בואו נהיה כנים — Amazon היא בעצם הקניון, הסופרמרקט וחנויות האלקטרוניקה של כל האינטרנט. אם אתם עובדים במכירות, ב-e-commerce או בתפעול, אתם כבר יודעים שמה שקורה ב-Amazon לא נשאר ב-Amazon — זה משפיע על התמחור, על המלאי ואפילו על השקת המוצר הגדולה הבאה שלכם. אבל הנה הבעיה: כל פרטי המוצר המפתים, המחירים, הדירוגים והביקורות נעולים מאחורי ממשק אינטרנט שנבנה לקונים, לא לצוותים רעבי נתונים. אז איך משיגים את הנתונים האלה בלי לבזבז את הסופ״שים על העתק-הדבק כאילו אנחנו ב-1999?
כאן נכנסת לתמונה גריפת אתרים. במדריך הזה אראה לכם שתי דרכים לחלץ נתוני מוצרים מ-Amazon: הגישה הקלאסית של “להפשיל שרוולים ולכתוב את זה ב-Python”, והמסלול המודרני של “לתת ל-AI לעשות את העבודה הקשה” בעזרת כלי גריפת אתרים ללא קוד כמו . אעבור איתכם על קוד Python אמיתי (כולל כל הבעיות והפתרונות העוקפים), ואז אראה איך Thunderbit יכול להביא לכם את אותם נתונים בכמה לחיצות בלבד — בלי לכתוב קוד בכלל. בין אם אתם מפתחים, אנליסטים עסקיים או סתם אנשים שנמאס להם מהזנת נתונים ידנית, יש פה משהו בשבילכם.
למה לחלץ נתוני מוצרים מ-Amazon? (amazon scraper python, web scraping with python)
Amazon היא לא רק הקמעונאית המקוונת הגדולה בעולם — היא גם השוק הפתוח הגדול בעולם למודיעין תחרותי. עם וכמעט , Amazon היא מכרה זהב לכל מי שרוצה:

- לעקוב אחרי מחירים (ולעדכן את שלכם בזמן אמת)
- לנתח מתחרים (לעקוב אחרי השקות חדשות, דירוגים וביקורות)
- ליצור לידים (לאתר מוכרים, ספקים או אפילו שותפים פוטנציאליים)
- לחזות ביקושים (על בסיס רמות מלאי ודירוגי מכירות)
- לזהות מגמות שוק (באמצעות כריית ביקורות ותוצאות חיפוש)
וזה לא רק תיאוריה — עסקים אמיתיים רואים ROI אמיתי. למשל, קמעונאי אלקטרוניקה אחד השתמש בנתוני תמחור שנגרפו מ-Amazon כדי , בעוד מותג אחר ראה אחרי שהפך את מעקב המחירים של המתחרים לאוטומטי.
הנה טבלה קצרה של מקרי שימוש וה-ROI שאפשר לצפות לו:
| מקרה שימוש | מי משתמש בזה | ROI / תועלת טיפוסית |
|---|---|---|
| מעקב מחירים | e-commerce, תפעול | שיפור של 15%+ בשולי הרווח, עלייה של 4% במכירות, 30% פחות זמן אנליסט |
| ניתוח מתחרים | מכירות, מוצר, תפעול | התאמות מחיר מהירות יותר, תחרותיות משופרת |
| מחקר שוק (ביקורות) | מוצר, שיווק | שיפור מהיר יותר של המוצר, קופי טוב יותר למודעות, תובנות SEO |
| יצירת לידים | מכירות | 3,000+ לידים/חודש, חיסכון של 8+ שעות לנציג בשבוע |
| מלאי וחיזוי ביקושים | תפעול, שרשרת אספקה | הפחתה של 20% בעודפי מלאי, פחות חוסרים |
| זיהוי מגמות | שיווק, הנהלה | איתור מוקדם של מוצרים וקטגוריות חמים |
והנה הפאנץ׳: מדווחים כיום על ערך מדיד מניתוח נתונים. אם אתם לא גורפים נתונים מ-Amazon, אתם משאירים תובנות — וכסף — על השולחן.
