האם גריפת אתרים היא בלתי חוקית? זו שאלת מיליון הדולר שאני שומע ממייסדים, משווקים וחובבי דאטה מדי שבוע.
עם —הפעם הראשונה שתעבורה אוטומטית עקפה את הפעילות האנושית—ועם נתח גדול מזה שמוקדש לגריפת אתרים לצורכי מודיעין עסקי, מכירות ואימון AI, לא פלא שכולם מנסים להבין איפה בדיוק עובר הקו המשפטי.
יום אחד תראו כותרת על פסק דין שקובע שגריפת נתונים ציבוריים מותרת. למחרת רגולטורים מזהירים מפני איסוף נתונים "בלתי חוקי" מרשתות חברתיות. זה מבלבל, אפילו לאנשים כמוני שמקדישים את ימיהם לבניית כלי AI Web Scraper ב-.
אז האם גריפת אתרים היא בלתי חוקית? התשובה אינה פשוט כן או לא. זה תלוי מה אתם גורפים, מאיפה אתם גורפים, איך אתם משתמשים בנתונים, ומה החוק קובע במדינה שלכם.
בסקירה המעמיקה הזו אפרק את המצב המשפטי, אפריך כמה מיתוסים נפוצים, ואשתף טיפים מעשיים (וגם כמה סיפורי קרב) שיעזרו לכם להישאר תואמי חוק—בין אם אתם מייסדים עצמאיים או צוות דאטה של Fortune 500.
גריפת אתרים והחוק: האם יש קו ברור?
אם אתם מקווים לתשובה במשפט אחד, אחסוך לכם זמן: החוק עדיין לא סימן קו חד וברור סביב גריפת אתרים.
במקום זאת, יש פסיפס של כללים חופפים—בעלות על נתונים, פרטיות, קניין רוחני, חוקים נגד פריצה, ואותם Terms of Service (ToS) מפורסמים לשמצה. כל אחד מהם עשוי להיכנס לתמונה, ולעיתים התשובה תלויה מאוד בנסיבות הספציפיות שלכם ().
בואו נפרק את שלושת התחומים המשפטיים העיקריים:
- בעלות על נתונים: בדרך כלל, עובדות ומידע ציבורי (כמו מחירים או מספרי טלפון) אינם מוגנים בזכויות יוצרים. אבל תוכן יצירתי (מאמרים, תמונות) ומאגרי מידע קנייניים יכולים להיות מוגנים—במיוחד באיחוד האירופי, שבו קיימות גם "זכויות במאגרי מידע" ().
- פרטיות: חוקי פרטיות מודרניים (למשל GDPR באירופה, PIPL בסין) מתייחסים לנתונים אישיים כנכס מוסדר—גם אם הם פורסמו בפומבי. גריפה של שמות, אימיילים או פרופילים חברתיים בלי בסיס חוקי עלולה להכניס אתכם לצרות ().
- חוזים (תנאי שימוש): אתרים רבים אוסרים במפורש גריפה ב-ToS שלהם. אף ש-ToS אינם חוקים, בתי משפט יכולים לראות בהם חוזים מחייבים. הפרה שלהם עלולה להוביל לתביעות, ובמקרים מסוימים אפילו להפעיל סעיפי anti-hacking אם עוקפים חסימות טכניות ().
אז האם גריפת אתרים היא בלתי חוקית? לפעמים כן, לפעמים לא, וברוב המקרים—"זה תלוי". השטן, כמו תמיד, בפרטים הקטנים.
השוואת גישות משפטיות: ארה״ב, האיחוד האירופי, בריטניה, סין
הנה טבלה קצרה שמראה איך אזורים מרכזיים מתייחסים לגריפת אתרים:
| אזור | גריפת נתונים ציבוריים | גריפת נתונים אישיים/פרטיים | אכיפה ונקודות בולטות |
|---|---|---|---|
| ארה"ב | בדרך כלל מותר עבור נתונים ציבוריים (ראו hiQ v. LinkedIn). הפרת ToS עלולה להוביל לתביעות אזרחיות. | מוגבל/בלתי חוקי אם עוקפים כניסות או עושים שימוש לרעה בנתונים אישיים. חוקי מדינה (כמו CCPA) עשויים לחול. | מכתבי cease-and-desist, חסימת IP, תביעות. CFAA חל אם עוקפים מחסומים טכניים. |
| האיחוד האירופי | מותר בתנאים עבור נתונים ציבוריים שאינם אישיים. עשויות לחול זכויות במאגרי מידע. חוק ה-AI של האיחוד האירופי (2026) מוסיף דרישות שקיפות לנתוני אימון AI. | מוסדר מאוד תחת GDPR—גם לנתונים אישיים פומביים נדרש בסיס חוקי. | רשויות הגנת מידע יכולות להטיל קנסות על הפרות פרטיות. נאכפות גם זכויות יוצרים/מאגרי מידע. חוק ה-AI של האיחוד אוסר גריפת תמונות פנים לצורכי AI. |
| בריטניה | דומה לאיחוד האירופי. אפשר לגרוף נתונים ציבוריים שאינם אישיים, אך יש לכבד זכויות נתונים וחוזים. | מחמיר לגבי נתונים אישיים—UK GDPR חל. Computer Misuse Act מפליל גישה בלתי מורשית. | ה-ICO יכול להעניש על הפרות הגנת מידע. בתי משפט עשויים לאכוף ToS. |
| סין | מפוקח מאוד. ייתכן שגריפת נתונים ציבוריים שאינם אישיים מותרת לשימוש פנימי, אך הסביבה זהירה. | מוגבל מאוד—PIPL דורש הסכמה לנתונים אישיים. חלים גם חוקים נגד תחרות בלתי הוגנת. | תיקים פליליים על גריפה רחבת היקף. בתי משפט משתמשים בדיני תחרות בלתי הוגנת כדי לעצור גריפה בלתי מורשית. |
(, )
האם גריפת אתרים היא בלתי חוקית? הגורמים המשפטיים המרכזיים שיש לשקול
אז מה באמת קובע אם פרויקט הגריפה שלכם חוקי או מסוכן? הנה הגורמים העיקריים:
- נתונים ציבוריים לעומת פרטיים: גריפת נתונים שכל אחד יכול לראות ברשת הפתוחה היא בדרך כלל בטוחה יותר. אבל גריפה של משהו שמאחורי התחברות, חומת תשלום או מחסום טכני? סביר מאוד שזה בלתי חוקי ().
