קישורים שבורים. עמודים יתומים. עמוד “test” מ-2019 שגוגל איכשהו אינדקסה. אם אתם מנהלים אתר, אתם מכירים את הכאב הזה.
סורק טוב תופס את כל הדברים האלה — וממפה את כל האתר כדי שתוכלו באמת לתקן. אבל הרבה אנשים מבלבלים בין “web crawler” לבין “web scraper”. זה לא אותו דבר.
בדקתי 10 סורקים חינמיים על אתרים אמיתיים. חלק מצוינים לבדיקות SEO טכניות. אחרים חזקים יותר בחילוץ נתונים. הנה מה שעבד — ומה פחות.
מה זה Website Crawler? הבנת הבסיס
בואו נעשה סדר אחת ולתמיד: website crawler זה לא אותו דבר כמו web scraper. אני יודע, כולם זורקים את המונחים האלה כאילו הם אותו דבר, אבל בפועל מדובר בשני כלים שונים לגמרי. תחשבו על סורק אתרים כמו על קרטוגרף שמשרטט מפה: הוא נכנס לכל פינה, עוקב אחרי כל לינק, ובונה תמונת מצב מלאה של כל העמודים. התפקיד שלו הוא גילוי: למצוא כתובות URL, למפות את מבנה האתר ולעזור באינדוקס תוכן. זה בדיוק מה שמנועי חיפוש כמו Google עושים עם הבוטים שלהם, וזה גם מה שכלי SEO עושים כשהם בודקים את “הבריאות” של האתר ().
לעומת זאת, web scraper הוא כורה הנתונים של העולם הזה. הוא לא מחפש “מפה יפה” — הוא רוצה את ה”זהב”: מחירי מוצרים, שמות חברות, ביקורות, אימיילים, ומה לא. סקרייפינג מתמקד בחילוץ שדות ספציפיים מתוך העמודים שהסורקים כבר מצאו ().
אנלוגיה קצרה:
- Crawler: מי שעובר בכל המעברים בסופר ומכין רשימה של כל המוצרים.
- Scraper: מי שניגש ישר למדף הקפה ורושם את המחיר של כל תערובת אורגנית.
למה זה חשוב? כי אם אתם רק רוצים למצוא את כל העמודים באתר (למשל לצורך בדיקת SEO), אתם צריכים סורק אתרים. אם אתם רוצים למשוך את כל מחירי המוצרים מאתר של מתחרה — אתם צריכים סקרייפר, או אפילו עדיף: כלי שיודע לעשות את שניהם.
למה להשתמש ב-Web Crawler אונליין? יתרונות עסקיים מרכזיים
אז למה בכלל להיכנס לקטע של סריקת אתרים? כי הרשת לא הולכת וקטנה. בפועל, יותר מ- כדי לשפר את האתרים שלהם, וחלק מכלי ה-SEO סורקים .
מה סורקים יכולים לעשות בשבילכם:
- בדיקות SEO: איתור קישורים שבורים, כותרות חסרות, תוכן כפול, עמודים יתומים ועוד ().
- בדיקת קישורים ו-QA: תפיסת 404 ולולאות הפניה לפני שהמשתמשים נתקלים בזה ().
- יצירת Sitemap: בנייה אוטומטית של XML sitemaps למנועי חיפוש ולתכנון ().
- אינוונטור תוכן: יצירת רשימה של כל העמודים, ההיררכיה שלהם והמטא-דאטה.
- ציות ונגישות: בדיקה של כל עמוד לפי WCAG, SEO ודרישות משפטיות ().
- ביצועים ואבטחה: סימון עמודים איטיים, תמונות כבדות מדי או בעיות אבטחה ().
- נתונים ל-AI ולאנליזה: הזנת נתוני סריקה לכלי אנליטיקה או AI ().
הנה טבלה קצרה שמחברת בין מקרי שימוש לתפקידים עסקיים:
| מקרה שימוש | למי זה מתאים | תועלת / תוצאה |
|---|---|---|
| SEO ובדיקת אתר | שיווק, SEO, בעלי עסקים קטנים | איתור בעיות טכניות, שיפור מבנה, שיפור דירוגים |
| אינוונטור תוכן ו-QA | מנהלי תוכן, מנהלי אתרים | בדיקת/העברת תוכן, איתור קישורים/תמונות שבורים |
| יצירת לידים (סקרייפינג) | מכירות, פיתוח עסקי | אוטומציה של פרוספקטינג, מילוי CRM בלידים עדכניים |
| מודיעין תחרותי | איקומרס, מנהלי מוצר | מעקב אחרי מחירי מתחרים, מוצרים חדשים, שינויי מלאי |
| Sitemap ושכפול מבנה | מפתחים, DevOps, יועצים | שכפול מבנה אתר לרידיזיין או גיבוי |
| איסוף תוכן ממקורות רבים | חוקרים, מדיה, אנליסטים | איסוף נתונים ממספר אתרים לניתוח או זיהוי מגמות |
| מחקר שוק | אנליסטים, צוותי אימון AI | איסוף דאטה-סטים גדולים לניתוח או אימון מודלים |
()
איך בחרנו את כלי ה-Website Crawler החינמיים הטובים ביותר
ביליתי לא מעט לילות מאוחרים (ועוד קצת קפה מעבר למה שנעים להודות) בחפירה בכלי סריקה, בקריאת תיעוד ובהרצת סריקות ניסיון. אלה הקריטריונים שבדקתי:
- יכולת טכנית: האם הכלי מתמודד עם אתרים מודרניים (JavaScript, התחברות, תוכן דינמי)?
- נוחות שימוש: האם הוא ידידותי למי שלא טכני, או שצריך קסמים בשורת פקודה?
- מגבלות התוכנית החינמית: האם זה באמת חינם או רק “טעימה”?
- נגישות אונליין: האם זה כלי ענן, אפליקציית דסקטופ או ספריית קוד?
- פיצ’רים ייחודיים: האם יש משהו מיוחד — כמו חילוץ בעזרת AI, sitemaps ויזואליים או סריקה מבוססת אירועים?
בדקתי כל כלי, עברתי על פידבק משתמשים והשוויתי פיצ’רים אחד מול השני. אם כלי גרם לי לרצות להעיף את הלפטופ מהחלון — הוא פשוט לא נכנס לרשימה.
טבלת השוואה מהירה: 10 סורקי אתרים חינמיים במבט אחד
| כלי וסוג | יכולות מרכזיות | מקרה שימוש מומלץ | דרישות טכניות | פרטי התוכנית החינמית |
|---|---|---|---|---|
| BrightData (ענן/API) | סריקה ארגונית, פרוקסים, רינדור JS, פתרון CAPTCHA | איסוף נתונים בהיקף גדול | עדיף ידע טכני | ניסיון חינם: 3 סקרייפרים, 100 רשומות לכל אחד (כ-300 רשומות סה״כ) |
| Crawlbase (ענן/API) | סריקה דרך API, אנטי-בוט, פרוקסים, רינדור JS | מפתחים שצריכים תשתית סריקה בצד שרת | אינטגרציית API | חינם: ~5,000 קריאות API ל-7 ימים, ואז 1,000/חודש |
| ScraperAPI (ענן/API) | רוטציית פרוקסי, רינדור JS, סריקה אסינכרונית, endpoints מוכנים | מפתחים, ניטור מחירים, דאטה ל-SEO | הקמה מינימלית | חינם: 5,000 קריאות API ל-7 ימים, ואז 1,000/חודש |
| Diffbot Crawlbot (ענן) | סריקה + חילוץ עם AI, knowledge graph, רינדור JS | דאטה מובנה בהיקף גדול, AI/ML | אינטגרציית API | חינם: 10,000 קרדיטים/חודש (כ-10k עמודים) |
| Screaming Frog (דסקטופ) | בדיקת SEO, ניתוח קישורים/מטא, sitemap, חילוץ מותאם | בדיקות SEO, מנהלי אתרים | אפליקציית דסקטופ, GUI | חינם: 500 כתובות URL לסריקה, פיצ’רים בסיסיים בלבד |
| SiteOne Crawler (דסקטופ) | SEO, ביצועים, נגישות, אבטחה, ייצוא אופליין, Markdown | מפתחים, QA, מיגרציה, תיעוד | דסקטופ/CLI, GUI | חינם וקוד פתוח, 1,000 כתובות URL בדוח GUI (ניתן לשינוי) |
| Crawljax (Java, קוד פתוח) | סריקה מבוססת אירועים לאתרים כבדי JS, ייצוא סטטי | מפתחים, QA לאפליקציות דינמיות | Java, CLI/קונפיג | חינם וקוד פתוח, ללא מגבלות |
| Apache Nutch (Java, קוד פתוח) | מבוזר, מבוסס תוספים, אינטגרציה עם Hadoop, חיפוש מותאם | מנועי חיפוש מותאמים, סריקה בהיקף גדול | Java, שורת פקודה | חינם וקוד פתוח, עלות תשתית בלבד |
| YaCy (Java, קוד פתוח) | סריקה וחיפוש P2P, פרטיות, אינדוקס ווב/אינטראנט | חיפוש פרטי, ביזור | Java, ממשק דפדפן | חינם וקוד פתוח, ללא מגבלות |
| PowerMapper (דסקטופ/SaaS) | sitemaps ויזואליים, נגישות, QA, תאימות דפדפנים | סוכנויות, QA, מיפוי ויזואלי | GUI, קל | ניסיון חינם: 30 יום, 100 עמודים (דסקטופ) או 10 עמודים (אונליין) לסריקה |
BrightData: סורק אתרים בענן ברמה ארגונית

BrightData הוא “הארטילריה הכבדה” של עולם הסריקה. זו פלטפורמת ענן עם רשת פרוקסים עצומה, רינדור JavaScript, פתרון CAPTCHA ו-IDE לבניית סריקות מותאמות. אם אתם עושים איסוף נתונים בהיקפים גדולים — למשל ניטור מחירים במאות אתרי איקומרס — קשה להתחרות בתשתית של BrightData ().
יתרונות:
- מתמודד עם אתרים “קשוחים” עם מנגנוני אנטי-בוט
- סקייל גבוה לצרכים ארגוניים
- תבניות מוכנות לאתרים נפוצים
חסרונות:
- אין שכבת חינם קבועה (רק ניסיון: 3 סקרייפרים, 100 רשומות לכל אחד)
- עלול להיות מוגזם לבדיקות פשוטות
- עקומת למידה למי שלא טכני
אם אתם צריכים לסרוק בהיקף גדול, BrightData זה כמו לשכור מכונית פורמולה 1. רק אל תצפו שזה יישאר חינם אחרי נסיעת המבחן ().
Crawlbase: Web Crawler חינמי מבוסס API למפתחים

Crawlbase (לשעבר ProxyCrawl) הולך חזק על סריקה תכנותית. אתם קוראים ל-API עם כתובת URL, והוא מחזיר HTML — כשהוא מטפל מאחורי הקלעים בפרוקסים, מיקוד גיאוגרפי ו-CAPTCHA ().
יתרונות:
- שיעורי הצלחה גבוהים (99%+)
- מתמודד עם אתרים כבדי JavaScript
- מצוין לשילוב בתוך אפליקציות או תהליכי עבודה קיימים
חסרונות:
- דורש אינטגרציה דרך API או SDK
- תוכנית חינמית: ~5,000 קריאות API ל-7 ימים, ואז 1,000/חודש
אם אתם מפתחים ורוצים לסרוק (ואולי גם לסקרייפינג) בהיקף גדול בלי להתעסק עם ניהול פרוקסים, Crawlbase הוא בחירה חזקה ().
ScraperAPI: מפשט סריקה של אתרים דינמיים

ScraperAPI הוא ה-API של “תביא לי את העמוד וזהו”. אתם נותנים URL, והוא מטפל בפרוקסים, דפדפנים headless ומנגנוני אנטי-בוט — ומחזיר HTML (או נתונים מובנים בחלק מהאתרים). הוא חזק במיוחד בעמודים דינמיים ומציע שכבת חינם נדיבה ().
יתרונות:
- קל מאוד למפתחים (קריאת API אחת)
- מתמודד עם CAPTCHA, חסימות IP ו-JavaScript
- חינם: 5,000 קריאות API ל-7 ימים, ואז 1,000/חודש
חסרונות:
- אין דוחות סריקה ויזואליים
- אם רוצים לעקוב אחרי קישורים, צריך לכתוב לוגיקת סריקה בקוד
אם אתם רוצים לחבר סריקת אתרים לקוד שלכם תוך דקות, ScraperAPI הוא פתרון מתבקש.
Diffbot Crawlbot: גילוי אוטומטי של מבנה אתר

Diffbot Crawlbot כבר משחק בליגה חכמה יותר. הוא לא רק סורק אתרים — הוא משתמש ב-AI כדי לסווג עמודים ולחלץ נתונים מובנים (כתבות, מוצרים, אירועים ועוד) ל-JSON. זה כמו מתמחה רובוטי שבאמת מבין מה הוא קורא ().
יתרונות:
- חילוץ נתונים בעזרת AI, לא רק סריקה
- מתמודד עם JavaScript ותוכן דינמי
- חינם: 10,000 קרדיטים/חודש (כ-10k עמודים)
חסרונות:
- מכוון למפתחים (אינטגרציית API)
- פחות כלי SEO ויזואלי — יותר לפרויקטי דאטה
אם אתם צריכים נתונים מובנים בהיקף גדול, במיוחד לאנליטיקה או AI, Diffbot הוא כוח רציני.
Screaming Frog: סורק SEO חינמי לדסקטופ

Screaming Frog הוא הקלאסיקה של סורקי הדסקטופ לבדיקות SEO. הוא סורק עד 500 כתובות URL בכל ריצה (בגרסה החינמית) ומספק את כל מה שצריך: קישורים שבורים, תגיות מטא, תוכן כפול, sitemaps ועוד ().
יתרונות:
- מהיר, יסודי ומוכר מאוד בעולם ה-SEO
- בלי קוד — מכניסים URL ומתחילים
- חינם עד 500 כתובות URL לסריקה
חסרונות:
- דסקטופ בלבד (אין גרסת ענן)
- פיצ’רים מתקדמים (רינדור JS, תזמון) דורשים רישיון בתשלום
אם SEO חשוב לכם, Screaming Frog הוא כלי חובה — רק אל תצפו שיסרוק אתר של 10,000 עמודים בחינם.
SiteOne Crawler: ייצוא אתר סטטי ותיעוד

SiteOne Crawler הוא אולר שוויצרי לבדיקות טכניות. הוא קוד פתוח, עובד על כמה פלטפורמות, ויכול לסרוק, לבצע אודיט ואפילו לייצא את האתר ל-Markdown לצורכי תיעוד או שימוש אופליין ().
יתרונות:
- מכסה SEO, ביצועים, נגישות ואבטחה
- מייצא אתרים לארכוב או מיגרציה
- חינם וקוד פתוח, בלי מגבלות שימוש
חסרונות:
- טכני יותר מחלק מכלי ה-GUI
- דוח ה-GUI מוגבל כברירת מחדל ל-1,000 כתובות URL (ניתן לשינוי)
אם אתם מפתחים, אנשי QA או יועצים שרוצים עומק (ואוהבים קוד פתוח), SiteOne הוא פנינה לא מספיק מוכרת.
Crawljax: Web Crawler בקוד פתוח (Java) לעמודים דינמיים
Crawljax הוא כלי נישתי ומדויק: הוא נועד לסרוק אפליקציות ווב מודרניות וכבדות JavaScript באמצעות סימולציה של אינטראקציות משתמש (קליקים, מילוי טפסים וכו’). הוא מבוסס אירועים ויכול אפילו להפיק גרסה סטטית של אתר דינמי ().
יתרונות:
- מצוין לסריקת SPA ואתרים כבדי AJAX
- קוד פתוח וניתן להרחבה
- ללא מגבלות שימוש
חסרונות:
- דורש Java וקצת תכנות/קונפיגורציה
- לא מתאים למשתמשים לא טכניים
אם אתם צריכים לסרוק אפליקציית React או Angular כמו משתמש אמיתי, Crawljax הוא חבר טוב.
Apache Nutch: סורק אתרים מבוזר וסקיילבילי

Apache Nutch הוא “הסבא” של סורקי הקוד הפתוח. הוא מיועד לסריקות ענק מבוזרות — למשל בניית מנוע חיפוש משלכם או אינדוקס של מיליוני עמודים ().
יתרונות:
- מגיע לסקייל של מיליארדי עמודים עם Hadoop
- גמיש מאוד להגדרות ולהרחבות
- חינם וקוד פתוח
חסרונות:
- עקומת למידה תלולה (Java, שורת פקודה, קונפיגים)
- לא מתאים לאתרים קטנים או שימוש “קליל”
אם אתם רוצים לסרוק את הרשת בהיקף גדול ולא מפחדים משורת פקודה, Nutch הוא הכלי.
YaCy: סורק ומנוע חיפוש מבוזר (Peer-to-Peer)
YaCy הוא כלי ייחודי: סורק ומנוע חיפוש מבוזר. כל מופע סורק ומאנדקס אתרים, ואפשר להצטרף לרשת P2P כדי לשתף אינדקסים עם אחרים ().
יתרונות:
- ממוקד פרטיות, בלי שרת מרכזי
- מצוין לבניית חיפוש פרטי או אינטראנט
- חינם וקוד פתוח
חסרונות:
- איכות התוצאות תלויה בכיסוי של הרשת
- דורש קצת הקמה (Java, ממשק דפדפן)
אם ביזור מדבר אליכם או שאתם רוצים מנוע חיפוש משלכם, YaCy הוא אופציה מרתקת.
PowerMapper: מחולל Sitemap ויזואלי ל-UX ול-QA

PowerMapper מתמקד בהמחשה של מבנה האתר. הוא סורק את האתר ומייצר sitemaps אינטראקטיביים, ובנוסף בודק נגישות, תאימות דפדפנים ובסיסי SEO ().
יתרונות:
- sitemaps ויזואליים מצוינים לסוכנויות ומעצבים
- בדיקות נגישות וציות
- GUI פשוט, בלי צורך בידע טכני
חסרונות:
- רק ניסיון חינם (30 יום, 100 עמודים בדסקטופ/10 עמודים אונליין לכל סריקה)
- הגרסה המלאה בתשלום
אם אתם צריכים להציג מפת אתר ללקוחות או לבדוק ציות, PowerMapper הוא כלי שימושי.
איך לבחור את ה-Web Crawler החינמי הנכון לצרכים שלכם
עם כל כך הרבה אפשרויות, איך בוחרים? הנה מדריך קצר:
- לבדיקות SEO: Screaming Frog (אתרים קטנים), PowerMapper (ויזואלי), SiteOne (אודיטים עמוקים)
- לאפליקציות ווב דינמיות: Crawljax
- לסריקות ענק או חיפוש מותאם: Apache Nutch, YaCy
- למפתחים שצריכים API: Crawlbase, ScraperAPI, Diffbot
- לתיעוד או ארכוב: SiteOne Crawler
- לסקייל ארגוני עם ניסיון: BrightData, Diffbot
גורמים חשובים לשקול:
- סקייל: כמה גדול האתר או משימת הסריקה?
- נוחות שימוש: אתם עובדים עם קוד או מעדיפים קליק-קליק?
- ייצוא נתונים: צריך CSV, JSON או אינטגרציה לכלים אחרים?
- תמיכה: יש קהילה או תיעוד שיעזרו כשנתקעים?
כשסריקה פוגשת סקרייפינג: למה Thunderbit היא בחירה חכמה יותר
המציאות היא שרוב האנשים לא עושים סריקת אתרים כדי לייצר “מפות יפות”. בדרך כלל המטרה היא לקבל נתונים מובנים — רשימות מוצרים, פרטי קשר או אינוונטור תוכן. כאן נכנסת .
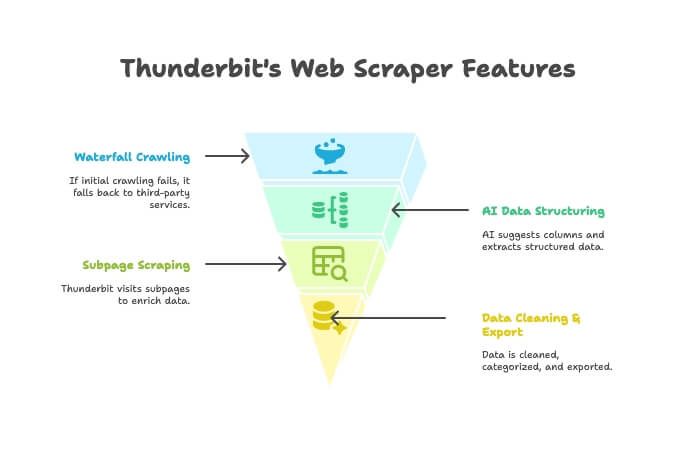
Thunderbit היא לא רק סורק אתרים או רק סקרייפר — זו תוסף Chrome מבוסס AI שמחבר בין השניים. ככה זה עובד:
- AI Crawler: Thunderbit חוקרת את האתר כמו סורק.
- Waterfall Crawling: אם המנוע של Thunderbit לא מצליח להביא את העמוד (למשל בגלל חומת אנטי-בוט קשוחה), היא עוברת אוטומטית לשירותי סריקה צד-שלישי — בלי הגדרות ידניות.
- מבנה נתונים בעזרת AI: אחרי שיש HTML, ה-AI של Thunderbit מציע עמודות מתאימות ומחלץ נתונים מובנים (שמות, מחירים, אימיילים וכו’) בלי שתכתבו אפילו selector אחד.
- Subpage Scraping: צריכים פרטים מכל עמוד מוצר? Thunderbit יכולה לבקר אוטומטית בכל תת-עמוד ולהעשיר את הטבלה.
- ניקוי וייצוא נתונים: אפשר לסכם, לקטלג, לתרגם ולייצא ל-Excel, Google Sheets, Airtable או Notion בלחיצה אחת.
- פשטות ללא קוד: אם אתם יודעים להשתמש בדפדפן — אתם יודעים להשתמש ב-Thunderbit. בלי קוד, בלי פרוקסים, בלי כאבי ראש.
מתי עדיף Thunderbit על סורק “קלאסי”?
- כשמטרת הסוף היא גיליון נתונים נקי ושימושי — לא רק רשימת URL.
- כשאתם רוצים לאוטומט את כל התהליך (סריקה, חילוץ, ניקוי, ייצוא) במקום אחד.
- כשחשוב לכם לחסוך זמן ועצבים.
אפשר ולראות בעצמכם למה כל כך הרבה משתמשים עסקיים עוברים אליו.
סיכום: איך להפיק את המקסימום מסורקי אתרים חינמיים
סורקי אתרים עברו דרך ארוכה. בין אם אתם אנשי שיווק, מפתחים או פשוט רוצים לשמור על אתר “בריא”, יש כלי חינמי (או לפחות כזה שאפשר לנסות בחינם) שמתאים לכם. מפלטפורמות ארגוניות כמו BrightData ו-Diffbot, דרך כלים בקוד פתוח כמו SiteOne ו-Crawljax, ועד ממפים ויזואליים כמו PowerMapper — המבחר מגוון יותר מאי פעם.
אבל אם אתם מחפשים דרך חכמה ומשולבת יותר להגיע מ-“אני צריך את הנתונים האלה” ל-“הנה הגיליון שלי”, שווה לנסות את Thunderbit. היא נבנתה למשתמשים עסקיים שרוצים תוצאות — לא רק דוחות.
מוכנים להתחיל לסרוק? הורידו כלי, הריצו סריקה ותראו מה פספסתם. ואם אתם רוצים לעבור מסריקה לנתונים שאפשר לעבוד איתם בשתי לחיצות, .
לעוד מדריכים מעמיקים ופרקטיים, בקרו ב-.
שאלות נפוצות
מה ההבדל בין website crawler לבין web scraper?
סורק מגלה וממפה את כל העמודים באתר (כמו יצירת תוכן עניינים). סקרייפר מחלץ שדות נתונים ספציפיים (כמו מחירים, אימיילים או ביקורות) מתוך העמודים האלה. סורקים מוצאים, סקרייפרים “כורים” ().
איזה web crawler חינמי הכי מתאים למשתמשים לא טכניים?
לאתרים קטנים ובדיקות SEO, Screaming Frog נוח לשימוש. למיפוי ויזואלי, PowerMapper מצוין (במהלך תקופת הניסיון). Thunderbit היא הכי קלה אם המטרה שלכם היא נתונים מובנים ואתם רוצים חוויה ללא קוד, ישירות בדפדפן.
האם יש אתרים שחוסמים web crawlers?
כן — חלק מהאתרים משתמשים בקובצי robots.txt או באמצעי אנטי-בוט (כמו CAPTCHA או חסימות IP) כדי לחסום סורקים. כלים כמו ScraperAPI, Crawlbase ו-Thunderbit (עם waterfall crawling) יכולים לעיתים לעקוף את זה, אבל תמיד סרקו באחריות וכבדו את כללי האתר ().
האם לסורקי אתרים חינמיים יש מגבלות עמודים או פיצ’רים?
ברוב המקרים כן. לדוגמה, הגרסה החינמית של Screaming Frog מוגבלת ל-500 כתובות URL לסריקה; תקופת הניסיון של PowerMapper מוגבלת ל-100 עמודים. כלים מבוססי API לרוב מוגבלים בקרדיטים חודשיים. כלים בקוד פתוח כמו SiteOne או Crawljax בדרך כלל לא מגבילים “קשיח”, אבל אתם מוגבלים לפי החומרה שלכם.
האם שימוש ב-web crawler הוא חוקי ותואם פרטיות?
בדרך כלל סריקה של עמודים ציבוריים היא חוקית, אבל תמיד כדאי לבדוק תנאי שימוש ו-robots.txt. אל תסרקו מידע פרטי או מוגן סיסמה בלי הרשאה, ושימו לב לחוקי פרטיות אם אתם מחלצים מידע אישי ().