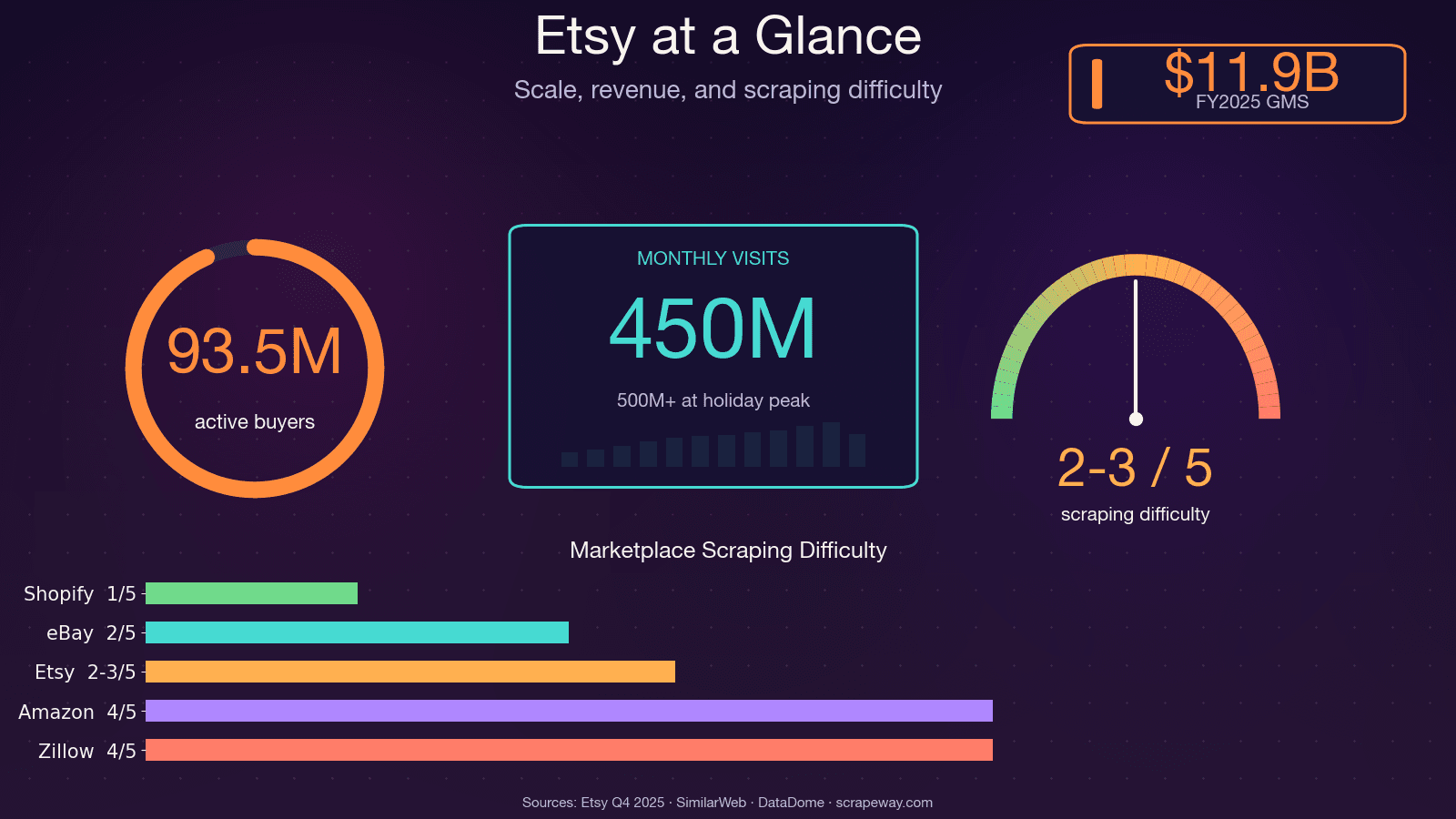
ל-Etsy יש יותר מ-100 מיליון רישומים פעילים, 5.6 מיליון מוכרים, וכ-450 מיליון ביקורים חודשיים. זה המון נתונים ציבוריים על תמחור, מגמות, ביקורות ומתחרים — ואם אי פעם ניסית לאסוף אותם ידנית, אתה כבר מכיר את הכאב.
פעם ביליתי סוף שבוע שלם בניסיון לקטלג ידנית מוצרי מתחרים עבור פרויקט מחקר שוק. כבר במוצר מספר 30 התחלתי לפקפק בכל החלטת חיים שהובילה אותי לגיליון האלקטרוני הזה. העניין הוא שנתוני Etsy הם בעלי ערך עצום לניתוח תמחור, פיתוח מוצרים, גילוי נישות והשוואת ביצועי מוכרים — אבל רק אם באמת אפשר להשיג אותם בהיקף גדול. על זה המדריך הזה מדבר: מדריך אחד שמסביר איך לגרוף נתונים מ-Etsy באמצעות Python בכל ארבעת סוגי הדפים המרכזיים (תוצאות חיפוש, דפי מוצר, דפי חנות וביקורות), לצד הסבר כן על ההגנות של Etsy נגד בוטים ואלטרנטיבה ללא קוד למי שמעדיף לוותר לגמרי על כתיבת סקריפטים.
מה זה אומר לגרוף את Etsy באמצעות Python?
גריפת אתרים, בפשטות, היא כתיבת קוד שנכנס לדפי אינטרנט ומחלץ אוטומטית את הנתונים שמעניינים אותך — שמות מוצרים, מחירים, תיאורים, תמונות, דירוגים, ביקורות, פרטי חנות — ומסדר אותם בפורמט מובנה כמו גיליון אלקטרוני או מסד נתונים.
Python היא השפה המועדפת לעבודה כזו. היא ידידותית למתחילים, יש לה קהילה עצומה, והיא מציעה מערכת ספריות עשירה במיוחד לגריפה: Requests (לשליפת דפים), BeautifulSoup (לפירוש HTML), Selenium ו-Playwright (לאוטומציה של דפדפן), ו-pandas (לארגון וייצוא נתונים). Python מדורגת באופן עקבי בין 3 השפות הפופולריות ביותר בסקר המפתחים השנתי של Stack Overflow, וספריות הגריפה שלה הן מהמורדות ביותר ב-PyPI.
כשאתה גורף את Etsy, אתה מחלץ נתונים מה-HTML (ולפעמים גם מ-JSON מוסתר) ש-Etsy שולחת לדפדפן שלך. סוגי הנתונים שאפשר לחלץ כוללים:
- שמות מוצרים, מחירים, תיאורים, תמונות ווריאציות
- פרטי מוכר/חנות (שם, כמות מכירות, מיקום, דירוג)
- דירוגים וטקסט מלא של ביקורות
- רישומי תוצאות חיפוש, קטגוריות וסימני מגמה
למה לגרוף את Etsy? מקרי שימוש אמיתיים שמייצרים החזר השקעה
גריפת Etsy היא לא רק תרגיל טכני — זו יתרון תחרותי. בין אם אתה מוכר, מנהל מוצר או אנליסט נתונים, גישה לנתוני Etsy מובנים יכולה להשפיע ישירות על השורה התחתונה.
| מקרה שימוש | מה גורפים | מי מרוויח | השפעה עסקית |
|---|---|---|---|
| ניתוח תמחור תחרותי | תוצאות חיפוש + מחירי מוצרים | תפעול מסחר אלקטרוני, מוכרים | תמחור דינמי יכול להעלות הכנסות בממוצע ב-5–22% |
| גילוי נישות ומגמות | תוצאות חיפוש, רישומים טרנדיים | מייסדים, אנליסטים | זיהוי מוקדם של נישות חמות (למשל, "preppy pajamas" צמחו ב-+1,112% בחיפושים) |
| פיתוח ושיפור מוצרים | ביקורות, פרטי מוצר | צוותי מוצר | מותג כלי מטבח אחד חזר למקום #1 של רב-המכר תוך 60 יום בעזרת נתוני סנטימנט של ביקורות |
| SEO ומחקר מילות מפתח | תוצאות חיפוש, כותרות/תגיות מוצר | צוותי שיווק | זיהוי מילות מפתח עם ביקוש גבוה ותחרות נמוכה |
| השוואת ביצועי מוכרים | דפי חנות, כמות מכירות | צוותי מכירות, אנליסטים | בניית רשימות לידים איכותיות ב-$0.01–0.10 לרשומה לעומת רשימות קנויות |
| מעקב מלאי ומלאי זמין | זמינות מוצרים | תפעול מסחר אלקטרוני | תגובה מהירה יותר לשינויים במלאי של מתחרים |
כל אחד ממקרי השימוש האלה דורש נתונים מסוגי דפים שונים ב-Etsy — ולכן בדיוק המדריך הזה מכסה את כולם.
חיסכון בזמן: ידני מול אוטומטי
- מחקר Etsy ידני: 30–45 דקות לכל מוצר (50–75 שעות עבור 100 מוצרים)
- גריפה אוטומטית: 100 רישומים ב-2–5 דקות
- גריפה מבוססת AI מהירה ב- ויכולה להגיע לדיוק של עד 99.5%
Etsy API מול גריפת אתרים: במה כדאי לבחור?
לפני שאתה כותב שורת קוד אחת, שווה לשאול: האם להשתמש ב-API הרשמי של Etsy או לגרוף את האתר ישירות? זו שאלה שאני רואה שוב ושוב בפורומים, והתשובה תלויה בנתונים שאתה צריך.
מה ה-API של Etsy יכול ומה הוא לא יכול לעשות
Etsy מציעה API v3 עם אימות OAuth 2.0. הוא מתאים לגישה לנתוני החנות שלך — רישומים, הזמנות, קבלות. אבל יש לו מגבלות אמיתיות:
- נתוני מתחרים: ה-API מוגבל בעיקר לחנות שלך. אי אפשר למשוך תמחור, מכירות או רישומים של מוכר אחר.
- ביקורות: אין endpoint חזק לטקסט מלא של ביקורות בכמות גדולה.
