
האינטרנט מפוצץ במידע שווה זהב — אבל ברוב המקרים הוא ממש לא בנוי לזה שתוריד אותו בקליק. ב‑2025, web scraping כבר מזמן לא “טריק של גיקים”: זה כלי עבודה יומיומי לצוותים שעוקבים אחרי מחירים, משרות, נדל״ן ומתחרים. הבעיה? כשנכנסים לעולם של web scraping github, מגלים ש‑GitHub מוצף בפרויקטים ב-github. חלק סופר מלוטשים, חלק פשוט מעצבנים, והרבה מהם לא ראו עדכון מאז שהיינו צעירים יותר. אז איך בוחרים את הפרויקט הנכון — במיוחד אם אתם לא מפתחים?
במדריך הזה אני עובר איתכם על 15 פרויקטי ה‑web scraping הכי חזקים ב‑GitHub לשנת 2025. אבל זה לא יהיה עוד “רשימה וזהו” — אני מפרק כל כלי לפי כמה כואב להקים אותו, לאיזה תרחיש הוא באמת מתאים, האם הוא מסתדר עם תוכן דינמי, מה מצב התחזוקה שלו, איך מייצאים נתונים, ולמי הוא באמת מיועד. ואם נמאס לכם להילחם בקוד, אראה למה פתרונות no‑code מבוססי AI כמו משנים את המשחק למשתמשים עסקיים וגם למי שלא מגיע מרקע טכני.
איך בחרנו את 15 פרויקטי ה‑web scraping המובילים ב‑GitHub
בואו נדבר תכל׳ס: לא כל ריפו ב‑GitHub שווה את הזמן שלכם. יש פרויקטים שעובדים “בשטח” אצל אלפים, ויש כאלה שהם ניסוי של סופ״ש שנשאר תקוע על 3 כוכבים. לרשימה הזו התמקדתי בפרויקטים שעומדים בקריטריונים הבאים:
- כוכבים וקהילה ב‑GitHub: פרויקטים עם אימוץ אמיתי (מאלפים בודדים ועד 90k+ כוכבים) ותורמים פעילים.
- פעילות עדכנית: כלים שממשיכים להתעדכן גם ב‑2025 — לא מאובנים דיגיטליים.
- תיעוד ושימושיות: דוקומנטציה ברורה, דוגמאות קוד, ועקומת למידה הגיונית.
- שימוש בעולם האמיתי: כלים שמשמשים לסקרייפינג עסקי או מחקרי אמיתי, לא רק דמו של “hello world”.
ומכיוון ש‑web scraping הוא לא “מידה אחת לכולם”, השוויתי כל פרויקט גם לפי:
- מורכבות התקנה והקמה: אפשר להתחיל תוך דקות, או שתמצאו את עצמכם נלחמים בדרייברים ותלויות?
- התאמה לתרחיש שימוש: מיועד לאיקומרס, חדשות, מחקר, או משהו אחר?
- תמיכה בדפים דינמיים: האם הוא יודע להתמודד עם אתרים מודרניים עמוסי JavaScript?
- בריאות הפרויקט: האם הוא מתוחזק באופן פעיל, או שהקומיט האחרון כבר מספיק ותיק כדי להצביע?
- אפשרויות ייצוא נתונים: האם הוא מוציא נתונים מוכנים לעבודה עסקית, או רק HTML גולמי?
- התאמה לקהל יעד: מתאים למתחילים ב‑Python, למהנדסי דאטה, או לצוותים לא טכניים?
לכל פרויקט הוספתי תגיות “מבט מהיר” לפי הקריטריונים האלה, כדי שתוכלו ישר לקפוץ למה שמתאים לכם — בין אם אתם בונים python scraper מאפס, או פשוט רוצים שהנתונים ינחתו לכם בתוך Google Sheet.

מורכבות התקנה והקמה: כמה מהר אפשר להתחיל לגרד נתונים?
בואו נודה באמת: החסם הכי גדול לרוב האנשים הוא פשוט לגרום לסקרייפר לרוץ. ככה אני מחלק את רמות המורכבות:
- Plug & Play (אפס קונפיגורציה): מתקינים ומתחילים. כמעט בלי הגדרות — מעולה למתחילים.
- בינוני (שורת פקודה, מעט קוד): דורש קצת קוד או עבודה ב‑CLI, אבל סביר אם כבר כתבתם סקריפטים בעבר.
- מתקדם (דרייברים, אנטי‑בוט, קוד עמוק): דורש סביבת עבודה, דרייברים לדפדפן, או יכולות רציניות ב‑Python/JS.
ככה נראית החלוקה של הפרויקטים המובילים:
- Plug & Play: MechanicalSoup (Python), Nokogiri (Ruby), Maxun (למשתמשי קצה לאחר פריסה)
- בינוני: Scrapy, Crawlee, Node Crawler, Selenium, Playwright, Colly, Puppeteer, Katana, Scrapling, WebMagic
- מתקדם: Heritrix, Apache Nutch (שניהם דורשים Java, קבצי קונפיגורציה או סטאק של ביג דאטה)
אם אתם לא מפתחים, “Plug & Play” או פתרונות no‑code הם ה‑bestie שלכם. לכל השאר, “בינוני” אומר שתצטרכו לכתוב קצת קוד — בדרך כלל לא נורא… אלא אם אתם אלרגיים לסוגריים מסולסלים.
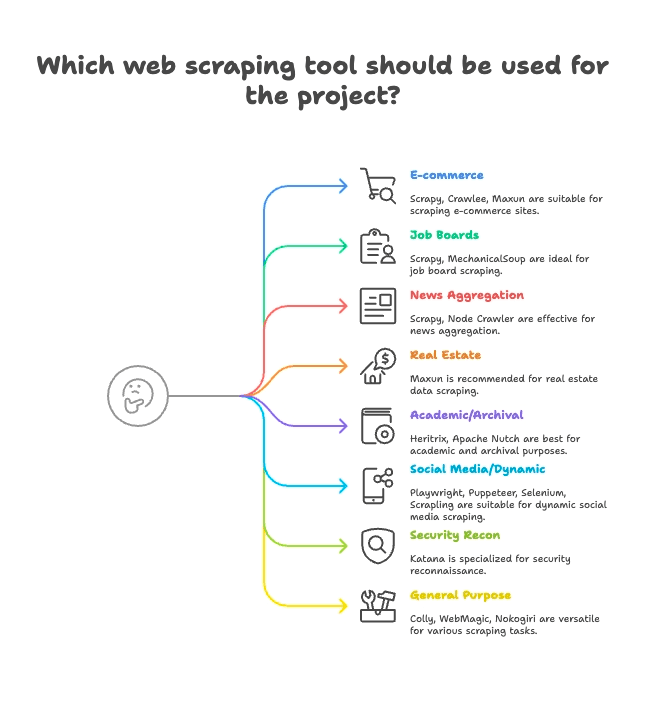
חלוקה לפי תרחישי שימוש: מצאו את הסקרייפר שמתאים לתעשייה שלכם
לא כל סקרייפר נולד לאותה משימה. ככה אני מקבץ את 15 המובילים לפי ההתאמה הכי טובה:
איקומרס ומעקב מחירים
- Scrapy: סקרייפינג בקנה מידה גדול, כולל עמודים רבים של מוצרים
- Crawlee: גמיש — מתאים גם לאתרים סטטיים וגם לדינמיים בתחום האיקומרס
- Maxun: ללא קוד, מצוין לחילוץ מהיר של רשימות מוצרים
לוחות דרושים וגיוס
- Scrapy: מתמודד מצוין עם עימוד (pagination) ורשימות מובנות
- MechanicalSoup: טוב לאתרים שדורשים התחברות כדי להגיע למשרות
חדשות ואגרגציית תוכן
- Scrapy: נבנה לזחילה בקנה מידה גדול באתרי חדשות
- Node Crawler: מהיר לאגרגציה של אתרי חדשות סטטיים
נדל"ן
- Thunderbit: סקרייפינג מבוסס AI לעמודי רשימות + עמודי פרטים (subpages)
- Maxun: בחירה ויזואלית של נתוני נכסים
מחקר אקדמי וארכוב רשת
- Heritrix: ארכוב אתר מלא (קבצי WARC)
- Apache Nutch: זחילה מבוזרת ליצירת דאטהסטים מחקריים
רשתות חברתיות ותוכן דינמי
- Playwright, Puppeteer, Selenium: גרידת פידים דינמיים, סימולציית התחברות
- Scrapling: סקרייפינג “שקט” לאתרים עם הגנות אנטי‑בוט
אבטחה וסריקה (Recon)
- Katana: גילוי URL מהיר, זחילה לצרכי אבטחה
כללי / רב‑שימושי
- Colly: סקרייפינג מהיר ב‑Go כמעט לכל אתר
- WebMagic: מבוסס Java וגמיש למגוון תחומים
- Nokogiri: פרסור Ruby לסקריפטים מותאמים אישית
תמיכה בדפים דינמיים: האם פרויקטי GitHub האלה יודעים לגרד אתרים מודרניים?
אתרים מודרניים מתים על JavaScript. React, Vue, גלילה אינסופית, AJAX — אם ניסיתם לגרד עמוד וקיבלתם “כלום” גדול ושמן, אתם יודעים בדיוק על מה אני מדבר.
ככה כל פרויקט מתמודד עם תוכן דינמי:
- תמיכת JS מלאה (דפדפן Headless):
- Selenium: שולט בדפדפנים אמיתיים ומריץ את כל ה‑JS
- Playwright: רב‑דפדפני ורב‑שפתי, עם תמיכת JS חזקה
- Puppeteer: Chrome/Firefox ב‑headless עם רינדור JS מלא
- Crawlee: עובר בין HTTP לדפדפן (באמצעות Puppeteer/Playwright)
- Katana: מצב headless אופציונלי לניתוח JS
- Scrapling: משלב Playwright לסקרייפינג “שקט” עם JS
- Maxun: משתמש בדפדפן מאחורי הקלעים לתוכן דינמי
- ללא תמיכת JS מובנית (HTML סטטי בלבד):
- Scrapy: צריך תוסף Selenium/Playwright כדי להתמודד עם JS
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch: כולם מורידים HTML בלבד — בלי תמיכת JS “מהקופסה”
ופה ה‑AI של Thunderbit ממש נותן שואו: הוא מזהה ומחלץ תוכן דינמי אוטומטית — בלי קונפיג ידני, בלי תוספים ובלי כאב ראש של סלקטורים. פשוט לוחצים “AI Suggest Fields” והוא עושה את העבודה, גם באתרים כבדים ב‑React. להסבר יותר עמוק, קפצו ל‑.
בריאות הפרויקט ואמינות: האם הסקרייפר הזה יעבוד גם בשנה הבאה?
אין דבר יותר מבאס מלבנות תהליך סביב כלי ואז לגלות שהוא ננטש. ככה נראית תמונת המצב אצל הפרויקטים המובילים:
- מתוחזק באופן פעיל (עדכונים תכופים):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- יציב אך עם קצב עדכונים איטי יותר:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- מצב תחזוקה (ייעודי, איטי):
- Heritrix:
- Apache Nutch:
Thunderbit הוא שירות מנוהל, אז אין צורך לדאוג מריפו שננטש. הצוות שלנו דואג שה‑AI, התבניות והאינטגרציות יישארו עדכניים — ובנוסף יש onboarding מודרך, מדריכים ותמיכה כשנתקעים.
טיפול בנתונים וייצוא: מ‑HTML גולמי לנתונים מוכנים לעבודה
איסוף הנתונים הוא רק חצי מהסיפור. בסוף צריך לקבל אותם בפורמט שהצוות באמת יכול לעבוד איתו — CSV, Excel, Google Sheets, Airtable, Notion, או אפילו API חי.
- ייצוא מובנה לנתונים מובנים:
- Scrapy: יצואנים מובנים ל‑CSV, JSON, XML
- Crawlee: דאטהסטים ואחסון גמיש
- Maxun: CSV, Excel, Google Sheets, JSON API
- Thunderbit:
- טיפול ידני בנתונים (לפי הקוד שלכם):
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling: אתם כותבים את הקוד לשמירה/ייצוא
- ייצוא ייעודי:
- Heritrix: WARC (קבצי ארכוב רשת)
- Apache Nutch: תוכן גולמי לאחסון/אינדוקס
הייצוא המובנה והאינטגרציות של Thunderbit חוסכים ים זמן למשתמשים עסקיים. בלי להתעסק עם CSV ובלי לכתוב “קוד דבק” — פשוט קליק והנתונים מוכנים.
התאמה לקהל יעד: למי מתאים כל פרויקט web scraping ב‑GitHub?
בואו נהיה אמיתיים: לא כל כלי מתאים לכל אחד. ככה הייתי ממליץ לפי קהל:
- מתחילים ב‑Python: MechanicalSoup, Scrapling (אם בא לכם אתגר)
- מהנדסי דאטה: Scrapy, Crawlee, Colly, WebMagic, Node Crawler
- אנשי QA ואוטומציה: Selenium, Playwright, Puppeteer
- חוקרי אבטחה: Katana
- מפתחי Ruby: Nokogiri
- מפתחי Java: WebMagic, Heritrix, Apache Nutch
- משתמשים לא טכניים / צוותים עסקיים: Maxun, Thunderbit
- Growth Hackers ואנליסטים: Maxun, Thunderbit
אם אתם לא בקטע של קוד, או שאתם פשוט רוצים תוצאות מהר, Thunderbit ו‑Maxun הם הבחירה הכי נוחה. לכל השאר — לכו על כלי שמתיישב עם השפה והתרחיש שלכם.
15 פרויקטי ה‑web scraping המובילים ב‑GitHub: השוואה מפורטת
יאללה, צוללים לכל פרויקט לפי קבוצות שימוש, עם תגיות “מבט מהיר” ונקודות עיקריות.
איקומרס, מעקב מחירים וזחילה כללית
— 57.1k כוכבים, עדכון יוני 2025

- תקציר: פריימוורק Python אסינכרוני ברמה גבוהה לזחילה וגרידת נתונים בקנה מידה גדול.
- הקמה: בינוני (קוד Python, עבודה אסינכרונית)
- תרחיש שימוש: איקומרס, חדשות, מחקר, “עכבישים” מרובי עמודים
- תמיכת JS: לא (דורש תוסף Selenium/Playwright)
- בריאות הפרויקט: מתוחזק באופן פעיל
- ייצוא נתונים: CSV, JSON, XML מובנים
- קהל יעד: מפתחים, מהנדסי דאטה
- דגשים: סקיילבילי וחזק, המון תוספים. עקומת למידה תלולה למתחילים.
— 17.9k כוכבים, 2025

- תקציר: ספריית Node.js עשירה לפעולות web scraping סטטיות ודינמיות.
- הקמה: בינוני (קוד Node/TS)
- תרחיש שימוש: איקומרס, רשתות חברתיות, אוטומציה
- תמיכת JS: כן (אינטגרציה עם Puppeteer/Playwright)
- בריאות הפרויקט: פעיל מאוד
- ייצוא נתונים: גמיש (datasets, storages)
- קהל יעד: צוותי פיתוח ב‑JS/TS
- דגשים: כלים נגד חסימות, מעבר קל בין מצב HTTP למצב דפדפן.
— 13k כוכבים, יוני 2025

- תקציר: פלטפורמת קוד פתוח לחילוץ נתוני רשת ללא קוד, עם ממשק ויזואלי.
- הקמה: בינוני (פריסת שרת), קל (למשתמשי קצה)
- תרחיש שימוש: כללי, איקומרס, סקרייפינג עסקי
- תמיכת JS: כן (דפדפן מאחורי הקלעים)
- בריאות הפרויקט: פעיל וצומח
- ייצוא נתונים: CSV, Excel, Google Sheets, JSON API
- קהל יעד: משתמשים לא טכניים, אנליסטים, צוותים
- דגשים: גרירה‑והקלקה, ניווט רב‑שלבי, אפשרות self‑host.
לוחות דרושים, גיוס ואינטראקציות פשוטות
— 4.8k כוכבים, 2024

- תקציר: ספריית Python לאוטומציה של שליחת טפסים וניווט בסיסי.
- הקמה: Plug & Play (Python, מעט קוד)
- תרחיש שימוש: לוחות דרושים עם התחברות, אתרים סטטיים
- תמיכת JS: לא
- בריאות הפרויקט: בוגר, מתוחזק קלות
- ייצוא נתונים: אין מובנה (ידני)
- קהל יעד: מתחילים ב‑Python, סקריפטים מהירים
- דגשים: מדמה סשן דפדפן בכמה שורות. לא מתאים לאתרים דינמיים.
אגרגציית חדשות ותוכן סטטי
— 6.8k כוכבים, 2024

- תקציר: זחלן מהיר ומקבילי בצד שרת עם פרסור Cheerio.
- הקמה: בינוני (callbacks/async ב‑Node)
- תרחיש שימוש: חדשות, סקרייפינג סטטי מהיר
- תמיכת JS: לא (HTML בלבד)
- בריאות הפרויקט: פעילות בינונית (v2 beta)
- ייצוא נתונים: אין מובנה (לפי הקוד שלכם)
- קהל יעד: מפתחי Node.js, צרכים של קונקרנציה גבוהה
- דגשים: זחילה אסינכרונית, הגבלת קצב, API בסגנון jQuery.
נדל"ן, מודעות וסקרייפינג של עמודי משנה

- תקציר: Web Scraper ללא קוד, מבוסס AI, למשתמשים עסקיים.
- הקמה: Plug & Play (תוסף Chrome, הקמה בשתי לחיצות)
- תרחיש שימוש: נדל"ן, איקומרס, מכירות, שיווק — כל אתר
- תמיכת JS: כן (ה‑AI מזהה תוכן דינמי אוטומטית)
- בריאות הפרויקט: מתעדכן באופן רציף, שירות מנוהל
- ייצוא נתונים: בלחיצה אחת ל‑Sheets, Airtable, Notion, CSV, JSON
- קהל יעד: משתמשים לא טכניים, צוותים עסקיים, מכירות ושיווק
- דגשים: AI “Suggest Fields”, סקרייפינג עמודי משנה, ייצוא מיידי, תהליך התחלה מודרך, תבניות, .
מחקר אקדמי וארכוב רשת
— 3k כוכבים, 2023

- תקציר: זחלן ארכוב בקנה מידה גדול של Internet Archive.
- הקמה: מתקדם (אפליקציית Java, קבצי קונפיגורציה)
- תרחיש שימוש: ארכוב רשת, זחילה ברמת דומיין
- תמיכת JS: לא (רק fetch)
- בריאות הפרויקט: מתוחזק (איטי אך יציב)
- ייצוא נתונים: WARC (קבצי ארכוב רשת)
- קהל יעד: ארכיונים, ספריות, מוסדות
- דגשים: סקיילבילי וחזק, עומד בתקנים. לא מיועד לסקרייפינג ממוקד.
— 3k כוכבים, 2024

- תקציר: זחלן קוד פתוח לביג דאטה ומנועי חיפוש.
- הקמה: מתקדם (Java + Hadoop לסקייל)
- תרחיש שימוש: זחילה למנועי חיפוש, ביג דאטה
- תמיכת JS: לא (HTTP בלבד)
- בריאות הפרויקט: פעיל (Apache)
- ייצוא נתונים: תוכן גולמי לאחסון/אינדוקס
- קהל יעד: ארגונים, ביג דאטה, מחקר אקדמי
- דגשים: ארכיטקטורת תוספים, זחילה מבוזרת.
רשתות חברתיות, תוכן דינמי ואוטומציה
— ~30k כוכבים, 2025

- תקציר: אוטומציית דפדפן לסקרייפינג ובדיקות, תומך בכל הדפדפנים המרכזיים.
- הקמה: בינוני (דרייברים, רב‑שפתי)
- תרחיש שימוש: אתרים כבדי JS, תהליכי בדיקה, רשתות חברתיות
- תמיכת JS: כן (אוטומציה מלאה של דפדפן)
- בריאות הפרויקט: פעיל ובוגר
- ייצוא נתונים: אין (ידני)
- קהל יעד: מהנדסי QA, מפתחים
- דגשים: רב‑שפתי, מדמה התנהגות משתמש אמיתית.
— 73.5k כוכבים, 2025

- תקציר: אוטומציית דפדפן מודרנית לסקרייפינג ולבדיקות E2E.
- הקמה: בינוני (סקריפטים רב‑שפתיים)
- תרחיש שימוש: אפליקציות ווב מודרניות, רשתות חברתיות, אוטומציה
- תמיכת JS: כן (headless או דפדפן אמיתי)
- בריאות הפרויקט: פעיל מאוד
- ייצוא נתונים: אין (המשתמש מטפל)
- קהל יעד: מפתחים שצריכים שליטה חזקה בדפדפן
- דגשים: רב‑דפדפני, auto-wait, יירוט רשת.
— 90.9k כוכבים, 2025

- תקציר: API ברמה גבוהה לאוטומציה של Chrome/Firefox.
- הקמה: בינוני (סקריפטים ב‑Node)
- תרחיש שימוש: סקרייפינג ב‑Headless Chrome, תוכן דינמי
- תמיכת JS: כן (Chrome/Firefox)
- בריאות הפרויקט: פעיל (צוות Chrome)
- ייצוא נתונים: אין (מותאם בקוד)
- קהל יעד: מפתחי Node.js, אנשי Front-end
- דגשים: שליטה עשירה בדפדפן, צילומי מסך, PDF, יירוט רשת.
— 5.4k כוכבים, יוני 2025

- תקציר: סקרייפינג “שקט” ומהיר עם יכולות אנטי‑בוט.
- הקמה: בינוני (קוד Python)
- תרחיש שימוש: סקרייפינג עם התחמקות, אנטי‑בוט, אתרים דינמיים
- תמיכת JS: כן (אינטגרציה עם Playwright)
- בריאות הפרויקט: פעיל, בקצה החדשנות
- ייצוא נתונים: אין מובנה (ידני)
- קהל יעד: מפתחי Python, האקרים, מהנדסי דאטה
- דגשים: Stealth, פרוקסי, אנטי‑חסימה, async.
סריקת אבטחה (Reconnaissance)
— 13.8k כוכבים, 2025

- תקציר: זחלן מהיר לאבטחה, אוטומציה וגילוי קישורים.
- הקמה: בינוני (כלי CLI או ספריית Go)
- תרחיש שימוש: זחילה לצרכי אבטחה, גילוי נקודות קצה
- תמיכת JS: כן (מצב headless אופציונלי)
- בריאות הפרויקט: פעיל (ProjectDiscovery)
- ייצוא נתונים: פלט טקסט (רשימות URL)
- קהל יעד: חוקרי אבטחה, מפתחי Go
- דגשים: מהירות, קונקרנציה, ניתוח JS ב‑headless.
סקרייפינג כללי / רב‑שימושי
— 24.3k כוכבים, 2025

- תקציר: פריימוורק סקרייפינג מהיר ואלגנטי ל‑Go.
- הקמה: בינוני (קוד Go)
- תרחיש שימוש: סקרייפינג כללי עם ביצועים גבוהים
- תמיכת JS: לא (HTML בלבד)
- בריאות הפרויקט: פעיל, קומיטים עדכניים
- ייצוא נתונים: אין מובנה (לפי הקוד שלכם)
- קהל יעד: מפתחי Go, מי שמכוון לביצועים
- דגשים: async, הגבלת קצב, סקרייפינג מבוזר.
— 11.6k כוכבים, 2023

