
Kerronpa sinulle: jos saisin dollarin joka kerta, kun joku lähettää minulle PDF:n, joka on täynnä “tärkeitä tietoja” ja odottaa minun muuttavan sen taikaiskusta taulukkolaskentaan, minulla olisi luultavasti varaa ostaa elinikäinen kahvivarasto (ja ehkä muutama Chrome-laajennus ylimääräistä). PDF-tiedostoja on kaikkialla — myyntisopimuksissa, tuotekatalogeissa, tutkimuspapereissa, laskuissa, mitä vain. Mutta kun niitä tiedostoja pitäisi oikeasti käyttää? Silloin hauskuus alkaa — eli suomeksi: päänsärky.
Olen ollut siellä, missä tiedostoja kopioidaan, liitetään, muotoillaan uudelleen ja välillä luovutetaan suoraan, kun asettelu hajoaa tai kuvat ja linkit katoavat tyhjiin. Mutta tässä on hyviä uutisia: PDF-scrapingin maailma on muuttunut valtavasti, etenkin tekoälypohjaisten työkalujen myötä. Jos kyllästyt siihen, että syötät numeroita uudelleen tuntikausia tai raivostut rikkinäisten taulukoiden takia, olet oikeassa paikassa. Sukelletaan PDF-scrapingin maailmaan, katsotaan miksi sillä on väliä ja miten työkalut kuten Thunderbit tekevät siitä vihdoin kivutonta.
Mikä on PDF-scraping? PDF-datan poiminnan perusteet
Aloitetaan yksinkertaisesti: PDF-scraping tarkoittaa vain hienommalta kuulostavaa tapaa sanoa “rakenteisen datan poimiminen PDF-tiedostoista automaattisesti”. PDF-scraper on työkalu (ohjelmisto, laajennus tai palvelu), joka poimii sinulle tärkeät asiat — tekstin, taulukot, kuvat, linkit, mitä vain — ja muuntaa ne muotoon, jota voit oikeasti käyttää, kuten Exceliin, Google Sheetsiin tai tietokantaan.
Mutta tässä on juju: PDF:t eivät ole kuin verkkosivut tai Excel-tiedostot. Ne muistuttavat enemmän digitaalisia tulosteita, jotka on suunniteltu näyttämään samalta kaikkialla, ei tietokoneen helposti pilkottaviksi. Joissakin PDF:issä teksti on valittavissa, toiset ovat pelkkiä skannattuja kuvia (jotka vaativat OCR:n eli optisen merkintunnistuksen), ja muotoilu voi vaihdella villisti. Siksi PDF:n scraping ei ole vain tekstin kopioimista — se on asettelujen, fonttien ja joskus jopa piilotetun metadatan palapelin purkamista.
Mitä PDF:stä voi poimia?
- Pelkkä teksti (kappaleet, otsikot jne.)
- Taulukot (esim. taloustiedot, tuotetiedot, kyselyaineistot)
- Kuvat ja grafiikat (kaaviot, logot, skannatut allekirjoitukset)
- Hyperlinkit ja viitteet (upotetut URL-osoitteet, sitaatit)
- Lomaketiedot (täytettävien lomakkeiden kentät)
- Metadata (tekijä, otsikko, luontipäivämäärä, tunnisteet)
Ja kyllä, joskus kaikki nämä ovat yhdessä ja samassa loistavan kaoottisessa dokumentissa.
Miksi PDF-scraping on tärkeää: käytännön käyttötapaukset ja liiketoimintahyödyt
Miksi PDF:ien scraping vaivautuisi? Koska kaikki käyttävät niitä, ja niissä oleva data on usein liiketoiminnan kannalta kriittistä. Tässä PDF-scraping pääsee oikeuksiinsa:
| Käyttötapaus | Manuaalinen työ | PDF-scraperilla | Ajan ja virheiden säästö |
|---|---|---|---|
| Myyntiliidien poiminta | Tuntikausia yhteystietojen kopioimista tarjouksista tai tapahtumien PDF:eistä, liidien hukkaamisen riski | Nostaa kaikki liidit suoraan taulukkoon | 80–90 % nopeampi, vähemmän virheitä |
| Verkkokaupan tuotedata | Päiviä tuotteiden tietojen syöttämistä toimittajien PDF:eistä, muotoilupainajaisia | Massapoiminta CSV:hen tai Sheetsiin | Yli 95 % ajansäästö, yhtenäinen data |
| Tutkimusdatan analyysi | Viikkoja taulukoiden puhtaaksikirjoittamista tieteellisistä artikkeleista, suuri kirjoitusvirheiden riski | Poimii taulukot, viitteet ja jopa skannatun tekstin | 80 % ajansäästö, parempi tarkkuus |
Lasketaanpa vähän numeroita:
- 2,5 biljoonaa PDF-tiedostoa luodaan joka vuosi.
