

אם אי פעם ניסיתם לבנות רשימת מכירות ממוקדת, לאתר שווקים חדשים או להשוות את עצמכם למתחרים, אתם כבר יודעים ש-Google Maps הוא מכרה זהב. אבל הנה העניין: עם יותר מ-1.5 מיליארד חיפושים של “לידי” בכל חודש ו-76% מהמחפשים המקומיים שמבקרים בעסק בתוך 24 שעות (thinkwithgoogle.com), הביקוש לנתונים עסקיים מעודכנים ומבוססי מיקום מעולם לא היה גבוה יותר.
בין אם אתם עובדים במכירות, בשיווק או בתפעול, חילוץ נתונים מובנים מ-Google Maps יכול להיות ההבדל בין שיחת קרה לליד חם עם פוטנציאל המרה גבוה.
אני עובד שנים ב-SaaS ובאוטומציה, וראיתי מקרוב איך צוותים משתמשים ב-Python (ועכשיו גם בכלים מבוססי AI כמו Thunderbit) כדי להפוך את Google Maps לנכס אסטרטגי.
במדריך הזה אפרק בדיוק איך לגרוף נתונים מ-Google Maps עם Python בשנת 2026 — צעד אחר צעד, עם קוד, טיפים לציות למדיניות, והשוואה לפתרונות ללא קוד. בין אם אתם מקצועני Python או פשוט רוצים את הדרך המהירה ביותר לנתונים שאפשר לפעול לפיהם, הגעתם למקום הנכון.
מה המשמעות של גריפת Google Maps עם Python?
נתחיל מהבסיס: גריפת Google Maps עם Python פירושה חילוץ אוטומטי של מידע עסקי — כמו שמות, כתובות, דירוגים, ביקורות, מספרי טלפון וקואורדינטות — מ-Google Maps, כך שתוכלו לנתח, לסנן ולייצא אותו לשימוש עסקי.

יש שתי דרכים עיקריות לעשות זאת:
- Google Maps Places API: הדרך הרשמית והמוסדרת. משתמשים במפתח API כדי לשלוח שאילתות לשרתי Google ומקבלים בחזרה נתוני JSON מובנים. זה יציב, צפוי, ו(ברוב המקרים) תואם למדיניות, אבל יש מכסות ועלויות.
- גריפת HTML מהאתר: מבצעים אוטומציה של הדפדפן (עם כלים כמו Playwright או Selenium), טוענים את Google Maps, מבצעים חיפושים ומנתחים את הדף שמוצג. זו שיטה גמישה יותר אבל שברירית — Google משנה את מבנה האתר לעיתים קרובות, וגריפת ה-HTML עלולה להפר את התנאים שלה.
שדות נתונים טיפוסיים שאפשר לחלץ:
- שם העסק
- קטגוריה/סוג
- כתובת מלאה (בתוספת עיר, מדינה, מיקוד, מדינה)
- קו רוחב וקו אורך
- מספר טלפון
- כתובת האתר
- דירוג ומספר ביקורות
- רמת מחירים
- סטטוס העסק (פתוח/סגור)
- שעות פתיחה
- Place ID (המזהה הייחודי של Google)
- כתובת URL של Google Maps
למה זה חשוב? כי השדות האלה מניעים הכול — מהפקת לידים ותכנון טריטוריות ועד השוואה למתחרים ומחקר שוק. המפתח הוא לכוון לנתונים הנכונים למטרות העסקיות שלכם — לא לגרוף סתם בלי הבחנה.
למה צוותי מכירות ושיווק מחלצים נתונים מ-Google Maps באמצעות Python
בואו נרד לקרקע. למה כל כך הרבה צוותי מכירות ושיווק אובססיביים לנתוני Google Maps בשנת 2026?
- הפקת לידים: בניית רשימות מדויקות במיוחד של עסקים מקומיים, כולל פרטי קשר ודירוגים, לקמפיינים של פנייה.
