
באיזו שפת תכנות כדאי להשתמש ל־web scraping? זה תלוי בפרויקט שלך — וראיתי מפתחים מתייאשים לגמרי אחרי שבחרו בשפה הלא נכונה.
שוק תוכנות ה־web scraping הגיע ל־. השפה הנכונה יכולה להביא לתוצאות מהירות יותר ולפחות תחזוקה. השפה הלא נכונה? תוביל ל־scrapers שבורים ולסופי שבוע מבוזבזים.
אני בונה כלי אוטומציה כבר שנים. הנה שבע שפות שהשתמשתי בהן ל־scraping — עם קטעי קוד, יתרונות וחסרונות אמיתיים, וגם מבט על מתי כדאי לוותר על כתיבת קוד ולהשתמש ב־ במקום זאת.
איך בחרנו את השפה הטובה ביותר ל־Web Scraping
כשמדובר ב־web scraping, לא כל שפות התכנות נולדו שוות. ראיתי פרויקטים עפים למעלה — וגם מתרסקים — בהתאם לכמה גורמים מרכזיים:
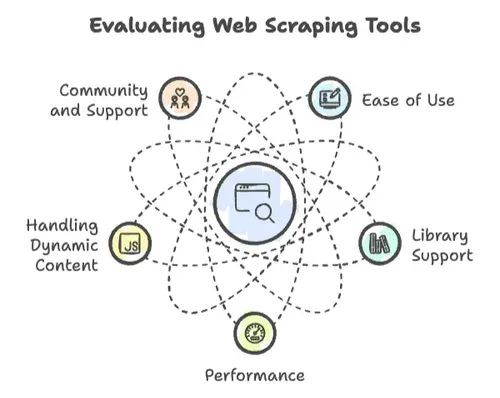
- קלות שימוש: כמה מהר אפשר להתחיל? האם התחביר ידידותי, או שצריך דוקטורט במדעי המחשב רק כדי להדפיס “Hello, World”?
- תמיכה בספריות: האם יש ספריות חזקות לבקשות HTTP, לניתוח HTML ולטיפול בתוכן דינמי? או שאתם ממציאים את הגלגל מחדש?
- ביצועים: האם היא יכולה להתמודד עם scraping של מיליוני עמודים, או שנגמר לה הכוח אחרי כמה מאות?
- טיפול בתוכן דינמי: אתרים מודרניים אוהבים JavaScript. האם השפה שלכם עומדת בקצב?
- קהילה ותמיכה: כשנתקלים בקיר — וזה יקרה — יש קהילה שתעזור?
על בסיס הקריטריונים האלה — והרבה בדיקות בשעות הלילה המאוחרות — הנה שבע השפות שאסקור:
- Python: הבחירה המועדפת למתחילים ולמקצוענים כאחד.
- JavaScript & Node.js: המלך של התוכן הדינמי.
- Ruby: תחביר נקי, סקריפטים מהירים.
- PHP: פשטות בצד השרת.
- C++: כשצריך מהירות גולמית.
- Java: מוכן לארגונים וניתן להרחבה.
- Go (Golang): מהיר ובעל מקביליות גבוהה.
ואם אתם חושבים, “שמעו, אני בכלל לא רוצה לקודד,” תישארו עד הסוף בשביל Thunderbit.
Web Scraping ב־Python: מעצמה ידידותית למתחילים
נתחיל עם הפייבוריט של הקהל: Python. אם תשאלו חדר מלא באנשי דאטה, “מהי שפת התכנות הטובה ביותר ל־web scraping?” — תשמעו את Python חוזרת כמו קריאה בהופעה של טיילור סוויפט.
למה Python?
- תחביר ידידותי למתחילים: אפשר לקרוא קוד Python בקול רם, והוא כמעט נשמע כמו אנגלית.
- תמיכה אדירה בספריות: מ־ לניתוח HTML, דרך לזחילה בקנה מידה גדול, ועד ל־HTTP ו־ לאוטומציה של דפדפן — ל־Python יש הכול.
