
כל AI web scraper נראה מרשים בסיור המוצר שלו. ואז מחברים אותו לאתר אמיתי עם הגנת Cloudflare, והוא מחזיר דף אתגר ובביטחון טוען שמצא 47 רישומי מוצרים.
בחודשים האחרונים הערכתי כלי גריפה עבור הצוות שלנו ב-Thunderbit. הפער בין ביצועי הדמו לבין האמינות בסביבת ייצור הוא, באופן עקבי, מקור התסכול הגדול ביותר שאני רואה בקהילות. משתמש אחד ב-Reddit ניסח זאת בצורה מושלמת: "מה מחזיק מעמד בייצור ומה עובד רק בדמו לפני שהוא מת אחרי שבועיים?" עם 31 מוצרים שמופיעים ב-Capterra בקטגוריית web scraping בלבד, ועוד עשרות תוספי Chrome, ספקי API ושווקי actors, פרדוקס הבחירה הוא אמיתי. אז בדקתי 12 מהם.
המאמר הזה מעריך 12 כלי AI web scraper לפי קריטריונים של סביבת ייצור: התמודדות עם בוטים, מדרגיות, איכות פלט מובנה, יעילות בעלויות, תמיכה באתרים דינמיים וגמישות למפתחים. בלי רשימות תכונות. בלי צילומי מסך שיווקיים. רק מה שבאמת עובד אחרי שהדמו נגמר.
לראות איך נראה AI Web Scraper מוכן לייצור
למה רוב ה-AI Web Scrapers נכשלים אחרי הדמו
הדפוס צפוי. אתר השיווק של הכלי מציג אותו מחלץ עמודות נקיות מדף רישום מוצרים פשוט. מתקינים אותו, מנסים אותו על אתר מסחר אלקטרוני מוגן, ומקבלים אחד מהבאים:
- תגובת
200 OKשמכילה דף אתגר של Cloudflare במקום נתונים אמיתיים - תוצאות נקיות עבור 5 הדפים הראשונים, ואז כשל שקט או שורות מומצאות
- חילוץ מושלם היום, סלקטורים שבורים בשבוע הבא אחרי עדכון פריסה קטן
אלה לא מקרי קצה. זה המצב הנפוץ.
כפי שאחד המומחים כתב ב-Reddit: "ה-scraper מחזיר 200 עם דף אתגר של Cloudflare, הסוכן שלך מנסה להסיק ממנו מסקנות, ממציא, ואין לך מושג למה."
הבעיה הבסיסית היא ארכיטקטונית. רוב הדמואים מציגים את שכבת הניתוח על דפים ציבוריים נקיים, בעוד שעבודה אמיתית נכשלת בשכבת השליפה. אתרי ייצור מוסיפים הגנה נגד בוטים, רינדור דינמי, דפי פירוט מקוננים, גלילה אינסופית, מצב התחברות, שונות בלוקאלים ופריסות משתנות.
כלי יכול להיראות מצוין בסיור מוצר ועדיין לקרוס בתוך תהליך העבודה הרציני הראשון של לקוח.
לכן המאמר הזה בוחן כל כלי דרך עדשת מוכנות לייצור, ולא דרך צ'ק-ליסט של תכונות. ששת הקריטריונים שבהם השתמשתי:
| קריטריון | למה זה חשוב |
|---|---|
| טיפול נגד בוטים/CAPTCHA | אתרים מוגנים נכשלים עוד לפני שאיכות החילוץ בכלל חשובה |
| מדרגיות מעבר לדמו | משימות אצווה והרצות מקבילות חושפות מגבלות תפעוליות |
| איכות פלט מובנה | משתמשים צריכים JSON/CSV נקיים, לא HTML גולמי שדורש ניקוי ידני |
| יעילות בטוקנים/עלות | חילוץ מבוסס AI יכול להיות יקר יותר מהגריפה עצמה |
| תמיכה באתרים דינמיים/כבדי JS | דפים מודרניים דורשים DOM מעובד, לא HTML סטטי |
| גמישות ללא קוד מול API | לצוותי מכירות ולמהנדסי נתונים יש צרכים שונים |
אם אתם רוצים סקירה מהירה ברמת השוק על איך web scraping השתנה בשנתיים האחרונות, ההרצאה הזו של Browserless היא נקודת פתיחה טובה לפני שמשווים בין הכלים אחד אחד.
איפה AI באמת עוזר בצינור גריפה, ואיפה הוא לא
מיתוס עיקש בשוק הזה הוא ש-"AI web scraper" אומר ש-AI מטפל בהכול מקצה לקצה. הקונצנזוס בקהילה ברור להפליא: scraper קודם, LLM אחר כך. הניסוח הישיר של משתמש אחד: "אתה משתמש ב-AI כדי לקרוא צילום מסך של דף אינטרנט. אתה לא משתמש ב-AI כדי לכתוב את ה-scraper עצמו."
לצינור הגריפה יש שלוש שכבות נפרדות, והערך של AI משתנה מאוד ביניהן:
זחילה ושליפה: שכבת התשתית
כאן קורות הבקשות: פרוקסי, דפדפנים headless, ניהול סשנים, פתרון CAPTCHA, ניסיונות חוזרים. AI כמעט לא מועיל כאן. עדיין צריך מאגרי פרוקסי, טביעת אצבע של דפדפן ותשתית עקיפה של חסימות. כאן רוב הכלים נכשלים קודם בסביבת ייצור.
ניתוח וחילוץ: המקום שבו AI מצטיין
אחרי שיש תוכן נקי של הדף, AI מצטיין בהפיכת HTML לא מובנה לשדות מובנים. חילוץ מבוסס סכימה, זיהוי שדות אדפטיבי וטיפול בווריאציות פריסה בלי סלקטורים שבירים של XPath הם נקודת החוזק של AI בגריפה.