- תכנון טריטוריות: מיפוי אזורי מכירה, אזורי חלוקה או אזורי שירות לפי צפיפות וסוגי עסקים אמיתיים.
- מעקב אחר מתחרים: מעקב לאורך זמן אחרי מיקומים, דירוגים וביקורות של מתחרים כדי לזהות מגמות והזדמנויות.
- מחקר שוק: ניתוח קטגוריות עסקיות, שעות פעילות ותחושות שעולות מהביקורות כדי לתמוך באסטרטגיית החדירה לשוק.
- בחירת מיקום: בנדל״ן ובקמעונאות, הערכת מיקומים פוטנציאליים לפי שירותים קרובים, תנועת מבקרים ותחרות.
השפעה בעולם האמיתי: לפי HubSpot State of Sales 2025, 92% מארגוני המכירות מתכננים להרחיב את ההשקעה ב-AI/נתונים, וצוותים שמשתמשים בנתונים מקומיים ממוקדים רואים שיעורי המרה גבוהים עד פי 8 לעומת מי שנשענים על רשימות קרות כלליות (martal.ca). מחקר אחד על לידים לזכיינות מצא 15 דולר הכנסה חדשה על כל דולר אחד שהושקע ברשימות לידים מבוססות Google Maps.
מיפוי מטרות עסקיות לשדות של Google Maps:
| מטרה עסקית | שדות נדרשים מ-Google Maps |
|---|---|
| רשימת לידים מקומית | name, address, phone, website, category |
| תכנון טריטוריות | name, lat/lng, business_status, opening_hours |
| השוואה למתחרים | name, rating, userRatingCount, priceLevel, reviews |
| בחירת מיקום | category, lat/lng, review density, openingDate |
| תובנות לגבי סנטימנט/תפריט | reviews, editorialSummary, photos, types |
| פנייה במייל/טלפון | nationalPhoneNumber, websiteUri (ואז העשרה לפי הצורך) |
הגדרת Google Maps Scraper ב-Python: כלים ודרישות
לפני שמתחילים לגרוף, צריך להגדיר את סביבת ה-Python ולאסוף את הכלים הנכונים. הנה מה שתצטרכו בשנת 2026:
1. התקנת Python והספריות הנדרשות
גרסת Python מומלצת: 3.10 ומעלה.
התקנת הספריות המרכזיות:
pip install \
requests==2.33.1 httpx==0.28.1 \
beautifulsoup4==4.14.3 lxml==6.0.3 \
pandas==2.3.3 \
selenium==4.43.0 playwright==1.58.0 \
googlemaps==4.10.0 google-maps-places==0.8.0 \
schedule==1.2.2 APScheduler==3.11.2 \
python-dotenv==1.2.2 tenacity==9.1.4
playwright install chromium
מה זה עושה:
requests,httpx: בקשות HTTP (קריאות API)beautifulsoup4,lxml: ניתוח HTML (לגריפת אתרים)pandas: ניקוי נתונים, ניתוח וייצואselenium,playwright: אוטומציה של דפדפן (לגריפת HTML)googlemaps,google-maps-places: לקוחות API של Google Mapsschedule,APScheduler: תזמון משימותpython-dotenv: טעינה מאובטחת של מפתחות API מקובצי.envtenacity: לוגיקת ניסיון חוזר לטיפול בשגיאות
2. קבלת מפתח Google Maps API (לגריפת נתונים מבוססת API)
- היכנסו ל-Google Cloud Console.
- צרו פרויקט או בחרו פרויקט קיים.
- הפעילו חיוב (נדרש, גם לשכבת החינם).
- הפעילו את “Places API (New)” תחת APIs & Services > Library.
- עברו ל-Credentials > Create Credentials > API Key.
- הגבילו את המפתח ל-APIs וכתובות IP ספציפיות מטעמי אבטחה.
