
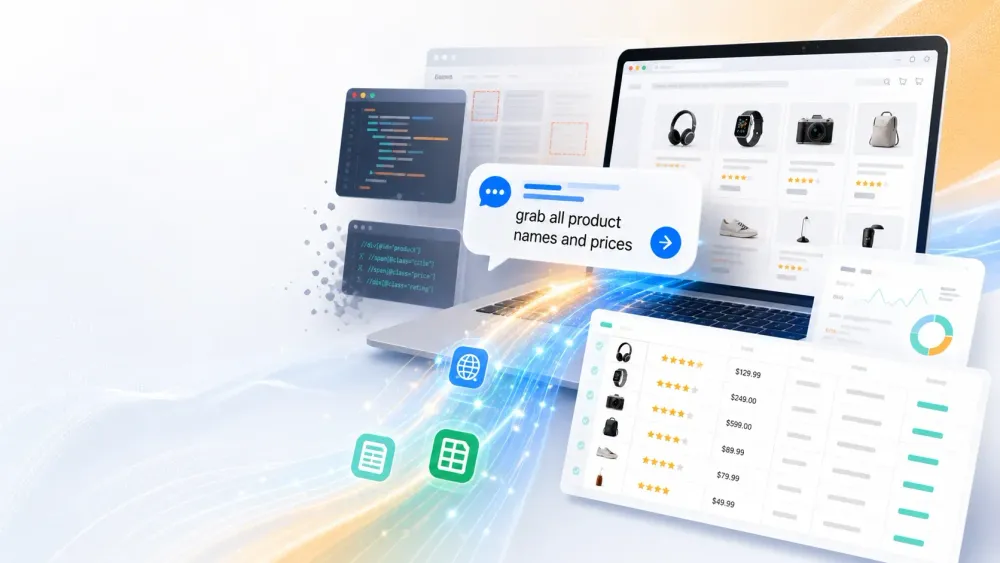
ב-2015, גריפת נתונים דרשה להתחנן בפני מפתח שיכתוב סקריפט Python, או לבלות סוף שבוע בלימוד XPath. ב-2026, אתה כותב “תביא את כל שמות המוצרים והמחירים” — וה-AI עושה את השאר.
המהפך הזה קרה מהר. יותר מ-2 מיליון חברות מסתמכות היום על גריפת אתרים. השוק עבר את המיליארד דולר ב-2024 והוא בדרך להכפיל את עצמו עד 2030.
המנוע הכי גדול? סורקי רשת מבוססי AI. הם מסתגלים לשינויים בפריסה, מבינים את תוכן הדף ולא רק תגיות HTML, ועובדים גם למי שמעולם לא כתב שורת קוד אחת.
השקעתי חודשים בבדיקה של 15 כאלה. הנה מה שמצאתי — כולל למה Thunderbit (כן, החברה שהקמתי יחד) זכה במקום הראשון.
למה AI משנה את גריפת דפי אינטרנט: העידן החדש של כלי Web Scraper
גרוף נתונים מכל אתר באמצעות AI Get Started Free
בואו נדבר דוגרי: גריפת רשת מסורתית מעולם לא נבנתה למשתמש העסקי הממוצע. הכול סבב סביב קוד, סלקטורים, ותפילה שהסקריפט שלכם לא יישבר בפעם הבאה שהאתר ישנה את הפריסה שלו. אבל AI ו-LLMs שינו את התמונה לגמרי.
כך זה עובד:
- הוראות בשפה טבעית: במקום להיאבק בקוד, פשוט אומרים ל-AI מה רוצים. כלים כמו Thunderbit מבינים את ההוראות שלך באנגלית פשוטה ומגדירים עבורך את החילוץ (מקור).
- למידה אדפטיבית: סקרפרים מבוססי AI יכולים להסתגל לשינויים בפריסה באתרים, וכך להפחית כאבי תחזוקה.
- טיפול בתוכן דינמי: אתרים מודרניים אוהבים JavaScript וגלילה אינסופית. כלים מונעי AI יודעים לעבוד עם האלמנטים האלה, ולחלץ נתונים שסקרפרים מהדור הישן היו מפספסים.
- פלט מובנה עם ניתוח AI: סקרפרים מבוססי LLM ממש מבינים את תוכן הדף ומוציאים נתונים נקיים ומובנים.
- עקיפה אוטומטית של הגנות נגד בוטים: סקרפרים מבוססי AI יכולים לעקוף מנגנוני אנטי-גריפת נתונים ולהשתמש בפרוקסי/דפדפנים ללא ממשק כדי להימנע מחסימות IP.
