מחירים, דירוגים ועוד מרשימות HKTVmall — בלי שום צורך בקוד. ייצאו את הנתונים ישירות ל‑Excel, ל‑Google Sheets או ל‑Notion, והפכו את המידע מ‑HKTVmall לתובנות שאפשר לפעול לפיהן.
למידע נוסף ->
Carousell 爬虫
חילוץ מודעות Carousell — כותרות פריטים, תיאורים, מחירים ופרטי מוכרים — ב־2 קליקים בלבד, ולאחר מכן ייצוא ישיר ל־Excel, Google Sheets או Notion. בלי קוד ובלי צורך בהגדרה מסובכת.
למידע נוסף ->Substack סקרייפר
חלצו ב-2 קליקים את מספרי המנויים ב-Substack, כותרות מאמרים ותיאורי פרסומים — ואז ייצאו ל-Excel, Google Sheets או Notion. בלי קוד; ה-AI של Thunderbit דואג לכל המבנה בשבילכם.
למידע נוסף ->מוכנים להאיץ את חילוץ הנתונים שלכם?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
הניסיון החינמי מספק קרדיטים ללא הגבלה ל-8 דפי אינטרנט.