- תקציר: פריימוורק זחילה גמיש ב‑Java, בסגנון Scrapy.
- הקמה: בינוני (Java, API פשוט)
- תרחיש שימוש: web scraping כללי ב‑Java
- תמיכת JS: לא (אפשר להרחיב עם Selenium)
- בריאות הפרויקט: קהילה פעילה
- ייצוא נתונים: pipelines ניתנים לחיבור
- קהל יעד: מפתחי Java
- דגשים: Thread pool, schedulers, אנטי‑חסימה.
— 6.2k כוכבים, 2025

- תקציר: פרסר HTML/XML מהיר ונייטיבי ל‑Ruby.
- הקמה: Plug & Play (Ruby gem)
- תרחיש שימוש: פרסור HTML/XML באפליקציות Ruby
- תמיכת JS: לא (פרסור בלבד)
- בריאות הפרויקט: פעיל, מתעדכן יחד עם Ruby
- ייצוא נתונים: אין (משתמשים ב‑Ruby לעיצוב)
- קהל יעד: מפתחי Ruby, Rails
- דגשים: מהירות, תאימות, מאובטח כברירת מחדל.
במבט מהיר: טבלת השוואת פיצ'רים
הנה טבלת סריקה מהירה — כולל Thunderbit להשוואה:
| Project | Setup Complexity | Use Case | JS Support | Maintenance | Data Export | Audience | Github Stars |
|---|---|---|---|---|---|---|---|
| Scrapy | בינוני | איקומרס, חדשות | לא | פעיל | CSV, JSON, XML | מפתחים, מהנדסי דאטה | 57.1k |
| Crawlee | בינוני | רב-שימושי, אוטומציה | כן | פעיל מאוד | דאטהסטים גמישים | צוותי פיתוח JS/TS | 17.9k |
| MechanicalSoup | Plug & Play | סטטי, טפסים | לא | בוגר | אין (ידני) | מתחילים ב-Python | 4.8k |
| Node Crawler | בינוני | חדשות, סטטי | לא | בינוני | אין (ידני) | מפתחי Node.js | 6.8k |
| Selenium | בינוני | כבד JS, בדיקות | כן | פעיל | אין (ידני) | מהנדסי QA, מפתחים | ~30k |
| Heritrix | מתקדם | ארכוב, מחקר | לא | מתוחזק | WARC | ארכיונים, מוסדות | 3k |
| Apache Nutch | מתקדם | ביג דאטה, חיפוש | לא | פעיל | תוכן גולמי | ארגונים, מחקר | 3k |
| WebMagic | בינוני | Java, כללי | לא | קהילה פעילה | pipelines ניתנים לחיבור | מפתחי Java | 11.6k |
| Nokogiri | Plug & Play | פרסור Ruby | לא | פעיל | אין (ידני) | מפתחי Ruby | 6.2k |
| Playwright | בינוני | דינמי, אוטומציה | כן | פעיל מאוד | אין (ידני) | מפתחים, QA | 73.5k |
| Katana | בינוני | אבטחה, גילוי | כן | פעיל | פלט טקסט | אבטחה, מפתחי Go | 13.8k |
| Colly | בינוני | ביצועים גבוהים, כללי | לא | פעיל | אין (ידני) | מפתחי Go | 24.3k |
| Puppeteer | בינוני | דינמי, אוטומציה | כן | פעיל | אין (ידני) | מפתחי Node.js | 90.9k |
| Maxun | קל (למשתמש) | ללא קוד, עסקי | כן | פעיל | CSV, Excel, Sheets, API | לא טכניים, אנליסטים | 13k |
| Scrapling | בינוני | Stealth, אנטי-בוט | כן | פעיל | אין (ידני) | מפתחי Python, האקרים | 5.4k |
| Thunderbit | Plug & Play | ללא קוד, עסקי | כן | מנוהל ומתעדכן | Sheets, Airtable, Notion | לא טכניים, משתמשים עסקיים | N/A |
למה Thunderbit היא הבחירה הטובה ביותר למשתמשים לא טכניים ולצוותים עסקיים
בואו נשים את זה על השולחן: רוב פרויקטי הקוד הפתוח ב‑GitHub נבנו על ידי מפתחים — בשביל מפתחים. זה אומר שהתקנה, תחזוקה ו‑debugging הם חלק מהדיל. אם אתם משתמשים עסקיים, אנשי שיווק, Sales Ops, או פשוט רוצים תוצאות — ולא כאב ראש של regex — Thunderbit נבנה בדיוק בשבילכם.
הנה מה שמבדל את Thunderbit:
- פשטות ללא קוד, עם AI: מתקינים את , לוחצים “AI Suggest Fields” ומתחילים לגרד. בלי Python, בלי סלקטורים, ובלי דרמות של “pip install”.
- תמיכה בדפים דינמיים: ה‑AI של Thunderbit קורא ומחלץ נתונים מאתרים מודרניים עמוסי JavaScript (React, Vue, AJAX) בלי שום הגדרה ידנית.
- סקרייפינג עמודי משנה: צריכים למשוך פרטים מכל מוצר או מודעה? ה‑AI של Thunderbit יודע להיכנס לעמודי משנה ולאחד את הנתונים לטבלה אחת — בלי קוד מותאם.
- ייצוא מוכן לעבודה עסקית: ייצוא בלחיצה אחת ל‑Google Sheets, Airtable, Notion, CSV או JSON. מושלם ללידים, מעקב מחירים או אגרגציית תוכן.
- עדכונים ותמיכה רציפים: Thunderbit הוא שירות מנוהל — אין סיכון ל‑“abandonware”. מקבלים תהליך התחלה מודרך, מדריכים וספריית תבניות מתרחבת לאתרים נפוצים.
- התאמה לקהל: Thunderbit מיועד למשתמשים לא טכניים, צוותים עסקיים, ולכל מי שמעדיף מהירות ואמינות על פני התעסקות בקוד.
ולא צריך להסתמך רק על מה שאני אומר — Thunderbit כבר בשימוש של יותר מ‑30,000 משתמשים ברחבי העולם, כולל צוותים ב‑Accenture, Grammarly ו‑Puma. וכן, אפילו דורגנו כ‑#1 Product of the Week ב‑Product Hunt.
אם בא לכם לראות כמה זה יכול להיות פשוט, .
סיכום: איך לבחור את פתרון ה‑web scraping הנכון ל‑2025
השורה התחתונה: GitHub הוא מכרה זהב של כלי סקרייפינג חזקים, אבל רובם מכוונים למפתחים. אם אתם אוהבים קוד, פריימוורקים כמו Scrapy, Crawlee, Playwright ו‑Colly יתנו לכם שליטה מלאה. אם אתם באקדמיה או באבטחה, Heritrix, Nutch ו‑Katana הם הבחירות הטבעיות.
אבל אם אתם משתמשים עסקיים, אנליסטים, או כל מי שפשוט צריך נתונים — מהר, מובנים ומוכנים לשימוש — Thunderbit הוא הפתרון הנכון. בלי התקנות מסובכות, בלי תחזוקה, בלי קוד. רק תוצאות.
אז מה הלאה? אם מסקרן אתכם, נסו פרויקט GitHub שמתאים לרמת הידע ולתרחיש שלכם. או אם אתם רוצים לדלג על עקומת הלמידה ולראות תוצאות אמיתיות תוך דקות, והתחילו לגרד כבר היום.
ואם תרצו להעמיק בעולם ה‑web scraping, תוכלו למצוא עוד מדריכים ב‑, למשל או .
שיהיה סקרייפינג מוצלח — ושכל הנתונים שלכם תמיד יהיו מסודרים, נקיים ומוכנים לפעולה. ואם אי פעם תיתקעו, תזכרו: כנראה יש לזה ריפו ב‑GitHub… או שפשוט תנו ל‑AI של Thunderbit לעשות את העבודה בשבילכם.