- שמרו את מפתח ה-API בקובץ
.env(לעולם אל תכניסו אותו לקוד):
GOOGLE_MAPS_API_KEY=your_actual_api_key_here
הערה: נכון למרץ 2025, Google כבר לא מציעה קרדיט אוניברסלי של 200 דולר בחודש. במקום זאת, יש ספי חינם חודשיים לכל שכבת API (ראו המחירון הרשמי).
איך לחלץ נתונים מ-Google Maps באמצעות Python: מדריך צעד-אחר-צעד
בואו נחלק את שתי הגישות העיקריות — מבוססת API ו-גריפת HTML — כדי שתוכלו לבחור מה מתאים לצרכים שלכם.
גישה 1: שימוש ב-Google Maps Places API (מומלץ)
שלב 1: התקנה וייבוא של הספריות הנדרשות
import os
import httpx
import pandas as pd
from dotenv import load_dotenv
שלב 2: טעינה מאובטחת של מפתח ה-API
load_dotenv()
API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]
שלב 3: בניית שאילתת החיפוש
תשתמשו ב-endpoint של Text Search כדי למצוא עסקים שתואמים לקריטריונים שלכם.
URL = "https://places.googleapis.com/v1/places:searchText"
FIELD_MASK = ",".join([
"places.id", "places.displayName", "places.formattedAddress",
"places.location", "places.rating", "places.userRatingCount",
"places.priceLevel", "places.types",
"places.nationalPhoneNumber", "places.websiteUri",
"nextPageToken",
])
שלב 4: שליחת בקשת ה-API
def text_search(query, lat, lng, radius=3000, min_rating=4.0):
body = {
"textQuery": query,
"minRating": min_rating, # סינון בצד השרת
"includedType": "restaurant",
"openNow": False,
"pageSize": 20,
"locationBias": {
"circle": {
"center": {"latitude": lat, "longitude": lng},
"radius": radius,
}
},
}
headers = {
"Content-Type": "application/json",
"X-Goog-Api-Key": API_KEY,
"X-Goog-FieldMask": FIELD_MASK, # תמיד להגדיר את זה!
}
r = httpx.post(URL, json=body, headers=headers, timeout=30)
r.raise_for_status()
return r.json()
שלב 5: טיפול בפאג’ינציה ואיסוף התוצאות
def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
results = []
next_page_token = None
while True:
data = text_search(query, lat, lng, radius, min_rating)
places = data.get('places', [])
results.extend(places)
next_page_token = data.get('nextPageToken')
if not next_page_token:
break
return results
שלב 6: ייצוא נתונים עם Pandas
df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
df.to_csv("brooklyn_coffee_shops.csv", index=False)
טיפים מקצועיים:
- תמיד הגדירו את הכותרת
X-Goog-FieldMaskכדי לשלוט בעלויות. אם מבקשים ביקורות או תמונות, המחיר ל-1,000 בקשות יכול לקפוץ מ-5 ל-25 דולר (פרטי המחיר). - השתמשו בסינון בצד השרת (כמו
minRating,includedType,locationBias) כדי לא לבזבז קרדיטים על תוצאות לא רלוונטיות. - שמרו ערכי
place_idלדה-דופליקציה ולעדכונים עתידיים.
גישה 2: גריפת HTML של Google Maps (לשימוש לימודי/חד-פעמי)
אזהרה: Google Maps היא אפליקציית דף יחיד. חייבים להשתמש באוטומציה של דפדפן (Playwright או Selenium), וגריפת HTML עלולה להפר את תנאי Google. השתמשו בזה למחקר, לא לייצור.
