האינטרנט הוא מקום פרוע ב-2026 — חצי מתעבורת האינטרנט כולה כבר מגיעה מבוטים, וסורקי האתרים הפתוחים-בקוד הם הגיבורים האלמוניים שפועלים מאחורי הקלעים, ומניעים הכול מניטור מחירים ועד אימון בינה מלאכותית. ביליתי שנים ב-SaaS ובאוטומציה, ואם למדתי דבר אחד, זה שבחירה נכונה של סורק מתארח-עצמית יכולה לחסוך לצוות שלך חודשים של כאבי ראש (ואולי גם כמה לילות של דיבוג). בין אם אתם גורפים כמה דפי מוצר או סורקים מיליוני כתובות URL למחקר, האלטרנטיבות הפתוחות-בקוד ל-Firecrawl ברשימה הזו מכסות אתכם — בלי קשר להיקף, לסטאק הטכנולוגי או לרמת הסיבוכיות שאתם מוכנים להתמודד איתה.
אבל הנה הטוויסט: אין פתרון אחד שמתאים לכולם. חלק מהצוותים צריכים את כוח הסוס הגולמי של Scrapy או את העוצמה הארכיונית של Heritrix, בעוד שאחרים יגלו שמידת התחזוקה של ספריות פתוחות-בקוד היא יקרה מדי. אז בואו נפרק את 9 האלטרנטיבות הפתוחות-בקוד המובילות ל-Firecrawl לשנת 2026, נראה היכן כל אחת מהן מצטיינת, ונעזור לכם להתאים את הכלי הנכון לצורכי העסק שלכם — בלי כאב הניסוי והטעייה.
איך לבחור את החלופה הפתוחה-בקוד הטובה ביותר ל-Firecrawl עבור העסק שלך
לפני שנצלול לרשימה, בואו נדבר אסטרטגיה. עולם גריפת האתרים הפתוח-בקוד מגוון יותר מאי פעם, והבחירה שלכם צריכה להתבסס על כמה גורמים מרכזיים:
- קלות שימוש: האם אתם רוצים ממשק של הצבע ולחיצה, או שאתם מרגישים בנוח לכתוב Python, Go או JavaScript?
- יכולת סקייל: האם אתם גורפים אתר אחד, או שצריך לסרוק מיליוני דפים לאורך מאות דומיינים?
- סוג התוכן: האם אתר היעד שלכם מבוסס HTML סטטי, או שהוא נשען על JavaScript כבד וטעינה דינמית?
- צרכי אינטגרציה: איך תרצו להשתמש בנתונים — לייצא ל-Excel, לדחוף למסד נתונים, או להזרים אותם לצינור אנליטיקה?
- תחזוקה: האם יש לכם משאבים לתחזק קוד מותאם אישית, או שאתם רוצים כלי שמתאים את עצמו אוטומטית לשינויים באתר?
הנה דף עזר מהיר שיעזור לכם להחליט:
| תרחיש | הכלי(ים) הטובים ביותר |
|---|---|
| ללא קוד, גלישה לא מקוונת | HTTrack |
| סריקה בהיקף גדול, רב-דומיינית | Scrapy, Apache Nutch, StormCrawler |
| אתרים דינמיים/כבדֵי JS | Puppeteer |
| נדרש אוטומציה של טפסים/התחברות | MechanicalSoup |
| הורדת אתר סטטי/ארכוב | Wget, HTTrack, Heritrix |
| מפתח Go, ביצועים גבוהים | Colly |
עכשיו, בואו נצלול אל 9 האלטרנטיבות הפתוחות-בקוד המובילות ל-Firecrawl לשנת 2026.
1. Scrapy: הטוב ביותר לגריפת Python בקנה מידה גדול

הוא אלוף המשקל הכבד של גריפת האתרים הפתוחה-בקוד. הוא בנוי ב-Python, והוא הבחירה המועדפת למפתחים שצריכים לגרוף בהיקפים גדולים — חשבו על מיליוני דפים, עדכונים תכופים ולוגיקה מורכבת באתר.
למה Scrapy?