- סוג הנתונים: נתונים אישיים (שמות, אימיילים, פרופילים) מפעילים חוקי פרטיות. תוכן מוגן בזכויות יוצרים (מאמרים, תמונות) אי אפשר להעתיק בשלמותו. עובדות טהורות (מחירים, מזג אוויר) הן בדרך כלל מותרות ().
- שימוש מיועד: ניתוח פנימי או מחקר מקבלים בדרך כלל יחס סלחני יותר מאשר פרסום מחדש או מכירה של נתונים שנגרפו. שימוש בנתונים שנגרפו כדי להתחרות ישירות במקור? זו תביעה שמחכה לקרות ().
- עמידה בכללי האתר: בדקו תמיד robots.txt ו-ToS. robots.txt אינו מחייב משפטית, אבל זו פרקטיקה טובה לכבד אותו. הפרת ToS עלולה להוביל לתביעות אזרחיות או גרוע מכך ().
- אמצעים טכניים: חשוב לגרוף בקצב דמוי-אנושי ולא לעקוף מנגנוני אבטחה. הפצצה של שרת או עקיפה של CAPTCHA עלולות לחצות את הקו לתחום הפריצה ().
מה השתנה ב-2024–2026: פסקי דין ורגולציות מרכזיים
הנוף המשפטי של גריפת אתרים השתנה באופן דרמטי מאז 2023. הנה ההתפתחויות שכל scraper חייב להכיר:
פסקי דין מרכזיים
-
Meta נגד Bright Data (2024): בית משפט פדרלי בארה״ב . השופט קבע ש"מבקר אינו נחשב ל'משתמש' אלא אם יש לו חשבון". זמן קצר לאחר מכן Meta ויתרה על יתר הטענות. זהו ניצחון משמעותי לגריפת נתונים ציבוריים.
-
X Corp נגד Bright Data (2024): Twitter (כיום X) הפסידה בתביעה דומה, מה שחיזק את אותו עיקרון: גריפת נתונים ציבוריים ללא התחברות אינה הפרה של ToS, משום שה-scraper לא הסכים מעולם לתנאים הללו.
-
Reddit נגד Perplexity AI (אוקטובר 2025): Reddit , בטענה להפרות DMCA ולעקיפת מערכות נגד בוטים. זה מסמן אסטרטגיה משפטית חדשה: פלטפורמות עוברות לטענות של זכויות יוצרים ואנטי-עקיפה במקום CFAA.
-
NYT נגד OpenAI (מרץ 2025): שופט פדרלי , ודחה את בקשת OpenAI לסילוק. זה עשוי לקבוע תקדים משמעותי בשאלה אם גריפת תוכן לצורך אימון מודלי AI נחשבת ל-"שימוש הוגן".
-
הסדר Anthropic (ספטמבר 2025): Anthropic הסכימה לשלם 1.5 מיליארד דולר כדי להסדיר תובענה ייצוגית אמריקאית על שימוש בטקסטים מוגנים בזכויות יוצרים לצורך אימון מודל ה-AI שלה—סימן לכך שהעלויות של גריפה לצורכי AI הן אמיתיות מאוד.
המגמה הגדולה: מ-CFAA אל דיני חוזים וזכויות יוצרים
התבנית ברורה: חוק ה-CFAA (Computer Fraud and Abuse Act) מאבד מכוחו כנשק נגד גורפי נתונים ציבוריים. חברות שניסו להשתמש ב-CFAA נגד גריפת נתונים ציבוריים—Meta, X, LinkedIn—נכשלו ברובן. במקום זאת, זירת הקרב המשפטית זזה אל:
- דיני חוזים (הפרות ToS—אבל בתי המשפט אומרים שמשתמשים שאינם משתמשים רשומים אינם כבולים ל-ToS)
- טענות לזכויות יוצרים (במיוחד עבור נתוני אימון ל-AI)
- חוקי anti-circumvention (סעיף 1201 ב-DMCA)
לגורפי אתרים, המשמעות היא שהסיכון המשפטי לא נעלם—הוא פשוט עבר מקום.