- מגבלות קצב: 10 בקשות/שנייה, 10,000 בקשות/יום כברירת מחדל. תקרת ה-offset היא 12,000 רשומות.
- שימוש ב-AI/ML: נדחה במפורש בסקירת האפליקציה.
- תיעוד: יש הרבה תלונות בקהילה — דוגמאות חלשות, endpoints שהוצאו משימוש, תמיכה איטית.
מתי גריפת אתרים היא המסלול הטוב יותר
אם אתה צריך מודיעין תחרותי, סנטימנט של ביקורות, ניתוח בין חנויות, או נתונים שמעבר למה שה-API חושף — גריפה היא הדרך. המחיר: תיתקל בהגנות של Etsy נגד בוטים (עוד על זה בהמשך), ותצטרך להשקיע בהקמה.
טבלת השוואה: API מול גריפה מול ללא קוד
| קריטריון | ה-API הרשמי של Etsy | גריפת אתרי Python | Thunderbit (ללא קוד) |
|---|---|---|---|
| גישה למחירי מוצרים | ✅ (שדות מוגבלים) | ✅ HTML/JSON-LD מלא | ✅ AI מחלץ כל שדה גלוי |
| נתוני ביקורות | ❌ לא זמין בכמות גדולה | ✅ דרך endpoint/HTML של ביקורות | ✅ גריפת תת-דפים |
| נתוני חנויות מתחרים | ❌ החנות שלך בלבד | ✅ כל חנות ציבורית | ✅ כל חנות ציבורית |
| נדרש אימות | ✅ OAuth 2.0 | ⚠️ עוגיות לנתונים אחרי התחברות | ⚠️ גריפת דפדפן להתחברות |
| סיכון לחסימה ע"י בוטים | אין | גבוה מאוד (DataDome) | מטופל (מקורי לדפדפן) |
| זמן הקמה | בינוני (מפתחות API, OAuth) | גבוה (קוד + פרוקסי) | כ-2 דקות |
אם אתה צריך נתוני מתחרים, ביקורות או ניתוח בין חנויות, ה-API פשוט לא מכסה את זה. זו התמונה הכנה.
בחר את גישת הגריפה ב-Python לפני שאתה כותב שורה אחת של קוד
שאלה שאני רואה כל הזמן ב-Reddit וב-Stack Overflow: "האם להשתמש ב-Requests + BeautifulSoup, ב-Selenium, בשירות Proxy API, או במשהו אחר לגמרי?" התשובה הנכונה תלויה ברמת המיומנות, בתקציב ובמקרה השימוש.
| גישה | הכי מתאים ל | עקומת למידה | תומך ב-JS? | טיפול נגד בוטים | עלות |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | מפתחים שרוצים שליטה מלאה | בינונית | ❌ | ידני (כותרות, פרוקסי) | חינם + עלויות פרוקסי |
| Selenium / Playwright | דפים כבדי JS, תהליכי התחברות | גבוהה | ✅ | חלקי (טביעת אצבע של דפדפן) | חינם + עלויות פרוקסי |
| שירותי Proxy API | קנה מידה + עקיפת אנטי-בוט | בינונית | ✅ (דרך API) | ✅ מובנה | החל מ-$49 לחודש |
| Thunderbit (ללא קוד) | לא-מפתחים, חילוץ מהיר | נמוכה מאוד | ✅ (מקורי לדפדפן) | ✅ (סשן דפדפן) | יש תכנית חינמית |
אם אתה רוצה שליטה מלאה ומרגיש בנוח עם Python, בחר ב-Requests + BeautifulSoup. אם צריך עיבוד JS או תהליכי התחברות, השתמש ב-Selenium. אם אתה צריך עקיפת אנטי-בוט בהיקף גדול, כדאי לשקול שירות פרוקסי. ואם אתה רוצה נתוני Etsy בלי לכתוב או לתחזק קוד, Thunderbit בהחלט שווה מבט — עוד על זה בהמשך.
איך Etsy נלחמת: הבנת ההגנה DataDome נגד בוטים
רוב מדריכי הגריפה יגידו לך "פשוט תשתמש בפרוקסי" וימשיכו הלאה. זה לא מספיק עבור Etsy. Etsy משתמשת ב-DataDome, אחת ממערכות ההגנה האגרסיביות ביותר נגד בוטים באינטרנט. מציג את Etsy כסיפור הצלחה, ומציין שפעם סקרייפרים היו אחראים לכ-1% מעלויות המחשוב של Etsy.