- סקייל עצום: Scrapy יכול להתמודד עם אלפי בקשות בשנייה, והוא משמש חברות שגורפות מיליארדי דפים בחודש ().
- נרחב ומודולרי: כותבים spiders מותאמים אישית, מחברים middleware לפרוקסים, מטפלים בהתחברויות, ומייצאים ל-JSON, CSV או מסדי נתונים.
- קהילה פעילה: המון תוספים, תיעוד ותשובות ב-Stack Overflow.
- מוכח בקרבות: בשימוש בייצור על ידי צוותי e-commerce, חדשות ומחקר ברחבי העולם.
מגבלות: עקומת למידה תלולה למי שאינו מפתח, ותצטרכו לתחזק את ה-spiders שלכם כשהאתרים משתנים. אבל אם אתם רוצים שליטה מלאה ויכולת סקייל, קשה לנצח את Scrapy.
2. Apache Nutch: הטוב ביותר למנועי חיפוש ארגוניים
הוא הסבא הגדול של הסורקים הפתוחים-בקוד, שנבנה לסריקה ברמת enterprise ובקנה מידה של האינטרנט. אם אתם חולמים לבנות מנוע חיפוש משלכם או לסרוק מיליוני דומיינים, Nutch הוא החבר שלכם.
למה Apache Nutch?
- סקייל מונע Hadoop: על בסיס Hadoop, Nutch יכול לסרוק מיליארדי דפים על פני קלאסטרים של שרתים ( משתמש בו כדי לסרוק את הרשת הציבורית).
- סריקה אצווית: מזינים לו רשימת כתובות URL התחלתיות ונותנים לו לרוץ — מעולה למשימות מתוזמנות ובקנה מידה גדול.
- אינטגרציה: עובד עם Solr, Elasticsearch וצינורות Big Data.
מגבלות: ההתקנה מורכבת (חשבו קלאסטרים של Hadoop, קובצי קונפיגורציה של Java), והוא עוסק יותר בגריפה גולמית מאשר בחילוץ נתונים מובנים. מוגזם לפרויקטים קטנים, אבל ללא תחרות בסריקה בקנה מידה של האינטרנט.
3. Heritrix: הטוב ביותר לארכוב אתרים ולציות

הוא הסורק של Internet Archive עצמו, שנבנה במיוחד לארכוב אתרים ולשימור דיגיטלי.
למה Heritrix?
- שלמות ברמת ארכיון: לוכד כל דף, נכס וקישור — מושלם לציות משפטי או לצילומי מצב היסטוריים.
- פלט WARC: שומר הכול בקובצי Web ARChive תקניים, מוכנים להפעלה חוזרת או לניתוח.
- ממשק ניהול מבוסס דפדפן: מגדירים ועוקבים אחרי סריקות דרך ממשק אינטרנט.
מגבלות: כבד משקל (דורש הרבה דיסק וזיכרון), לא מריץ JavaScript, ומפיק ארכיונים גולמיים במקום טבלאות נתונים מובנות. מתאים במיוחד לספריות, ארכיונים או תעשיות מפוקחות.
4. Colly: הטוב ביותר למפתחי Go בעלי ביצועים גבוהים
הוא חביבם של מפתחי Go — סורק אתרים מהיר, קל משקל ובעל מקביליות גבוהה.
למה Colly?
- מהיר בטירוף: מנגנון המקביליות של Go מאפשר ל-Colly לגרוף אלפי דפים עם צריכת CPU/RAM מינימלית ().
- ממשק פשוט: מגדירים callbacks לאלמנטים ב-HTML, והוא מטפל ב-cookies וב-robots.txt אוטומטית.
- מעולה לאתרים סטטיים: מושלם לדפים שמרונדרים בצד השרת, ל-API-ים, או כשאתם רוצים לשלב גריפה בתוך backend ב-Go.
מגבלות: אין תמיכה מובנית ברינדור JavaScript (לאתרים דינמיים תצטרכו לשלב אותו עם משהו כמו Chromedp), ותצטרכו לדעת Go.
5. MechanicalSoup: הטוב ביותר לאוטומציה פשוטה של טפסים

היא ספריית Python שמגשרת בין בקשות HTTP פשוטות לבין אוטומציית דפדפן מלאה.