- זרימות נתונים משולבות: הכלים הטובים ביותר לא רק אוספים נתונים — הם מעבירים אותם למקום שבו צריך, עם ייצוא בלחיצה אחת ל-Google Sheets, Airtable, Notion ועוד (מקור).
התוצאה? גריפת אתרים היא עכשיו חוויה של הצבע-הקלק, ואפילו כמעט כמו צ'אט, שפותחת את הדלת לצוותי מכירות, שיווק ותפעול — לא רק למפתחים — לנצל נתוני רשת ישירות.
15 סורקי רשת מבוססי AI ששווה להכיר ב-2026
בואו נפרק את 15 סורקי הרשת מבוססי ה-AI המובילים, ונתחיל ב-Thunderbit. אתן סקירה של כל כלי: התכונות המרכזיות, קהל היעד, המחיר, ומה מייחד אותו. וכן, אהיה כן לגבי איפה כל אחד חזק — ואיפה אולי פחות.
1. Thunderbit: סקרפר ה-AI לכולם
ברור שיש לי כאן קצת הטיה, אבל Thunderbit הוא סקרפר ה-AI שהלוואי שהיה לי לפני שנים. הנה למה הוא במקום הראשון ברשימה:
- חילוץ בשפה טבעית: אתה “משוחח” עם Thunderbit. פשוט תאר את הנתונים שאתה רוצה — “גרוף את כל שמות המוצרים והמחירים מהעמוד הזה” — וה-AI עושה את השאר (מקור). בלי קוד, בלי סלקטורים, בלי כאב ראש.
- סריקת תתי-דפים וריבוי רמות: Thunderbit יכול לעקוב אחרי קישורים ולגרוף תתי-דפים. למשל, לגרוף רשימת מוצרים ואז להיכנס לכל מוצר כדי לחלץ פרטים, הכול ברצף אחד.
- פלט מובנה מיידי: ה-AI מformat ומנקה נתונים תוך כדי תנועה, מציע שדות רלוונטיים, מנרמל פורמטים, ואפילו מסכם או מסווג טקסט.
- תמיכה רחבה במקורות: Thunderbit לא מיועד רק ל-HTML — הוא יכול לחלץ גם מ-PDFים ומתמונות באמצעות OCR ו-vision AI מובנים (מקור).
- אינטגרציות עסקיות: ייצוא בלחיצה אחת ל-Google Sheets, Airtable, Notion או Excel (מקור). קבעו גריפות מתוזמנות ותנו לנתונים לזרום ישירות לתוך זרימת העבודה של הצוות.
- תבניות מוכנות מראש: לאתרים כמו Amazon, LinkedIn, Zillow וכו', Thunderbit מציע “מתכוני” גריפה מוכנים לחילוץ נתונים בלחיצה אחת.
- ידידותי למשתמש ונגיש: הממשק הוא הצבע-הקלק, עם עוזר אינטואיטיבי. משתמשים מדווחים שהם מתחילים לעבוד תוך דקות.

Thunderbit זוכה לאמון של יותר מ-30,000 משתמשים ברחבי העולם, כולל צוותים ב-Accenture, Grammarly ו-Puma. צוותי מכירות משתמשים בו כדי לבנות רשימות לידים, מתווכי נדל”ן מאחדים רישומי נכסים, ומשווקים עוקבים אחרי מתחרים — הכול בלי לכתוב שורת קוד אחת.
מחיר: יש מסלול חינמי (עד 100 שלבים לחודש), ותוכניות בתשלום שמתחילות ב-14.99 דולר לחודש. אפילו התוכניות המקצועיות משתלמות ליחידים ולצוותים קטנים.
Thunderbit הוא הדבר הכי קרוב שראיתי ל“להפוך את האינטרנט למסד נתונים” — והוא בנוי לכולם, לא רק למהנדסים.
נסו את תוסף Chrome של Thunderbit
2. Crawl4AI
למי זה מיועד: מפתחים וצוותים טכניים שבונים צינורות מותאמים אישית.
Crawl4AI הוא מסגרת קוד פתוח מבוססת Python, מותאמת למהירות ולסריקה בקנה מידה גדול, עם מחשבה על אינטגרציה עם LLMs. הוא מהיר מאוד, תומך בדפדפנים ללא ממשק עבור תוכן דינמי, ויכול לבנות נתונים מחולצים בצורה מובנית כדי להזין בקלות זרימות עבודה של AI.
- הכי טוב ל: מפתחים שצריכים מנוע סריקה חזק וניתן להתאמה.
- מחיר: חינם (רישיון MIT). תצטרכו לארח ולהפעיל אותו בעצמכם.