- 90 % organisaatioista käyttää PDF:ää ensisijaisena muotona tiedon jakamiseen.
- Manuaalinen digitaalinen hallinnollinen työ, kuten PDF-datan syöttö, vie 40 % työajasta.
- Automaattiset työkalut voivat pudottaa virheprosentin 5–10 %:sta 1 %:iin.
Jos työskentelet myynnissä, verkkokaupassa tai tutkimuksessa, PDF-datan poiminnan automatisointi ei ole vain kiva lisä — se on kilpailuetu.
Perinteiset PDF-scraping-menetelmät: haasteet ja rajoitukset
Rehellisesti sanottuna vanhat tavat saada dataa ulos PDF:istä eivät ole… kovin hyviä. Tässä on se, mitä useimmat meistä ovat kokeilleet (ja miksi se on niin turhauttavaa):

1. Manuaalinen kopiointi ja liittäminen
- Kipupisteet: Muotoilu menee rikki, taulukoista tulee sekamelskaa, kuvat ja linkit katoavat, ja sinulle jää päänsärky.
- Työvoimakustannus: Korkea. Jos sinulla on 5 000 PDF:ää ja jokaiseen menee minuutti, se on yli 80 tuntia elämästäsi, joita et saa takaisin.
- Virheaste: 5–10 %. Kirjoitusvirheitä, ohitettuja rivejä, vahingossa poistettuja tietoja — tuttu juttu.
2. Muunna Word/Excel-muotoon ja siivoa sitten
- Kipupisteet: Toimii joskus yksinkertaisille dokumenteille, mutta monimutkaiset asettelut tai taulukot menevät sekaisin. Sitten joudut vielä siivoamaan sotkun.
- Kuvat/linkit: Katoavat yleensä matkalla.
- Tarkkarajainen poiminta: Unohda se — saat koko dokumentin, et vain sitä mitä tarvitset.
3. Omat skriptit (Python jne.)
- Kipupisteet: Sinun pitää osata koodata (tai ainakin tuntea joku, joka osaa). Jokainen uusi PDF-muoto tarkoittaa skriptin säätämistä. Skannatut PDF:t? Onnea matkaan.
- Ylläpito: Korkea. Joka kerta kun toimittaja muuttaa laskupohjaansa, skripti hajoaa.
- Skaalautuvuus: Ei heikkohermoisille — eikä varsinkaan ei-teknisille käyttäjille.
4. Verkkopohjaiset muuntimet
- Kipupisteet: Helppo kertaluontoisiin hommiin, mutta sinun pitää ladata arkaluontoiset dokumentit kolmannen osapuolen palvelimelle (hei, compliance-ongelmat). Rajallinen kontrolli siihen, mitä poimitaan.
- Muotoilu: Vaihtelee. Saatat käyttää enemmän aikaa siivoamiseen kuin mitä säästit.
Yhteenveto: Perinteiset menetelmät ovat hitaita, virhealttiita eivätkä skaalaudu. Siksi niin monet tiimit vain “elävät asian kanssa” — mutta valtavalla tuottavuuden hinnalla.
Nykyaikaiset ratkaisut PDF-scrapingiin: koodista no-code-työkaluihin
Onneksi emme ole enää jumissa pimeällä keskiajalla. Tarjolla on nykyään älykkäämpiä, nopeampia ja käyttäjäystävällisempiä PDF-scraping-vaihtoehtoja.
1. Koodikirjastot (kehittäjille)
- Esimerkkejä: PyPDF2, PDFMiner, Tabula-py.
- Vahvuudet: Erittäin joustava, voidaan automatisoida suuriin eriin, ilmainen (avoin lähdekoodi).
