
יש אנשים שאוספים בולים. אחרים אוספים סניקרס. אבל אם אתם עובדים במכירות, שיווק, איקומרס או תפעול בשנת 2025, רוב הסיכויים שאתם אוספים משהו קצת יותר… דיגיטלי: נתוני ווב. ולא בקטנה—עסקים משקיעים כיום בממוצע כ-5 מיליון דולר בשנה באיסוף נתונים מהאינטרנט, ו-web scraping הפך לכלי סטנדרטי בין מחלקות—מאסטרטגיה ועד שירות לקוחות ().
וכשיש כזה בום בביקוש, שני שמות קופצים כמעט בכל מדריך ובכל פרויקט של python scraper: playwright ו-selenium. שניהם התחילו ככלי אוטומציה לדפדפן לצורכי בדיקות, אבל היום הם כבר מזמן הפכו למסגרות המובילות למי שרוצה להפוך את הרשת לנתונים מובנים שאפשר לעבוד איתם. אבל יש כאן קאץ׳: הבחירה ביניהם היא לא רק עניין טכני—זו בחירה של הכלי הנכון לצרכי ה-scraping האמיתיים שלכם. ואם אתם לא מפתחים, או פשוט רוצים תוצאות מהר, יש גם דרך קלה יותר (רמז: היא לא כוללת כתיבת אפילו שורת Python אחת). בואו נצלול.
מכלי בדיקות למעצמות Web Scraping: מה זה Playwright ומה זה Selenium
נתחיל מהבסיס. selenium איתנו עוד מ-2004—הוותיק המנוסה והאמין של אוטומציית דפדפן. הוא נבנה במקור עבור בודקי QA, ומאפשר לשלוט בדפדפנים כמו Chrome, Firefox ואפילו Internet Explorer (למי שאוהב לחיות על הקצה). playwright, לעומת זאת, נכנס חזק ב-2020 בגיבוי Microsoft, עם גישה מודרנית לאוטומציה—אפשר לחשוב עליו כאח הצעיר, הזריז והעדכני של selenium.
שני הכלים מאפשרים לכתוב סקריפטים (לעיתים קרובות ב-Python) שפותחים דפדפן, נכנסים לאתר, לוחצים על כפתורים, ממלאים טפסים, והכי חשוב עבורנו—מחלצים נתונים. למרות שהשורשים שלהם בעולם הבדיקות האוטומטיות, הם הפכו לתשתית מרכזית ל-web scraping—ממעקב מחירים ועד יצירת לידים (). והפופולריות שלהם כבר לא נשארת רק אצל מפתחים: יותר ויותר משתמשים עסקיים מנסים להפשיל שרוולים ולבנות scrapers בעצמם—או לפחות לנסות.
אבל כאן מגיע הטוויסט: כשמחלצים נתונים, סדר העדיפויות משתנה. פחות אכפת לכם מכיסוי בדיקות ויותר חשוב לכם לקבל נתונים בצורה יציבה, להימנע מחסימות, ולא לבזבז את הסופ״ש על דיבוג שגיאות Python. כאן בדיוק נחשפים ההבדלים האמיתיים בין playwright ל-selenium.
ההבדלים המרכזיים: Playwright מול Selenium ל-Web Scraping

ניגש ישר לעניין: גם playwright וגם selenium יכולים לבצע scraping, אבל כל אחד זורח בסיטואציות אחרות.
- selenium הוא הוותיק. הוא עובד כמעט עם כל דפדפן ושפה, יש לו קהילה עצומה, והוא מתאים במיוחד ל-scraping של אתרים ישנים וסטטיים עם מבנה צפוי.
- playwright הוא הכלי המודרני עם פיצ׳רים עדכניים. הוא נבנה עבור אתרים דינמיים וכבדי JavaScript, עם כלים מובנים להתמודדות עם התחברויות, פופ-אפים, גלילה אינסופית ועוד. הוא גם מהיר יותר וקל יותר להקמה—במיוחד למשתמשי Python.
אבל לא צריך להסתמך רק על מה שאני אומר—בואו נפרק את זה לפי פיצ׳רים.
טבלת השוואת פיצ׳רים: Playwright מול Selenium
| פיצ׳ר | Selenium | Playwright |
|---|---|---|
| תמיכה בשפות | Python, Java, C#, JS, Ruby ועוד | Python, JS/TS, Java, C# |
| תמיכה בדפדפנים | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| מורכבות התקנה | דורש דרייבר לדפדפן והגדרות ידניות | פקודה אחת מתקינה הכול |
| מהירות/ביצועים | איטי יותר וצורך יותר משאבים | מהיר ב-40–50%, אסינכרוני/מקבילי כברירת מחדל |
| התמודדות עם תוכן דינמי | המתנות ידניות, יותר קוד | Auto-wait, עובד בקלות עם אתרי JS כבדים |
| התחמקות מאנטי-בוט | נוטה לזיהוי, דורש תוספים | Stealth מובנה, מחקה משתמשים טוב יותר |
| כלי דיבוג | בסיסיים (Selenium IDE, צילומי מסך) | Inspector, הקלטת וידאו, codegen |
| תמיכת קהילה | ענקית ובשלה, המון מדריכים | צומחת מהר, תיעוד מודרני, מפתחים פעילים |
| תהליך עבודה ל-Python Scraper | יותר התקנות ויותר boilerplate | חלק יותר, פחות קוד, נוח למתחילים |
איך לבחור נכון: מתי להשתמש ב-Playwright ומתי ב-Selenium ל-Web Scraping
אז מה לבחור לפרויקט הבא? הנה הגישה שלי, אחרי שנים של בניית כלי אוטומציה ועזרה לצוותים להוציא נתונים מהמערב הפרוע של האינטרנט.
- selenium מתאים לכם אם:
- האתר שאתם מגרדים הוא “אולד סקול”—HTML סטטי, מעט JavaScript, בלי פופ-אפים מתוחכמים.
- אתם חייבים לתמוך בדפדפנים מוזרים (שלום Internet Explorer) או להשתלב במערכות ישנות.
- אתם רוצים את הביטחון של קהילה ענקית ואינסוף תשובות ב-StackOverflow.
- אתם כבר מכירים selenium מפרויקטי בדיקות.
- playwright הוא הבחירה הנכונה אם:
- האתר מודרני, דינמי ומלא JavaScript (איקומרס, רשתות חברתיות, או כל דבר שגורם למאוורר של הלפטופ לעבוד שעות נוספות).
- צריך להתחבר לחשבון, לעבור בין טאבים, להתמודד עם גלילה אינסופית או פופ-אפים.
- אתם רוצים להתחיל מהר—פחות התקנות ופחות קוד.
- נמאס לכם לכתוב
time.sleep(5)בכל מקום ואתם רוצים שהכלי ינהל את התזמונים בשבילכם.
כלל אצבע פשוט: אם הניסיון הראשון שלכם עם selenium מלא ברגעים של “למה זה לא נטען?”, כנראה הגיע הזמן לנסות playwright.
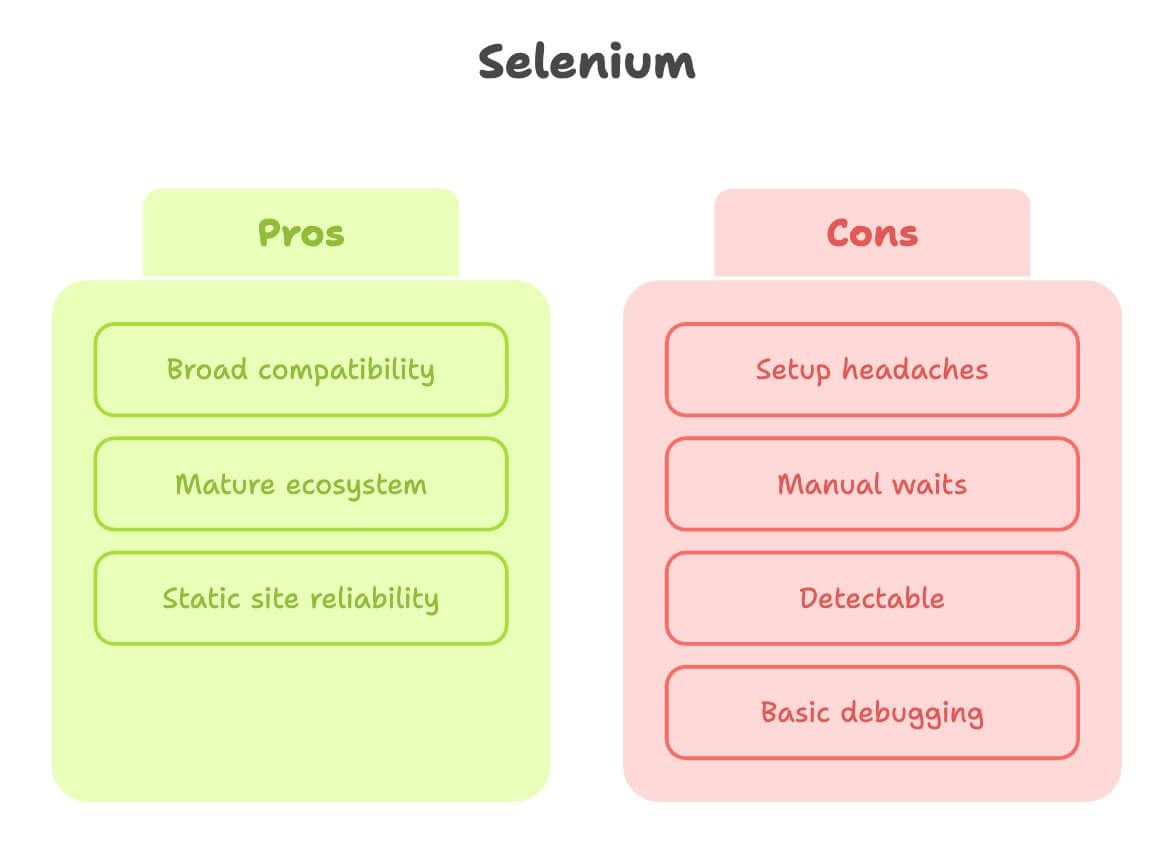
Selenium ל-Web Scraping: יתרונות ומגבלות
מגיע ל-selenium קרדיט. הוא הסבא של אוטומציית הדפדפן, ובהרבה משימות scraping הוא פשוט עושה את העבודה.
יתרונות:
- תאימות רחבה: עובד כמעט עם כל דפדפן ושפה.
- אקוסיסטם בשל: המון מדריכים, שאלות-תשובות ותוספים.
- מצוין לאתרים סטטיים: אם העמוד לא משתנה הרבה, selenium יציב מאוד.
מגבלות:
- כאב ראש בהתקנה: צריך להוריד ולהגדיר דרייבר לדפדפן (כמו ChromeDriver) ולתחזק גרסאות. מתחילים נתקעים כאן לא מעט ().
- המתנות ידניות: תוכן דינמי? תמצאו את עצמכם כותבים הרבה explicit waits או, גרוע מזה, sleep אקראי.
- קל יותר לזיהוי: אתרים רבים מזהים דפדפנים שמופעלים ע״י selenium וחוסמים—במיוחד בהרצה בענן.
- דיבוג בסיסי: אין הקלטת וידאו מובנית או Inspector אינטראקטיבי.
בשורה התחתונה, selenium מעולה לאתרים פשוטים ויציבים—אבל באתרים מודרניים ואינטראקטיביים הוא יכול להרגיש כמו לדחוף סלע במעלה ההר.
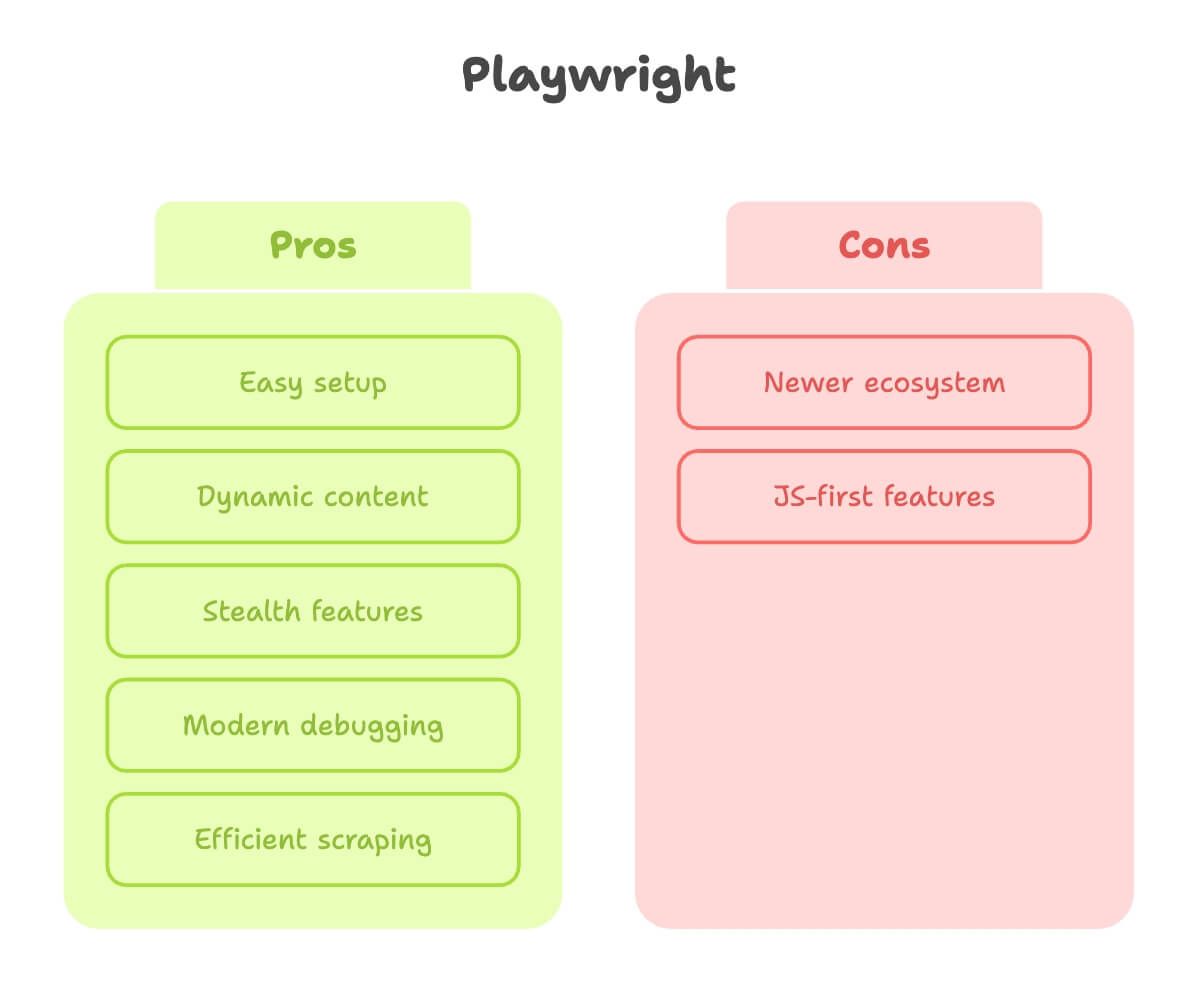
Playwright ל-Web Scraping: יתרונות ומגבלות
ועכשיו playwright. מניסיון אישי עם שני הכלים, playwright מרגיש כאילו נבנה ע״י אנשים שבאמת עברו את הסבל של web scraping.
יתרונות:
- התקנה קלה: pip אחד, פקודה אחת, ואתם בפנים. בלי דרייברים ובלי דרמות.
- התמודדות מצוינת עם תוכן דינמי: Auto-wait לאלמנטים, כך שלא צריך לנחש מתי העמוד “מוכן” ().
- פיצ׳רי stealth: מחקה משתמשים אמיתיים טוב יותר, כולל stealth mode ותמיכה בכמה contexts (מעולה ל-scraping ככמה “משתמשים” במקביל).
- דיבוג מודרני: Inspector, הקלטת וידאו, ואפילו יצירת קוד לפי קליקים ידניים.
- מהיר ויעיל יותר: במיוחד כשמגרדים הרבה עמודים או מריצים במקביל.
מגבלות:
- אקוסיסטם צעיר יותר: יש מעט פחות מדריכים, אם כי הפער נסגר מהר.
- חלק מהפיצ׳רים “JS-first”: רוב הדברים עובדים ב-Python, אבל לפעמים תמצאו פיצ׳ר שמתועד טוב יותר ב-JS.
השורה התחתונה: playwright הוא הבחירה שלי לכל אתר שהוא אפילו קצת דינמי, או כשאני רוצה תוצאות מהר בלי להילחם בהתקנות.
התחמקות מאנטי-בוט: איזה Python Scraper מתמודד טוב יותר עם אתרים מודרניים?
בואו נדבר על הפיל שבחדר: חסימות. ב-web scraping, החלק הקשה הוא לא לכתוב קוד—אלא לוודא שהאתר לא טורק לכם את הדלת.
- selenium: כברירת מחדל קל יותר לזהות אותו. אתרים מזהים את דגל
webdriver, user agents של headless ועוד סימנים מחשידים. יש פתרונות (כמו undetected-chromedriver), אבל הם דורשים עוד התקנות ותמיד רודפים אחרי טכנולוגיות אנטי-בוט (). - playwright: מגיע עם יכולות stealth מובנות—הסתרת “טביעות אצבע” של אוטומציה, תמיכה בכמה contexts, והמתנה לאינטראקציות שנראות יותר אנושיות. זה לא קסם, אבל לרוב תיחסמו פחות מהר.
אבל האמת היא: אף אחד מהכלים לא חסין לחלוטין. ב-scraping “כבד” (כמו סניקרס או אתרי כרטיסים), עדיין תצטרכו פרוקסים, רוטציה של IP, ואולי גם פתרון CAPTCHA. playwright פשוט הופך את זה לפחות כואב.
חוויית מפתח: התקנה, עקומת למידה ודיבוג
בואו נדבר על החוויה בפועל—במיוחד אם אתם מתחילים או פשוט רוצים לסיים את המשימה בלי דוקטורט ב-Python.
- selenium:
- התקנה: מתקינים Python, מתקינים selenium, מורידים דרייבר מתאים, מוסיפים ל-PATH, ומקווים שהגרסאות תואמות. (ראיתי יותר אנשים נתקעים בדרייבר מאשר ב-scraping עצמו.)
- עקומת למידה: יש המון חומר, אבל גם הרבה קוד ישן ומדריכים לא מעודכנים.
- דיבוג: בעיקר print וצילומי מסך. Selenium IDE קיים, אבל בסיסי.
- playwright:
- התקנה:
pip install playwright, ואזplaywright install. זהו. - עקומת למידה: תיעוד מודרני, הרבה דוגמאות, ו-API “אנושי” יותר—אפשר לבחור אלמנטים לפי טקסט, role או placeholder.
- דיבוג: Inspector מאפשר לעבור שלב-שלב, לראות את הדפדפן, ואפילו להקליט וידאו של הרצות scraping ().
- התקנה:
אם חשוב לכם לראות תוצאות מהר ולהשקיע פחות זמן בהתקנה ובפתרון תקלות, playwright מנצח בבירור. selenium מצוין אם אתם כבר מכירים את הניואנסים שלו או צריכים את התאימות הרחבה.
צעד-אחר-צעד: בניית Python Web Scraper ראשון עם Playwright או Selenium
בואו נראה איך זה נראה בפועל לבנות scraper עם כל כלי—בלי קוד, רק שלבים.
Playwright (Python):
- התקנת Playwright ודפדפנים:
pip install playwright+playwright install - הפעלת דפדפן: Chromium, Firefox או WebKit (headless או עם חלון).
- ניווט לעמוד:
page.goto("<https://example.com>") - המתנה לתוכן: Playwright מבצע auto-wait לטעינת אלמנטים.
- חילוץ נתונים: סלקטורים ידידותיים (כמו
get_by_text,locator("span.price")). - עמודים מרובים/תתי-עמודים: לולאה בין עמודים או קליקים על קישורים—קל להריץ כמה עמודים במקביל.
- ייצוא נתונים: שמירה ל-CSV, Excel או מסד נתונים.
- דיבוג: Inspector או הקלטת וידאו כשמשהו משתבש.
Selenium (Python):
- התקנת Selenium:
pip install selenium - הורדת דרייבר לדפדפן: (למשל ChromeDriver), והוספה ל-PATH.
- הפעלת דפדפן: Chrome, Firefox או אחר.
- ניווט לעמוד:
driver.get("<https://example.com>") - המתנה לתוכן: הוספת explicit waits (
WebDriverWait) אוtime.sleepאם אתם מרגישים אמיצים. - חילוץ נתונים:
find_elementאוfind_elements(סלקטורים CSS/XPath). - עמודים מרובים/תתי-עמודים: לולאה בין כתובות או קליקים—אבל אתם מנהלים את התזמונים והניווט בעצמכם.
- ייצוא נתונים: שמירה ל-CSV, Excel או מסד נתונים.
- דיבוג: בעיקר ידני—לצפות בדפדפן, להדפיס HTML או לצלם מסך.
רואים את ההבדל? playwright פשוט יותר “Plug and Play” לאתרים מודרניים.
מעבר לקוד: Web Scraping ללא קוד עם Thunderbit AI Web Scraper
עכשיו בואו נהיה כנים: לא כולם רוצים להפוך לגורו Python רק כדי לקבל טבלת מחירים או רשימת לידים. אולי אתם במכירות, שיווק, נדל״ן או תפעול, ואתם פשוט רוצים את הנתונים—עכשיו. כאן נכנס .
כמייסד-שותף של Thunderbit, ראיתי מקרוב כמה משתמשים עסקיים רוצים לדלג על הקוד ולהגיע ישר לתוצאה. לכן בנינו שמאפשר לבצע scraping לכל אתר בשתי לחיצות—בלי Python, בלי דרייברים ובלי דיבוג.
איך Thunderbit עובד
- נכנסים לאתר שממנו רוצים לחלץ נתונים.
- לוחצים על “AI Suggest Fields”. ה-AI של Thunderbit סורק את העמוד ומציע שדות נתונים (כמו שם מוצר, מחיר, תמונה, דירוג).
- לוחצים על “Scrape”. מיד מתקבלת טבלה מסודרת של הנתונים.
- מייצאים ל-Excel, Google Sheets, Airtable, Notion, CSV או JSON. וזהו.
בלי להתעסק עם סלקטורים, בלי ניסוי וטעייה, בלי קוד. זה קל כמו להזמין אוכל—ובכנות, לרוב גם מהיר יותר מהמשלוח.
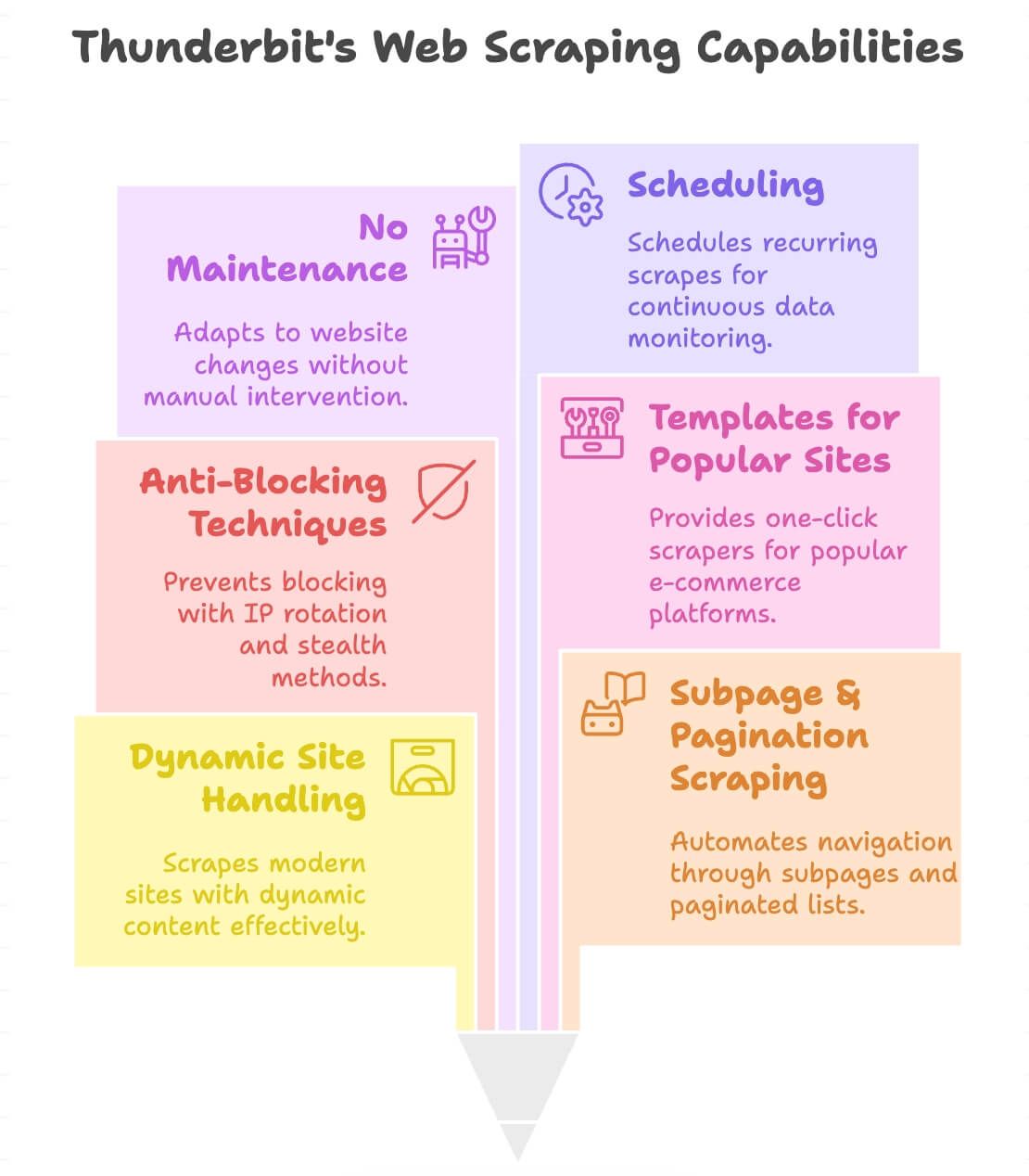
מה מייחד את Thunderbit?
- מתמודד עם אתרים דינמיים: מגרד אתרי איקומרס מודרניים, מדריכים (directories) ואפילו אתרים עם גלילה אינסופית או פופ-אפים.
- Scraping של תתי-עמודים ופאג׳ינציה: מקליק אוטומטית לעמודי מוצר או רשימות מדורגות כדי להביא את כל הנתונים.
- מנגנוני אנטי-חסימה מובנים: רוטציית IP בצד השרת וטכניקות stealth כדי להפחית חסימות.
- תבניות לאתרים פופולריים: scrapers בלחיצה אחת ל-Amazon, eBay, Shopify, Zillow ועוד ().
- בלי תחזוקה: אם האתר משתנה, ה-AI של Thunderbit מסתגל—אין צורך לשכתב את ה-scraper.
- תזמון: קובעים scraping חוזר למעקב שוטף (למשל בדיקת מחירים יומית).
- תמיכה ב-34 שפות: חילוץ ותרגום נתונים כמעט מכל מקום.
והכי חשוב: לא צריך לדעת כלום על HTML, CSS או Python. אם אתם יודעים להשתמש בדפדפן—אתם יודעים להשתמש ב-Thunderbit.
איזו פתרון Web Scraping מתאים לכם?
נסכם עם מדריך החלטה קצר:
| המצב שלכם | הכלי המומלץ |
|---|---|
| חילוץ מאתר סטטי ופשוט; לא מפריע לכם להתקין ולהגדיר | Selenium |
| חילוץ מאתר מודרני ודינמי; רוצים תוצאות מהר | Playwright |
| חייבים תמיכה בדפדפנים/שפות ישנים | Selenium |
| רוצים התקנה קלה, דיבוג מודרני ופחות קוד | Playwright |
| לא מפתחים; רוצים נתונים עכשיו, בלי קוד ובלי התקנות | Thunderbit |
| צריך לחלץ הרבה עמודים, תתי-עמודים או לתזמן משימות | Thunderbit |
| רוצים ייצוא ישיר ל-Excel, Sheets, Notion, Airtable | Thunderbit |
| שונאים לדבג שגיאות Python | Thunderbit |
אם אתם מפתחים, או אוהבים להתעסק בקוד, playwright ו-selenium הם כלים חזקים. אבל אם המטרה שלכם היא להכניס נתונים לגיליון כמה שיותר מהר, Thunderbit יחסוך לכם שעות—ואולי אפילו ימים—של עבודה.
סיכום: Web Scraping מהיר ואמין—בדרך שלכם
web scraping הפך למיינסטרים, ובצדק: עסקים צריכים נתונים כדי להתחרות—והם צריכים אותם עכשיו. playwright ו-selenium התפתחו מכלי בדיקות צנועים למסגרות scraping חיוניות, לכל אחת יתרונות משלה. selenium הוא הוותיק האמין לאתרים סטטיים ולסביבות ישנות; playwright הוא הבחירה המודרנית והמהירה לעמודים דינמיים ואינטראקטיביים.
אבל הנה העצה הכנה שלי, אחרי שנים ב-SaaS, אוטומציה ו-AI: אם אתם לא כאן בשביל הקוד, אל תבזבזו זמן על דרייברים, סלקטורים וטריקים נגד אנטי-בוט. עם אפשר לעבור מ-“אני צריך את הנתונים האלה” ל-“הנה קובץ ה-Excel שלי” תוך דקות—לא ימים.
אז בין אם אתם מקצועני Python או משתמשים עסקיים שרק רוצים תוצאה, יש פתרון scraping שמתאים לצרכים שלכם—ולסבלנות שלכם. נסו, בדקו מה עובד בתהליך שלכם, וזכרו: ה-scraper הטוב ביותר הוא זה שמביא לכם את הנתונים שאתם צריכים, עם מינימום כאב ראש.
ואם אי פעם תמצאו את עצמכם מדבגים שגיאת דרייבר של selenium ב-2 בלילה—תדעו ש-Thunderbit עדיין כאן, מוכן לבצע scraping בשתי לחיצות.
רוצים ללמוד עוד על scraping ללא קוד, חילוץ נתונים מבוסס AI, ואיך Thunderbit יכול לעזור לצוות שלכם? כנסו ל- שלנו, או התחילו עם כבר היום.
נ.ב. אם אתם עדיין מתלבטים איזה כלי לבחור, או רוצים לראות את Thunderbit בפעולה, קפצו ל- שלנו לדמוים, טיפים, וקצת הומור על web scraping. (כן, יש גם כאלה.)
קריאה נוספת: