גריפת Facebook עדיין שווה את המאמץ ב-2026, אבל רק אם בוחרים את מודל האיסוף הנכון. Pew Research Center דיווח ב-20 בנובמבר 2025 כי , ו-Meta מסרה ב-29 באפריל 2026 ש- במרץ 2026. ההיקף הזה שומר על Facebook רלוונטי לניטור Marketplace, מחקר על עמודים ציבוריים, יצירת לידים ומעקב אחרי מתחרים. החלק הקשה הוא לא למצוא מקרי שימוש. החלק הקשה הוא להוציא נתונים נקיים בלי להיתקע על חומות התחברות, טעינות דינמיות, חסימות זמניות או הגדרות גריפה שבירות.
הרשימה השנתית הזו בנויה למהירות החלטה. בדקתי שוב את דפי המוצר הרשמיים, התיעוד ואותות התמחור ב-8 במאי 2026, ואז שמרתי את הרשימה ממוקדת בכלים שעדיין הגיוניים למשתמשים עסקיים אמיתיים. אם הזרימה שלך היא בעיקר “לתפוס את הנתונים בדף הזה ולשלוח אותם לגיליון”, התחילו עם Thunderbit. אם אתם צריכים תשתית בקנה מידה של API, Bright Data, Apify ו-Nimble by Nimbleway צריכים להיות בראש הרשימה. אם העבודה שלכם כוללת אוטומציות בענן או פעולות המשך אחרי האיסוף, PhantomBuster בהחלט ראוי למבט קרוב יותר.
בחירות מהירות לפי משימה
- צריכים את הייצוא הכי מהיר ללא קוד מ-Facebook או Marketplace? התחילו עם .
- צריכים קנה מידה ארגוני ל-API וניהול עקיפה של חסימות? הכניסו לרשימה קצרה את .
- צריכים זרימות גריפה גמישות בענן? הסתכלו מקרוב על .
- צריכים איסוף רשת ציבורית בגישת API-first עם פחות תחזוקת scraper? שקלו את .
- צריכים API ידידותי לתקציב למשימות קלות יותר? עדיין רלוונטי.
- צריכים גם גריפה וגם אוטומציה של תהליכי עבודה? הוא ההתאמה הטובה יותר.
- צריכים בונה זרימות בקליק עם תזמון? נשארת אפשרות חזקה ללא קוד.
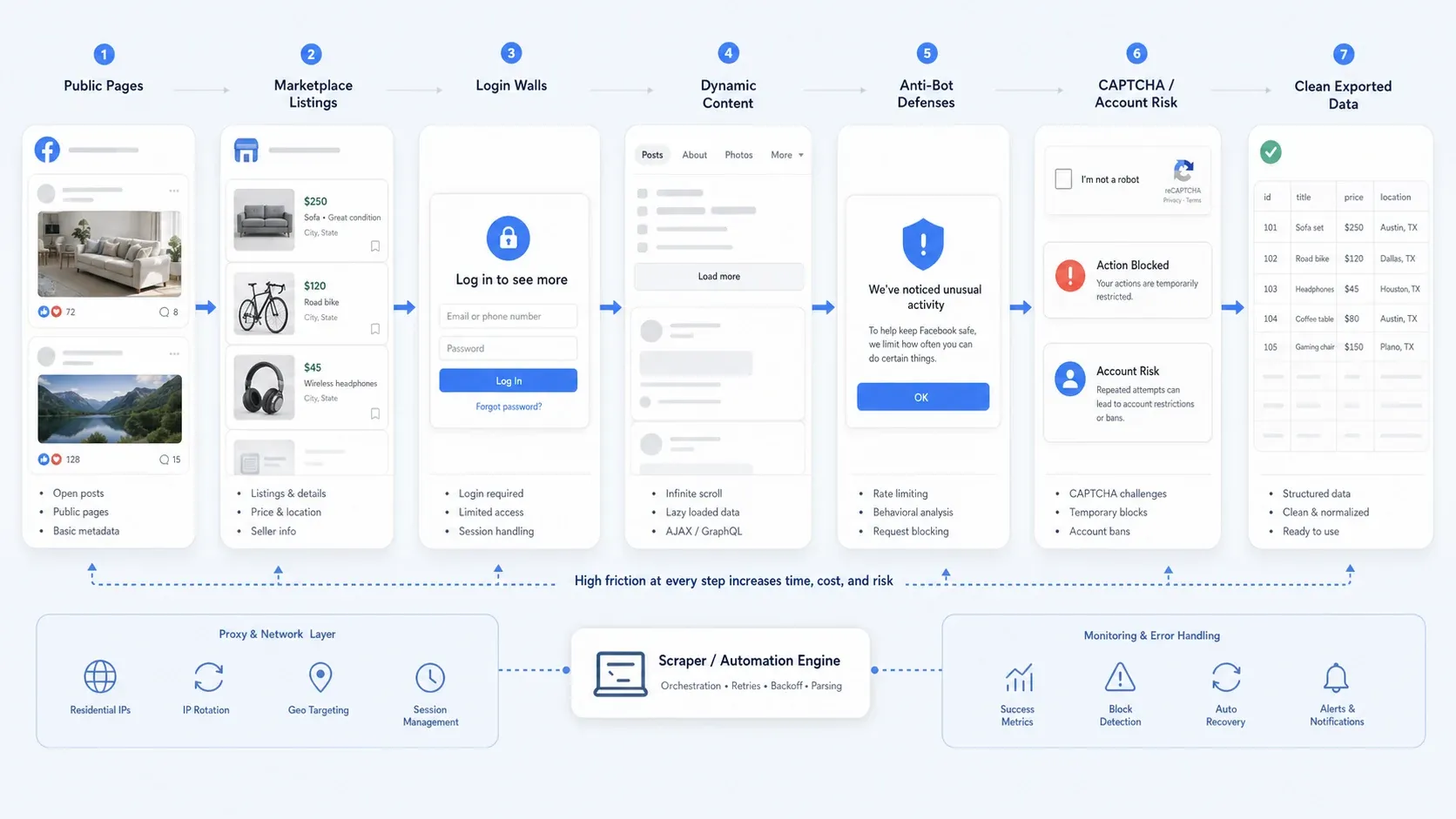
למה גריפת Facebook עדיין קשה ב-2026
איסוף נתונים מ-Facebook הוא כבר כמעט אף פעם לא רק בעיית סלקטורים. בפועל, רוב הצוותים נתקלים באחת או יותר מהבעיות הבאות:
- גישה ציבורית חלקית: חלק מהעמודים נשארים פתוחים, בעוד שזרימות אחרות דוחפות להתחברות כדי לראות יותר פרטים.