עיבוד לאחר מכן: תיוג, תרגום, סיווג
אחרי החילוץ, AI מוסיף ערך בסיווג מוצרים, תרגום טקסט, נרמול מספרי טלפון או סיכום תיאורים. התאמה חזקה, אבל רק אם הנתונים שחולצו כבר נכונים.
כך 12 הכלים מתחלקים בין השכבות האלה:
| כלי | זחילה/שליפה | ניתוח/חילוץ | עיבוד לאחר מכן | תיאור מומלץ |
|---|---|---|---|---|
| Thunderbit | חזק | חזק | חזק | AI scraper מלא, ללא קוד |
| Octoparse | חזק | בינוני | נמוך | scraper חזותי מבוסס חוקים עם תשתית ענן |
| Browse AI | בינוני | בינוני | בינוני | פלטפורמת רובוטים בענן, ממוקדת ניטור |
| Firecrawl | בינוני | חזק | נמוך-בינוני | API חילוץ למפתחים |
| Apify | חזק | בינוני-חזק | בינוני | שוק actors ואורקסטרציה |
| Gumloop | בינוני | בינוני | חזק | אוטומציית workflows עם צמתי גריפה |
| Bright Data | חזק מאוד | בינוני | נמוך-בינוני | סט תשתית ארגוני |
| Bardeen | בינוני | בינוני | חזק | אוטומציית דפדפן ל-workflows של GTM |
| Diffbot | נמוך-בינוני | חזק מאוד | בינוני | חילוץ מאומן מראש בתוספת knowledge graph |
| ScrapingBee | חזק | נמוך-בינוני | נמוך | API לשליפה ולעקיפת חסימות |
| Instant Data Scraper | נמוך | בינוני (דפים פשוטים) | נמוך | scraper מהיר מבוסס היוריסטיקה בדפדפן |
| ParseHub | בינוני | בינוני | נמוך | scraper חזותי לדסקטופ עם אינטראקציות מורכבות |
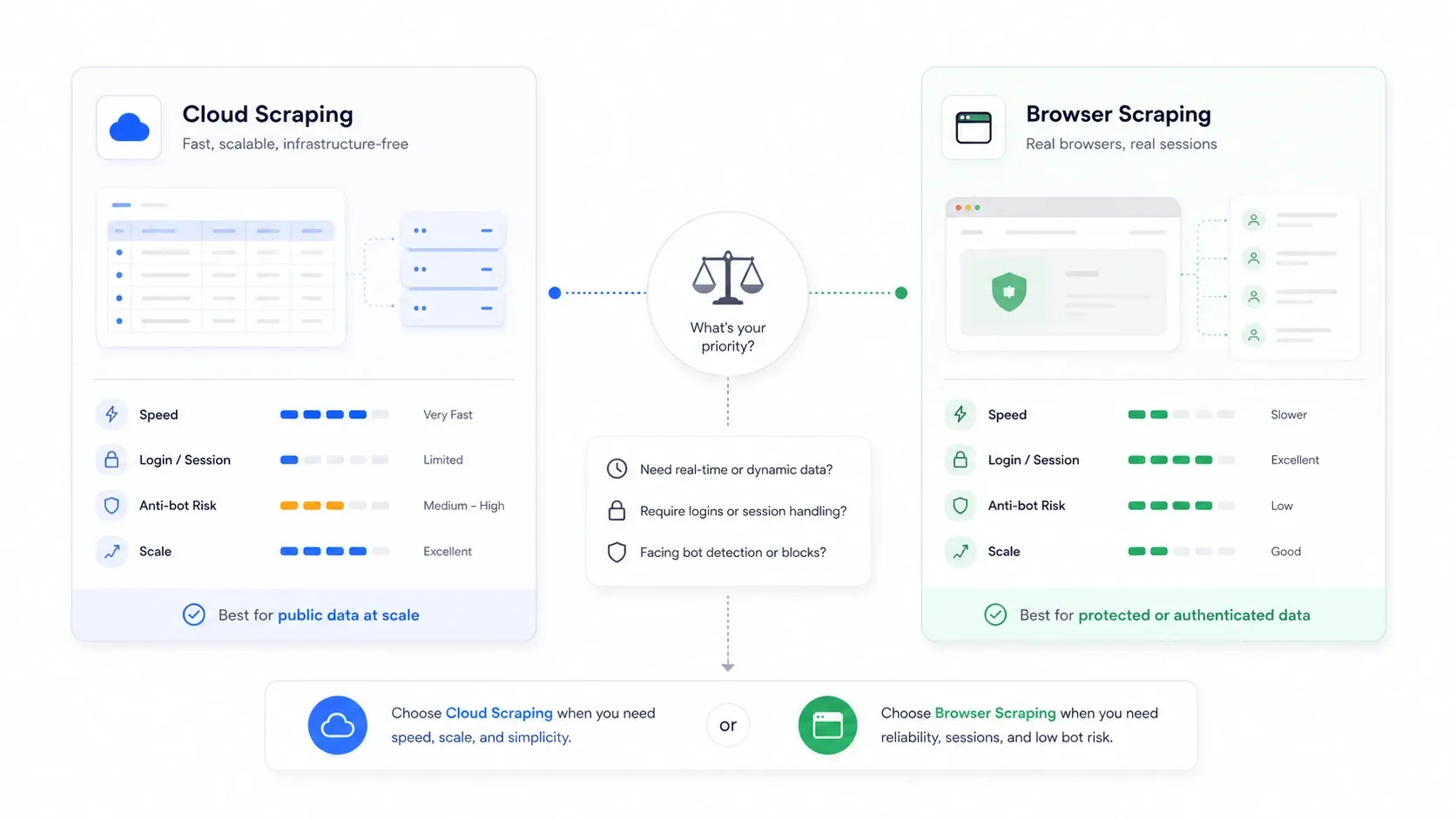
גריפה בענן מול גריפה בדפדפן: הבחירה שאף אחד לא מסביר
זו ההחלטה הארכיטקטונית שרוב מאמרי הסיכום מתעלמים ממנה לחלוטין, ולעיתים היא חשובה יותר מהכלי שבוחרים.