3. ScrapeGraphAI
למי זה מיועד: מפתחים ואנליסטים שבונים סוכני AI או צינורות נתונים מורכבים.
ScrapeGraphAI הוא ספריית Python בקוד פתוח, מונעת פרומפטים, שהופכת אתרים לגרפים מובנים של נתונים באמצעות LLMs. אפשר לכתוב פרומפטים כמו “חלץ את כל שמות המוצרים, המחירים והדירוגים מ-5 העמודים הראשונים”, והוא בונה עבורך זרימת עבודה של גריפה (מקור).
- הכי טוב ל: משתמשים טכניים שרוצים גריפה גמישה מבוססת פרומפטים.
- מחיר: חינם לספריית הקוד הפתוח; ה-API בענן מתחיל ב-20 דולר לחודש.
4. Firecrawl
למי זה מיועד: מפתחים שבונים סוכני AI או צינורות נתונים בקנה מידה גדול.
Firecrawl היא פלטפורמת סריקה ו-API ממוקדת AI, שהופכת אתרים שלמים לנתונים “מוכנים ל-LLM” (מקור). היא מוציאה Markdown או JSON, מטפלת בתוכן דינמי, ומשתלבת עם מסגרות כמו LangChain ו-LlamaIndex.
- הכי טוב ל: מפתחים שצריכים להזרים נתוני רשת חיים למודלי AI.
- מחיר: ליבת הקוד הפתוח חינמית; תוכניות הענן מתחילות ב-19 דולר לחודש.
5. Browse AI
למי זה מיועד: משתמשים עסקיים, Growth hackers ואנליסטים.
Browse AI היא פלטפורמת ללא-קוד עם ממשק הצבע-הקלק. אתם “מאמנים” רובוט על ידי לחיצה על הנתונים הרצויים, וה-AI מכליל את הדפוס לגריפות עתידיות. הוא מטפל בכניסות, גלילה אינסופית, ויכול לנטר אתרים לשינויים.
- הכי טוב ל: משתמשים לא-טכניים שרוצים לאוטומט איסוף נתונים וניטור.
- מחיר: תוכנית חינם (50 קרדיטים לחודש); תוכניות בתשלום מתחילות ב-19 דולר לחודש.
6. LLM Scraper
למי זה מיועד: מפתחים שרוצים שה-AI יעשה את הניתוח.
LLM Scraper היא ספריית JavaScript/TypeScript בקוד פתוח שמאפשרת לכם להגדיר סכימת נתונים ולתת ל-LLM לחלץ את הנתונים האלה מכל דף אינטרנט. היא בנויה על Playwright, תומכת במספר ספקי LLM, ואפילו יכולה לייצר קוד שניתן לשימוש חוזר.
- הכי טוב ל: מפתחים שרוצים להפוך כל דף אינטרנט לנתונים מובנים באמצעות LLMs.
- מחיר: חינם (רישיון MIT).
7. Reader (Jina Reader)
למי זה מיועד: מפתחים שבונים יישומי LLM, צ'אטבוטים או מסכמים.
Jina Reader הוא API שמחלץ טקסט נקי ונתונים מובנים מדפי אינטרנט (ואפילו מ-PDFים/תמונות), ומחזיר Markdown או JSON מוכנים ל-LLM. הוא מופעל על ידי מודל AI ייעודי, ואפילו יכול לכתוב כיתובים לתמונות.
- הכי טוב ל: שליפת תוכן נקי וקריא עבור LLMs או מערכות שאלות ותשובות.
- מחיר: API חינמי (אין צורך במפתח לשימוש בסיסי).
8. Bright Data
למי זה מיועד: ארגונים ומשתמשים מקצועיים שצריכים קנה מידה, תאימות ואמינות.
Bright Data היא שחקנית כבדה בתעשיית נתוני האינטרנט, עם רשת פרוקסי ענקית וכלי גריפה מונעי AI. היא מציעה סקרפרים מוכנים מראש, Web Scraper API כללי, וזרימות נתונים “מוכנות ל-LLM”.
- הכי טוב ל: ארגונים שצריכים נתוני רשת אמינים בקנה מידה.
- מחיר: מבוסס שימוש, פרימיום. יש ניסיון חינם.
9. Octoparse
למי זה מיועד: משתמשים לא-טכניים עד חצי-טכניים.
Octoparse הוא כלי ותיק ללא-קוד עם מעצב תהליכי עבודה ויזואלי וזיהוי אוטומטי מונע AI. הוא מטפל בכניסות, גלילה אינסופית, ויכול לייצא נתונים במגוון פורמטים.
- הכי טוב ל: אנליסטים, בעלי עסקים קטנים או חוקרים.