- תוכן דינמי: תצוגות Marketplace, שרשורי תגובות ארוכים ותוכן עמודים נטענים לעיתים בהדרגה.
- הגנות נגד בוטים: הגבלת קצב, בדיקות התנהגותיות, CAPTCHA וחסימות פעולה זמניות שוברים אוטומציות נאיביות.
- סיכון תפעולי: איסוף שמבוסס על התחברות הוא מסוכן הרבה יותר מגריפת עמודים ציבוריים, במיוחד אם חשוב לכם בטיחות החשבון ואפשרות שחזור.
איך הערכתי את הכלים האלה
אופטימיזציה של הדף הזה נועדה לבניית רשימה קצרה, לא לניפוח תכונות. הכלים כאן הושוו לפי:
- התאמה לזרימה: האם המוצר באמת מתאים למשימות איסוף מ-Facebook ומ-Marketplace שצוותים אמיתיים מבצעים?
- קלות שימוש: האם משתמשים ללא פיתוח או צוותים רזים יכולים להגיע לפלט שימושי במהירות?
- קנה מידה ואמינות: האם הכלי עדיין הגיוני אחרי שעוברים מגריפה חד-פעמית?
- ניהול anti-bot וסשנים: כמה כאב תשתיתי המוצר מסיר?
- איכות הפלט: האם אפשר לקבל נתונים מובנים ל-CSV, Sheets או מערכות המשך בלי ניקוי משמעותי?
- אות תמחור: האם המוצר מעשי להערכה, או שהוא דורש תהליך מכירה ארגוני כבד?
- עמדת compliance: האם הכלי ממוקד בבירור באיסוף נתונים ציבוריים ובשימוש אחראי?
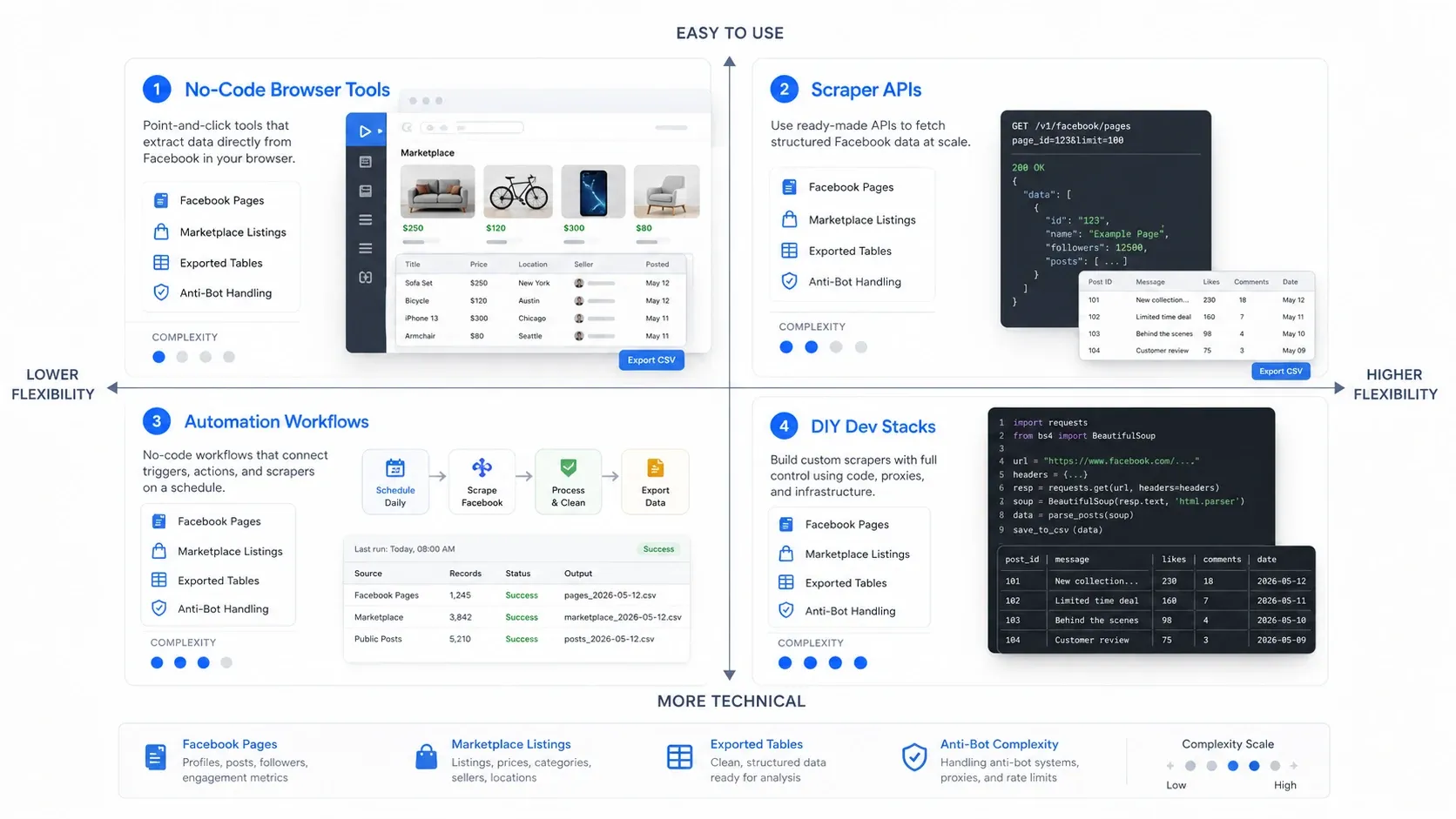
איזה סוג של Facebook Scraper אתם צריכים?