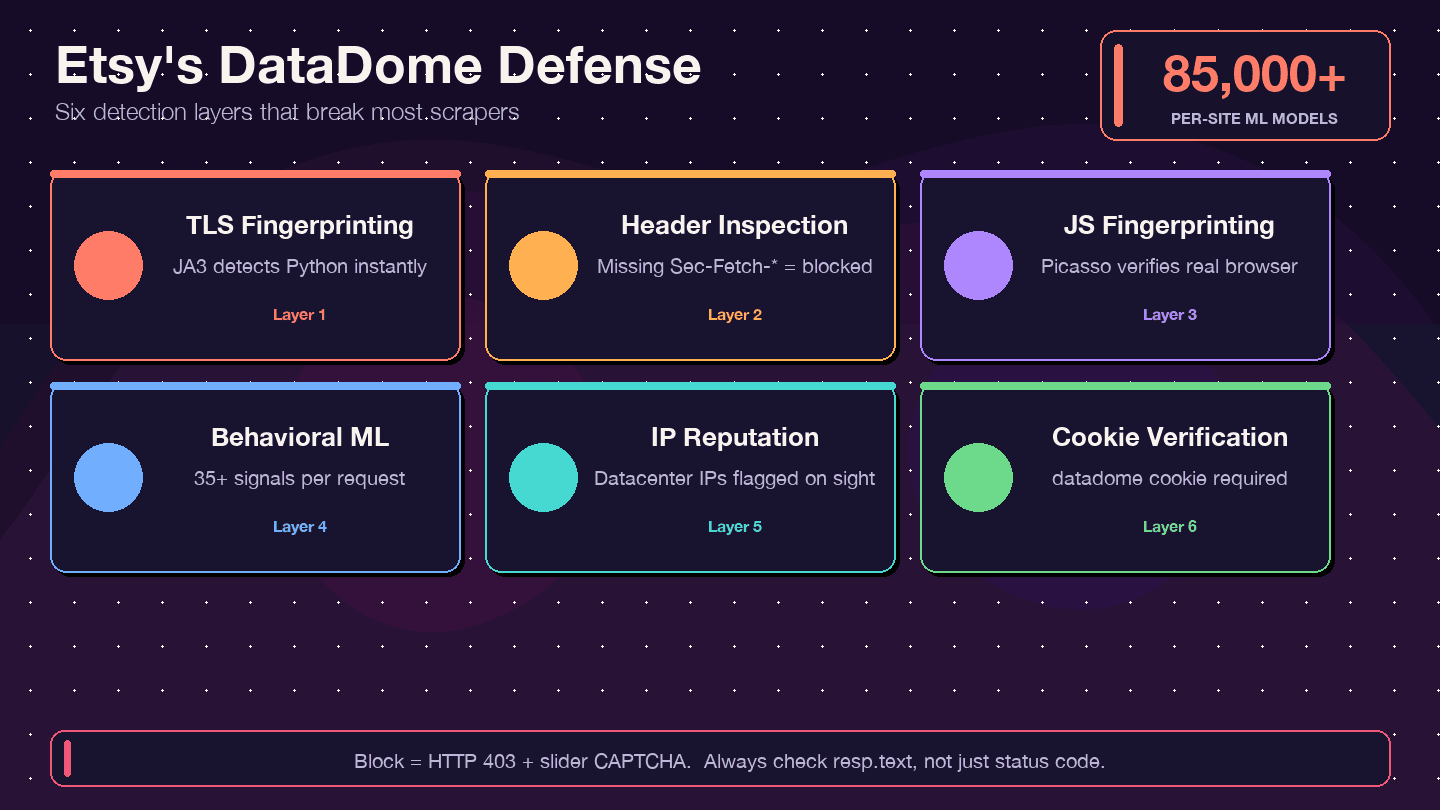
מה זה DataDome ואיך זה עובד?
DataDome לא בודק רק את כתובת ה-IP שלך. הוא מפעיל שכבת זיהוי מרובת-רמות:
- טביעת אצבע של TLS (JA3): ספריית
requestsשל Python כוללת חתימת TLS ייחודית ש-DataDome יכול לזהות מיד. - בדיקת כותרות/פרוטוקול HTTP: בודקת כותרות דפדפן מלאות ועקביות — כותרות חסרות או מסודרות לא נכון הן דגל אדום.
- טביעת אצבע של JavaScript (פרוטוקול Picasso): מריץ אתגרי JS בדפדפן כדי לוודא שאתה משתמש אמיתי.
- למידת מכונה התנהגותית: מנתחת יותר מ-35 אותות לכל בקשה, עם יותר מ-85,000 מודלים לכל אתר.
- ניקוד מוניטין IP: כתובות IP של Data Center מסומנות מיד.
- אימות עוגיות: עוגיית
datadomeחייבת להיות קיימת ותקפה.
סימנים שנחסמת (ואיך לבדוק את זה)
אחת התקלות הנפוצות ביותר: אתה מקבל תשובת 200 OK, אבל ה-HTML הוא למעשה עמוד CAPTCHA, לא הנתונים שרצית. סימנים נוספים:
- שגיאות 403 Forbidden
- לולאות הפניה
- גוף התגובה מכיל אובייקט JavaScript בשם
ddאו HTML של CAPTCHA עם סליידר
תמיד בדוק את גוף התגובה, לא רק את קוד הסטטוס. בדיקה מהירה:
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("נחסמת! התקבל עמוד CAPTCHA במקום נתונים.")כותרות ועוגיות שמפחיתות זיהוי
אי אפשר להבטיח שלא תיחסם, אבל כותרות ריאליסטיות וניהול עוגיות עושים הרבה:
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "en-US,en;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '"Chromium";v="133", "Not-A.Brand";v="99", "Google Chrome";v="133"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '"Windows"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})עוד דברים חשובים:
- שמור עוגיות בין בקשות באמצעות
requests.Session(). - הוסף השהיות אקראיות (2–7 שניות) בין בקשות.