שינויים רגולטוריים
- עדכוני CCPA לשנת 2026: התקנות המעודכנות של קליפורניה ל-CCPA , והוסיפו כללים חדשים לטכנולוגיות קבלת החלטות אוטומטיות (ADMT), להערכות סיכון ולחובות של data brokers.
- חוקי פרטיות חדשים במדינות בארה״ב: אינדיאנה, קנטקי ורוד איילנד חוקקו חוקי פרטיות מקיפים שנכנסו לתוקף ב-2026.
- חוק ה-AI של האיחוד האירופי: האכיפה המלאה מתחילה ב-—החוק מחייב מפתחי AI לחשוף מקורות נתוני אימון, לכבד opt-out של זכויות יוצרים, ואוסר גריפת תמונות פנים למערכות AI.
- AI Accountability for Publishers Act (פברואר 2026): הצעת חוק אמריקאית שתדרוש מחברות AI לקבל אישור ולשלם למו״לים לפני גריפת התוכן שלהם.
מדיניות גריפה של פלטפורמות מרכזיות: מה חשוב לדעת
לא כל אתר מתייחס לגריפה באותו אופן. הנה פירוק לפי פלטפורמות של מה האתרים הגדולים מאפשרים, מה הם חוסמים, ומה בתי המשפט אמרו:
| פלטפורמה | ToS על גריפה | הגנות טכניות | אכיפה משפטית | מה בטוח מעשית |
|---|---|---|---|---|
| Google (Search & Maps) | אוסרת גישה אוטומטית ב-ToS. ל-Maps Platform יש סעיף מפורש של "No Scraping". | אתגרי SearchGuard JS, CAPTCHA, הגבלת קצב. עדכון robots.txt ב-2025 כדי לחסום crawlers של AI. | תבעה גורפים בדצמבר 2025 באמצעות DMCA. חוסמת באופן פעיל crawlers של AI (Anthropic, Meta, OpenAI). | גריפת נתונים עסקיים ציבוריים ב-Google Maps היא בעלת הגנה משפטית (תקדים hiQ), אבל צפויות חסימות טכניות. עדיף להשתמש ב-API רשמי כשאפשר. |
| Amazon | אוסרת במפורש כל גריפה ב-Conditions of Use ("no robot, spider, scraper, or other automated means"). | זיהוי בוטים אגרסיבי, CAPTCHA, חסימת IP. robots.txt חוסם את כל הבוטים מלבד Googlebot/Bingbot. חוסם במפורש crawlers של AI מאז 2025. | תבעה את Perplexity AI בנובמבר 2025. שולחת מכתבי cease-and-desist באופן קבוע. עדכנה את BSA במרץ 2026 עם כללי agent AI. | נתוני מוצרים ציבוריים (מחירים, רשימות) הם עובדתיים וניתנים לגריפה לפי הדין האמריקאי, אבל Amazon נלחמת בזה חזק. הגבילו קצב בקשות והימנעו מנתונים אישיים. |
| אוסרת גריפה ב-ToS; נדרשת הסכמה של המשתמש כדי לגשת לשירותים. | חומות התחברות לרוב נתוני הפרופיל, זיהוי anti-bot, הגבלת קצב. | תיק hiQ אישר שגריפת פרופילים ציבוריים אינה הפרה של CFAA, אבל LinkedIn ניצחה בטענות חוזיות/תחרות בלתי הוגנת כשנעשה שימוש בחשבונות פיקטיביים. | פרופילים ציבוריים (שנראים בלי התחברות) הם יעד בעל הגנה משפטית סבירה לגריפה. אסור ליצור חשבונות פיקטיביים או לגרוף נתונים מאחורי התחברות. | |
| Meta (Facebook & Instagram) | ToS אוסרים גריפה; כללים נפרדים לנתונים מחוברים מול לא מחוברים. | חומות התחברות לרוב התוכן, זיהוי בוטים מתקדם. | הפסידה ל-Bright Data ב-2024—בית המשפט קבע ש-ToS לא חלים על גורפים שאינם מחוברים. Meta ויתרה על שאר הטענות. | נתונים ציבוריים (עמודי עסקים, פוסטים ציבוריים) שנראים בלי התחברות נמצאים במצב בטוח יותר. אסור לגרוף פרופילים פרטיים או נתונים מאחורי התחברות. |
| X (Twitter) | עדכנה את ה-ToS ב-2023 כדי לאסור כל גריפה ו-crawling ללא הסכמה בכתב. ביטלה את חריג robots.txt הישן. | robots.txt חוסם את כל ה-crawlers (Disallow: /). אתגרי Cloudflare Turnstile. מגבלות קצב נוקשות (300 בקשות/שעה). דירוג מוניטין IP. | הפסידה ל-Bright Data בנוגע לנתונים ציבוריים, אך מגבילה מאוד את הגישה הטכנית. | ציוצים ופרופילים ציבוריים הם בעלי הגנה משפטית סבירה לגריפה, אבל המחסומים הטכניים של X הם מהקשים ביותר ב-2026. צפו לחסימות ללא תשתית פרוקסי פרימיום. |
השורה התחתונה: בתי המשפט קבעו שוב ושוב שגריפת נתונים ציבוריים הנראים לכל, ללא התחברות אינה מפרה את CFAA. אבל פלטפורמות עדיין יכולות לפעול נגדכם דרך דיני חוזים, זכויות יוצרים או טענות anti-circumvention—והן בהחלט יקשה עליכם טכנית. תמיד גרפו באחריות.