גריפה בענן פירושה ששרתים מרוחקים שולפים דפים בשמכם. גריפה בדפדפן פירושה שהחילוץ מתבצע בסשן הדפדפן שלכם, תוך שימוש בקוקיז שלכם, ב-IP שלכם ובמצב ההתחברות שלכם.
| תרחיש | מצב עדיף | למה |
|---|---|---|
| אתרי מסחר וקטלוגים ציבוריים בנפח גבוה | ענן | מקביליות מהירה יותר וללא צוואר בקבוק של המחשב המקומי |
| אתרים שדורשים התחברות או אימות | דפדפן | משתמש מחדש בקוקיז האמיתיים של הסשן |
| אתרים שמענישים כתובות IP של דאטה-סנטר | דפדפן | נראה כמו תעבורת משתמש רגילה |
| משימות ניטור חוזרות וגדולות | ענן | תזמון ורציפות קלים יותר |
| משימות חד-פעמיות, שבריריות ורגישות נגד-בוטים | דפדפן | קל יותר לבדוק מה האתר באמת רינדר |
גם כלכלית זה חשוב. דוח State of Web Scraping של Apify ל-2026 מצא ש-[65.8%] מהעוסקים בתחום הגדילו שימוש בפרוקסי](https://blog.apify.com/web-scraping-report-2026/) משנה לשנה, ו-62%+ דיווחו על הוצאות תשתית גבוהות יותר. אנטי-בוט הוא לא רק בעיה טכנית. הוא בעיית תקציב.
רוב הכלים מציעים רק מצב אחד. הנה החלוקה:
| כלי | ענן | דפדפן | שניהם |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (מקומי) | ✅ |
| Browse AI | ✅ | הגדרה בלבד | — |
| Firecrawl | ✅ | API לאינטראקטיבי | — |
| Apify | ✅ | ✅ (דרך actors) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | מוגבל (דפים ציבוריים) | ✅ | חלקי |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (בתשלום) | ✅ (דסקטופ) | ✅ |
12 ה-AI Web Scrapers במבט אחד
הנה ההשוואה המרכזית בין כל 12 הכלים:
| כלי | מתאים במיוחד ל | שכבה חינמית | ענן/דפדפן | גישת API | גריפה מתוזמנת | טיפול נגד בוטים |
|---|---|---|---|---|---|---|
| Thunderbit | צוותים לא טכניים | ✅ (6 דפים) | שניהם | ✅ | ✅ | חזק |
| Octoparse | גריפה עתירת תבניות | ✅ (מוגבל) | שניהם | ✅ | ✅ | בינוני-חזק |
| Browse AI | ניטור שינויים | ✅ (מוגבל) | בעיקר ענן | ✅ | ✅ | בינוני |
| Firecrawl | צינורות חילוץ למפתחים | ✅ (1,000 קרדיטים/חודש) | ענן + API לדפדפן | ✅ | לא | בינוני |
| Apify | צוותי מפתחים + שוק | ✅ ($5 שימוש חינם) | שניהם | ✅ | ✅ | חזק עם תוספים |
| Gumloop | אוטומציית workflows | ✅ (5,000 קרדיטים/חודש) | שניהם | ✅ | ✅ | בינוני |
| Bright Data | גישת נתונים לארגונים | ניסיון / קרדיטים | שניהם | ✅ | חיצוני | חזק מאוד |
| Bardeen | אוטומציית דפדפן למכירות ותפעול | ✅ (100 קרדיטים) | דפדפן תחילה | מוגבל | ✅ | בינוני-נמוך |
| Diffbot | APIs לחילוץ מובנה | ✅ (10,000 קרדיטים) | ענן | ✅ | לא | נמוך בשליפה / גבוה בחילוץ |
| ScrapingBee | שליפה ועקיפת חסימות למפתחים | ✅ (1,000 קרדיטים) | ענן | ✅ | לא | חזק |
| Instant Data Scraper | גריפות חינמיות חד-פעמיות | ✅ (חינם לחלוטין) | רק דפדפן | לא | לא | נמוך |
| ParseHub | workflows חזותיים מורכבים | ✅ (5 פרויקטים) | דסקטופ + ענן | ✅ | ✅ (בתשלום) | בינוני |
להבין איך חילוץ מבוסס AI משתלב בצינור גריפה אמיתי
1. Thunderbit
Thunderbit הוא ה-AI web scraper שבנינו במיוחד עבור צוותים לא טכניים שצריכים נתונים באיכות ייצור בלי לכתוב קוד או לנהל תשתית. תהליך העבודה המרכזי באמת כולל שתי לחיצות: AI Suggest Fields קורא את הדף ומציע עמודות, ואז Scrape מריץ את החילוץ במצב ענן או דפדפן.
מה שמבדיל אותו מסקרייפרים אחרים ללא קוד הוא הארכיטקטורה. Thunderbit מפריד בין נושאי זחילה כמו תשתית ענן, סבב פרוקסי, טיפול נגד בוטים ורינדור JavaScript לבין חילוץ AI שקורא HTML ומוציא עמודות מובנות. זה תואם לדפוס שמומחים ממליצים עליו: "scraper קודם, LLM אחר כך", אבל ארוז בזרימת עבודה של תוסף Chrome שמוכרי מכירות ומנהלי תפעול באמת יכולים להשתמש בה.
יתרונות מרכזיים
- גם גריפה בענן וגם בדפדפן באותו ממשק. אפשר לעבור בין המצבים לפי זהות האתר: ציבורי או דורש סשן מאומת. מצב הענן מטפל בעד 50 דפים במקביל.
- ה-AI קורא מחדש את מבנה הדף בכל פעם. אין צורך בתחזוקת XPath. כשהאתר משנה את הפריסה, Thunderbit מסתגל אוטומטית בהרצה הבאה.
- גריפת תתי-דפים. ה-AI מבקר בדפי פירוט מקושרים ומעשיר את טבלת הנתונים הראשית בלי קונפיגורציה ידנית.
- Field AI Prompts. תיוג מותאם, תרגום וסיווג במהלך החילוץ במקום כשלב נפרד של עיבוד לאחר מכן.
- ייצוא חינם ל-Google Sheets, Excel, Airtable ו-Notion.
- תבניות scraper מיידיות לאתרים פופולריים כמו Amazon, Zillow ו-LinkedIn.
- תזמון בשפה טבעית. תגידו לו "לגרוף כל יום שני ב-9 בבוקר" והוא ימיר את זה ללוח זמנים חוזר.
- Open API עם נקודות קצה של Distill ו-Extract, עיבוד באצוות של עד 100 כתובות URL, ומקביליות שפורסמה: מ-2 בחינם עד 50 ב-Pro 1.
איפה אפשר להשתפר
- השכבה החינמית קטנה בכוונה.
- חוויית ה-no-code מתבססת בעיקר על תוסף Chrome. מפתחים שרוצים workflows רק דרך API צריכים להשתמש ב-Open API בנפרד.
- לא הכלי הנכון אם הצורך העיקרי שלכם הוא תשתית פרוקסי גולמית בלי חילוץ.
תמחור
קיימת שכבה חינמית. חבילות no-code מתחילות ב-$9 לחודש בחיוב שנתי או $15 לחודש בחיוב חודשי עבור Starter. תמחור ה-API נפרד: שימוש חד-פעמי חינמי של 600 יחידות, ואז $16 לחודש בחיוב שנתי עבור Starter API ו-$40 לחודש בחיוב שנתי עבור Pro 1 API. ראו Thunderbit Pricing ו-API Pricing.
מתאים במיוחד ל: צוותי מכירות, מסחר אלקטרוני ותפעול שצריכים נתוני web מובנים בלי תמיכה הנדסית.
2. Octoparse
Octoparse הוא בונה workflows חזותי ל-web scraping עם ספרייה גדולה של תבניות מוכנות מראש. הוא קיים מספיק זמן כדי שיהיה לו תשתית ענן בשלה, והוא מטפל היטב ב-pagination באתרים מובנים וצפויים.
יתרונות מרכזיים
- תבניות גריפה מוכנות מראש רבות לאתרים פופולריים
- חילוץ בענן עם ריצות מתוזמנות
- סבב IP ופתרון CAPTCHA כתוספים בתשלום
- גישת API בחבילות הגבוהות יותר
איפה אפשר להשתפר
- יכולות AI קלות יותר מכלים שמבוססים על LLM. הצעת שדות עדיין נשענת יותר על תבניות מאשר על קריאה אדפטיבית.
- פריסות מורכבות או חריגות דורשות כוונון ידני משמעותי בעורך החזותי.
- עקומת הלמידה נעשית תלולה יותר כשצריך לוגיקה מותנית או פתרונות עקיפת חסימות.
תמחור
קיימת חבילה חינמית לנצח. דף התמיכה הרשמי כעת מפנה למחירים של Standard החל מ-$75 לחודש בחיוב שנתי ו-Professional החל מ-$208 לחודש בחיוב שנתי, בעוד שכמה דפים מקומיים ונתיבי שדרוג מציגים שקילות חודשיות גבוהות יותר. הנקודה החשובה היא שהתמחור של Octoparse כיום משלב שכבות מנוי עם תוספים בתשלום כמו residential proxies ופתרון CAPTCHA.
מתאים במיוחד ל: אנליסטים וצוותי תפעול שגורפים אתרים מובנים וידידותיים לתבניות בהיקף בינוני.
3. Browse AI
Browse AI היא פלטפורמת no-code מבוססת ענן שנבנתה בעיקר לניטור שינויים באתר לאורך זמן, כמו מחירי מתחרים, זמינות מלאי ועדכוני תוכן. הגריפה היא חלק מהמוצר, אבל ההבדל האמיתי הוא מערכת הניטור וההתראות החוזרת.
יתרונות מרכזיים
- זיהוי שינויים והתראות מובנים
- מקליט רובוטים ללא קוד עם הגדרה בקליק
- רובוטים מוכנים מראש לאתרים פופולריים
- תמיכה ב-proxy פרימיום בחבילות גבוהות יותר
איפה אפשר להשתפר
- תמחור מבוסס קרדיטים נעשה יקר מהר כשמנטרים דפי פירוט בהיקף גדול
- פחות אטרקטיבי לחילוץ חד-פעמי בקנה מידה גדול מאשר כלים מבוססי API
- טיפול אנטי-בוט בינוני; חלק מהאתרים עדיין דורשים פרוקסי פרימיום או פתרונות עוקפים
תמחור
קיים חשבון חינמי. החבילות בתשלום מתחילות סביב $19 לחודש בחיוב שנתי עבור Starter, עם שכבות גבוהות יותר של קרדיטים וניטור מעל זה.
מתאים במיוחד ל: צוותים שצריכים ניטור מתמשך של מחירי מתחרים, שינויי תוכן או רמות מלאי, ולא חילוץ המוני חד-פעמי.
4. Firecrawl
Firecrawl הוא API שמיועד למפתחים וממיר דפי אינטרנט ל-Markdown נקי או ל-JSON מובנה. הוא יושב בעיקר בשכבת החילוץ ומצוין עבור צוותים שבונים RAG pipelines או מזינים תוכן רשת ל-LLMs.
יתרונות מרכזיים
- איכות פלט Markdown מצוינת ל-workflows של LLM בהמשך
- API נקי עם scrape, crawl, map, search, extract ופעולות דפדפן
- תמיכה בעיבוד באצוות
- מקביליות מ-2 בחינם עד 100 ב-Growth
איפה אפשר להשתפר
- אין ממשק no-code ונדרשים כישורי פיתוח
- יש תמיכה מובנית בפרוקסי ובסיפוק נגד חסימות, אבל Firecrawl לא ממוצב כספק עקיפת חסימות ייעודי
- אין מתזמן מובנה ראשון-ממעלה למשימות חוזרות
- לא חסכוני למי שאינו מפתח ורק רוצה גיליון נתונים
תמחור
החבילה החינמית כוללת 1,000 קרדיטים בחודש. החבילות בתשלום מתחילות ב-$16 לחודש בחיוב שנתי עבור Hobby, ומתרחבות עם יותר קרדיטים, מקביליות ושימוש בדפדפן. סשנים של דפדפן מחויבים בנפרד בקרדיטים.
מתאים במיוחד ל: מפתחים שבונים pipelines של LLM, מערכות RAG או workflows מותאמי-חילוץ וזקוקים ל-Markdown או JSON נקיים מדפי אינטרנט.
5. Apify
Apify היא פלטפורמה עם שוק של scraping actors מוכנים מראש, לצד כלים לבניית actors מותאמים. אפשר לחשוב עליה כשכבת orchestration שבה בוחרים או בונים scraperים ייעודיים לאתרים מסוימים, ואז מתזמנים ומנהלים אותם דרך API מאוחד.
יתרונות מרכזיים
- שוק actors עצום עם scraperים שנבנו על ידי הקהילה למאות אתרים
- API ו-SDK חזקים למפתחים
- ניהול פרוקסי ותזמון מובנים
- משתלבת עם הרבה כלים downstream
איפה אפשר להשתפר
- "ללא קוד" נכון רק חלקית ברגע שיוצאים משוק הכלים וצריכים לוגיקה מותאמת
- האמינות של actors תלויה בתחזוקה של הקהילה
- המחיר יכול לטפס כי חישוב, עלות actors ופרוקסי מצטברים
תמחור
השכבה החינמית כוללת $5 בקרדיטים חודשיים לפלטפורמה. החבילות בתשלום מתחילות ב-$39 לחודש עבור Starter, עם שכבות גבוהות יותר המיועדות להתרחבות.
מתאים במיוחד ל: צוותי פיתוח שרוצים workflows גריפה ניתנים לשימוש חוזר ולתזמון, עם אקוסיסטם גדול של פתרונות מוכנים מראש.
6. Gumloop
Gumloop היא פלטפורמת אוטומציית workflows ללא קוד, הכוללת צומת לגריפת web. הערך האמיתי הוא לא הגריפה לבדה. הוא חיבור החילוץ ל-LLMs, ל-Google Sheets, ל-CRMs ולכלים אחרים על קנבס חזותי אחד.
יתרונות מרכזיים
- בונה workflows ויזואלי מסוג drag-and-drop
- משלב גריפה עם LLMs וכלים עסקיים downstream בזרימה אחת
- החבילה החינמית מוצגת כרגע עם 5,000 קרדיטים/חודש
- תזמון מבוסס זמן ל-workflows חוזרים
- מצבי scraping בסיסיים ו-Web Agent אינטראקטיבי מכסים גם זרימות פשוטות וגם עשירות יותר
איפה אפשר להשתפר
- מנוע הגריפה פחות חזק מכלי AI web scraper ייעודיים
- עומק הטיפול נגד בוטים והפרוקסי מוגבל יותר לעומת ספקים מתמחים
- מגבלות מקביליות וטריגרים הדוקות יותר בחינם
- לא אידיאלי כ-use case ראשי לגריפה בהיקף גדול ובנפח גבוה
תמחור
קיימת חבילה חינמית. Gumloop איחדה בסוף 2025 את מבנה Solo ו-Team הישן שלה לחבילת Pro, והמסרים הציבוריים מאז מתמקדים בקרדיטים חינמיים נדיבים יותר ובשכבות בתשלום מאוחדות, ולא בתמחור שמתחיל מה-scraper.
מתאים במיוחד ל: צוותים שרוצים שגריפה תהיה רק שלב אחד בתוך workflow אוטומטי רחב יותר: לגרוף, לנתח ולהזרים לכלים עסקיים.
אם אתם רוצים לראות איך מרגיש בפועל workflow של חילוץ ילידי-AI לפני שאתם קוראים את המשך הרשימה, ההדרכה הזו של Thunderbit היא הדמו הרלוונטי ביותר לצוותים לא טכניים.
7. Bright Data
Bright Data היא ערימת התשתית ברמת enterprise ברשימה הזו. אם הבעיה שלכם היא "אני לא מצליח לעבור את הגנת הבוטים באתר הזה לא משנה מה אני מנסה", Bright Data היא כנראה התשובה, אבל היא מגיעה עם מורכבות ותמחור תואמים ל-enterprise.
יתרונות מרכזיים
- רשת פרוקסי מובילה בתעשייה על פני residential, datacenter ו-mobile IPs
- Web Unlocker לעקיפת אנטי-בוט ו-CAPTCHA
- Scraping Browser עם עקיפה מובנית של חסימות
- מערכי נתונים שנאספו מראש לרכישה
- שליטה פרוגרמטית מלאה דרך API ו-SDK
איפה אפשר להשתפר
- לא מיועד למשתמשים לא טכניים
- התמחור משקף מיצוב ארגוני
- חילוץ AI אינו הסיבה העיקרית לקניית הפלטפורמה
תמחור
Browser API מתחיל ב-$8/GB לפי שימוש, עם תעריפים נמוכים יותר לכל GB בהתחייבויות חודשיות גדולות יותר. מוצרים אחרים של Bright Data כמו Unlocker, Scraper APIs, datasets ומאגרי פרוקסי משתמשים ביחידות תמחור שונות.
מתאים במיוחד ל: צוותי נתונים ארגוניים שצריכים לגרוף אתרים מוגנים מאוד בקנה מידה, ויש להם צוות טכני שינהל את התשתית.
8. Bardeen
Bardeen הוא כלי אוטומציה לדפדפן שמתמקד בלחיצות, מילוי טפסים וגריפה עם שכבת חילוץ נתונים מבוססת AI מעל. הכי נכון להבין אותו ככלי workflow של GTM שגם גורף, ולא ככלי גריפה שגם עושה GTM.
יתרונות מרכזיים
- אוטומציה אינטואיטיבית בסגנון playbook עם גריפה כשלב אחד
- scraperים רשמיים המתוחזקים על ידי צוות Bardeen לאתרים פופולריים
- אינטגרציות חזקות עם CRM, Google Sheets, Slack וכלים עסקיים אחרים
- טוב לגריפת לידים, העשרה ו-workflows של ייצוא ל-CRM
איפה אפשר להשתפר
- ארכיטקטורה של דפדפן תחילה מגבילה גריפה בנפח גבוה ללא השגחה
- גריפה בענן עובדת רק על דפים ציבוריים, לא על דפים מוגנים
- הטיפול נגד בוטים הוא בעיקר מה שסשן הדפדפן כבר מספק
- חילוץ AI עלול להיאבק בפריסות מורכבות או לא סטנדרטיות
תמחור
החבילה החינמית כוללת 100 קרדיטים חודשיים. תיעוד התמיכה הציבורי מתייחס לתמחור היסטורי של $15 לחודש Pro עבור משתמשים קיימים, בעוד שהאריזה המסחרית הנוכחית של Bardeen נוטה יותר לכיוון enterprise ו-workflows ופחות לתמחור קלאסי זול של scraper.
מתאים במיוחד ל: צוותי מכירות ותפעול שצריכים גריפה כחלק מ-workflow רחב יותר של אוטומציית דפדפן.
9. Diffbot
Diffbot משתמש בראייה ממוחשבת וב-NLP כדי לקרוא דפי אינטרנט כמו אדם, ולהוציא נתונים מובנים על מאמרים, מוצרים, דיונים וארגונים. זו אחת מ-APIs החילוץ האיכותיות ביותר שיש אם הדפים שלכם מתאימים למודלים שאומנו מראש.
יתרונות מרכזיים
- מודלי חילוץ מאומנים מראש למאמרים, מוצרים, דיונים ועוד
- Knowledge Graph עם מיליארדי ישויות להעשרת נתונים
- איכות פלט מובנה חזקה על סוגי דפים נתמכים
- API ברור למפתחים עם מגבלות קצב מפורסמות
איפה אפשר להשתפר
- אין ממשק no-code
- אין זחילה מובנית, ניהול פרוקסי או טיפול נגד בוטים
- יקר לצוותים קטנים
- פחות גמיש בסוגי דפים לא סטנדרטיים מאשר מחלצי סכימה עם prompts
תמחור
החבילה החינמית כוללת 10,000 קרדיטים. Startup הוא $299 לחודש עבור 250,000 קרדיטים, ו-Plus הוא $899 לחודש עבור 1,000,000 קרדיטים.
מתאים במיוחד ל: צוותי פיתוח שצריכים חילוץ מובנה מדויק מסוגי דפים סטנדרטיים ומוכנים לטפל בשליפה בנפרד.
10. ScrapingBee
ScrapingBee הוא API ל-web scraping שמתמקד בשכבת השליפה והעקיפה של חסימות. שולחים לו URL, והוא מטפל בפרוקסי, ברינדור דפדפן headless ובהגנות נגד בוטים, ומחזיר HTML או, לפי בחירה, נתונים מחולצים.
יתרונות מרכזיים
- סבב פרוקסי מובנה וטיפול נגד בוטים
- תמיכה ברינדור JavaScript
- REST API פשוט
- נקודת קצה ל-graping של Google Search
- מקביליות מפורסמת לפי חבילה
איפה אפשר להשתפר
- יכולות חילוץ AI מוגבלות
- אין ממשק no-code
- אין תזמון או ניטור מובנים
- תגובת
200עם דף חסימה עדיין יכולה להיחשב לבקשה מוצלחת
תמחור
החבילה החינמית כוללת 1,000 קרדיטי API. החבילות בתשלום מתחילות ב-$49 לחודש ומתרחבות עם יותר מקביליות ונפח בקשות.
מתאים במיוחד ל: מפתחים שצריכים בעיקר שליפת דפים אמינה מעבר להגנות אנטי-בוט, ויטפלו בחילוץ בקוד שלהם או בכלי נפרד.
11. Instant Data Scraper
Instant Data Scraper הוא תוסף Chrome חינמי עם יותר מ-1,000,000 משתמשים שמזהה אוטומטית דפוסי נתונים בדף ומאפשר ייצוא ל-CSV או Excel. אין כאן הצעת שדות מבוססת AI במובן של LLM. הוא משתמש בזיהוי דפוסים היוריסטי.
יתרונות מרכזיים
- חינם לחלוטין, ללא צורך בחשבון
- זיהוי נתונים בלחיצה אחת בהרבה דפי רשימות וטבלאות
- מטפל ב-pagination בחלק מהאתרים
- חסם כניסה נמוך במיוחד
- עדיין מתוחזק, עם עדכוני Chrome Web Store ב-2026
איפה אפשר להשתפר
- אין הצעת שדות או תיוג נתונים מבוססי AI
- אין גריפה בענן, תזמון או API
- מתקשה בפריסות מורכבות, תוכן דינמי ואתרים כבדי JS
- אין טיפול נגד בוטים מעבר למה שהדפדפן שלכם כבר יודע לטעון
- הייצוא מוגבל ל-CSV ו-Excel
תמחור
חינם. תמיד.
מתאים במיוחד ל: כל מי שצריך גריפה מהירה וחד-פעמית של דף רישום פשוט ולא רוצה לפתוח חשבון או לשלם כלום.
12. ParseHub
ParseHub היא אפליקציית דסקטופ עם ממשק חזותי של point-and-click לבניית פרויקטי גריפה. היא יכולה להתמודד עם נתונים מקוננים מורכבים, תוכן שנטען ב-AJAX, גלילה אינסופית ואינטראקציות עם dropdown, שכלים פשוטים יותר מפספסים לעיתים קרובות.