שלב 1: התקנת Playwright והפעלת דפדפן
from playwright.sync_api import sync_playwright
import time, re
def scrape_maps(query, max_results=100):
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
ctx = browser.new_context(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
locale="en-US",
)
page = ctx.new_page()
page.goto("https://www.google.com/maps", timeout=60_000)
page.fill("#searchboxinput", query)
page.click('button[aria-label="Search"]')
page.wait_for_selector('div[role="feed"]')
feed = page.locator('div[role="feed"]')
prev = 0
while True:
feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
time.sleep(2)
count = page.locator('div[role="feed"] > div > div[jsaction]').count()
if count == prev or count >= max_results:
break
prev = count
if page.locator("text=You've reached the end of the list").count():
break
rows = []
cards = page.locator('div[role="feed"] > div > div[jsaction]')
for i in range(cards.count()):
c = cards.nth(i)
name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
rating_el = c.locator('span[role="img"]').first
raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
rating = float(m.group(1)) if m else None
reviews = int(m.group(2).replace(",", "")) if m else None
rows.append({"name": name, "rating": rating, "reviews": reviews})
browser.close()
return rows
טיפים:
- Google מחליפה אקראית את מחלקות ה-CSS כל כמה שבועות, כך שהקוד הזה עשוי להזדקק לעדכונים קבועים.
- השתמשו בעיכובים דמויי-אנוש והימנעו מגריפה מהירה מדי כדי להפחית את הסיכון לחסימה.
- לעולם אל תנסו לעקוף CAPTCHA או את מערכת SearchGuard של Google — זה עלול לחשוף אתכם לסיכון משפטי.
אל תגרפו בעיוורון: איך לכוון במדויק לנתונים שאתם צריכים
גריפת הכול היא מתכון לבזבוז זמן ולמאגרי נתונים מנופחים. הנה איך לכוון רק לנתונים החשובים:
- הפקת רשימות URL ממוקדות: השתמשו בפילטרים של Google Maps עצמה (קטגוריה, מיקום, דירוג, פתוח עכשיו) כדי לצמצם תוצאות לפני הגריפה.
- התאמת ביטויים מדויקת: חפשו סוגי עסקים או מילות מפתח מדויקות (למשל, “vegan bakery in Austin”).
- מסנני מיקום: ציינו עיר, שכונה או אפילו קואורדינטות ורדיוס לדיוק מירבי.
- סינון בצד השרת (API): השתמשו ב-
minRating,includedTypeו-locationBiasבגוף בקשת ה-API. - סינון בצד הלקוח (Python): אחרי הגריפה, השתמשו ב-pandas כדי לסנן עסקים עם דירוג מעל 4.0, יותר מ-50 ביקורות, או קטגוריות מסוימות.
דוגמה: סינון רק מסעדות במנהטן עם דירוג מעל 4.0
df = pd.DataFrame(results)
filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
filtered.to_csv("manhattan_top_restaurants.csv", index=False)
שימוש בספריות Python כדי לארגן ולייצא נתונים מ-Google Maps
אחרי שגרפתם את הנתונים, הגיע הזמן לנקות, לנתח ולייצא אותם לצוות שלכם.
ניקוי וארגון נתונים עם Pandas
import pandas as pd
df = pd.read_json("brooklyn_restaurants.json")
df = (
df.dropna(subset=["name", "address"])
.drop_duplicates(subset=["place_id"])
.assign(
name=lambda d: d["name"].str.strip(),
phone=lambda d: d["phone"].astype(str)
.str.replace(r"\D", "", regex=True)
.str.replace(r"^1?(\d{10})$", r"+1\1", regex=True),
rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
user_ratings_total=lambda d: pd.to_numeric(
d["user_ratings_total"], errors="coerce"
).fillna(0).astype("int32"),
)
)
ניתוח וסיכום של נתונים
דוגמה: דירוג ממוצע לפי שכונה
by_neighborhood = (
df.groupby("neighborhood", as_index=False)
.agg(avg_rating=("rating", "mean"),
n_places=("place_id", "nunique"),
median_reviews=("user_ratings_total", "median"))
.sort_values("avg_rating", ascending=False)
)
ייצוא ל-Excel או CSV
df.to_csv("brooklyn_top.csv", index=False)
df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")
יש לכם מאגרי נתונים גדולים? השתמשו בפורמט Parquet למהירות וליעילות בנפח:
df.to_parquet("brooklyn_top.parquet", compression="zstd")
Thunderbit: חלופה מבוססת AI ל-Google Maps Scraper ב-Python
עכשיו, אם אתם חושבים, “זה הרבה הגדרה בשביל רשימת לידים פשוטה,” אתם לא לבד. בדיוק בגלל זה בנינו את Thunderbit — Web Scraper ללא קוד, מבוסס AI, שהופך את חילוץ הנתונים מ-Google Maps (ומעוד מקורות רבים) לפשוט כמו כמה קליקים.
