רוב המדריכים לגרידת eBay מחזיקים מעמד בערך שלושה חודשים. אני יודע, כי הצוות שלנו ב-Thunderbit ראה מפתחים עוברים שוב ושוב בין קטעי קוד שבורים, סלקטורי CSS מיושנים ו-repos ב-GitHub ש"עבדו" — עד ששתי רענוני עיצוב של eBay אחרי זה הם כבר הפסיקו לעבוד בשקט.
eBay יושב על — מאגר נתוני המחירים הארוך-זנב הגדול ביותר באינטרנט הפתוח אחרי Amazon. הנתונים האלה מזינים הכול, מתמחור של משווקים מחדש ועד מודיעין תחרותי. אבל הגישה אליהם בצורה תוכנית היא מטרה נעה: הממשק של eBay מבוסס React ומשנה שמות של מחלקות CSS, ניסויי A/B מציגים מבני DOM שונים למשתמשים שונים, ובאמצע עומד Akamai Bot Manager וחוסם את הדרך אל ה-HTML. המדריך הזה נותן לכם קוד Python שעובד היום, מסביר למה סקרייפרים נשברים כדי שתוכלו לבנות כאלה עמידים יותר, עובר בכנות על ההחלטה בין eBay API לגרידה, ומראה גם מסלול ללא קוד כש-Python פשוט לא מצדיק את ההקמה.
מה זה אומר לגרד את eBay עם Python?
גרידת eBay עם Python פירושה כתיבת סקריפטים שמורידים באופן תוכני דפי eBay, מנתחים את ה-HTML (או JSON מוסתר), ומחלצים נתונים מובנים — כותרות, מחירים, פרטי מוכר, תאריכי מכירה, פרטי וריאציות — לפורמט שאפשר באמת לעבוד איתו, כמו CSV, גיליון אלקטרוני או מסד נתונים.
אפשר לגרד כמה סוגי דפים ב-eBay:
- תוצאות חיפוש (למשל כל המודעות של "AirPods Pro")
- דפי מוצר בודדים (מפרט מלא, תמונות, פרטי מוכר)
- מכירות שהושלמו / פריטים שנמכרו (מחירי עסקה ותאריכים בפועל)
- פרופילים של מוכרים וביקורות
Python הוא לרוב הבחירה הטבעית למשימה הזו. המערכת האקולוגית שלו — Requests, BeautifulSoup, lxml, pandas — הופכת שליפה, ניתוח HTML ועיבוד נתונים לפשוטים יחסית. עם זאת, יש הבדל משמעותי בין גרידת ה-HTML של האתר לבין שימוש ב-API הרשמי של eBay — וזה משהו שאכסה מיד בהמשך.
למה בכלל לגרד את eBay? שימושים עסקיים מהעולם האמיתי
אם אתם קוראים את זה, כנראה כבר יש לכם סיבה. ובכל זאת, חשוב לעגן את הדיון בערך עסקי ממשי, כי ה-ROI של נתוני eBay באמת מרשים. Bain מצאה ששיפור של לאורך אלפי עסקים. McKinsey מייחסת ל- בקמעונאות.
השימושים הנפוצים ביותר שאני רואה:
| שימוש | הנתונים הדרושים | התועלת העסקית |
|---|---|---|