- Heikkoudet: Vaatii paljon käyttöönottoa, ohjelmointitaitoja, on hauras (hajoaa uusien formaattien kanssa), OCR-/kuvatuki on rajallinen.
2. Verkkopohjaiset PDF-muuntimet
- Esimerkkejä: Smallpdf, PDF2Go, Zamzar.
- Vahvuudet: Ei käyttöönottoa, helppo ei-teknisille käyttäjille, nopea pieniin töihin.
- Heikkoudet: Rajallinen muokattavuus, tietosuojaongelmat, muotoiluvirheet, tiedosto- ja sivurajoitukset.
3. Tekoälypohjaiset PDF-scraperit
- Esimerkkejä: Thunderbit, Nanonets, Docparser.
- Vahvuudet: Ei koodausta, käsittelee tekstiä/taulukoita/kuvia/linkkejä, AI ehdottaa mitä poimia, tukee massatehtäviä, integroituu Sheetsiin/Notioniin/Airtableen.
- Heikkoudet: Joissakin on krediitti- tai sivurajoja, saattaa vaatia internet-yhteyden, monimutkaiset dokumentit voivat vaatia hieman opettelua.
PDF-scraping-työkalujen vertailu: mikä lähestymistapa sopii sinulle?
| Työkalu/menetelmä | Käyttöönotto | Paras kohde | Poimii | Mukautettavissa? | Kustannus |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Kohtalainen (UI/koodi) | PDF:ien taulukot | Taulukot | Jossain määrin | Ilmainen |
| PDFMiner | Vaatii koodausta | Tekstipitoiset PDF:t | Teksti | Kyllä (koodi) | Ilmainen |
| PyPDF2 | Vaatii koodausta | Yksinkertainen teksti/metatiedot | Teksti, metadata | Kyllä (koodi) | Ilmainen |
| Smallpdf/verkkopohj. muunt. | Ei mitään (verkkopohjainen) | Nopeat muunnokset | Koko dokumentti (Word/Excel) | Ei | Freemium |
| Thunderbit | 2 klikkauksen asennus | Liiketoimintakäyttäjät, tiimit | Teksti, taulukot, kuvat, linkit | Kyllä (AI-kehotteet) | Freemium (16,5 $/kk Pro-versiossa) |
Tutustu Thunderbitiin: tekoälyllä toimiva PDF-scraper Chrome-laajennus
Kuinka poimia dataa PDF:stä tekoälyn avulla Get Started Free
Nyt puhutaan työkalusta, joka on tehnyt elämästäni — ja monen liiketoimintakäyttäjän elämästä — paljon helpompaa: Thunderbit.
Mikä tekee Thunderbitistä erilaisen?
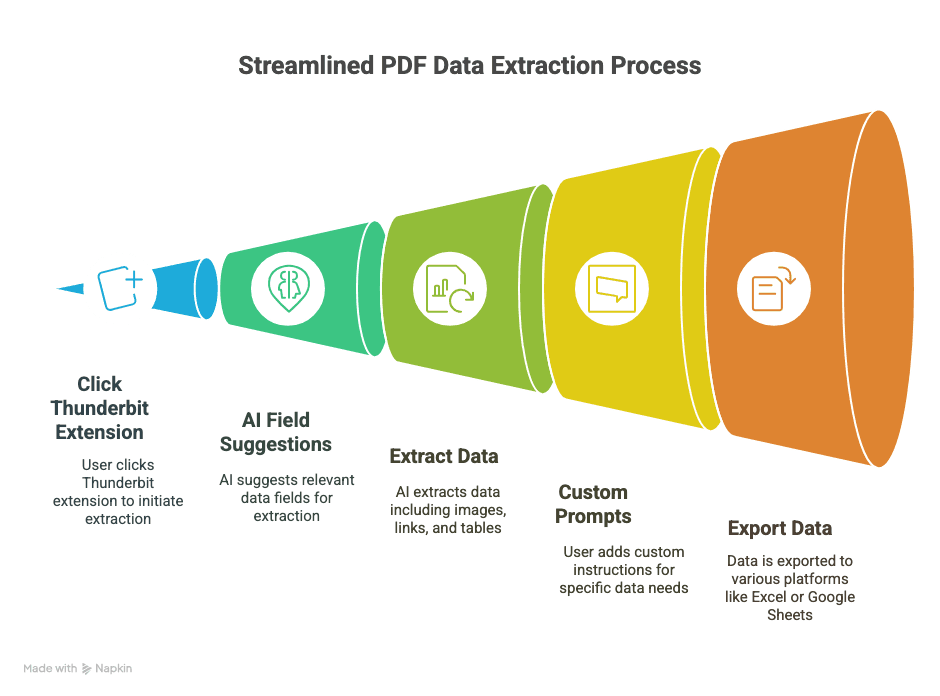
- 2 klikkauksen poiminta: Avaa PDF Chromessa, klikkaa Thunderbit-laajennusta ja anna tekoälyn hoitaa loput.