- מחיר: יש תוכנית חינם; תוכניות בתשלום מתחילות ב-119 דולר לחודש.
10. Apify
למי זה מיועד: מפתחים וצוותי טכנולוגיה שצריכים גריפה/אוטומציה מותאמת.
Apify היא פלטפורמת ענן להפעלת סקריפטי גריפה (“actors”) ומציעה חנות של actors מוכנים מראש. היא ניתנת להרחבה, משתלבת עם AI, ותומכת בניהול פרוקסי.
- הכי טוב ל: מפתחים שרוצים להריץ סקריפטים מותאמים בענן.
- מחיר: תוכנית חינם; תוכניות בתשלום לפי שימוש מתחילות ב-49 דולר לחודש.
11. Zyte (Scrapy Cloud)
למי זה מיועד: מפתחים וחברות שצריכים גריפה ברמת ארגון.
Zyte היא החברה מאחורי Scrapy, ומציעה פלטפורמת ענן וחילוץ אוטומטי מונע AI. היא מטפלת בתזמון, פרוקסי ופרויקטים בקנה מידה גדול.
- הכי טוב ל: צוותי פיתוח שמריצים פרויקטי גריפה ארוכי טווח.
- מחיר: מניסיונות חינם ועד תוכניות ארגוניות מותאמות אישית.
12. Webscraper.io
למי זה מיועד: מתחילים, עיתונאים וחוקרים.
Webscraper.io היא תוסף Chrome פופולרי לחילוץ נתונים בהצבעה והקלקה. היא פשוטה, חינמית לשימוש מקומי, ומציעה שירות ענן למשימות גדולות יותר.
- הכי טוב ל: משימות גריפה מהירות, חד-פעמיות.
- מחיר: תוסף חינמי; תוכניות ענן מתחילות בכ-50 דולר לחודש.
13. ParseHub
למי זה מיועד: משתמשים לא-טכניים שצריכים יותר כוח מכלים בסיסיים.
ParseHub היא אפליקציית דסקטופ עם תהליך עבודה ויזואלי לגריפת תוכן דינמי, כולל מפות וטפסים. היא יכולה להריץ פרויקטים בענן ומציעה API.
- הכי טוב ל: משווקים דיגיטליים, אנליסטים ועיתונאים.
- מחיר: יש תוכנית חינם (200 דפים להרצה); תוכניות בתשלום מתחילות ב-189 דולר לחודש.
14. Diffbot
למי זה מיועד: ארגונים וחברות AI שצריכים נתוני רשת מובנים בקנה מידה גדול.
Diffbot משתמשת ב-Computer Vision וב-NLP כדי לחלץ נתונים באופן אוטומטי מכל דף אינטרנט, ומציעה APIs למאמרים, מוצרים וגרף ידע עצום.
- הכי טוב ל: מודיעין שוק, פיננסים ונתוני אימון ל-AI.
- מחיר: פרימיום, החל מכ-299 דולר לחודש.
15. DataMiner
למי זה מיועד: משתמשים לא-טכניים, במיוחד במכירות, שיווק ועיתונות.
DataMiner הוא תוסף Chrome לחילוץ מהיר של נתוני רשת בהצבעה והקלקה. יש לו ספריית “מתכונים” מוכנים מראש, ויכול לייצא ישירות ל-Google Sheets.
- הכי טוב ל: משימות מהירות כמו ייצוא טבלאות או רשימות לגיליונות.
- מחיר: תוכנית חינמית (500 דפים ביום); Pro מתחילה בכ-19 דולר לחודש.
השוואה בין כלי ה-AI Web Scraper המובילים: איזה מתאים לצרכים שלך?