| ניטור מחירים והתאמת תמחור | מחירי מודעות פעילות, משלוח, מצב מוצר | תמחור תחרותי, הגנה על המרווח |
| ניתוח מתחרים | מבחר מוצרים, מבצעים, תנאי משלוח | מיצוב אסטרטגי, זיהוי פערים במבחר |
| מחקר שוק וזיהוי מגמות | קצב הופעת מודעות, מגמות בקטגוריה, דפוסי ביקוש | זיהוי מוצרים חדשים, תחזית ביקוש |
| תמחור למשווקים מחדש / הערכות שווי | מחירי מכירה, תאריכי מכירה, מצב מוצר | ערך שוק הוגן, החלטות קנייה |
| ניתוח סנטימנט | ביקורות, דירוגים, מדיניות החזרות | תובנות על איכות מוצר, שביעות רצון לקוחות |
| יצירת לידים | פרופילי מוכרים, מידע על חנות, פרטי קשר | פנייה עסקית למוכרים עם GMV גבוה |
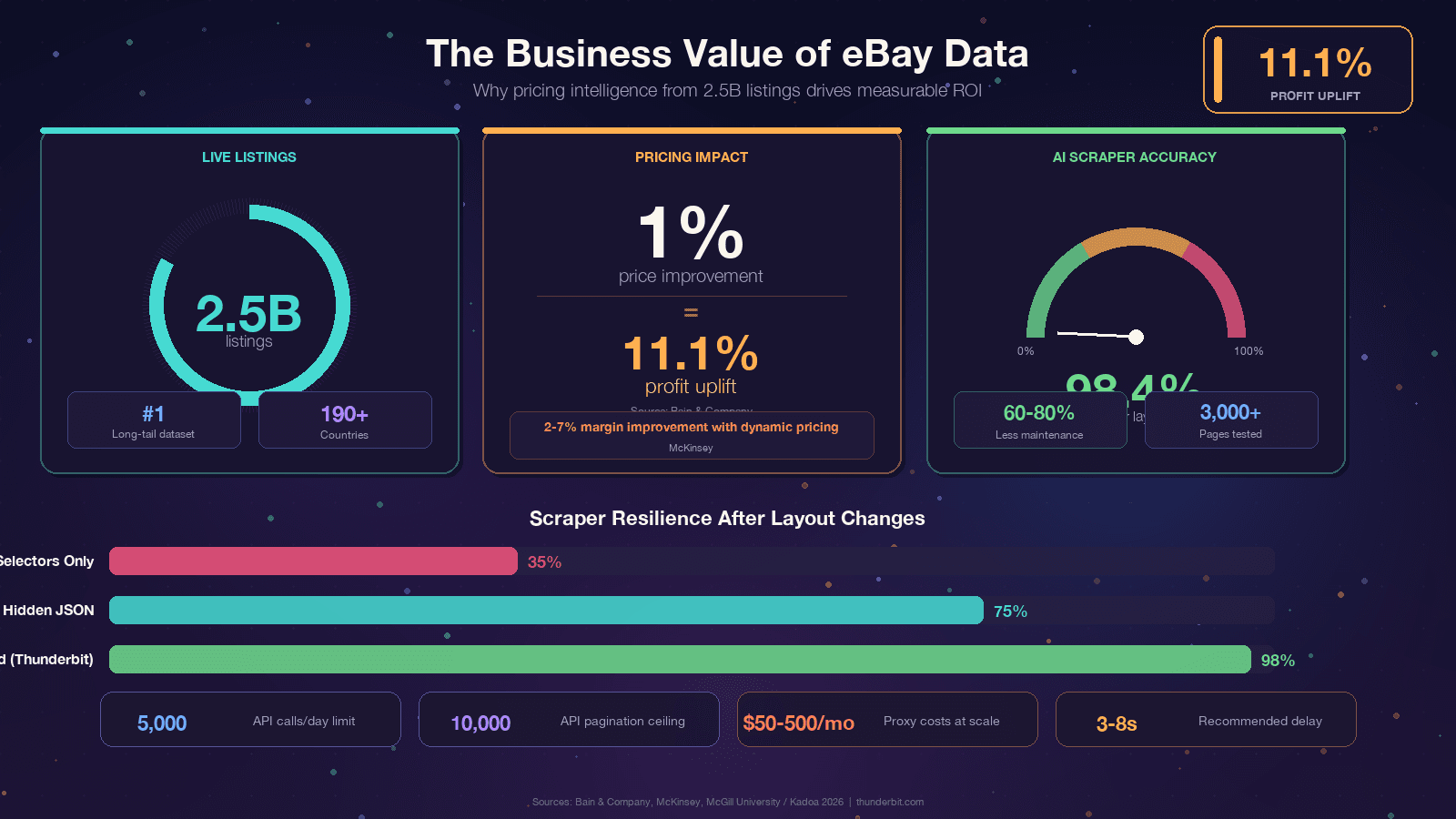
המכנה המשותף: הנתונים קיימים ב-eBay, אבל הם נעולים בתוך דפי אינטרנט.
גרידה היא הדרך להפוך אותם ליתרון תחרותי.
API רשמי של eBay מול גרידת Python: במה כדאי לבחור?
זו השאלה שהייתי רוצה שיותר מדריכים יענו עליה בכנות. eBay מציע APIs רשמיים — בעיקר את — ומשתמשים רבים תוהים אם עדיף להשתמש בהם או לגרד ישירות. התשובה תלויה לחלוטין בנתונים שאתם צריכים.
| קריטריון | eBay Browse/Finding API | גרידת Web ב-Python |
|---|---|---|
| פריטים שנמכרו / הושלמו | מוגבל — קיים Marketplace Insights API אבל הגישה אליו נדחית לעיתים קרובות | גישה מלאה דרך פרמטרי URL כמו LH_Sold=1&LH_Complete=1 |
| מגבלות קצב | 5,000 קריאות ביום ברמה הבסיסית | מנוהל בעצמכם (תלוי פרוקסי) |
| שדות נתונים | מוגדרים מראש (כותרת, מחיר, קטגוריה, פרטי מוכר בסיסיים) | כל מה שרואים בדף (ביקורות, מפרט מלא, מטריצת וריאציות) |
| מורכבות התקנה | OAuth 2.0, רישום אפליקציה, מפתחות API | pip install + קוד |
| יציבות | נקודות קצה יציבות | נשבר כשה-HTML משתנה |
| עלות | יש שכבה חינמית, בתשלום לנפח | קוד חינמי, אבל עלות פרוקסי בקנה מידה גדול |
| נתוני וריאציות / MSKU | חלקי — לעיתים קרובות רק SKU הורה | מלא (דרך ניתוח JSON מוסתר) |
| עומק עימוד | תקרת קשיח של 10,000 פריטים | תיאורטית ללא הגבלה |
הערה קצרה: ה-Finding API הישן (שכלל findCompletedItems) . אם אתם משתמשים ב-ebaysdk-python או בכל ספרייה שפונה למודול Finding, היא כרגע שבורה בפרודקשן.
