IDCrawl Scraper
מומחים בחברות מובילות סומכים עלינו














נתוני Idcrawl שנשארים שימושיים
השתמשו ב־idcrawl כדי לחלץ נתונים מהר יותר, נקי יותר ובקנה מידה גדול עם Thunderbit.
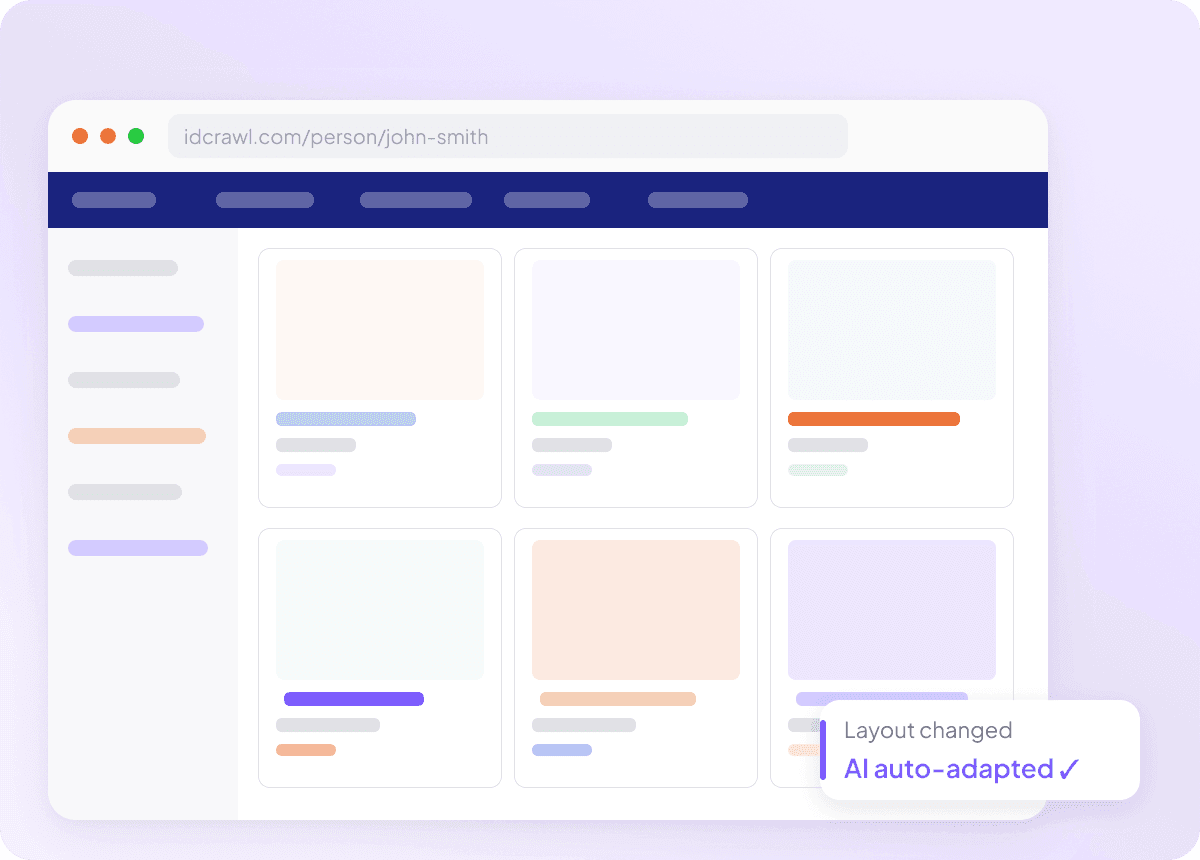
מתאים את עצמו כש־Idcrawl משתנה
סקרייפרים שנשברים אחרי כל עדכון אתר הם חסרי ערך, במיוחד כשמנסים לחלץ שם מלא, תפקיד, שם חברה, כתובת אימייל, מספר טלפון ופרופיל LinkedIn מ־idcrawl. Thunderbit קורא את הדף לפי המשמעות, לא לפי סלקטורים קבועים, ולכן הוא יכול להסתגל כשהפריסה משתנה. אתם מבזבזים פחות זמן על תיקון סקרייפרים ויותר זמן על קבלת הנתונים שאתם צריכים.
נתונים נקיים מההתחלה
נתונים גולמיים הם רק תחילת העבודה, ותוצאות מ־idcrawl לרוב דורשות ניקוי לפני שהן באמת שימושיות. Thunderbit מבנה ומעצב את הנתונים במהלך החילוץ, כך שמה שאתם מייצאים כבר נקי ומוכן לשימוש. המשמעות היא פחות מיון, פחות עבודה חוזרת ומסירה חלקה יותר לצוות שלכם.
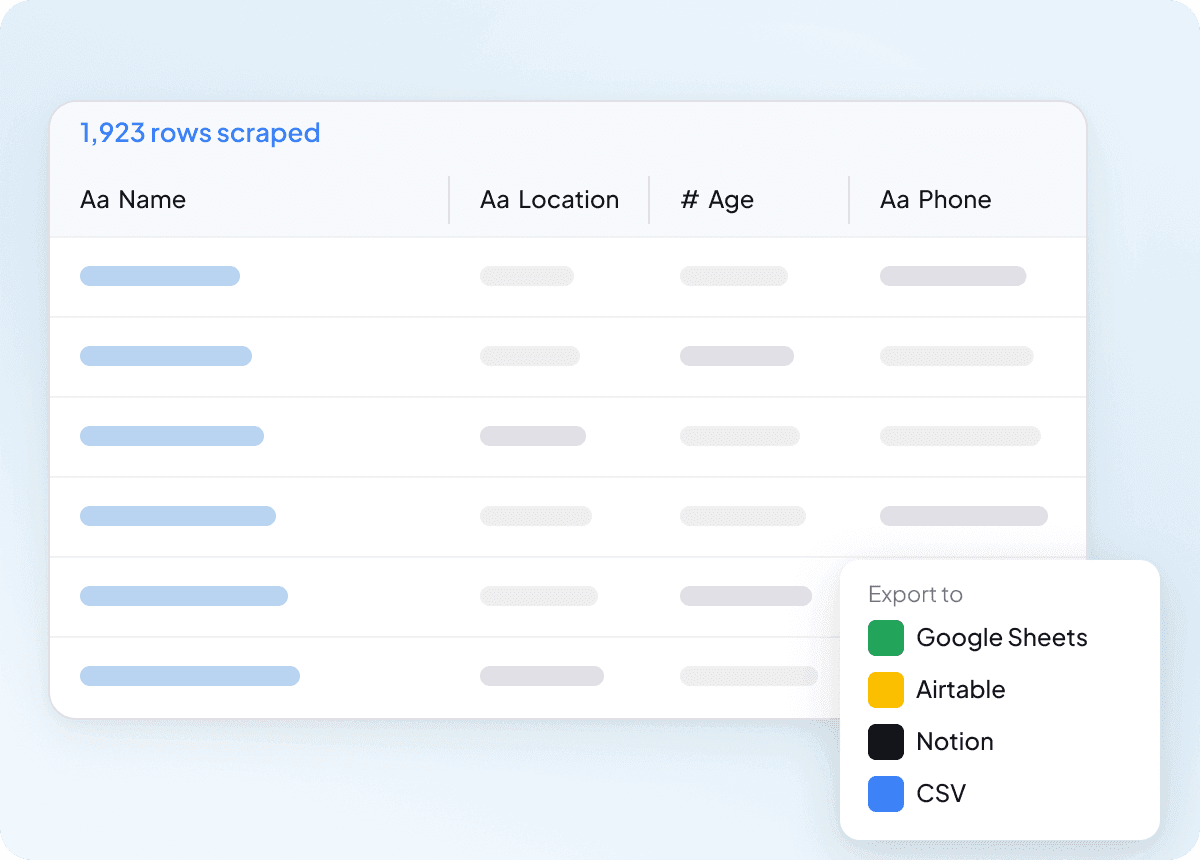
גריפת Idcrawl בכמות גדולה בבת אחת
גריפת דף אחד של idcrawl בכל פעם לא מתאימה להיקפים גדולים כשצריך רשימת אנשי קשר ארוכה. Thunderbit יכול לגרוף בכמות גדולה מאות דפים בבת אחת, כך שאפשר להזין לו רשימת כתובות URL ולחלץ שם מלא, תפקיד, שם חברה, כתובת אימייל, מספר טלפון ופרופיל LinkedIn מכולם. זו דרך הרבה יותר קלה להפוך רשימה גדולה לנתונים שימושיים.

למה Thunderbit שונה מסקרייפרים מסורתיים של idcrawl?
דרך פשוטה יותר לחלץ נתוני idcrawl בלי תיקונים מתמידים.
סקרייפרים מסורתיים
הדרך הישנה לעשות דבריםThunderbit AI
הגישה החכמה יותראל תסתפקו במילה שלנו
ראו מה המשתמשים שלנו אומרים על Thunderbit.






שאלות נפוצות
קשורים שימושים
גלו עוד שימושים ב-web scraper של Thunderbit.
מגרד וידאו
מגרד הווידאו של Thunderbit מאפשר לחלץ נתוני סרטונים ויוצרים בעזרת AI בכמה קליקים בלבד. אספו רשימות סרטונים, מדדי ביצועים ופרטי פרופיל, ואז ייצאו ל‑Excel, Google Sheets, Airtable או Notion לצורכי מעקב ומחקר משפיענים.
למידע נוסף ->
מחלץ Wikipedia
קבלו נתוני תיבת מידע, מקורות וטקסט מאמרים מ-Wikipedia לגיליון מסודר ונקי — בלי קוד, ה-AI עושה עבורכם את המבנה.
למידע נוסף ->
Sports Direct Scraper
משכו שמות מוצרים, מחירים ואחוזי הנחה מ‑Sports Direct באמצעות ה‑AI של Thunderbit — בלי הגדרה מסובכת ובלי צורך בקוד.
למידע נוסף ->
UNIQLO Scraper
איספו נתוני מוצרים של Uniqlo כמו שמות, מחירים ומידות זמינות בלחיצות בודדות בלבד, בזכות תוסף הכרום של Thunderbit.
למידע נוסף ->
סקרייפר Trivago
גרפו שמות בתי מלון, מחירים ודירוגים מ-Trivago בכמה קליקים בלבד — בלי צורך בקוד או בהגדרה.
למידע נוסף ->
HKTVmall Scraper
אספו שמות מוצרים, מחירים ואפילו דירוגי לקוחות מרשימות המוצרים של HKTVmall בכמה קליקים בלבד — בלי שום צורך בהגדרה מורכבת.
למידע נוסף ->מוכנים להאיץ את חילוץ הנתונים שלכם?
הצטרפו ל-100,000+ אנשי מקצוע שכבר משתמשים ב-Thunderbit כדי לאוטומט תהליכי web scraping.
ניסיון חינם כולל קרדיטים בלתי מוגבלים ל-8 דפי אינטרנט.