סקירה כללית: Amazon Scraper Python מול כלים לגריפת אתרים ללא קוד
יש שתי דרכים עיקריות להוציא נתונים מ-Amazon מהדפדפן ולהכניס אותם לגיליונות האלקטרוניים או לדשבורדים שלכם:
-
Amazon Scraper Python (web scraping with python):
כתיבת סקריפט משלכם באמצעות ספריות Python כמו Requests ו-BeautifulSoup. זה נותן לכם שליטה מלאה, אבל תצטרכו לדעת לתכנת, להתמודד עם מנגנוני נגד-בוט ולתחזק את הסקריפט כשהאתר של Amazon משתנה.
-
כלי גריפת אתרים ללא קוד (כמו Thunderbit):
שימוש בכלי שמאפשר לכם להצביע, ללחוץ ולחלץ נתונים — בלי צורך בתכנות. כלים מודרניים כמו אפילו משתמשים ב-AI כדי להבין אילו נתונים לחלץ, להתמודד עם דפי משנה ודפי מספר, ולייצא ישירות ל-Excel או ל-Google Sheets.
כך הם עומדים זה מול זה:
| קריטריון | סקרייפר ב-Python | ללא קוד (Thunderbit) |
|---|---|---|
| זמן הקמה | גבוה (התקנה, קוד, דיבוג) | נמוך (התקנת תוסף) |
| מיומנות נדרשת | נדרש תכנות | אין (הצבעה ולחיצה) |
| גמישות | בלתי מוגבלת | גבוהה עבור מקרי שימוש נפוצים |
| תחזוקה | אתם מתקנים את הקוד | הכלי מתעדכן מעצמו |
| התמודדות עם נגד-בוט | אתם מטפלים בפרוקסי ובכותרות | מובנה, מטופל בשבילכם |
| סקלאביליות | ידני (threads, פרוקסי) | גריפה בענן, מקבילית |
| ייצוא נתונים | מותאם אישית (CSV, Excel, DB) | בלחיצה אחת ל-Excel, Sheets |
| עלות | חינם (הזמן שלכם + פרוקסי) | Freemium, תשלום לפי היקף |
| מתאים במיוחד ל | מפתחים, צרכים מותאמים אישית | משתמשים עסקיים, תוצאות מהירות |
בקטעים הבאים אעבור איתכם על שתי הגישות — קודם איך לבנות Amazon scraper ב-Python (עם קוד אמיתי), ואז איך לעשות את אותו הדבר עם ה-AI web scraper של Thunderbit.
תחילת עבודה עם Amazon Scraper Python: דרישות מוקדמות והגדרה
לפני שנצלול לקוד, בואו נגדיר את הסביבה.
תצטרכו:
- Python 3.x (להורדה מ-)
- עורך קוד (אני אוהב VS Code, אבל כל עורך יעבוד)
- את הספריות הבאות:
requests(לבקשות HTTP)beautifulsoup4(לניתוח HTML)lxml(מנתח HTML מהיר)pandas(לטבלאות נתונים/ייצוא)re(ביטויים רגולריים, מובנה)
התקנת הספריות:
1pip install requests beautifulsoup4 lxml pandasהגדרת הפרויקט:
- צרו תיקייה חדשה לפרויקט.
- פתחו את העורך, צרו קובץ Python חדש (למשל,
amazon_scraper.py). - אתם מוכנים להתחיל!
צעד-אחר-צעד: גריפת אתרים ב-Python עבור נתוני מוצרים מ-Amazon
בואו נעבור על גריפה של עמוד מוצר אחד ב-Amazon. (אל דאגה, נגיע גם לגריפה של כמה מוצרים ועמודים בעוד רגע.)
1. שליחת בקשות ושליפת HTML
קודם כול, נביא את ה-HTML של עמוד מוצר. (החליפו את ה-URL בכל מוצר Amazon שתרצו.)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)שימו לב: סביר ש-Amazon תחסום בקשה בסיסית כזו. ייתכן שתראו שגיאת 503 או CAPTCHA במקום עמוד המוצר. למה? כי Amazon יודעת שאתם לא דפדפן אמיתי.