ההמלצה שלי: השתמשו ב-Browse API עבור שאילתות יציבות, מובנות ובנפח בינוני על מודעות פעילות. השתמשו בגרידת Python כשאתם צריכים מחירי מכירה, ביקורות, נתוני וריאציות, או כל שדה שה-API לא חושף. הרבה צוותים משתמשים בשניהם.
אילו כלים וספריות צריך כדי לגרד את eBay עם Python
לפני שנכתוב קוד, הנה ערכת הכלים. ברוב דפי eBay לא צריך דפדפן headless — הנתונים משובצים ב-HTML שנוצר בצד השרת.
| ספרייה | מטרה |
|---|---|
requests או httpx | לקוח HTTP להורדת דפי eBay |
curl_cffi | לקוח HTTP עם טביעת TLS אמיתית של דפדפן (קריטי לעקיפת Akamai) |
beautifulsoup4 | מנתח HTML לחילוץ באמצעות סלקטורי CSS |
lxml | מנוע ניתוח מהיר עבור BeautifulSoup |
jmespath | שפת שאילתות לניתוח בלובי JSON מקוננים |
pandas | עיבוד נתונים וייצוא ל-CSV/Excel |
gspread | אינטגרציה עם Google Sheets |
התקינו הכול בשורה אחת:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadעבדו עם Python 3.11+ — pandas 3.0 דורש 3.10+, ו-3.11 נותן שיפור ביצועים של 10–60% בעבודות שקשורות ל-I/O.
ספרייה אחת ראויה לציון מיוחד: curl_cffi היא כנראה השדרוג המשמעותי ביותר שסקרייפר eBay בשנת 2026 יכול לעשות. eBay משתמש ב-, והווקטור המרכזי של Akamai לזיהוי הוא טביעת TLS. requests רגיל שולח טביעת JA3 שנראית כמו Python ולכן מסומנת מיד. curl_cffi מחקה את לחיצת היד TLS של Chrome אמיתי, וזה פותר בערך 90% מהיעדים שמוגנים על ידי Akamai בלי צורך בדפדפן headless.
שלב אחר שלב: איך לגרד תוצאות חיפוש של eBay עם Python
זהו המדריך המרכזי. נגרד דפי תוצאות חיפוש של eBay עבור רשימות מוצרים.
- רמת קושי: מתחיל–בינוני
- זמן נדרש: כ-30 דקות לגרידה ראשונה שעובדת
- מה צריך: Python 3.11+, הספריות שלמעלה, טרמינל, וכתובת URL של חיפוש ב-eBay
שלב 1: הקמת פרויקט Python
צרו תיקיית פרויקט והתקינו תלויות:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasצרו קובץ בשם scrape_ebay.py. זה יהיה סביבת העבודה שלכם.
שלב 2: בניית כתובת ה-URL של החיפוש ב-eBay
מבנה כתובת החיפוש של eBay פשוט למדי. הפרמטר המרכזי הוא _nkw (keyword):
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # פריטים לדף: 60, 120 או 240 (240 עלול להדליק דגלי בוט)
7 "_pgn": "1", # מספר עמוד
8}
9url = f"\{base_url\}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1פרמטרים שימושיים נוספים:
LH_BIN=1— רק Buy It Now_sacat=175673— קטגוריה ספציפית_sop=12— מיון לפי התאמה הטובה ביותר (10 = המחיר+משלוח הנוכים ביותר, 13 = חדש ביותר)LH_Complete=1&LH_Sold=1— פריטים שנמכרו / הושלמו (אכסה זאת בסעיף ייעודי בהמשך)
שלב 3: שליחת בקשה וטיפול בתגובה
כאן curl_cffi מצדיק את עצמו. requests.get() רגיל יחזיר לעיתים קרובות 403 מ-Akamai. עם curl_cffi אנחנו מחקים דפדפן Chrome אמיתי:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Status \{r.status_code\}, retrying in {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Request error: \{e\}, retrying...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Failed after \{max_retries\} retries: \{url\}")ההשהיה האקספוננציאלית עם ג'יטר חשובה — מרווחי שינה קבועים הם בעצמם טביעת אצבע של בוט.
שלב 4: ניתוח רשומות המוצרים מדף החיפוש
eBay נמצא כרגע בעיצומו של מעבר בין שני מבני תוצאות חיפוש. סקרייפר עמיד חייב לדעת להתמודד עם שניהם:
| שדה | מבנה ישן | מבנה חדש |
|---|---|---|
| מכולת כרטיס | li.s-item | li.s-card או div.su-card-container |
| כותרת | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| מחיר | span.s-item__price | .s-card__price |
קוד הניתוח שמתמודד עם שניהם:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # כותרת — נסה את שני המבנים
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # דלג על כרטיס ה-placeholder הרפאים "Shop on eBay"
11 if not title or "Shop on eBay" in title:
12 continue
13 # מחיר
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # תמונה
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # משלוח
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsמלכודת הכרטיס הראשון היא קלאסית. ה-li.s-item הראשון בהרבה דפי חיפוש של eBay הוא placeholder מוסתר עם הכותרת "Shop on eBay" וללא מחיר אמיתי. תמיד סננו אותו.
שלב 5: טיפול בעימוד כדי לגרד כמה דפים
eBay מחלק את הדפים באמצעות הפרמטר _pgn. הקישור לעמוד הבא משתמש ב-a.pagination__next:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Scraping page \{page_num\}: \{url\}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" No results on page \{page_num\}, stopping.")
12 break
13 all_results.extend(results)
14 print(f" Found {len(results)} listings (total: {len(all_results)})")
15 # השהיה מנומסת — 3 עד 8 שניות עם ג'יטר
16 time.sleep(random.uniform(3, 8))
17 return all_resultsהג'יטר האקראי של 3–8 שניות הוא לא בגדר רשות.
eBay עם Akamai מסמן דפוסי תעבורה של יותר מבקשה אחת לשנייה מ-IP יחיד.
שלב 6: ייצוא הנתונים ל-CSV או JSON
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"Exported {len(df)} listings to CSV and JSON.")עכשיו אמור להיות לכם גיליון נקי של מודעות eBay. במחשב שלי, גרידה של 3 דפים (360 מודעות) לקחה בערך 45 שניות כולל השהיות.
איך לגרד דפי מוצר של eBay עם Python
תוצאות החיפוש נותנות סיכום. דפי המוצר נותנים את הדברים המעניינים באמת: תיאורים מלאים, ציון משוב של המוכר, מאפייני פריט, קרוסלות תמונות ונתוני וריאציות.
ניתוח דף של מודעת מוצר אחת
דפי פריט של eBay נמצאים ב-/itm/<ITEM_ID>. נתיב החילוץ היציב ביותר הוא JSON-LD — eBay מטמיע בלוק סכמה מסוג Product ששורד כמעט כל שינוי ב-CSS:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — נתיב החילוץ היציב ביותר
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. גיבויי CSS לשדות שלא נמצאים ב-JSON-LD
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. מאפייני פריט
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemהדפוס כאן — קודם JSON-LD, אחר כך גיבויי CSS — הוא המפתח לבניית סקרייפרים שלא נשברים כל רבעון. עוד על זה בהמשך.
גרידת וריאציות מוצרים ב-eBay (נתוני MSKU)
לחלק ממודעות eBay יש כמה וריאציות — צבעים שונים, מידות, נפחי אחסון. ה-DOM הגלוי מציג רק טווח מחירים כמו "$899 to $1,099" עד שהמשתמש לוחץ על אפשרות. המחיר האמיתי לכל וריאציה נמצא באובייקט JavaScript מוסתר בשם MSKU.
זהו אחד המקומות שבהם ה-API של eBay מספק רק נתונים חלקיים (SKU הורה), ולכן גרידה היא לעיתים הבחירה הטובה יותר.
1import re, json
2def extract_variants(html):
3 # התאמה לא חמדנית היא קריטית — .+ חמדני יבלע את כל הדף
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusה-(.+?) הלא-חמדני בביטוי הרגולרי הוא בדיוק המקום שבו כמעט כל סקרייפר eBay נופל. .+ חמדני יבלע הכול עד ה-"QUANTITY" האחרון בדף, וייצור JSON שבור. ראיתי את הבאג הזה בלפחות שלושה מדריכים ש"עבדו".
איך לגרד פריטים שנמכרו ופריטים שהושלמו ב-eBay עם Python
זהו המקרה שמצדיק את הגרידה לעומת ה-API. נתוני פריטים שנמכרו — מה באמת נמכר, באיזה מחיר, ובאיזה תאריך — הם תקן הזהב למחקר שוק, לתמחור של משווקים מחדש ולהערכות שווי. ה-Browse API של eBay לא מספק זאת במפורש. טכנית כן, אבל הגישה אליו היא "Limited Release" ומסורבת .
פרמטרי ה-URL הדרושים הם LH_Complete=1 (מוצרים שהושלמו) ו-LH_Sold=1 (סינון רק לפריטים שנמכרו בפועל). חייבים להעביר את שניהם. העברת LH_Sold=1 בלבד תחזיר בשקט פריטים פעילים בקטגוריות מסוימות — זו המלכודת הנפוצה ביותר בקהילה.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Scraping sold page \{page_num\}...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # רק פריטים שנמכרו בפועל (מחיר ירוק בתוך POSITIVE)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # פריט שהושלם אך לא נמכר — דלג
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # ניתוח תאריך המכירה
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]\{2\}\s+\d{1,2},\s*\d\{4\})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldההבדל המרכזי ב-HTML: פריטים שנמכרו מציגים את המחיר בירוק (בתוך מעטפת .POSITIVE), בעוד פריטים שהושלמו אך לא נמכרו מציגים מחיר באדום עם קו חוצה. תמיד סננו לפי המחלקה .POSITIVE.