- AI-pohjaiset kenttäehdotukset: Thunderbitin “AI Suggest Fields” lukee PDF:si ja suosittelee todennäköisesti tarvitsemasi sarakkeet (kuten “Nimi”, “Sähköposti”, “Hinta” jne.).
- Käsittelee kuvat, linkit ja taulukot: Ei vain pelkkää tekstiä — Thunderbit voi poimia kuvia, hyperlinkkejä ja jopa ajaa OCR:n skannatuista dokumenteista.
- Mukautetut kehotteet: Tarvitsetko vain puhelinnumerot tai tuotetiedot? Lisää oma ohje, ja Thunderbit keskittyy juuri siihen.
- Vienti kaikkialle: Lähetä data suoraan Exceliin, Google Sheetsiin, Airtableen tai Notioniin. Ei enää CSV-säätöä.
- Erä- ja alasivujen scraping: Onko sinulla lista PDF:iä tai linkkejä? Thunderbit voi käsitellä ne kaikki yhdellä kertaa.
- Yritystason luotettavuus: Suunniteltu tarkkuutta, yksityisyyttä ja oikeita työprosesseja varten.
Lyhyesti: se on kuin sinulla olisi digitaalinen harjoittelija, joka oikeasti tykkää tehdä tietojen syöttöä (eikä koskaan väsy).
Kuinka poimia dataa PDF:stä Thunderbitillä: vaihe vaiheelta
Lataa Thunderbit Chrome -laajennus Get Started Free
Valmis näkemään, kuinka helppoa se voi olla? Näin minä käytän Thunderbitia muuttaakseni PDF:t jäsennellyksi, käyttökelpoiseksi dataksi:
1. Asenna Thunderbit
- Hae Thunderbit Chrome -laajennus.
- Luo tili (Google-tilillä tai sähköpostilla — vie sekunteja).
2. Avaa PDF Chromessa
- Avaa PDF joko verkkolinkin kautta tai vedä paikallinen PDF Chrome-välilehteen.
3. Käynnistä Thunderbit PDF:ssä
- Klikkaa Thunderbit-kuvaketta selaimen työkalurivillä.
- Valitse “AI Web Scraper” — Thunderbit tunnistaa PDF:n ja valmistautuu työskentelemään.
4. Anna tekoälyn ehdottaa kenttiä
- Klikkaa “AI Suggest Columns”.
- Thunderbitin tekoäly käy PDF:n läpi ja suosittelee sarakkeita (kuten “Päivämäärä”, “Summa”, “Yhteyshenkilön nimi” jne.).
- Esikatsele poimittua dataa taulukossa suoraan laajennuksen sisällä.
5. Mukauta tarvittaessa
- Nimeä sarakkeet uudelleen, poista ylimääräiset tai lisää omia kenttiä (esim. “Takuuaika” tai “Tuotteen URL”).
- Hankalassa datassa voit valita tekstiä PDF:stä ja opettaa tekoälyä sen perusteella, mitä haluat.
6. Valitse vientimuoto
- Valitse CSV, Google Sheets, Airtable tai Notion.
- Anna Thunderbitille lupa yhdistää palveluun (kertaluonteinen käyttöönotto).
7. Poimi ja vie
- Paina “Scrape” tai “Export”.
- Thunderbit käsittelee PDF:n ja lähettää datan sinne, minne haluat — yleensä sekunneissa.
Kokeile Thunderbit PDF-scraperia nyt
Siinä se. Ei koodausta, ei kopioi-liitä-rumbaa, ei draamaa.