- קהילה ענקית: יותר מ־ על web scraping בלבד.
דוגמת קוד ב־Python: חילוץ כותרת של עמוד
1import requests
2from bs4 import BeautifulSoup
3response = requests.get("<https://example.com>")
4soup = BeautifulSoup(response.text, 'html.parser')
5title = soup.title.string
6print(f"Page title: \{title\}")יתרונות:
- פיתוח ואב־טיפוס מהירים.
- המון מדריכים ושאלות ותשובות.
- מצוין לניתוח נתונים — גריפת נתונים עם Python, ניתוח עם pandas, וויזואליזציה עם matplotlib.
- הספריות ממשיכות להתפתח: גרסת 2.14 של Scrapy (ינואר 2026) הביאה
async/awaitמובנה לכל המסגרת, כך שסיפור ה־async כבר לא שייך רק ל־Selenium/Playwright.
מגבלות:
- איטית יותר משפות מקומפלת בעבודות ענק.
- טיפול באתרים דינמיים במיוחד עלול להיות מסורבל (למרות ש־Selenium ו־Playwright עוזרים).
- לא אידיאלית ל־scraping של מיליוני עמודים במהירות מסחררת.
השורה התחתונה:
אם אתם חדשים ב־scraping, או פשוט רוצים לסיים דברים מהר, Python היא שפת התכנות הטובה ביותר ל־web scraping — נקודה. .
JavaScript & Node.js: גריפת אתרים דינמיים בקלות
אם Python היא הסכין השווייצרית, JavaScript (ו־Node.js) היא המקדחה החשמלית — במיוחד ל־scraping של אתרים מודרניים וכבדי JavaScript.
למה JavaScript/Node.js?
- מקורית לתוכן דינמי: היא רצה בדפדפן, כך שהיא יכולה לראות את מה שהמשתמשים רואים — גם אם העמוד בנוי עם React, Angular או Vue.
- אסינכרוניות כברירת מחדל: Node.js יכולה ללהטט במאות בקשות בו־זמנית.
- מוכרת למפתחי ווב: אם בניתם אתר, אתם כבר מכירים קצת JavaScript.
ספריות מרכזיות:
- : תמיכה בכמה דפדפנים (Chromium, Firefox, WebKit) עם המתנה אוטומטית ופרוקסי לכל הקשר. אם אתם מתחילים scraper חדש ב־Node ב־2026, זו ברירת המחדל.
- : Chrome ללא ממשק גרפי דרך Chrome DevTools Protocol. עדיין מצוין לעבודות שמוגבלות ל־Chrome ולתלות קלה יותר.
- : ניתוח HTML בסגנון jQuery ל־Node כשלא צריך דפדפן אמיתי.
דוגמת קוד ב־Node.js: חילוץ כותרת עמוד עם Puppeteer
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
6 const title = await page.title();
7 console.log(`Page title: $\{title\}`);
8 await browser.close();
9})();יתרונות:
- מטפלת באופן טבעי בתוכן שנוצר על ידי JavaScript.
- מצוינת ל־infinite scroll, חלונות קופצים ואתרים אינטראקטיביים.
- יעילה ל־scraping בקנה מידה גדול ובמקביליות גבוהה.
מגבלות:
- תכנות אסינכרוני יכול להיות מאתגר למתחילים.
- דפדפנים ללא ממשק גרפי צורכים הרבה זיכרון אם מריצים יותר מדי יחד.
- פחות כלי ניתוח נתונים בהשוואה ל־Python.
מתי JavaScript/Node.js היא שפת התכנות הטובה ביותר ל־web scraping?
כשאתר היעד דינמי, או כשצריך לבצע אוטומציה של פעולות בדפדפן. .
Ruby: תחביר נקי לסקריפטים מהירים של Web Scraping
Ruby היא לא רק לאפליקציות Rails ולשירה אלגנטית בקוד. היא בחירה מצוינת ל־web scraping — במיוחד אם אתם אוהבים שהקוד שלכם נקרא כמעט כמו הייקו.
למה Ruby?
