

יש משהו על־זמני בלפתוח טרמינל, להקליד פקודה אחת ולראות נתוני אינטרנט גולמיים נשפכים פנימה, כאילו זה עתה פרצתם למטריקס. עבור מפתחים ומשתמשים טכניים מתקדמים, cURL הוא בדיוק אותו שרביט קסם — כלי שורת פקודה צנוע שרץ בשקט על מיליארדי מכשירים, משרתי ענן ועד המקרר החכם שלכם. וגם ב-2026, עם כל כלי ה-no-code וה-AI המבריקים שיש היום, גריפת אתרים ב-cURL עדיין נשארת מהלך מועדף לכל מי שרוצה מהירות, שליטה ויכולת סקריפטינג.
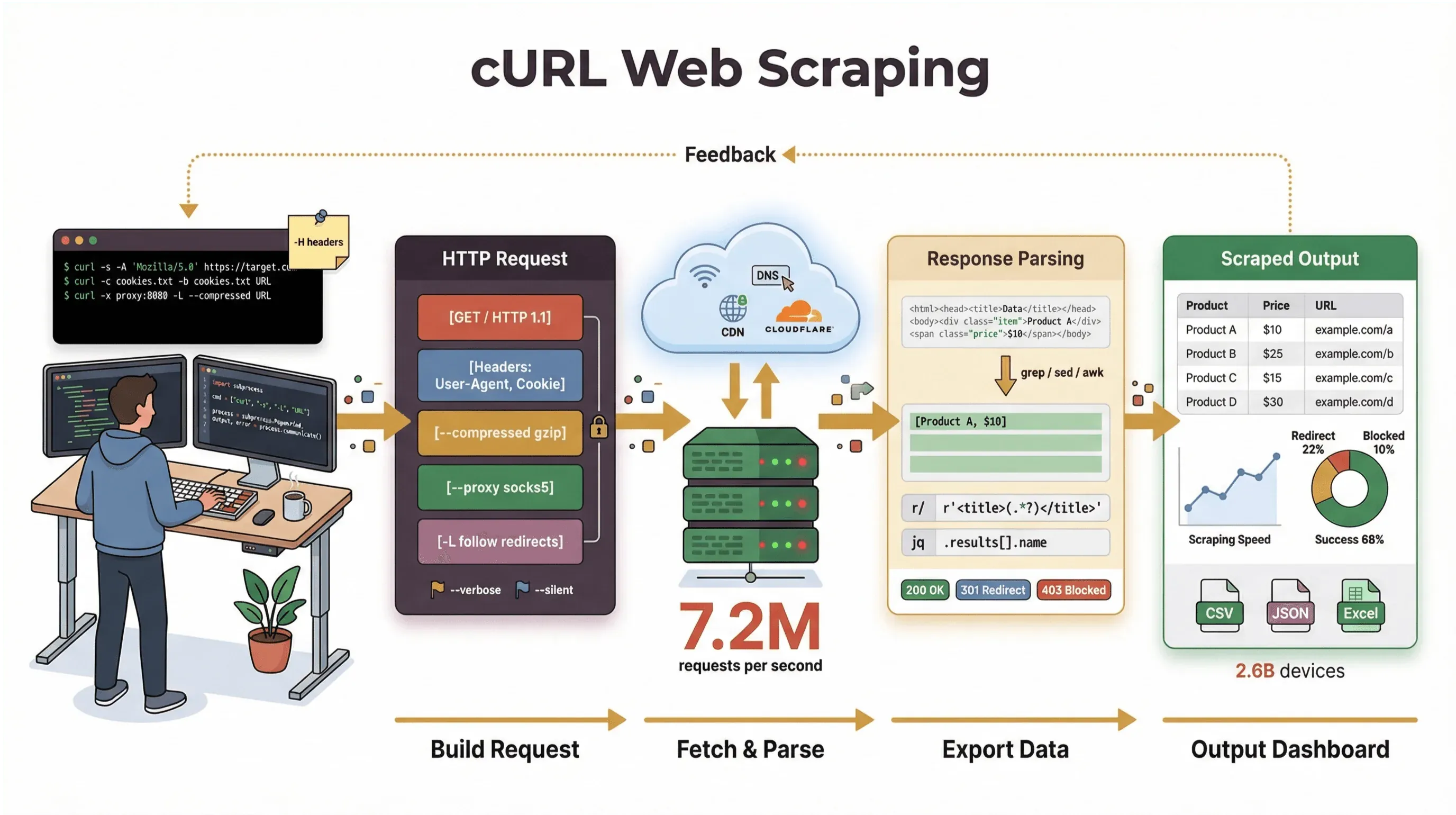 שנים שאני בונה כלי אוטומציה ועוזר לצוותים להתמודד עם נתוני אינטרנט, ואני עדיין פונה ל-cURL כשאני צריך למשוך דף, לדבג API או ליצור אבטיפוס לזרימת עבודה של גריפה. במדריך הזה אעבור אתכם על tutorial לגריפת אתרים עם cURL, שיכלול גם את הבסיס וגם טריקים מקצועיים — כולל דוגמאות פקודה אמיתיות, טיפים מעשיים ומבט מפוכח על איפה cURL מצטיין ואיפה הוא נתקל בקיר. ואם אתם יותר אנשי עסקים שמעדיפים לא לגעת בשורת הפקודה, אראה לכם איך Thunderbit, ה-web scraper שלנו המופעל ב-AI, יכול לקחת אתכם מ“אני צריך את הנתונים האלה” ל“הנה הגיליון שלי” בשתי לחיצות — בלי קוד בכלל.
שנים שאני בונה כלי אוטומציה ועוזר לצוותים להתמודד עם נתוני אינטרנט, ואני עדיין פונה ל-cURL כשאני צריך למשוך דף, לדבג API או ליצור אבטיפוס לזרימת עבודה של גריפה. במדריך הזה אעבור אתכם על tutorial לגריפת אתרים עם cURL, שיכלול גם את הבסיס וגם טריקים מקצועיים — כולל דוגמאות פקודה אמיתיות, טיפים מעשיים ומבט מפוכח על איפה cURL מצטיין ואיפה הוא נתקל בקיר. ואם אתם יותר אנשי עסקים שמעדיפים לא לגעת בשורת הפקודה, אראה לכם איך Thunderbit, ה-web scraper שלנו המופעל ב-AI, יכול לקחת אתכם מ“אני צריך את הנתונים האלה” ל“הנה הגיליון שלי” בשתי לחיצות — בלי קוד בכלל.
בואו נצלול פנימה ונראה למה cURL עדיין רלוונטי לגריפת אתרים ב-2026, איך להשתמש בו ביעילות, ומתי הגיע הזמן לעבור לכלי חזק אפילו יותר.
מהו cURL? הבסיס לגריפת אתרים ב-cURL
בליבו, cURL הוא כלי שורת פקודה וספרייה להעברת נתונים באמצעות כתובות URL. הוא קיים כבר כמעט 30 שנה (כן, באמת), והוא נמצא בכל מקום — מוטמע במערכות הפעלה, מפעיל סקריפטים, ומטפל בשקט בהעברת נתונים ביותר מ-עשרים מיליארד התקנות. אם אי פעם הרצתם פקודה מהירה כדי להביא דף אינטרנט, לבדוק API או להוריד קובץ, סביר מאוד שהשתמשתם ב-cURL.
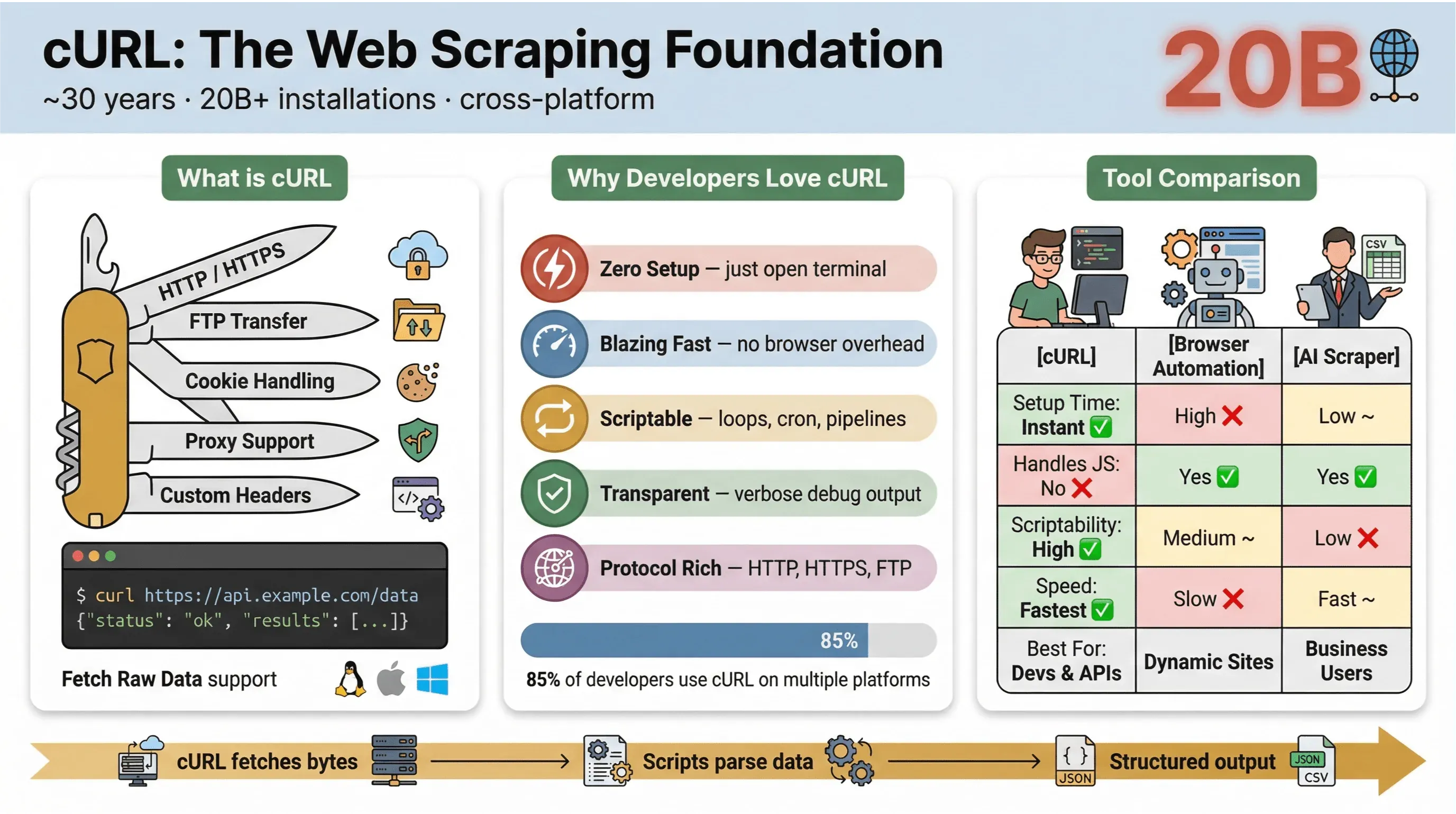 הנה מה שהופך את cURL לכל כך פופולרי לגריפת אתרים:
הנה מה שהופך את cURL לכל כך פופולרי לגריפת אתרים:
- קל משקל וחוצה פלטפורמות: רץ על Linux, macOS, Windows ואפילו על מכשירים משובצים.
- תמיכה בפרוטוקולים: מטפל ב-HTTP, HTTPS, FTP ועוד.
- ניתן לסקריפטינג: מושלם לאוטומציה, משימות cron וקוד דבק.
- לא נדרשת אינטראקציה של משתמש: מיועד לשימוש לא אינטראקטיבי — נהדר למשימות אצווה וצינורות עיבוד.
אבל חשוב לדייק: התפקיד העיקרי של cURL הוא להביא נתונים גולמיים — HTML, JSON, תמונות, מה שתרצו. הוא לא מנתח, לא מרנדר ולא מארגן את הנתונים עבורכם. תחשבו על cURL כעל “הקילומטר הראשון” של גריפת אתרים: הוא מביא את הבייטים, אבל כדי להפוך אותם למידע מובנה תצטרכו כלים אחרים (כמו סקריפטים ב-Python, או grep/sed/awk, או AI Web Scraper).
אם תרצו לראות את התיעוד הרשמי, בדקו את מדריך ה-HTTP scripting של cURL.
למה להשתמש ב-cURL לגריפת אתרים? (tutorial לגריפת אתרים עם cURL)
אז למה מפתחים ומשתמשים טכניים ממשיכים לחזור ל-cURL לגריפת אתרים, אפילו עם כל הכלים החדשים בחוץ? הנה מה שמבליט את cURL:
- הגדרה מינימלית: בלי התקנות, בלי תלויות — פשוט פותחים את הטרמינל ומתחילים.
- מהירות: משיכת נתונים מיידית, בלי לחכות לטעינת דפדפן.
- יכולת סקריפטינג: לולאות על פני כתובות URL, אוטומציה של בקשות, וחיבור פקודות בקלות.
- תמיכה בפרוטוקולים ופיצ'רים: טיפול בעוגיות, פרוקסי, הפניות, כותרות מותאמות ועוד.
- שקיפות: רואים בדיוק מה קורה בעזרת פלט verbose/debug.
בסקר המשתמשים של cURL לשנת 2025, 85.7% מהמשיבים אמרו שהם משתמשים בכלי שורת הפקודה cURL, ו-96.2% דיווחו שהם משתמשים בו על Linux — עדיין הפלטפורמה המובילה ל-cURL בפער גדול.
--- זה עדיין אולר שווייצרי לבקשות HTTP, למשיכת נתונים מהירה ולפתרון תקלות.
הנה השוואה מהירה בין cURL לבין שיטות גריפה אחרות:
| תכונה | cURL | אוטומציה בדפדפן (למשל Selenium) | AI Web Scraper (למשל Thunderbit) |
|---|---|---|---|
| זמן הגדרה | מיידי | גבוה | נמוך |
| יכולת סקריפטינג | גבוהה | בינונית | נמוכה (לא צריך קוד) |
| טיפול ב-JavaScript | לא | כן | כן (Thunderbit: דרך הדפדפן) |
| תמיכה בעוגיות/סשנים | ידנית | אוטומטית | אוטומטית |
| מבנה הנתונים | ידני (לנתח אחר כך) | ידני (לנתח אחר כך) | מבוסס AI/תבניות |
| הכי מתאים ל | מפתחים, משיכות מהירות | אתרים מורכבים ודינמיים | משתמשי עסקים, ייצוא מובנה |
בקיצור: cURL מנצח בגדול כשצריך משיכת נתונים מהירה וניתנת לסקריפטינג — במיוחד עבור דפים סטטיים, APIs, או כשאתם רוצים לאוטמט תהליכי עבודה פשוטים. אבל ברגע שצריך לנתח HTML מורכב, להתמודד עם JavaScript או לייצא נתונים מובנים, תצטרכו כלי ייעודי יותר.
מתחילים: דוגמאות לפקודות בסיסיות של גריפת אתרים ב-cURL
בואו נעבוד בידיים. כך משתמשים ב-cURL למשימות בסיסיות של גריפת אתרים, שלב אחר שלב.
משיכת HTML גולמי עם cURL
המקרה הפשוט ביותר: למשוך את ה-HTML של דף אינטרנט.
curl https://books.toscrape.com/
הפקודה הזו מביאה את דף הבית של Books to Scrape, אתר דמו ציבורי לגריפת אתרים. תראו את פלט ה-HTML הגולמי בטרמינל — חפשו תגים כמו <title> או קטעים כמו “In stock.”
שמירת הפלט לקובץ
רוצים לשמור את ה-HTML לניתוח מאוחר יותר? השתמשו בדגל -o:
curl -o page.html https://books.toscrape.com/
עכשיו יהיה לכם קובץ page.html עם תוכן ה-HTML המלא. זה מושלם לניתוח נוסף או לפריסה בעזרת כלים אחרים.
שליחת בקשות POST עם cURL
צריכים לשלוח טופס או לתקשר עם API? השתמשו בדגל -d לבקשות POST. הנה דוגמה עם httpbin, אתר שנועד לבדיקות HTTP:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
תקבלו תגובת JSON שתחזיר את הנתונים ששלחתם — מעולה לבדיקה וליצירת אבטיפוס.
בדיקת כותרות וניפוי שגיאות
לפעמים רוצים לראות את כותרות התגובה או לדבג את הבקשה:
-
כותרות בלבד (בקשת HEAD):
curl -I https://books.toscrape.com/ -
כולל כותרות יחד עם הגוף:
curl -i https://httpbin.org/get -
פלט verbose/debug:
curl -v https://books.toscrape.com/
הדגלים האלה עוזרים להבין מה קורה מאחורי הקלעים — חיוני לניפוי תקלות.
הנה טבלת עזר מהירה לפקודות האלה:
| משימה | דוגמת פקודה | הערות |
|---|---|---|
| משיכת HTML | curl URL | פולט HTML לטרמינל |
| שמירה לקובץ | curl -o file.html URL | כותב את הפלט לקובץ |
| בדיקת כותרות | curl -I URL or curl -i URL | -I ל-HEAD בלבד, -i כולל כותרות עם הגוף |
| שליחת נתוני טופס | curl -d "a=1&b=2" URL | שולח נתונים בקידוד טופס |
| ניפוי בקשה/תגובה | curl -v URL | מציג מידע מפורט על הבקשה/תגובה |
לעוד דוגמאות, בדקו את תיעוד ה-scripting הרשמי של cURL.
רמה אחת למעלה: גריפת אתרים מתקדמת עם cURL (גריפת אתרים ב-cURL)
אחרי שמתרגלים לבסיס, cURL פותח עולם של יכולות מתקדמות למשימות גריפה מורכבות יותר.
טיפול בעוגיות ובסשנים
אתרים רבים דורשים עוגיות כדי לשמור על סשני התחברות או לעקוב אחרי משתמשים. עם cURL אפשר לשמור ולהשתמש מחדש בעוגיות בין בקשות:
# שמירת עוגיות אחרי התחברות
curl -c cookies.txt https://example.com/login
# שימוש בעוגיות בבקשות הבאות
curl -b cookies.txt https://example.com/account
כך אפשר לחקות סשנים של דפדפן ולגשת לדפים שמאחורי מסך התחברות (כל עוד אין אתגר JavaScript).
התחזות ל-User-Agent והוספת כותרות מותאמות
חלק מהאתרים מציגים תוכן שונה בהתאם ל-User-Agent או לכותרות שלכם. כברירת מחדל, cURL מזדהה כ-“curl/VERSION”, מה שעלול להפעיל חסימות או תוכן חלופי. כדי לחקות דפדפן:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
אפשר גם להגדיר כותרות מותאמות, למשל העדפות שפה:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
זה עוזר לקבל את אותו תוכן שדפדפן אמיתי היה רואה.
שימוש בפרוקסי לגריפת אתרים
צריכים לנתב את הבקשות דרך פרוקסי (לבדיקות גאוגרפיות או כדי להימנע מחסימות IP)? השתמשו בדגל -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
רק ודאו שאתם משתמשים בפרוקסי באחריות ובהתאם לתנאי השימוש של האתר.
אוטומציה של גריפה מרובת דפים
רוצים לגרוף כמה דפים — למשל רשימות מוצרים מחולקות לעמודים? השתמשו בלולאת shell פשוטה:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
הקוד הזה מושך את דפים 2 עד 5 של קטלוג Books to Scrape ושומר כל אחד לקובץ נפרד. (עמוד 1 הוא דף הבית.)
מגבלות של גריפת אתרים ב-cURL: מה חשוב לדעת
למרות שאני אוהב את cURL, הוא לא פתרון קסם לכל בעיה. הנה איפה הוא נופל:
- אין ביצוע JavaScript: cURL לא יכול להתמודד עם דפים שדורשים JavaScript כדי לרנדר תוכן או לפתור אתגרי anti-bot (developers.cloudflare.com).
- נדרש ניתוח ידני: מקבלים HTML או JSON גולמיים, אבל צריך לנתח אותם בעצמכם — לרוב בעזרת סקריפטים או כלים נוספים.
- טיפול מוגבל בסשנים: ניהול כניסות מורכבות, טוקנים או טפסים מרובי שלבים עלול להסתבך מהר.
- אין מבנה נתונים מובנה: cURL לא הופך דפי אינטרנט לשורות, טבלאות או גיליונות אלקטרוניים.
- רגיש לזיהוי אנטי-בוט: אתרים רבים משתמשים היום בהגנות בוט מתקדמות (JavaScript, fingerprinting, CAPTCHAs) ש-cURL פשוט לא יכול לעקוף (datadome.co).
הנה טבלת השוואה מהירה:
| מגבלה | cURL בלבד | כלי גריפה מודרניים (למשל Thunderbit) |
|---|---|---|
| תמיכה ב-JavaScript | לא | כן |
| מבנה נתונים | ידני | אוטומטי (AI/תבנית) |
| טיפול בסשנים | ידני | אוטומטי |
| עקיפת אנטי-בוט | מוגבל | מתקדם (מבוסס דפדפן/AI) |
| קלות שימוש | טכני | לא טכני |
עבור דפים סטטיים ו-APIs, cURL הוא מצוין. לכל דבר דינמי יותר או מוגן יותר, תצטרכו לעלות שלב בשרשרת הכלים.
Thunderbit מול cURL: גישת גריפת האתרים הטובה ביותר למשתמשים לא טכניים
עכשיו בואו נדבר על Thunderbit, תוסף Chrome ה-web scraper שלנו המופעל ב-AI. אם אתם אנשי מכירות, שיווק או תפעול שפשוט רוצים להביא נתונים מאתר ל-Excel, Google Sheets או Notion — בלי לגעת בשורת הפקודה — Thunderbit נבנה בשבילכם.
כך Thunderbit משווה ל-cURL:
| תכונה | cURL | Thunderbit |
|---|---|---|
| ממשק משתמש | שורת פקודה | קליק-קליק (תוסף Chrome) |
| הצעת שדות ב-AI | לא | כן (ה-AI קורא את הדף ומציע עמודות) |
| טיפול בדפדוף/תתי-דפים | סקריפטינג ידני | אוטומטי (ה-AI מזהה וגורף) |
| ייצוא נתונים | ידני (ניתוח + שמירה) | ישירות ל-Excel, Google Sheets, Notion, Airtable |
| דפי JavaScript/מוגנים | לא | כן (גריפה מבוססת דפדפן) |
| בלי צורך בקוד | לא (דורש סקריפטינג) | כן (כל אחד יכול להשתמש) |
| שכבת חינם | תמיד חינם | חינם עד 6 דפים (10 עם Boost לניסיון) |
עם Thunderbit, פשוט פותחים את התוסף, לוחצים על “AI Suggest Fields”, ונותנים ל-AI להבין אילו נתונים לחלץ. אפשר לגרוף טבלאות, רשימות, פרטי מוצרים ואפילו לבקר בתתי-דפים באופן אוטומטי. אחר כך מייצאים את הנתונים ישירות לכלי העסקיים המועדפים עליכם — בלי ניתוח, בלי כאב ראש.
Thunderbit זוכה לאמון של יותר מ-100,000 משתמשים ברחבי העולם, והוא פופולרי במיוחד בקרב צוותי מכירות, ecommerce ונדל״ן שצריכים נתונים מובנים במהירות.
נסו את תוסף Chrome של Thunderbit לגריפת אתרים
רוצים לנסות? הורידו את תוסף Chrome כאן.
שילוב cURL ו-Thunderbit: אסטרטגיות גמישות לגריפת אתרים
אם אתם משתמשים טכניים, אין צורך לבחור רק בכלי אחד. למעשה, הרבה צוותים משתמשים יחד ב-cURL וב-Thunderbit כדי למקסם גמישות:
- אבטיפוס עם cURL: השתמשו ב-cURL כדי לבדוק במהירות endpoints, לבדוק כותרות ולהבין איך אתר מגיב.
- להתרחב עם Thunderbit: כשצריך נתונים מובנים, גריפת כמה דפים או תהליך עבודה שניתן לחזור עליו, עוברים ל-Thunderbit לחילוץ בלחיצה וייצוא ישיר.
הנה זרימת עבודה לדוגמה למחקר שוק:
- השתמשו ב-cURL כדי למשוך כמה דפים ולבדוק את מבנה ה-HTML.
- זהו את שדות הנתונים שאתם רוצים (למשל שמות מוצרים, מחירים, ביקורות).
- פתחו את Thunderbit, לחצו על “AI Suggest Fields”, ותנו ל-AI להגדיר את ה-scraper.
- גרפו את כל הדפים (כולל תתי-דפים או רשימות מחולקות לעמודים) וייצאו ל-Google Sheets.
- נתחו, שתפו ופעלו לפי הנתונים שלכם — בלי ניתוח ידני.
הנה טבלת החלטה מהירה:
| תרחיש | להשתמש ב-cURL | להשתמש ב-Thunderbit | להשתמש בשניהם |
|---|---|---|---|
| משיכת API מהירה או דף סטטי | ✅ | ||
| צריך נתונים מובנים בגיליון אלקטרוני | ✅ | ||
| ניפוי כותרות/עוגיות | ✅ | ||
| גריפת דפים דינמיים/עשירים ב-JS | ✅ | ||
| בניית workflow ניתן לחזרה ללא קוד | ✅ | ||
| יצירת אבטיפוס ואז הרחבה | ✅ | ✅ | זרימת עבודה היברידית |
אתגרים נפוצים ומוקשים בגריפת אתרים עם cURL
לפני שתשתוללו עם cURL, בואו נדבר על האתגרים שתפגשו בעולם האמיתי:
- מערכות אנטי-בוט: אתרים רבים משתמשים היום בהגנות מתקדמות (אתגרי JavaScript, CAPTCHAs, fingerprinting) ש-cURL לא יכול לעקוף (developers.cloudflare.com).
- בעיות באיכות הנתונים: שינויים ב-HTML, שדות חסרים או פריסות לא עקביות יכולים לשבור את הסקריפטים שלכם.
- עומס תחזוקה: בכל פעם שאתר משתנה, תצטרכו לעדכן את לוגיקת הניתוח שלכם.
- סיכוני חוקיות ותאימות: תמיד בדקו את תנאי השימוש של האתר, robots.txt והחוקים הרלוונטיים לפני גריפה. רק כי נתון הוא ציבורי, לא אומר שהוא חופשי לשימוש (calawyers.org, polsinelli.com).
- מגבלות בקנה מידה: cURL נהדר למשימות קטנות, אבל לגריפה בקנה מידה גדול תצטרכו לנהל פרוקסי, מגבלות קצב וטיפול בשגיאות.
טיפים לפתרון תקלות ולשמירה על תאימות:
- תמיד התחילו מאתרים עם הרשאה או אתרי דמו (כמו Books to Scrape).
- כבדו מגבלות קצב — אל תתקפו endpoints.
- הימנעו מגריפת נתונים אישיים אלא אם יש לכם בסיס חוקי לכך.
- אם אתם נתקלים בקירות של JavaScript או CAPTCHA, שקלו לעבור לכלי מבוסס דפדפן כמו Thunderbit.
סיכום שלב-אחר-שלב: איך לגרוף אתרים עם cURL
הנה צ'קליסט מהיר לרפרנס לגריפת אתרים ב-cURL:
- זהו את כתובת/ות ה-URL היעד: התחילו עם דף סטטי או endpoint של API.
- משכו את הדף:
curl URL - שמרו את הפלט לקובץ:
curl -o file.html URL - בדקו כותרות/דיבוג:
curl -I URL,curl -v URL - שלחו נתוני POST:
curl -d "a=1&b=2" URL - טפלו בעוגיות/סשנים:
curl -c cookies.txt ...,curl -b cookies.txt ... - הגדירו כותרות מותאמות/User-Agent:
curl -A "..." -H "..." URL - עקבו אחרי הפניות:
curl -L URL - השתמשו בפרוקסי (אם צריך):
curl -x proxy:port URL - אוטומטו גריפה מרובת דפים: השתמשו בלולאות shell או בסקריפטים.
- נתחו ומבנו את הנתונים: השתמשו בכלים/סקריפטים נוספים לפי הצורך.
- עברו ל-Thunderbit לגריפה מובנית, ללא קוד או לדפים דינמיים.
מסקנה ותובנות מרכזיות: בחירת כלי גריפת האתרים הנכון
גריפת נתונים מכל אתר באמצעות AI Get Started Free
גריפת אתרים ב-cURL עדיין מיומנות חזקה למשתמשים טכניים ב-2026 — במיוחד למשיכות נתונים מהירות, יצירת אבטיפוס ואוטומציה. המהירות, יכולת הסקריפטינג והנפוצות של cURL הופכות אותו לחלק קבוע בארגז הכלים של כל מפתח. אבל ככל שהאינטרנט נעשה דינמי ומוגן יותר, וככל שמשתמשי עסק דורשים נתונים מובנים בלי קוד, כלים כמו Thunderbit מגדירים מחדש מה אפשרי.
עיקרי הדברים:
- השתמשו ב-cURL עבור דפים סטטיים, APIs ויצירת אבטיפוס מהירה — במיוחד כשאתם רוצים שליטה מלאה.
- עברו ל-Thunderbit (או ל-AI web scrapers דומים) כשאתם צריכים נתונים מובנים, דפים דינמיים/עשירים ב-JavaScript, או תהליך עבודה ידידותי לעסקים בלי קוד.
- שלבו בין השניים כדי לקבל גמישות מקסימלית: אבטיפוס עם cURL, ואז הרחבה ומבנה עם Thunderbit.
- תמיד גרפו באחריות — כבדו תנאי אתר, מגבלות קצב וגבולות חוקיים.
סקרנים לראות כמה פשוטה יכולה להיות גריפת אתרים? נסו את תוסף Chrome החינמי של Thunderbit ותתנסו בעצמכם בחילוץ נתונים המופעל ב-AI. ואם תרצו להעמיק, בדקו את בלוג Thunderbit לעוד מדריכים, טיפים ותובנות מהתעשייה. ייתכן שתאהבו גם:
- איך לגרוף כל אתר באמצעות AI
- איך לגרוף נתוני אתר ל-Excel באמצעות AI
- מהי גריפת נתונים ואיך עושים זאת ב-2025
גריפה נעימה — ושהנתונים שלכם תמיד יהיו נקיים, מובנים, ובמרחק פקודה (או קליק) אחד.
גלו את תוכניות Thunderbit לגריפת אתרים בהיקף גדול
שאלות נפוצות
1. האם cURL יכול להתמודד עם דפי אינטרנט שמרונדרים ב-JavaScript?
לא, cURL לא יכול להריץ JavaScript. הוא מביא HTML גולמי כפי שהשרת מספק אותו. אם דף דורש JavaScript כדי לרנדר תוכן או לפתור אתגרי anti-bot, cURL לא יוכל לגשת לנתונים. במקרים כאלה, השתמשו בכלים מבוססי דפדפן כמו Thunderbit.
2. איך שומרים פלט של cURL ישירות לקובץ?
השתמשו בדגל -o: curl -o filename.html URL. זה כותב את גוף התגובה לקובץ במקום להציג אותו בטרמינל.
3. מה ההבדל בין cURL ל-Thunderbit עבור גריפת אתרים?
cURL הוא כלי שורת פקודה למשיכת נתוני אינטרנט גולמיים — מצוין למשתמשים טכניים ולאוטומציה. Thunderbit הוא תוסף Chrome המופעל ב-AI, שנועד למשתמשי עסק שרוצים לחלץ נתונים מובנים מכל אתר, להתמודד עם דפים דינמיים ולייצא ישירות לכלים כמו Excel או Google Sheets — בלי קוד.
4. האם זה חוקי לגרוף אתרים עם cURL?
גריפת נתונים ציבוריים היא בדרך כלל חוקית בארה״ב לאחר פסיקות משפטיות מהשנים האחרונות, אבל תמיד צריך לבדוק את תנאי השימוש של האתר, robots.txt והחוקים הרלוונטיים. הימנעו מגריפת נתונים אישיים או מוגנים בלי אישור, וכבדו מגבלות קצב והנחיות אתיות (calawyers.org, polsinelli.com).
5. מתי כדאי לעבור מ-cURL לכלי מתקדם יותר כמו Thunderbit?
אם צריך לגרוף דפים דינמיים/עשירים ב-JavaScript, אם רוצים נתונים מובנים בגיליון אלקטרוני, או אם מעדיפים workflow ללא קוד, Thunderbit הוא הבחירה הטובה יותר. השתמשו ב-cURL למשימות מהירות וטכניות; השתמשו ב-Thunderbit לחילוץ נתונים ידידותי לעסקים, שניתן לחזור עליו.
לעוד טיפים ומדריכים על גריפת אתרים, בקרו ב-בלוג Thunderbit או בדקו את ערוץ היוטיוב שלנו.
נסו את AI Web Scraper של Thunderbit Get Started Free