הנה השוואה ברמה גבוהה שתעזור לך למצוא את ההתאמה:
| כלי | שימוש ב-AI/LLM | קלות שימוש | פלט/אינטגרציה | מתאים במיוחד ל | מחיר |
|---|---|---|---|---|---|
| Thunderbit | ממשק שפה טבעית; AI מציע שדות | הכי קל (צ'אט ללא קוד) | ייצוא ל-Sheets, Airtable, Notion | צוותים לא טכניים | מסלול חינמי; Pro בכ-30$/חודש |
| Crawl4AI | סריקה מוכנה ל-AI; אינטגרציה עם LLMs | קשה (קוד Python) | ספרייה/CLI; אינטגרציה דרך קוד | מפתחים שצריכים צינורות נתונים מהירים ל-AI | חינם |
| ScrapeGraphAI | צינורות פרומפט של LLM לגריפה | בינוני (קצת קוד או API) | API/SDK; פלט JSON | מפתחים/אנליסטים שבונים סוכני AI | חינם כ-OSS; API החל מ-20$/חודש |
| Firecrawl | סורק ל-Markdown/JSON מוכנים ל-LLM | בינוני (שימוש ב-API/SDK) | SDKs (Py, Node וכו'); אינטגרציה ל-LangChain | מפתחים שמזינים נתוני רשת חיים ל-AI | חינם + ענן בתשלום |
| Browse AI | הצבעה והקלקה בעזרת AI | קל (ללא קוד) | יותר מ-7000 אינטגרציות אפליקציה (Zapier) | משתמשים לא טכניים שמאוטומטים ניטור רשת | חינם 50 הרצות; בתשלום מ-19$/חודש |
| LLM Scraper | משתמש ב-LLMs לניתוח דף לפי סכימה | קשה (קוד TS/JS) | ספריית קוד; פלט JSON | מפתחים שרוצים שה-AI יעשה את הניתוח | חינם (עם API LLM משלכם) |
| Reader (Jina) | מודל AI מחלץ טקסט/JSON | קל (קריאת API פשוטה) | REST API מחזיר Markdown/JSON | מפתחים שמוסיפים חיפוש/תוכן רשת ל-LLMs | API חינמי |
| Bright Data | APIs משופרים ב-AI; רשת פרוקסי ענקית | קשה (API, טכני) | APIs/SDKs; זרימות נתונים או datasets | ארגונים בקנה מידה | לפי שימוש |
| Octoparse | זיהוי אוטומטי מונע AI של רשימות | בינוני (אפליקציה ללא קוד) | CSV/Excel, API לתוצאות | משתמשים חצי-טכניים | חינם מוגבל; 59–166$/חודש |
| Apify | כמה יכולות AI (Actors, מדריכי AI) | קשה (סקריפטים בקוד) | API מקיף; משתלב עם LangChain | מפתחים שצריכים גריפה מותאמת בענן | תוכנית חינם; תשלום לפי שימוש |
| Zyte (Scrapy) | חילוץ אוטומטי מבוסס ML; מסגרת Scrapy | קשה (קוד Python) | API, ממשק Scrapy Cloud; JSON/CSV | צוותי פיתוח, פרויקטים ארוכי טווח | תמחור מותאם אישית |
| Webscraper.io | בלי AI (תבניות ידניות) | קל (תוסף דפדפן) | הורדת CSV, Cloud API | מתחילים, גריפות מהירות חד-פעמיות | תוסף חינמי; ענן בכ-50$/חודש |
| ParseHub | בלי LLM מפורש; בונה ויזואלי | בינוני (אפליקציה ללא קוד) | JSON/CSV; API להרצות בענן | לא-מפתחים שגורפים אתרים מורכבים | חינם 200 דפים; בתשלום מ-189$/חודש |
| Diffbot | Vision/NLP מבוססי AI לכל דף; גרף ידע | קל (רק קריאות API) | APIs (Article/Prod/...) + שאילתות Knowledge Graph | ארגונים, נתוני רשת מובנים | החל מכ-299$/חודש |
| DataMiner | בלי LLM; מתכונים קהילתיים | הכי קל (ממשק דפדפן) | ייצוא Excel/CSV; Google Sheets | משתמשים לא טכניים שגורפים לגיליונות | חינם מוגבל; Pro בכ-19$/חודש |
קטגוריות של כלים: ממנועי-על למפתחים ועד סקרפרים ידידותיים לעסק
כדי להבין את הרשימה, נחלק את הכלים לכמה קטגוריות:
1. מנועי-על למפתחים ולקוד פתוח
- דוגמאות: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- חוזקות: גמישות גבוהה, קנה מידה והתאמה אישית. מצוינים לבניית צינורות מותאמים או לאינטגרציה עם מודלי AI.
- פשרות: דורשים מיומנויות קוד ויותר קונפיגורציה.
- שימושים: בניית צינור נתונים מותאם, גריפת אתרים מורכבים, או אינטגרציה עם מערכות פנימיות.
2. סוכני גריפה משולבי AI
- דוגמאות: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- חוזקות: מצמצמים את הפער בין גריפה להבנת נתונים. ממשקי שפה טבעית הופכים אותם לנגישים.
- פשרות: חלקם עדיין מתפתחים; ייתכן שלא יציעו שליטה עדינה מאוד.
- שימושים: תשובות מהירות או סטים של נתונים, בניית סוכנים אוטונומיים, או הזנת נתונים חיים ל-LLMs.
3. סקרפרים ללא-קוד/עם מעט קוד, ידידותיים לעסקים
- דוגמאות: Thunderbit, Browse AI, Octoparse, ParseHub, Webscraper.io, DataMiner
- חוזקות: ידידותיים למשתמש, כמעט בלי צורך בקוד, טובים למשימות עסקיות שוטפות.
- פשרות: עלולים להתקשות באתרים מורכבים מאוד או בסקייל ענק.
- שימושים: יצירת לידים, ניטור מתחרים, פרויקטי מחקר ושליפות נתונים חד-פעמיות.
4. פלטפורמות ושירותי נתונים ארגוניים
- דוגמאות: Bright Data, Diffbot, Zyte
- חוזקות: פתרונות מקצה לקצה, שירותים מנוהלים, תאימות ואמינות בקנה מידה.
- פשרות: עלות גבוהה יותר, נדרש יותר תהליך הטמעה.
- שימושים: צינורות נתונים רציפים בקנה מידה גדול, מודיעין שוק ונתוני אימון ל-AI.
איך לבחור את סורק ה-AI המתאים לצורכי גריפת דפי אינטרנט שלך
מהי גריפת נתונים ואיך עושים אותה Get Started Free
בחירת הכלי הנכון יכולה להרגיש מבלבלת, אז הנה המדריך שלי, שלב אחר שלב:
- הגדירו את המטרות ודרישות הנתונים: אילו אתרים ונתונים אתם צריכים? באיזו תדירות? כמה? מה תעשו איתם?
- העריכו את היכולת הטכנית שלכם: אין קוד? נסו את Thunderbit, Browse AI או Octoparse. יש קצת סקריפטים? LLM Scraper או DataMiner. יש לכם כישורי פיתוח חזקים? Crawl4AI, Apify או Zyte.
- קחו בחשבון תדירות וקנה מידה: חד-פעמי? השתמשו בכלים חינמיים. חוזר? חפשו יכולות תזמון. בקנה מידה גדול? כלים ארגוניים או קוד פתוח בקנה מידה.
- תקציב ומודל תמחור: תוכניות חינמיות מעולות לבדיקה. בחירה בין מנוי לתשלום לפי שימוש תלויה בצרכים שלכם.
- ניסיון והוכחת היתכנות: בדקו כמה כלים על הנתונים האמיתיים שלכם. לרובם יש מסלולים חינמיים.
- תחזוקה ותמיכה: מי יתקן אם האתר ישתנה? כלים ללא-קוד עם AI עשויים לתקן אוטומטית שינויים קטנים; בקוד פתוח זה תלוי בכם או בקהילה.
- מיפוי כלים לתרחישים: צוות מכירות שגורף לידים? Thunderbit או Browse AI. חוקר שאוסף ציוצים? DataMiner או Webscraper.io. מודל AI שצריך כתבות חדשות? Jina Reader או Zyte. בונים אתר השוואות? Apify או Zyte.
- תכננו גיבוי: לפעמים כלי אחד לא יעבוד עבור אתר מסוים. כדאי שתהיה חלופה.
הכלי “הנכון” הוא זה שמביא לכם את הנתונים שאתם צריכים עם הכי מעט חיכוך ובתוך התקציב שלכם. לפעמים, זו דווקא שילוב של כמה כלים.
Thunderbit לעומת כלי Web Scraper מסורתיים: מה מייחד אותו?
בואו ניכנס לפרטים על מה שהופך את Thunderbit לשונה:
- ממשק שפה טבעית: בלי קוד, בלי אקרובטיקה של הצבע-הקלק. פשוט מתארים מה רוצים (מקור).
- אפס קונפיגורציה והצעות לתבניות: Thunderbit מזהה אוטומטית עימוד, תתי-דפים, ואפילו מציע תבניות לאתרים נפוצים (מקור).
- ניקוי והעשרה של נתונים בעזרת AI: מסכם, מסווג, מתרגם ומעשיר נתונים תוך כדי הגריפה (מקור).
- פחות כאבי תחזוקה: ה-AI של Thunderbit עמיד לשינויים קטנים באתר, ולכן יש פחות שבירות.
- אינטגרציה עם כלי עבודה עסקיים: ייצוא ישיר ל-Google Sheets, Airtable, Notion — בלי עוד התעסקות ב-CSV (מקור).
- מהירות עד ערך: מרעיון לנתונים בתוך דקות, לא ימים.
- עקומת למידה: אם אתה יודע לגלוש באינטרנט ולתאר מה אתה צריך, אתה יכול להשתמש ב-Thunderbit.
- גמישות: גריפת אתרים, PDFים, תמונות ועוד — הכול עם אותו כלי.
Thunderbit הוא לא רק סקרפר — הוא עוזר נתונים שנכנס לתוך תהליך העבודה שלך, בין אם אתה במכירות, שיווק, ecommerce או נדל”ן.
נסו את Thunderbit AI Web Scraper
שיטות עבודה מומלצות לגריפת דפי אינטרנט עם כלי AI Web Scraper
כדי להפיק את המרב מסקרפרים מבוססי AI, הנה הטיפים המובילים שלי:
- הגדירו בבירור את צרכי הנתונים שלכם: דעו אילו שדות אתם רוצים, כמה דפים, ובאיזה פורמט אתם צריכים את הפלט.
- נצלו את ההצעות של ה-AI: השתמשו בזיהוי השדות ובהצעות ה-AI של הכלים כדי לא לפספס נתונים חשובים (מקור).
- התחילו קטן ואשרו: בדקו על דגימה קטנה, עברו על הפלט, והתאימו לפי הצורך.
- טפלו בתוכן דינמי: ודאו שהכלי שלכם תומך בתוכן דינמי ובאינטראקציות (עמודיות, גלילה אינסופית וכו').
- כבדו את מדיניות האתר: בדקו robots.txt, הימנעו מגריפת נתונים רגישים, וכבדו מגבלות קצב.
- שלבו לאוטומציה: השתמשו ביכולות ייצוא ו-webhooks כדי לחבר את הנתונים שנגרפו ישירות לזרימת העבודה שלכם.
- שמרו על איכות הנתונים: בצעו בדיקת היגיון, השתמשו בעיבוד לאחר מכן, ועקבו אחרי שגיאות.
- היו תמציתיים בפרומפטים: כשמשתמשים בכלים מונעי AI, הוראות ברורות וספציפיות נותנות תוצאות טובות יותר.
- למדו מהקהילה: הצטרפו לפורומים ולקהילות לקבלת טיפים ופתרון בעיות.
- הישארו מעודכנים: כלים מבוססי AI מתפתחים מהר — עקבו אחרי פיצ'רים ושיפורים חדשים.
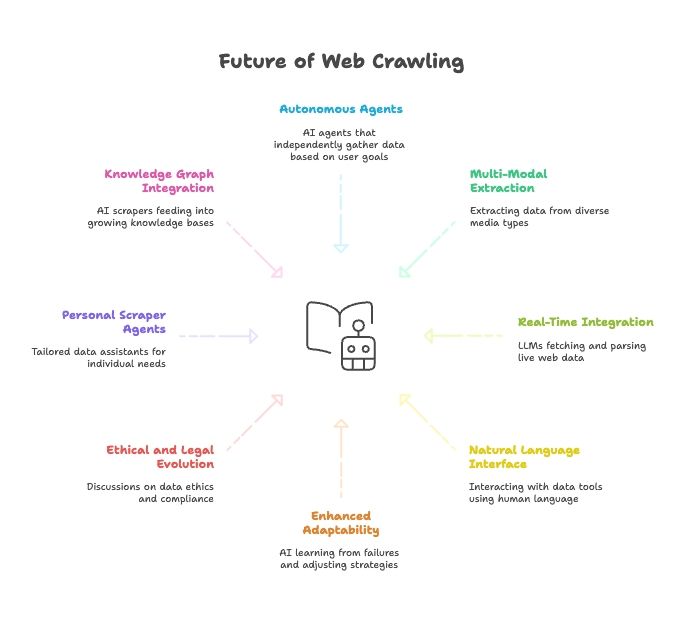
העתיד של גריפת אתרים: AI, LLMs ועלייתם של סוכני Web Scraper בשפה טבעית
אם מסתכלים קדימה, המפגש בין AI לגריפת אתרים רק מואץ:
- סוכני גריפה אוטונומיים לחלוטין: בקרוב, פשוט תספרו לסוכן AI מה היעד הסופי שלכם, והוא כבר ימציא איך להשיג את הנתונים.
- חילוץ נתונים רב-מודלי: סקרפרים יחילו נתונים מטקסט, תמונות, PDFים ואפילו סרטונים.
- אינטגרציה בזמן אמת עם מודלי AI: ל-LLMs יהיו מודולים מובנים לשליפה וניתוח של נתוני רשת חיים.
- שפה טבעית בכל דבר: נדבר עם כלי הנתונים שלנו כמו שאנחנו מדברים עם בני אדם, וכך איסוף והמרת נתונים יהפכו לנגישים לכולם.
- יכולת הסתגלות משופרת: סקרפרים מבוססי AI ילמדו מכישלונות ויתאימו אסטרטגיות אוטומטית.
- התפתחות אתית ומשפטית: צפוי יותר דיון סביב אתיקה של נתונים, תאימות ושימוש הוגן.
- סוכני גריפה אישיים: דמיינו עוזר נתונים אישי שאוסף חדשות, משרות ועוד, מותאם לצרכים שלכם.
- אינטגרציה עם גרפי ידע: סקרפרים מבוססי AI יזינו ללא הפסקה מאגרי ידע שהולכים וגדלים, ויעצימו AI חכם יותר.
השורה התחתונה? עתיד גריפת האתרים שזור בעתיד ה-AI. הכלים נעשים חכמים יותר, אוטונומיים יותר ונגישים יותר בכל יום.
סיכום: פתיחת ערך עסקי עם סורק ה-AI הנכון
גריפת אתרים עברה ממיומנות נישתית וטכנית ליכולת עסקית מרכזית — בזכות AI. 15 הכלים שסקרתי כאן מייצגים את הטוב ביותר שאפשר ב-2026, ממנועי-על למפתחים ועד עוזרים ידידותיים לעסקים.
הסוד האמיתי? בחירת הכלי הנכון יכולה להגדיל משמעותית את הערך שאתם מקבלים מנתוני רשת. עבור צוותים לא-טכניים, Thunderbit הוא הדרך הקלה ביותר להפוך את האינטרנט למסד נתונים מובנה ומוכן לניתוח — בלי קוד, בלי כאב ראש, רק תוצאות.
אז בין אם אתם אוספים לידים, מנטרים מתחרים, או מזינים את מודל ה-AI מהדור הבא שלכם, קחו זמן להעריך את הצרכים שלכם, נסו כמה כלים, ותראו מה עובד לכם. ואם אתם רוצים לחוות היום את העתיד של גריפת אתרים, נסו את Thunderbit. התובנות שאתם צריכים נמצאות במרחק פרומפט אחד בלבד.
סקרנים לעוד? בדקו את בלוג Thunderbit למדריכים מעמיקים, טיוטוריאלים, והחידושים האחרונים בתחום חילוץ הנתונים באמצעות AI.
קריאה נוספת:
- מהי גריפת נתונים ואיך עושים אותה ב-2026
- איך לגרוף נתוני אתר ל-Excel באמצעות AI
- כלי ותוכנות ה-Web Scraping הטובים ביותר ב-2026
נסו AI Web Scraper Get Started Free
שאלות נפוצות
1. מהו סורק רשת מבוסס AI ואיך הוא שונה מסקרפרים מסורתיים?
סורק רשת מבוסס AI משתמש בעיבוד שפה טבעית ולמידת מכונה כדי להבין, לחלץ ולבנות נתוני רשת בצורה מובנית. בניגוד לסקרפרים מסורתיים שדורשים כתיבת קוד ידנית וסלקטורים של XPath, כלי AI יכולים לטפל בתוכן דינמי, להסתגל לשינויים בפריסה, ולפרש הוראות משתמש באנגלית פשוטה.
2. מי צריך להשתמש בכלי גריפת אתרים מבוססי AI כמו Thunderbit?
Thunderbit בנוי גם למשתמשים לא-טכניים וגם לטכניים. הוא אידיאלי לאנשי מכירות, שיווק, תפעול, מחקר ו-ecommerce שרוצים לחלץ נתונים מובנים מאתרים, PDFים או תמונות — בלי לכתוב קוד.
3. אילו תכונות גורמות ל-Thunderbit לבלוט מול סורקי AI אחרים?
Thunderbit מציע ממשק בשפה טבעית, סריקה רב-רמתית, בניית מבנה נתונים אוטומטית, תמיכה ב-OCR, וייצוא חלק לפלטפורמות כמו Google Sheets ו-Airtable. יש בו גם הצעות שדות מונעות AI ותבניות מוכנות מראש לאתרים פופולריים.
4. האם יש אפשרויות חינמיות לגריפת אתרים ב-AI ב-2026?
כן. כלים רבים כמו Thunderbit, Browse AI ו-DataMiner מציעים תוכניות חינמיות עם שימוש מוגבל. למפתחים, אפשרויות קוד פתוח כמו Crawl4AI ו-ScrapeGraphAI מספקות פונקציונליות מלאה ללא עלות, אם כי הן דורשות הגדרה טכנית.
5. איך לבחור את סורק ה-AI המתאים לצרכים שלי?
התחילו בזיהוי מטרות הנתונים, היכולת הטכנית, התקציב ודרישות הסקייל שלכם. אם אתם רוצים פתרון ללא-קוד וקל לשימוש, Thunderbit או Browse AI הן בחירות מצוינות. לצרכים בקנה מידה גדול או מותאמים אישית, כלים כמו Apify או Bright Data מתאימים יותר.