- חמֵה שרשרת הפניות: בקר קודם בדף הבית, אחר כך בחיפוש, ואז בדפי מוצר.
- בהיקפים גדולים, רוטציה של פרוקסי residential היא קריטית. כתובות IP של Data Center מסומנות כמעט מיד.
הטכניקות האלה מפחיתות זיהוי, אבל לא מבטלות אותו. לגריפה בנפח גבוה, סביר שתצטרך שירות פרוקסי או גישה מבוססת דפדפן.
הגדרת סביבת Python שלך לגריפת Etsy
לפני שמתחילים:
- רמת קושי: בינונית
- זמן נדרש: כ-30–60 דקות (הקמה + גריפה ראשונה)
- מה צריך: Python 3.8+, pip, עורך קוד, דפדפן Chrome (לבדיקת DevTools)
התקנת תלויות
צור תיקיית פרויקט, הגדר סביבה וירטואלית, והתקן את הספריות שתצטרך:
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # ב-Windows: venv\Scripts\activate
4pip install requests beautifulsoup4 lxml pandas- requests — שולפת דפי אינטרנט
- beautifulsoup4 — מפרשת HTML
- lxml — מנתח HTML מהיר יותר (אופציונלי אך מומלץ)
- pandas — מבנה וייצוא נתונים ל-CSV/Excel
אם תצטרך מאוחר יותר אוטומציה של דפדפן (להתחברות או לדפים כבדי JS), התקן גם:
1pip install seleniumלהבין את מבנה הדפים של Etsy לפני שכותבים קוד
הנה טיפ שחוסך המון זמן: Etsy מטמיעה נתוני מוצר מובנים בתוך תגי <script type="application/ld+json"> ברוב הדפים. נתוני JSON-LD האלה כבר מאורגנים — שם מוצר, מחיר, דירוג, תמונות — כך שלא צריך להיאבק בכל שדה עם CSS selectors שבירים.
פתח כל דף מוצר ב-Etsy, קליק ימני, "View Page Source", וחפש application/ld+json. תמצא בלוק עם @type: Product שמכיל את רוב הנתונים שאתה צריך. דפי תוצאות חיפוש כוללים @type: ItemList.
CSS selectors עדיין שימושיים כגיבוי (לנתונים שלא נמצאים ב-JSON-LD, כמו פרטי משלוח או טקסט של ביקורות), אבל JSON-LD צריך להיות התחנה הראשונה שלך.
שלב 1: גריפת תוצאות חיפוש של Etsy באמצעות Python
תוצאות חיפוש הן נקודת ההתחלה של רוב פרויקטי הגריפה ב-Etsy — בין אם אתה עוקב אחרי נישה, בודק תמחור של מתחרים או בונה מסד נתונים של מוצרים.
בניית כתובת ה-URL לחיפוש
כתובות החיפוש של Etsy פועלות לפי המבנה הזה:
1https://www.etsy.com/search?q=\{keyword\}&ref=pagination&page=\{page_number\}במונחים מרובי מילים, קודד את הרווחים ב-URL (למשל, handmade+jewelry או handmade%20jewelry). הפרמטר ref=pagination גורם לבקשה להיראות יותר כמו ניווט אמיתי בדפדפן.
פרמטרים שימושיים נוספים: order (most_relevant, price_asc, price_desc, date_desc), min_price, max_price, ship_to, free_shipping=true. כל דף מחזיר 48 פריטים.
שליחת הבקשה וניתוח ה-HTML
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"נחסמת בדף \{page\}. נסה להוסיף השהיות או פרוקסי.")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_productsחילוץ נתוני רישום מ-JSON-LD
המערך itemListElement נותן לך את שם כל רישום, ה-URL, התמונה, המחיר והמטבע. אם אתה גם צריך דירוגי כוכבים או מספר תוצאות (לא תמיד ב-JSON-LD), עבור ל-CSS selectors:
- כרטיס רישום:
.v2-listing-card - כותרת:
h3.v2-listing-card__title - מחיר:
span.currency-value - קישור:
a.listing-link(href)
טיפול בדפדוף בין דפים
לולאה דרך הדפים והוסף השהיה אקראית בין כל בקשה. Etsy בדרך כלל מחזירה עד 20–250 דפים, תלוי בשאילתה.
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"נגרפו {len(results)} מוצרים.")בגריפה של 5 דפים, זה לקח בערך 20 שניות בבדיקה שלי — לעומת 30+ דקות של העתק-הדבק ידני.
שלב 2: גריפת דפי מוצר של Etsy באמצעות Python
אחרי שיש לך רשימת כתובות של מוצרים מתוצאות החיפוש, השלב הבא הוא למשוך נתונים מפורטים מכל דף רישום.