למה סקרייפרים של eBay נשברים (ואיך לבנות כאלה עמידים)
אם סקרייפר ה-eBay שלכם הפסיק לעבוד, אתם בחברה טובה. זו הבעיה מספר אחת כמעט בכל שרשור בפורום על גרידת eBay שקראתי. השאלה היא לא אם הסקרייפר יישבר — אלא מתי.
למה זה קורה:
- eBay משתמש ב-React עם שמות מחלקות שנוצרים דינמית ומשתנים עם כל פריסה
- ניסויי A/B מציגים מבני DOM שונים למשתמשים שונים (הפיצול בין
s-itemל-s-cardהוא דוגמה חיה עכשיו) - רענוני אתר תקופתיים משנים את הקינון של ה-HTML, גם כשהנתונים עצמם לא משתנים
- סלקטורים ישנים כמו
#itemTitleו-#prcIsumהוסרו לפני שנים אבל עדיין מופיעים במדריכים
כפי ש- מנסח זאת: "האתגר האמיתי בגרידת eBay הוא התמודדות עם שינויי סלקטורים ב-CSS. eBay מעדכנת את ה-frontend באופן קבוע, מה ששובר סקרייפרים שמסתמכים על שמות מחלקות ספציפיים."
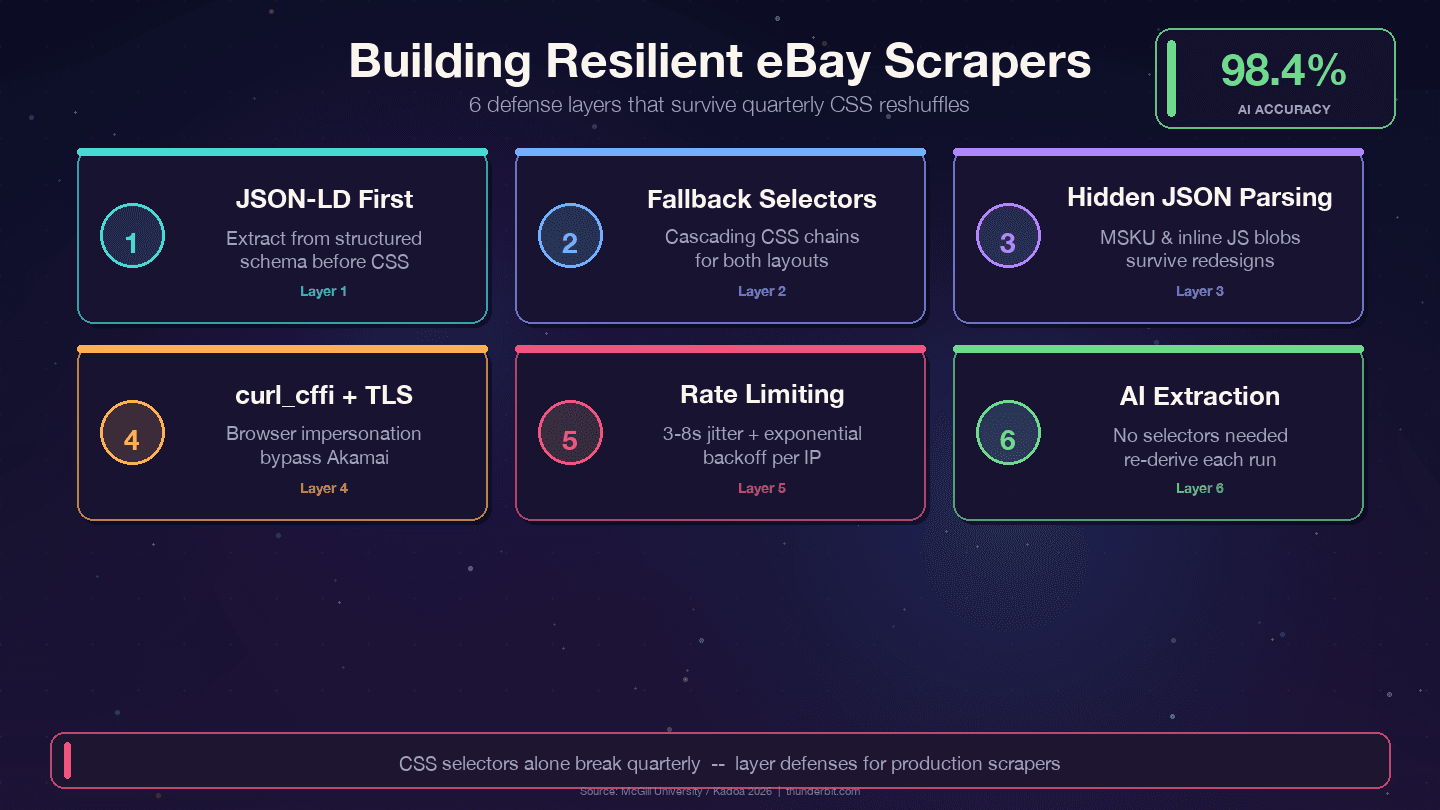
אסטרטגיות הגנה לסקרייפרי eBay לאורך זמן
ארבע אסטרטגיות ששורדות את הטלטלות הרבעוניות של eBay:
1. העדיפו JSON-LD על פני סלקטורי CSS. eBay מטמיעה בדפי פריט נתוני סכמה מובנים מסוג Product. שכבת הנתונים משתנה הרבה פחות משכבת התצוגה — מעצבים משכתבים מחלקות CSS כל רבעון, אבל שמות שדות כמו price, name ו-seller ממופים ל-API פנימי וכמעט לא משנים שם.
2. השתמשו בסלקטורי fallback מדורגים. אף פעם אל תישענו על סלקטור CSS יחיד. תמיד תנו חלופות:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. נתחו בלובי JSON מוסתרים. אובייקט הווריאציות MSKU ונתוני JavaScript מוטמעים שורדים שינויי CSS כי הם נוצרים בצד השרת. חילוץ באמצעות regex מתוך תגיות <script> דורש יותר עבודה בהתחלה, אבל מצמצם משמעותית תחזוקה.
4. תעדו כשלי סלקטורים. הוסיפו ניטור כדי לדעת מתי סלקטור הפסיק להתאים, ולא רק שהנתונים ריקים:
1if title is None:
2 print(f"WARNING: title selector failed for \{url\}")5. השתמשו ב-curl_cffi עם התחזות לדפדפן. זה מתמודד עם טביעת ה-TLS של Akamai בלי צורך בדפדפן headless.
האלטרנטיבה מבוססת ה-AI: בלי תחזוקת סלקטורים
אם נמאס לכם לתקן סלקטורים כל כמה חודשים, יש גישה שונה מהיסוד. כלים כמו משתמשים ב-AI כדי לקרוא את הדף מחדש בכל פעם ולהפיק את לוגיקת החילוץ בזמן אמת. מחקר של אוניברסיטת McGill בדק סקרייפרים מבוססי AI מול סקרייפרים מבוססי סלקטורים על פני 3,000 דפים ומצא ששיטות , כשמדדי ענף מצביעים על .
| גישה | נשברת כש-eBay משנה HTML? | מאמץ תחזוקה |
|---|---|---|
| סלקטורי CSS קשיחים | כן, כל רבעון | גבוה — תיקונים שוטפים |
| חילוץ JSON מוסתר / JSON-LD | לעיתים נדירות | נמוך |
| גרידה מבוססת AI (Thunderbit) | לא — ה-AI מפיק מחדש את הסלקטורים בכל הרצה | אין |
אכסה את תהליך העבודה עם Thunderbit בפירוט בהמשך. בינתיים, העיקר: אם אתם בונים סקרייפר שאתם מתכננים להפעיל חודשים, כדאי להשקיע בחילוץ מבוסס JSON עם סלקטורי fallback. אם אתם לא רוצים לתחזק סלקטורים בכלל, שווה לבדוק את הגישה של AI.
איך לאוטומט גרידות eBay חוזרות לניטור מחירים
גרידה חד-פעמית מועילה. אבל ניטור מחירים, מעקב מלאי וניתוח מתחרים דורשים איסוף נתונים חוזר. כמעט כל מאמר מתחרה שראיתי מזכיר ניטור מחירים כשימוש, אבל כמעט אף אחד לא מראה איך באמת מבצעים אוטומציה.
אפשרות 1: Cron Jobs (Linux/macOS) או Task Scheduler (Windows)
הגישה הפשוטה ביותר. עטפו את סקריפט ה-Python שלכם ב-cron job. תמיד השתמשו בנתיב המלא ל-Python של ה-venv — cron רץ עם סביבת עבודה מינימלית:
1crontab -e
2# כל יום ב-08:15
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1ב-Windows, השתמשו ב-PowerShell:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $Tזה דורש מחשב שפועל תמיד, ואתם מנהלים בעצמכם פרוקסי ואמצעי אנטי-בוט.
אפשרות 2: Cloud Functions (Serverless)
AWS Lambda או Google Cloud Functions מאפשרים להריץ סקרייפרים בלי שרת ייעודי. מאמץ ההקמה גבוה יותר — צריך לארוז תלויות, לטפל ב-timeouts (Lambda מוגבל ל-15 דקות), ועדיין לנהל פרוקסי. אבל אין תחזוקת שרת.
אפשרות 3: תזמון ללא קוד עם Thunderbit
פיצ'ר של Thunderbit מאפשר לתאר את המרווח בשפה פשוטה (למשל "כל יום ב-8 בבוקר"), להזין כתובות eBay וללחוץ על Schedule. הוא רץ בענן עם טיפול אנטי-בוט מובנה.
| גישה | מאמץ הקמה | צריך שרת? | מטפל באנטי-בוט? |
|---|---|---|---|
| Cron + סקריפט Python | בינוני | כן (מחשב דולק תמיד) | אתם מנהלים פרוקסי |
| פונקציית ענן (Lambda) | גבוה | לא (serverless) | אתם מנהלים פרוקסי |
| Thunderbit Scheduled Scraper | נמוך (מתארים במילים) | לא (מבוסס ענן) | מובנה |
לשמירת נתוני גרידה חוזרת, מסד SQLite מקומי הוא הפתרון הנכון להיסטוריית מחירים. השתמשו ב-ON CONFLICT ... DO UPDATE (ולא INSERT OR REPLACE, שמפר ):
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);לא רוצים לקודד? איך לגרד את eBay תוך 2 דקות עם Thunderbit
השקעתי 2,000 מילים בקוד Python. עכשיו אני רוצה להיות כן לגבי מתי בכלל לא צריך אותו.
אם אתם משתמשים עסקיים שעושים מחקר שוק חד-פעמי, משווקים מחדש שבודקים השוואות, או צוות ecommerce שצריך נתונים היום בלי ספרינט פיתוח, Python הוא מוגזם. ההתקנה, תחזוקת הסלקטורים, ניהול הפרוקסי — כל זה הרבה overhead בשביל "אני רק צריך את 200 המודעות האלה בגיליון אלקטרוני."
איך Thunderbit מגרד את eBay (שלב אחר שלב)
- התקינו את — בלי צורך בכרטיס אשראי.
- עברו לכל דף תוצאות חיפוש או דף מוצר ב-eBay בתוך Chrome.
- לחצו על "AI Suggest Fields" בסרגל הצד של Thunderbit. ה-AI קורא את הדף ומציע עמודות: כותרת, מחיר, מצב, משלוח, מוכר, דירוג.
- לחצו על "Scrape." התוסף עובר על העימוד וממלא את טבלת הנתונים. במיוחד עבור eBay, ל-Thunderbit יש שעובדות בלחיצה אחת.
- ייצוא ל-Google Sheets, Airtable, Notion, CSV, JSON או Excel — בחינם.
כל התהליך לוקח פחות מ-2 דקות.
מדדתי את זה.
העשרת דפי משנה: קבלת נתונים מדפי פריט בלי קוד נוסף
אחרי גרידת דף תוצאות חיפוש, Thunderbit יכול להיכנס לכל דף מוצר ולהוסיף שדות נוספים — מפרט מלא, פרטי מוכר, תיאור, כל התמונות. זה מחליף את 20+ שורות קוד ה-Python לגרידת דפי משנה שכתבנו קודם בלחיצה אחת.
מתי עדיין להשתמש ב-Python
Python מנצח כשצריך:
- גרידה בקנה מידה גדול (עשרות אלפי דפים להרצה)
- לוגיקת ניתוח מותאמת מאוד או טרנספורמציית נתונים
- אינטגרציה עם pipelines קיימים של נתונים (Airflow, dbt, Kafka)
- שליטה עדינה ב-TLS / session לעבודות אנטי-בוט מתקדמות
- כלכלת יחידה — במיליוני שורות, סטאק מתוחזק מנצח SaaS מבוסס קרדיטים
לרוב הפרויקטים החד-פעמיים או הבינוניים, Thunderbit מהיר ופשוט יותר. לפייפליינים בייצור בקנה מידה גדול, Python נותן לכם שליטה מלאה.
טיפים להימנע מחסימה כשמגרדים את eBay עם Python
שכבת Akamai של eBay היא דבר אמיתי. מה שבאמת עובד בפועל:
- השתמשו ב-
curl_cffiעםimpersonate="chrome124"— זה השיפור הכי גדול לעומתrequestsרגיל - סובבו מחרוזות User-Agent מרשימת גרסאות דפדפן עדכניות (Chrome 143, Firefox 124, Safari 26)
- הוסיפו השהיות אקראיות של — מרווחים קבועים הם טביעת אצבע
- השתמשו בפרוקסי Residential או Rotating לכל דבר מעבר לכמה עשרות דפים. כתובות IP של data center (AWS, GCP, DigitalOcean) מסומנות מהר על ידי Akamai.
- כבדו את
robots.txt— רוב כתובות ה-browse המסוננות מסומנות במפורש כ-Disallowed; דפי פריט (/itm/<id>) לא - טפלו ב-CAPTCHA בצורה חלקה — זהו אותם ונסו שוב עם IP אחר, או השתמשו בשירות לפתרון CAPTCHA
- אל תפציצו את השרת. התקדים של קובע ש-trespass to chattels חל כשהגרידה באמת פוגעת בשרתים. הישארות על בקשה אחת לשנייה לכל IP שומרת אתכם הרחק מהסף הזה.
לשימוש מסחרי בנפח גבוה, שקלו להשתמש ב-Browse API עבור מודעות פעילות ובגרידה ממוקדת רק עבור השוואות של פריטים שנמכרו ונתונים שה-API לא חושף. גישת ההיבריד הזו נקייה יותר גם טכנית וגם משפטית.
האם זה חוקי לגרד את eBay עם Python?
אני לא עורך דין, והפוסט הזה אינו ייעוץ משפטי. לכן אשמור את זה קצר.
הנוף המשפטי השתנה לטובת גרידת נתונים ציבוריים זמינים. התקדימים המרכזיים:
- (בית המשפט לערעורים של המחוז התשיעי, 2022): גרידה של נתונים זמינים לציבור לא מפרה את CFAA
- Van Buren v. United States (בית המשפט העליון של ארה״ב, 2021): צמצם את סעיף "exceeds authorized access" של CFAA
- (בית המשפט הפדרלי בקליפורניה, 2024): גרידה ללא התחברות לא מפרה את תנאי השימוש כי הסקרייפר אינו "user"
עם זאת, עדכון אוסר במפורש על "buy-for-me agents, LLM-driven bots, or any end-to-end flow that attempts to place orders without human review." הקו ברור: גרידת קריאה בלבד של דפים ציבוריים היא על בסיס חזק; אוטומציה של checkout לא.
שיטות מומלצות: גרדו רק נתונים גלויים לציבור. אל תיצרו חשבונות פיקטיביים ואל תעקפו שערי התחברות. אל תמכרו מחדש בכמויות תמונות מוגנות בזכויות יוצרים ממודעות. ולפרויקטים מסחריים בקנה מידה גדול — התייעצו עם יועץ משפטי.
מסקנה ונקודות עיקריות
Python הוא הדרך הגמישה ביותר לגרד את eBay, אבל הוא דורש תחזוקה מתמשכת ככל שה-HTML של האתר משתנה. מסגרת ההחלטה:
- השתמשו ב-eBay Browse API עבור שאילתות יציבות, מובנות ובנפח בינוני על מודעות פעילות
- השתמשו בגרידת Python עבור פריטים שנמכרו, ביקורות, נתוני וריאציות וכל מה שה-API לא חושף
- השתמשו ב- אם אתם רוצים נתוני eBay בלי לכתוב או לתחזק קוד
הקוד במדריך הזה שם דגש על עמידות: קודם חילוץ JSON-LD, אחר כך סלקטורי CSS מדורגים, ולבסוף ניתוח JSON מוסתר עבור וריאציות. הגישה הרב-שכבתית הזו אומרת שהסקרייפר שלכם לא ימות בפעם הבאה שצוות ה-frontend של eBay ישחרר רענון עיצוב.
אם אתם רוצים לנסות את המסלול ללא קוד, מאפשרת לבדוק אותו על דפי eBay כבר עכשיו. ואם אתם רוצים לראות איך עובדת, זה במרחק לחיצה אחת.
לעוד מידע על כלי גרידת רשת, בדקו את המדריכים שלנו על , , ו-. אפשר גם לצפות במדריכים ב-.
שאלות נפוצות
1. האם אפשר לגרד את eBay בחינם עם Python?
כן. כל הספריות (Requests, BeautifulSoup, curl_cffi, pandas) הן חינמיות וקוד פתוח. העלויות מגיעות בקנה מידה גדול — פרוקסי Residential לגרידה בנפח גבוה עולים בדרך כלל 50–500 דולר בחודש, תלוי ברוחב הפס. לפרויקטים קטנים (כמה מאות דפים) אפשר לגרד מ-IP ביתי עם הגבלת קצב זהירה.
2. איך מגרדים פריטים שנמכרו ופריטים שהושלמו ב-eBay עם Python?
הוסיפו LH_Complete=1&LH_Sold=1 לפרמטרים של כתובת החיפוש. חייבים להעביר את שניהם — LH_Sold=1 בלבד מחזיר בשקט מודעות פעילות בקטגוריות מסוימות. סננו את התוצאות על ידי בדיקה של מחלקת ה-CSS .POSITIVE על רכיב המחיר, שמצביעה על מכירה בפועל ולא על פריט שהושלם אך לא נמכר.
3. האם eBay חוסם גרידת רשת?
eBay משתמש ב-Akamai Bot Manager, שמזהה סקרייפרים בעיקר דרך טביעת TLS וניתוח התנהגותי. קריאות requests רגילות מקבלות לעיתים קרובות תגובות 403. שימוש ב-curl_cffi עם התחזות לדפדפן, סיבוב User-Agents והוספת השהיות אקראיות של 3–8 שניות בין בקשות מטפל ברוב החסימות. פרוקסי Residential עוזרים בקנה מידה.
4. עדיף להשתמש ב-eBay API או בגרידת רשת?
השתמשו ב-Browse API לשאילתות יציבות, בנפח בינוני, על מודעות פעילות (עד 5,000 קריאות ביום). השתמשו בגרידה כשאתם צריכים היסטוריית מחירי מכירה, נתוני וריאציות/MSKU מלאים, ביקורות, או כל שדה שה-API לא חושף. Marketplace Insights API אמנם מספק טכנית נתוני מכירות, אבל הגישה אליו מוגבלת ו-.
5. מה הדרך הקלה ביותר לגרד את eBay בלי לקודד?
משתמש ב-AI כדי לקרוא דפי eBay, להציע עמודות נתונים ולחלץ רשימות בלחיצה אחת. הוא מטפל בעימוד, בהעשרת דפי משנה ובייצוא ל-Google Sheets, Excel, Airtable או Notion. מוכנות מראש הופכות את זה למהיר עוד יותר לשימושים נפוצים.
למידע נוסף