
האינטרנט מוצף בנתונים יקרי ערך — בין אם אתם עוסקים במכירות, מסחר אלקטרוני או מחקר שוק, Web scraping הוא הנשק הסודי ליצירת לידים, לניטור מחירים ולניתוח תחרותי. אבל יש קאץ': ככל שיותר עסקים נכנסים לעולם ה-scraping, אתרים נלחמים בחזרה בעוצמה רבה מאי פעם. השינוי הזה אמיתי: ניתוח של מצא שיותר משליש מ-1,000 האתרים המובילים כבר חוסמים רק את ה-crawler של OpenAI — והארגז הרחב יותר של הוא כיום הנורמה, לא החריג.
אם אי פעם ראיתם את סקריפט ה-Python שלכם רץ חלק במשך 20 דקות — ואז פתאום נתקל בקיר של שגיאות 403 — אתם יודעים עד כמה התסכול הזה אמיתי.
במשך שנים עבדתי ב-SaaS ובאוטומציה, וראיתי מקרוב איך פרויקטי scraping יכולים לעבור מ"וואו, זה קל" ל"למה אני חסום בכל מקום?" בשנייה אחת. אז בואו נהיה פרקטיים: אראה לכם איך לבצע Web scraping בלי להיחסם ב-Python, אשתף בשיטות הטובות ביותר ובקטעי קוד, ואסביר מתי כדאי לשקול חלופות מבוססות AI כמו . בין אם אתם מקצועני Python או רק "מגרדים" את דרככם קדימה (משחק מילים מכוון), תצאו מכאן עם ארגז כלים לחילוץ נתונים אמין וללא חסימות.
מהו Web Scraping בלי להיחסם ב-Python?
בבסיסו, Web scraping בלי להיחסם פירושו חילוץ נתונים מאתרים בצורה שלא מפעילה את מנגנוני ההגנה שלהם נגד בוטים. בעולם ה-Python, זה הרבה מעבר לכתיבה של לולאת requests.get() — זה אומר להשתלב, לחקות משתמשים אמיתיים, ולהקדים צעד אחד את מערכות הזיהוי.
למה Python? — בזכות התחביר הפשוט שלה, האקוסיסטם העצום (למשל: requests, BeautifulSoup, Scrapy, Selenium), והגמישות שלה לכל דבר — מסקריפטים מהירים ועד סורקים מבוזרים. אבל הפופולריות באה עם מחיר: מערכות anti-bot רבות כבר מכוונות לזהות דפוסי scraping מבוססי Python.
אז אם אתם רוצים לגרד נתונים בצורה אמינה, צריך ללכת מעבר לבסיס. זה אומר להבין איך אתרים מזהים בוטים, ואיך אפשר לעקוף את הזיהוי — בלי לחצות קווים אתיים או משפטיים.
למה חשוב להימנע מחסימות בפרויקטי Web Scraping ב-Python
חסימה היא לא רק תקלה טכנית — היא יכולה לשבש תהליכים עסקיים שלמים. הנה פירוט:
| מקרה שימוש | ההשפעה של חסימה |
|---|---|
| יצירת לידים | רשימות לקוחות פוטנציאליים חלקיות או לא מעודכנות, אובדן מכירות |
| ניטור מחירים | פספוס שינויי מחירים אצל מתחרים, החלטות תמחור שגויות |
| איסוף תוכן | חוסרים בחדשות, ביקורות או נתוני מחקר |
| מודיעין שוק | נקודות עיוורות במעקב אחר מתחרים או תעשייה |
| מודעות נדל"ן | נתוני נכסים לא מדויקים או מיושנים, הזדמנויות שפוספסו |
כש-scraper נחסם, אתם לא רק מפסידים נתונים — אתם מבזבזים משאבים, מסתכנים בבעיות ציות, ואולי גם מקבלים החלטות עסקיות שגויות על סמך מידע חלקי. בעולם שבו , אמינות היא הכול.