הדרך המהירה ביותר לבחור נכון היא לבחור קודם את הקטגוריה הנכונה. כלים לגריפת Facebook נופלים בדרך כלל לארבעה מודלי פעולה:
- כלי דפדפן ללא קוד: הכי טוב כשצריך חילוץ מהיר מהדף שכבר פתוח מולכם.
- Scraper APIs: הכי טוב כשצריך איסוף אמין וחוזר בנפח גבוה יותר.
- זרימות אוטומציה: הכי טוב כשגריפה היא רק שלב אחד בתוך תהליך go-to-market רחב יותר.
- מחסניות פיתוח DIY: הכי טוב כשיש לצוות שלכם שליטה מקסימלית והוא מוכן לשאת בנטל התחזוקה.
טבלת השוואה
| כלי | מתאים במיוחד ל | למה נכנס לרשימה הקצרה | אות תמחור |
|---|---|---|---|
| Thunderbit | צוותים ללא רקע טכני ומשימות מהירות אד-הוק | זיהוי שדות באמצעות AI, טיפול מובנה בדפים דינמיים בדפדפן, ייצוא מהיר | ניסיון חינם; תוכניות בתשלום מבוססות קרדיטים |
| Bright Data | צינורות נתונים גדולים של רשתות חברתיות ציבוריות | APIs ייעודיים לגריפת מדיה חברתית, ניהול עקיפה של חסימות, קנה מידה חזק | תמחור לפי שימוש ולתאגידים |
| Apify | זרימות גריפה גמישות בענן | Facebook actors מוכנים מראש, תזמון, גישת API, מרחב להתאמה אישית | תוכניות בתשלום לפלטפורמה ושימוש לפי מדידה |
| Nimble by Nimbleway | איסוף רשת ציבורית בגישת API-first | זרימת API מבוססת URL ונטל תחזוקת scraper נמוך יותר | תמחור בהובלת מכירות |
| ScrapingBot | משימות נתונים ציבוריים קטנות ואבות-טיפוס | API פשוט, תמיכה ברינדור, מחיר כניסה נמוך יותר | שכבה חינמית; תוכניות בתשלום החל מכ-22 דולר לחודש |