התמודדות עם מנגנוני נגד-בוט של Amazon
Amazon לא ממש אוהבת בוטים. כדי להימנע מחסימה, תצטרכו:
- להגדיר כותרת User-Agent (להעמיד פנים שאתם Chrome או Firefox)
- לסובב User-Agents (לא להשתמש באותו אחד בכל פעם)
- להאט את קצב הבקשות (להוסיף השהיות אקראיות)
- להשתמש בפרוקסי (לגריפה בהיקף גדול)
כך מגדירים כותרות:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)רוצים ללכת צעד קדימה? השתמשו ברשימת User-Agents ותקנו אותה לכל בקשה. למשימות גדולות, תרצו להשתמש בשירות פרוקסי (יש לא מעט כאלה), אבל לגריפה בהיקף קטן כותרות והשהיות בדרך כלל מספיקות.
חילוץ שדות המוצר המרכזיים
אחרי שיש לכם HTML, הגיע הזמן לנתח אותו עם BeautifulSoup.
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")עכשיו נחלץ את הדברים החשובים:
כותרת המוצר
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else Noneמחיר
המחיר של Amazon יכול להופיע בכמה מקומות. נסו את אלה:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.textדירוג ומספר ביקורות
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # למשל, "1,554 ratings"כתובת תמונת המוצר הראשית
לפעמים Amazon מסתירה תמונות ברזולוציה גבוהה בתוך JSON ב-HTML. הנה דרך קצרה עם regex:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else Noneאו פשוט לתפוס את תגית התמונה הראשית:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else Noneפרטי המוצר
מפרטים כמו מותג, משקל ומידות נמצאים בדרך כלל בטבלה:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = valueאו, אם Amazon משתמשת בפורמט של “detailBullets”:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()הדפיסו את התוצאות:
1print("Title:", product_title)
2print("Price:", price)
3print("Rating:", rating, "based on", reviews_count, "reviews")
4print("Main image URL:", main_image_url)
5print("Details:", details)גריפה של כמה מוצרים וטיפול בדפי מספר
מוצר אחד זה נחמד, אבל כנראה תרצו רשימה שלמה. כך גורפים תוצאות חיפוש וכמה עמודים.
קבלת קישורים למוצרים מעמוד חיפוש
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)טיפול בדפי מספר
כתובות החיפוש של Amazon משתמשות ב-&page=2, &page=3 וכן הלאה.
1for page in range(1, 6): # גריפת 5 העמודים הראשונים
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page=\{page\}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... חילוץ קישורי מוצרים כמו למעלה ...מעבר על עמודי מוצרים וייצוא ל-CSV
אספו את נתוני המוצרים שלכם ברשימת מילונים, ואז השתמשו ב-pandas:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # list of dicts
3df.to_csv("amazon_products.csv", index=False)או ל-Excel:
1df.to_excel("amazon_products.xlsx", index=False)שיטות עבודה מומלצות לפרויקטים של Amazon Scraper Python
בואו נהיה מציאותיים — Amazon משנה כל הזמן את האתר שלה ונלחמת ב-scrapers. כך תשמרו על הפרויקט שלכם חי:
- סובבו כותרות ו-User-Agents (השתמשו בספרייה כמו
fake-useragent) - השתמשו בפרוקסי לגריפה בהיקף גדול
- האטו בקשות (
time.sleep() אקראי בין בקשות) - טפלו בשגיאות בחן (נסו שוב על 503, והאטו אם נחסמתם)
- כתבו לוגיקת ניתוח גמישה (חפשו כמה סלקטורים לכל שדה)
- עקבו אחרי שינויים ב-HTML (אם הסקריפט פתאום מחזיר
Noneלכל דבר, בדקו את העמוד) - כבדו את robots.txt (Amazon אוסרת גריפה של הרבה אזורים — גרפו באחריות)
- נקו את הנתונים תוך כדי (הסירו סימני מטבע, פסיקים, רווחים)
- הישארו מחוברים לקהילה (פורומים, Stack Overflow, Reddit’s r/webscraping)
צ׳ק-ליסט לתחזוקת הסקרייפר שלכם:
- [ ] סובבו User-Agents וכותרות
- [ ] השתמשו בפרוקסי אם גורפים בהיקף גדול
- [ ] הוסיפו השהיות אקראיות
- [ ] חלקו את הקוד למודולים כדי להקל על עדכונים
- [ ] עקבו אחרי חסימות או CAPTCHA-ים
- [ ] ייצאו נתונים באופן קבוע
- [ ] תעדו את הסלקטורים והלוגיקה שלכם
לצלילה עמוקה יותר, בדקו את .
האלטרנטיבה ללא קוד: גריפת Amazon עם Thunderbit AI Web Scraper
אוקיי, אז ראיתם את הדרך עם Python. אבל מה אם אתם לא רוצים לכתוב קוד — או פשוט רוצים לקבל את הנתונים בשתי לחיצות ולהמשיך בחיים? כאן נכנס Thunderbit.
Thunderbit הוא תוסף Chrome של AI web scraper שמאפשר לכם לחלץ נתוני מוצרים מ-Amazon (ונתונים כמעט מכל אתר) בלי לכתוב קוד בכלל. הנה למה אני אוהב אותו:
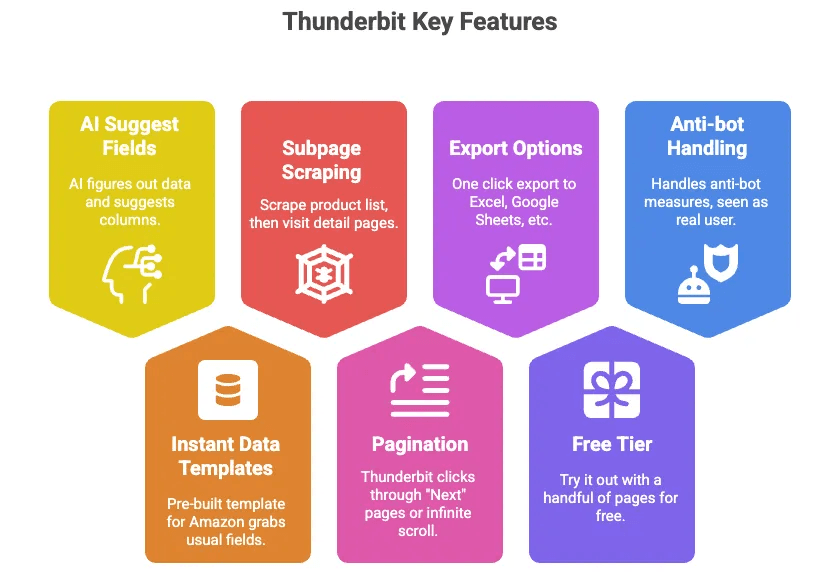
- הצעת שדות באמצעות AI: פשוט לוחצים על כפתור, וה-AI של Thunderbit מבין אילו נתונים נמצאים בעמוד ומציע עמודות (כמו כותרת, מחיר, דירוג וכו׳).
- תבניות נתונים מיידיות: עבור Amazon יש תבנית מוכנה מראש שמושכת את כל השדות הרגילים — בלי הגדרה בכלל.
- גריפת דפי משנה: גורפים רשימת מוצרים, ואז נותנים ל-Thunderbit לבקר בכל עמוד פירוט של מוצר ולמשוך מידע נוסף אוטומטית.
- עמודי מספר: Thunderbit יכול ללחוץ בשבילכם על עמודי “הבא” או על גלילה אינסופית.
- ייצוא ל-Excel, Google Sheets, Airtable, Notion: בלחיצה אחת והנתונים שלכם מוכנים לעבודה.
- שכבה חינמית: אפשר להתנסות בכמה עמודים בחינם.
- מטפל בשבילכם במנגנוני נגד-בוט: מכיוון שהוא רץ בדפדפן שלכם (או בענן), Amazon רואה בו משתמש אמיתי.
צעד-אחר-צעד: שימוש ב-Thunderbit לגריפת נתוני מוצרים מ-Amazon
כך זה עובד, בפשטות:
-
התקינו את Thunderbit:
הורידו את והתחברו.
-
פתחו את Amazon:
עברו לעמוד Amazon שתרצו לגרוף (תוצאות חיפוש, עמוד מוצר, כל דבר).
-
לחצו על “AI Suggest Fields” או השתמשו בתבנית:
Thunderbit יציע עמודות לחילוץ (או שתוכלו לבחור בתבנית Amazon Product).
-
בדקו את העמודות:
התאימו את העמודות אם תרצו (הוספת/הסרת שדות, שינוי שמות וכו׳).
-
לחצו על “Scrape”:
Thunderbit מושך את הנתונים מהעמוד ומציג אותם בטבלה.
-
טיפול בדפי משנה ובעמודי מספר:
אם גרפתם רשימה, לחצו על “Scrape Subpages” כדי לבקר בכל עמוד פירוט של מוצר ולמשוך עוד מידע. Thunderbit יכול גם ללחוץ אוטומטית דרך עמודי “Next”.
-
ייצאו את הנתונים שלכם:
לחצו על “Export to Excel” או “Export to Google Sheets”. סיימתם.
-
(רשות) תזמון גריפה:
צריכים את הנתונים האלה כל יום? השתמשו במתזמן של Thunderbit כדי להפוך את זה לאוטומטי.
וזהו. בלי קוד, בלי דיבוג, בלי פרוקסי, בלי כאבי ראש. להדגמה ויזואלית, בדקו את או את .
Amazon Scraper Python מול גריפת אתרים ללא קוד: השוואה זו לצד זו
בואו נחבר הכול יחד:
| קריטריון | סקרייפר ב-Python | Thunderbit (ללא קוד) |
|---|---|---|
| זמן הקמה | גבוה (התקנה, קוד, דיבוג) | נמוך (התקנת תוסף) |
| מיומנות נדרשת | נדרש תכנות | אין (הצבעה ולחיצה) |
| גמישות | בלתי מוגבלת | גבוהה עבור מקרי שימוש נפוצים |
| תחזוקה | אתם מתקנים את הקוד | הכלי מתעדכן מעצמו |
| התמודדות עם נגד-בוט | אתם מטפלים בפרוקסי ובכותרות | מובנה, מטופל בשבילכם |
| סקלאביליות | ידני (threads, פרוקסי) | גריפה בענן, מקבילית |
| ייצוא נתונים | מותאם אישית (CSV, Excel, DB) | בלחיצה אחת ל-Excel, Sheets |
| עלות | חינם (הזמן שלכם + פרוקסי) | Freemium, תשלום לפי היקף |
| מתאים במיוחד ל | מפתחים, צרכים מותאמים אישית | משתמשים עסקיים, תוצאות מהירות |
אם אתם מפתחים שאוהבים להתעסק ולבנות משהו סופר-מותאם, Python הוא החבר שלכם. אם אתם רוצים מהירות, פשטות ובלי לכתוב קוד, Thunderbit הוא הדרך הנכונה.
מתי לבחור ב-Python, ללא קוד או ב-AI web scraper עבור נתוני Amazon
בחרו ב-Python אם:
- אתם צריכים לוגיקה מותאמת אישית או רוצים לשלב גריפה במערכות ה-backend שלכם
- אתם גורפים בהיקף עצום (עשרות אלפי מוצרים)
- אתם רוצים ללמוד איך גריפה עובדת מתחת למכסה המנוע
בחרו ב-Thunderbit (ללא קוד, AI web scraper) אם:
- אתם רוצים נתונים מהר, בלי לכתוב קוד
- אתם משתמשים עסקיים, אנליסטים או משווקים
- אתם צריכים לאפשר לצוות שלכם להשיג נתונים בעצמם
- אתם רוצים להימנע מההתעסקות עם פרוקסי, מנגנוני נגד-בוט ותחזוקה
השתמשו בשניהם אם:
- אתם רוצים להקים אבטיפוס מהר עם Thunderbit, ואז לבנות פתרון Python מותאם לייצור
- אתם רוצים להשתמש ב-Thunderbit לאיסוף נתונים וב-Python לניקוי וניתוח הנתונים
עבור רוב המשתמשים העסקיים, Thunderbit יכסה 90% מצורכי גריפת Amazon שלכם בזמן קצר בהרבה. עבור 10% הנותרים — הדברים הסופר-מותאמים, ההיקף הגדול או האינטגרציה העמוקה — Python עדיין שולט.
סיכום ותובנות מרכזיות
גריפת נתוני מוצרים מ-Amazon היא כוח-על לכל צוות מכירות, e-commerce או תפעול. בין אם אתם עוקבים אחרי מחירים, מנתחים מתחרים או פשוט מנסים להציל את הצוות שלכם מהעתקה-הדבקה אינסופית, יש לכם פתרון.
- גריפה ב-Python נותנת לכם שליטה מלאה, אבל מגיעה עם עקומת למידה ותחזוקה שוטפת.
- כלי גריפת אתרים ללא קוד כמו Thunderbit הופכים את חילוץ הנתונים מ-Amazon לנגיש לכולם — בלי קוד, בלי כאבי ראש, רק תוצאות.
- הגישה הטובה ביותר? השתמשו בכלי שמתאים למיומנויות שלכם, ללוח הזמנים שלכם ולמטרות העסקיות שלכם.
אם זה מסקרן אתכם, נסו את Thunderbit — ההתחלה בחינם, ותתפלאו כמה מהר אפשר להשיג את הנתונים שאתם צריכים. ואם אתם מפתחים, אל תפחדו לשלב: לפעמים הדרך המהירה ביותר לבנות היא לתת ל-AI לעשות עבורכם את החלקים המשעממים.
שאלות נפוצות
1. למה עסק ירצה לגרוף נתוני מוצרים מ-Amazon?
גריפת Amazon מאפשרת לעסקים לעקוב אחר מחירים, לנתח מתחרים, לאסוף ביקורות למחקר מוצר, לחזות ביקושים וליצור לידים למכירות. עם יותר מ-600 מיליון מוצרים וכמעט 2 מיליון מוכרים ב-Amazon, זהו מקור עשיר למודיעין תחרותי.
2. מה ההבדלים העיקריים בין שימוש ב-Python לבין כלים ללא קוד כמו Thunderbit לגריפת Amazon?
סקרייפרים ב-Python מציעים גמישות מקסימלית, אבל דורשים מיומנויות תכנות, זמן הקמה ותחזוקה שוטפת. Thunderbit, AI web scraper ללא קוד, מאפשר למשתמשים לחלץ נתוני Amazon מיידית דרך תוסף Chrome — בלי צורך בקוד, עם טיפול מובנה בנגד-בוט ואפשרויות ייצוא ל-Excel או Sheets.
3. האם חוקי לגרוף נתונים מ-Amazon?
תנאי השימוש של Amazon בדרך כלל אוסרים על גריפה, והם מיישמים באופן פעיל מנגנוני נגד-בוט. עם זאת, עסקים רבים עדיין גורפים נתונים ציבוריים תוך הקפדה על פעולה אחראית, כמו שמירה על מגבלות קצב והימנעות מבקשות מופרזות.
4. איזה סוג של נתונים אפשר לחלץ מ-Amazon בעזרת כלי גריפת אתרים?
שדות נפוצים כוללים כותרות מוצרים, מחירים, דירוגים, מספרי ביקורות, תמונות, מפרטי מוצר, זמינות ואפילו מידע על מוכרים. Thunderbit תומך גם בגריפת דפי משנה ובעמודי מספר כדי ללכוד נתונים על פני כמה רשימות ועמודים.
5. מתי כדאי לבחור בגריפה ב-Python במקום בכלי כמו Thunderbit, או להפך?
בחרו ב-Python אם אתם צריכים שליטה מלאה, לוגיקה מותאמת אישית או מתכננים לשלב את הגריפה במערכות backend. בחרו ב-Thunderbit אם אתם רוצים תוצאות מהירות בלי קוד, צריכים סקיילינג קל, או שאתם משתמשים עסקיים שמחפשים פתרון עם תחזוקה נמוכה.
רוצים להעמיק? בדקו את המשאבים הבאים:
גריפה נעימה — ושגיליונות האלקטרוניים שלכם תמיד יהיו מעודכנים.