Vinkkejä tarkkaan PDF-datan poimintaan Thunderbitillä
- Tarkista tekoälyn ehdottamat kentät: Tekoäly on fiksu, mutta nopea vilkaisu varmistaa, että saat juuri sen mitä tarvitset.
- Käsittele monimutkaiset taulukot: Monisivuisissa tai oudosti muotoilluissa taulukoissa käytä esikatselua virheiden havaitsemiseen ja säädä sarakkeita tarpeen mukaan.
- Poimi kuvat/linkit: Varmista, että sisällytät nämä kentät, jos PDF:ssä on niitä — Thunderbit saa nekin talteen.
- Skannatut PDF:t: Thunderbitin sisäänrakennettu OCR on hyvä, mutta mitä siistimpi skannaus, sitä paremmat tulokset.
- Mukautetut kehotteet: Haluatko vain sähköpostiosoitteet tai puhelinnumerot? Lisää kehote kuten “Poimi kaikki sähköpostiosoitteet”, ja Thunderbit keskittyy niihin.
Edistynyt PDF-scraping: kuvien, linkkien ja mukautetun datan poiminta
Thunderbit ei ole vain pelkkää tekstiä varten. Näin saat PDF:istäsi vielä enemmän irti:
- Kuvat: Poimi logot, kaaviot tai muut upotetut grafiikat. Thunderbit voi jopa tehdä OCR:n kuvien sisällä olevalle tekstille.
- Hyperlinkit: Poimi kaikki URL-osoitteet tai viitteet — erinomainen tutkimuspapereihin tai ansioluetteloihin.
- Mukautetut tietotyypit: Käytä AI-kehotteita poimiaksesi juuri sen mitä tarvitset (esim. “Etsi kaikki tuotteen SKU-tunnukset ja niiden hinnat”).
- Yhteenvedot ja luokittelu: Lisää sarake ja pyydä Thunderbitia tiivistämään osio tai luokittelemaan dataa lennossa.
Datan poiminta PDF:stä tiettyihin liiketoiminnan tarpeisiin
- Myynti: Poimi vain yhteystiedot tarjouspinoista.
- Verkkokauppa: Nouda toimittajakatalogeista tuotetiedot, hinnat ja kuvat.
- Tutkimus: Poimi taulukot, viitteet ja jopa luo yhteenvedot tieteellisistä artikkeleista.
Ja kun data on ulkona, jäsennä se helposti analysoitavaan muotoon Excelissä, Google Sheetsissä tai Notionissa — Thunderbit hoitaa raskaan työn, sinä saat käyttää tuloksia.
PDF-datan vienti ja hyödyntäminen: poiminnasta toimintaan
Datan saaminen ulos on vasta alku. Näin saat siitä oikeasti hyötyä:
- Vientivaihtoehdot: CSV, Excel, Google Sheets, Airtable, Notion — valitse suosikkisi.
- Muotoiluvinkit: Käytä Thunderbitin saraketyyppiasetuksia (numero, päivämäärä, teksti), niin data on siistiä ja analyysivalmista.
- Työnkulkuintegraatio: Yhdistä viety data CRM-järjestelmiin, varastojärjestelmiin tai analytiikkadashboardeihin.
- Yhteistyö: Jaa Google Sheets- tai Airtable-pohjat tiimisi kanssa — kaikki työskentelevät saman, ajan tasalla olevan datan pohjalta.
Parasta? Ei enää taulukkojen lähettelyä sähköpostilla edestakaisin eikä sitä, jäikö jokin rivi huomaamatta.
Yleiset sudenkuopat PDF-scrapingissa ja miten vältät ne
Parhaillakin työkaluilla voi tulla vastaan muutama kompastuskivi. Tässä mitä olen oppinut — joskus kantapään kautta:
- OCR-virheet: Sumeat skannaukset tai oudot fontit voivat hämätä jopa parasta OCR:ää. Pyri käyttämään mahdollisimman siistejä PDF:iä ja tarkista kriittiset kentät kahteen kertaan.
- Monimutkaiset asettelut: Monipalstaiset tai sisäkkäiset taulukot saattavat kaivata hieman manuaalista ohjausta — käytä Thunderbitin manuaalista valintaa tai kehotteita.
- Tietotyypit: Numerot pilkuilla tai päivämäärät oudossa muodossa? Aseta saraketyyppi ennen vientiä tai siivoa data Excelissä/Sheetsissä.