| PhantomBuster | זרימות אוטומציה ל-GTM | אוטומציות בענן, זרימות מבוססות פעולות בדפדפן, התאמה ליצירת לידים | ניסיון חינם; תוכניות בתשלום החל מכ-56 דולר לחודש |
| Octoparse | גריפה ויזואלית ללא קוד עם תזמון | בונה בקליק, חילוץ בענן, זרימות חוזרות | תוכנית חינמית; תוכניות בתשלום החל מכ-119 דולר לחודש |
1. Thunderbit
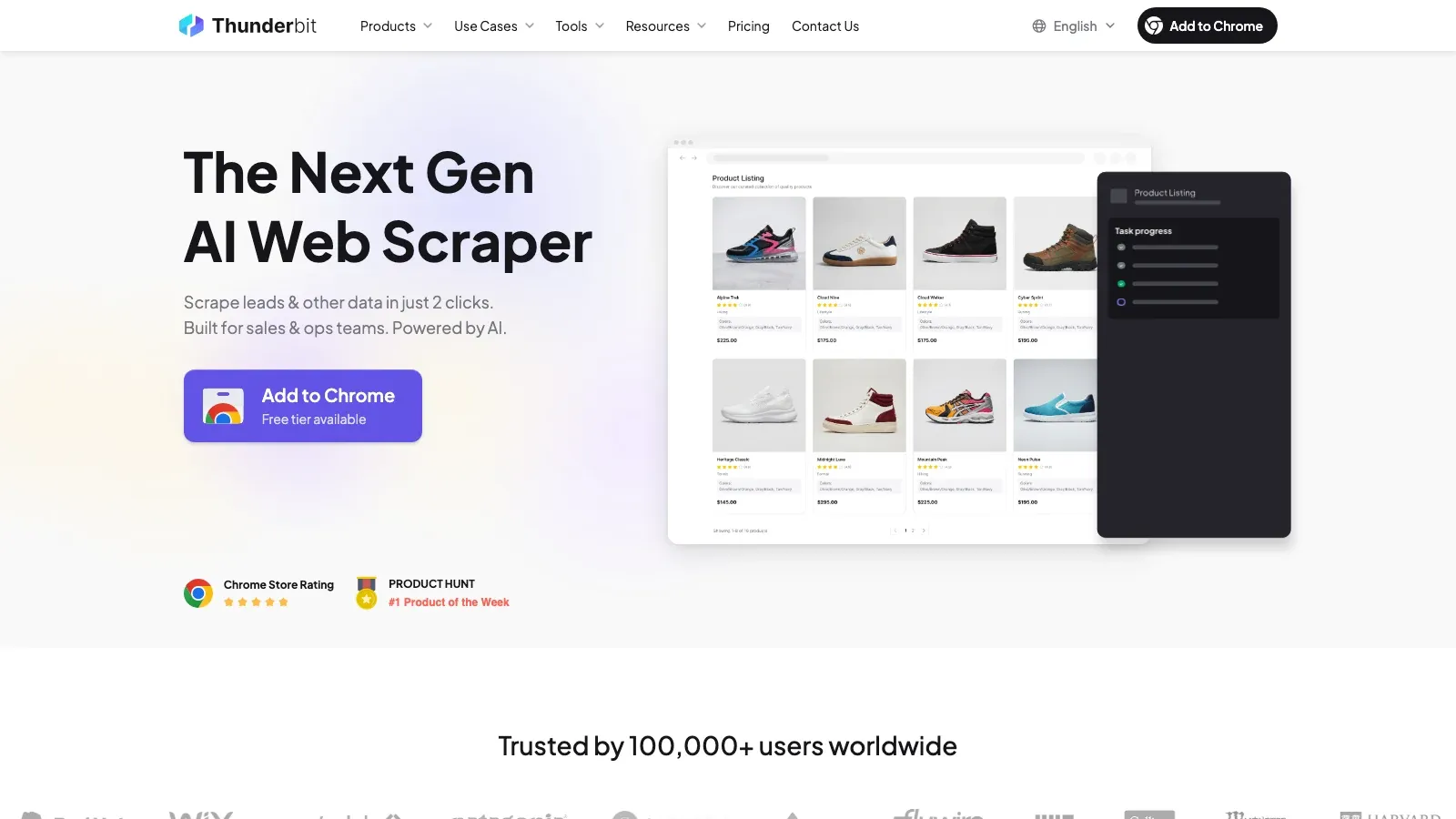
הוא הבחירה החזקה ביותר כאן אם המטרה שלכם היא להפוך עמוד Facebook או רשימת תוצאות ב-Marketplace לנתונים מובנים במהירות, בלי לבנות או לתחזק scraper. היתרון המרכזי שלו הוא חילוץ סמנטי: הוא קורא את הדף, מציע שדות שימושיים, ומאפשר לייצא את התוצאה בלי להתעסק בסלקטורים, פרוקסי או קוד.
למה הוא בולט:
- AI Suggest Fields: Thunderbit מזהה שדות סבירים כמו כותרת, מחיר, מוכר, מיקום, פרטי קשר וכתובות URL.
- טיפול מובנה בדפדפן: מכיוון שהוא רץ במקום שבו הדף מוצג, הוא עובד טוב על דפים דינמיים וכבדי גלילה.
- העשרת תתי-עמודים: אפשר לאסוף תחילה נתוני רשימה, ואז לפתוח כל רישום או עמוד כדי לקבל פרטים עשירים יותר.
- ייצוא שימושי: Excel, Google Sheets, Airtable ו-Notion הם כולם יעדי יצוא טבעיים.
אם אתם רוצים סרטון אחד לפני שתנסו בעצמכם זרימת עבודה מבוססת דפדפן, ההדרכה המעשית הזו של Thunderbit היא המקום הכי שימושי להתחיל ממנו, כי היא מראה את תהליך החילוץ בפועל במקום להישאר ברמת ההבטחות על תכונות:
מתאים במיוחד ל: משתמשים ללא רקע טכני, צוותי מכירות, מפעילים וחוקרים שרוצים תוצאות מהר.
אות תמחור: יש ניסיון חינם; התוכניות בתשלום מבוססות קרדיטים. בדקו את .
2. Bright Data
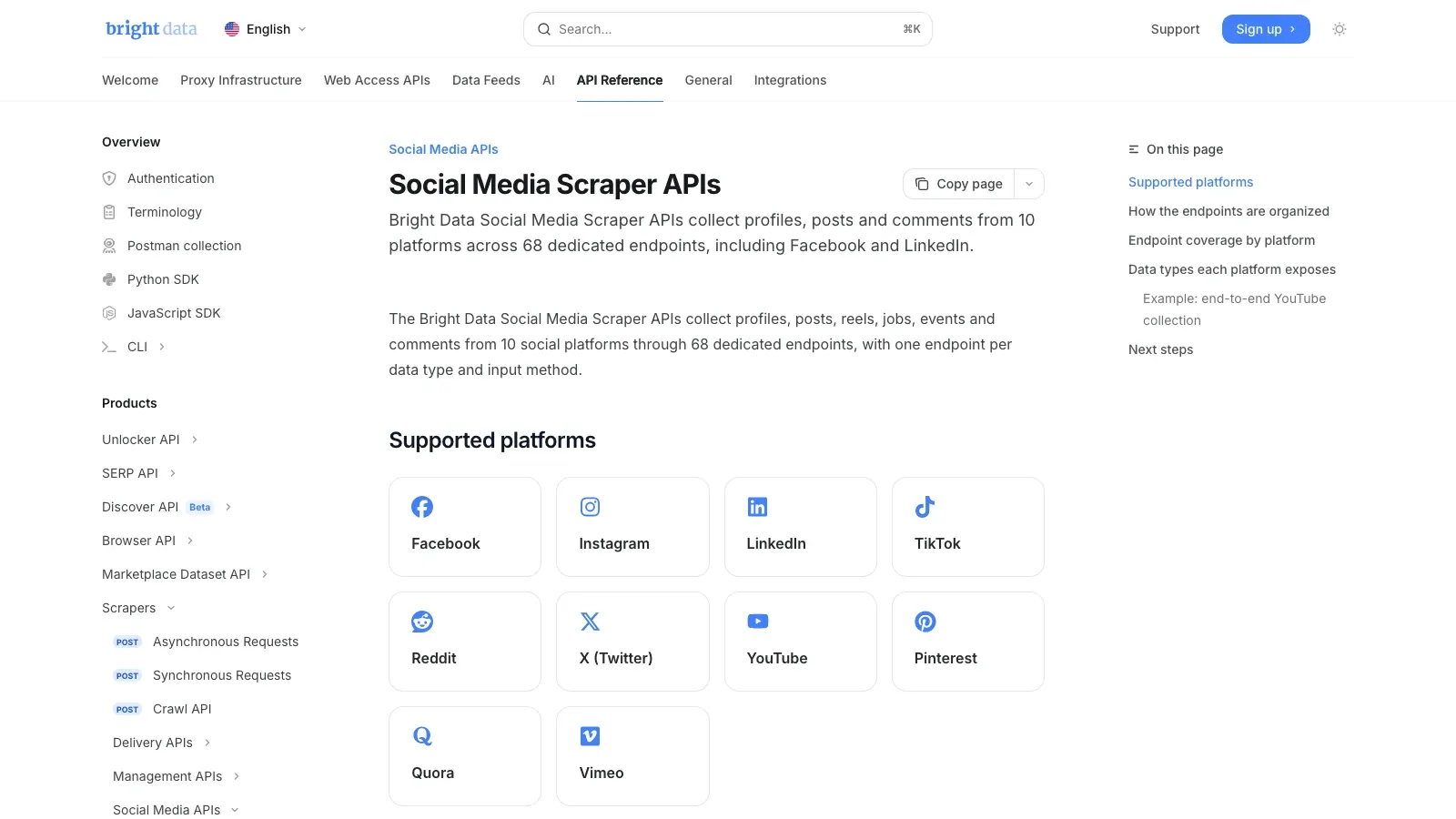
הוא הבחירה של תשתית-ראשונה. בתיעוד של Bright Data עצמו נאמר כי שלו מכסים 10 פלטפורמות ו-68 נקודות קצה ייעודיות, כולל Facebook. אם העבודה שלכם היא איסוף נתונים ציבוריים בקנה מידה גדול, סט כזה של APIs מנוהלים הוא בדרך כלל ריאלי יותר מאשר לנסות להרחיב תוסף דפדפן או scraper שנבנה ידנית.
למה הוא ראוי להיות ברשימה הקצרה:
- נקודות קצה ייעודיות לגריפת רשתות חברתיות
- ניהול עקיפה של חסימות וחילוץ
- אספקת פלט מובנה לצינורות נתונים
- התאמה טובה יותר למשימות ניטור ואנליטיקה רגישות לאמינות
מתאים במיוחד ל: אנליסטים, צוותי נתונים, פרויקטי ניטור גדולים ומאגרי נתונים ציבוריים של רשתות חברתיות בקנה מידה גדול.
אות תמחור: התמחור משתנה לפי מוצר ונפח. בדקו מול .
3. Apify
נשאר רלוונטי כי הוא מספק איזון טוב בין תבניות להתאמה אישית מלאה. ה-actor של Facebook Pages Scraper הוא נקודת התחלה שימושית, בעוד שהפלטפורמה הרחבה יותר של Apify מספקת ריצות בענן, תזמון, APIs ומקום להרחיב את הזרימה אם הצרכים שלכם נעשים מורכבים יותר.
למה הוא נכנס לרשימה:
- Facebook actors מוכנים מראש
- הרצה בענן ולוחות זמנים חוזרים
- ייצוא גמיש וגישה ל-API
- קל יותר להרחבה מאשר זרימת דפדפן ללא קוד בלבד
מתאים במיוחד ל: מרקטינג טכנולוגי, סוכנויות, צוותי תפעול ומשימות איסוף חוזרות על פני כמה אתרים.
אות תמחור: תוכניות הפלטפורמה בתשלום, ושימוש ב-actor מחויב בנפרד לפי מדידה. בדקו את .