למה MechanicalSoup?
- אוטומציה של טפסים: נכנסים בקלות, ממלאים טפסים ושומרים סשנים — מצוין לגריפה מאחורי אימות.
- קל משקל: משתמשת ב-Requests וב-BeautifulSoup מאחורי הקלעים, כך שהיא מהירה וקלה להגדרה.
- מעולה לאתרים אינטראקטיביים: אם אתם צריכים לשלוח טפסי חיפוש או לגרוף נתונים אחרי התחברות, MechanicalSoup היא בחירה מצוינת ().
מגבלות: אין הרצת JavaScript, ולכן זה לא יעבוד על אתרים כבדי JS. מתאים בעיקר לדפים סטטיים או מרונדרים בצד השרת עם אינטראקציות פשוטות.
6. Puppeteer: הטוב ביותר לאתרים דינמיים וכבדי JavaScript
הוא הסכין השווייצרית לגריפה של אתרים מודרניים וכבדי JavaScript. זו ספריית Node.js שמעניקה לכם שליטה מלאה על דפדפן Chrome headless.
למה Puppeteer?
- מטפל בתוכן דינמי: גורף SPAs, גלילה אינסופית ודפים שטוענים נתונים דרך AJAX ().
- הדמיית משתמש: לוחץ על כפתורים, ממלא טפסים, מצלם מסכים ואפילו פותר CAPTCHAs (עם תוספים).
- אוטומציה חזקה: מעולה לבדיקות, ניטור וגריפה של כל מה שמשתמש אמיתי יכול לראות.
מגבלות: צורך משאבים רבים (מריץ מופעי Chrome מלאים), איטי יותר מסורקי HTTP בלבד, והסקיילינג דורש חומרה חזקה או אורכסטרציה בענן.
7. Wget: הטוב ביותר להורדות מהירות משורת הפקודה

הוא כלי שורת הפקודה הקלאסי להורדת אתרים וקבצים סטטיים.
למה Wget?
- פשטות: מוריד אתרים או תיקיות שלמות בפקודה אחת — בלי לכתוב קוד.
- מהירות: כתוב ב-C, ולכן הוא מהיר ויעיל.
- מעולה לתוכן סטטי: מושלם לאתרי תיעוד, בלוגים או הורדות קבצים בכמות גדולה ().
מגבלות: אין הרצת JavaScript או טיפול בטפסים, והוא מוריד דפים גולמיים ולא נתונים מובנים. תחשבו עליו כעל שואב אבק דיגיטלי לאתרים סטטיים.
8. HTTrack: הטוב ביותר לגלישה לא מקוונת (ללא קוד)
הוא בן הדוד הידידותי למשתמש של Wget, ומציע ממשק גרפי לשיקוף אתרים.
למה HTTrack?
- פשטות של GUI: אשף שלב-אחר-שלב הופך אותו לנגיש גם למשתמשים לא טכניים.
- גלישה לא מקוונת: מתאים את הקישורים כך שתוכלו לגלוש באתר המשוקף מקומית.
- מעולה לארכוב: מושלם לחוקרים, משווקים או לכל מי שרוצה תמונת מצב של אתר בלי לכתוב קוד ().
מגבלות: אין תמיכה בתוכן דינמי, הוא יכול להיות איטי באתרים גדולים, והוא לא מיועד לחילוץ נתונים מובנים.
9. StormCrawler: הטוב ביותר לגריפה מבוזרת בזמן אמת

הוא הסורק המודרני והמבוזר לצוותים שצריכים נתוני אינטרנט בזמן אמת ובקנה מידה גדול.
למה StormCrawler?
- גריפה בזמן אמת: בנוי על Apache Storm, ולכן הוא מעבד נתונים כזרמים — מעולה לניטור חדשות או למנועי חיפוש ().
- מודולרי וסקיילבילי: אפשר להוסיף רכיבי parsing, indexing ו-bolts של עיבוד מותאם אישית לפי הצורך.
- משמש את Common Crawl: מניע את מאגר החדשות של אחד מארכיוני הרשת הפתוחה הגדולים ביותר.
מגבלות: דורש פיתוח Java וקלאסטר Storm, ולכן הוא מתאים בעיקר לצוותים עם ניסיון במערכות מבוזרות. מוגזם לפרויקטים קטנים.
השוואת האלטרנטיבות הפתוחות-בקוד ל-Firecrawl: איזה מתחרה חינמי מתאים לצרכים שלכם?
הנה מבט השוואתי על כל 9 הכלים:
| כלי | שימוש מיטבי | יתרונות מרכזיים | חסרונות | שפה / התקנה |
|---|---|---|---|---|
| Scrapy | סריקה בהיקף גדול ותדיר | חזק, סקיילבילי, קהילה ענקית | עקומת למידה תלולה, דורש Python | מסגרת Python |
| Apache Nutch | סריקה ארגונית בקנה מידה של אינטרנט | מונע Hadoop, מוכח בקנה מידה גדול | התקנה מורכבת, מבוסס אצוות | Java/Hadoop |
| Heritrix | סריקת ארכיון וציות | לכידת אתר מלאה, פלט WARC | כבד, בלי JS, ארכיונים גולמיים | יישום Java, ממשק אינטרנט |
| Colly | מפתחי Go, גריפה עתירת ביצועים | מהיר, API פשוט, מקביליות | בלי JS, דורש Go | ספריית Go |
| MechanicalSoup | אוטומציה של טפסים, גריפת התחברויות | קל משקל, ניהול סשנים | בלי JS, היקף מוגבל | ספריית Python |
| Puppeteer | אתרים דינמיים / כבדי JS | שליטה מלאה בדפדפן, אוטומציה | צורך משאבים, דורש Node.js | ספריית Node.js |
| Wget | הורדת אתר סטטי, גישה לא מקוונת | פשוט, מהיר, CLI | בלי JS, דפים גולמיים | כלי שורת פקודה |
| HTTrack | משתמשים לא טכניים, ארכוב אתרים | GUI, גלישה לא מקוונת קלה | בלי JS, איטי באתרים גדולים | יישום שולחני (GUI) |
| StormCrawler | סריקה מבוזרת בזמן אמת | סקיילבילי, מודולרי, בזמן אמת | נדרש ידע ב-Java/Storm | קלאסטר Java/Storm |
האם כדאי לבנות סורק משלכם או להשתמש בחלופה פתוחה-בקוד קיימת ל-Firecrawl?
הנה האמת הכנה: לבנות סורק משלכם נשמע כיף — עד שאתם טובעים בתחזוקה, פרוקסים וכאבי ראש של מניעת בוטים. הכלים הפתוחים-בקוד שלמעלה מרכזים שנות ניסיון שנצברו בעמל וידע קהילתי. לפי דוחות בתעשייה, השימוש בפתרונות קיימים הוא הדרך המהירה והאמינה ביותר להשיג תוצאות ולהימנע מלהמציא את הגלגל מחדש ().
- אמצו קוד פתוח אם: הצרכים שלכם תואמים למה שכבר קיים, אתם רוצים לצמצם זמן פיתוח, ואתם מעריכים תמיכת קהילה.
- בנו משלכם אם: יש לכם דרישות באמת ייחודיות, מומחיות עמוקה בתוך הארגון, והגריפה היא ליבת העסק.
עם זאת, קוד פתוח הוא לא באמת "חינם" כשמחשבים את עלות זמן ההנדסה, תחזוקת השרתים והעדכונים התכופים שנדרשים כדי להתמודד עם מנגנוני חסימת גריפה. אם אתם רוצים את היתרונות של סורק חזק בלי לכתוב קוד, יש עוד אפשרות אחת.
בונוס: כשקוד פתוח נהיה מורכב מדי, נסו את Thunderbit
למרות שהכלים שמנינו למעלה מדהימים למפתחים, לכולם יש מגבלות משותפות: הם דורשים ידע בקוד, הם מתקשים עם מנגנוני anti-bot דינמיים מבוססי AI, והם דורשים תחזוקה שוטפת.
היא ההמלצה שלי לכל מי שצריך לעקוף את המגבלות האלה. היא מגשרת על הפער בין גריפה עוצמתית לבין קלות שימוש.
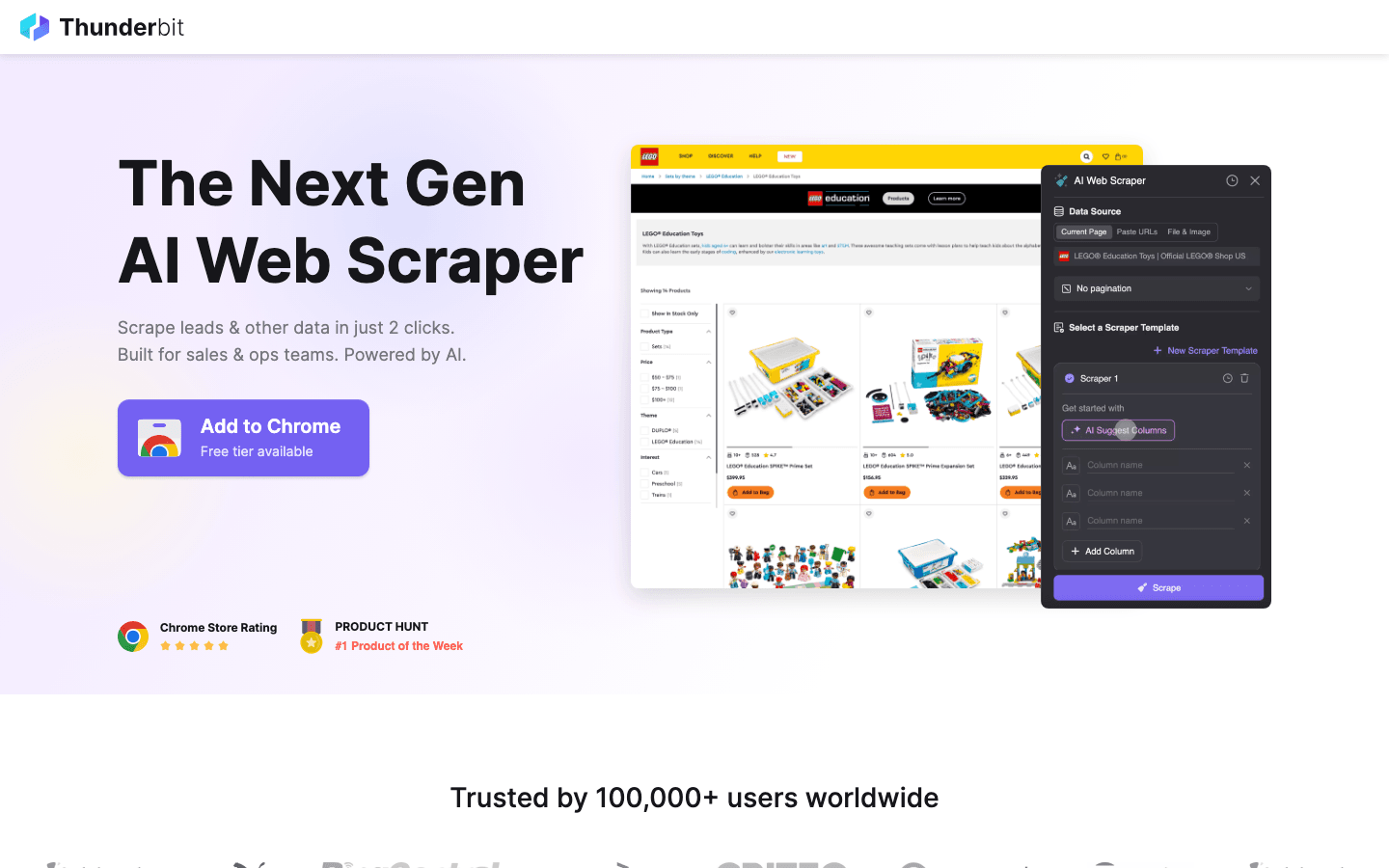
למה לשקול את Thunderbit במקום קוד פתוח?
- בלי קוד בכלל: בניגוד ל-Scrapy או Puppeteer, Thunderbit היא תוסף Chrome מבוסס AI. לוחצים על "AI Suggest Fields", והוא בונה בשבילכם את הסורק.
- מטפלת בדברים הקשים: תוכן דינמי, גלילה אינסופית ו-pagination מטופלים אוטומטית על ידי AI, וכך אתם חוסכים שעות של כתיבת סקריפטים מותאמים אישית.
- ייצוא מיידי: עוברים מאתר ל-Excel, Google Sheets או Notion בשתי לחיצות.
- בלי תחזוקה: לא צריך לעדכן קוד כשהאתר משנה את הפריסה שלו — ה-AI של Thunderbit מסתגל בשבילכם.
אם אתם אנשי מכירות, משווקים או חוקרים שרוצים נתונים עכשיו בלי ללמוד Python או Go, Thunderbit היא ההשלמה המושלמת לכלים הפתוחים-בקוד שברשימה הזו.
רוצים לראות את זה בפעולה? ונסו בעצמכם.
סיכום: איך למצוא את סורק האתרים המתארח-עצמית הנכון לשנת 2026
עולם האלטרנטיבות הפתוחות-בקוד ל-Firecrawl עשיר מאי פעם. בין אם אתם צריכים את הסקייל הגולמי של Scrapy או Nutch, ובין אם אתם זקוקים לנאמנות הארכוב של Heritrix, יש פתרון לכל תרחיש עסקי. המפתח הוא להתאים את הכלי לצרכים שלכם — לא להנדס יתר על המידה אם אתם רק צריכים שליפת נתונים מהירה, ולא להשקיע פחות מדי אם אתם סורקים בקנה מידה של האינטרנט.
וזכרו, אם המסלול הפתוח-בקוד מתגלה כטכני מדי או גוזל זמן רב מדי, כלים מבוססי AI כמו Thunderbit מוכנים לקחת את העומס.
מוכנים להתחיל? הריצו את Scrapy לפרויקט הנתונים הגדול הבא שלכם, או לגריפה פשוטה ומבוססת AI. אם אתם רעבים לעוד טיפים על גריפת אתרים, בקרו ב- לעומקים ולטוטוריאלים.
שאלות נפוצות
1. מה היתרון המרכזי בשימוש בחלופות פתוחות-בקוד ל-Firecrawl?
חלופות פתוחות-בקוד מציעות גמישות, חיסכון בעלויות ויכולת לארח-עצמית ולהתאים אישית את הסורק. כך נמנעים מתלות בספק אחד ונהנים מתמיכה ועדכונים של קהילה פעילה.
2. איזה כלי הכי מתאים למשתמשים לא טכניים שצריכים תוצאות מהירות?
הוא בחירה פתוחה-בקוד מצוינת לגלישה לא מקוונת. עם זאת, לחילוץ נתונים מובנים (כמו טבלאות Excel), אנחנו ממליצים על כלי הבונוס בזכות יכולות ה-AI שלו.
3. איך מטפלים באתרים דינמיים וכבדי JavaScript?
הוא הבחירה הטובה ביותר — הוא שולט בדפדפן אמיתי, ולכן יכול לגרוף כל מה שמשתמש יכול לראות, כולל SPAs ותוכן שנטען ב-AJAX.
4. מתי כדאי להשתמש בסורק כבד כמו Apache Nutch או StormCrawler?
אם אתם צריכים לסרוק מיליוני דפים לאורך דומיינים רבים, או זקוקים לגריפה מבוזרת בזמן אמת (למשל למנועי חיפוש או לניטור חדשות), הכלים האלה בנויים לסקייל ולאמינות.
5. מה עדיף — לבנות סורק משלכם או להשתמש בפתרון פתוח-בקוד קיים?
עבור רוב הצוותים, שימוש והתאמה של כלי פתוח-בקוד קיים הוא מהיר, זול ואמין יותר. בנו משלכם רק אם יש לכם צרכים מאוד מיוחדים ומשאבים לתחזק אותו לאורך זמן.
גריפה נעימה — ושכל הנתונים שלכם תמיד יהיו טריים, מובנים ומוכנים לפעולה.
למידע נוסף