- Tiedosto- ja sivurajoitukset: Massiiviset PDF:t? Pilko ne pienempiin osiin tai käytä Thunderbitin pilvitilaa erätehtäviin.
- Tekoälyn “hallusinaatiot”: Harvinaisia, mutta joskus tekoäly saattaa arvata sarakkeen nimen tai täyttää puuttuvaa dataa. Tarkista tulos aina silmäillen, etenkin tärkeät numerot.
- Manuaalinen tarkistus: Kun kyse on kriittisestä datasta, tee nopea validointi — automaattiset työkalut ovat tarkkoja, mutta ihmisen silmä ei ole koskaan pahitteeksi.
Ja jos tulet seinään vastaan, Thunderbitin tuki ja yhteisö auttavat.
Yhteenveto ja tärkeimmät opit: miten saat PDF-scrapingin toimimaan liiketoiminnassasi
Vedetään yhteen. Datan poimiminen PDF:istä oli ennen painajainen — hidasta, virhealtista ja yksinkertaisesti rasittavaa. Mutta nykyaikaisilla työkaluilla kuten Thunderbit se on nyt nopeaa, tarkkaa ja, uskallan sanoa, melkein jopa nautittavaa.
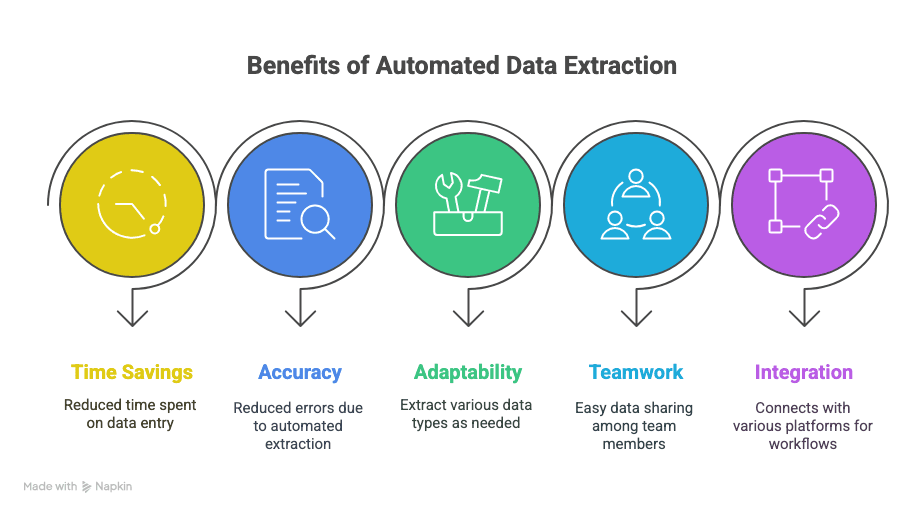
Saat käyttöösi tämän:
- Aikaa takaisin: Säästät tunteja — jopa viikkoja — manuaalisessa tietojen syötössä.
- Vähemmän virheitä: Automatisoitu poiminta tarkoittaa vähemmän kirjoitusvirheitä ja unohtuneita rivejä.
- Joustavuutta: Poimi juuri se mitä tarvitset — tekstiä, taulukoita, kuvia, linkkejä, mitä vain.
- Yhteistyötä: Jaa data välittömästi tiimisi kanssa, missä tahansa he ovatkin.
- Älykkäämpiä työnkulkuja: Integroi Sheetsiin, Notioniin, Airtableen ja muualle.
Valmiina kokeilemaan? Lataa Thunderbit Chrome -laajennus, aja se seuraavan PDF:si läpi ja huomaa, kuinka paljon helpompaa elämä voi olla. Tuleva minäsi (ja ranneliikkeesi) kiittävät.
Lisää vinkkejä ja oppaita löydät Thunderbit Blogista tai syvenny aiheeseen artikkelissa Kuinka poimia dataa PDF:stä tekoälyn avulla.
Muutetaan PDF-päänsäryt tuottavuusvoitoiksi — yksi klikkaus kerrallaan.
Shuai Guan, Thunderbitin toinen perustaja ja toimitusjohtaja
Kokeile Thunderbitin tekoälypohjaista PDF-scraperia Get Started Free