4. Nimble by Nimbleway
הוא האפשרות בגישת API-first לצוותים שרוצים לשלוח URL ולתת לפלטפורמה לטפל בגישה, ברינדור ובאספקה. Nimble ממקמת את שלה כאיסוף נתוני אינטרנט ציבוריים מקצה לקצה, מה שהופך אותו לשימושי כשגריפת Facebook היא רק חלק אחד ממחסנית נתונים רחבה יותר.
למה כדאי להעריך אותו:
- זרימת API מבוססת URL
- פחות נטל תחזוקת scraper לצוותי הנדסה
- התאמה טובה לחילוץ עמיד מרשת ציבורית
- שימושי כשהנתונים שנגרפו מזינים מוצרים פנימיים או דשבורדים
מתאים במיוחד ל: צוותים בהובלת הנדסה, צינורות נתוני מוצר וארגונים שרוצים שכבת הפשטת תשתית במקום כלים נקודתיים.
אות תמחור: Nimble לא מדגישה תמחור ציבורי בשירות עצמי בדפי ה-API המרכזיים שלה, לכן צפו לתמחור בהובלת מכירות ואשרו ישירות מול .
5. ScrapingBot
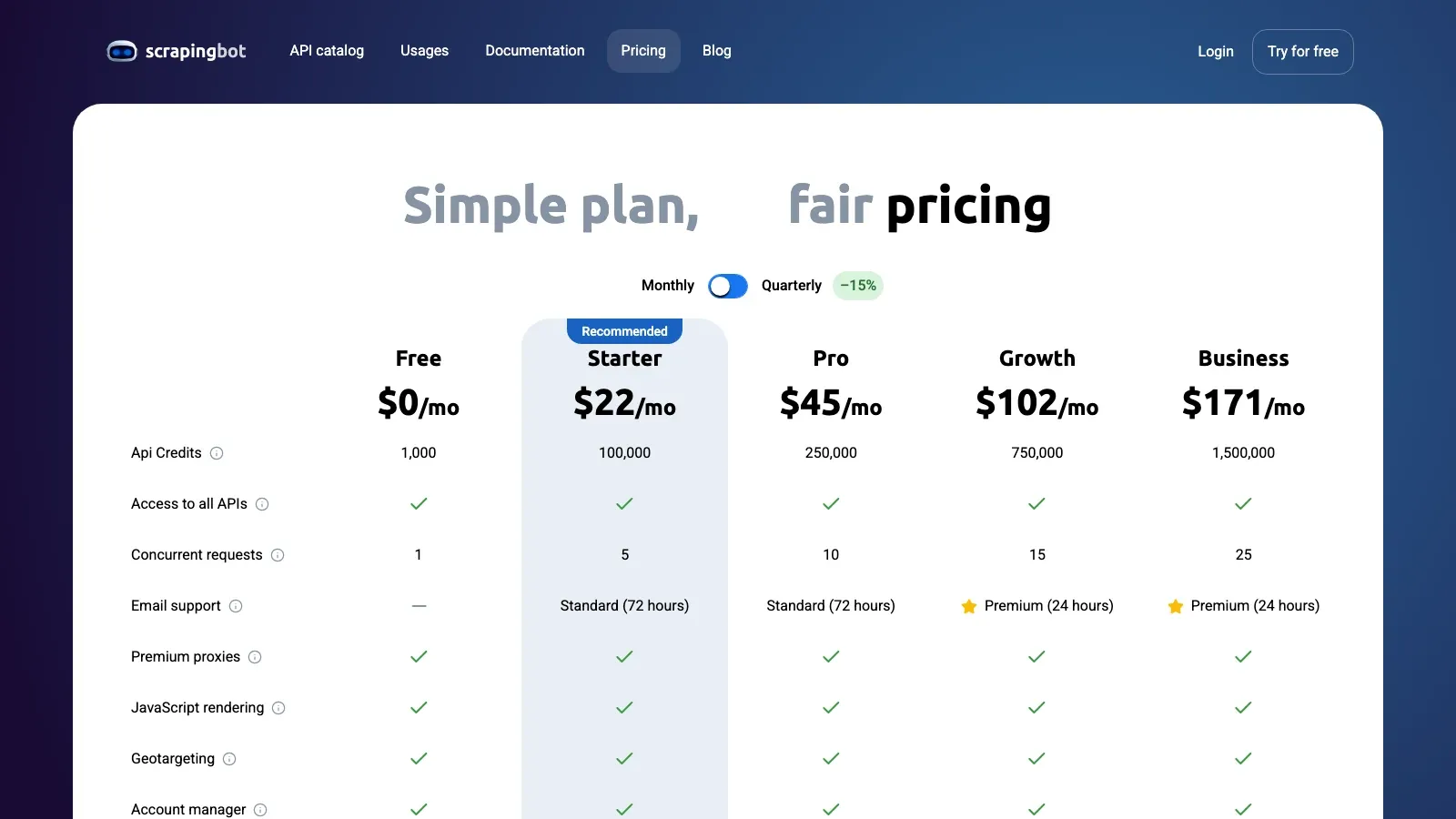
הוא אפשרות ה-API החסכונית ברשימה הזו. הוא לא הפלטפורמה הכי עמוקה או הכי ממוקדת Facebook כאן, אבל הוא עדיין הגיוני למשימות קטנות של נתונים ציבוריים כשצריך API, תמיכה ברינדור ורף עלות נמוך יותר מאשר תשתית גריפה ארגונית.
איפה הוא מתאים:
- גריפה ציבורית פשוטה מבוססת API
- מחיר כניסה נמוך יותר
- כולל רינדור וניהול פרוקסי
- טוב יותר לאבות-טיפוס ולמשיכות חוזרות קלות מאשר לתוכניות מודיעין גדולות
מתאים במיוחד ל: סטארטאפים, עסקים קטנים ומפתחים שבודקים מקרי שימוש קלים יותר לאיסוף מעמודים ציבוריים.
אות תמחור: יש שכבה חינמית; דף התמחור הציבורי הנוכחי מתחיל תוכניות בתשלום מכ-.
6. PhantomBuster
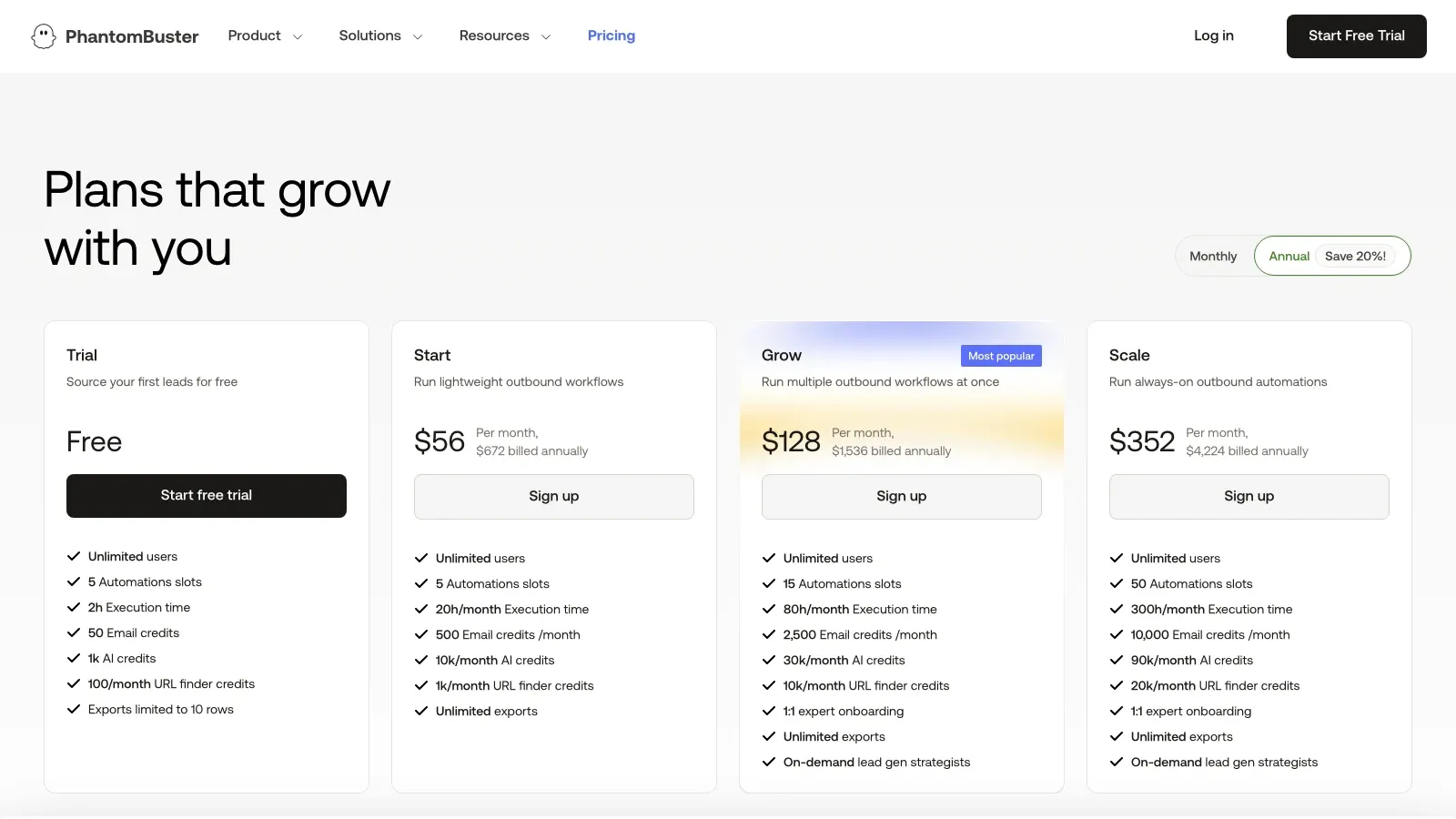
עוסק פחות בתשתית גריפה גולמית ויותר במה שקורה אחרי האיסוף. אם מקרה השימוש שלכם הוא “לאסוף את הנתונים, ואז להפעיל פנייה, העשרה או פעולות המשך”, PhantomBuster לרוב שימושי יותר מאשר מחלץ פשוט, כי הוא בנוי סביב אוטומציות בענן וזרימות פעולה בדפדפן.
למה צוותים עדיין מכניסים אותו לרשימה הקצרה:
- זרימות אוטומציה מבוססות ענן
- שימושי ליצירת לידים ולפעולות GTM
- התאמה טובה יותר כשגריפה היא שלב אחד בתוך תהליך רחב יותר
- פרקטי למפעילים שחשוב להם לבצע פעולות, לא רק ייצוא
מתאים במיוחד ל: צוותי GTM, צוותי Growth, מגייסים ומפעילים שמחברים איסוף לפעולה בהמשך.
אות תמחור: יש ניסיון חינם; התוכניות בתשלום בדף התמחור הנוכחי מתחילות מכ-.
7. Octoparse
נשארת אחת מכלי הגריפה הוויזואליים הטובים יותר ללא קוד עבור משתמשים שרוצים זרימות חוזרות וריצות מתוזמנות בענן. היא לא קלה כמו Thunderbit למשימות Facebook חד-פעמיות ומהירות, אבל היא נותנת למשתמשים ללא פיתוח יותר שליטה מפורשת על איך לוגיקת החילוץ נבנית ונחזרת על עצמה.
למה היא עדיין רלוונטית:
- בונה זרימות ויזואלי של point-and-click
- חילוץ בענן ותזמון
- טוב למשימות מובנות שחוזרות על עצמן
- מתאים יותר לאנליסטים שרוצים שחזוריות בלי קוד
מתאים במיוחד ל: אנליסטים ללא רקע טכני, צוותי תפעול ב-SMB ומשימות איסוף חוזרות עם לוגיקת זרימה מפורשת יותר.
אות תמחור: דף התמחור הציבורי של Octoparse מציג תוכניות בתשלום שמתחילות מכ-.
רשימה קצרה לפי צוות
אם כבר ברור לכם איזה סוג צוות יישא בזרימה, התחילו כאן:
- מפעיל יחיד או עסק קטן: Thunderbit, ScrapingBot או Octoparse
- צוות מכירות / GTM: Thunderbit או PhantomBuster
- אנליסט תפעול: Thunderbit, Apify או Octoparse
- צוות אוטומציה ל-Growth: PhantomBuster או Apify
- צוות הנדסת נתונים: Bright Data, Nimble או Apify

איך לבחור את ה-Facebook scraper הנכון
- בחרו ב-Thunderbit אם מהירות ופשטות חשובות יותר מקנה מידה מקסימלי.
- בחרו ב-Bright Data אם אתם צריכים קנה מידה לנתונים ציבוריים ואמינות מנוהלת.
- בחרו ב-Apify אם אתם רוצים גמישות פלטפורמה וזרימות מבוססות actors.
- בחרו ב-Nimble אם אתם רוצים שכבת הפשטה בגישת API-first עם פחות תחזוקת scraper.
- בחרו ב-PhantomBuster אם גריפה היא רק שלב אחד בזרימת אוטומציה רחבה יותר ל-GTM.
- בחרו ב-Octoparse אם אתם רוצים שחזוריות ויזואלית בלי קוד.
- בחרו ב-ScrapingBot אם התקציב חשוב והמשימה פשוטה יחסית.
מסקנה סופית
שוק הכלים ברור יותר ב-2026 משהיה לפני שנה. אתם לא באמת בוחרים “Facebook scraper” אוניברסלי אחד וטוב מכולם. אתם בוחרים מודל איסוף: חילוץ מהיר ללא קוד, קנה מידה מנוהל ב-API, אוטומציה בענן, או שליטה מעשית בזרימת עבודה ויזואלית. תתחילו משם והרשימה הקצרה נעשית הרבה יותר קלה.
אם הצוות שלכם רוצה את הדרך המהירה ביותר מעמוד Facebook או מרישום Marketplace לנתונים מובנים ושימושיים, Thunderbit עדיין המקום הכי קל להתחיל ממנו. אם הנפח שלכם או הדרישות ההנדסיות כבדים הרבה יותר, Bright Data, Apify ו-Nimble הגיוניים יותר. אם הזרימה שלכם מתחילה בגריפה אבל מסתיימת בפעולות המשך, PhantomBuster הוא הרשימה הקצרה החכמה יותר.
שאלות נפוצות
1. מהו כלי גריפת Facebook הכי קל למשתמשים ללא רקע טכני?
Thunderbit הוא נקודת ההתחלה הקלה ביותר לרוב המשתמשים ללא רקע טכני, כי הוא עובד בדפדפן, מציע שדות אוטומטית ומייצא נתונים במהירות בלי קוד.
2. איזה כלי גריפת Facebook הכי מתאים לאיסוף נתונים ציבוריים בקנה מידה גדול?
Bright Data הוא הבחירה התשתיתית החזקה ביותר ברשימה הזו כשמדובר באיסוף נתוני רשתות חברתיות ציבוריים בקנה מידה גדול, ואמינות חשובה יותר מקלות שימוש.
3. מה אם אני צריך גם גריפה וגם אוטומציית המשך?
PhantomBuster הוא ההתאמה הטובה יותר כשהאיסוף הוא רק שלב אחד בתוך זרימת לידים או GTM רחבה יותר.
4. האם גריפת Facebook עדיין קשה ב-2026?
כן. תוכן דינמי, חומות התחברות, מגבלות קצב, מערכות נגד בוטים ובעיות סיכון לחשבון עדיין הופכים את Facebook לקשה יותר מגריפת אתרים ציבוריים פשוטים יותר.
5. איך צוותים צריכים לחשוב על compliance?
תישארו ממוקדים בנתונים ציבוריים, השתמשו בקצבים סבירים, הימנעו משימוש לרעה בפרטי גישה, וסקרו את תנאי הפלטפורמה ואת כללי הפרטיות החלים לפני שמגדילים זרימה.
לקריאה נוספת: