
מחקר המבוסס על סריקה שבחן איך אתרי תעבורה גבוהה מפרסמים הנחיות קריאות-מכונה עבור מודלי שפה גדולים, איך נראות ההטמעות המוקדמות, ולמה מדידת האימוץ דורשת יותר מספירת תגובות HTTP 200.
- מערך נתונים:
data/llms_probe_results_top_10000.csv - רשימת Tranco הורדה: 6 במאי 2026
- היקף:
/llms.txtו-/llms-full.txtברמת השורש
מדדי מפתח
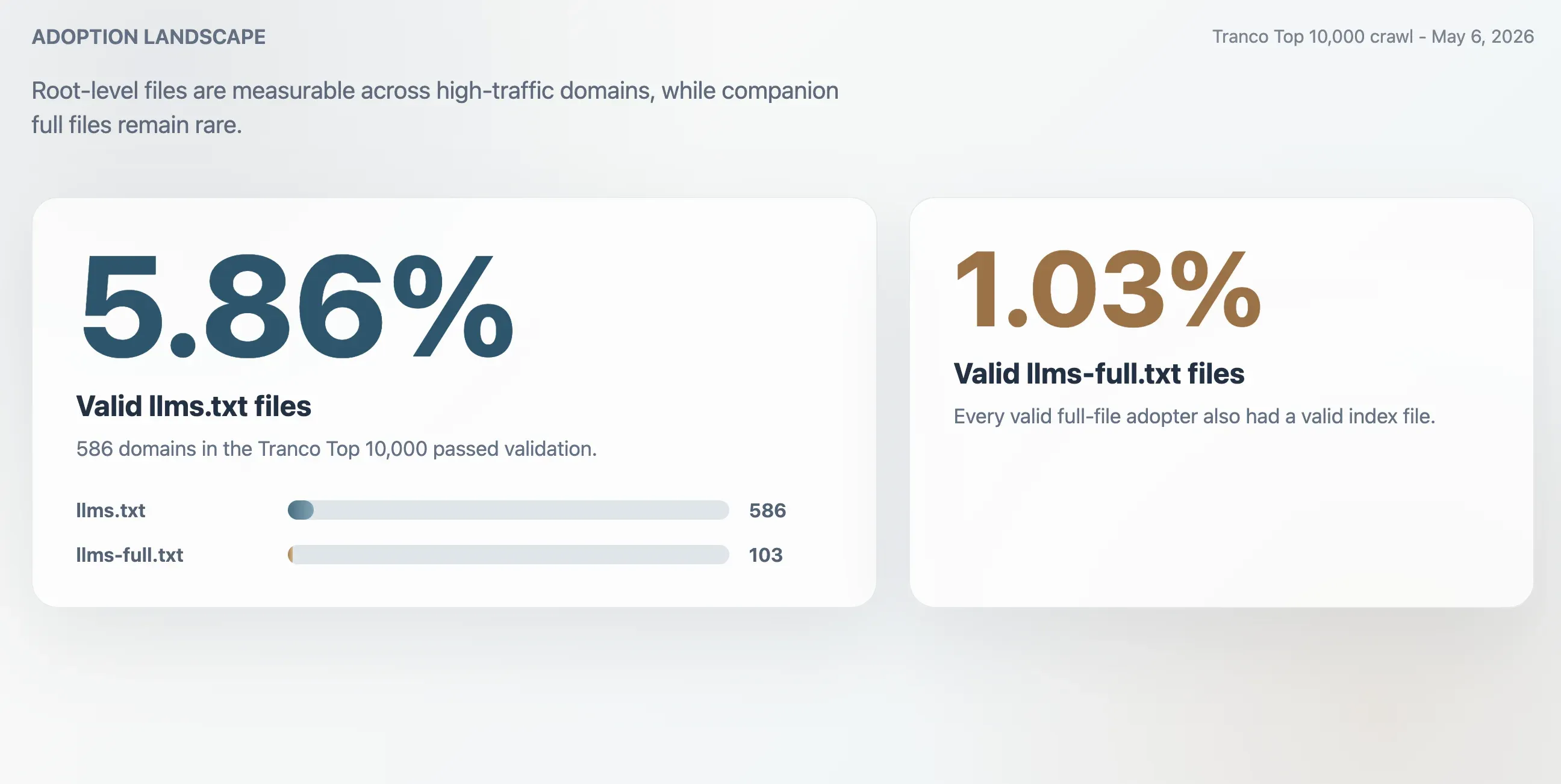
- 5.86%: אימוץ תקף של
llms.txtב-Top 10,000 של Tranco, כלומר 586 דומיינים. - 1.03%: אימוץ תקף של
llms-full.txt, כלומר 103 דומיינים. לכל מאמץ תקף של הקובץ המלא היה גם קובץ אינדקס תקף. - 63.51%: שיעור תגובות HTTP 200 עבור
/llms.txtשנכשלו באימות. - 2.74x: הערכת יתר בקירוב אם מודדים אימוץ רק לפי תגובות HTTP 200 גולמיות.
תקציר מנהלים
llms.txt עדיין נוהג אינטרנטי מוקדם, אבל הוא כבר לא ניסוי שולי. בסריקה מ-6 במאי 2026 של 10,000 הדומיינים המובילים ב-Tranco, המחקר מצא 586 קובצי llms.txt תקפים, כלומר שיעור אימוץ נצפה של 5.86%. קובץ llms-full.txt המשלים היה הרבה פחות נפוץ: ל-103 דומיינים היה קובץ מלא תקף, כלומר שיעור אימוץ של 1.03%.
הממצא המתודולוגי החשוב ביותר הוא שקודי מצב הם אינדיקטור גרוע לאימוץ. הסורק זיהה 1,606 תגובות HTTP 200 עבור /llms.txt, אך רק 586 עברו אימות. 1,020 הנותרים היו ברובם הפניות לא רלוונטיות, דפי HTML כלליים, גופים ריקים או תגובות לא תקינות אחרות. סורק נאיבי שסופר כל תגובת 200 כאימוץ היה מעריך יתר את האימוץ התקף בערך פי 2.74.
בקרב המאמץ התקף, איכות ההטמעה גבוהה יותר ממה שנרטיב של מצייני מקום בלבד היה מציע. גודל הקובץ התקף החציוני היה כ-7.1 KB, 61.77% מהקבצים התקפים היו גדולים מ-5 KB, 70.82% הכילו שישה מקטעי Markdown או יותר, ו-77.47% הכילו 11 קישורי Markdown או יותר. קבוצת המאמץ המוקדם כוללת את Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog ו-Cloudinary.
llms.txtמובן הכי טוב כאיתות הסברי וניווטי למערכות AI, ולא כתחליף ל-robots.txt. הערך שלו אינו רק עצם קיומו של הקובץ, אלא האם הוא עוזר למכונות למצוא מידע סמכותי, תמציתי ועדכני.
הקשר: הרשת מוסיפה אותות המיועדים ל-AI
אתרים משתמשים כבר שנים ב-robots.txt כדי לבטא העדפות סריקה, ב-sitemap.xml כדי לשפר גילוי כתובות URL, ובנתונים מובְנים כדי לעזור למנועי חיפוש ולמערכות פלטפורמה לפרש דפים. AI גנרטיבי מציג בעיה אחרת. תוכן עשוי לשמש לאימון, לשליפה, לסיכום, לגלישה סוכנתית, לסיוע בקוד, לתמיכת לקוחות וליצירת תשובות. זה יוצר שני צרכים במקביל: מפרסמים רוצים יותר שליטה על שימוש אוטומטי, אבל הם גם רוצים שמערכות AI ימצאו את המידע הקנוני הנכון כשהן כן מתקשרות עם האתר.
ההצעה המקורית ל-llms.txt, שהציג Jeremy Howard בשנת 2024, מגדירה את הקובץ כמסמך Markdown שממוקם בשורש האתר ומספק מידע ידידותי ל-LLM בזמן האינפרנס. ההצעה טוענת שדפי HTML כוללים לעיתים ניווט, פרסום, סקריפטים ורעש אחר שמקשים על מודלים לשוניים לעבד אותם. קובץ Markdown תמציתי יכול לכוון מודלים אל הדפים, התיעוד, ה-API, הדוגמאות, המדיניות ומידע המוצר החשובים ביותר.
מחקר אינטרנט חיצוני מספק את הרקע הרחב יותר. “Consent in Crisis” של Data Provenance Initiative מתאר עלייה מהירה במגבלות הקשורות ל-AI בתוך robots.txt ובתנאי שימוש, וטוען שמנגנוני ההסכמה הקיימים ברשת לא תוכננו לשימוש חוזר בקנה מידה גדול בנתוני AI. Cloudflare Radar AI Insights גם הפכו דפוסי AI crawler ו-robots.txt לגלויים ברמת Top 10,000 הדומיינים. בסביבה הזו, llms.txt נמצא בצד הבונה של איתות AI: לא “אל תסרוק את זה”, אלא “אם אתה צריך להבין את האתר, התחל כאן”.
ראיות חיצוניות והוויכוח על האימוץ
הדיון הציבורי סביב llms.txt מתחלק בין שתי טענות. הטענה האופטימית היא שהקובץ נותן למערכות AI נתיב נקי ויעיל יותר לתוכן סמכותי. הטענה הספקנית היא שאף ספק LLM מרכזי לא התחייב בפומבי להשתמש בו כאות דירוג, סריקה או ציטוט, ולכן מפרסמים לא צריכים לצפות לרווחי תעבורה מהקובץ לבדו. שלושת המקורות החיצוניים שנבחנו לעדכון הזה תומכים במסקנה מורכבת יותר: llms.txt הוא תשתית שימושית, אבל הראיות להשפעה ישירה על תעבורה עדיין מוגבלות ותלויות הקשר.
מדדי אימוץ חיצוניים משתנים במהירות
המדד של Rankability לאימוץ דיווח על שיעור אימוץ של 0.3% בקרב 1,000 האתרים המובילים נכון ל-22 ביוני 2025, כלומר 3 מתוך 1,000 אתרים. הוא מתאר סריקה אוטומטית חודשית של domain.com/llms.txt, עם אימות שמוציא הפניות ותגובות HTML. המתודולוגיה הזו דומה בכיוון לגישת האימות השמרנית של המחקר הנוכחי.
ההבדל בתוצאות גדול: המחקר הזה מצא 75 קובצי llms.txt תקפים ב-Top 1,000 של Tranco ב-6 במאי 2026, כלומר 7.50%. אין להתייחס לשני המספרים כסדרת זמן נוקשה, משום שמקור הדירוג, פרטי ההטמעה, לוגיקת האימות ותזמון הסריקה עשויים להיות שונים. עדיין, הניגוד מרמז שהאימוץ השתנה באופן מהותי בין אמצע 2025 למאי 2026, במיוחד בקרב אתרי מפתחים, SaaS, ענן, אבטחה ותיעוד.
| מקור | צילום מצב | מדגם | אימוץ תקף מדווח | פרשנות |
|---|---|---|---|---|
| Rankability | 22 ביוני 2025 | 1,000 האתרים המובילים | 0.3% | מדד ציבורי מוקדם שהראה אימוץ מינימלי באמצע 2025. |
| המחקר הזה | 6 במאי 2026 | Top 1,000 של Tranco | 7.50% | סריקה מאוחרת יותר שמראה אימוץ גלוי באתרים עתירי תעבורה. |
| המחקר הזה | 6 במאי 2026 | Top 10,000 של Tranco | 5.86% | מדגם רחב יותר שמראה שהאימוץ ניתן למדידה אך עדיין אינו מיינסטרים. |
ניסויי תעבורה נשארים מעורבים
Search Engine Land פרסם בינואר 2026 ניתוח של 10 אתרים שעקב אחריהם 90 יום לפני ו-90 יום אחרי ההטמעה. המאמר דיווח ששני אתרים ראו עליות בתעבורת AI של 12.5% ו-25%, שמונה לא ראו שיפור מדיד, ואחד ירד ב-19.7%. הפרשנות המרכזית הייתה זהירות סיבתית: לשני סיפורי ההצלחה לכאורה היו גם השקות של תבניות חדשות, בנייה מחדש של מרכזי משאבים, הוספת טבלאות השוואה ניתנות לחילוץ, חשיפה תקשורתית, תיקון בעיות טכניות או פרסום תוכן חדש בסגנון FAQ. במסגרת הזו, llms.txt תיעד עבודה טובה יותר על תוכן וטכנולוגיה; לא נראה שהוא גרם לצמיחה לבדו.
ניסוי הבלוג האישי של Renat Alimbekov הגיע למסקנה חיובית יותר מתוך תצפית קטנה יותר ברמת אתר. הוא השווה שתי תקופות של ארבעה חודשים ב-Yandex.Metrica לאחר הוספה של llms.txt וגם llms-full.txt. סשני ההפניה מ-LLM עלו מ-75 ל-92, עלייה של 23%, בעוד שהמשתמשים עלו מ-51 ל-64. סשנים מ-Perplexity עלו מ-29 ל-55, בעוד שסשנים מ-ChatGPT ירדו מ-31 ל-26. באותו פוסט מצוין גם שהתעבורה הכוללת מהפניות גדלה מהר יותר, מ-160 ל-290 סשנים, כך שחלקם של סשני ה-LLM ירד מ-47% ל-32%.
| סוג הראיה | התוצאה שנצפתה | הסתייגות מרכזית | איך זה משפיע על הדוח הזה |
|---|---|---|---|
| מחקר לפני/אחרי של Search Engine Land על 10 אתרים | שני אתרים עלו, שמונה לא הראו שינוי מדיד, אחד ירד. | במקרים החיוביים היו במקביל שינויים בתוכן, יח״צ וטכנולוגיה. | תומך בהתייחסות ל-llms.txt כתשתית, לא כמנוף צמיחה עצמאי. |
| תצפית לפני/אחרי בבלוג האישי של Alimbekov | סשני ההפניה מ-LLM עלו ב-23% בתקופה שאחרי. | אין קבוצת ביקורת; התעבורה הכוללת מהפניות עלתה ב-81%, וחלק ה-LLM ירד. | מרמז על יתרון אפשרי לבלוגים טכניים, במיוחד דרך Perplexity, אבל הסיבתיות לא מבודדת. |
| מחקר האימוץ המבוסס על סריקה הזה | 586 קבצים תקפים והטמעות מובנות רבות. | מודד נוכחות ומבנה, לא השפעה על תעבורה בהמשך. | מראה אימוץ ובשלות הטמעה, אבל לא ROI בפני עצמו. |
מה הוויכוח מבהיר
הראיות החיצוניות מחדדות את הפרשנות של מערך הנתונים הזה. קובץ llms.txt מובנה היטב יכול להפחית חיכוך בניתוח מכונה, במיוחד עבור תיעוד מפתחים, חומרי API ותוכן בסיס ידע. אבל מקרי התעבורה החזקים ביותר עדיין נראים תלויים בתוכן שהוא שימושי, ניתן לחילוץ, סמכותי וניתן לגילוי מחוץ לקובץ. לכן, השאלה המעשית אינה “האם llms.txt חשוב?” במנותק. השאלה היא האם הקובץ הוא חלק ממערכת תוכן רחבה יותר שניתן לקרוא אותה על ידי AI.
פרשנות מעודכנת: יש ליישם את
llms.txtכתשתית זולה הפונה ל-AI. לא כדאי להציג אותו כתחליף לתיעוד טוב יותר, תוכן מובנה, נגישות טכנית, ציטוטים, קישורים או סמכות מותג.
נסה את Thunderbit לגריפת אתרי אינטרנט עם AI
מתודולוגיה
המחקר השתמש ב-Top 10,000 הדומיינים של Tranco כדגימה שלו. Tranco הוא דירוג מחקרי של אתרים מובילים, שנועד להיות יציב יותר ועמיד יותר למניפולציות מאשר הרבה רשימות מובילות מסורתיות. קובץ המקור של Tranco הורד ב-6 במאי 2026, עם חותמת Last-Modified של המקור ב-5 במאי 2026 בשעה 22:17:59 GMT.
הסורק בדק שני נתיבים ברמת השורש עבור כל דומיין:
https://example.com/llms.txt, עם גיבוי HTTP כשנדרש.https://example.com/llms-full.txt, עם גיבוי HTTP כשנדרש.
עבור כל בדיקה, הסורק רשם קוד מצב, כתובת URL סופית, שיטת הבאה, בתים של תגובה, סוג תוכן, הודעת שגיאה, זמן שחלף ותוצאת אימות. גופי תגובה מוצלחים נשמרו תחת raw_llms_txt/ לצורך סקירה וניתוח משני.
כללי אימות
תגובה נספרה כקובץ תקף רק אם החזירה גוף מוצלח ולא נראתה כחלופת אתר גנרית. נתיב ה-URL הסופי היה חייב להישאר /llms.txt או /llms-full.txt. גופים ריקים נדחו. מסמכי HTML ברורים ו-shells של אפליקציות נדחו. סוג התוכן שימש כראיה תומכת ולא ככלל היחיד, משום שמספר קטן של קבצים תקפים דמויי-טקסט הוגשו עם סוגי תוכן חריגים.
נוף האימוץ
הסריקה מצאה 586 קובצי llms.txt תקפים ב-Top 10,000 של Tranco. מכאן שיעור אימוץ תקף של 5.86%. הקובץ המשלים הקטן יותר, llms-full.txt, היה קיים ותקף ב-103 דומיינים, כלומר 1.03% מהמדגם.
| מדד | כמות | חלק מתוך Top 10,000 |
|---|---|---|
| דומיינים שנסרקו | 10,000 | 100.00% |
| קובצי llms.txt תקפים | 586 | 5.86% |
| קובצי llms-full.txt תקפים | 103 | 1.03% |
| תגובות HTTP 200 עבור /llms.txt | 1,606 | 16.06% |
| תגובות HTTP 200 שנדחו כלא תקפות | 1,020 | 10.20% |
האימוץ אינו רק עניין של אתרים גדולים
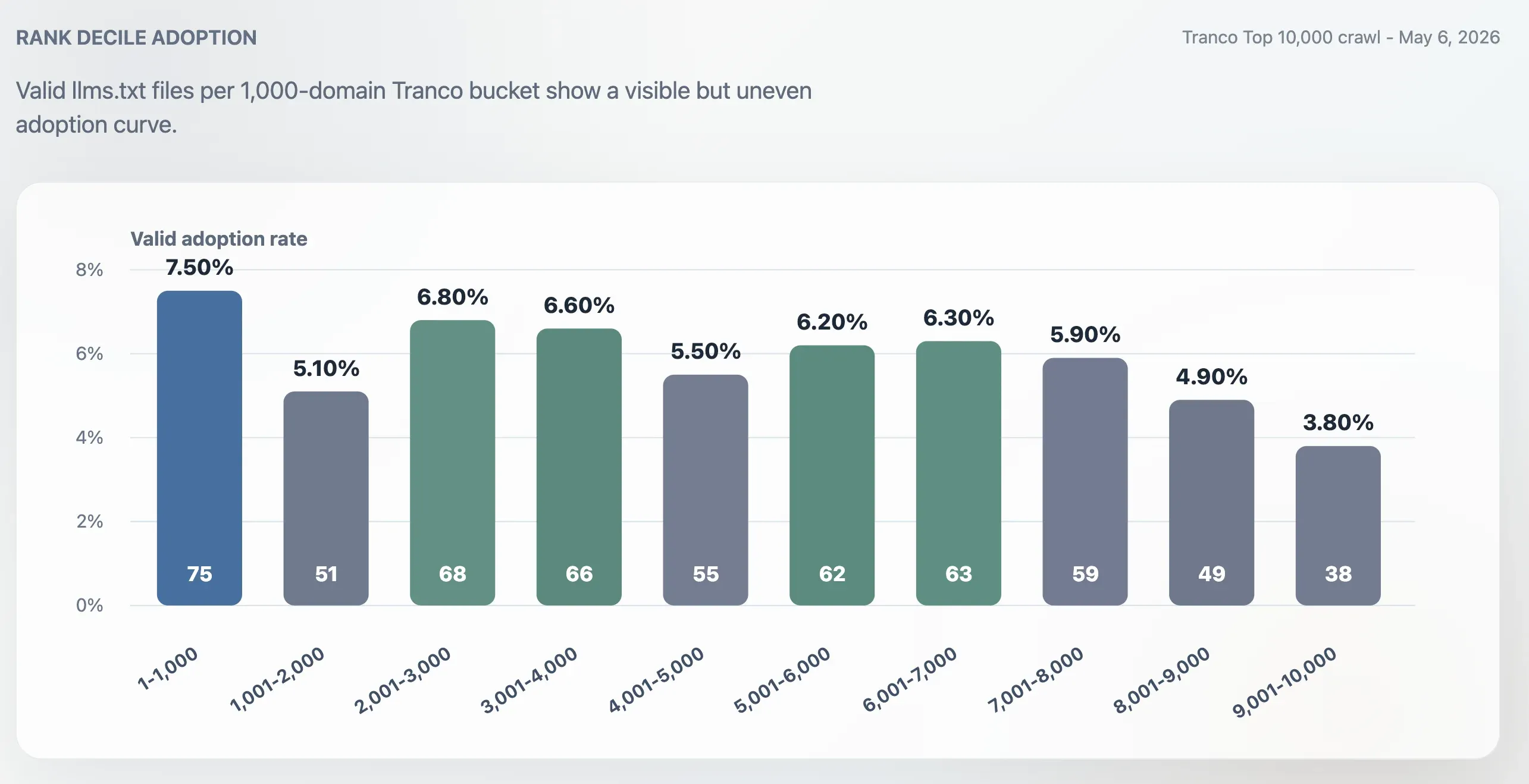
האימוץ היה גבוה יותר ב-Top 1,000 מאשר בכלל Top 10,000, אבל הוא לא היה מוגבל לאתרים הגדולים ביותר. שיעור האימוץ ב-Top 1,000 היה 7.50%. ה-bucket האחרון של 1,000 דומיינים, מקומות 9,001–10,000, ירד ל-3.80%. אמצע הדירוג נותר פעיל: ה-buckets של 2,001–3,000, 3,001–4,000, 5,001–6,000 ו-6,001–7,000 עמדו כולם סביב 6%.
מאמצים מוקדמים
המאמץ התקף המדורג הגבוה ביותר היה Cloudflare במקום 4 ב-Tranco. מאמצים מדורגים גבוהים נוספים כללו את Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink ו-OneSignal.
המאמצים האלה אינם אקראיים. הם נוטים להיות בעלי משטחי תיעוד גדולים, קווי מוצרים שדורשים הסבר, API או אקוסיסטמות מפתחים, תוכן תמיכה, דפי תמחור, חומרי אבטחה ופרטיות, ומספיק סמכות מותג כדי להתעניין באופן שבו מערכות AI מפרשות את האתר שלהם.
| דירוג | דומיין | גודל הקובץ | דפוס שנצפה |
|---|---|---|---|
| 4 | cloudflare.com | 4,225 B | אינדקס תמציתי של מוצר, מפתחים, חברה ותמחור. |
| 26 | azure.com | 47,037 B | כלים למפתחים, AI, מחשוב, אחסון, אבטחה, ניטור ומשאבים אופציונליים. |
| 28 | github.com | 27,108 B | גישה פרוגרמטית, Copilot, MCP, REST API, Actions, מאגרים וקישורי CLI. |
| 248 | stripe.com | 64,229 B | תשלומים, Connect, Checkout, Billing, Tax, Atlas, Radar ותיעוד למפתחים. |
| 265 | salesforce.com | 1.02 MB | קטלוג עצום של מוצרים וקישורים ל-Agentforce, בלי כותרות מקטעי Markdown. |
קטגוריות מאמצי Top 1,000
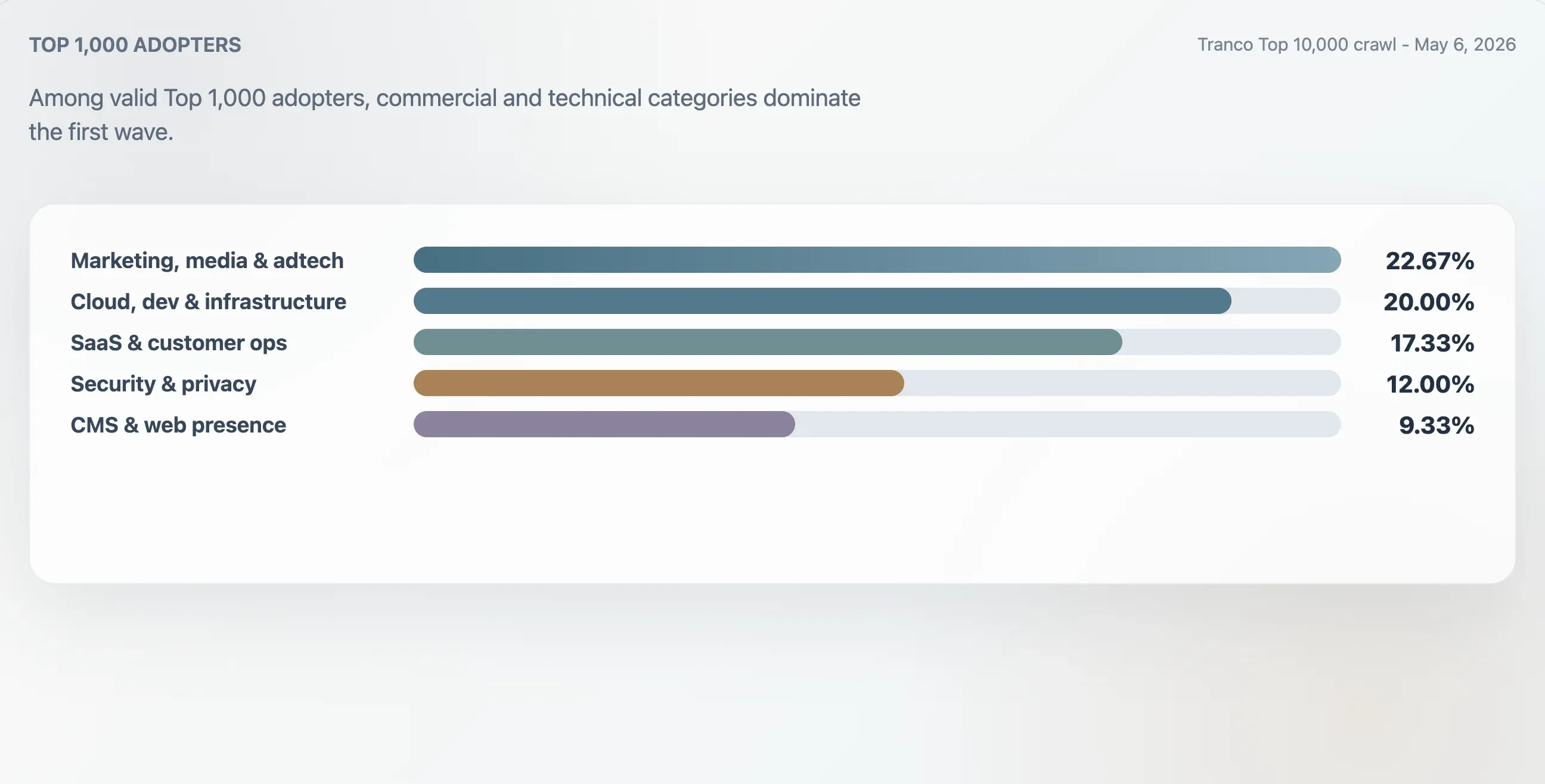
המחקר סיווג את 75 המאמץ התקפים ב-Top 1,000 של Tranco לפי הקשר הדומיין, כותרות ראשונות, מבנה הקובץ הגולמי ומילות מפתח בתוכן. הקבוצה הגדולה ביותר הייתה שיווק, מדיה ו-adtech עם 22.67%. אתרי ענן, מפתחים ותשתיות היוו 20.00%. אתרי SaaS, פרודוקטיביות ותפעול לקוחות היוו 17.33%. אתרי אבטחה, זהות ופרטיות היוו 12.00%.
| קטגוריה | דומיינים | חלק מתוך מאמצי Top 1,000 | ציון איכות חציוני | קישורים חציוניים |
|---|---|---|---|---|
| שיווק, מדיה ו-adtech | 17 | 22.67% | 94 | 25 |
| ענן, פיתוח ותשתיות | 15 | 20.00% | 94 | 62 |
| SaaS, פרודוקטיביות ותפעול לקוחות | 13 | 17.33% | 94 | 46 |
| אבטחה, זהות ופרטיות | 9 | 12.00% | 98 | 78 |
| CMS, אחסון ונוכחות אינטרנט | 7 | 9.33% | 100 | 24 |
דפוסי TLD
דומיינים ברמה העליונה אינם תוויות ענפיות, אבל הם כן רמזים כיווניים שימושיים. מבין TLDs עם לפחות 50 דומיינים במדגם, ל-.io היה שיעור האימוץ התקף הגבוה ביותר, 14.44%. אחריו .com עם 8.19%. אימוץ נמוך יותר ב-.gov, .edu ו-.net מרמז שקבוצת המאמץ המוקדם היא יותר מסחרית וטכנית מאשר מוסדית.
איכות ההטמעה
אימוץ תקף אינו אומר איכות הטמעה אחידה. חלק מהקבצים הם אינדקסים קצרים ומסודרים היטב. חלקם הם בעיקר פרוזה. חלקם הם קטלוגי קישורים גולמיים. חלקם הם מצייני מקום כמעט ריקים. חלקם הם dumps של תוכן בגודל רב-מגה-בייט שעשויים להיות שלמים אך יקרים לשליפה ולפירוש.
מבין קובצי llms.txt התקפים, 362 היו גדולים מ-5 KB, כלומר 61.77% מהמאמצים התקפים. הגודל החציוני של הקובץ היה כ-7.1 KB. גודל הקובץ ב-P90 היה 156 KB, ב-P95 היה 356 KB, ב-P99 היה 2.54 MB, והקובץ הגדול ביותר שנצפה היה 7.97 MB.
אותות תוכן נפוצים
סריקת מילות מפתח ברמת הקובץ מצאה שאתרים רבים אינם רק מפרסמים הצהרה; הם מכוונים את המודלים לחומר שימושי מבחינה תפעולית. מונחי תמיכה או עזרה הופיעו ב-70.31% מהקבצים התקפים. מונחי בלוג, מדריך או tutorial הופיעו ב-67.92%. מונחי אבטחה, פרטיות, ציות או תנאים הופיעו ב-61.43%. תמחור הופיע ב-53.92%, תיעוד ב-52.22%, מונחי API ב-33.96%, ואותות changelog או גרסאות שחרור ב-27.30%.
ניקוד איכות וטיפוסים
כדי לעבור מנוכחות לבשלות, המחקר יצר ציון הטמעה קל משקל. הציון מתחשב בסוג התוכן, גודל הקובץ, מבנה ה-Markdown, מספר הקישורים, כיסוי הנושאים ואותות אזהרה כמו היעדר כותרות, היעדר קישורי Markdown, סוגי תוכן חריגים, קבצים זעירים, קבצים גדולים מאוד והתנהגות של dump קישורים. זה לא תקן רשמי. זהו מודל ניקוד מחקרי להשוואת ההטמעות שנצפו.
באמצעות המודל הזה, 416 קבצים תקפים סווגו כאינדקסים מובנים חזקים, 107 כאינדקסים שימושיים, 24 כדקים או לא סדירים, ו-39 כסמליים או בעלי תועלת נמוכה. ניתוח טיפוסים נפרד מצא 296 אינדקסים מובנים, 113 קובצי טקסט מחולקים למקטעים, 63 קטלוגי קישורים, 52 אינדקסים דקים, 50 קבצים סמליים או מצייני מקום, ו-12 dumps ענקיים של תוכן.
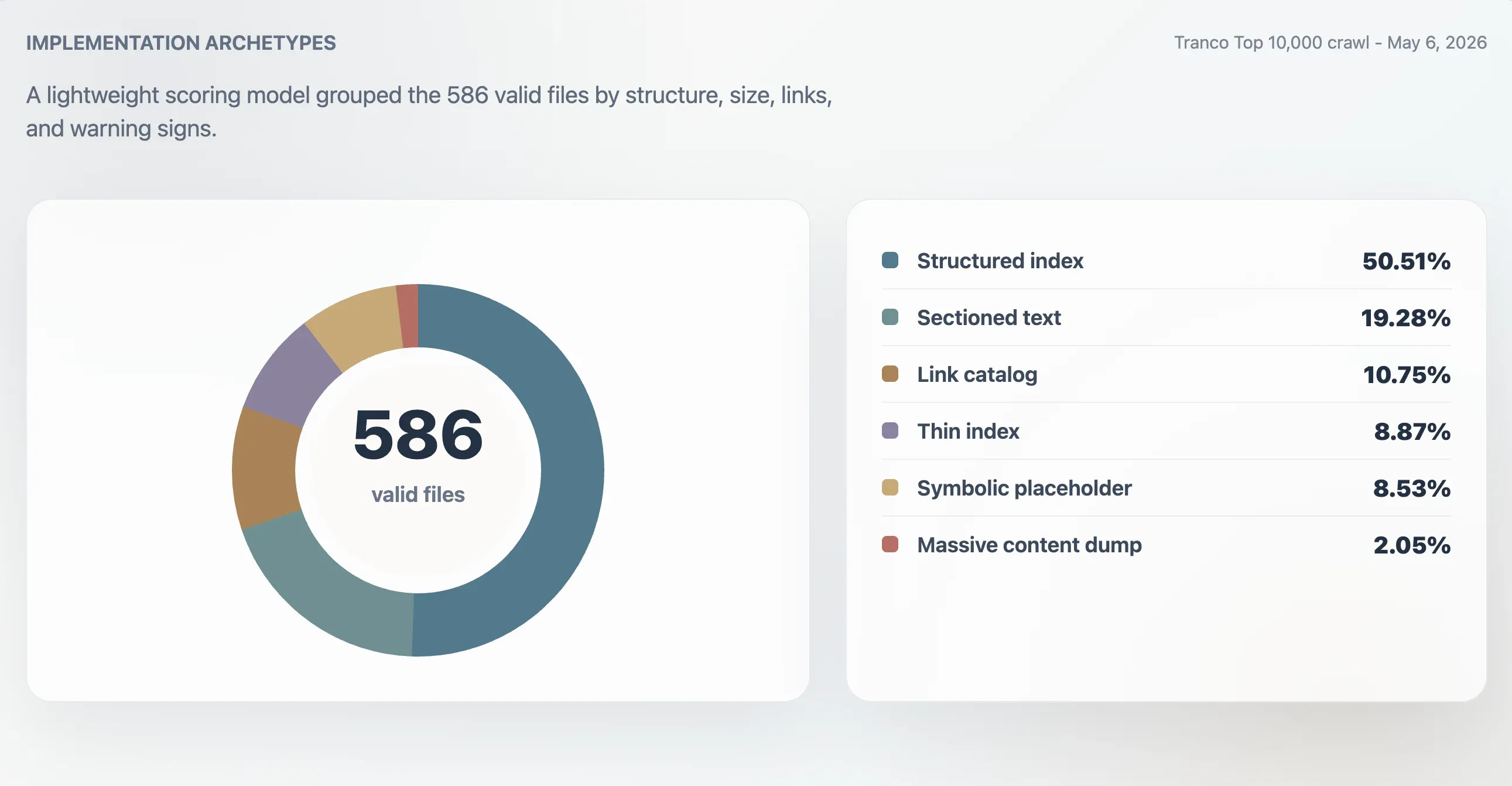
| טיפוס | דומיינים | חלק מהקבצים התקפים | ציון חציוני | גודל קובץ חציוני | קישורים חציוניים |
|---|---|---|---|---|---|
| אינדקס מובנה | 296 | 50.51% | 98 | 11,241 B | 61.5 |
| טקסט מחולק למקטעים | 113 | 19.28% | 78 | 4,718 B | 0 |
| קטלוג קישורים | 63 | 10.75% | 86 | 4,160 B | 23 |
| אינדקס דק | 52 | 8.87% | 66 | 2,814 B | 0 |
| סמלי או מציין מקום | 50 | 8.53% | 27 | 15 B | 0 |
| dump תוכן ענק | 12 | 2.05% | 74 | 2.84 MB | 7,259.5 |
למאמצים הגדולים יש הטמעות צפופות יותר
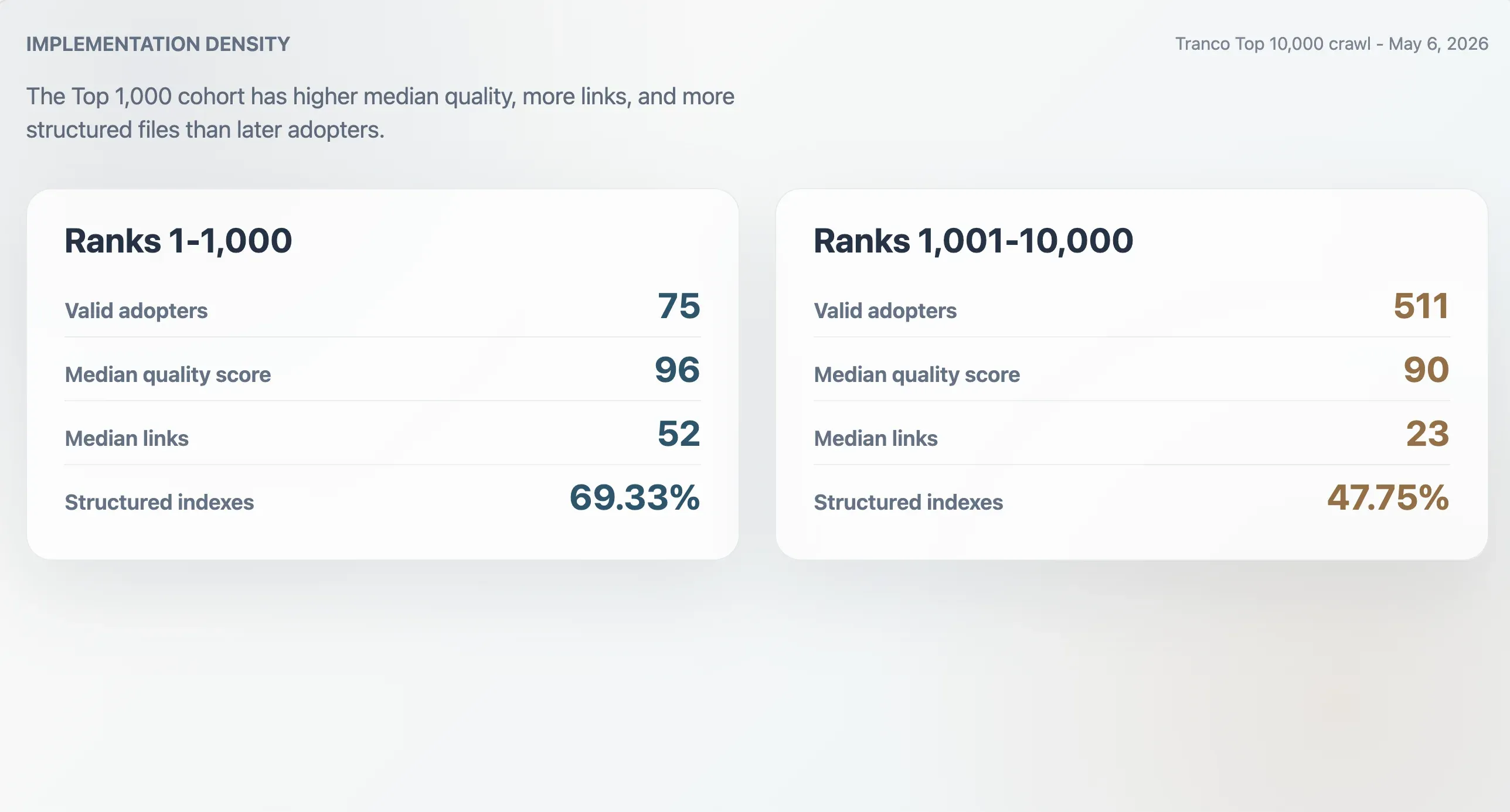
ל-75 המאמץ התקפים ב-Top 1,000 של Tranco היה ציון איכות חציוני של 96, גודל קובץ חציוני של 9,068 בתים, מספר קישורי Markdown חציוני של 52 ומספר מקטעים חציוני של 11. ל-511 המאמץ המדורגים 1,001–10,000 היו חציונים נמוכים יותר: ציון 90, גודל קובץ 6,506 בתים, 23 קישורי Markdown ו-9 מקטעים. המאמץ ב-Top 1,000 היו גם סבירים יותר להיות אינדקסים מובנים: 69.33% לעומת 47.75% בקבוצה המאוחרת יותר.
בעיית החיוביות הכוזבות

סיכון המדידה הגדול ביותר הוא חיוביות כוזבות. מתוך 1,606 הדומיינים שהחזירו HTTP 200 עבור /llms.txt, 1,020 נכשלו באימות. הסיבה הלא תקינה הנפוצה ביותר הייתה הפניה לא רלוונטית, עם 618 מקרים. עוד 367 תגובות היו מסמכי HTML כלליים. 29 החזירו גוף ריק, ושש היו תגובות לא תקינות אחרות או לא מסווגות.
זה חשוב משום שאתרים גדולים רבים מנתבים נתיבים לא מוכרים לדפי התחברות, לדפי בית, ל-shells של אפליקציות, לדפים אזוריים, למסכי הסכמה או לחלופות שיווקיות. תגובות כאלה יכולות להיראות תקינות לסורק המבוסס על קוד מצב, אך אינן מכילות שום אות תקף של llms.txt.
llms-full.txt: נדיר יותר ולא אחיד יותר
הקובץ המשלים llms-full.txt היה הרבה פחות נפוץ מ-llms.txt. הסריקה מצאה 103 קבצים מלאים תקפים, השווים ל-17.58% ממאמצי llms.txt התקפים ול-1.03% מכלל מדגם Top 10,000.
ההטמעות של הקובץ המלא היו לא אחידות. מבין 103 המאמץ עם שני הקבצים, ל-57 היה קובץ llms-full.txt גדול יותר מקובץ האינדקס, אבל ל-46 היה קובץ מלא שלא היה גדול יותר מקובץ האינדקס או שהיה קטן מ-100 בתים. יחס הגודל החציוני בין הקובץ המלא לאינדקס היה 1.43, אבל מקרי הקצה היו הרבה יותר גבוהים. הקובץ המלא של Supabase היה בערך פי 7,139 מגודל קובץ האינדקס שלו. ל-Made-in-China.com היה קובץ מלא בגודל 89.89 MB.
| דומיין | llms.txt | llms-full.txt | יחס |
|---|---|---|---|
| made-in-china.com | 4.49 MB | 89.89 MB | 20.0x |
| sendbird.com | 281.86 KB | 11.99 MB | 42.5x |
| taboola.com | 286.78 KB | 11.73 MB | 40.9x |
| supabase.co | 1.26 KB | 8.98 MB | 7,139.3x |
| neon.tech | 27.44 KB | 5.01 MB | 182.7x |
המלצה: פרסמו
llms-full.txtרק כאשר לאתר כבר יש צינור תיעוד יציב, משמעת גרסאות וסיבה ברורה לחשוף כמויות גדולות של תוכן בקובץ יחיד שניתן לקריאה על ידי מכונה.
llms.txt, robots.txt ו-sitemap.xml
אין להתייחס ל-llms.txt כאל robots.txt חדש. שניהם קבצים ניתנים לקריאה על ידי מכונה ברמת השורש, אבל הם מתקשרים דברים שונים. robots.txt הוא אות של העדפות סריקה ובקרת גישה. sitemap.xml הוא אות לגילוי כתובות URL. llms.txt הוא אות הסברי וניווטי.
| אות | תפקיד ראשי | קורא טיפוסי | הפרשנות במחקר הזה |
|---|---|---|---|
robots.txt | הגדרת העדפות סריקה והגבלות ברמת נתיב. | סורקי חיפוש, סורקי AI, סורכי ארכיון, בוטים כלליים. | אות ניהול וגישה. |
sitemap.xml | רשימת כתובות URL שניתן לגלות עבור מערכות אינדוקס. | מנועי חיפוש וצינורות אינדוקס. | אות גילוי. |
llms.txt | אספקת הקשר תמציתי לאתר, קישורים חשובים, תיעוד, API, דוגמאות והפניות למדיניות. | יישומי LLM, סוכני AI, כלי מפתחים, מערכות שליפה. | אות הסבר וניווט. |
המלצות
עבור אתרים ששוקלים llms.txt, ההטמעות החזקות ביותר במערך הנתונים הזה והראיות החיצוניות לתעבורה מצביעות על דפוס פרגמטי:
- פרסמו
/llms.txtבשורש ושמרו עליו נגיש בלי התחברות, בלי ביצוע JavaScript, בלי מסכי consent ובלי הפניות מחוץ לנתיב. - הגישו אותו כ-
text/plainאוtext/markdownכשאפשר. - התחילו בתיאור קצר של האתר, ואז קבצו קישורים לפי מוצר, תיעוד, API, תמחור, changelog, דוגמאות, תמיכה, מדיניות ומשאבי חברה.
- העדיפו קישורים קנוניים על פני רשימות URL ממצות.
- הימנעו מקבצים סמליים ריקים; במקרה הטוב הם אות חלש.
- הימנעו מ-dumps ענקיים ולא מובחנים אלא אם יש מקרה שימוש חזק לצריכה על ידי מכונה וצינור יצירה אמין.
- אמתו את ה-URL הסופי, גוף התגובה, סוג התוכן, מבנה ה-Markdown, מספר הקישורים וגודל הקובץ לאחר הפרסום.
צוותים צריכים גם לנהל ציפיות בזהירות. הניסויים הציבוריים הזמינים אינם מוכיחים ש-llms.txt מגדיל באופן עצמאי תעבורת הפניה מ-AI. אם צוות רוצה לבדוק השפעה עסקית, עליו לעקוב יחד אחרי הפניות מ-LLM, דפים מצוטטים, בקשות בוטים, עדכניות אינדקס ושינויי תוכן. ניסוי שימושי היה משווה קבוצות דפים תואמות, שומר על עדכוני תוכן קבועים ככל האפשר, ומפריד תעבורה ספציפית לפלטפורמות כמו Perplexity, ChatGPT, Gemini, Claude ו-Bing/Copilot.
מגבלות
זהו צילום מצב המבוסס על סריקה, לא אמת נצחית. אתרים יכולים להוסיף, להסיר או לשנות קובצי llms.txt בכל עת. ייתכן שחלק מהדומיינים יחסמו בקשות אוטומטיות או יתנהגו אחרת לפי גאוגרפיה, הגדרת TLS, לוגיקת הפניות, user agent או מנגנוני הגנה נגד בוטים. המחקר בדק רק קבצים ברמת השורש ולא חיפש בתת-דומיינים או בנתיבים לא סטנדרטיים.
ציון האיכות והטיפוסים הם כלי מחקר, לא תוויות ציות רשמיות. ניתוח הנושאים מבוסס מילות מפתח ויש לקרוא אותו ככיוון כללי. המחקר אינו מוכיח שאיזו פלטפורמת AI ספציפית קוראת, מכבדת או משתמשת כיום ב-llms.txt ב-production.
לראיות התעבורה החיצוניות שנבחנו בגרסה הזו יש גם מגבלות. הניתוח של Search Engine Land חזק יותר כהתבוננות רב-אתרית זהירה מאשר כניסוי אקראי. התוצאה של Alimbekov שימושית כמחקר מקרה שקוף ברמת אתר, אבל אין בה קבוצת ביקורת והיא כוללת תקופה שבה התעבורה הכוללת מהפניות עלתה באופן משמעותי. ההפניות האלה עוזרות למסגר את הדיון, אבל אינן הופכות את הסריקה הזו למחקר תעבורה סיבתי.
קבצים ושחזור
| קובץ | מטרה |
|---|---|
crawl_llms_txt.py | סורק עבור /llms.txt ו-/llms-full.txt. |
analyze_llms_txt.py | ניתוח אימוץ ראשי ויצירת גרפים. |
deep_analyze_llms_txt.py | ניתוח משני עבור עשירוני דירוג, TLDs, אותות נושא, ציוני איכות, טיפוסים והתנהגות של שני קבצים. |
deep_dive_early_quality.py | סיווג מאמצים מוקדמים וצלילה מעמיקה לאיכות ההטמעה. |
data/llms_probe_results_top_10000.csv | מערך הנתונים הראשי של תוצאות הסריקה. |
data/deep_analysis_top_10000.json | סיכום הניתוח המשני. |
data/deep_early_quality_analysis.json | קטגוריות של מאמצים מוקדמים, השוואת קהלי איכות, פרטי טיפוסים ומקרי בוחן. |
מקורות
- The /llms.txt file, Jeremy Howard, 2024.
- HTTP Archive Web Almanac 2024 Methodology.
- Cloudflare Radar: Expanded AI insights.
- Cloudflare Radar AI Insights.
- Consent in Crisis: The Rapid Decline of the AI Data Commons, Data Provenance Initiative.
- Tranco: A Research-Oriented Top Sites Ranking Hardened Against Manipulation.
- Does llms.txt matter?, Search Engine Land, ינואר 2026.
- The State of llms.txt Adoption, Rankability, יוני 2025.
- How LLMS.txt Increased AI Chat Traffic by 23%, Renat Alimbekov.
תיקוני מתודולוגיה, בעיות במערך הנתונים וניתוחים נוספים יתקבלו בברכה ב- support@thunderbit.com. דוח זה פורסם ללא תלות בעמדה מסחרית כלשהי של Thunderbit. הנתונים בדוח זה עומדים בפני עצמם. — צוות המחקר של Thunderbit, מאי 2026.
נסה את Thunderbit כדי לגרוף ולנתח נתוני רשת Get Started Free