שליפת דף המוצר
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return Noneטיפול בווריאציות מחיר
לחלק מהמוצרים יש offers.price יחיד. אחרים (עם ווריאציות כמו מידה או צבע) משתמשים ב-offers.lowPrice וב-offers.highPrice. הקוד למעלה מטפל בשניהם על ידי נפילה מ-price ל-lowPrice.
ניתוח שדות נוספים באמצעות CSS selectors
לנתונים שלא נמצאים ב-JSON-LD — פרטי משלוח, אפשרויות וריאציה, פרטי מוכר מלאים — תצטרך CSS selectors:
- כותרת:
h1[data-buy-box-listing-title] - וריאציות:
select[data-selector-id]אוdiv[data-option-set] - משלוח:
div.wt-text-captionליד אזור המשלוח
הפשרה: JSON-LD נקי ויציב יותר לאורך שינויי פריסה. CSS selectors שבירים יותר אבל מכסים יותר שדות.
שלב 3: גריפת דפי חנות Etsy באמצעות Python
זה החלק שרוב מדריכי המתחרים מדלגים עליו לגמרי — ובצדק אפשר לטעון שזה הנתון היקר ביותר עבור צוותי מכירות ואנליסטים תחרותיים.
בניית כתובת ה-URL של החנות ושליפת הדף
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # מטא-נתונים של החנות מה-HTML (לא ב-JSON-LD)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # רישומים מ-JSON-LD
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_dataמה אפשר לחלץ מדפי חנות
ה-JSON-LD בדפי חנות הוא @type: ItemList — הוא מכסה את רישומי המוצרים, אבל לא מטא-נתונים ברמת החנות כמו כמות מכירות, מיקום או דירוג. בשביל אלה צריך CSS selectors:
| נקודת נתון | Selector | הערות |
|---|---|---|
| שם החנות | h1 או meta title | בדרך כלל בכותרת הדף |
| סך המכירות | div.shop-sales-reviews a | טקסט כמו "12,345 sales" |
| דירוג כוכבים | ערך של input[name="initial-rating"] | מספרי 1–5 |
| מיקום | div.shop-location | עיר, מדינה |
| מועד הצטרפות | div.shop-info | טקסט של תאריך |
נתוני חנות הם בעלי ערך ייחודי לבניית רשימות לידים, השוואת ביצועים מול מתחרים או זיהוי מוכרים מובילים בנישה.
שלב 4: גריפת ביקורות Etsy באמצעות Python
ביקורות הן בין הנתונים היקרים ביותר — וגם המאתגרים ביותר — ב-Etsy. טקסט הביקורת המלא, הדירוגים והתאריכים לא נמצאים ב-HTML הראשוני של הדף; הם נטענים דרך endpoint פנימי של API.
גישה 1: איתור ה-API הפנימי של הביקורות ב-Etsy
פתח דף מוצר ב-Chrome, פתח DevTools (F12), עבור ללשונית Network, וגלול למטה לאזור הביקורות. תראה בקשת POST לכתובת כמו:
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviewsה-endpoint הזה מחזיר מקטעי HTML שמכילים את כרטיסי הביקורות. כדי להשתמש בו, צריך:
- listing_id — המזהה המספרי מכתובת ה-URL של המוצר
- shop_id — חילוץ מתוך HTML של דף המוצר בעזרת regex
- csrf_nonce — חילוץ מתג
<meta>בדף
חילוץ מזהים ו-Token של CSRF
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrfגריפת ביקורות עם דפדוף
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviewsגישה 2: ניתוח ביקורות מה-HTML (גיבוי)
אם גישת ה-API נכשלת (למשל בגלל בעיות ב-Token של CSRF), אפשר לנתח את קבוצת הביקורות הראשונה ישירות מ-HTML של דף המוצר. המגבלה: רק האצווה הראשונית של הביקורות נמצאת ב-HTML הסטטי. לעוד, צריך את ה-API או כלי אוטומציה כמו Selenium.
טיפול בנתונים שדורשים התחברות: גריפת חנות Etsy שלך
זו פער שאף מדריך אחר לא מכסה, אבל זו דרישה אמיתית — במיוחד למוכרי Etsy שרוצים לחלץ הזמנות, הכנסות וסטטיסטיקות משלהם.
הבעיה: requests בלבד לא יכול לגשת לדשבורד של Etsy כי הוא לא נושא את עוגיות סשן ההתחברות שלך.
אפשרות 1: Selenium עם התחברות ידנית ולכידת עוגיות
השתמש ב-Selenium כדי לפתוח דפדפן, להתחבר ידנית (או לאוטומט את ההתחברות), ואז להמשיך לגרוף בזמן שאתה מזוהה:
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# התחבר ידנית בחלון הדפדפן, ואז:
5input("לחץ Enter אחרי ההתחברות...")
6cookies = driver.get_cookies()
7# עכשיו אפשר להשתמש ב-driver.get() כדי לנווט לדפי הדשבורד ולגרוףאפשר גם לשמור עוגיות מסשן Selenium ולהשתמש בהן מחדש עם requests.Session() לגריפה מהירה וקלה יותר אחרי ההתחברות הראשונית.
אפשרות 2: ייצוא עוגיות מהדפדפן לשימוש עם Requests
השתמש בתוסף דפדפן (כמו "EditThisCookie") כדי לייצא את עוגיות סשן Etsy הפעיל שלך, ואז טען אותן לתוך סשן Requests:
1import requests
2session = requests.Session()
3# הוסף עוגיות שיוצאו מהדפדפן
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ... הוסף עוגיות סשן נוספות לפי הצורך
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)המסלול הקל: מצב גריפת הדפדפן של Thunderbit
מכיוון ש- פועל בתוך דפדפן Chrome שלך, הוא יורש אוטומטית את סשן Etsy הפעיל שלך. בלי קוד אימות, בלי ייצוא עוגיות — פשוט נווט לדשבורד של Etsy וגרוף. זה באמת שימושי לחילוץ הזמנות, הכנסות, סטטיסטיקות ונתונים אחרים שרק מוכרים רואים, בלי שום סקריפט.
ייצוא ושימוש בנתוני Etsy שגרפת
שמירה ל-CSV או JSON
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)שיטות מומלצות: לכלול חותמות זמן בשם הקובץ, להשתמש בקידוד UTF-8, ולטפל בתווים מיוחדים בשמות מוצרים (מוכרי Etsy אוהבים אימוג'ים ותווים עם סימנים דיאקריטיים).
ייצוא ל-Google Sheets, Airtable או Notion
עבור משתמשי Python, ספריות כמו gspread (Google Sheets) או ה-API של Airtable מאפשרות לדחוף נתונים בתכנות. אבל אם אתה משתמש ב-, כל הייצוא — ל-Google Sheets, Excel, Airtable ו-Notion — חינמי ובקליק אחד. בלי מפתחות API, בלי הגדרת OAuth.
דלג על הקוד: איך לגרוף Etsy עם Thunderbit (אלטרנטיבה ללא קוד)
לא כולם רוצים לכתוב סקריפטי Python, לתחזק הגדרות פרוקסי או לדבג CSS selectors ב-2 בלילה. אם זה אתה, הנה איך לקבל נתונים מ-Etsy עם .
התקנת תוסף Chrome של Thunderbit
עבור אל והתקן את Thunderbit. צור חשבון חינמי — התכנית החינמית נותנת , וכל הייצוא חינם.
להשתמש ב-AI Suggest Fields בכל דף Etsy
נווט לדף חיפוש, מוצר או חנות ב-Etsy. לחץ על "הצעת שדות באמצעות AI" בסרגל הצד של Thunderbit. ה-AI סורק את הדף וממליץ על עמודות — שם מוצר, מחיר, דירוג, תמונות, שם חנות, תגיות, פרטי משלוח. התאם או הוסף עמודות לפי הצורך.
לחיצה על Scrape וייצוא
לחץ על "גריפה" כדי לחלץ נתונים מהדף הנוכחי. עבור תוצאות מרובות דפים, השתמש בגריפת הדפדוף של Thunderbit. כדי להעשיר רשימת כתובות URL של מוצרים בפרטים מכל דף מוצר (תיאורים, ביקורות, משלוח), השתמש ב-גריפת תת-דפים — Thunderbit מבקר בכל קישור ושולף את הנתונים הנוספים אוטומטית.
ייצוא ל-Excel, Google Sheets, Airtable או Notion — הכול בחינם.
מתי Thunderbit מנצח את Python לגריפת Etsy
- אין צורך בהגדרת פרוקסי או בקוד אנטי-בוט. Thunderbit רץ בתוך דפדפן Chrome האמיתי שלך, כך שהוא יורש את הסשן שלך ונראה ל-DataDome כמו משתמש רגיל.
- AI מסתגל אוטומטית לשינויים בפריסה. אין selectors שבורים שצריך לתקן כש-Etsy מעדכנת את ה-frontend שלה.
- מצוין למחקר חד-פעמי, ניתוח תחרותי או חברי צוות לא טכניים. אם אתה רק צריך סט נתונים מהיר, אין צורך בסביבת Python.
- גריפת תת-דפים מאפשרת להעשיר רשימת כתובות URL של מוצרים בנתונים מפורטים בלי לכתוב לולאות מקוננות.
להדרכה מלאה, בדוק את .
השוואת עלויות ל-6 חודשים: Python מול Thunderbit
| גורם | Python בעצמך | Thunderbit |
|---|---|---|
| זמן הקמה | 8–20 שעות | פחות מ-5 דקות |
| עלות ל-6 חודשים (כולל עבודה ופרוקסי) | $2,720–9,450 | $90–228 |
| תחזוקה חודשית | 4–10+ שעות (עדכוני selectors = יותר מ-80% תקורה) | 0–1 שעות |
| טיפול נגד בוטים | פרוקסי residential בעלות אשראי פי 85 מהרגיל | מבוסס דפדפן, עוקף באופן טבעי את DataDome |
| איכות נתונים | גבוהה (עם מאמץ) | גבוהה (מונעת AI) |
אני לא אומר ש-Python היא הבחירה הלא נכונה — אם אתה צריך שליטה מלאה, לוגיקה מותאמת אישית או אינטגרציה לצינור עבודה גדול יותר, קוד הוא המלך. אבל עבור רוב משתמשי העסק שרק צריכים נתוני Etsy, חישוב ה-ROI נוטה לכיוון כלי ללא קוד.
טיפים משפטיים ואתיים לגריפת Etsy
שואלים אותי על חוקיות בכל פוסט בנושא גריפה, אז הנה הגרסה הקצרה:
- תנאי השימוש של Etsy אוסרים במפורש גישה אוטומטית. עם זאת, Etsy נשענת על אכיפה טכנית (DataDome) ולא על ליטיגציה — לא מוכרות תביעות ספציפיות נגד סקרייפרים שקשורות ל-Etsy.
- גרוף רק נתונים הזמינים לציבור. אל תעקוף אימות ואל תיגש לדשבורדים פרטיים של מוכרים שאינם שלך.
- השתמש בקצב בקשות סביר. השהיות של 2–7 שניות בין בקשות, ואל תעמיס על השרתים של Etsy.
- כבד את
robots.txt. Etsy מאפשרת דפי חיפוש אבל מגבילה חלק מהנתיבים. - טפל בנתונים אישיים באחריות תחת חוקי פרטיות כמו GDPR.
- התייעץ עם ייעוץ משפטי בפרויקטי גריפה מסחריים בהיקף גדול.
למידע נוסף, ראה את הפוסט שלנו על — כולל Meta נגד Bright Data (2024), שבו אושרה גריפת נתונים ציבוריים.
סיכום: תובנות מפתח
כיסינו כאן הרבה מאוד. הנה מה שאני רוצה שתיקח איתך:
- הנתונים המובנים ב-JSON-LD של Etsy הופכים את החילוץ לנקי יותר מניתוח HTML גולמי ברוב השדות.
- DataDome הוא מכשול אמיתי — השתמש בכותרות נכונות, השהיות, ניהול עוגיות ופרוקסי residential לגריפת Python בהיקף גדול.
- ה-API של Etsy מוגבל. אם אתה צריך ביקורות, חנויות מתחרים או ניתוח בין מוכרים, גריפה היא המסלול המעשי.
- Thunderbit מציע חלופה ללא קוד שמטפלת באנטי-בוט ובאימות באופן מקורי — שווה לנסות אם אתה רוצה נתוני Etsy בלי לתחזק סקריפטים.
- תמיד גרוף באחריות וכבד את תנאי Etsy.
אם אתה רוצה להתחיל בלי לכתוב קוד, . או השתמש בקוד Python מהמדריך הזה כדי לבנות סקרייפר מותאם אישית משלך — ושלעולם לא יישברו לך ה-selectors ביום שישי אחר הצהריים.
לעוד מדריכי גריפה, בדוק את ואת האוסף .
שאלות נפוצות
1. האם חוקי לגרוף את Etsy באמצעות Python?
גריפת נתונים הזמינים לציבור היא בדרך כלל מותרת לפי תקדימים משפטיים עדכניים (למשל, Meta נגד Bright Data, hiQ נגד LinkedIn). עם זאת, תנאי השימוש של Etsy אוסרים גישה אוטומטית, לכן תמיד בדקו את תנאי השימוש ואת robots.txt שלהם לפני הגריפה. לשימוש מסחרי או בהיקף גדול, כדאי להתייעץ עם ייעוץ משפטי.
2. האם אפשר לגרוף את Etsy בלי להיחסם?
Etsy משתמשת ב-DataDome, אחת ממערכות ההגנה הקשות ביותר נגד בוטים. כותרות ריאליסטיות, השהיות בין בקשות, שמירת עוגיות ורוטציה של פרוקסי residential עוזרות להפחית חסימות. הגישה של Thunderbit, שפועלת מתוך הדפדפן, עוקפת את רוב הזיהוי כי היא פועלת בתוך סשן Chrome האמיתי שלך.
3. האם ל-Etsy יש API שאפשר להשתמש בו במקום גריפה?
כן — Etsy מציעה API v3, אבל הוא מוגבל בעיקר לנתוני החנות שלך וחסר גישה חזקה לביקורות. רוב מקרי השימוש של מודיעין תחרותי וניתוח בין חנויות דורשים גריפה.
4. אילו ספריות Python צריך כדי לגרוף את Etsy?
לפחות: requests, beautifulsoup4, pandas (לייצוא), ו-json (מובנה). עבור דפים כבדי JS או דפים שדורשים התחברות, הוסף selenium. לניתוח HTML מהיר יותר, השתמש ב-lxml.
5. איך גורפים ביקורות Etsy ספציפית?
ביקורות של Etsy נטענות דרך endpoint פנימי של API (/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews). צריך לחלץ את מזהה הרישום, מזהה החנות ו-Token ה-CSRF מדף המוצר, ואז לשלוח POST ל-endpoint עם דפדוף. כגיבוי, אפשר לנתח את האצווה הראשונה של הביקורות מה-HTML של דף המוצר — שני המסלולים מוסברים שלב-אחר-שלב במדריך הזה.
למידע נוסף