איך אתרים מזהים וחוסמים Web scrapers ב-Python
אתרים נהיו ממש מתוחכמים בזיהוי בוטים. הנה מנגנוני ההגנה הנפוצים ביותר שתיתקלו בהם (, ):
- רשימות חסימה של כתובות IP: יותר מדי בקשות מאותה IP? נחסמת.
- בדיקות User-Agent ו-Header: בקשות עם כותרות חסרות או גנריות (כמו ברירת המחדל של Python
python-requests/2.25.1) בולטות מיד. - Rate Limiting: יותר מדי בקשות בזמן קצר מפעיל האטה או חסימה.
- CAPTCHA: חידות של "הוכח שאתה אנושי" שבוטים לא יכולים לפתור (בקלות).
- ניתוח התנהגותי: אתרים עוקבים אחרי דפוסים רובוטיים — למשל לחיצה על אותו כפתור בדיוק באותו מרווח זמן.
- Honeypots: קישורים או שדות מוסתרים שרק בוטים יתקשרו איתם.
- Browser Fingerprinting: איסוף פרטים על הדפדפן והמכשיר שלכם כדי לזהות כלי אוטומציה.
- מעקב אחר Cookies ו-Session: בוטים שלא מטפלים נכון ב-cookies או ב-sessions מסומנים.
תחשבו על זה כמו בידוק ביטחוני בשדה תעופה: אם אתם נראים, מתנהגים ונעים כמו כולם, אתם עוברים חלק. אם אתם מגיעים עם מעיל טרנץ' ומשקפי שמש, תצפו לשאלות נוספות.
טכניקות Python חיוניות ל-Web Scraping בלי להיחסם
בואו נגיע לחלק החשוב: איך באמת להימנע מחסימות כשמבצעים scraping עם Python. הנה האסטרטגיות המרכזיות שכל scraper צריך להכיר:

פרוקסי מסתובבים וכתובות IP מתחלפות
למה זה חשוב: אם כל הבקשות שלכם מגיעות מאותה IP, אתם מטרה קלה לחסימות IP. פרוקסי מסתובבים מאפשרים לפזר בקשות על פני כמה כתובות IP, וכך הרבה יותר קשה לחסום אתכם.
איך עושים את זה ב-Python:
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...more proxies
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # process responseאפשר להשתמש בשירותי פרוקסי בתשלום (כמו residential או rotating proxies) כדי לקבל יותר אמינות ().
הגדרת User-Agent וכותרות מותאמות אישית
למה זה חשוב: כותרות ברירת המחדל של Python צורחות "בוט". חיקו דפדפנים אמיתיים על ידי הגדרת user-agent וכותרות נוספות.
קוד לדוגמה:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)סובבו user-agents כדי להוסיף שכבת הסוואה נוספת ().
אקראיות בתזמון ובדפוסי הבקשות
למה זה חשוב: בוטים מהירים וצפויים; בני אדם איטיים ואקראיים. הוסיפו השהיות וערבבו את אופן הניווט.
טיפ ל-Python:
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # Wait 2–7 secondsאפשר גם לבצע אקראיות לנתיבי לחיצה ולדפוסי גלילה אם משתמשים ב-Selenium.
ניהול Cookies ו-Session
למה זה חשוב: אתרים רבים דורשים cookies או אסימוני session כדי לאפשר גישה לתוכן. בוטים שמתעלמים מזה נחסמים.
איך לנהל ב-Python:
1import requests
2session = requests.Session()
3response = session.get(url)
4# session will handle cookies automaticallyלזרימות מורכבות יותר, השתמשו ב-Selenium כדי ללכוד cookies ולהשתמש בהם מחדש.
הדמיית התנהגות אנושית עם דפדפנים Headless
למה זה חשוב: חלק מהאתרים משתמשים ב-JavaScript, תנועת עכבר או גלילה כאותות למשתמשים אמיתיים. דפדפנים headless כמו Selenium או Playwright יכולים לחקות פעולות כאלה.
דוגמה עם Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))זה עוזר לעקוף ניתוח התנהגותי ותוכן דינמי ().
אסטרטגיות מתקדמות: עקיפת CAPTCHA ו-Honeypots ב-Python
CAPTCHA נועדו לעצור בוטים במקום. אף על פי שחלק מספריות Python מסוגלות לפתור CAPTCHA פשוטים, רוב ה-scrapers הרציניים מסתמכים על שירותי צד שלישי (כמו 2Captcha או Anti-Captcha) כדי לפתור אותם בתשלום ().
שילוב לדוגמה:
1# Pseudocode for using 2Captcha API
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# Wait for solution, then submit with your requestHoneypots הם שדות או קישורים מוסתרים שרק בוטים יתקשרו איתם. הימנעו מלחיצה או שליחה של כל דבר שלא נראה בדפדפן אמיתי ().
תכנון כותרות בקשה חזקות עם ספריות Python
מעבר ל-user-agent, אפשר לסובב ולהקפיץ גם כותרות אחרות (כמו Referer, Accept, Origin וכו') כדי להשתלב טוב יותר.
עם Scrapy:
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # More headers
7 }
8 }עם Selenium: השתמשו בפרופילי דפדפן או בתוספים כדי להגדיר כותרות, או הזריקו אותן באמצעות JavaScript.
עדכנו את רשימת הכותרות שלכם — העתיקו בקשות אמיתיות מהדפדפן באמצעות DevTools להשראה.
כש-Web scraping מסורתי ב-Python כבר לא מספיק: עליית טכנולוגיות anti-bot
זו המציאות: ככל ש-scraping הופך פופולרי יותר, כך גם השדרוגים של anti-bot. . זיהוי מבוסס AI, ספי בקשות דינמיים ו-browser fingerprinting מקשים יותר מאי פעם גם על סקריפטי Python מתקדמים להישאר מתחת לרדאר ().
לפעמים, לא משנה כמה הקוד שלכם חכם — תיתקלו בקיר. ואז הגיע הזמן לשקול גישה אחרת.
Thunderbit: אלטרנטיבה של AI Web Scraper ל-scraping ב-Python
כש-Python מגיע לקצה היכולת שלו, נכנס לתמונה כ-Web scraper ללא קוד ובעל יכולות AI, שנבנה למשתמשים עסקיים — לא רק למפתחים. במקום להילחם עם פרוקסי, כותרות ו-CAPTCHA, סוכן ה-AI של Thunderbit קורא את האתר, מציע את השדות הטובים ביותר לחילוץ, ומטפל בכל דבר — מניווט בתת-דפים ועד ייצוא הנתונים.
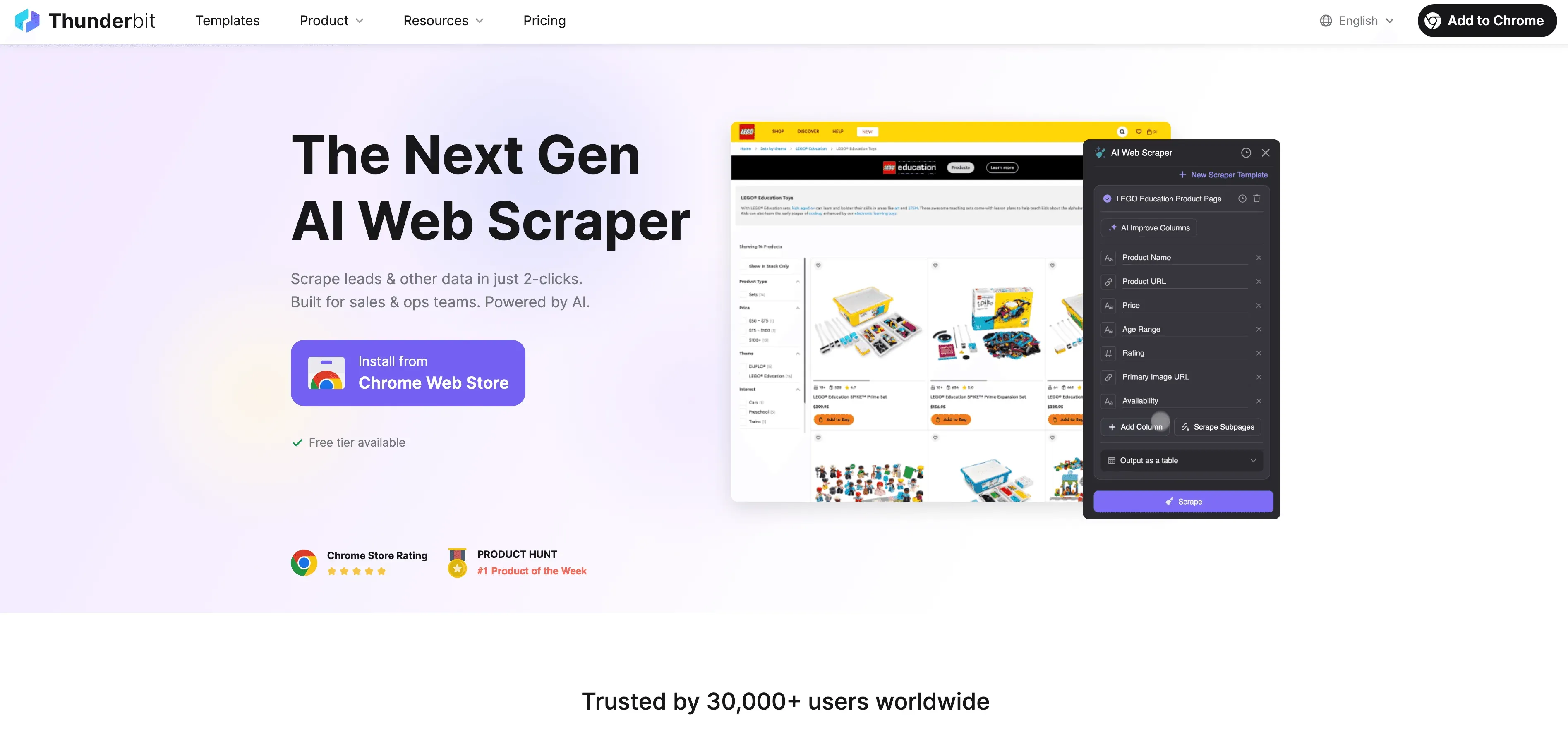
מה מייחד את Thunderbit?
- הצעת שדות מבוססת AI: לחצו על “AI Suggest Fields” ו-Thunderbit יסרוק את הדף, ימליץ על עמודות, ואפילו ייצור הוראות חילוץ.
- Scraping של תת-דפים: Thunderbit יכול לבקר בכל תת-דף (כמו פרטי מוצר או פרופילי LinkedIn) ולהעשיר את הטבלה שלכם אוטומטית.
- Scraping בענן או בדפדפן: בחרו את האפשרות המהירה ביותר — ענן לאתרים ציבוריים, דפדפן לדפים המוגנים ב-login.
- Scraping מתוזמן: הגדירו ושכחו — Thunderbit יכול לבצע scraping לפי לוח זמנים, כך שהנתונים שלכם תמיד עדכניים.
- תבניות מיידיות: לאתרים פופולריים (Amazon, Zillow, Shopify וכו'), Thunderbit מציע תבניות בלחיצה אחת — בלי צורך בהגדרה.
- ייצוא נתונים חינמי: ייצוא ל-Excel, Google Sheets, Airtable או Notion — בלי עמלות נוספות.
יותר מ- סומכים על Thunderbit, ואתם לא צריכים לכתוב אפילו שורת קוד אחת.
איך Thunderbit עוזר למשתמשים להימנע מחסימות ולאוטומט חילוץ נתונים
ה-AI של Thunderbit לא רק מחקה התנהגות אנושית — הוא מסתגל לכל אתר בזמן אמת, וכך מפחית את הסיכון להיחסם. כך זה עובד:
- ה-AI מסתגל לשינויי פריסה: פחות עבודה חוזרת כשאתר מעדכן עיצוב — לא צריך לחזור ולכוונן selectors בכל שבוע.
- טיפול בתת-דפים וב-pagination: Thunderbit עוקב אחר קישורים ורשימות מחולקות לעמודים בשבילכם, בדיוק כמו אדם שלוחץ ומתקדם.
- Scraping בענן באצוות: הריצו משימות מענן של Thunderbit ולא מהמחשב הנייד שלכם, עם גודל אצווה שמוגדר לפי התוכנית (ראו את למגבלות העדכניות).
- פחות קוד לתחזוקה: אתם לא אלה שרודפים אחרי selectors שבורים בחצות כשאתר משתנה; ה-AI פשוט קורא מחדש את הדף.
לצלילה עמוקה יותר, עיינו ב-.
השוואה בין scraping ב-Python לבין Thunderbit: במה כדאי לבחור?
בואו נשים אותם זה מול זה:
| תכונה | scraping ב-Python | Thunderbit |
|---|---|---|
| זמן הקמה | בינוני–גבוה (סקריפטים, פרוקסי וכו') | נמוך (2 לחיצות, ה-AI עושה את השאר) |
| מיומנות טכנית | נדרש קוד | אין צורך בקוד |
| אמינות | משתנה (קל לשבור) | גבוהה (ה-AI מסתגל לשינויים) |
| סיכון לחסימות | בינוני–גבוה | נמוך (ה-AI מחקה משתמש ומסתגל) |
| סקיילביליות | דורש קוד מותאם והגדרת ענן | scraping בענן ואצוות מובנים מראש |
| תחזוקה | תכופה (שינויי אתר, חסימות) | מינימלית (ה-AI מתכוונן אוטומטית) |
| אפשרויות ייצוא | ידני (CSV, מסד נתונים) | ישירות ל-Sheets, Notion, Airtable, CSV |
| עלות | חינם (אבל גוזל זמן) | שכבה חינמית, תכניות בתשלום להיקפים גדולים |
מתי להשתמש ב-Python:
- אתם צריכים שליטה מלאה, לוגיקה מותאמת אישית, או שילוב עם תהליכי Python אחרים.
- אתם מגרדים אתרים עם מעט הגנות נגד בוטים.
מתי להשתמש ב-Thunderbit:
- אתם רוצים מהירות, אמינות ואפס הגדרה.
- אתם מגרדים אתרים מורכבים או כאלה שמשתנים לעיתים תכופות.
- אתם לא רוצים להתעסק עם פרוקסי, CAPTCHA או קוד.
מדריך שלב-אחר-שלב: הגדרת Web Scraping בלי להיחסם ב-Python
בואו נעבור על דוגמה מעשית: scraping של נתוני מוצר מאתר דוגמה, תוך יישום שיטות עבודה מומלצות למניעת חסימות.
1. התקינו את הספריות הנדרשות
1pip install requests beautifulsoup4 fake-useragent2. הכינו את הסקריפט שלכם
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Replace with your URLs
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # Extract data here
16 print(soup.title.text)
17 else:
18 print(f"Blocked or error on \{url\}: \{response.status_code\}")
19 time.sleep(random.uniform(2, 6)) # Random delay3. הוסיפו סיבוב פרוקסי (אופציונלי)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # More proxies
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...rest of code4. טפלו ב-Cookies וב-Session
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...rest of code5. טיפים לפתרון בעיות
- אם אתם רואים הרבה שגיאות 403/429, האטו את הבקשות שלכם או נסו פרוקסי חדשים.
- אם אתם נתקלים ב-CAPTCHA, שקלו להשתמש ב-Selenium או בשירות לפתרון CAPTCHA.
- תמיד בדקו את
robots.txtואת תנאי השימוש של האתר.
סיכום ומסקנות מרכזיות
Web scraping ב-Python הוא כלי עוצמתי — אבל חסימות הן סיכון קבוע ככל שטכנולוגיות anti-bot מתפתחות. הדרך הטובה ביותר להימנע מחסימות? לשלב שיטות עבודה טכניות מומלצות (פרוקסי מסתובבים, כותרות חכמות, השהיות אקראיות, טיפול ב-session ודפדפנים headless) עם כבוד לכללי האתר ולאתיקה.
אבל לפעמים, אפילו הטריקים הטובים ביותר ב-Python לא מספיקים. כאן נכנסים כלים מבוססי AI כמו — ללא קוד, עם יכולת להתמודד עם שינויי פריסה ו-pagination שמכשילים סקריפטים קשיחים, ומתאימים למשתמשים עסקיים שלא רוצים לבלות את הערבים שלהם במעקב אחרי משימת Selenium.
רוצים לראות כמה קל יכול להיות scraping? ותנסו בעצמכם — או היכנסו ל- שלנו לעוד טיפים ומדריכים ל-scraping.
שאלות נפוצות
1. למה אתרים חוסמים Web scrapers ב-Python?
אתרים חוסמים scrapers כדי להגן על הנתונים שלהם, למנוע עומס יתר על השרת, ולעצור בוטים אוטומטיים מניצול לרעה של השירותים שלהם. קל לזהות סקריפטים ב-Python אם הם משתמשים בכותרות ברירת מחדל, לא מטפלים ב-cookies, או שולחים יותר מדי בקשות מהר מדי.
2. מהן הדרכים היעילות ביותר להימנע מחסימה בזמן scraping ב-Python?
השתמשו בפרוקסי מסתובבים, הגדירו user-agent וכותרות ריאליים, אקראו את תזמון הבקשות, נַהֲלו cookies/sessions, וחיקו התנהגות אנושית עם כלים כמו Selenium או Playwright.
3. איך Thunderbit עוזר להימנע מחסימות לעומת סקריפטי Python?
Thunderbit משתמש ב-AI כדי להסתגל לפריסות אתרים, לחקות גלישה אנושית, ולטפל בתת-דפים וב-pagination באופן אוטומטי. הוא מפחית את הסיכון לחסימות בכך שהוא משתלב ומתעדכן בזמן אמת — בלי צורך בקוד או בפרוקסי.
4. מתי כדאי לי להשתמש ב-scraping ב-Python לעומת כלי AI כמו Thunderbit?
השתמשו ב-Python כשאתם צריכים לוגיקה מותאמת אישית, שילוב עם קוד Python אחר, או כשאתם מגרדים אתרים פשוטים. השתמשו ב-Thunderbit ל-scraping מהיר, אמין וסקיילבילי — במיוחד כשהאתרים מורכבים, משתנים לעיתים תכופות, או חוסמים סקריפטים באגרסיביות.
5. האם Web scraping הוא חוקי?
Web scraping הוא חוקי עבור נתונים הזמינים לציבור, אבל אתם חייבים לכבד את תנאי השימוש, מדיניות הפרטיות והחוקים הרלוונטיים של כל אתר. לעולם אל תגרדו נתונים רגישים או פרטיים, ותמיד פעלו בצורה אתית ואחראית.
מוכנים לגרד חכם יותר, לא קשה יותר? נסו את Thunderbit, והשאירו את החסימות מאחור.
למידע נוסף:
- Web Scraping של Google News עם Python: מדריך צעד-אחר-צעד
- בנו כלי מעקב מחירים ל-Best Buy באמצעות Python
- 14 דרכים לבצע Web Scraping בלי להיחסם
- 10 הטיפים הטובים ביותר איך לא להיחסם בזמן Web scraping