למה Thunderbit?
- בלי קוד ובלי מפתחות API: פשוט פותחים את תוסף Chrome של Thunderbit, נכנסים ל-Google Maps ולוחצים על “AI Suggest Fields”.
- זיהוי שדות מבוסס AI: ה-AI של Thunderbit קורא את הדף ומציע את העמודות הנכונות — שם, כתובת, דירוג, טלפון, אתר ועוד.
- גריפת תתי-עמודים: רוצים להעשיר את הטבלה עם נתונים מאתר האינטרנט של כל עסק? Thunderbit יכול לבקר בכל תת-עמוד ולמשוך מידע נוסף אוטומטית.
- ייצוא ל-Excel, Google Sheets, Airtable או Notion: לא צריך יותר להתעסק עם pandas — פשוט לוחצים “Export” והנתונים מוכנים לצוות.
- גריפה מתוזמנת: מגדירים משימות חוזרות כדי לעקוב אחרי מתחרים או לרענן את רשימת הלידים אוטומטית.
- אפס תחזוקה: ה-AI של Thunderbit מסתגל לשינויים באתר, כך שאתם לא נאלצים לתקן כל הזמן סקריפטים שבורים.
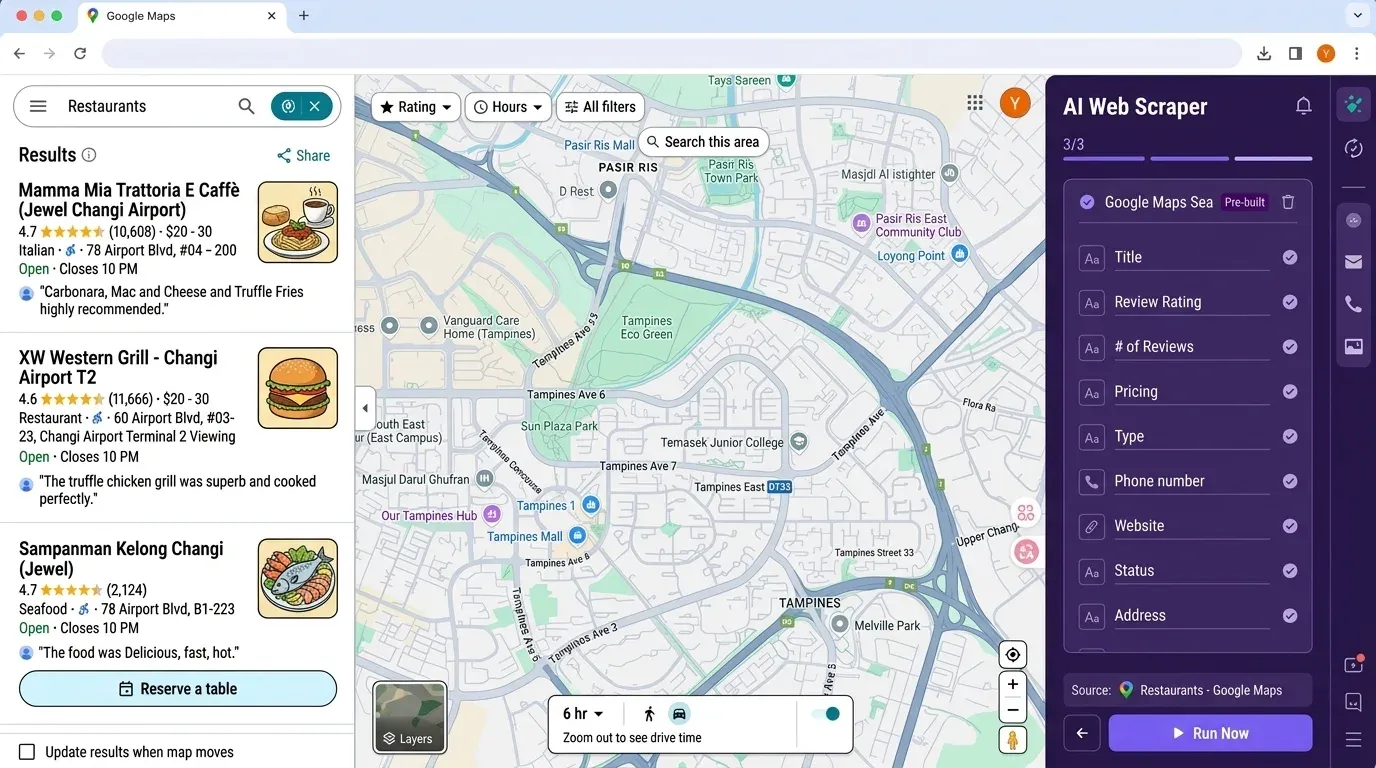
תהליך Thunderbit מול Python:
| שלב | Scraper ב-Python | Thunderbit |
|---|---|---|
| התקנת כלים | 30–60 דק׳ (Python, pip, ספריות) | 2 דק׳ (תוסף Chrome) |
| הגדרת מפתח API | 10–30 דק׳ (Cloud Console) | לא נדרש |
| בחירת שדות | קוד ידני, field masks | AI Suggest Fields (קליק אחד) |
| חילוץ נתונים | כתיבה/הרצה של סקריפטים, טיפול בשגיאות | לחיצה על “Scrape” |
| ייצוא | pandas ל-CSV/Excel | ייצוא ל-Excel/Sheets/Notion |
| תחזוקה | עדכונים ידניים לשינויים באתר | ה-AI מסתגל אוטומטית |
בונוס: Thunderbit זוכה לאמון של יותר מ-30,000 משתמשים ברחבי העולם, והשכבה החינמית מאפשרת לגרוף עד 6 דפים (או 10 עם תוספת ניסיון) ללא עלות.
שמירה על ציות: תנאי השימוש של Google Maps ואתיקת גריפה
כאן רוב המדריכים ל-Python כבר מסוכנים כי הם מיושנים. הנה מה שצריך לדעת בשנת 2026:
- תנאי השימוש של Google Maps Platform §3.2.3 אוסרים במפורש גריפה, שמירה במטמון או ייצוא של נתונים מחוץ ל-APIs הרשמיים (cloud.google.com). החריג היחיד: מותר לשמור ערכי latitude/longitude עד 30 יום; אפשר לשמור Place IDs ללא הגבלת זמן.
- משתמשי API כפופים לחוזה: אם השתמשתם במפתח API, הסכמתם לתנאי Google — גם אם אתם גורפים רק מידע ציבורי.
- עקיפת חסמים טכניים (CAPTCHA, SearchGuard) היא כעת הפרה פוטנציאלית של DMCA §1201, ויכולה לשאת עונשים פליליים (ppc.land).
- GDPR וחוקי פרטיות: אם אתם אוספים נתונים אישיים (מיילים, טלפונים, שמות כותבי ביקורות) מ-Google Maps, חייבת להיות לכם עילה חוקית וחובה לכבד בקשות מחיקה. ה-CNIL הצרפתי קנס את KASPR ב-200,000 אירו בשנת 2024 על גריפת אנשי קשר מ-LinkedIn (edpb.europa.eu).
- שיטות מומלצות:
- ברירת המחדל צריכה להיות Places API ככל האפשר.
- הגבילו קצב בקשות (≤10 QPS ל-API, 1–2 בקשות בשנייה לגריפת HTML).
- לעולם אל תעקפו CAPTCHA או חסימות טכניות.
- אל תפיצו מחדש נתונים אישיים שנגרפו.
- כבדו בקשות ביטול והסרה.
- תמיד בדקו את החוקים המקומיים — GDPR, CCPA ואחרים נאכפים בפועל.
השורה התחתונה: אם ציות מדאיג אתכם, הישארו עם ה-API וצמצמו את כמות הנתונים שאתם אוספים. עבור רוב המשתמשים העסקיים, כלי ללא קוד כמו Thunderbit מצמצם את רמת הסיכון (בלי מפתח API, בלי הפצה מחדש).
תזמון ואוטומציה של גריפת Google Maps עם Python
אם אתם צריכים לשמור על הנתונים טריים — למשל למעקב שבועי אחרי מתחרים או לעדכון חודשי של רשימות לידים — אוטומציה היא חברה טובה.
תזמון פשוט עם schedule
import schedule, time
from my_scraper import run_job
schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
while True:
schedule.run_pending()
time.sleep(30)
תזמון ברמת Production עם APScheduler
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.triggers.cron import CronTrigger
sched = BackgroundScheduler(timezone="America/New_York")
sched.add_job(
run_job,
CronTrigger(hour=3, minute=15, jitter=600), # 3:15 לפנות בוקר ± 10 דק׳
kwargs={"query": "restaurants in Brooklyn"},
id="brooklyn_daily",
max_instances=1,
coalesce=True,
misfire_grace_time=3600,
)
sched.start()
טיפים לאוטומציה בטוחה
- הוסיפו jitter אקראי ללוח הזמנים כדי להימנע מדפוסים צפויים.
- בגריפת HTML, לעולם אל תריצו יותר מ-1–2 בקשות בשנייה.
- בשימוש ב-API, עקבו אחרי המכסה והגדירו התראות חיוב.
- תמיד רשמו שגיאות ותחזקו קובץ “dead-letter” לבקשות שנכשלו.
בונוס Thunderbit: עם Thunderbit אפשר לתזמן גריפות חוזרות ישירות בממשק — בלי קוד, בלי cron jobs, בלי הגדרת שרת.
נקודות מפתח: חילוץ נתונים מ-Google Maps בצורה יעילה, ממוקדת ותואמת
נסכם את העיקר:
- Google Maps הוא המקור מספר 1 לנתוני מיקום עסקיים, ומניע הכול — מהפקת לידים ועד מחקר שוק.
- גריפה עם Python מציעה גמישות ושליטה, אבל מגיעה עם עלויות הגדרה, תחזוקה וציות — במיוחד כשאמצעי ההגנה של Google והאכיפה המשפטית מתחזקים.
- חילוץ מבוסס API הוא המסלול הבטוח והסקיילבילי ביותר עבור רוב הצוותים. תמיד השתמשו ב-field masks ובסינון בצד השרת כדי לשלוט בעלויות.
- גריפת HTML היא שברירית ומסוכנת — השתמשו בה רק למחקר חד-פעמי, ולעולם אל תעקפו חסמים טכניים.
- כוונו את הנתונים שלכם: השתמשו בהתאמת ביטויים, מסנני מיקום ותהליכי עבודה עם pandas כדי לחלץ רק את מה שאתם צריכים.
- Thunderbit הוא המסלול המהיר ביותר למי שלא מתכנת: מבוסס AI, בלי הגדרה, ייצוא מיידי ותזמון מובנה.
- ציות חשוב: כבדו את תנאי Google, חוקי הפרטיות ומגבלות הקצב כדי להימנע מבעיות משפטיות.
לעוד מדריכים וטיפים, היכנסו ל-Thunderbit Blog ול-ערוץ YouTube שלנו.
שאלות נפוצות
1. האם מותר לגרוף נתוני Google Maps עם Python בשנת 2026?
גריפה של Google Maps דרך ה-API הרשמי מותרת במסגרת התנאים של Google, כל עוד אתם מכבדים מכסות ולא מפיצים מחדש נתונים מוגבלים. גריפת HTML של Google Maps אסורה במפורש לפי תנאי השימוש של Google ויש בה סיכון משפטי, במיוחד אם עוקפים חסמים טכניים או אוספים נתונים אישיים ללא הסכמה. תמיד בדקו חוקים מקומיים (GDPR, CCPA וכו׳) והקפידו על שיטות עבודה טובות לציות.
2. מה ההבדל בין שימוש ב-Google Maps API לבין גריפת HTML מהאתר?
ה-API יציב, מוסדר ומיועד לחילוץ נתונים, אבל דורש מפתח API וכפוף למכסות ולעלויות. גריפת HTML משתמשת באוטומציה של דפדפן כדי לחלץ נתונים מהדף המעובד, אבל היא שברירית (כי האתר משתנה לעיתים קרובות), עלולה להפר תנאים, והיא מסוכנת יותר מבחינה משפטית. לרוב השימוש העסקי, ה-API הוא המסלול המומלץ.
3. כמה עולה לחלץ נתונים מ-Google Maps באמצעות Python בשנת 2026?
המחיר של Google Places API הוא לכל 1,000 בקשות, ונע בין 5 דולר (Essentials) ל-25 דולר (Enterprise+Atmosphere), תלוי בשדות שאתם מבקשים. יש ספי חינם חודשיים (10,000 ל-Essentials, 5,000 ל-Pro, 1,000 ל-Enterprise), אבל גריפה בקנה מידה גדול יכולה להצטבר מהר. תמיד השתמשו ב-field masks ובסינון בצד השרת כדי לשלוט בעלויות.
4. איך Thunderbit משתווה ל-Google Maps Scraper מבוססי Python?
Thunderbit הוא Web Scraper ללא קוד, מבוסס AI, שמאפשר לחלץ נתונים מ-Google Maps (ועוד הרבה מעבר) בלי תכנות, מפתחות API או תחזוקה. הוא אידיאלי לצוותי מכירות ושיווק שרוצים ייצוא מהיר ואמין ל-Excel, Google Sheets, Airtable או Notion. למשתמשים טכניים שצריכים לוגיקה מותאמת אישית, Python מציע יותר גמישות — אבל דורש יותר הגדרה וניהול ציות.
5. איך אפשר לאוטומט גריפת נתונים חוזרת מ-Google Maps?
עם Python, השתמשו בספריות תזמון כמו schedule או APScheduler כדי להריץ את ה-scraper במרווחים קבועים (יומי, שבועי וכו׳). הוסיפו jitter אקראי כדי להפחית זיהוי ועקבו אחרי מכסת ה-API שלכם. עם Thunderbit, אפשר לתזמן גריפות חוזרות ישירות בממשק — בלי קוד או הגדרת שרת.
מוכנים להפוך את Google Maps לזרוע העל שלכם במכירות ובשיווק? בין אם אתם חובבי Python או רוצים את הפתרון המהיר ביותר בלי קוד, הכלים כבר כאן בשנת 2026. נסו את Thunderbit לגריפה מיידית ומבוססת AI — או הפשילו שרוולים וצאו לדרך עם ה-API. כך או כך, שהרשימות שלכם יהיו טריות, הייצוא נקי, והקמפיינים מלאים בלידים מקומיים עם שיעורי המרה גבוהים. גריפה נעימה!
מידע נוסף




