אתם נרשמים ל‑ScraperAPI, רואים "100,000 credits" בתוכנית Hobby, ומתחילים לגרד נתונים. שלושה ימים אחר כך, הדשבורד מראה ש‑80% מהקרדיטים כבר נעלמו — ובפועל הצלחתם לגרד אולי 6,000 עמודים. מה קרה? מה שקרה הוא מערכת המכפילים של הקרדיטים, וזה הדבר החשוב ביותר ב‑ScraperAPI שכמעט אף סקירה לא באמת מסבירה. ביליתי שבועות בחפירה בתיעוד של ScraperAPI, שלפתי נתוני תמחור אמיתיים מחמישה ספקים מתחרים, וקראתי כל שרשור ב‑Reddit וכל סקירת Capterra שהצלחתי למצוא. זו סקירת ScraperAPI שהייתי רוצה שתהיה קיימת כשצוות שלנו התחיל לראשונה להעריך APIs לגרידת נתונים. אני אעבור איתכם על החשבון האמיתי של הקרדיטים, אראה איפה ScraperAPI מצטיין (ואיפה הוא נופל חזק), אסכם מה משתמשים אמיתיים אומרים ב‑G2, Capterra ו‑Reddit, ובכנות — אעזור לכם להבין אם בכלל אתם צריכים API לגרידת נתונים.
מהו ScraperAPI ולמי הוא מיועד?
ScraperAPI הוא API לגרידת אתרים שמטפל בכל התשתית המורכבת שמאחורי גרידה בקנה מידה גדול: החלפת פרוקסי דרך , פתרון CAPTCHA אוטומטי, רינדור JavaScript וניסיונות חוזרים אוטומטיים. אתם שולחים אליו URL בקריאת API פשוטה, והוא מחזיר HTML (או JSON מנותח, אם משתמשים בנקודות הקצה של הנתונים המובנים). החברה נוסדה ב‑2018 על ידי Daniel Ni, יושבת בלאס וגאס, ומשרתת כיום כולל Deloitte, Sony ו‑Alibaba — ומעבדת .
הקהל המרכזי הוא צוותי פיתוח ו‑ops טכניים שבונים צינורות גרידה מותאמים אישית. אם אתם לא כותבים קוד, ScraperAPI לא נבנה בשבילכם (עוד נחזור לזה).
מערכת היכולות המרכזית: החלפת פרוקסי, רינדור JavaScript, גאוטרגוטינג, נקודות קצה לנתונים מובנים עבור אתרים פופולריים, וניסיונות חוזרים אוטומטיים לבקשות שנכשלו.
אבל הנה מה שרוב הסקירות מפספסות: מספרי הקרדיטים הבולטים בעמוד התמחור של ScraperAPI הם מאוד מטעים אם לא מבינים איך המכפילים עובדים. אז משם נתחיל.
איך מערכת הקרדיטים של ScraperAPI באמת עובדת (החלק שרוב הסקירות מדלגות עליו)
ScraperAPI מחייבת לפי מערכת קרדיטים. העיקרון הבסיסי פשוט: בקשת API אחת = קרדיט אחד. בפועל, זה כמעט אף פעם לא מה שקורה. העלות האמיתית של הקרדיטים תלויה בשני דברים: הדומיין שאתם מגרדים, וה‑feature flags שאתם מפעילים. והעלויות האלה מצטברות בדרכים שלא תמיד אינטואיטיביות.
טבלת מכפילי הקרדיטים שכל משתמש צריך לראות לפני ההרשמה

עוד לפני שאתם מפעילים פרמטר אחד, סוג האתר שאתם מגרדים קובע את עלות הקרדיט הבסיסית:
| קטגוריית דומיין | קרדיטים בסיסיים לכל בקשה | דוגמאות |
|---|---|---|
| אתרים רגילים | 1 | בלוגים, אתרי חדשות, HTML פשוט |
| מסחר אלקטרוני | 5 | Amazon, eBay, Walmart |
| SERP (מנועי חיפוש) | 25 | Google, Bing |
| רשתות חברתיות | 30 |
בנוסף, דגלי תכונות מוסיפים קרדיטים נוספים:
| פרמטר | קרדיטים נוספים | הערות |
|---|---|---|
render=true (רינדור JS) | +10 | כל התוכניות |
screenshot=true | +10 | כל התוכניות |
premium=true (פרוקסי פרימיום) | +10 | כל התוכניות |
ultra_premium=true | +30 | רק בתוכניות בתשלום |
| עקיפת אנטי‑בוט (Cloudflare, DataDome, PerimeterX) | +10 לכל אחד | מזוהה אוטומטית — אתם לא בוחרים את זה |
premium=true + render=true יחד | +25 | לא +20 |
ultra_premium=true + render=true יחד | +75 | לא +40 |
השורה האחרונה היא הבעיה האמיתית. שילוב תכונות עולה יותר מסכום העלויות של כל אחת בנפרד. פרוקסי פרימיום (+10) יחד עם רינדור JavaScript (+10) אמורים לעלות לוגית +20 קרדיטים נוספים, אבל ScraperAPI גובה . Ultra‑premium (+30) יחד עם רינדור JavaScript (+10) אמורים לעלות +40, אבל בפועל זה — כמעט כפול. ההצטברות הלא‑ליניארית הזו לא מתועדת בצורה בולטת, והיא הסיבה העיקרית לכך שמשתמשים מדווחים שהקרדיטים נעלמים מהר מהצפוי.
פרמטרים שעולים אפס קרדיטים נוספים: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
מה כל תוכנית באמת נותנת: מ‑Free ועד Enterprise
אלו :
| תוכנית | מחיר חודשי | שנתי (לחודש) | קרדיטי API | Threads מקבילים | גאוטרגוטינג |
|---|---|---|---|---|---|
| Free | $0 | — | 1,000 | 5 | לא |
| Hobby | $49 | $44 | 100,000 | 20 | ארה"ב ו‑EU בלבד |
| Startup | $149 | $134 | 1,000,000 | 50 | ארה"ב ו‑EU בלבד |
| Business | $299 | $269 | 3,000,000 | 100 | ברמת מדינה (50+ מדינות) |
| Scaling | $475 | $427 | 5,000,000 | 200 | ברמת מדינה |
| Enterprise | מותאם אישית | מותאם אישית | 5,000,000+ | 200+ | ברמת מדינה |
ועכשיו, הנה העלות האפקטיבית לכל 1,000 בקשות בכל דרגה, אחרי חישוב המכפילים:
| תוכנית | רגיל (1×) | רינדור JS (10×) | E-commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup ($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business ($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling ($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
תוכנית של $49 בחודש שמפורסמת כ‑"100,000 credits" נותנת בפועל רק 1,333 בקשות אמיתיות כשמגרדים אתרים מוגנים עם ultra‑premium יחד עם רינדור JavaScript. זה יוצא — יקר יותר מהרבה שירותי גרידה מנוהלים במלואם.
למה הקרדיטים נעלמים מהר יותר ממה שאתם מצפים
שלושה דברים תופסים משתמשים לא מוכנים.
ראשית: התמחור לפי דומיין הוא אוטומטי. אתם לא בוחרים אם לשלם פי 5 על Amazon או פי 25 על Google. זה מוחל ברגע ש‑ScraperAPI מזהה את הדומיין. אותו דבר לגבי קרדיטי עקיפת אנטי‑בוט (+10 עבור Cloudflare, DataDome, PerimeterX) — הם מתווספים אוטומטית כשהמערכת מזהה אותם.
שנית: הקרדיטים לא עוברים לחודש הבא. קרדיטים שלא נוצלו . אין צבירה.
ושלישית — וזה כואב — Pay‑As‑You‑Go זמין רק בתוכנית Scaling ($475 לחודש) ומעלה. אם אתם ב‑Hobby, Startup או Business ומסיימים את הקרדיטים באמצע המחזור, פשוט ניתקת לכם הגישה עד לתקופת החיוב הבאה. האפשרות היחידה היא לשדרג לתוכנית גבוהה יותר.
משתמש אחד ב‑Reddit דיווח שקיבל הצעת מחיר של $3,600 עבור 60 מיליון קרדיטים לפי 1 קרדיט לבקשת Amazon, אבל אחרי התשלום הופעל מכפיל של 5 קרדיטים בלי גילוי מראש. התוכנית שלו, שהייתה אמורה לכסות 60 מיליון, הייתה בפועל שוות ערך ל‑12 מיליון בקשות בלבד — פער של ממה שציפה.
מלכודת הקרדיטים של DataPipeline
תכונת ה‑DataPipeline ללא קוד של ScraperAPI (גרידה מתוזמנת עם מסירה דרך webhook) משתמשת בלוח קרדיטים נפרד, גבוה משמעותית. בקשה רגילה בסיסית עולה דרך ה‑API הרגיל:
| סוג בקשה | Standard API | DataPipeline | יחס |
|---|---|---|---|
| בקשה רגילה בסיסית | 1 | 6 | פי 6 |
| E-commerce בסיסי | 5 | 10 | פי 2 |
| SERP בסיסי | 25 | 30 | פי 1.2 |
| Ultra-premium + JS (רגיל) | 75 | 80 | פי 1.07 |
משתמשים שמגדירים צינורות ללא קוד ומצפים לעלות קרדיטים רגילה מגלים שהם שורפים פי 6 קרדיטים על בקשות בסיסיות. זה מתועד, אבל צריך לחפש את זה לעומק.
עלות אמיתית לבקשה: ScraperAPI מול המתחרים
תמחור כותרת לא אומר הרבה בלי לקחת בחשבון מכפילים. שלפתי תמחור עדכני מחמישה ספקים, ואיחדתי את ההשוואה סביב רמת המחיר של כ‑$300 בחודש בשלושה תרחישים נפוצים.
גרידת HTML בסיסית (ללא JS, ללא פרוקסי פרימיום)
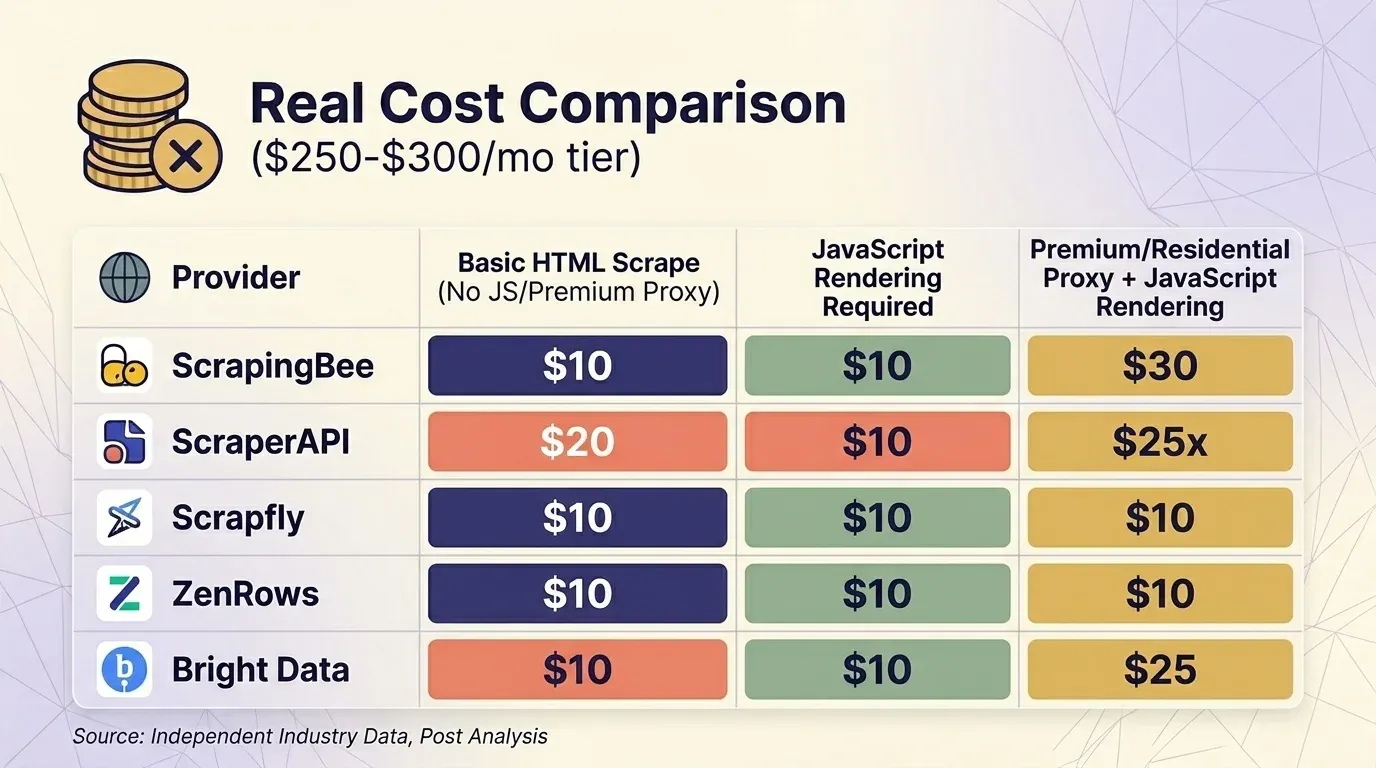
| ספק | תוכנית | קרדיטים לבקשה | בקשות בפועל | עלות ל‑1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3,000,000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3,000,000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2,500,000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | ~1,071,000 | $0.28 |
| Bright Data | PAYG | $1.50/1K | ~200,000 | $1.50 |
נדרש רינדור JavaScript
| ספק | תוכנית | קרדיטים לבקשה | בקשות בפועל | עלות ל‑1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (מופעל כברירת מחדל) | 600,000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416,667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300,000 | $1.00 |
| ZenRows | Business $300 | 5× | ~214,000 | $1.40 |
| Bright Data | PAYG | קבוע | ~200,000 | $1.50 |
פרוקסי פרימיום/Residential + רינדור JavaScript (אתרים מוגנים)
| ספק | תוכנית | קרדיטים לבקשה | בקשות בפועל | עלות ל‑1K |
|---|---|---|---|---|
| Bright Data | PAYG | קבוע | ~200,000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120,000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120,000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80,645 | $3.10 |
| ZenRows | Business $300 | 25× | ~42,857 | $7.00 |
ה‑Web Unlocker של Bright Data הוא הספק היחיד — כל הבקשות מתומחרות באותו מחיר קבוע. ברמת כ‑$300, ScrapingBee ו‑ScraperAPI תחרותיים עבור גרידה של אתרים מוגנים, בעוד ZenRows הוא היקר ביותר.
הערת התנהגות חשובה: ScrapingBee בעלות של 5×. אם אתם משווים ראש בראש בין ScrapingBee ל‑ScraperAPI, ודאו שאתם משווים עם אותן הגדרות רינדור.
ניתוח עצמאי של Scrape.do מצא ש‑ScraperAPI עולה בממוצע — "יותר מכל ספק אחר שנבדק" — עם זמן תגובה ממוצע של , מה שהופך אותו ל"אחד הספקים האיטיים ביותר שקיימים." כדאי לדעת את זה לפני שמתחייבים.
שיעורי הצלחה לפי אתר: איפה ScraperAPI מצטיין ואיפה הוא מתקשה
אין API לגרידת אתרים שעובד באותה מידה טוב על כל אתר. בנצ'מרקים עצמאיים של Scrapeway (אפריל 2026) מספרים סיפור חד וברור.
ביצועים לפי קטגוריית אתר
| אתר יעד | שיעור הצלחה | מהירות ממוצעת | עלות ל‑1K (Business Plan) |
|---|---|---|---|
| Zillow | 100% | 10.5s | $0.49 |
| Etsy | 99% | 4.8s | $4.90 |
| Amazon | 98% | 6.5s | $2.45 |
| 95% | 17.8s | $14.70 | |
| Walmart | 93% | 11.4s | $2.45 |
| Indeed | 90% | 15.8s | $4.90 |
| StockX | 84% | 3.9s | $4.90 |
| Realtor.com | 12% | 11.8s | $0.49 |
| 0% | — | — | |
| Booking.com | 0% | — | — |
| Twitter/X | 0% | — | — |
שיעור הצלחה ממוצע כולל: , מעט מעל ממוצע התעשייה של 58.2–59.5%. זמן תגובה ממוצע: 5.2–7.3 שניות, טוב מהממוצע בתעשייה של 9.8 שניות.
איפה ScraperAPI עובד טוב
ScraperAPI חזק באמת ב‑e-commerce (Amazon, Walmart, Etsy) וב‑נדל"ן (Zillow). נקודות הקצה של הנתונים המובנים עבור אתרים אלה מחזירות JSON מנותח בצורה אמינה. אם השימוש העיקרי שלכם הוא גרידת דפי מוצרים ב‑Amazon או Google SERPs, ScraperAPI הוא בחירה סבירה.
איפה ScraperAPI חלש
רשתות חברתיות הן אזור מת. Instagram, Twitter/X ו‑Booking.com כולם מציגים שיעור הצלחה של 0% בבדיקות עצמאיות. LinkedIn עובד ב‑95%, אבל עם 30 קרדיטים לבקשה, העלות גבוהה.
אתרים שדורשים התחברות הם מחוץ לתחום במפורש. ScraperAPI תומך בשמירת session באמצעות הפרמטר session_number, אבל . הוא לא יודע להתמודד עם מילוי טפסים, אימות דו‑שלבי או זרימות התחברות מורכבות.
נתונים מיושנים ביעדים מוגנים. ScraperAPI מפעיל , כלומר אם אתם מגרדים נתונים רגישים לזמן (מחירים, מלאי), ייתכן שתקבלו תוצאות בנות עד 10 דקות.
בבנצ'מרק של Proxyway לשנת 2025, ל‑ScraperAPI היה עם 81.72%.
סיכום ביצועים לפי קטגוריית אתר
| קטגוריית אתר | הביצועים של ScraperAPI | בעיות ידועות | חלופה אפשרית |
|---|---|---|---|
| Amazon / e-commerce | ✅ חזק (SDP endpoints) | כבד בקרדיטים בקנה מידה | Thunderbit templates (בלחיצה אחת, בלי קרדיט לכל שורה עבור התבנית) |
| Google SERPs | ✅ חזק | גאוטרגוטינג עולה תוספת; שיעור הצלחה נמוך יחסית ב‑Google באחד הבנצ'מרקים | — |
| נדל"ן (Zillow) | ✅ מצוין (100%) | — | — |
| Instagram / רשתות חברתיות | ❌ 0% הצלחה | כישלון מוחלט | Playwright + פרוקסי (DIY) |
| SPAs עתירי JS | ⚠️ בינוני | דורש רינדור headless בעלות 10× קרדיטים | Scrapfly, ZenRows |
| אתרים שדורשים התחברות | ❌ אסור לפי ה‑ToS | אין תמיכה ב‑session/auth | Thunderbit browser scraping (משתמש ב‑login session שלכם) |
| Booking.com / תיירות | ❌ 0% הצלחה | כישלון מוחלט | Bright Data |
מה משתמשים אמיתיים אומרים: סיכום תחושות מ‑G2, Capterra ו‑Reddit
אספתי משוב משלוש פלטפורמות. אלו הדירוגים הנוכחיים:
| פלטפורמה | דירוג | ביקורות |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
תתי‑הדירוגים ב‑Capterra: קלות שימוש 4.9/5, שירות לקוחות 4.6/5, תכונות 4.5/5, תמורה לכסף 4.5/5.
סיכום תחושות לפי נושא
| נושא | סימנים חיוביים | סימנים שליליים |
|---|---|---|
| קלות הקמה / תיעוד | "מאוד קל להגדיר. אפשר להתחיל לגרד בתוך דקות." — Latenode community; דירוג קלות שימוש ב‑Capterra 4.9/5 | — |
| שקיפות תמחור | "רמת כניסה משתלמת" (מספר ביקורות ב‑Capterra) | "פירוט עלויות הקרדיטים יכול להיות מבלבל" — John S., Founder, Capterra (פבר' 2025); "המחירים עלו ב‑1000% והאיכות ירדה" — CTO, Online Media, Capterra (ספט' 2022) |
| אמינות | "עובד מצוין עבור Amazon/Google" (G2, Capterra) | "ScraperAPI נהיה לא יציב במשימות כבדות" — emcarter, Latenode; "שיעור כשל של 80% ביעדים מסוימים" (Reddit) |
| תמיכת לקוחות | "צוות מגיב במהירות" (Capterra) | משתמש דיווח שקיבל מחיר אחד ואז חויב פי 5 ללא גילוי מראש (Reddit) |
| ערך לאורך זמן | גובה תשלום רק על בקשות שהצליחו (200/404) | "אם מריצים פעילות בקנה מידה גדול, ההוצאות יכולות להצטבר מהר" ובניית תשתית מותאמת אישית היא "חסכונית יותר בטווח הארוך" — mikezhang, Latenode |
המסקנה: ScraperAPI נחשב טוב מאוד מבחינת קלות ההקמה הראשונית, ומציג אמינות טובה על יעדים פופולריים ומאוד נתמכים. התלונות מתרכזות בהפתעות תמחור (מכפילים, עליות לא צפויות) ובאמינות מול יעדים קשים יותר.
נקודות הקצה לנתונים מובנים של ScraperAPI: שוות את הקרדיטים הנוספים?
ScraperAPI מציע על פני 5 פלטפורמות, ומחזיר JSON מנותח במקום HTML גולמי:
- Amazon (3 endpoints): פרטי מוצר לפי ASIN, תוצאות חיפוש, הצעות מתחרים. מחזיר 18+ שדות כולל מחיר, דירוגים, תיאורים, ביקורות, BSR, תמונות, מידע על המוכר. תומך ב‑.
- Google (5 endpoints): (תוצאות אורגניות, knowledge graph, וידאו, שאלות קשורות, עימוד), Shopping, Maps, News, Jobs.
- Walmart (4 endpoints): מוצר, חיפוש, קטגוריה, ביקורות.
- eBay (2 endpoints): מוצר, חיפוש.
- Redfin (4 endpoints): חיפוש, פרטי סוכן, נכסים להשכרה, למכירה.
נקודות הקצה לנתונים מובנים זמינות בכל התוכניות, כולל Free. ScraperAPI טוען לשיעור הצלחה של עבור דומיינים נתמכים — אם כי בנצ'מרקים עצמאיים מציירים תמונה קצת יותר מורכבת, תלוי באתר.
שלמות הנתונים
ה‑Amazon SDP הוא ההצעה החזקה ביותר של ScraperAPI. הוא מחזיר סט מקיף של שדות: מחיר, ביקורות, BSR, וריאנטים, תמונות, מידע על מוכר ועוד. ה‑Google SERP SDP מחזיר תוצאות אורגניות, מודעות, featured snippets ו‑People Also Ask. שלמות הנתונים באמת טובה בשתי הפלטפורמות האלה.
יעילות קרדיטים: SDP מול parsing עצמאי
בתוכנית Business ($299 בחודש, 3M קרדיטים), גרידת 10,000 מוצרי Amazon דרך ה‑SDE עולה 50,000 קרדיטים (5 לכל מוצר) — בערך $5 מתוך התוכנית. בניית parser עצמאי עם בקשה רגילה (קרדיט אחד לכל מוצר) תעלה רק 10,000 קרדיטים, אבל תצטרכו להשקיע זמן פיתוח בבנייה ותחזוקה של ה‑parser.
לצוותים קטנים בלי מפתחים, SDEs חוסכים זמן אמיתי.
לצוותים עם יכולת הנדסית שגורפים בהיקפים גדולים, קשה להצדיק את תוספת 5× הקרדיטים.
איך SDPs משתווים לתבניות גרידה ללא קוד
ההשוואה הזו חשובה יותר ממה שרוב הסקירות מודות. מציע תבניות גרידה מיידיות ל‑Amazon, Shopify, Zillow, ו‑ שלא דורשות כתיבת קוד וגם לא עלות קרדיט לכל שורה עבור התבנית עצמה.
| גורם | ScraperAPI SDP (Amazon) | תבנית Amazon של Thunderbit |
|---|---|---|
| זמן הקמה | 30–60 דק' (קוד + אינטגרציית API) | ~2 דקות (התקנת התוסף, פתיחת Amazon, לחיצה על התבנית) |
| עלות ל‑1,000 מוצרים (Business plan) | ~$5 (50,000 קרדיטים ב‑$0.10 לקרדיט) | ~$16.50 (1,000 שורות × קרדיט אחד ב‑$0.0165 לקרדיט ב‑Pro) |
| שfields מוחזרים | 18+ (מקיף) | שם מוצר, מחיר, דירוג, ביקורות, תמונות, URL ועוד |
| אפשרויות ייצוא | JSON (דורש קוד לפענוח) | Excel, CSV, Google Sheets, Airtable, Notion — בלחיצה אחת |
| תחזוקה | ScraperAPI מתחזק את ה‑SDP | צוות Thunderbit מתחזק את התבניות |
| מיומנות טכנית | נדרש Python/Node.js | לא נדרש |
עבור צוותי פיתוח שמבצעים גרידת Amazon בהיקפים גדולים, ה‑SDP של ScraperAPI חסכוני יותר לכל מוצר בקנה מידה. עבור משתמשים עסקיים שצריכים נתוני Amazon בגיליון בלי לכתוב קוד, Thunderbit מהיר הרבה יותר להקמה ולשימוש.
האם אתם בכלל צריכים API לגרידת נתונים? המסלול ללא קוד שרוב הסקירות מתעלמות ממנו
הרבה אנשים שמחפשים "Scraper API review" עוד לא התחייבו לזרימת עבודה מבוססת API. הם מנסים להבין אם הם צריכים כזה בכלל.
באופן מפתיע, רבים מהם לא צריכים. שוק ה‑web scraping API הוא תעשייה של שצומחת בקצב שנתי של 14–18%, אבל הצמיחה הזו מונעת בעיקר מצוותי הנדסה בארגונים — לא ממנהל Sales Ops שצריך 500 לידים מאתר כלשהו.
API לגרידת נתונים מול כלי ללא קוד: מסגרת החלטה ראש בראש
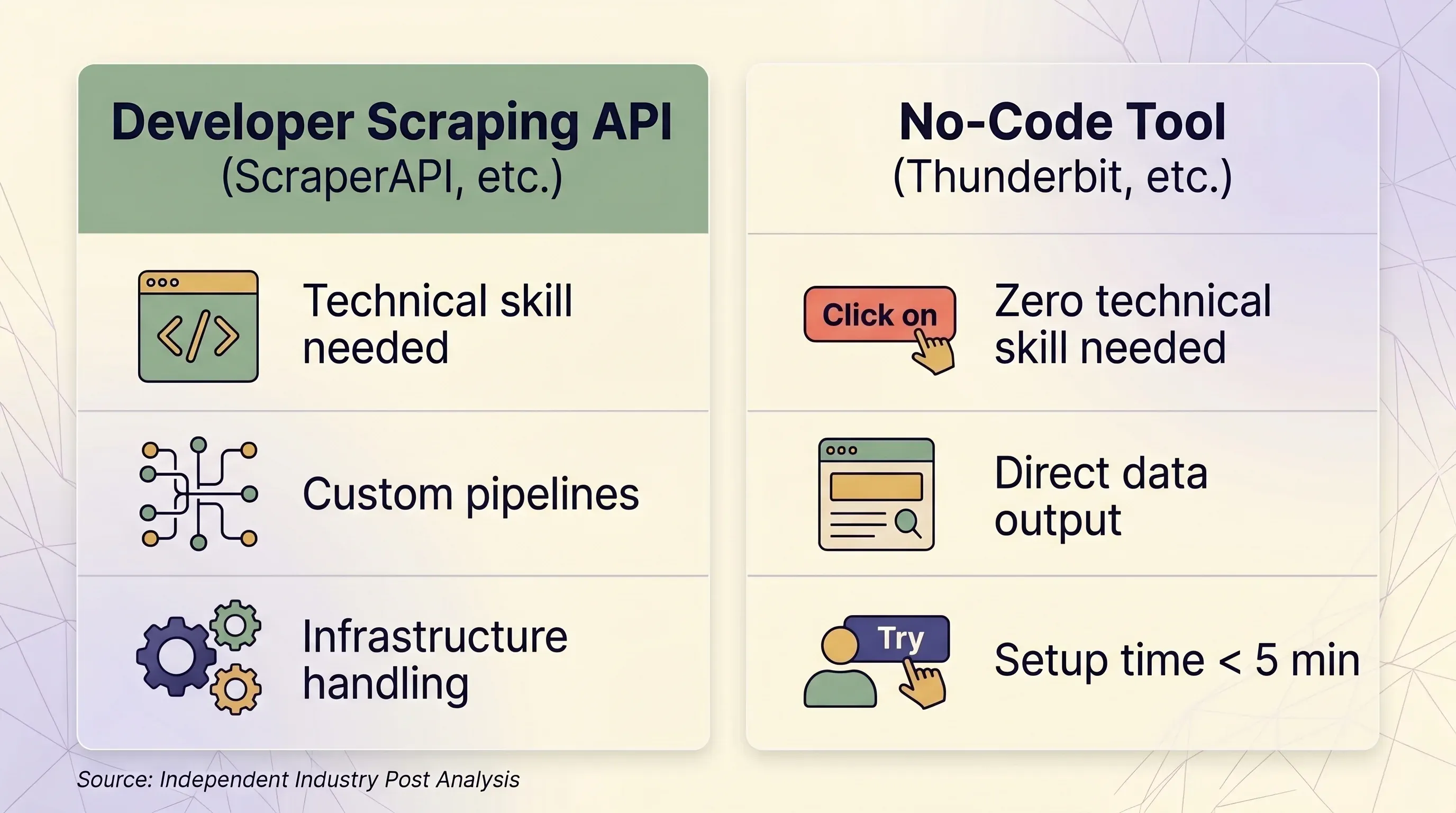
| גורם | API לגרידת נתונים (ScraperAPI וכו') | כלי ללא קוד (Thunderbit וכו') |
|---|---|---|
| הכי מתאים ל | מפתחים שבונים צינורות נתונים בקנה מידה | משתמשים עסקיים, משווקים, צוותי מכירות, חוקרים |
| מיומנות טכנית נדרשת | Python/Node.js, מושגי HTTP, ניתוח JSON | אין — לחיצה ישירה בדפדפן |
| זמן הקמה | לפחות 1–2 שעות (קוד + בדיקות + ניפוי שגיאות) | פחות מ‑5 דקות |
| טיפול באנטי‑בוט | פרוקסי פרימיום (10–75 קרדיטים לבקשה) | session אמיתי בדפדפן — עוקף fingerprinting באופן טבעי |
| אתרים שדורשים התחברות | ❌ אסור לפי ה‑ToS של ScraperAPI | ✅ Browser Scraping משתמש ב‑session הקיים שלכם |
| קנה מידה (עמודים/יום) | 100K–3M+ בקשות בחודש | לפי צורך, בדרך כלל פחות מ‑1,000 עמודים ביום |
| פלט נתונים | HTML גולמי או JSON (דורש קוד לפענוח) | שורות/עמודות מובנות — מוכנות לשימוש |
| ייצוא | JSON, CSV (דרך קוד) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON |
| תחזוקה | חייבים לעדכן selectors, לוגיקת retry, ותשתית | אין — AI קורא מחדש את מבנה הדף בכל פעם |
| יחידת תמחור | קרדיטים לפי בקשה (משתנה: 1–75 קרדיטים לבקשה) | קרדיטים לפי שורה (קרדיט אחד = שורה אחת, 2 עבור תתי‑עמודים) |
| מחיר כניסה | $49 בחודש עבור 100K קרדיטים | $9 בחודש עבור 5,000 קרדיטים (שנתי) |
| תוכנית חינם | 1,000 קרדיטים/חודש, 5 מקביליים | 6 עמודים/חודש, 30 קרדיטים לעמוד |
| צפיות תמחור | נמוכה — מכפילים יוצרים עלויות מפתיעות | גבוהה — שורה אחת תמיד = קרדיט אחד |
מתי API לגרידת נתונים כן הגיוני
- יש לכם צוות פיתוח או הנדסה
- אתם צריכים לגרד 100K+ עמודים ביום באופן פרוגרמטי
- אתם צריכים התאמה עמוקה של כותרות בקשה, sessions ולוגיקת retry
- היעדים שלכם נתמכים היטב (Amazon, Google, Walmart, Zillow)
מתי כלי ללא קוד כמו Thunderbit הוא הבחירה הנכונה יותר
- אתם עובדים במכירות, e-commerce ops, שיווק או נדל"ן — לא בהנדסה
- אתם צריכים נתונים מעשרות אתרים שונים בלי לבנות parser מותאם לכל אתר
- אתם רוצים ייצוא ישיר ל‑Excel, Google Sheets, Airtable או Notion
- אתם צריכים לגרד אתרים שדורשים התחברות (ה‑ של Thunderbit משתמש ב‑session שלכם)
- אתם רוצים ש‑AI יקרא את הדף מחדש בכל פעם — בלי תחזוקת קוד כשהאתרים משנים פריסה
- אתם צריכים גרידת תתי‑עמודים: Thunderbit יכול לבקר בכל דף פירוט ולהעשיר שורות אוטומטית
זרימת העבודה של באמת פשוטה: מתקינים את התוסף, עוברים לכל דף, לוחצים "AI Suggest Fields", לוחצים "Scrape", ומייצאים. ה‑AI מבין איזה מידע יש בדף ומציע עמודות — לא צריך לכתוב selectors או קוד. למידע נוסף על איך זה עובד, קראו את .
חוו חריגות בעלויות ענן ב‑2024, וחברות שמשתמשות בתמחור לפי שימוש בלי הגנות מתאימות רואות בגלל bill shock. התחזיתיות של מודל קרדיטים לפי שורה שווה שיקול אם כבר נפגעתם בעבר מעלויות API משתנות.
יתרונות וחסרונות של ScraperAPI בקצרה
| יתרונות | חסרונות |
|---|---|
| תשתית פרוקסי חזקה (40M+ IPs, 50+ מדינות) | מערכת מכפילי קרדיטים מבלבלת — שילוב תכונות עולה יותר מסכומן |
| תיעוד מצוין והקמה ראשונית פשוטה (Capterra Ease of Use: 4.9/5) | קרדיטים לא עוברים לחודש הבא |
| אמין על Amazon, Google, Zillow, Etsy | 0% הצלחה ב‑Instagram, Twitter/X, Booking.com |
| גובה תשלום רק על בקשות מוצלחות (200/404) | תגובות 404 עדיין צורכות קרדיטים |
| 18 נקודות קצה לנתונים מובנים עם JSON מנותח | אתרים שדורשים התחברות אסורים במפורש |
| זמין בכל התוכניות כולל Free | Pay‑As‑You‑Go רק ב‑Scaling ($475/חודש) ומעלה |
| מדיניות החזר כספי של 7 ימים ללא שאלות | מטמון כפוי של 10 דקות ביעדים קשים — סיכון לנתונים מיושנים |
| צמיחת הכנסות של 30–35% משנה לשנה מרמזת על פיתוח פעיל | DataPipeline עולה עד פי 6 מקרדיטי ה‑API הרגיל |
| — | גאוטרגוטינג מעבר לארה"ב ו‑EU דורש Business plan ($299/חודש) |
| — | אין התראות שימוש יזומות — חייבים לבדוק ידנית את הדשבורד |
טיפים מעשיים להפקת המקסימום מ‑ScraperAPI (אם תחליטו להשתמש בו)
עקבו אחר צריכת הקרדיטים מדי יום
ה‑ של ScraperAPI מספק סטטיסטיקות שימוש כולל זמן תגובה ממוצע, דומיינים שנגרדו ומדדי concurrency. עם זאת, אין התראות שימוש יזומות — לא מייל ולא SMS כשהקרדיטים אוזלים. צריך לבדוק ידנית. היסטוריית האנליטיקה מוגבלת ל‑2 שבועות בתוכניות Hobby/Startup ול‑6 חודשים בתוכניות Business ומעלה.
קבעו תזכורת ביומן לבדוק את הדשבורד כל יום בחודש הראשון. צריך לפתח אינטואיציה לגבי כמה מהר הקרדיטים נשרפים ביעדים הספציפיים שלכם.
התחילו עם התוכנית החינמית כדי לבדוק את אתרי היעד
השתמשו ב‑1,000 הקרדיטים החינמיים (בתוספת תקופת ניסיון של 7 ימים עם 5,000 קרדיטים) כדי לבדוק שיעורי הצלחה באתרים הספציפיים שלכם לפני שאתם מתחייבים לתוכנית בתשלום. תעדו אילו אתרים דורשים רינדור JavaScript או פרוקסי פרימיום כדי שתוכלו להעריך עלויות חודשיות ריאליות אחרי חישוב המכפילים.
כבו תכונות פרימיום אלא אם האתר דורש אותן
ScraperAPI לא מפעיל אוטומטית פרוקסי פרימיום או רינדור JavaScript — אתם חייבים להגדיר במפורש render=true, premium=true או ultra_premium=true. אבל תמחור לפי דומיין כן אוטומטי: Amazon תמיד עולה 5 קרדיטים, Google תמיד 25, LinkedIn תמיד 30. קרדיטי עקיפת אנטי‑בוט (+10 עבור Cloudflare, DataDome, PerimeterX) מתווספים גם הם אוטומטית כשהמערכת מזהה אותם. חשוב לדעת את זה לפני הרצת batch.
השתמשו בנקודות הקצה לנתונים מובנים עבור אתרים נתמכים
אם אתם מגרדים Amazon או Google, ה‑SDEs חוסכים זמן פיתוח גם אם הם עולים יותר קרדיטים. עבור אתרים שאינם נתמכים, בדקו האם יהיה מהיר וזול יותר מבניית parser מותאם.
הכינו תוכנית גיבוי ליעדים לא אמינים
אם שיעור ההצלחה של ScraperAPI באתר מסוים יורד מתחת ל‑90%, שקלו לנתב את הבקשות דרך ספק אחר או להשתמש בכלי מבוסס דפדפן. עבור אתרים שדורשים התחברות, ScraperAPI פשוט לא יעבוד — תצטרכו כלי כמו שפועל בתוך session הדפדפן שלכם.
הכירו את המלכודות
- תגובות 404 צורכות קרדיטים — ScraperAPI מחייב גם על קודי מצב 200 וגם 404
- בקשות שבוטלו עדיין מחויבות אם מבטלים לפני שסיום חלון העיבוד של 70 שניות
- מטמון כפוי של 10 דקות ביעדים קשים — ייתכן שתקבלו נתונים מיושנים
- Pay‑As‑You‑Go זמין רק ב‑Scaling ($475/חודש) ומעלה — משתמשי דרגות נמוכות שממצים קרדיטים מנותקים
- גאוטרגוטינג מעבר לארה"ב ו‑EU דורש Business plan ($299/חודש)
מסקנות עיקריות: האם ScraperAPI הוא הכלי הנכון עבורכם?
ככה הגעתי למסקנה אחרי כל המחקר:
- ScraperAPI הוא בחירה טובה לצוותי פיתוח שמגרדים כמויות גבוהות של יעדים נתמכים היטב כמו Amazon, Google, Walmart ו‑Zillow. נקודות הקצה לנתונים מובנים באמת שימושיות, תשתית הפרוקסי גדולה, והתיעוד מעל הממוצע.
- מערכת מכפילי הקרדיטים היא הסיכון הגדול ביותר. אם לא מבינים איך המכפילים מצטברים, תוציאו יותר מדי. הפער בין הקרדיטים המוצגים לבין מספר הבקשות בפועל יכול להיות פי 5–75. עשו חישוב ספציפי למקרה השימוש שלכם לפני התחייבות לתוכנית בתשלום.
- האמינות תלויה באתר. ScraperAPI מצטיין ב‑e-commerce ובנדל"ן, בינוני בלוחות משרות וברשתות חברתיות, וחסר תועלת לחלוטין ב‑Instagram, Twitter/X ו‑Booking.com. אל תניחו ביצועים אחידים.
- לצוותים לא טכניים, ScraperAPI הוא לא הכלי הנכון. אם אתם עובדים במכירות, שיווק או ops וצריכים נתונים מובנים בלי לכתוב קוד, כלי ללא קוד כמו יוביל אתכם לשם בשתי לחיצות — עם זיהוי שדות מבוסס AI, ייצוא ישיר לגיליון, העשרת תתי‑עמודים, וללא עומס תחזוקה. בדקו את או צפו במדריכים ב‑.
- למפתחים עם תקציב מוגבל, בדקו את התוכנית החינמית של ScraperAPI על היעדים הספציפיים שלכם, ואז השוו עלות אפקטיבית לבקשה מול ScrapingBee, Scrapfly ו‑Bright Data לפני שמחליטים. האפשרות הזולה ביותר תלויה לחלוטין במקרה השימוש ובדרישות התכונות.
רוצים לראות איך המספרים עובדים עבור צורכי הגרידה הספציפיים שלכם? התחילו עם התוכנית החינמית של ScraperAPI כדי לבדוק את אתרי היעד, או כדי לראות כמה רחוק שתי לחיצות יכולות לקחת אתכם. למידע נוסף על , בדקו את התוכניות שלנו.
שאלות נפוצות
האם ScraperAPI חינמי?
כן, ScraperAPI מציע תוכנית חינמית עם וניסיון של 7 ימים עם 5,000 קרדיטים. עם זאת, מכפילי הקרדיטים עבור רינדור JavaScript, פרוקסי פרימיום, או דומיינים יקרים (Amazon = 5×, Google = 25×, LinkedIn = 30×) אומרי שכושר השימוש האמיתי שלכם עשוי להיות נמוך בהרבה מ‑1,000 בקשות. בתוכנית החינמית, פרוקסי ultra‑premium אינם זמינים.
כמה עולה ScraperAPI לכל בקשה?
זה תלוי מאוד בדגלי התכונות ובדומיין היעד. בקשה רגילה לאתר HTML פשוט עולה קרדיט אחד. בקשת Amazon עולה 5 קרדיטים. בקשת Google SERP עולה 25 קרדיטים. הוספת רינדור JavaScript מוסיפה 10 קרדיטים. שילוב של פרוקסי ultra‑premium עם רינדור JavaScript עולה 75 קרדיטים לבקשה. בתוכנית Hobby ($49/חודש, 100K קרדיטים), זה נע בין $0.00049 לבקשה (רגיל) ל‑$0.0368 לבקשה (ultra‑premium + JS). ראו את טבלאות העלויות המלאות למעלה לפרטים.
האם ScraperAPI טוב לגרידת Amazon?
נקודת הקצה לנתונים מובנים של Amazon ב‑ScraperAPI היא אחת החזקות שלו, עם בבנצ'מרקים עצמאיים ופלט JSON מנותח מקיף (18+ שדות). עם זאת, כל בקשת Amazon עולה לפחות 5 קרדיטים, כך שהעלויות מצטברות בקנה מידה. עבור צוותים קטנים שרוצים נתוני Amazon בגיליון בלי קוד, מציעה חלופה בלחיצה אחת עם ייצוא ישיר.
מהן החלופות הטובות ביותר ל‑ScraperAPI?
למפתחים: (הזול ביותר עבור HTML בסיסי), (טוב לרינדור JavaScript), (הטוב ביותר לאתרים מוגנים — תמחור קבוע בלי קשר לרינדור), ו‑. למשתמשים לא טכניים: — תוסף Chrome ללא קוד, מבוסס AI, עם ייצוא ישיר ל‑Excel, Google Sheets, Airtable ו‑Notion. ראו את למבט מעמיק יותר.
האם ScraperAPI יכול לגרד אתרים שדורשים התחברות?
ScraperAPI תומך בשמירת session דרך הפרמטר session_number (אותו IP לאורך כמה בקשות), אבל הוא . הוא לא מסוגל להתמודד עם מילוי טפסים, אימות דו‑שלבי או זרימות auth מורכבות. עבור אתרים שדורשים התחברות, כלים מבוססי דפדפן כמו — שמשתמשים ב‑browser session הקיים שלכם כדי לגרד את מה שאתם רואים — הם האפשרות האמינה יותר.
למדו עוד