נתוני אימון ל-AI וגריפת אתרים: החזית המשפטית החדשה
אם אתם עוקבים אחרי החדשות ב-2026, אתם יודעים שגריפת נתונים לצורך אימון מודלי AI הפכה לשדה הקרב המשפטי החם ביותר. הנה מה שקורה:
- תביעות זכויות יוצרים מצטברות. ה-New York Times, סופרים ומו״לים תבעו את OpenAI, Anthropic ואחרים, בטענה שגריפה המונית של תוכן מוגן לצורך אימון LLMs אינה "שימוש הוגן". Anthropic הגיעה להסדר של תביעה ייצוגית גדולה ב-1.5 מיליארד דולר ב-2025—סימן לכך שהעלויות של גריפה לצורכי AI הן ממשיות מאוד.
- ההגנה של "שימוש הוגן" אינה יציבה. בתי המשפט בארה״ב עדיין לא נתנו פסק דין סופי בשאלה אם אימון AI על נתונים שנגרפו הוא שימוש הוגן. פסיקות מוקדמות מרמזות שזה תלוי מאוד באופן שבו הנתונים הושגו ובמה עושים עם פלט ה-AI.
- חקיקה חדשה בדרך. ה- (שהוצג בפברואר 2026) שואף לחייב חברות AI לקבל אישור ולשלם למו״לים לפני גריפת התוכן שלהם.
- חוק ה-AI של האיחוד האירופי (אכיפה מלאה ב-) מחייב מפתחי AI לחשוף מקורות נתוני אימון, לכבד opt-out קריא-מכונה של זכויות יוצרים (תחת חריג ה-TDM של דירקטיבת זכויות היוצרים), ולסמן תוכן שנוצר ב-AI. הוא גם אוסר על מערכות AI שגורפות תמונות פנים מהאינטרנט.
- crawlers של AI/LLM מתפוצצים. נתח התעבורה של crawlers של AI גדל פי ארבעה מ-2.6% ל-10.1% בתוך שמונה חודשים בלבד. GPTBot של OpenAI לבדו צמח ב-305%. בתגובה, אתרים גדולים (Amazon, Reddit, ה-NYT) מעדכנים robots.txt כדי לחסום במפורש crawlers של AI.
מה זה אומר עבורכם: אם אתם גורפים נתונים לצרכים עסקיים מסורתיים (יצירת לידים, ניטור מחירים, מחקר שוק), ייתכן שהכללים הספציפיים ל-AI לא יחולו ישירות. אבל אם אתם מזינים נתונים שנגרפו לתוך מודלי AI, צעדו בזהירות רבה—וקבלו ייעוץ משפטי.
חוקי גריפת אתרים בעולם: השוואה מהירה
בואו נתרחק קצת ונראה איך הכללים מסתדרים ברמה הגלובלית:
- ארצות הברית: אין איסור גורף. גריפה של אתרים ציבוריים היא בדרך כלל חוקית (), ופסקי הדין נגד Meta ו-X Corp ב-2024 חיזקו עוד יותר את הטיעון לטובת גריפת נתונים ציבוריים. אבל גריפה מאחורי התחברות או מחסומים טכניים עדיין עלולה להפעיל את CFAA. המגמה כעת היא שחברות משתמשות במקום זאת בדיני חוזים וטענות זכויות יוצרים. חוקי הפרטיות מתרחבים במהירות: CCPA קיבל עדכונים משמעותיים שנכנסו לתוקף ב-1 בינואר 2026, כולל כללים חדשים לקבלת החלטות אוטומטיות וחובות על data brokers. גם אינדיאנה, קנטקי ורוד איילנד חוקקו חוקי פרטיות מקיפים ב-2026.
- האיחוד האירופי: חוקי פרטיות מחמירים. GDPR חל אפילו על נתונים אישיים ציבוריים. זכויות במאגרי מידע יכולות לחסום גריפה רחבת היקף של נתונים מובנים (). חדש: נכנס לאכיפה מלאה ב-2 באוגוסט 2026, ודורש ממפתחי AI לחשוף מקורות נתוני אימון ולכבד opt-out של זכויות יוצרים. החוק אוסר גריפת תמונות פנים מהאינטרנט לצורך מערכות AI.
- בריטניה: מיישרת קו עם כללי האיחוד האירופי אחרי הברקזיט. אפשר לגרוף נתונים ציבוריים, אבל גריפת מידע אישי מוסדרת בקפדנות. Computer Misuse Act יכול להפליל גישה בלתי מורשית.
- סין: מגבילה מאוד. PIPL ו-Data Security Law דורשים הסכמה לנתונים אישיים. בתי משפט משתמשים בדיני תחרות בלתי הוגנת כדי לחסום גריפה שפוגעת בעסקים ().
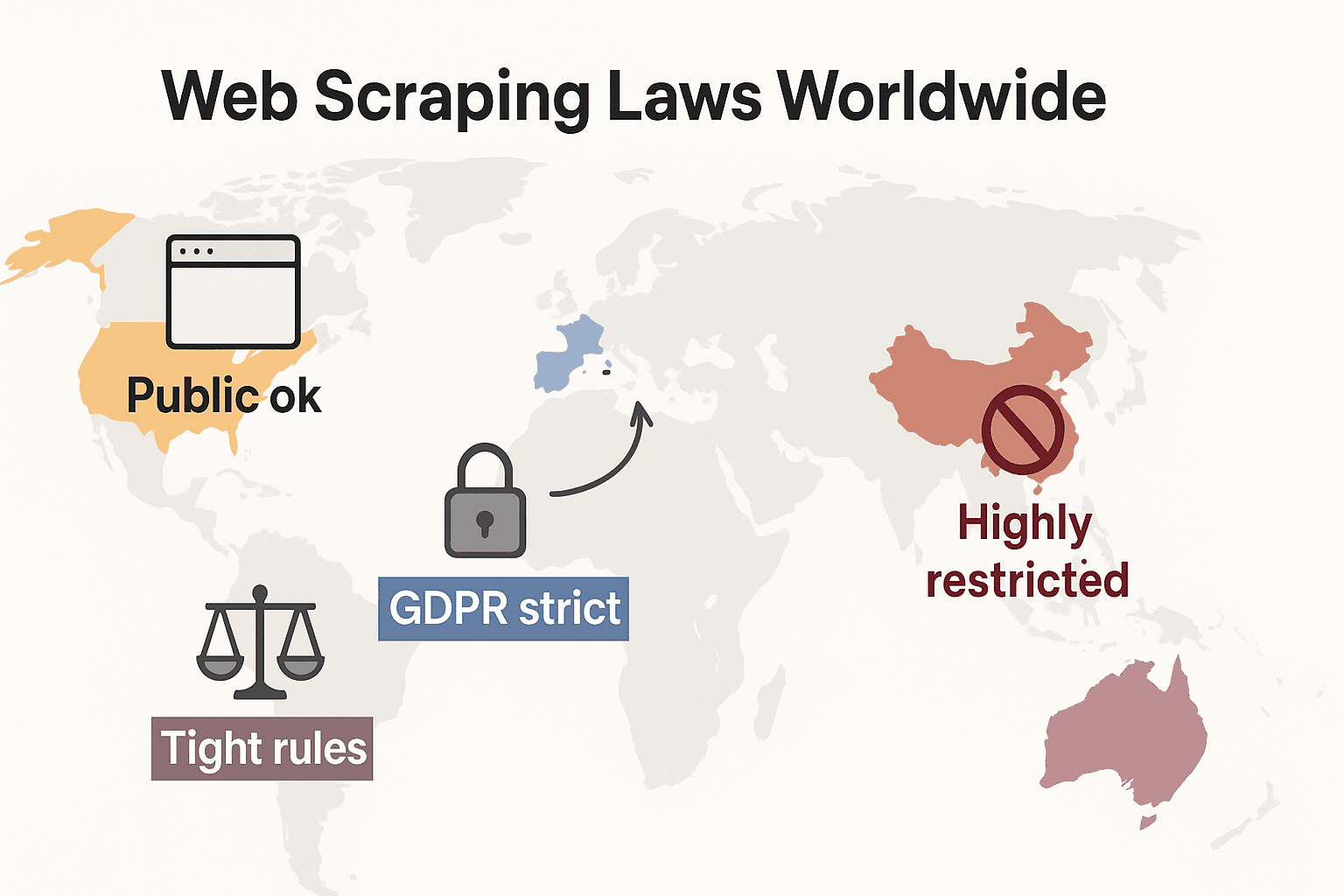
בשורה התחתונה: גריפת נתונים ציבוריים שאינם אישיים לשימוש פנימי היא בדרך כלל הבטוחה ביותר. כל דבר אחר? בדקו את החוקים המקומיים ופעלו בזהירות.
מיתוסים נפוצים על החוקיות של גריפת אתרים
בואו נפריך כמה מיתוסים שאני שומע כל הזמן:
- מיתוס 1: "גריפת אתרים היא בלתי חוקית, נקודה."
לא נכון. אין חוק שאוסר על כל גריפת אתרים. מה שחשוב הוא איך ומה אתם גורפים (). - מיתוס 2: "אם המידע ציבורי, אני יכול לעשות איתו מה שבא לי."
לא בדיוק. מידע ציבורי עדיין יכול להיות מוגן על ידי חוקי פרטיות או זכויות יוצרים, ו-ToS עשויים להגביל שימושים מסוימים (). - מיתוס 3: "גריפת אתרים זה אותו דבר כמו פריצה."
לא. גריפה של דפי אינטרנט ציבוריים אינה פריצה. עקיפת התחברויות או מחסומים טכניים היא סיפור אחר (). - מיתוס 4: "אם לא תפסו אותי, הכול בסדר."
חשיבה מסוכנת. אתרים רבים משתמשים בטכנולוגיות נגד בוטים ויבחינו בכך. שתיקה אינה הסכמה. - מיתוס 5: "אם נותנים קרדיט או משתמשים בזה פנימית, זה בסדר."
מתן קרדיט לא גובר על דיני זכויות יוצרים או פרטיות. שימוש פנימי בטוח יותר, אבל הוא לא כרטיס חופשי. - מיתוס 6: "כל גריפת אתרים מפרה פרטיות."
לא כל גריפה כוללת נתונים אישיים. אבל גריפה של כמויות גדולות של מידע אישי בלי אמצעי הגנה היא כמעט תמיד בלתי חוקית (). - מיתוס 7: "אם ToS של אתר אוסרים גריפה, אז תמיד בלתי חוקי לגרוף."
לא בהכרח. ב-2024 קבעו בתי המשפט ב-Meta v. Bright Data וב-X Corp v. Bright Data ש-ToS אינם מחייבים משתמשים שמעולם לא הסכימו להם—כלומר, אם אתם גורפים בלי התחברות או בלי פתיחת חשבון, ייתכן שתנאי האתר לא חלים עליכם. זה עדיין תחום מתפתח, אבל מדובר בשינוי משמעותי.
איך לגרוף נתונים באופן חוקי: שיטות עבודה מומלצות לעמידה בדרישות
הנה צ'קליסט הקבוע שלי לגריפת אתרים חוקית ואתית:
- קראו והקפידו על תנאי השימוש של האתר. אם כתוב "אין גריפה", שקלו לעצור או לבקש אישור ().
- היצמדו לנתונים ציבוריים. אם צריך סיסמה, מדובר בנתונים מוגבלים—אל תגרפו אותם ().
- בדקו robots.txt וגרפו בנימוס. זה לא מחייב משפטית, אבל זו אדיבות בסיסית. אל תעמיסו על השרתים—פזרו את הבקשות שלכם ().
- הימנעו מנתונים אישיים אלא אם יש לכם בסיס חוקי. אם חייבים לאסוף אותם, עמדו ב-GDPR/CCPA וצמצמו את היקף האיסוף.
- אל תפרסמו מחדש תוכן שנגרף בשלמותו. הוסיפו ערך או ניתוח, או קבלו אישור ().
- אל תזינו תוכן שנגרף למודלי AI בלי לבדוק זכויות יוצרים. המצב המשפטי משתנה במהירות—קבלו ייעוץ אם זהו תרחיש השימוש שלכם.
- השתמשו ב-API רשמי או בייצוא נתונים כשיש כאלה. הם נועדו בדיוק לזה ובדרך כלל בטוחים יותר ().
- היו שקופים ואחראים. אם אתם אוספים נתונים אישיים, הודיעו לאנשים ושמרו יומן פעילות.
- צמצמו ואבטחו את הנתונים שלכם. אספו רק מה שאתם צריכים, שמרו על דיוקם ואחסנו אותם בצורה בטוחה.
- הישארו מעודכנים ופנו לייעוץ משפטי במקרי קצה. החוקים ופסקי הדין משתנים במהירות—במיוחד חוק ה-AI של האיחוד האירופי וחוקי הפרטיות של מדינות בארה״ב. כשיש ספק, שאלו מומחה.
שימוש חוקי בכלי גריפת אתרים: מה עסקים צריכים לדעת
כלי גריפת אתרים כמו הופכים את איסוף הנתונים לנגיש גם למי שלא כותב קוד, אבל עדיין צריך להשתמש בהם באחריות:
- בחרו בכלים שממוקדים בציות. Thunderbit, למשל, גורף רק מה שאפשר לראות בדפדפן שלכם—בלי תחבולות API או גישה לא מורשית ().
- היצמדו לשימושים לגיטימיים. אנליטיקה פנימית, מחקר שוק וניטור מחירים של מתחרים הם בדרך כלל בטוחים. פרסום מחדש או מכירה של נתונים שנגרפו? הרבה יותר מסוכן.
- הגדירו את הכלים לעמידה בדרישות. קבעו עיכובי זחילה, כבדו robots.txt, והשתמשו בתבניות שאוספות רק את מה שצריך.
- שמרו את זה בתוך הארגון. שימוש פנימי בנתונים שנגרפו בטוח יותר מאשר פרסום שלהם מחדש.
- חנכו את הצוות. ודאו שכולם מבינים את הכללים ואת שיטות העבודה המומלצות.
- נצלו תכונות ציות מובנות. Thunderbit מזהיר מפני אתרים מסוכנים, גורף בקצב דמוי-אנושי, ולא מאחסן את הנתונים שלכם בשרתים שלו.
- אל תכפו את זה. אם כלי לא מצליח לגרוף אתר, אל תנסו לעקוף אותו בהאקינג. לא כל נתון אפשר להשיג בלי סיכון.
הגישה של Thunderbit: לאפשר גריפת AI Web Scraper תואמת חוק
ב- השקענו הרבה מחשבה בציות. כך ה-AI Web Scraper שלנו עוזר למשתמשים להישאר בצד הנכון של החוק:
- גורף רק מה שרואים. Thunderbit פועל בתוך סשן הדפדפן שלכם, ולכן הוא לא יכול לגשת לנתונים שלא הייתם יכולים להעתיק ידנית.
- מנחה משתמשים עם אזהרות. אם תנסו לגרוף אתר עם מדיניות אנטי-גריפה מחמירה, Thunderbit יתריע.
- מהירויות גריפה דמויות-אנוש. בין אם אתם גורפים מקומית או בענן, Thunderbit נמנע מהעמסת יתר על שרתים.
- בחירת נתונים מותאמת אישית. ה-AI שלנו מציע עמודות רלוונטיות, ועוזר לכם לאסוף רק את מה שצריך.
- טיפול בתתי-דפים ובעימוד. Thunderbit מנווט באתר כמו משתמש אמיתי, תוך כבוד למבנה שלו.
- פרטיות ואבטחה. הנתונים שלכם נשארים אצלכם—Thunderbit לא מאחסן אותם ולא עושה בהם שימוש חוזר.
- ייצוא ידידותי לציות. ייצוא ישיר ל-Google Sheets, Airtable, Notion או CSV לשימוש פנימי ובטוח.
- תזמון ואוטומציה. הגדירו גריפות חוזרות במרווחים אחראיים.
- תמיכה רב-לשונית. ממשק Thunderbit תומך ב-34 שפות, כך שהציות נגיש לכל העולם.
- עדכוני תבניות שוטפים. התבניות המיידיות שלנו לאתרים פופולריים נשמרות מעודכנות לפי שינויים משפטיים וטכניים.
על ידי הטמעת ציות בתוך המוצר, Thunderbit עוזר לצוותים לאסוף את הנתונים שהם צריכים—בלי כאבי ראש משפטיים.
להישאר צעד אחד קדימה: התאמה לשינויים משפטיים וטכניים בגריפת אתרים
גריפת אתרים היא לא משחק של "הגדר ושכח". חוקים ומבני אתרים משתנים כל הזמן. הנה איך להישאר מקדימה:
- עקבו אחרי התפתחויות משפטיות. קצב השינוי האיץ ב-2024–2026—עקבו אחרי חדשות של דיני טכנולוגיה, עדכוני רגולטורים ובלוגים מקצועיים (כמו ). שימו לב לאכיפת חוק ה-AI של האיחוד האירופי (אוגוסט 2026), לחוקי פרטיות חדשים במדינות בארה״ב ולתיקי זכויות יוצרים מתמשכים ב-AI.
- הסתגלו לשינויים טכניים. אתרים מעדכנים כל הזמן את המבנה שלהם ואת ההגנות נגד בוטים. פלטפורמות גדולות (Amazon, X, Google) הקשיחו משמעותית את ההגנות שלהן ב-2025–2026. ה-AI והטמפלטים של Thunderbit נועדו להסתגל אוטומטית.
- אמצו APIs רשמיים כשיש כאלה. אם אתר עובר למודל API בתשלום, שקלו לעבור אליו מטעמי אמינות וציות.
- בצעו ביקורת לגריפה באופן קבוע. תעדו את המקורות שלכם, בדקו שינויי ToS או מדיניות, והתאימו את האסטרטגיה לפי הצורך.
- נצלו את עדכוני התבניות של Thunderbit. הצוות שלנו שומר על התבניות מעודכנות, כך שלא תצטרכו לדאוג משינויים שוברים או מדרישות ציות חדשות.
- הישארו גמישים. אם מקור נתונים נהיה מסוכן מדי, עברו למקור אחר או חפשו שותפות.
עם הכלים והגישה הנכונים, אפשר לשמור על צינור הנתונים שלכם זורם—בלי לדרוך על מוקשים משפטיים.
סיכום: ניווט בנוף המשפטי של גריפת אתרים
גריפת אתרים אינה בלתי חוקית מטבעה—זהו כלי חזק לעסקים, למחקר ולחדשנות. אבל כמו כל כלי, גם לו יש כללים. המפתח הוא להבין מה אתם גורפים, איך אתם גורפים, ומה תעשו עם הנתונים. כבדו את החוקים המקומיים, שמרו על מדיניות האתרים, והשתמשו בכלים שממוקדים בציות כמו כדי לשמור על פעילות תקינה.
פסקי הדין של 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) חיזקו את המקרה לטובת גריפת נתונים ציבוריים, אבל סיכונים חדשים צצים סביב נתוני אימון ל-AI, טענות זכויות יוצרים וחוק ה-AI של האיחוד האירופי. המדיניות של הפלטפורמות משתנה מאוד—Google, Amazon, LinkedIn, Meta ו-X כל אחת אוכפת כללים אחרת—אז חשוב להכיר את המפה לפני שמתחילים לגרוף.
אם יש לכם ספק, פנו לייעוץ משפטי—במיוחד בפרויקטים גדולים או רגישים. ותזכרו: הנוף המשפטי תמיד משתנה, אז הישארו מעודכנים וגמישים.
רוצים ללמוד עוד על גריפת אתרים, ציות ואוטומציה? כנסו ל- למדריכים נוספים, או נסו בעצמכם את .
שאלות נפוצות
1. האם גריפת אתרים היא בלתי חוקית בכל מקום?
לא. גריפת אתרים אינה בלתי חוקית מטבעה, אבל החוקיות שלה תלויה במה שאתם גורפים, איך אתם גורפים, ואיפה אתם נמצאים. גריפת נתונים ציבוריים שאינם אישיים לשימוש פנימי מותרת בדרך כלל ברוב האזורים, אבל גריפת נתונים אישיים או מוגנים בזכויות יוצרים, או הפרת תנאי האתר, עלולות להיות בלתי חוקיות ().
2. האם robots.txt הופך גריפה לבלתי חוקית אם מתעלמים ממנו?
robots.txt אינו מחייב משפטית, אבל זו פרקטיקה טובה לכבד אותו. התעלמות מ-robots.txt לא תוביל בפני עצמה לתביעה, אבל היא עלולה לגרום לכם להיראות כמו "גורם בעייתי" אם תתעורר מחלוקת ().
3. האם אפשר לגרוף את Google, Amazon או LinkedIn?
זה מורכב. שלושתם אוסרים גריפה ב-ToS שלהם, אבל בתי המשפט קבעו שToS עשויים שלא לחול על משתמשים שאינם מחוברים (ראו Meta v. Bright Data ו-X Corp v. Bright Data, שתיהן מ-2024). גריפת נתונים ציבוריים גלויים (מחירי מוצרים, רשימות עסקים, פרופילים ציבוריים) היא בדרך כלל בת הגנה משפטית בארה״ב. עם זאת, כל פלטפורמה אוכפת אחרת: Amazon אגרסיבית במיוחד מבחינה משפטית (היא תבעה את Perplexity AI בנובמבר 2025); LinkedIn מסתמכת על מחסומים טכניים וטענות חוזיות; Google משתמשת יותר ויותר באכיפה מבוססת DMCA. תמיד גרפו באחריות וצפו לאמצעי נגד טכניים.
4. האם אפשר לגרוף את Facebook או Instagram?
אחרי Meta v. Bright Data (2024), גריפת נתונים ציבוריים מ-Facebook ומ-Instagram ללא התחברות נמצאת על קרקע משפטית חזקה יותר. בית המשפט קבע שתנאי השימוש של Meta אינם חלים על מי שאינם משתמשים מחוברים. אבל אל תיצרו חשבונות פיקטיביים ואל תגרפו נתונים מאחורי חומות התחברות—זה כבר חוצה את הקו.
5. האם אפשר לגרוף את X (Twitter)?
X עדכנה את ה-ToS שלה ב-2023 כדי לאסור כל גריפה ללא הסכמה בכתב, והיא פרסה הגנות טכניות אגרסיביות (Cloudflare Turnstile, מגבלת 300 בקשות/שעה, דירוג מוניטין IP). עם זאת, Bright Data ניצחה בבית המשפט על בסיס דומה—נתונים ציבוריים שנגרפו בלי חשבון אינם כפופים ל-ToS של X. מבחינה טכנית, X היא אחת הפלטפורמות הקשות ביותר לגריפה ב-2026.
6. האם גריפת נתונים לצורך אימון מודלי AI היא חוקית?
זו שאלת הפתוחה הגדולה ביותר ב-2026. תביעות גדולות (NYT נגד OpenAI, ההסדר של Anthropic בסך 1.5 מיליארד דולר) מעידות על סיכון משפטי משמעותי. חוק ה-AI של האיחוד האירופי דורש לחשוף מקורות נתוני אימון ולכבד opt-out של זכויות יוצרים. ה-AI Accountability for Publishers Act המוצע ידרוש אישור ותשלום. אם אתם גורפים כדי לאמן AI, קבלו ייעוץ משפטי לפני שממשיכים.
7. מה הדרך הבטוחה ביותר להשתמש בכלי גריפת אתרים כמו Thunderbit?
היצמדו לגריפת נתונים ציבוריים, כבדו את תנאי האתר, הימנעו ממידע אישי אלא אם יש לכם בסיס חוקי, והשתמשו בנתונים פנימית. Thunderbit נועד לעזור לכם להישאר תואמי חוק בכך שהוא גורף רק מה שנראה בדפדפן שלכם ומתריע על אתרים מסוכנים ().
8. האם אפשר לגרוף נתונים לשימוש מסחרי?
זה תלוי. שימוש בנתונים שנגרפו לניתוח פנימי או למחקר הוא בדרך כלל בטוח יותר. פרסום מחדש או מכירה של נתונים שנגרפו, במיוחד אם הם מוגנים בזכויות יוצרים או כוללים מידע אישי, מסוכן הרבה יותר ועשוי לדרוש אישור או רישיון.
9. איך נשארים מעודכנים בשינויים משפטיים וטכניים בגריפת אתרים?
עקבו אחרי חדשות של דיני טכנולוגיה, עקבו אחרי שינויי ToS או מדיניות באתרי היעד שלכם, והשתמשו בכלים כמו Thunderbit שמעדכנים את התבניות ואת תכונות הציות שלהם באופן קבוע. דברים מרכזיים לעקוב אחריהם ב-2026: אכיפת חוק ה-AI של האיחוד האירופי (אוגוסט), תביעות זכויות יוצרים מתמשכות ב-AI, וחוקי פרטיות חדשים במדינות בארה״ב. כשיש ספק, התייעצו עם איש מקצוע משפטי.