יתרונות מרכזיים
- ממשק סלקטורים חזותי להגדרת כללי חילוץ
- מטפלת בנתונים מקוננים, dropdowns, גלילה אינסופית ותוכן AJAX
- שכבה חינמית עם עד 5 פרויקטים
- ייצוא ל-JSON, CSV ו-Excel
- תזמון בענן וסבב IP בחבילות בתשלום
איפה אפשר להשתפר
- תהליך עבודה רק בדסקטופ, בלי הנוחות של תוסף דפדפן
- מהירות ביצוע איטית יותר מכלים ילידי-ענן
- פרויקטים נשברים כשפריסת האתר משתנה כי אין שכבת AI לקריאה מחדש
- יכולות AI מוגבלות ותחושה יותר ישנה של visual scraper
תמחור
קיימת חבילה חינמית עם 5 פרויקטים ו-200 דפים להרצה. החבילות בתשלום מתחילות ב-$189 לחודש עם תזמון, סבב IP ומגבלות גבוהות יותר.
מתאים במיוחד ל: משתמשים לא טכניים שצריכים לגרוף אתרים אינטראקטיביים מורכבים ומוכנים להשקיע זמן בהגדרת workflow חזותי.
איך להתחיל עם AI Web Scraper ב-5 שלבים
לכל כלי ברשימה יש תהליך onboarding שונה. אני אשתמש ב-Thunderbit כדוגמה קונקרטית כי הוא הכי מתאים לכוונת החיפוש של "אני רק צריך שזה יעבוד על דף אמיתי".
שלב 1: להתקין ולנווט
התקינו את Thunderbit Chrome Extension ונווטו לדף שאתם רוצים לגרוף: דף מוצרים, ספרייה או פורטל נדל״ן.
שלב 2: לתת ל-AI להציע את שדות הנתונים
לחצו על AI Suggest Fields. ה-AI קורא את הדף הנוכחי ומציע שמות עמודות וסוגי נתונים. בדף מוצר, הוא עשוי להציע Product Name, Price, Rating, Image URL ו-Description.
שלב 3: להתאים את השדות עם Promptים של AI
כוונו את העמודות אם ברירות המחדל לא בדיוק מתאימות. הוסיפו Field AI Prompts לשינויים מותאמים כמו "לתרגם את התיאור לספרדית", "לסווג כ-Electronics, Home או Fashion", או "לחלץ רק את המחיר המספרי".
שלב 4: לבחור מצב ענן או דפדפן ולגרוף
בחרו גריפה בענן לאתרים ציבוריים או גריפה בדפדפן ליעדים מאומתים או מוגנים מאוד. ואז לחצו על Scrape.
שלב 5: לייצא את הנתונים לכל מקום
ייצאו את התוצאות ל-Google Sheets, Excel, Airtable או Notion. הייצוא חינם.
מה אם פריסת האתר משתנה?
זהו יתרון ייצור מרכזי של מחלצים ילידי-AI לעומת כלים מבוססי חוקים. scraperים מסורתיים כמו ParseHub ו-workflows ישנים של Octoparse נשענים על סלקטורים של XPath או נתיבי CSS. כשאתר מעדכן את מבנה ה-HTML שלו, הסלקטורים נשברים ואתם חוזרים להגדרה ידנית.
מחלצים מבוססי AI כמו Thunderbit קוראים מחדש את מבנה הדף בכל פעם. המשמעות היא שאין צורך בתחזוקת XPath ואין סלקטורים שבירים. ה-AI מסתגל לשינויי פריסה אוטומטית בהרצה הבאה.
גריפה מתוזמנת וגישת API: תכונות למשתמשי-על שאף אחד לא סוקר
גריפות חד-פעמיות טובות למחקר. מקרי שימוש בסביבת ייצור כמו ניטור מחירים, רענון רשימות לידים ומעקב מלאי דורשים חילוץ חוזר וגישת פרוגרממטית. התכונות האלה מפרידות בין צעצועים לכלים.
תמיכה בתזמון
| כלי | תזמון מובנה | הערות |
|---|---|---|
| Thunderbit | ✅ | הגדרה בשפה טבעית |
| Octoparse | ✅ | ריצות ענן מתוזמנות |
| Browse AI | ✅ | תכונת מוצר מרכזית |
| Firecrawl | ❌ | שימוש ב-cron חיצוני |
| Apify | ✅ | ביטויי cron מלאים |
| Gumloop | ✅ | טריגרים מבוססי זמן ל-workflows |
| Bright Data | חיצוני | בדרך כלל מאורגן דרך מערכות הלקוח |
| Bardeen | ✅ | תזמון playbook |
| Diffbot | ❌ | API-first, orchestration חיצונית |
| ScrapingBee | ❌ | API בלבד |
| Instant Data Scraper | ❌ | כלי דפדפן ידני |
| ParseHub | ✅ (בתשלום) | תכונת פרימיום |
השוואת API למפתחים
| כלי | אינדיקציית מקביליות או קצב | מודל תמחור |
|---|---|---|
| Thunderbit | 2 → 50 במקביל | מבוסס קרדיטים |
| Firecrawl | 2 → 100 במקביל | מבוסס קרדיטים |
| Apify | תלוי בחבילה | Compute units |
| Gumloop | מקביליות workflows מוגבלת לפי חבילה | מבוסס קרדיטים |
| Diffbot | 5 calls/min → 25 calls/sec | מבוסס קרדיטים |
| ScrapingBee | 10 → 200 במקביל | API מבוסס קרדיטים |
| Bright Data | Browser API מפרסם בקשות מקבילות ללא הגבלה | מבוסס GB |
אם השימוש שלכם יותר טכני ואתם מנסים להחליט כמה תשתית אתם רוצים להחזיק בעצמכם, ההדרכה הזו של Firecrawl היא השלמה שימושית ומכוונת-ביצוע להשוואות המוצרים למעלה.
איך לבחור את ה-AI Web Scraper הנכון
אחרי שבדקתי את כל 12 הכלים, כך הייתי מחליט:
- צוות לא טכני שצריך נתונים מהר: להתחיל עם Thunderbit. תהליך שתי הלחיצות, הייצוא החינמי והמעבר בין דפדפן לענן מכסים את רוב צורכי הגריפה העסקיים בלי תמיכה הנדסית.
- צריך ניטור והתראות מתמשכים: Browse AI בנוי בדיוק לזה. הוא לא מחלץ חד-פעמי הכי חזק, אבל זיהוי השינויים שלו הוא תכונת ליבה.
- מפתח שבונה pipeline של LLM: Firecrawl ל-Markdown או JSON, או Diffbot לחילוץ מובנה מאומן מראש. לשלב אחד מהם עם ScrapingBee או Bright Data אם צריך טיפול רציני נגד בוטים בשכבת השליפה.
- צריך שוק של scraperים מוכנים מראש: ל-Apify יש את אקוסיסטם ה-actors הגדול ביותר. רק צריך להיות מוכנים לתחזוקה כש-actors נשברים.
- יעד ברמת enterprise ומוגן מאוד: Bright Data. שום דבר אחר לא משתווה לתשתית הפרוקסי שלה, אבל צריך להתאים את התקציב והצוות הטכני בהתאם.
- רוצים שגריפה תהיה חלק מאוטומציה רחבה יותר: Gumloop או Bardeen, תלוי אם אתם מאוטמטים workflows או משימות GTM מבוססות דפדפן.
- רק צריכים גריפה חינמית ומהירה: Instant Data Scraper. אפס הגדרה, אפס עלות, אפס מורכבות, אבל גם אפס תזמון, אפס AI ואפס ענן.
- אתרים אינטראקטיביים מורכבים עם dropdowns ו-AJAX: ParseHub עדיין מטפל בהם טוב יותר מרוב התוספים, למרות שעלות התחזוקה אמיתית.
לבדוק את Thunderbit על דף אמיתי לפני שאתם מתחייבים לסטאק גדול יותר
סיכום
שוק ה-AI web scraper ב-2026 עמוס בכלים שנראים מרשימים בדמו ומאכזבים בייצור. הפער בין "עובד בצילום מסך שיווקי" לבין "עובד באתר מסחר מוגן ב-3 לפנות בוקר לפי לוח זמנים" הוא המקום שבו רוב הקונים מבזבזים זמן וכסף.
התובנה המרכזית מהערכת כל 12 הכלים היא פשוטה: שכבת השליפה עדיין החלק הקשה. AI מצטיין בחילוץ ובעיבוד לאחר מכן, אבל הוא לא מחליף תשתית פרוקסי, טיפול נגד בוטים או ניהול סשנים. הכלים הטובים ביותר או פותרים את שתי השכבות, כמו Thunderbit ו-Bright Data, או כנים לגבי השכבה שהם מכסים, כמו Firecrawl לחילוץ ו-ScrapingBee לשליפה.
אם אתם רוצים לראות איך נראה AI web scraper מוכן לייצור בלי לכתוב קוד, נסו את Thunderbit. השכבה החינמית מספיקה כדי לבדוק את כל ה-workflow על דפים אמיתיים. אם הצרכים שלכם יותר מוכווני פיתוח, שלבו API לחילוץ עם שירות שליפה ייעודי וחסכו לעצמכם את התסכול שבציפייה שכלי אחד יעשה הכול.
שאלות נפוצות
למה רוב ה-AI web scrapers נכשלים באתרים אמיתיים אחרי שעבדו מצוין בדמו?
דמואים בדרך כלל מציגים חילוץ על דפים נקיים ולא מוגנים. אתרים אמיתיים מוסיפים הגנת Cloudflare, רינדור JavaScript דינמי, pagination, דרישות התחברות ופריסות שמשתנות לעיתים קרובות. רוב הכלים מטפלים טוב בשכבת הניתוח והחילוץ, אבל חסרה להם תשתית חזקה לשכבת השליפה.
מה ההבדל בין גריפה בענן לגריפה בדפדפן, ומתי להשתמש בכל אחת?
גריפה בענן משתמשת בשרתים מרוחקים כדי לשלוף דפים, ולכן היא מהירה, מקבילית וסקיילבילית יותר. גריפה בדפדפן רצה בסשן הדפדפן שלכם ומתאימה יותר לאתרים מאומתים או לאתרים עם זיהוי בוטים אגרסיבי. Thunderbit הוא אחד הכלים הבודדים שמציעים את שני המצבים באותו ממשק.
האם אפשר להשתמש ב-AI web scraper למשימות חוזרות כמו ניטור מחירים?
כן, אבל רק אם הכלי תומך בגריפה מתוזמנת. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen ו-ParseHub בחבילות בתשלום כוללים תזמון.
איזה AI web scraper הוא הטוב ביותר אם אין לי כישורי קוד?
Thunderbit מציע את הנתיב המהיר ביותר לנתונים שימושיים עבור משתמשים לא טכניים. Instant Data Scraper הוא חינמי לחלוטין אבל מוגבל לדפים פשוטים. Browse AI ו-Octoparse מציעים ממשקים חזותיים עם יותר הגדרה. ParseHub חזק לאתרים אינטראקטיביים מורכבים אבל עקומת הלמידה שלו תלולה יותר.
כמה באמת עולה AI web scraping ברמת ייצור?
הטווח רחב. Instant Data Scraper חינמי. Thunderbit, Firecrawl ו-Browse AI מציעים נקודות כניסה חינמיות עם חבילות בתשלום בעלות נמוכה. כלים ברמת ביניים כמו Octoparse, ParseHub ו-ScrapingBee יכולים לנוע בערך בין $49 ל-$189 בחודש. פתרונות ארגוניים כמו Bright Data ו-Diffbot מתחילים הרבה יותר גבוה.