- תחביר קריא ובעל הבעה: אפשר לכתוב ב־Ruby scraper שכמעט קל לקרוא אותו כמו רשימת הקניות.
- מצוינת לאב־טיפוס: מהירה לכתיבה, קלה לכוונון.
- ספריות מרכזיות: לניתוח, לאוטומציה של ניווט.
דוגמת קוד ב־Ruby: חילוץ כותרת של עמוד
1require 'open-uri'
2require 'nokogiri'
3html = URI.open("<https://example.com>")
4doc = Nokogiri::HTML(html)
5title = doc.at('title').text
6puts "Page title: #\{title\}"יתרונות:
- קריאה גבוהה ותמציתיות.
- מעולה לפרויקטים קטנים, סקריפטים חד־פעמיים, או אם אתם כבר עובדים עם Ruby.
מגבלות:
- איטית יותר מ־Python או Node.js בעבודות גדולות.
- פחות ספריות ל־scraping ופחות תמיכה קהילתית בתחום.
- לא אידיאלית ל־scraping של אתרים עתירי JavaScript (למרות שאפשר להשתמש ב־Watir או Selenium).
התאמה טובה ביותר:
אם אתם Rubyists או רוצים להרים סקריפט מהיר, Ruby היא תענוג. ל־scraping דינמי בקנה מידה גדול, כדאי להסתכל בכיוון אחר.
PHP: פשטות בצד השרת לחילוץ נתוני ווב
PHP אולי נשמעת כמו שריד מהאינטרנט המוקדם, אבל היא עדיין חיה ובועטת — במיוחד אם רוצים לגרוף נתונים ישירות בשרת.
למה PHP?
- רצה כמעט בכל מקום: ברוב שרתי האינטרנט כבר מותקנת PHP.
- קלה לשילוב עם אפליקציות ווב: אפשר לגרוף ולהציג באתר באותו מהלך.
- ספריות מרכזיות: ל־HTTP, לבקשות, לאוטומציה של דפדפן ללא ממשק גרפי.
דוגמת קוד ב־PHP: חילוץ כותרת של עמוד
1<?php
2$ch = curl_init("<https://example.com>");
3curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
4$html = curl_exec($ch);
5curl_close($ch);
6$dom = new DOMDocument();
7@$dom->loadHTML($html);
8$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
9echo "Page title: $title\n";
10?>יתרונות:
- קל לפריסה על שרתי ווב.
- מתאים לגריפת נתונים כחלק מזרימת עבודה של אתר.
- מהיר למשימות scraping פשוטות בצד השרת.
מגבלות:
- תמיכת ספריות מוגבלת ל־scraping מתקדם.
- לא בנויה למקביליות גבוהה או ל־scraping בקנה מידה גדול.
- טיפול באתרים עתירי JavaScript מסובך (למרות ש־Panther עוזרת).
התאמה טובה ביותר:
אם הסטאק שלכם כבר מבוסס PHP, או אם אתם רוצים לגרוף ולהציג נתונים באתר, PHP היא בחירה פרקטית. .
C++: Web Scraping עתיר ביצועים לפרויקטים בקנה מידה גדול
C++ היא המכונית השרירית של שפות התכנות. אם אתם צריכים מהירות גולמית ושליטה, ולא מפחדים קצת מעבודה ידנית, C++ יכולה לקחת אתכם רחוק.
למה C++?
- מהירה בטירוף: מנצחת את רוב השפות במשימות תלויות CPU.
- שליטה מדויקת: ניהול זיכרון, threads ושיפורי ביצועים.
- ספריות מרכזיות: ל־HTTP, לניתוח.
דוגמת קוד ב־C++: חילוץ כותרת של עמוד
1#include <curl/curl.h>
2#include <iostream>
3#include <string>
4size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
5 std::string* html = static_cast<std::string*>(userp);
6 size_t totalSize = size * nmemb;
7 html->append(static_cast<char*>(contents), totalSize);
8 return totalSize;
9}
10int main() {
11 CURL* curl = curl_easy_init();
12 std::string html;
13 if(curl) {
14 curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
15 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
16 curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
17 CURLcode res = curl_easy_perform(curl);
18 curl_easy_cleanup(curl);
19 }
20 std::size_t startPos = html.find("<title>");
21 std::size_t endPos = html.find("</title>");
22 if(startPos != std::string::npos && endPos != std::string::npos) {
23 startPos += 7;
24 std::string title = html.substr(startPos, endPos - startPos);
25 std::cout << "Page title: " << title << std::endl;
26 } else {
27 std::cout << "Title tag not found" << std::endl;
28 }
29 return 0;
30}יתרונות:
- מהירות שאין לה מתחרים בעבודות scraping ענקיות.
- מצוינת לשילוב scraping במערכות עתירות ביצועים.
מגבלות:
- עקומת למידה תלולה (תביאו קפה).
- ניהול זיכרון ידני.
- מעט ספריות ברמה גבוהה; לא אידיאלית לתוכן דינמי.
התאמה טובה ביותר:
כשצריך לגרוף מיליוני עמודים, או כשהביצועים הם קריטיים לחלוטין. אחרת, סביר שתבלו יותר זמן בדיבוג מאשר בגריפה.
Java: פתרונות Web Scraping מוכנים לארגונים
Java היא סוס העבודה של עולם הארגונים. אם אתם בונים משהו שצריך לרוץ לנצח, לטפל בכמויות גדולות של נתונים, ולשרוד אפוקליפסת זומבים, Java היא חברה טובה.
למה Java?
- חזקה וניתנת להרחבה: מצוינת לפרויקטי scraping גדולים וארוכי טווח.
- טיפוסיות חזקה וטיפול בשגיאות: פחות הפתעות בפרודקשן.
- ספריות מרכזיות: לניתוח, לאוטומציה של דפדפן, ל־HTTP.
דוגמת קוד ב־Java: חילוץ כותרת של עמוד
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3public class ScrapeTitle {
4 public static void main(String[] args) throws Exception {
5 Document doc = Jsoup.connect("<https://example.com>").get();
6 String title = doc.title();
7 System.out.println("Page title: " + title);
8 }
9}יתרונות:
- ביצועים גבוהים ומקביליות טובה.
- מצוינת לבסיסי קוד גדולים ותחזוקתיים.
- תמיכה טובה בתוכן דינמי (באמצעות Selenium או HtmlUnit).
מגבלות:
- תחביר ארוך; דורשת יותר הכנה משפות סקריפט.
- מוגזמת לסקריפטים קטנים וחד־פעמיים.
התאמה טובה ביותר:
ל־scraping ברמת ארגון, או כשצריך אמינות ויכולת הרחבה ללא פשרות.
Go (Golang): Web Scraping מהיר ובעל מקביליות גבוהה
Go היא הילדה החדשה בשכונה, אבל היא כבר עושה גלים — במיוחד עבור scraping מהיר ובעל מקביליות גבוהה.
למה Go?
- מהירות של שפה מקומפלת: כמעט מהירה כמו C++.
- מקביליות מובנית: Goroutines הופכות scraping מקביל לקליל.
- ספריות מרכזיות: ל־scraping, לניתוח.
דוגמת קוד ב־Go: חילוץ כותרת של עמוד
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly"
5)
6func main() {
7 c := colly.NewCollector()
8 c.OnHTML("title", func(e *colly.HTMLElement) {
9 fmt.Println("Page title:", e.Text)
10 })
11 err := c.Visit("<https://example.com>")
12 if err != nil {
13 fmt.Println("Error:", err)
14 }
15}יתרונות:
- מהירה ויעילה בטירוף ל־scraping בקנה מידה גדול.
- קלה לפריסה (binary יחיד).
- מצוינת לזחילה מקבילית.
מגבלות:
- קהילה קטנה יותר משל Python או Node.js.
- פחות ספריות scraping ברמה גבוהה.
- טיפול באתרים עתירי JavaScript דורש הגדרה נוספת (Chromedp או Selenium).
התאמה טובה ביותר:
כשצריך לגרוף בקנה מידה גדול, או כש־Python פשוט לא מספיק מהירה. .
השוואת שפות התכנות הטובות ביותר ל־Web Scraping
בואו נחבר הכול יחד. הנה השוואה זה לצד זה שתעזור לכם לבחור את השפה הטובה ביותר ל־web scraping ב־2026:
| שפה/כלי | קלות שימוש | ביצועים | תמיכה בספריות | טיפול בתוכן דינמי | מקרה השימוש הטוב ביותר |
|---|---|---|---|---|---|
| Python | גבוהה מאוד | בינונית | מצוינת | טובה (Selenium/Playwright) | שימוש כללי, מתחילים, ניתוח נתונים |
| JavaScript/Node.js | בינונית | גבוהה | חזקה | מצוינת (מובנית) | אתרים דינמיים, scraping אסינכרוני, מפתחי ווב |
| Ruby | גבוהה | בינונית | סבירה | מוגבלת (Watir) | סקריפטים מהירים, יצירת אב־טיפוס |
| PHP | בינונית | בינונית | סבירה | מוגבלת (Panther) | צד שרת, שילוב באפליקציות ווב |
| C++ | נמוכה | גבוהה מאוד | מוגבלת | מוגבלת מאוד | ביצועים קריטיים, קנה מידה עצום |
| Java | בינונית | גבוהה | טובה | טובה (Selenium/HtmlUnit) | ארגונים, שירותים ארוכי טווח |
| Go (Golang) | בינונית | גבוהה מאוד | בצמיחה | בינונית (Chromedp) | scraping מהיר ובעל מקביליות גבוהה |
מתי כדאי לוותר על קוד: Thunderbit כפתרון Web Scraping ללא קוד
טוב, בואו נהיה כנים: לפעמים אתם פשוט רוצים את הנתונים — בלי קוד, בלי דיבוג, ובלי כאבי הראש של “למה הסלקטור הזה לא עובד”. בדיוק בשביל זה יש את .
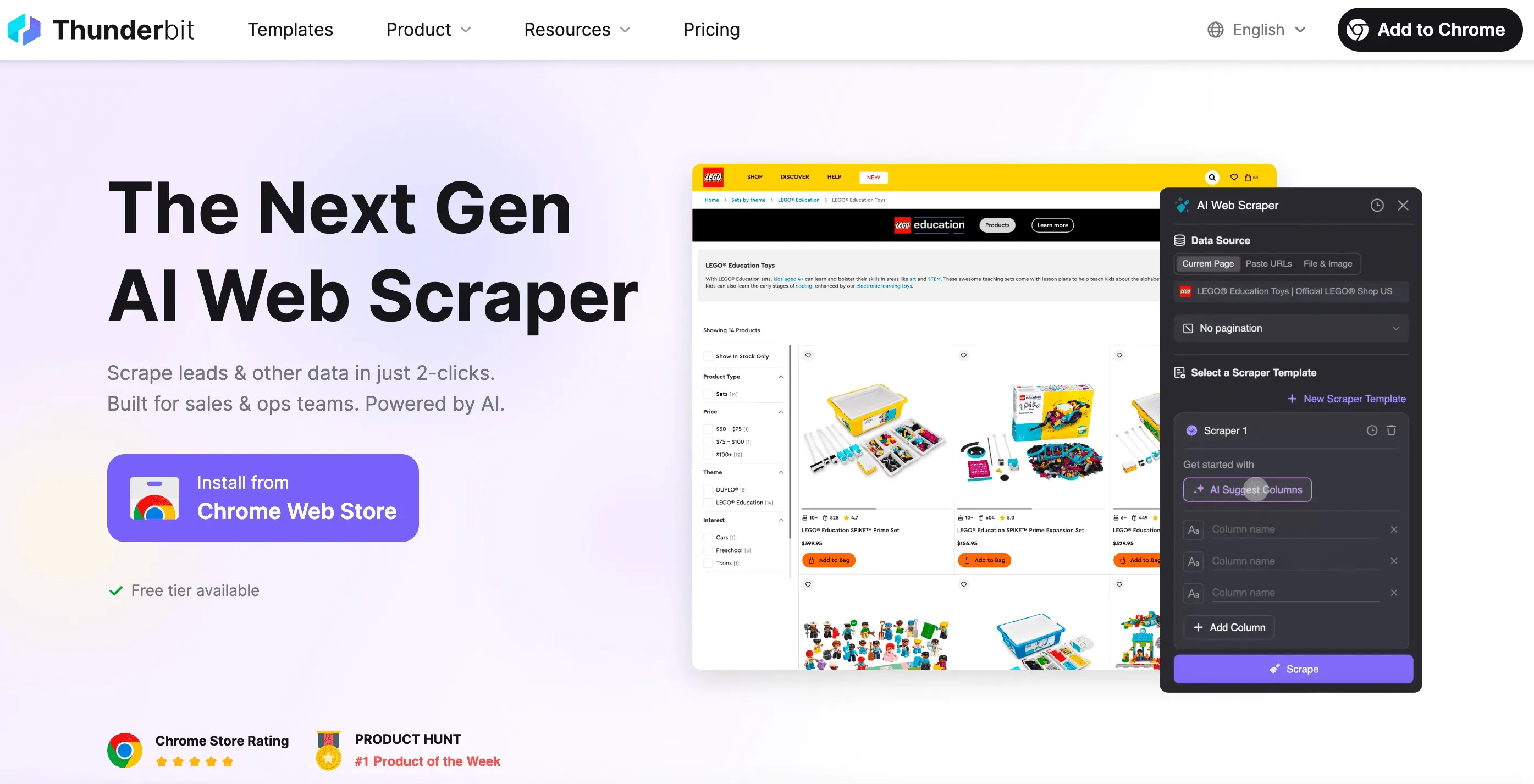
כמייסד־שותף של Thunderbit, רציתי לבנות כלי שהופך web scraping לפשוט כמו להזמין טייק־אווי. הנה מה שמבדיל את Thunderbit:
- הגדרה בשתי לחיצות: פשוט לוחצים על “AI Suggest Fields” ועל “Scrape”. בלי להתעסק בבקשות HTTP, בפרוקסי או בתחבולות נגד בוטים.
- תבניות חכמות: תבנית scraper אחת יכולה להתאים עצמה לכמה פריסות עמודים. אין צורך לכתוב מחדש את ה־scraper בכל פעם שהאתר משתנה.
- Scraping בדפדפן ובענן: אפשר לבחור בין scraping בדפדפן שלכם (מעולה לאתרים עם התחברות) לבין scraping בענן (מהיר במיוחד לנתונים ציבוריים).
- מטפל בתוכן דינמי: ה־AI של Thunderbit שולט בדפדפן אמיתי — כך שהוא יכול להתמודד עם infinite scroll, חלונות קופצים, התחברויות ועוד.
- ייצוא לכל מקום: הורדה ל־Excel, Google Sheets, Airtable, Notion, או פשוט העתקה ללוח.
- ללא תחזוקה: אם אתר משתנה, פשוט מריצים מחדש את ההצעה של ה־AI. בלי עוד סשנים של דיבוג בשעות הלילה.
- תזמון ואוטומציה: מגדירים scrapers לרוץ לפי לוח זמנים — בלי cron jobs, בלי הגדרת שרת.
- Extractors ייעודיים: צריכים אימיילים, מספרי טלפון או תמונות? ל־Thunderbit יש גם extractors בלחיצה אחת עבורם.
והחלק הכי טוב? לא צריך לדעת אפילו שורת קוד אחת. Thunderbit בנויה למשתמשי עסקים, משווקים, צוותי מכירות, אנשי נדל״ן — לכל מי שצריך נתונים, ומהר.
רוצים לראות את Thunderbit בפעולה? או בדקו את להדגמות.
סיכום: בחירת השפה הטובה ביותר ל־Web Scraping ב־2026
Web scraping ב־2026 נגיש יותר — וחזק יותר — מאי פעם. הנה מה שלמדתי אחרי שנים בשוחות האוטומציה:
- Python עדיין השפה הטובה ביותר ל־web scraping אם רוצים להתחיל מהר ולקבל המון משאבים בהישג יד.
- JavaScript/Node.js היא בלתי מנוצחת ל־scraping של אתרים דינמיים וכבדי JavaScript.
- Ruby ו־PHP מצוינות לסקריפטים מהירים ולשילוב עם ווב, במיוחד אם אתם כבר משתמשים בהן.
- C++ ו־Go הן החברות שלכם כשצריך מהירות וקנה מידה.
- Java היא הבחירה המועדפת לארגונים ולפרויקטים ארוכי טווח.
- ואם אתם רוצים לדלג על כתיבת קוד לגמרי? הוא הנשק הסודי שלכם.
לפני שנכנסים לזה, שאלו את עצמכם:
- כמה גדול הפרויקט שלי?
- האם אני צריך לטפל בתוכן דינמי?
- מה רמת הנוחות הטכנית שלי?
- האם אני רוצה לבנות, או פשוט להשיג את הנתונים?
נסו קטע קוד מהדוגמאות למעלה, או תנו ל־Thunderbit ניסיון בפרויקט הבא שלכם. ואם אתם רוצים להעמיק, בדקו את לעוד מדריכים, טיפים וסיפורי scraping מהשטח.
בהצלחה ב־scraping — ושהנתונים שלכם תמיד יהיו נקיים, מובנים, ובמרחק קליק אחד.
נ.ב. אם אי פעם תמצאו את עצמכם תקועים בחור הארנב של web scraping ב־2 בלילה, זכרו: תמיד יש Thunderbit. או קפה. או שניהם.
שאלות נפוצות
1. מהי שפת התכנות הטובה ביותר ל־web scraping ב־2026?
Python נשארת הבחירה המובילה בזכות תחביר קריא, ספריות חזקות (כמו BeautifulSoup, Scrapy ו־Selenium), וקהילה גדולה. היא אידיאלית גם למתחילים וגם למקצוענים, במיוחד כשמשלבים scraping עם ניתוח נתונים.
2. איזו שפה הכי טובה ל־scraping של אתרים כבדי JavaScript?
JavaScript (Node.js) היא הבחירה המובילה לאתרים דינמיים. כלים כמו Puppeteer ו־Playwright נותנים שליטה מלאה בדפדפן, ומאפשרים אינטראקציה עם תוכן שנטען דרך React, Vue או Angular.
3. האם יש אפשרות ללא קוד ל־web scraping?
כן — הוא AI web scraper ללא קוד שמטפל בכל דבר, מתוכן דינמי ועד תזמון. פשוט לוחצים על “AI Suggest Fields” ומתחילים לגרוף. זה מושלם לצוותי מכירות, שיווק או תפעול שצריכים נתונים מובנים במהירות.
4. האם עדיין צריך לבחור שפה אם סוכן קוד ב־AI יכול לכתוב את ה־scraper בשבילי?
שאלה הוגנת ב־2026. כלים כמו Claude Code, Cursor ו־OpenAI Codex ישמחו לייצר spider של Scrapy, סקריפט של Playwright, או crawler של Go + Colly מתוך פרומפט של פסקה אחת — כך שהחיכוך של “איזו שפה ללמוד קודם” באמת נמוך יותר משהיה לפני שנתיים. אבל הסוכן עדיין מוציא קוד באיזושהי שפה, ואתם (או מי שיירש את הפרויקט) עדיין תצטרכו לקרוא, לדבג ולפרוס אותו. לכן הבחירה עדיין חשובה; פשוט חשוב יותר למה שיקרה בתחזוקה מאשר ל־30 השורות הראשונות. אם אתם לא רוצים לגעת בקוד בכלל, כאן Thunderbit נכנס לתמונה — הוא מדלג על שאלת השפה לחלוטין.
למידע נוסף: